基于粒子群优化随机森林的回归预测系统功能说明
·
粒子群算法PSO优化随机森林RFR的回归预测MATLAB代码 代码注释清楚,可以读取EXCEL数据,使用换自己数据集。 很方便,初学者容易上手。
一、系统概述
本系统是一套基于MATLAB开发的回归预测解决方案,创新性地融合了粒子群优化(PSO)算法与随机森林(RF)模型,通过PSO算法对随机森林的关键参数进行智能寻优,显著提升了传统随机森林模型在回归预测任务中的精度与稳定性。系统支持Excel表格与MAT文件两种数据输入格式,内置数据预处理、参数优化、模型训练、预测评估全流程功能模块,具备良好的易用性与扩展性,特别适合初学者快速上手,同时也可满足专业用户的定制化预测需求。
二、核心功能模块
(一)数据处理模块
- 数据导入功能
- 支持两种主流数据格式导入:一是通过xlsread函数读取Excel文件(如示例中的Folds5x2_pp.xlsx),可指定工作表(Sheet1)与数据范围(A2:E500);二是通过load函数加载MAT格式数据文件,满足不同数据存储场景的需求。
- 数据导入过程中自动处理表格结构,无需用户手动调整数据维度,降低操作门槛。 - 数据集划分功能
- 采用随机打乱(randperm)与顺序截取相结合的方式划分训练集与测试集,示例中默认将数据按4:1比例划分为400个样本的训练集与100个样本的测试集,用户可根据数据规模灵活调整划分比例。
- 划分过程中保持输入特征(前4列)与目标变量(第5列)的对应关系,确保数据完整性与一致性。 - 数据归一化功能
- 基于mapminmax函数实现数据标准化处理,将输入特征与目标变量分别映射到[0,1]区间,消除不同特征量纲差异对模型训练的影响。
- 保存归一化参数(psinput、psoutput),用于测试集数据的统一标准化处理与预测结果的反归一化还原,保证数据处理的连贯性。
(二)粒子群优化(PSO)模块
- 参数初始化功能
- 可配置PSO核心参数,包括学习因子(c1、c2,默认均为2)、最大迭代次数(maxgen,默认50)、种群规模(sizepop,默认30)、速度边界(Vmax=2、Vmin=-1)与粒子位置边界(popmax=[100,20]、popmin=[10,2])。
- 初始化种群位置与速度,通过fun函数计算初始种群的适应度(以均方根误差RMSE为评价指标),为后续迭代寻优奠定基础。 - 迭代寻优功能
- 速度更新:根据个体最优位置(gbest)与全局最优位置(zbest),结合学习因子与随机因子动态调整粒子速度,同时通过速度边界限制避免速度异常波动。
- 位置更新:基于调整后的速度更新粒子位置,通过位置边界限制确保粒子位置始终在合理参数范围内(如随机森林的决策树数量、节点特征数)。
- 自适应变异:设置1.95的变异概率阈值,对满足条件的粒子进行随机变异,增加种群多样性,避免算法陷入局部最优。
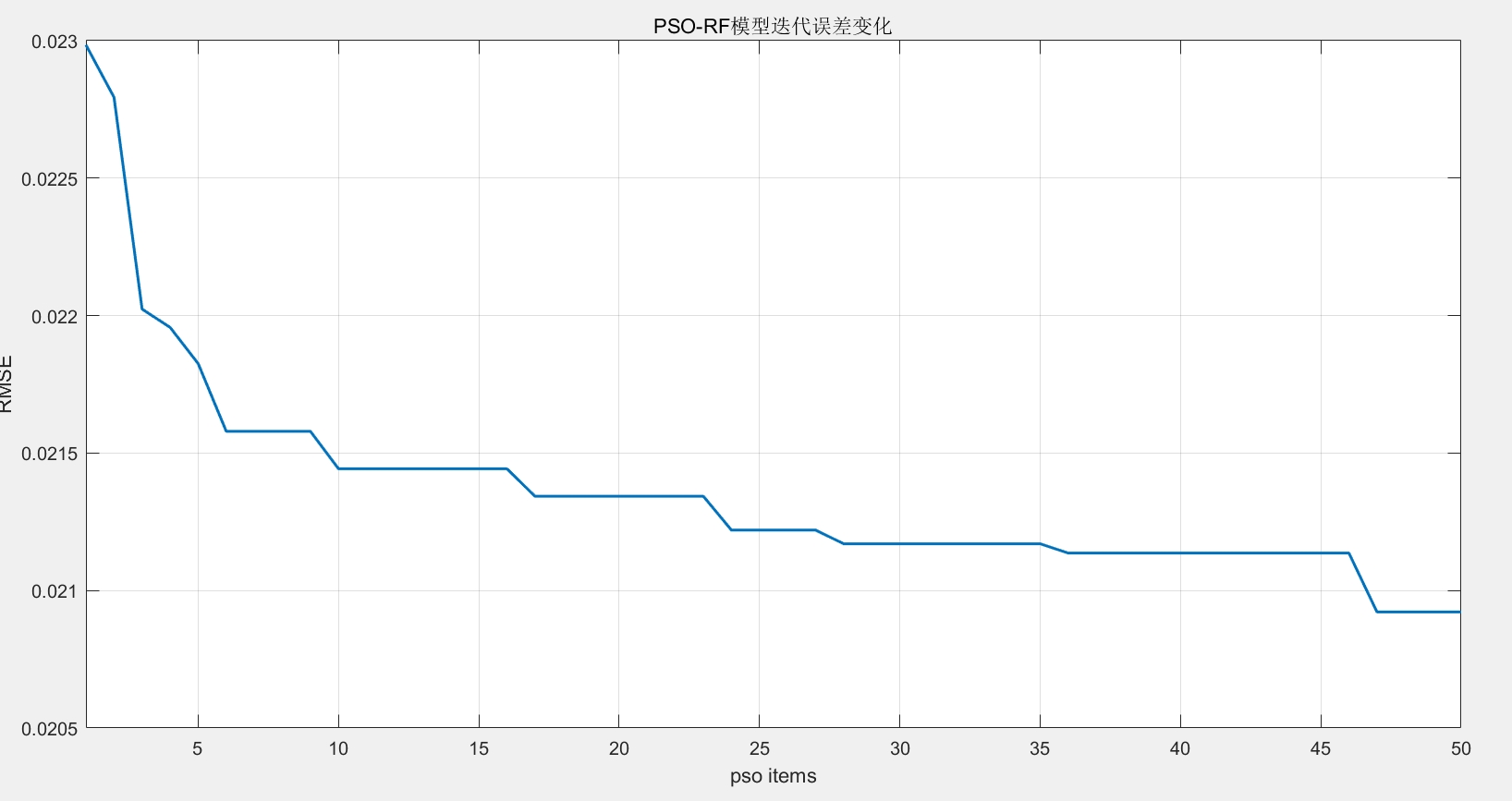
- 最优更新:每次迭代后更新个体最优与全局最优位置及对应的适应度值,记录每次迭代的全局最优适应度(BestFit),生成迭代误差变化曲线。 - 优化结果输出功能
- 迭代结束后输出全局最优粒子位置,该位置对应随机森林的最优超参数组合(决策树数量ntrees、节点特征数nlayers)。
- 生成PSO优化迭代图,直观展示迭代过程中RMSE的变化趋势,帮助用户分析算法收敛性与寻优效率。
(三)随机森林回归模型模块
- 模型训练功能
- 基于regRF_train函数构建随机森林回归模型,该函数支持配置决策树数量(ntree)、节点特征数(mtry)、终端节点最小样本数(nodesize,默认5)、采样方式(replace,默认有放回采样)等核心参数。
- 训练过程中自动处理数据中的缺失值与异常值,支持分类特征与连续特征的混合输入(最大支持32个分类水平),同时可配置变量重要性评估、邻近度计算等扩展功能。
- 输出训练完成的模型对象(model),包含决策树结构(lDau、rDau)、节点状态(nodestatus)、模型性能指标(mse、rsq)等关键信息。 - 预测功能
- 基于regRFpredict函数实现测试集预测,输入测试集数据与训练好的模型对象,通过调用底层mexRFpredict函数快速生成预测结果(t_sim2)。
- 支持预测结果的反归一化处理(mapminmax('reverse')),将标准化后的预测结果还原为原始数据尺度,确保预测结果的实际意义。
(四)模型评估与可视化模块
- 误差分析功能
- 计算多种回归预测误差指标,包括误差平方和(SSE)、平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)、平均百分比误差(MAPE),全面评估模型预测精度。
- 计算预测值与真实值的相关系数(R),反映两者的线性相关程度,进一步验证模型的可靠性。
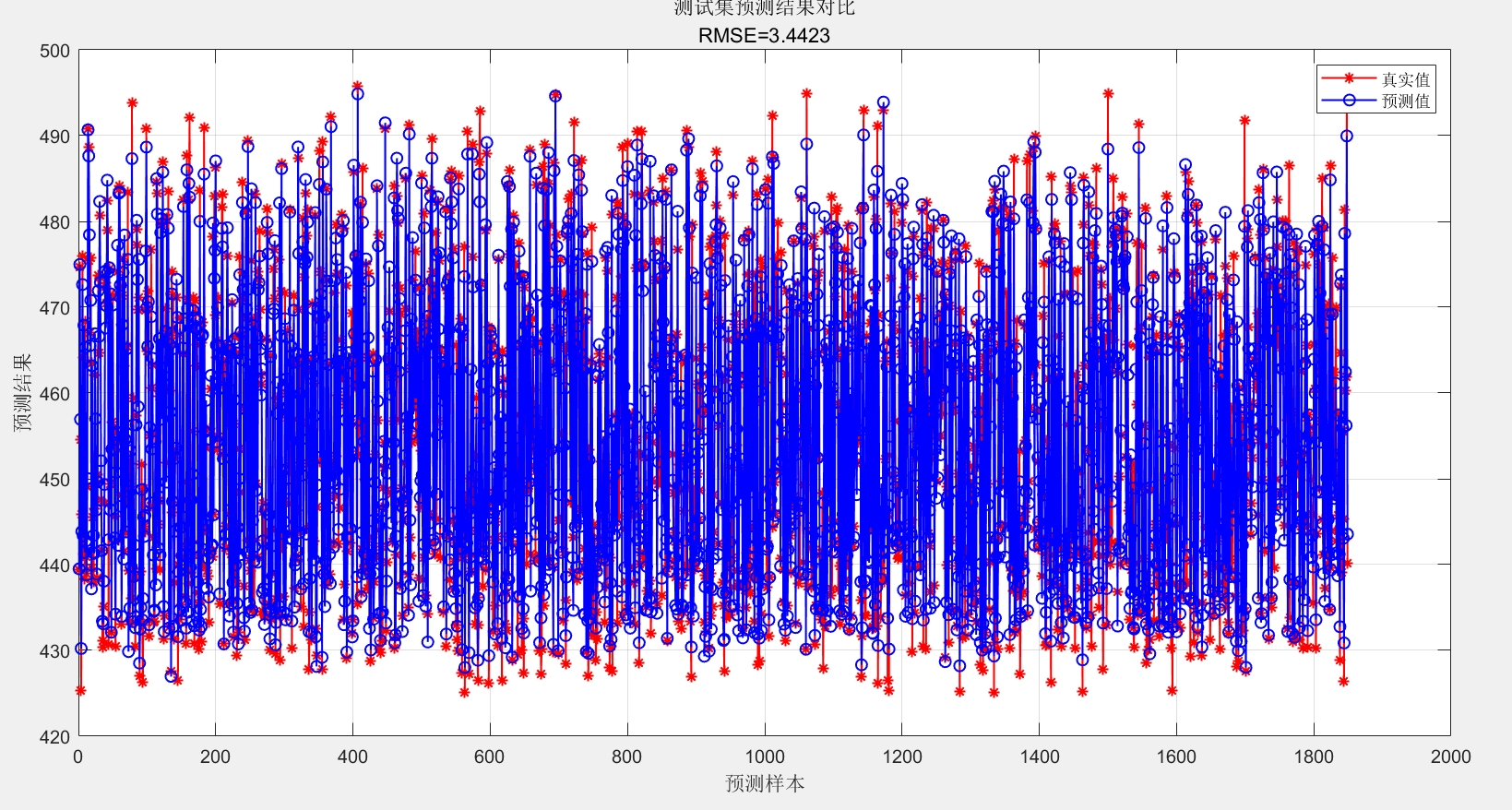
- 输出标准化的误差分析报告,包含各误差指标的具体数值与模型预测准确率((1-MAPE)*100%),便于用户快速判断模型性能。 - 可视化功能
- 生成测试集预测结果对比图,以红色星线表示真实值,蓝色圆点线表示预测值,直观展示两者的拟合程度,同时在图标题中标注RMSE值,增强结果可读性。
- 所有图表均支持网格显示(grid on)、坐标轴标签与标题自定义,用户可根据需求调整图表样式,便于结果展示与报告生成。
三、系统工作流程
- 环境准备:通过
clear all与clc清空MATLAB工作空间变量与命令行窗口,避免历史数据干扰。 - 数据处理:导入原始数据→划分训练集与测试集→数据归一化处理,完成模型输入数据准备。
- 参数优化:初始化PSO参数与种群→迭代更新粒子速度与位置→确定随机森林最优超参数,完成模型参数寻优。
- 模型训练:基于最优超参数构建随机森林回归模型→训练模型并保存模型对象,完成模型构建。
- 预测评估:使用训练好的模型对测试集进行预测→反归一化处理预测结果→计算误差指标并生成可视化图表,完成模型性能评估。
四、系统特点与优势
- 高精度预测:通过PSO算法优化随机森林超参数,有效解决传统随机森林参数凭经验设置导致的性能不稳定问题,显著提升回归预测精度。
- 易用性强:支持多种数据格式导入,代码注释清晰,用户仅需修改数据路径与少量参数即可适配自身数据集,初学者可快速上手。
- 功能完备:涵盖数据预处理、参数优化、模型训练、预测评估全流程功能,无需额外集成第三方工具,降低系统使用复杂度。
- 扩展性好:PSO参数、随机森林参数均可灵活配置,支持用户根据具体任务需求调整算法参数,同时可扩展支持多分类、多输出回归等复杂任务。
- 可视化直观:内置迭代过程与预测结果可视化功能,帮助用户直观理解算法运行过程与模型性能,便于结果分析与报告撰写。
五、适用场景
本系统适用于能源负荷预测、环境污染物浓度预测、工业生产参数预测、金融时间序列预测等多种回归预测场景,尤其适合数据维度适中(特征数100以内、样本数1000以内)、对预测精度要求较高的应用场景,可作为科研人员、工程师进行回归预测任务的高效工具。

粒子群算法PSO优化随机森林RFR的回归预测MATLAB代码 代码注释清楚,可以读取EXCEL数据,使用换自己数据集。 很方便,初学者容易上手。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)