空间智能 | 基线 对比汇总 | 数据集
本文系统分析了当前主流的空间智能评估基准(VSI-Bench、SITE-Bench、SAT等),从核心数据、任务类型、数据规模等维度进行对比。
这些基准主要测试多模态模型的空间感知与推理能力,涵盖空间构型理解、深度几何、尺寸测量、关系推理、运动预测、视角转换等任务类型。
🗺️ 一、空间智能基准测试全景对比
本文汇总分析主流空间智能评估基准,包括:核心数据对比、数据规模、任务类型、数据特点 等关键维度:
📊 1.1、基础信息对比
| 基准名称 | 主导机构 | 核心作者 | 年份 | 论文链接 | 代码仓库 | 数据集/模型 |
|---|---|---|---|---|---|---|
| VSI-Bench | 纽约大学、耶鲁大学、斯坦福大学 | 李飞飞、谢赛宁等 | 2025 | arXiv:2412.14171 | GitHub | HF: VSI-Bench |
| SITE-Bench | 微软研究院、华盛顿大学、AI2 | Wenqi Wang、Jianfeng Gao 等 | 2025 | arXiv:2505.05456 | GitHub | HF: SITE-Bench |
| SAT | 波士顿大学、华盛顿大学、AI2 | Arijit Ray、Kate Saenko 等 | 2025 | OpenReview | GitHub | HF: Qwen2.5-VL-SAT |
| MMSI-Bench | 上海 AI Lab、港中文、浙大、清华、上交 | Runsen Xu、Tai Wang 等 | 2025 | arXiv:2505.23764 | GitHub | HF: MMSI-Bench |
| MindCube | 西北大学 MLL Lab、斯坦福、清华、上海 AI Lab | 李飞飞、谢赛宁、Yin Baiqiao 等 | 2025 | arXiv:2506.21458 | GitHub | HF: MindCube |
| BLINK | 宾夕法尼亚大学、华盛顿大学、AI2 | Xingyu Fu、Ranjay Krishna 等 | 2024 | arXiv:2404.12390 | GitHub | HF: BLINK |
📊 1.2、空间智能基线核心数据对比表
| 基准名称 | 发布机构 | 总样本量 | 数据模态 | 图像/视频数 | 任务类别 | 认知层次 | 核心任务类型 |
|---|---|---|---|---|---|---|---|
| VSI-Bench | 纽约大学、斯坦福、耶鲁 | 5,170 QA | 视频为主 | 真实室内视频 | 3 大类 | 5 维度(感知、记忆、关系、语言、时间) | 空间构型(计数/方向/距离/路径)、测量(距离/尺寸)、时空(顺序) |
| SITE-Bench | 微软研究院、华盛顿大学、AI2 | 8,068 QA | 图像+视频 | 13,172 图 / 3,808 视频 | 6 大类别 | 3 层次(感知→理解→推断) | 物体计数、关系推理、定位、3D信息、多视角、运动预测 |
| SAT | 波士顿大学、华盛顿大学、AI2 | 218K QA | 合成+真实 | 22K 合成场景 / 150 真实 QA | 5 大类 | 动态空间能力 | 自我中心运动、物体运动、视角转换、动作识别、物体跟踪 |
| MMSI-Bench | 上海AI Lab、港中文、清华等 | 1,000 QA | 多图像 | 120K+ 候选图池 | 10+1 类 | 位置/属性/运动三维度 | 位置关系(6类)、属性感知(2类)、运动推理(2类)、多步推理 |
| MindCube | 斯坦福、西北大学、上海AI Lab | 21,154 QA | 多视角图像 | 3,268 场景图 | 3 维度 | 位置表征/方向感知/动态推理 | 位置表征、方向感知、动态推理 |
| BLINK | 宾大、华盛顿大学、AI2 | 3,807 QA | 图像 | 单图/多图/视觉提示 | 14 类 | 纯视觉感知(深度/几何/对应) | 深度几何、视觉对应、物体属性、结构理解、高级感知 |
📈 1.3、数据规模与来源对比
| 基准 | 数据构建方式 | 源数据集数量 | 新标注比例 | 数据特点 |
|---|---|---|---|---|
| VSI-Bench | 筛选+重组 | 2+ (Ego4D, Epic-Kitchens) | 部分新标注 | 真实室内第一人称视频 |
| SITE-Bench | 整合+过滤+分层采样 | 31 个 (22图+8视频) | 13.9% (1,125条) | 最大规模多源整合 |
| SAT | 程序化合成 | 自建 | 100% 合成 | 22K 合成场景,可无限扩展 |
| MMSI-Bench | 全人工设计 | 8 个真实数据集 | 100% 专家标注 | 300+小时人工打磨 |
| MindCube | 合成+真实混合 | 自建 | 部分 | 多视角室内场景 |
| BLINK | CV任务重组 | 14 个经典CV任务 | 重组标注 | 经典计算机视觉任务改编 |
二、VSI-Bench:多模态大模型的视觉空间智能探索
> 项目概览:纽约大学、耶鲁大学和斯坦福大学联合研究团队(包括李飞飞、谢赛宁等)提出的视觉空间智能基准测试,探索多模态大语言模型(MLLMs)如何从视频中感知、记忆和回忆三维空间。
🔗 1、核心资源
| 资源类型 | 链接 | 说明 |
|---|---|---|
| 论文 PDF | arXiv:2412.14171 | 《Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces》 |
| 代码仓库 | GitHub | 项目代码、评估脚本与工具 |
| 数据集 | Hugging Face | VSI-Bench 数据集(5000+ 问答对) |
| 项目主页 | Website | 可视化演示与补充材料 |
🧠 2、研究背景
人类具备通过连续视觉观察记忆空间的视觉-空间智能(Visual-Spatial Intelligence)。那么,经过百万级视频数据集训练的多模态大语言模型(MLLMs),是否也能像人类一样"在空间中思考"?
该研究旨在回答一个核心问题:MLLMs 在观看完一段视频后,能否理解和记忆其中的三维空间信息?
📊 3、VSI-Bench 基准测试
VSI-Bench(Visual-Spatial Intelligence Benchmark),这是一个基于视频的视觉空间智能评估基准:
数据集统计
| 属性 | 数值 | 说明 |
|---|---|---|
| 总样本数 | 5,170 | 高质量问答对 |
| 视频来源 | Ego4D, Epic-Kitchens 等 | 真实室内第一人称视频 |
| 任务类别 | 3 大类 | 构型、测量、时空 |
| 能力维度 | 5 维度 | 感知、记忆、关系、语言、时间 |
| 评估方式 | 零样本(Zero-shot) | 无需特定任务微调 |
如下图所示,展示了VSI-Bench的任务分为三类:构型任务、测量估计任务、时空任务。
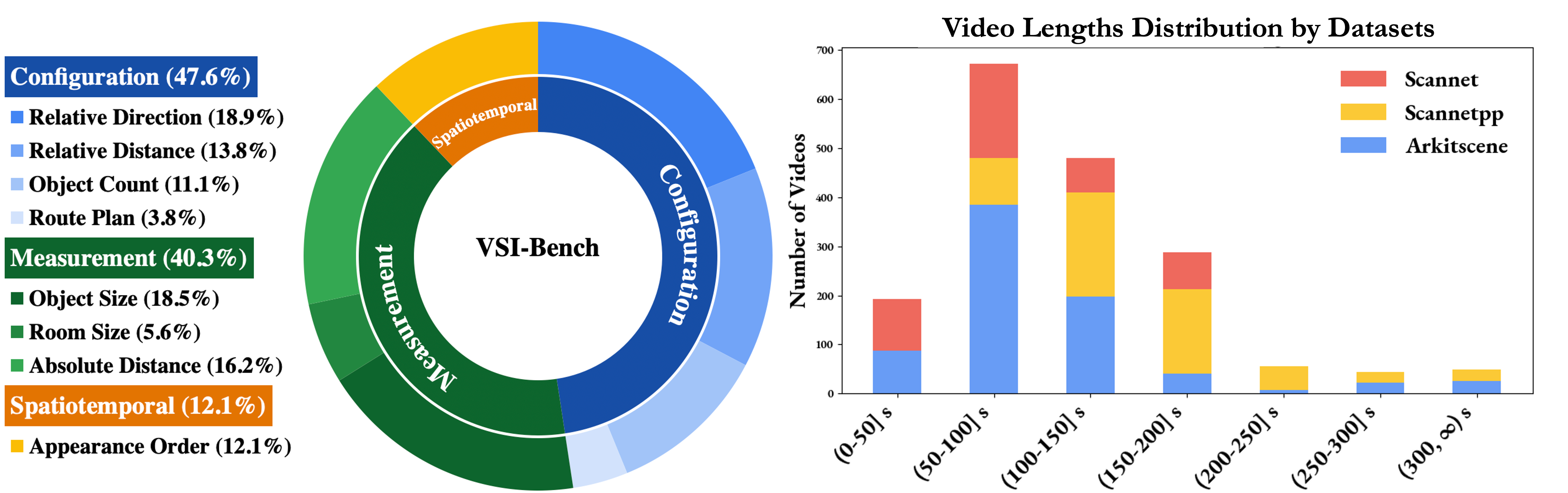
1. 构型任务(Configurational)
评估模型对空间布局的理解:
- 物体计数(Object Counting)
- 相对方向(Relative Direction)
- 相对距离(Relative Distance)
- 路径规划(Path Planning)
2. 测量估计(Measurement)
测试模型对物理尺度的感知:
- 绝对距离(Absolute Distance)
- 物体尺寸(Object Size)
- 房间大小(Room Size)
3. 时空任务(Spatiotemporal)
- 考察时间维度上的空间变化:物体出现顺序(Object Order)
💡 任务类型详细分类
| 任务类型 | 子任务 | 描述 | 示例子问题 |
|---|---|---|---|
| 构型任务 | Object Counting | 统计特定物体数量 | “视频中有多少个椅子?” |
| Relative Direction | 判断相对方向 | “冰箱在门的哪一侧?” | |
| Relative Distance | 比较物体间距离 | “沙发和电视,哪个离摄像机更近?” | |
| Room Size | 估计房间尺寸 | “这个房间有多大?” | |
| Path Planning | 路径规划能力 | “从A点到B点需要经过哪些房间?” | |
| 测量估计 | Absolute Distance | 绝对距离估计 | “摄像机距离桌子大约多远?” |
| Object Size | 物体尺寸估计 | “这个茶几大概有多宽?” | |
| 时空任务 | Object Order | 物体出现顺序 | “按从近到远顺序排列看到的物体” |
三、SITE-Bench:空间智能全面评估基准——从感知到推理的三层认知框架
项目概览:微软研究院、华盛顿大学、艾伦人工智能研究所(AI2)等机构联合研究团队提出的空间智能全面评估基准,系统性地将
空间智能划分为感知、理解、推断三个认知层次,构建首个覆盖全谱系空间能力的评估体系。
🔗 1、核心资源
| 资源类型 | 链接 | 说明 |
|---|---|---|
| 论文 PDF | arXiv:2505.05456 | 《SITE: towards Spatial Intelligence Thorough Evaluation》(ICCV 2025 接收) |
| 代码仓库 | GitHub | 评估代码、数据集处理工具与实验脚本 |
| 数据集 | Hugging Face | SITE-Bench 数据集(多维度空间推理任务) |
| 项目主页 | Website | 论文详情与补充材料 |
🧠 2、研究背景
当前多模态大语言模型(MLLMs)在空间推理任务上取得了显著进展,但现有基准测试往往只关注单一认知层次(如仅测试空间关系理解或仅测试几何推理)。然而,人类的空间智能是一个从基础感知到高级推断的连续认知体系。
该研究旨在回答一个核心问题:如何系统性地评估 MLLMs 在完整空间认知谱系上的表现,从感知物体几何属性,到理解空间关系,再到推断不可见状态?
研究团队基于认知科学理论(三种分类系统:Hegarty 的空间尺度理论、空间可视化与定向理论、Uttal 的 2×2 分类系统),提出首个三层认知框架的空间智能评估基准,填补了现有评估体系碎片化、层次单一的空白。
📊 3、SITE-Bench 基准测试
SITE(Spatial Intelligence Thorough Evaluation),这是一个基于三层认知层次的空间智能评估框架:
3.1 认知层次架构
| 认知层次 | 定义 | 核心能力 | 代表性任务 |
|---|---|---|---|
| L1: 空间感知 | 感知个体物体及其内在空间属性 | 3D 检测、3D 分割、方向估计、深度估计 | 物体几何结构识别、朝向判断 |
| L2: 空间理解 | 推理物体间的相对空间排列 | 空间关系理解、相对距离/方向判断 | 物体间位置关系、场景布局理解 |
| L3: 空间推断 | 推理超出直接可见环境的状态 | 空间模拟、心理旋转、视角转换、路径规划 | 遮挡推理、未来状态预测、导航规划 |
3.2 数据集统计(基于 Hugging Face 官方数据)
| 属性 | 数值 | 说明 |
|---|---|---|
| 总样本量 | 8,068 条 QA 对 | 标准化多项选择视觉问答格式 |
| ├─ 图像测试集 | 4,260 条 (52.8%) | image_test 子集 |
| └─ 视频测试集 | 3,808 条 (47.2%) | video_test 子集 |
| 问题选项分布 | ||
| ├─ 4 选项问题 | 5,019 条 (62.2%) | 主流格式 |
| ├─ 2 选项问题 | 1,573 条 (19.5%) | 是/否判断类 |
| └─ 3/5/6 选项问题 | 1,476 条 (18.3%) | 多样化选项 |
| 数据来源 | 31 个数据集 | |
| ├─ 现有图像数据集 | 22 个 | VSR、CV-Bench、GQA、VQA 等 |
| ├─ 现有视频数据集 | 8 个 | VSI-Bench、VideoMME、MLVU 等 |
| └─ 新标注数据集 | 1 个 | Ego-Exo4D(视角转换任务) |
| 视觉数据规模 | ||
| ├─ 图像数量 | 13,172 张 | 单图/多图场景 |
| └─ 视频数量 | 3,808 个 | 动态场景 |
| 标注类型 | ||
| ├─ 现有标注样本 | 6,943 条 (86.1%) | 来自已有数据集 |
| └─ 新标注样本 | 1,125 条 (13.9%) | 视角转换与动态场景任务 |
3.3 六大粗粒度类别分布
| 类别 | 英文缩写 | 说明 |
|---|---|---|
| 计数与存在判断 | Count. | Counting and Existence |
| 空间关系推理 | Rel. | Spatial Relationship Reasoning |
| 物体定位与位置 | Loc. | Object Localization and Positioning |
| 3D 信息理解 | 3D Inf. | 3D Information Understanding |
| 多视角推理 | MultiV. | Multi-View Reasoning |
| 运动预测与导航 | Mov. | Movement Prediction and Navigation |
💡 4、任务类型详细分类
SITE-Bench 基于三层认知框架,构建了覆盖全谱系的空间推理任务:
4.1 空间感知任务(Level 1)
评估模型对个体物体空间属性的感知能力:
| 任务类型 | 描述 | 示例子问题 |
|---|---|---|
| 3D 物体检测 | 从 2D 图像推断 3D 边界框,感知物体三维尺寸与体积 | “物体的长宽高分别是多少?” |
| 3D 分割 | 分离个体物体及其 3D 边界,获取几何结构 | “圈出物体的 3D 轮廓” |
| 方向估计 | 预测物体相对于相机坐标系的旋转姿态 | “物体相对于相机是朝左还是朝右偏转?” |
| 深度估计 | 感知场景深度信息 | “物体 A 距离相机有多远?” |
| 绝对大小判断 | 判断物体在图像中的相对大小 | “the sheep is large in relation to the image” |
| 相对大小判断 | 比较两个物体的大小关系 | “the mouse is bigger than the car in size” |
4.2 空间理解任务(Level 2)
评估模型对物体间空间关系的理解能力:
| 任务类型 | 描述 | 示例子问题 |
|---|---|---|
| 空间关系推理 | 判断物体间相对位置(左右、前后、上下) | “茶壶在杯子的左侧还是右侧?” |
| 相对距离判断 | 比较物体间距离远近 | “苹果和香蕉,哪个离相机更近?” |
| 实例定位 | 在场景中定位特定物体 | “找出场景中所有的圆形物体” |
| 绝对距离估计 | 估计物体与观察者的绝对距离 | “沙发距离摄像机大约 3 米还是 5 米?” |
4.3 空间推断任务(Level 3)
评估模型对不可见状态的推断与预测能力:
| 任务类型 | 描述 | 示例子问题 |
|---|---|---|
| 遮挡推理 | 推断被遮挡或隐藏的元素 | “桌子后面可能有什么物体?” |
| 心理旋转 | 模拟物体旋转后的朝向变化 | “物体顺时针旋转 90 度后会是什么形状?” |
| 空间操作推理 | 推理物体移动或物理交互后的结果 | “把红色方块推到蓝色方块旁边,会发生什么?” |
| 视角转换(View Association) | 从指定视角推理场景状态 | “从右侧看,物体会出现在左边还是右边?” |
| 帧序列重排(Frames Reordering) | 根据运动动态推断时间顺序 | “将打乱的帧按正确时间顺序排列” |
| 空间规划 | 在给定布局中生成导航路径 | “从 A 点到 B 点的最短路径是什么?” |
| 逆向渲染 | 从 2D 图像推断 3D 几何与材质 | “这个物体的 3D 形状是什么样的?” |
4.4 两项新提出的任务
| 任务名称 | 类型 | 说明 |
|---|---|---|
| Ego-Exo View Association | 外在-静态 | 关联自我中心视角(egocentric)与他人中心视角(exocentric)的图像 |
| Shuffled Frames Reordering | 外在-动态 | 根据运动动态对打乱的多视角帧序列进行时间排序 |
任务示例1,如下图所示: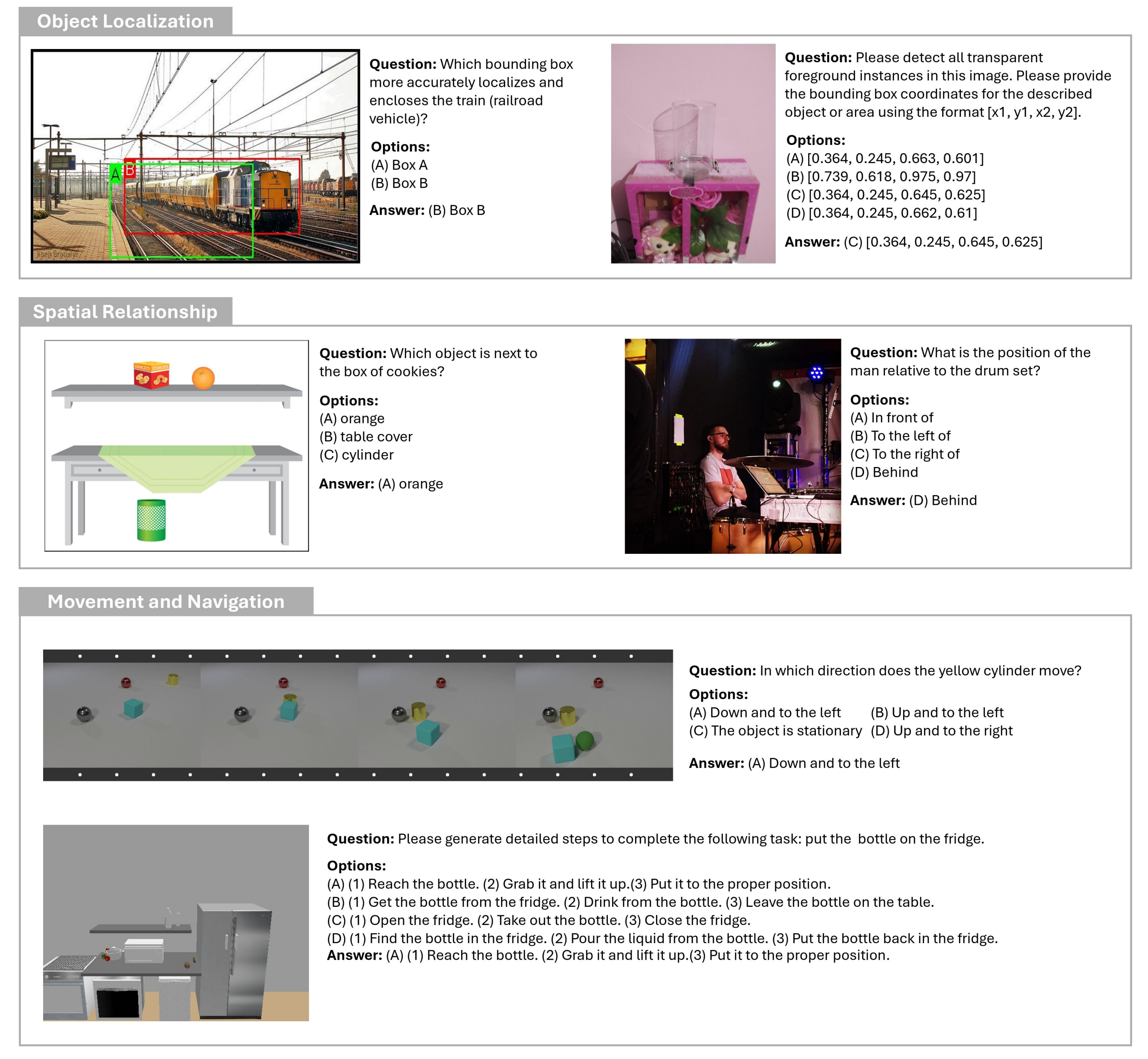
任务示例2,如下图所示:
](h
🎯 5、SITE-Bench 的独特价值
与现有空间推理基准相比,SITE-Bench 具有以下创新特征:
| 特征 | SITE-Bench 设计 | 现有基准局限 |
|---|---|---|
| 认知层次 | 三层完整架构(感知-理解-推断) | 仅覆盖单一层次(多为理解层) |
| 任务多样性 | 6 大类别 + 30+ 源数据集 | 集中于空间关系问答 |
| 模态支持 | 单图、多图、视频三种模态 | 以单视图 2D 图像为主 |
| 评估标准 | CAA 校正准确率,消除选项数量偏差 | 普通准确率,受选项数量影响 |
| 认知科学基础 | 三种认知科学分类系统驱动设计 | 缺乏系统性理论指导 |
| 新任务设计 | 视角转换 + 动态帧重排 | 缺乏视角变换类任务 |
📚 6、数据来源详情
| 数据类型 | 来源数据集示例 |
|---|---|
| 图像数据集(22个) | VSR、CV-Bench、GQA、VQA、CLEVR、SPEC(绝对/相对大小)等 |
| 视频数据集(8个) | VSI-Bench、VideoMME、MLVU、MVBench 等 |
| 新标注数据集(1个) | Ego-Exo4D(5,035 个多视角视频片段) |
四、SAT:多模态大模型的空间能力训练——从静态推理到动态感知
> 项目概览:波士顿大学、华盛顿大学、艾伦人工智能研究所(AI2)等机构联合研究团队提出的空间能力训练框架,通过合成数据训练提升多模态大语言模型(MLMs)在动态空间推理(如视角转换、自我中心动作识别)上的能力。
🔗 1、核心资源
| 资源类型 | 链接 | 说明 |
|---|---|---|
| 论文 PDF | OpenReview | 《SAT: Spatial Aptitude Training for Multimodal Language Models》 |
| 代码仓库 | GitHub | 项目代码、数据生成工具与评估脚本 |
| 预训练模型 | Hugging Face | 基于 Qwen2.5-VL 的 SAT 微调模型(13B) |
| 项目主页 | Website | 数据集可视化与动态推理示例 |
🧠 2、研究背景
现有研究表明,多模态大语言模型(MLMs)在空间推理方面存在明显短板。但以往基准测试仅关注静态空间推理(如判断物体相对位置),而现实世界的机器人导航、自动驾驶等应用需要动态空间能力——如视角转换(perspective-taking)和以自我为中心的动作识别(egocentric action recognition)。
该研究旨在回答:如何让 MLMs 不仅理解静态空间关系,还能推理动态变化(如相机移动、物体运动)带来的空间变化?
📊 3、SAT 数据集与基准测试
SAT(Spatial Aptitude Training),这是一个结合合成训练数据与真实图像测试集的空间能力评估框架:
数据集统计
| 属性 | 数值 | 说明 |
|---|---|---|
| 问答对数量 | 218K | 训练集+测试集(涵盖静态与动态任务) |
| 场景数量 | 22K | 合成场景(使用照片级真实感物理引擎生成) |
| 任务类别 | 5 大类 | 自我中心运动、物体运动、视角转换、动作识别、物体跟踪 |
| 真实测试集 | 150 QA | 真实世界图像构成的动态空间推理测试 |
| 数据生成方式 | 程序化生成 | 可任意扩展,支持新动作、场景和 3D 资产 |
如下图所示,展示了 SAT 从静态空间问题(现有基准)扩展到动态空间问题的思路,包括相机移动、物体运动和多视角推理。
模拟的数据示例,如下图所示:
真是场景数据示例,如下图所示:
💡 4、任务类型详细分类
SAT 基于认知科学中的空间认知测试,构建了五类动态空间推理任务:
| 能力维度 | 子任务 | 描述 | 示例子问题 |
|---|---|---|---|
| 自我中心运动 | Egocentric Movement | 判断相机如何移动 | “相机从第一帧到第二帧是如何移动的?(向左转并前进)” |
| 物体运动 | Object Movement | 检测物体移动方向 | “从第一帧到第二帧,有物体移动了吗?(红色盒子离相机更近了)” |
| 视角转换 | View Transformation | 想象其他视角的场景 | “如果从右侧看,物体会出现在左边还是右边?” |
| 动作识别 | Action Recognition | 识别执行的动作 | “视频中的人物正在执行什么动作?” |
| 物体跟踪 | Object Tracking | 跨帧跟踪物体位置 | “绿色物体在两帧之间移动了多远?” |
🎯 5、关键实验发现
5.1 动态推理的"盲点"
即使在静态空间问题上表现良好的 MLMs(如 GPT-4V、Gemini),在动态空间问题上仍表现不佳,准确率显著下降。这表明动态空间推理是比静态推理更具挑战性的能力。
5.2 合成数据的真实迁移能力
使用 SAT 合成数据进行指令微调后,模型在真实图像基准上的零样本性能显著提升:
| 基准测试 | 性能提升 | 说明 |
|---|---|---|
| CVBench | +23% | 经典空间推理基准 |
| BLINK | +8% | 挑战性视觉感知基准 |
| VSR | +18% | 视觉空间推理基准 |
5.3 小模型匹配大模型
当在 SAT 上进行指令微调时:
- LLaVA-13B 模型在空间推理能力上与 GPT-4V 和 Gemini-3-1.0 等更大规模的专有模型相匹配[48][51]
- Qwen2.5-VL-7B 经过 SAT 训练后,在动态空间推理任务上实现平均 11% 的性能提升[60]
5.4 完美标注 vs 伪标注
研究揭示了一个重要发现:模拟环境中完美的 3D 标注比真实图像的伪标注(pseudo-annotation)更有效。这证明了合成数据在教授空间能力方面的价值。
🔬 6、技术方法
数据生成流程
- 3D 仿真环境:使用物理引擎生成照片级真实感场景
- 动作执行:在场景中执行相机移动(旋转/平移)或物体移动
- 3D 信息提取:利用特权信息(privileged 3D information)获取精确的物体位置、相机位姿
- QA 生成:基于动作前后 3D 场景的变化自动生成问答对
训练策略
- 指令微调(Instruction Tuning):在 SAT 数据上进行微调
- 模型架构:支持 LLaVA、Qwen2.5-VL 等多种架构
- 跨模态对齐:改善视觉-语言在空间理解上的对齐
五、MMSI-Bench:多图像空间智能基准——揭示多模态大模型的"空间盲区"
> 项目概览:上海人工智能实验室、香港中文大学、浙江大学、清华大学、上海交通大学等机构联合研究团队提出的多图像空间智能评估基准,通过人工精心设计的千道难题,揭示当前多模态大语言模型(MLLMs)在多视角空间推理上与人类的巨大鸿沟。
🔗 1、核心资源
| 资源类型 | 链接 | 说明 |
|---|---|---|
| 论文 PDF | arXiv:2505.23764 | 《MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence》 |
| 代码仓库 | GitHub | 项目代码、评估脚本与自动化错误分析工具 |
| 数据集 | Hugging Face | MMSI-Bench 数据集(1,000 问答对,120,000+ 候选图像) |
| 项目主页 | Website | 数据可视化、样例展示与错误分析演示 |
🧠 2、研究背景
空间智能(Spatial Intelligence)是多模态大语言模型(MLLMs)在复杂物理世界中运行的核心能力——理解物体位置、运动轨迹以及场景几何关系。然而,现有基准测试大多仅探查单图像空间理解,局限于简单的空间关系判断。
真实世界的空间理解更为复杂:模型必须跨越多张图像进行推理,追踪物体和相机(自我)运动,并关联那些在单帧中从未共现的实体。该研究旨在回答一个核心问题:当前 MLLMs 是否具备真正的多图像空间推理能力?它们能否整合来自不同视角或时间点的信息,重建三维场景并执行复杂的空间推断?
📊 3、MMSI-Bench 基准测试
研究团队构建了 MMSI-Bench(Multi-image Spatial Intelligence Benchmark),这是一个专为多图像空间智能设计的视觉问答(VQA)评估基准:
数据集统计
| 属性 | 数值 | 说明 |
|---|---|---|
| 问答对数量 | 1,000 | 高质量多项选择题(4选项) |
| 候选图像池 | 120,000+ | 来自8个真实世界数据集 |
| 人均研发时间 | 300+ 小时 | 6名3D视觉研究人员精心制作 |
| 平均图像数/题 | 2.55 | 基础任务2张,多步推理任务更多 |
| 任务类别 | 10 类基础 + 1 类进阶 | 覆盖位置、属性、运动三维度 |
| 人类准确率 | 97% | 专家级表现 |
| 最强开源模型 | ~30% | 如 InternVL3-78B、Qwen2.5-VL-72B |
| OpenAI o3/GPT-5 | 40% | 最佳闭源模型表现 |
| 随机猜测基线 | 25% | 4选1随机概率 |
💡 4、任务类型详细分类
MMSI-Bench 基于空间认知科学,围绕三个核心空间元素(相机/观察者、物体、区域),构建了十类基础空间推理任务及多步推理任务:
| 认知维度 | 子任务 | 描述 | 示例子问题 |
|---|---|---|---|
| 位置关系 | 相机-相机 | 多相机位姿关系判断 | “从Image 2的视角看,Image 1中的物体会出现在左侧还是右侧?” |
| 相机-物体 | 相机与物体的相对位置 | “从当前相机位置看,红色盒子在视野的左边还是右边?” | |
| 相机-区域 | 相机与场景区域的关系 | “相机位于房间的东北角还是西南角?” | |
| 物体-物体 | 物体间相对空间排列 | “茶壶在杯子的左侧还是右侧?” | |
| 物体-区域 | 物体在区域中的位置 | “冰箱位于厨房区域内还是客厅区域内?” | |
| 区域-区域 | 场景区域间关系 | “卧室相对于客厅位于北侧还是南侧?” | |
| 属性感知 | 测量估计 | 空间尺度量化 | “两张图中,哪张的相机距离地面更高?” |
| 外观属性 | 视角相关的视觉属性 | “从Image 1到Image 2,物体的颜色变亮还是变暗?” | |
| 运动推理 | 相机运动 | 自我中心运动判断 | “从Image 1到Image 2,相机是向左转还是向右转?” |
| 物体运动 | 物体运动轨迹追踪 | “蓝色方块在两帧之间是靠近还是远离相机?” | |
| 多步推理 | 链式空间推理 | 组合多类基础任务 | “先找到厨房,然后判断灶台相对于冰箱的位置,最后规划从冰箱取食材到灶台的路线” |
数据来源
MMSI-Bench 整合了8个多样化的真实世界数据集:
| 数据集 | 场景类型 | 特点 |
|---|---|---|
| ScanNet | 室内场景 | 房间级3D重建 |
| Matterport3D | 室内大空间 | 多层建筑扫描 |
| DTU | 小型物体 | 多视角立体重建 |
| nuScenes | 自动驾驶 | 户外道路环境 |
| Waymo | 自动驾驶 | 高质量传感器数据 |
| Ego4D | 第一人称视频 | 人类日常活动 |
| AgiBot-World | 机器人操作 | 机械臂交互场景 |
| DAVIS 2017 | 视频对象分割 | 动态物体追踪 |
任务示例1,如下图所示:
任务示例2,如下图所示: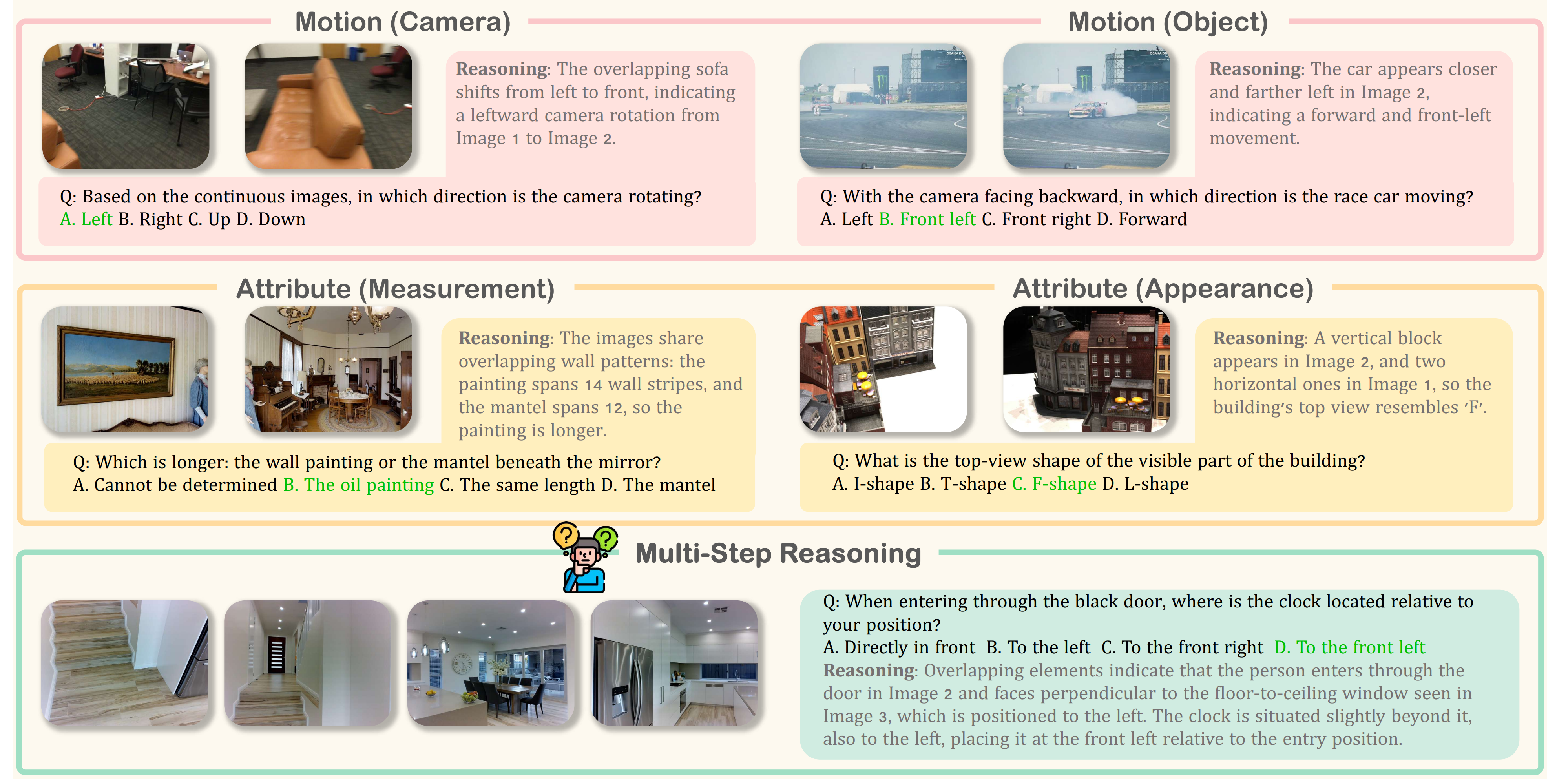
🔬 5、关键实验发现
5.1 模型-人类性能鸿沟
| 模型类型 | 代表模型 | 准确率 | 与随机差距 | 与人类差距 |
|---|---|---|---|---|
| 人类专家 | 6名3D视觉研究者 | 97% | — | — |
| 顶级闭源 | OpenAI o3 / GPT-5 | ~40% | +15% | -57% |
| 最强开源 | InternVL3-78B / Qwen2.5-VL-72B | ~30% | +5% | -67% |
| 多数开源模型 | 如 LLaVA、MiniGPT-4 等 | ~25% | ≈0% | -72% |
实验结果显示,即使是目前最强的推理模型 o3,其准确率也仅为人类的 40%,而大多数开源模型表现接近随机猜测水平。这可能是目前模型-人类差距最大的基准评测之一[83][99]。
5.2 具身智能相关性验证
MMSI-Bench 与具身智能(Embodied AI)下游任务高度相关:
| 下游任务 | 皮尔逊相关系数 | 斯皮尔曼相关系数 | 任务描述 |
|---|---|---|---|
| EB-Navigation | 0.8147 | 0.7333 | 仿真环境中的导航能力 |
| EB-Manipulation | 0.7402 | 0.7500 | 以物体为中心的操控技能 |
| EB-Habitat | 0.7299 | 0.6167 | 高级主动感知与规划 |
高相关性表明,MMSI-Bench 测量的多图像空间理解能力,与真实机器人导航、操作等具身任务所需的核心能力高度一致[87]。
5.3 四种主导错误模式
基于人工标注的逐步推理过程,研究团队构建了自动化错误分析管道,诊断出当前 MLLMs 的四种主导失败模式:
| 错误类型 | 描述 | 典型表现 |
|---|---|---|
| 1. Grounding Errors | 视觉基础错误 | 无法正确识别图像中的物体或区域,“看错了” |
| 2. Overlap-Matching & Scene-Reconstruction Errors | 重叠匹配与场景重建错误 | 难以匹配不同视角下的同一物体,无法重建场景整体几何 |
| 3. Situation-Transformation Reasoning Errors | 情境转换推理错误 | 无法推理场景随时间或视角变化的状态转换 |
| 4. Spatial-Logic Errors | 空间逻辑错误 | 掌握空间关系但逻辑推理错误,如方位判断错误 |
这四种错误模式为改进 MLLMs 的空间智能提供了具体的技术方向[82][90]。
🎯 6、MMSI-Bench 的独特价值
与现有空间推理基准相比,MMSI-Bench 具有以下创新特征:
| 特征 | MMSI-Bench 设计 | 现有基准局限 |
|---|---|---|
| 图像数量 | 强制多图像(平均2.55张/题) | 单图像为主,无法评估跨视图推理 |
| 数据构建 | 全人工精心打磨(300+小时专家工作) | 自动模板生成或伪标注,质量参差不齐 |
| 推理过程 | 提供详细逐步推理标注 | 仅有答案,缺乏可解释性 |
| 错误分析 | 自动化错误诊断管道 | 缺乏系统性错误归因工具 |
| 任务难度 | 非平凡问题(需多图+推理,非常识可解) | 常见问题可通过单图或语言常识解决 |
| 场景真实性 | 纯真实世界数据(8个真实数据集) | 合成数据或简化场景 |
六、MindCube:空间心智模型——让 AI 像人类一样"脑补"不可见空间
> 项目概览:李飞飞(Fei-Fei Li)、谢赛宁(Saining Xie)等来自斯坦福、西北大学、清华、上海 AI Lab 的研究团队提出的空间心智模型基准测试,探索视觉语言模型(VLMs)如何从有限视角构建对三维空间的内部表征。
🔗 1、核心资源
| 资源类型 | 链接 | 说明 |
|---|---|---|
| 论文 PDF | arXiv:2506.21458 | 《Spatial Mental Modeling from Limited Views》 |
| 代码仓库 | GitHub | 项目代码、评估脚本、训练框架与数据集工具 |
| 模型权重 | Hugging Face | MindCube 专用模型与认知地图生成权重 |
| 项目主页 | Website | 可视化演示、数据集样本与补充材料 |
🧠 2、研究背景
人类仅需扫视房间的几个角落,就能在脑海中构建出完整的室内布局,甚至能推断出家具背后或墙壁后方隐藏的物品。这种能力被称为空间心智模型(Spatial Mental Model)——一种对不可见空间的内部表征能力。
该研究旨在回答一个核心问题:当视觉语言模型(VLMs)只能看到房间的局部视角时,它们能否像人类一样构建出完整的空间认知地图,并据此回答关于不可见区域的问题?
📊 3、MindCube 基准测试
研究团队构建了 MindCube 基准测试,专门用于评估 VLMs 在有限视角下的空间心理建模能力:
数据集统计
| 属性 | 数值 | 说明 |
|---|---|---|
| 图像数量 | 3,268 | 多视角室内场景图像 |
| 问答对数量 | 21,154 | 空间推理问题 |
| 视角类型 | 3 类 | 旋转(Rotation)、环绕(Around)、穿行(Among) |
| 评估维度 | 3 维度 | 位置表征、方向感知、动态推理 |
| 不可见区域 | 遮挡/视野外 | 墙壁后方、家具背后等隐藏物体 |
如下图所示,展示了三种视角类型:旋转、环绕、穿行,以及对应的认知地图构建过程。
任务示例 ,如下图所示:
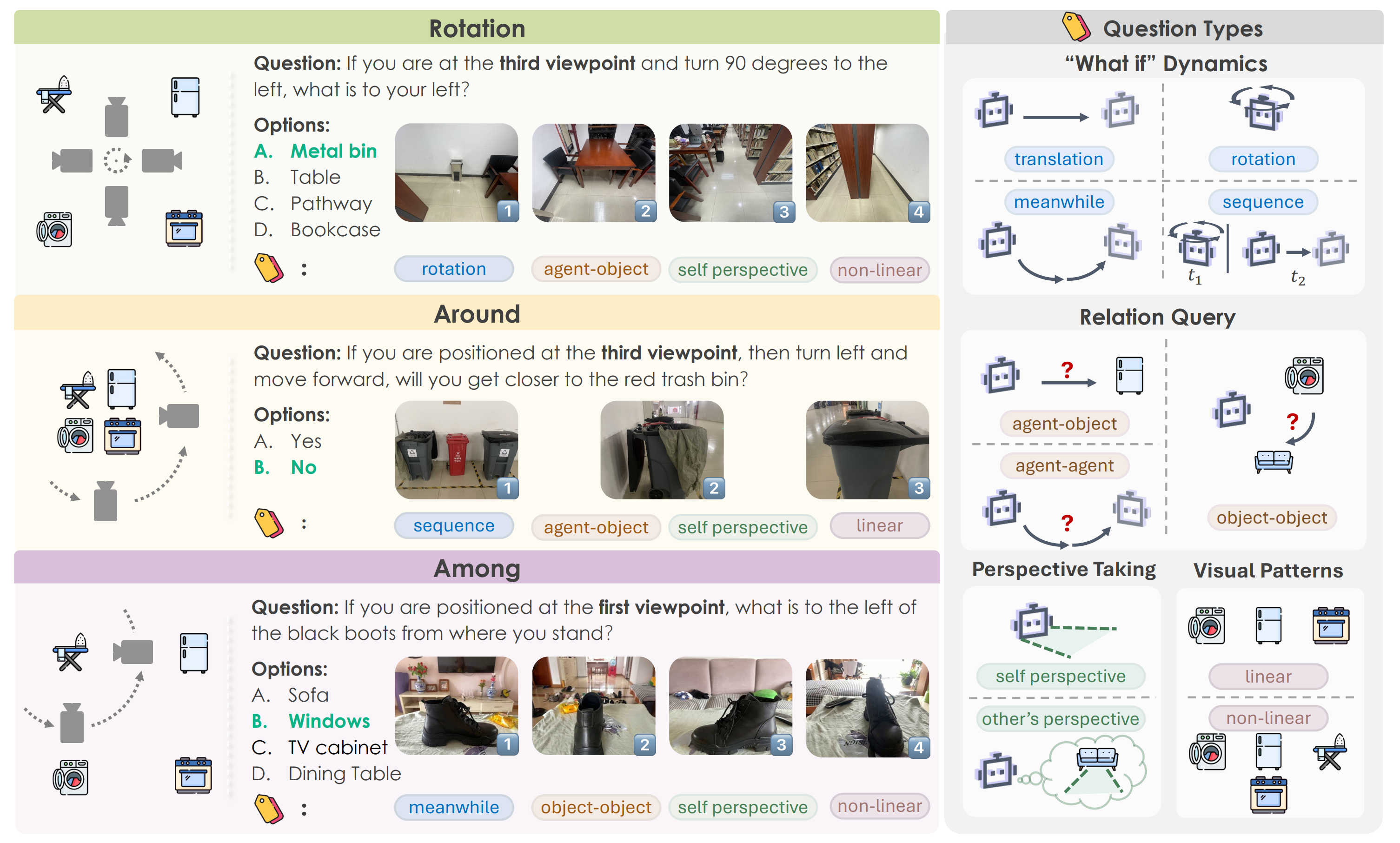
💡 4、任务类型详细分类
MindCube 评估模型在三种核心空间认知能力上的表现:
| 能力维度 | 子任务 | 描述 | 示例子问题 |
|---|---|---|---|
| 位置表征 | 认知地图构建 | 从有限视角推断物体位置 | “红色盒子在蓝色盒子的左侧还是右侧?” |
| 方向感知 | 视角获取 | 理解相机观察方向 | “从当前视角看,书架在门的哪一边?” |
| 动态推理 | 运动模拟 | 假设性运动与轨迹推断 | “如果我从A点走到B点,会经过哪些物体?” |
🎯 5、“先建图后推理”:认知支架策略
面对 VLMs 在空间推理上的短板,研究团队探索了三种**认知支架(Cognitive Scaffolds)**策略:
- 视角插值:补充中间视角以增强视觉信息
- 语言链式推理(CoT):引入自然语言推理链条
- 认知地图生成:构建结构化的空间表征
关键发现
实验结果表明:仅仅增加视觉信息或将认知地图作为被动输入效果不佳,而主动构建和利用内部表征才是关键。
Map-then-Reason 框架
研究团队提出了**“先建图后推理”(map-then-reason)**的协同训练范式:
- 生成阶段:模型首先基于有限视角生成认知地图
- 推理阶段:模型基于自己生成的地图进行空间推理回答
性能提升
| 训练阶段 | 准确率 | 提升幅度 | 关键特征 |
|---|---|---|---|
| 基线(Raw-QA) | 37.8% | - | 直接回答,无中间步骤 |
| 监督微调(SFT) | 60.8% | +23.0% | 生成认知地图后回答 |
| 强化学习(RL) | 70.7% | +32.9% | 优化地图质量,增强推理一致性 |
🔬 6、技术细节
认知地图表示
认知地图采用结构化 JSON 格式表示,包含:
- 物体列表:检测到的所有物体及其属性
- 位置坐标:相对相机或全局坐标系的位置
- 空间关系:物体间的相对位置关系(左右、前后、距离)
训练策略对比
| 训练方法 | 效果 | 局限性 |
|---|---|---|
| 监督微调 | 地图质量改善明显 | 可能存在幻觉(hallucination) |
| 自我批评强化学习 | 进一步提升性能 | 仍无法完全消除物体幻觉 |
| 推理时扩展 | 增加地图采样数量 | 边际效益递减 |
🌟 7、研究意义与展望
MindCube 项目的核心贡献在于证明了空间心智模型是可以被教会的。通过适当的训练目标和数据,VLM 能够学会系统性地生成和利用高质量的内部空间表征。
这项工作:
- 填补空白:解决了 AI 在三维空间理解上的关键短板
- 通向具身智能:为机器人在复杂环境中的导航与操作奠定基础
- AGI 路径:被视为通向通用人工智能的重要一步——让 AI 不仅"看见"空间,而是真正"理解"其全局结构
七、BLINK:多模态大模型"看得见"却"看不懂"的视觉感知盲区
> 项目概览:宾夕法尼亚大学、华盛顿大学、艾伦人工智能研究所(AI2)等机构联合研究团队提出的视觉感知基准测试,揭示当前多模态大语言模型(MLLMs)虽能"看见"图像,却难以真正"感知"视觉细节的核心瓶颈。
🔗 1、核心资源
| 资源类型 | 链接 | 说明 |
|---|---|---|
| 论文 PDF | arXiv:2404.12390 | 《BLINK: Multimodal Large Language Models Can See but Not Perceive》 |
| 代码仓库 | GitHub | 评估脚本、可视化工具与实验代码(ECCV 2024) |
| 数据集 | Hugging Face | BLINK 数据集(3,807 问答对,14 个子任务) |
| 项目主页 | Website | 样例展示、Leaderboard 与补充材料 |
🧠 2、研究背景
当前多模态大语言模型(MLLMs)在视觉-语言任务中展现出强大能力,许多人认为它们具备类人般的视觉理解。然而,现有基准测试(如 MMBench、MMMU)往往将视觉感知与语言知识和推理混为一谈。
该研究旨在回答一个核心问题:MLLMs 真的能"看"吗?还是仅仅依赖语言推理来"猜"答案?
研究团队通过"密集描述"实验揭示:将图像转换为详细文本描述后,纯文本 GPT-4 在 MMBench 等传统基准上表现良好,但在 BLINK 任务上却完全失败(接近随机水平)。这表明现有基准很大程度上可通过语言推理解决,而非真正的视觉感知。
📊 3、BLINK 基准测试
研究团队构建了 BLINK(Benchmark for Language models’ INtuitive visual acuity),这是一个专注于核心视觉感知能力的评估基准:
数据集统计
| 属性 | 数值 | 说明 |
|---|---|---|
| 总样本数 | 3,807 | 多项选择题(单图/多图/视觉提示) |
| 任务数量 | 14 类 | 经典计算机视觉任务重组 |
| 人类准确率 | 95.70% | 平均表现("眨眼间"可解决) |
| GPT-4V 准确率 | 51.26% | 仅比随机猜测高 13.17% |
| Gemini 准确率 | 45.72% | 仅比随机猜测高 7.63% |
| 评估方式 | 零样本(Zero-shot) | 无需特定任务微调 |
如下图所示,展示了 BLINK 的 14 个视觉感知任务,涵盖从像素级到图像级、从低级模式匹配到高级语义理解的多维度挑战。
任务示例1 ,如下图所示:
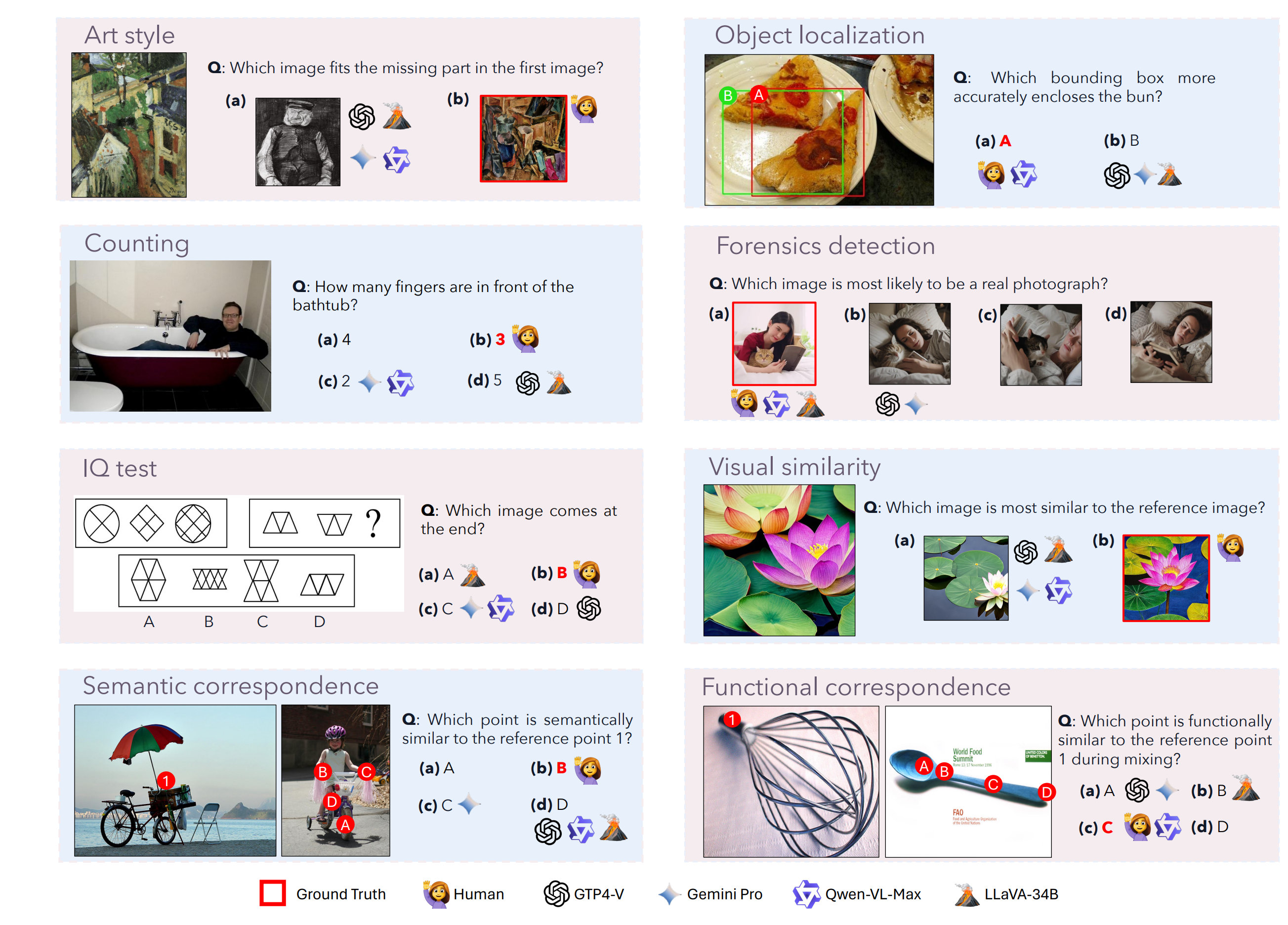
任务示例2 ,如下图所示: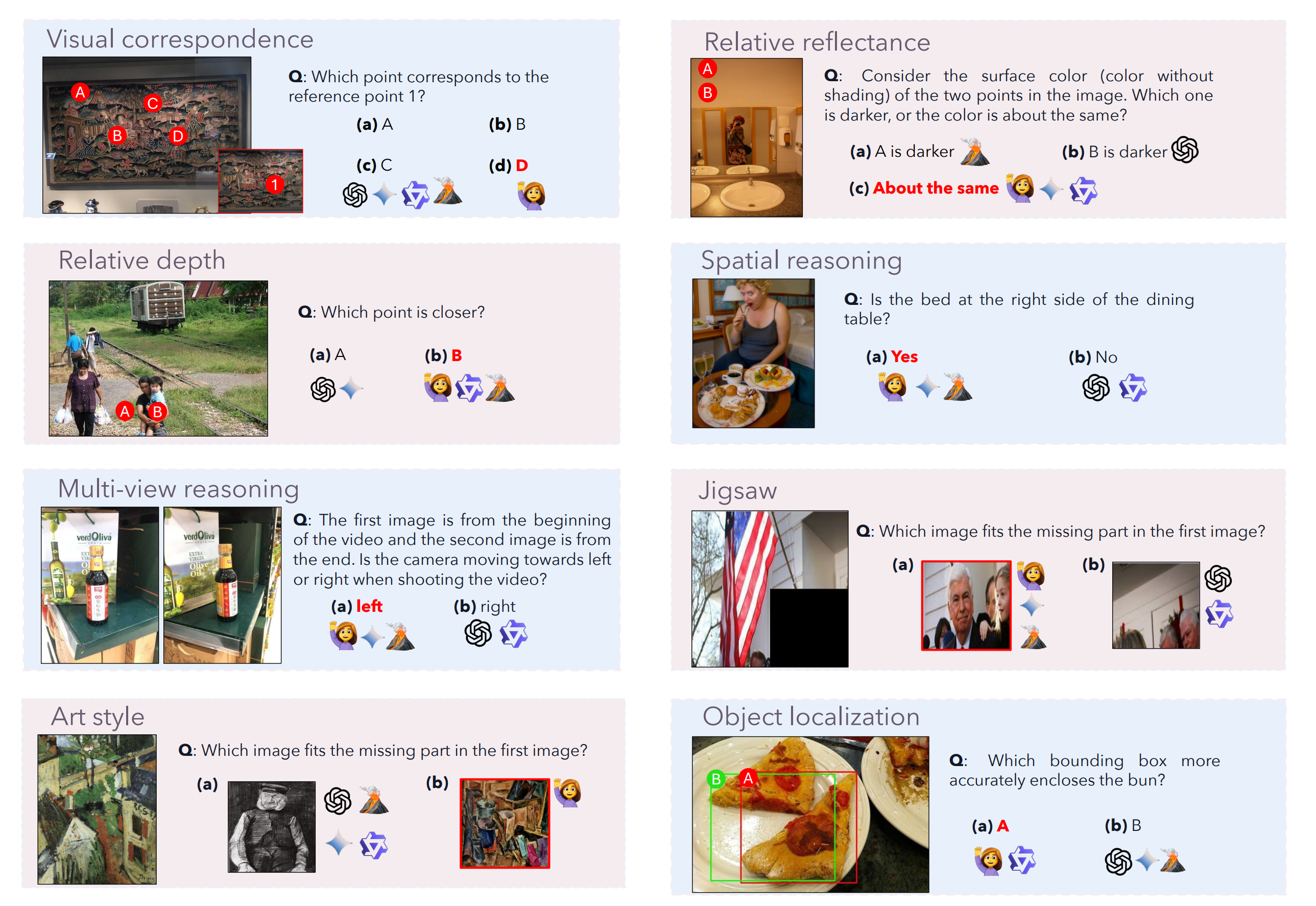
💡 4、任务类型详细分类
BLINK 将 14 个经典计算机视觉任务重组为多项选择题,评估模型在纯视觉感知(无需领域知识)上的能力:
| 任务类别 | 子任务 | 描述 | 示例子问题 |
|---|---|---|---|
| 深度与几何 | Relative Depth | 相对深度估计 | “物体 A 和 B,哪个离相机更近?” |
| Spatial Relation | 空间关系判断 | “红色圆圈是在蓝色方块左侧吗?” | |
| Multi-view Reasoning | 多视角推理 | “从右侧看,物体会出现在左边还是右边?” | |
| 视觉对应 | Visual Correspondence | 像素级视觉匹配 | “在两图中圈出同一物体位置” |
| Semantic Correspondence | 语义级对应 | “两图中功能相似的部件在哪里?” | |
| Functional Correspondence | 功能对应 | “哪个物体与参考物功能相同?” | |
| 物体属性 | Relative Reflectance | 相对反射率 | “两个表面,哪个更亮/反光更强?” |
| Visual Similarity | 视觉相似度 | “哪两个物体外观最相似?” | |
| Art Style | 艺术风格识别 | “这幅画属于什么风格?” | |
| 结构理解 | Jigsaw | 拼图/碎片重组 | “哪块碎片能填补缺口?” |
| Object Localization | 物体定位 | “圈出图中所有圆形物体” | |
| Counting | 物体计数 | “图中有几个红色方块?” | |
| 高级感知 | Forensic Detection | 图像取证检测 | “哪张图是 AI 生成的/被篡改的?” |
| IQ Test | 视觉 IQ 测试 | “按规律选择下一个图形” |
🔬 5、关键实验发现
5.1 人类 vs 模型性能差距
| 模型 | 准确率 | 与随机差距 | 表现分析 |
|---|---|---|---|
| 人类 | 95.70% | — | 几乎完美的视觉直觉 |
| GPT-4V | 51.26% | +13.17% | 勉强超越随机 |
| Gemini Pro | 45.72% | +7.63% | 接近随机水平 |
| ** specialist CV 模型** | >80% | — | 专家模型表现远超通用 MLLMs |
5.2 语言推理无法替代视觉感知
研究团队进行关键消融实验:将图像替换为密集文本描述(Dense Caption):
- 传统基准(MMBench/MMMU):纯文本 GPT-4 表现良好,说明语言推理足以解决
- BLINK 任务:纯文本模型完全失败,准确率接近随机水平
这证明 BLINK 任务抵制通过自然语言进行中介,必须依赖真正的视觉理解能力[24][30]。
5.3 专家模型 vs 通用模型
分析显示,专门的计算机视觉(CV)模型在 BLINK 任务上表现远优于通用 MLLMs:
- 专家模型在深度估计、视觉对应等任务上可达 80%+ 准确率
- 这提示了未来改进路径:结合专用视觉编码器或模块可能是提升 MLLMs 视觉感知能力的关键方向[24]
🎯 6、BLINK 的独特设计
与现有基准相比,BLINK 具有以下创新特征:
| 特征 | BLINK 设计 | 传统基准局限 |
|---|---|---|
| 视觉提示 | 支持圆圈、方框、图像掩码等多样化视觉标注 | 仅文本问答 |
| 感知范围 | 涵盖深度估计、反射率、多视角推理等低/中级感知 | 偏重识别级 VQA |
| 知识依赖 | "视觉常识"问题,无需领域知识,人类秒级解决 | 如 MMMU 需大学专业知识 |
| 任务来源 | 14 个经典 CV 任务重组(对应、拼图、取证等) | 多为自然场景问答 |
分享完成~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)