技能才是AI Agent的“灵魂“,小模型+技能包竟能超越大模型?
这篇《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》由多个大学合作的研究成果,针对现在特别火爆的Skills进行了系统性、体系化的深度研究,从构建数据集、制定测评指标、开展实验室验证进行了全流程的研究,目的就是要告诉大家构建skills的最佳实践。正如[前期的文章]提到的,现在AI生态中,Agent是操作系统,LLM是芯片,Skills就是应用程序,这里就是要告诉你构建应用程序要遵循的原则。
在人工智能领域,当前这些尖端的大语言模型(LLM)被投入到医疗诊断、精密制造或复杂的金融审计等特定行业任务时,它们往往表现得像是一个博学但缺乏实践经验的“职场新人”——空有海量知识,却不知道具体的“活儿”该怎么干。
根据最新发布的 SkillsBench 研究,这种“知识”与“执行”之间的断层,正通过Agent Skills(智能体技能)得到弥补。如果我们把模型比作 CPU,把 Agent Harness(如 Claude Code、Gemini CLI)比作操作系统,那么 Skills 就是运行其上的“应用程序”。这份涵盖 11 个领域、86 个任务的深度报告揭示了一个令技术决策者深思的真相:模型本身的规模(Scaling Laws)并非万能,人类精心编排的“程序性知识”(Procedural Knowledge)才是 Agent 进化为真正生产力的关键。
1.模型无法“自学成才”,人类智慧依然不可替代
在许多人的想象中,既然 LLM 已经具备极强的推理能力,它们理应能通过“自我提示”生成操作规程来指导自己。但 SkillsBench 的数据无情地击碎了这个幻想。
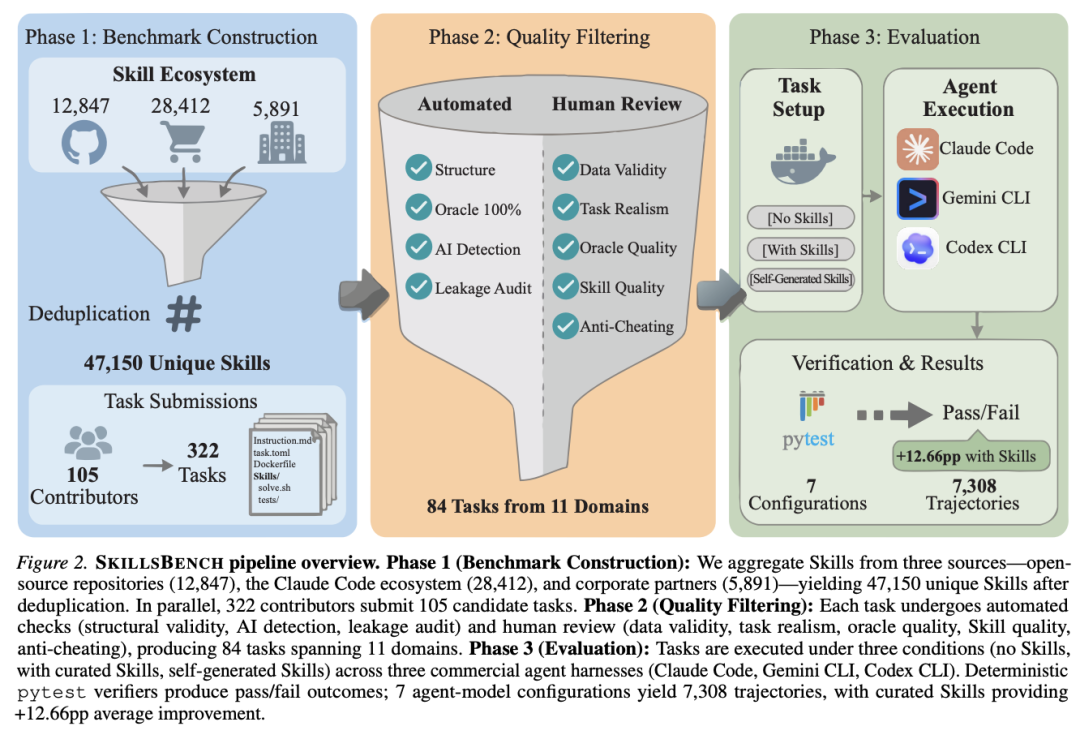
实验对比了三种条件下的表现:
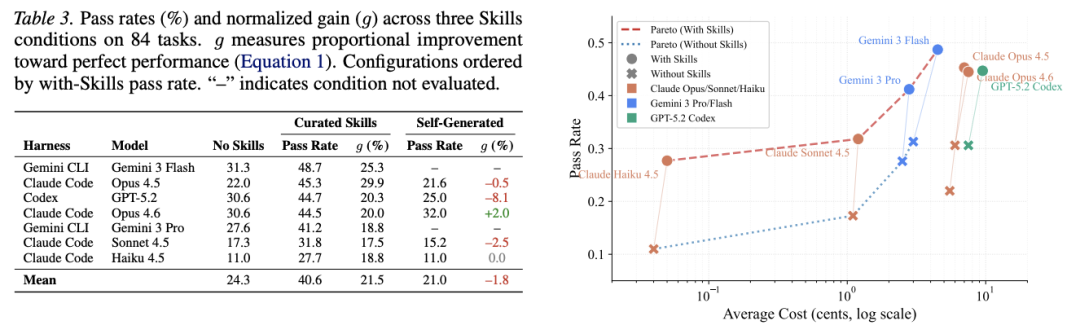
- 人工精选技能 (Curated Skills):平均将任务通过率提升了16.2 个百分点。
- 自生成技能 (Self-generated Skills):平均表现提升仅为-1.3 个百分点(甚至在部分模型上出现了负增长)。
有效的技能需要人类策划的领域专家知识,模型无法可靠地通过自生成获取这些程序性知识。研究识别出了模型“自学”失败的两大关键模式:首先,模型往往“完全无法识别”高专业度任务对特定技能的需求,转而尝试用通用的平庸方法解决问题;其次,即使意识到需要技能,模型生成的程序也往往极其模糊。
2.医疗与制造业是“技能”的最大受益者
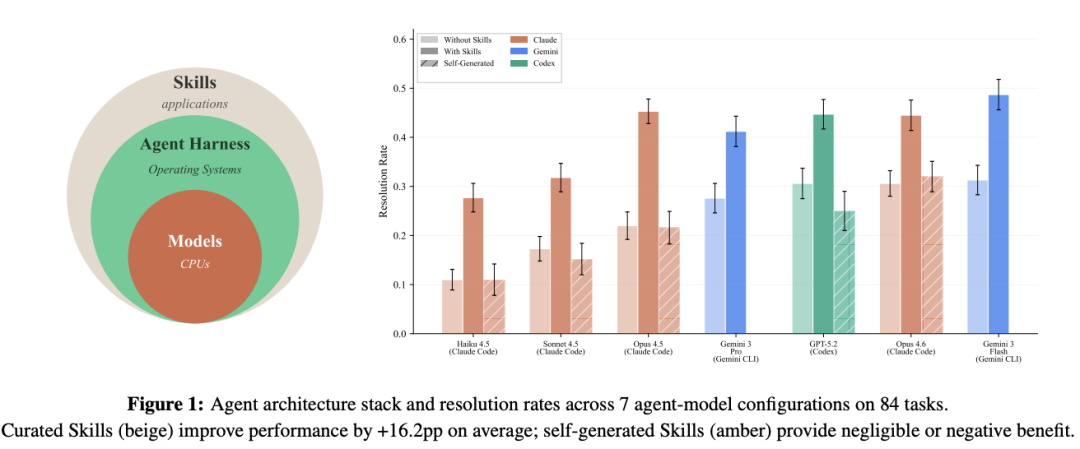
Agent Skills 的辅助效果在不同领域表现出极大的异质性。在预训练数据较少的“专业深水区”,外部技能包的辅助效果最为显著。
- 医疗领域 (Healthcare):提升幅度高达+51.9pp。
- 制造业 (Manufacturing):提升幅度高达+41.9pp。
- 网络安全 (Cybersecurity):提升幅度为+23.2pp。
- 软件工程 (Software Engineering):提升幅度仅为+4.5pp。
这种差异背后的逻辑非常明确:在软件工程等领域,模型在预训练阶段已经“见过”海量的代码和文档,因此边际收益递减。但在临床数据协调或制造业工艺优化等任务中,模型存在严重的程序性知识空白,此时由人类专家策划分发的技能包就成了填补鸿沟的基石。
3.小模型 + 技能包 = 跨模型的“帕累托前沿”移动
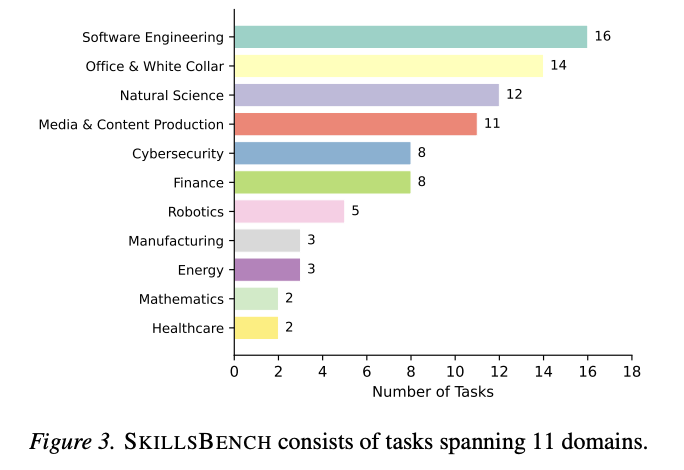
这或许是该研究对企业级应用最具商业价值的发现:通过注入技能,轻量级模型能够实现“以弱胜强”的跨模型性能跨越(Cross-Model Pareto Frontier Shift)。
具体数据显示:
- Claude Haiku 4.5(带技能):胜率为27.7%。
- Claude Opus 4.5(无技能):胜率仅为22.0%。
这意味着通过优化外部技能模块,初创公司和企业开发者可以用成本更低、速度更快的轻量级模型,实现超越旗舰模型的表现。这为企业提供了一个更具成本效益的路径:不再单纯依赖昂贵的大模型推理,而是通过精密的“技能工程”来提升业务表现。
4.“文档极简主义”:防范“认知负荷”导致的性能倒退
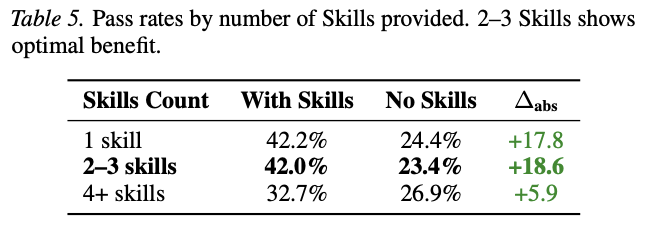
在为 Agent 编写技能文档时,开发者往往倾向于面面俱到。然而,SkillsBench 提出了一个反直觉的警告:过度详尽的文档(Comprehensive Documentation)实际上会导致性能下降。
实验数据显示:
- 2–3 个技能模块:任务表现提升幅度最高,达到+18.6pp。
- 4 个以上模块:提升幅度骤降至+5.9pp。
- 全百科全书式文档:导致性能负增长-2.9pp。
这种现象被称为“认知负荷”(Cognitive Load)。过度的信息会在长上下文中产生干扰,导致模型在处理复杂指令时“迷失”。高效的技能设计应当遵循“黄金比例”:提供简洁、分步骤且带有至少一个工作示例的定义。
5.成本效率的艺术:迭代探索与代币博弈
引入技能包虽然会增加 6%–13% 的输入 Token 消耗,但其带来的性能飞跃远超成本支出。以 Gemini 3 Flash为例,它展现了一种独特的“补偿策略”:
- Token消耗:它通过增加“迭代探索”(Iterative Exploration)来换取推理深度,其输入 Token 消耗量是 Pro 模型的2.3 倍(1.08M vs 0.47M)。
- 最终成本:尽管 Token 数量更多,但由于其单价远低于 Pro 模型,在标准非缓存 API 定价下,完成单次任务的总成本反而便宜了44% 到 47%。
这证明了技能注入不仅是性能的助推器,更是成本效率的优化器。它允许模型减少无效的盲目尝试,将昂贵的计算资源聚焦在正确的执行路径上。
结语:从“Scaling Laws”转向“Skill Engineering”
SkillsBench 的研究标志着 AI Agent 开发范式的深刻转型。未来的竞争核心将不再仅仅是模型参数的原始积累,而是编排与程序化技能的精度竞赛。
如果未来的 AI 核心能力趋于平稳,那么谁能为 AI 提供更精准、更模块化、更符合行业直觉的“操作手册”,谁就能在实际商业场景中赢得先机。技能是填补 LLM 程序性知识空白的桥梁,而高质量的人类策划分发,则是这座桥梁赖以生存的基石。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)