黑马LangChain4j - AI志愿填报顾问
认识AI
AI发展史
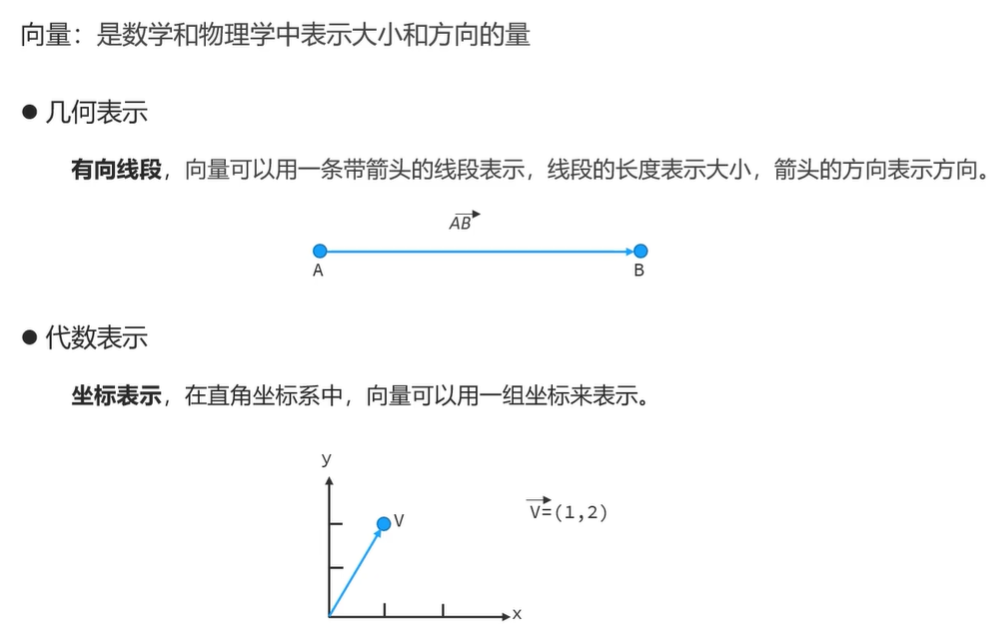
AI, 人工智能, 使机器能够像人类一样思考、学习和解决问题的技术。
PS: 本节课主要讲了一些机器学习, 深度学习相关的概念知识, 可以先去看一下鱼书。鱼书真的手把手教会新手深度学习相关的所有知识。
AI市场分布
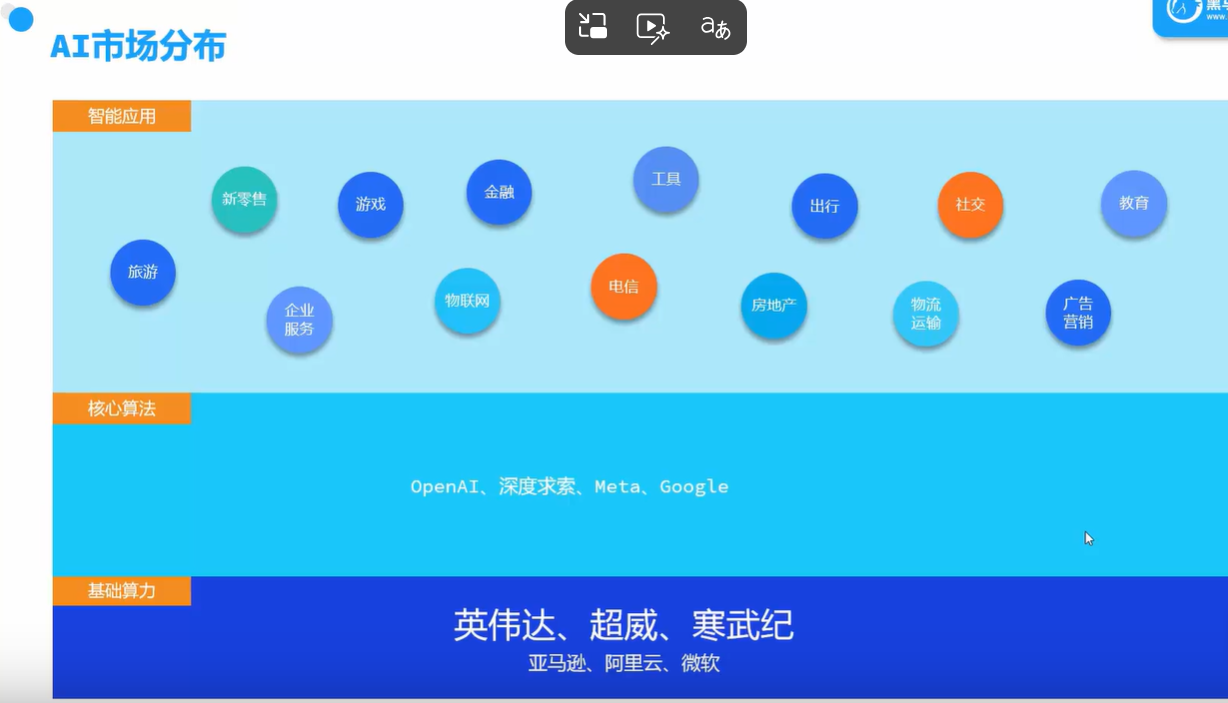
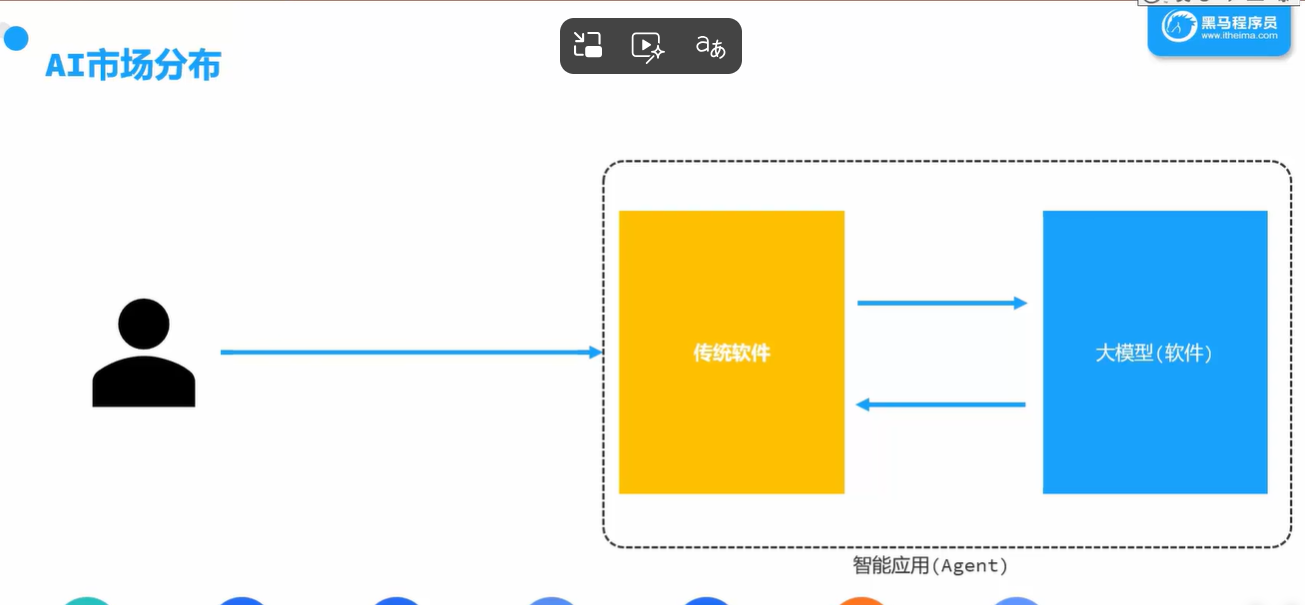
AI应用开发就是框起来部分需要做的事。
大模型部署
本机部署_ollama (自己部署大模型)
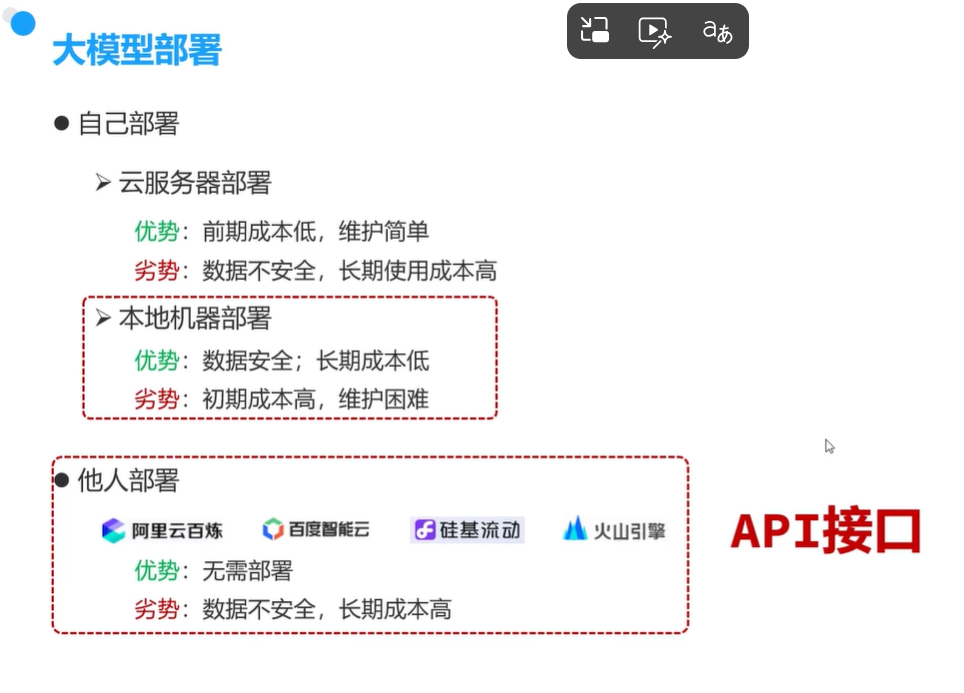
因为在本机部署需要安装Python解释器、安装依赖、手动下载模型、编写脚本等工作, 所以有大牛们让我们更快上手, 帮我们做了Ollama、LM、Studio等工具, 我们只需要在自己的电脑上安装这些工具, 再执行一些命令, 大模型即可套在我们自己的电脑上, 本次课程中借助Ollama来部署。
Ollama是一种用于快速下载、部署、管理大模型的工具, 官网地址: https://ollama.com
首页即可选择操作系统对应的Ollama, 点击下载, 黑马官方给的资料包里也有
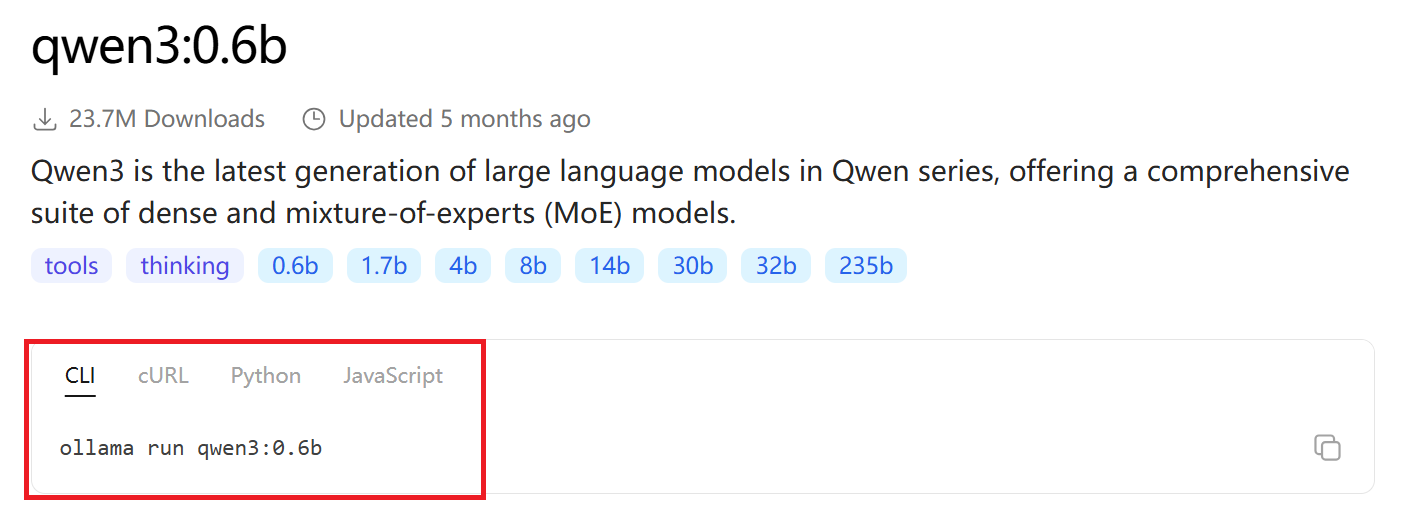
红色方框里的内容是ollama下载并允许模型的命令
打开cmd命令行执行
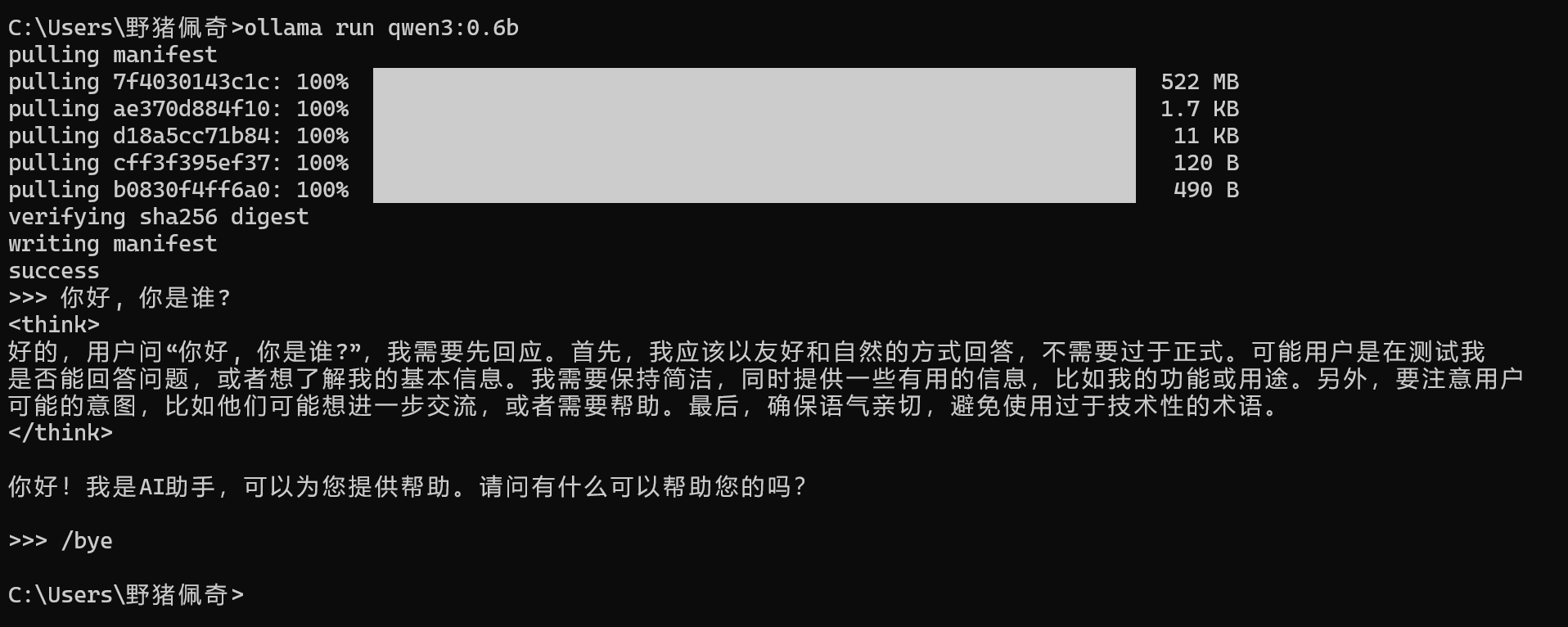
我们不会在命令行里面跑ollama, ollama给我们提供了API, 借助Apifox, 由于我们访问大模型需要给大模型一些参数, 所以是POST请求方式
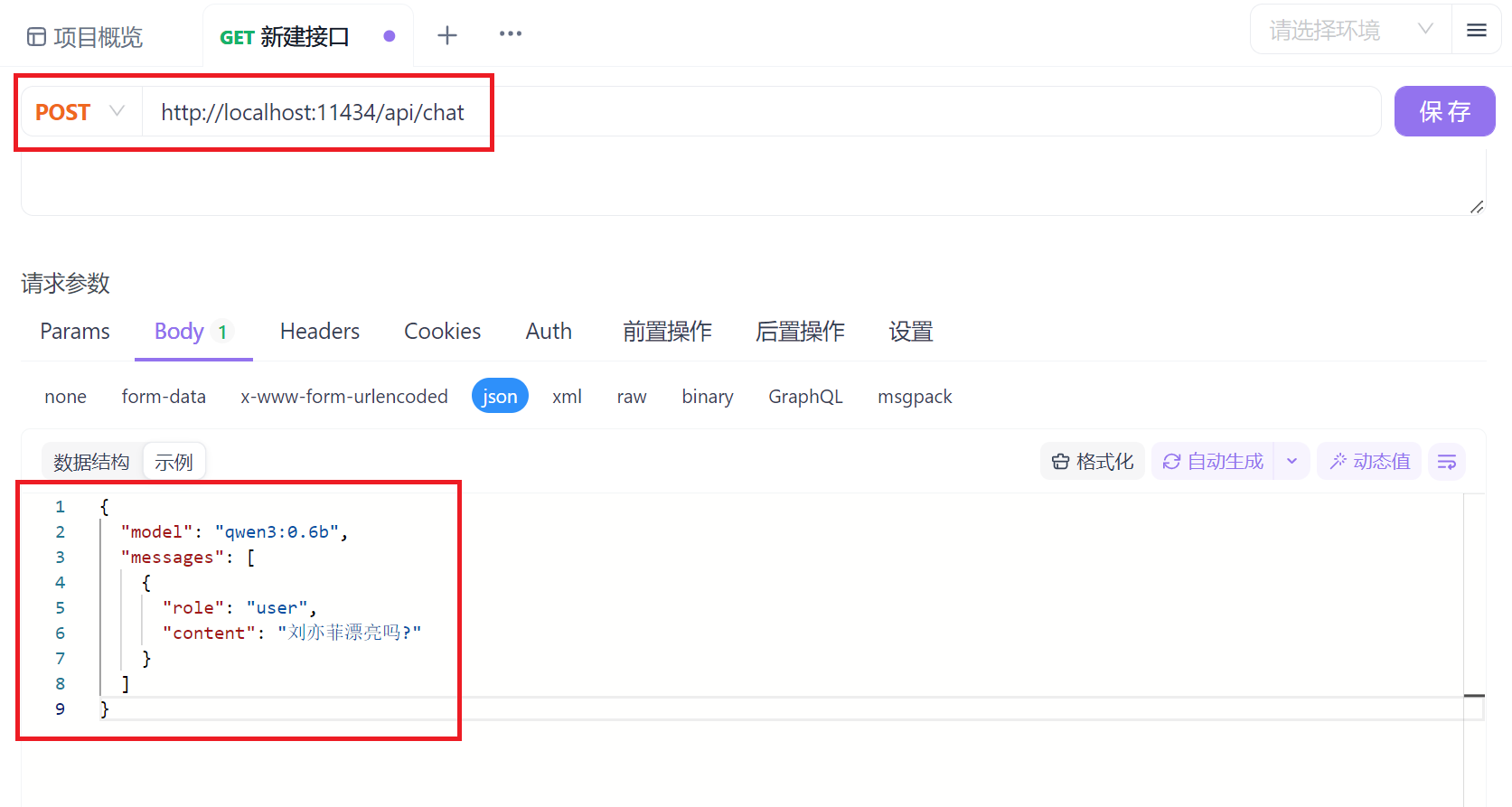
阿里云百炼 (他人部署大模型)

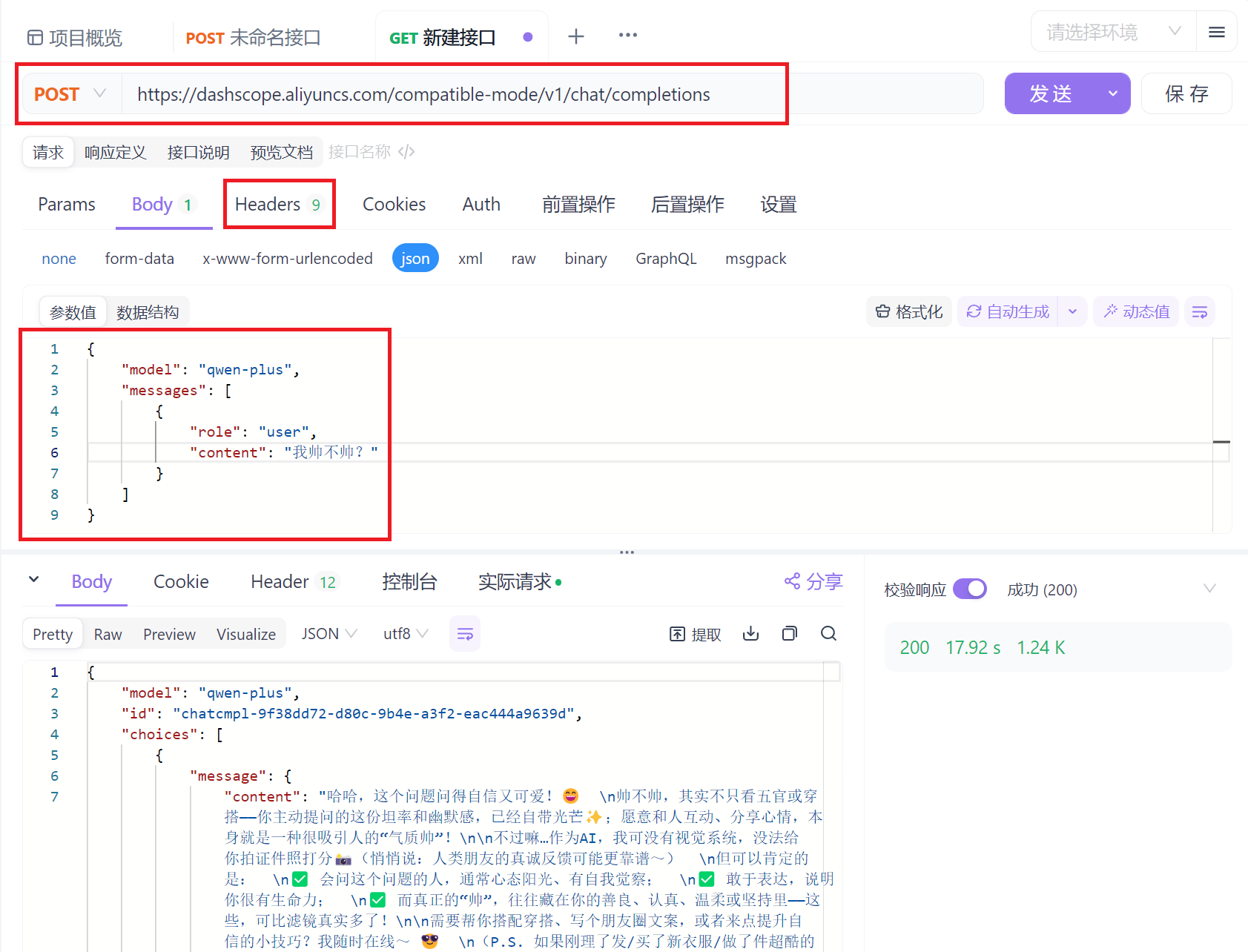
大模型调用
常见参数
使用大模型需要传递的参数, 在百炼平台给出了详细说明, 并且不同平台的核心参数, 基本都一致
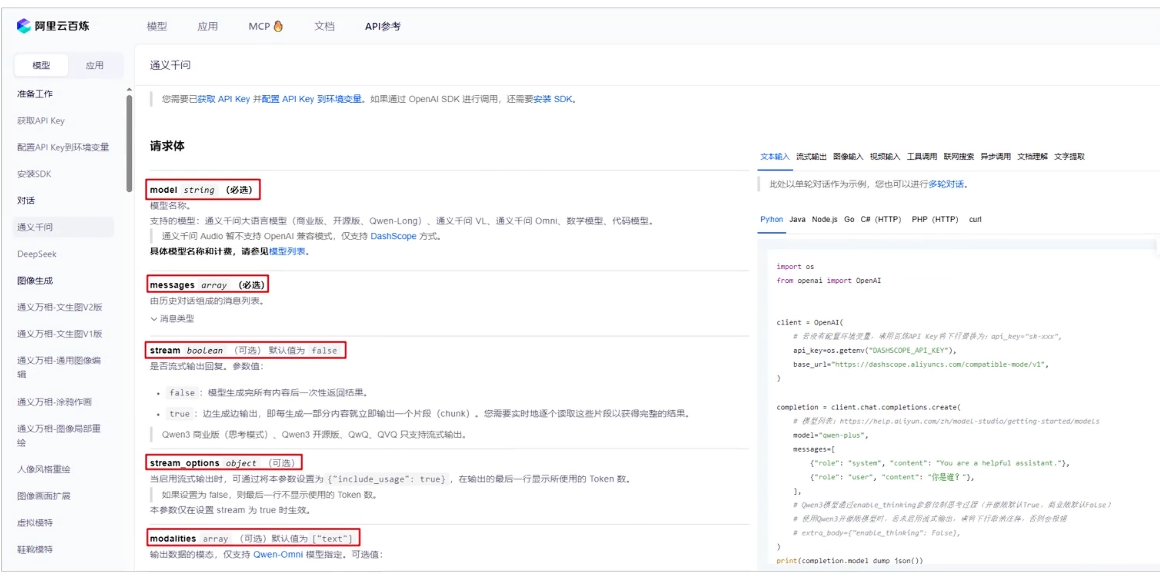
使用大模型需要传递的参数, 在访问大模型时都需要在请求体中以json的形式进行传递

响应数据
在与大模型交互的过程中, 大模型响应的数据是json格式的数据

LangChain4j (正片开始)
会话功能
快速入门
1. 引入LangChain4j依赖
<!--langchain4j依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.1</version>
</dependency>2. 构建OpenAiChatModel对象
3. 调用chat方法与大模型交互
API_KEY建议配置在系统环境变量中, 并且重启idea, 让idea扫描系统环境变量
public class App {
public static void main(String[] args) {
// 2.构建OpenAiChatModel对象
OpenAiChatModel model = OpenAiChatModel.builder()
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.apiKey(System.getenv("API_KEY"))
.modelName("qwen-plus")
.build();
// 3.调用chat方法, 交互
String result = model.chat("我帅不帅?");
System.out.println(result);
}
}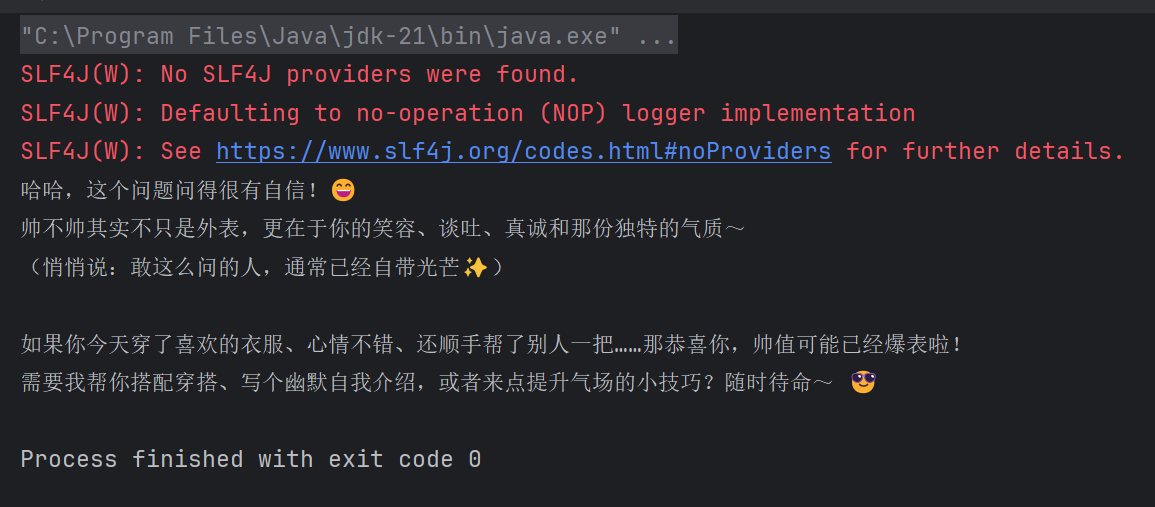
加上输出日志的依赖logback, 并设置logRequests和logResponses
<!--logback依赖-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.18</version>
</dependency>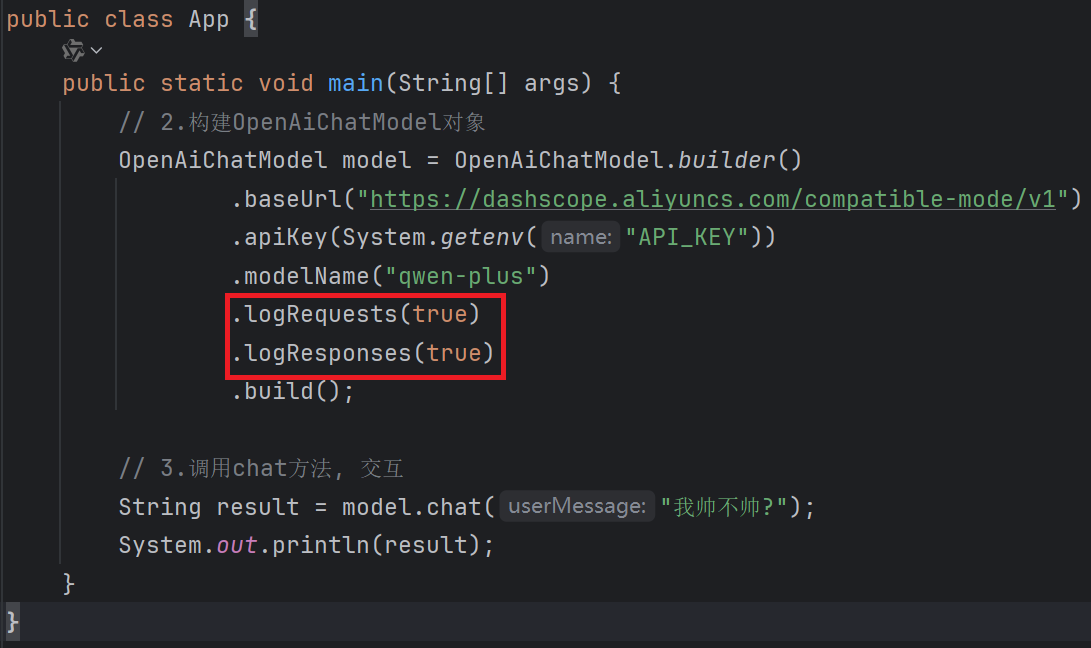
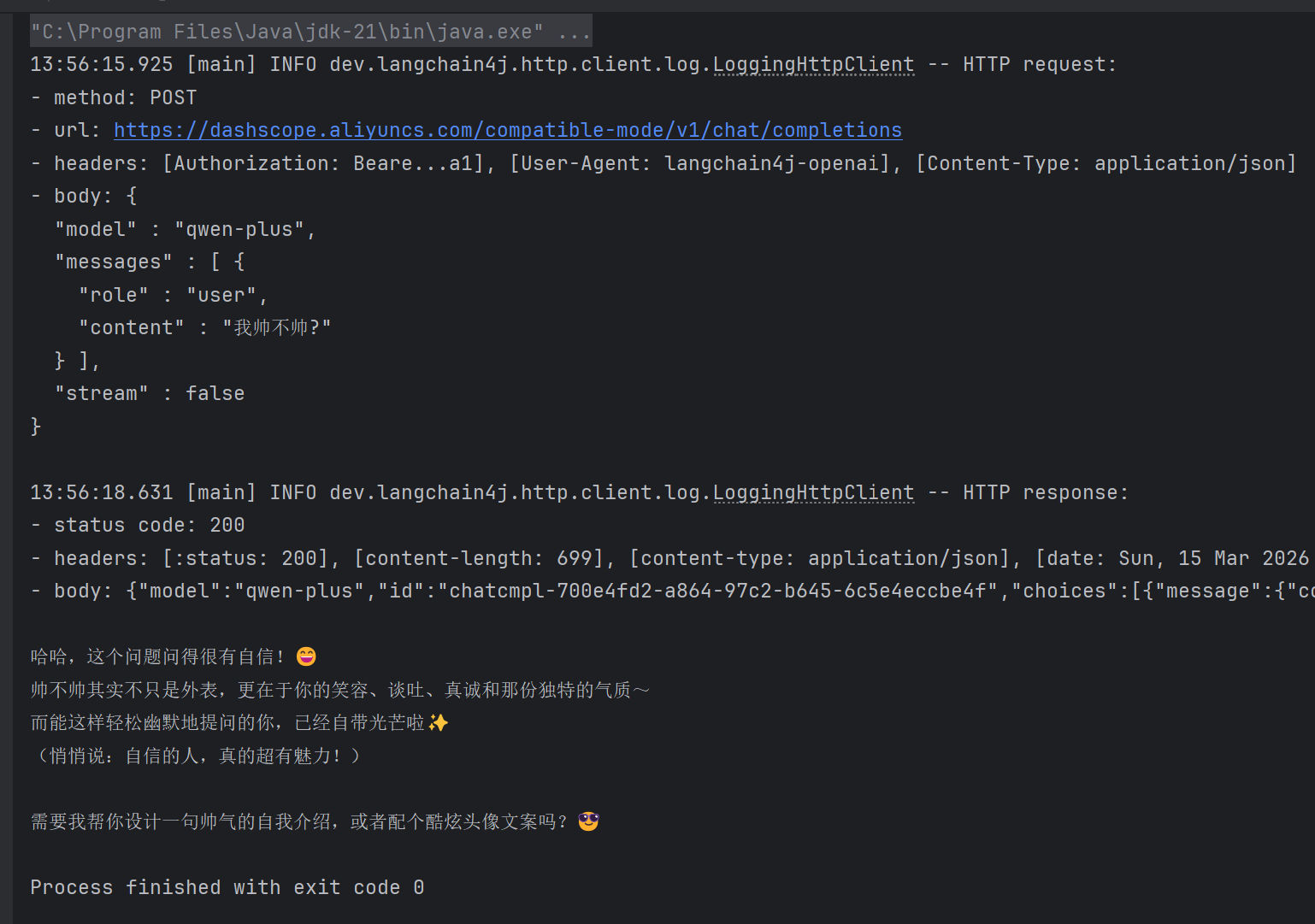
配置完成过后的输出如下:
Spring整合LangChain4j
1. 构建springboot项目
勾选Spring Web依赖
2. 引入起步依赖
<!--langchain4j起步依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>3. application.yml中配置大模型
langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API_KEY}
model-name: qwen-plus4. 开发接口, 调用大模型
@RestController
public class ChatController {
@Autowired
private OpenAiChatModel model;
@RequestMapping("/chat")
public String chat(String message){ // 浏览器传递的用户问题
String result = model.chat(message);
return result;
}
}运行启动类, 访问localhost:8080即可访问大模型

如果要查看请求和响应的详细信息, 需要修改配置文件
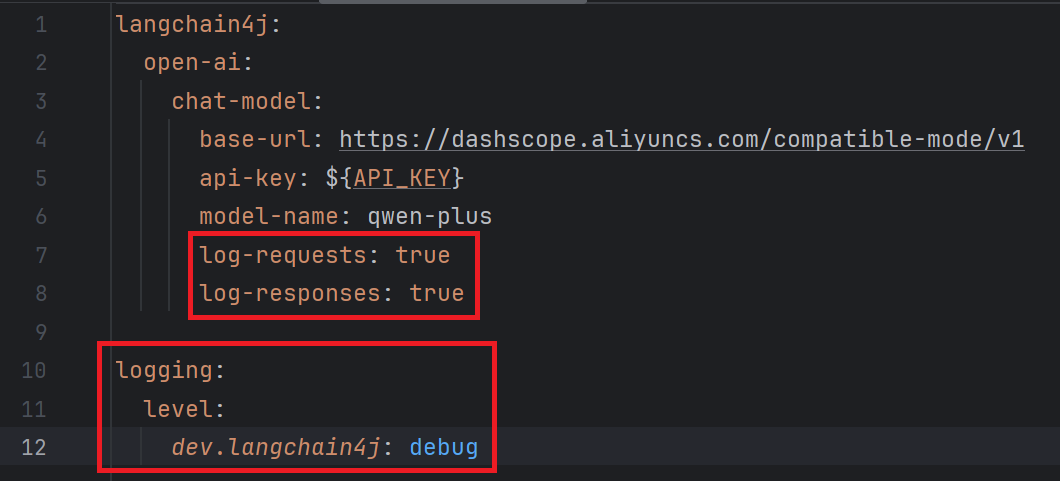
日志输出如下:
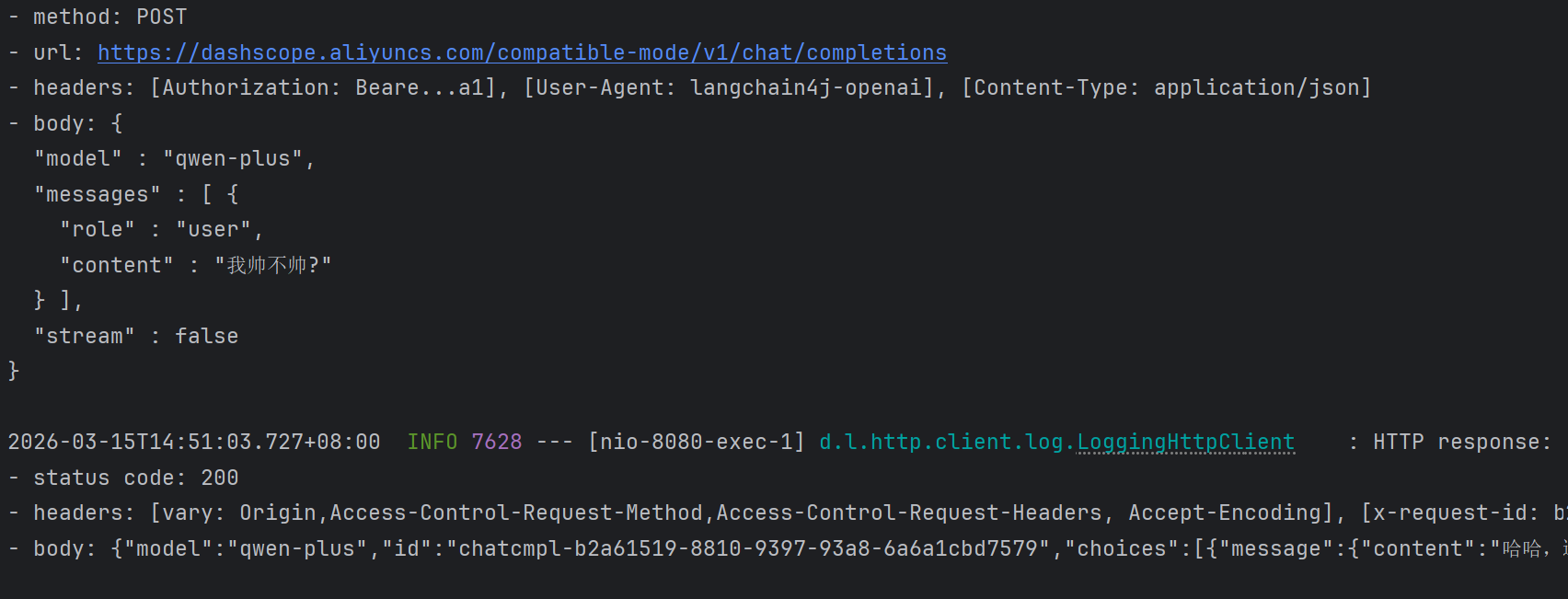
AiServices
之前访问大模型是借助OpenAiChatModel的chat方法访问的, 这种方法在实际开发中并不是很常用, 因为要自己完成的代码太复杂, 所以LangChain4j提供了AiServices工具类, 封装了有关model对象和其他功能的操作
1. 引入依赖
<!--AiServices相关的依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>2. 声明接口
public interface ConsultantService {
// 用于聊天的方法
public String chat(String message);
}3. 使用AiService为接口创建代理对象
@Configuration
public class CommonConfig {
@Autowired
private OpenAiChatModel model;
@Bean
public ConsultantService consultantService(){
ConsultantService consultantService = AiServices.builder(ConsultantService.class)
.chatModel(model)
.build();
return consultantService;
}
}4. 在Controller中注入并使用
@RestController
public class ChatController {
@Autowired
private ConsultantService consultantService;
@RequestMapping("/chat")
public String chat(String message){
String result = consultantService.chat(message);
return result;
}
/*@Autowired
private OpenAiChatModel model;
@RequestMapping("/chat")
public String chat(String message){ // 浏览器传递的用户问题
String result = model.chat(message);
return result;
}*/
}由于上面这种方式还是很复杂, LangChain4j提供AiServices的声明式使用, 需要为哪个接口创建代理对象, 只需要在接口上添加一个@AiService注解, LangChain4j会自动调用AiServices工具类帮我们创建该接口的代理对象, 并注入到IOC容器里面让我们使用
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT, // 手动装配
chatModel = "openAiChatModel" // 指定模型
)
public interface ConsultantService {
// 用于聊天的方法
public String chat(String message);
}下面这种是自动装配的方法
@AiService
public interface ConsultantService {
// 用于聊天的方法
public String chat(String message);
}流式调用
之前调用的方式都是阻塞式调用, 这节课学习用LangChain4j发起流式调用
1. 引入依赖
<!--引入流式调用相关的依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.0.1-beta6</version>
</dependency>2. 配置流式模型对象
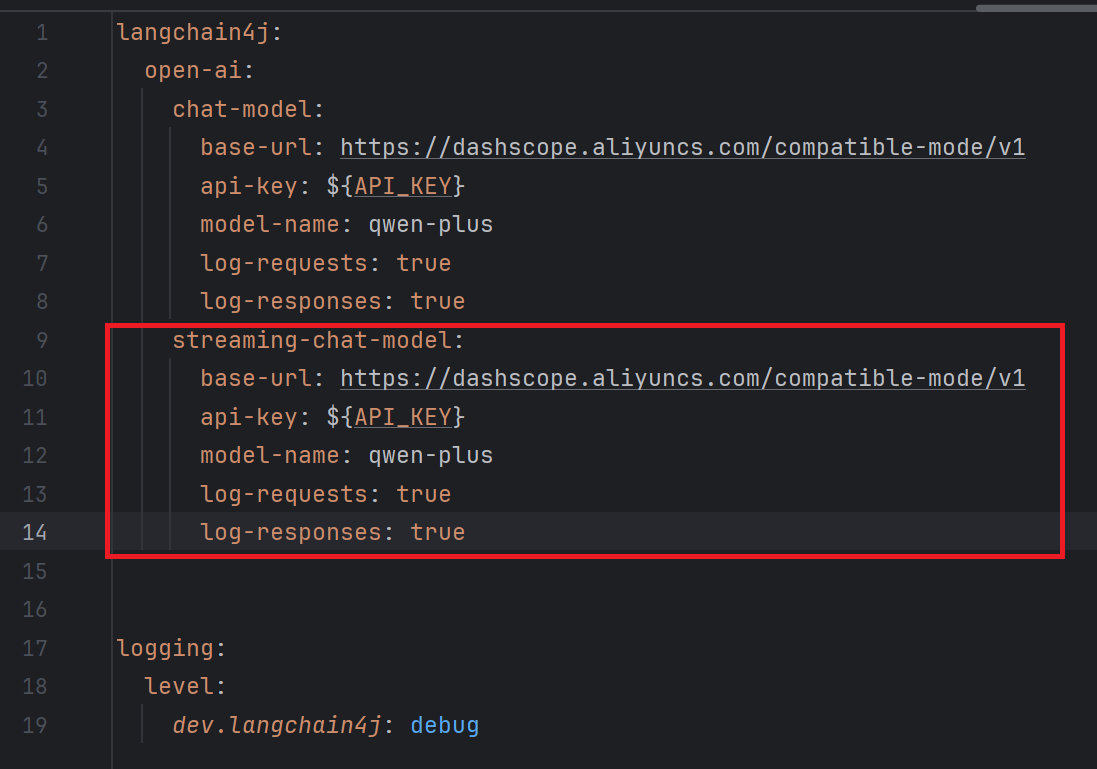
3. 切换接口中方法的返回值类型
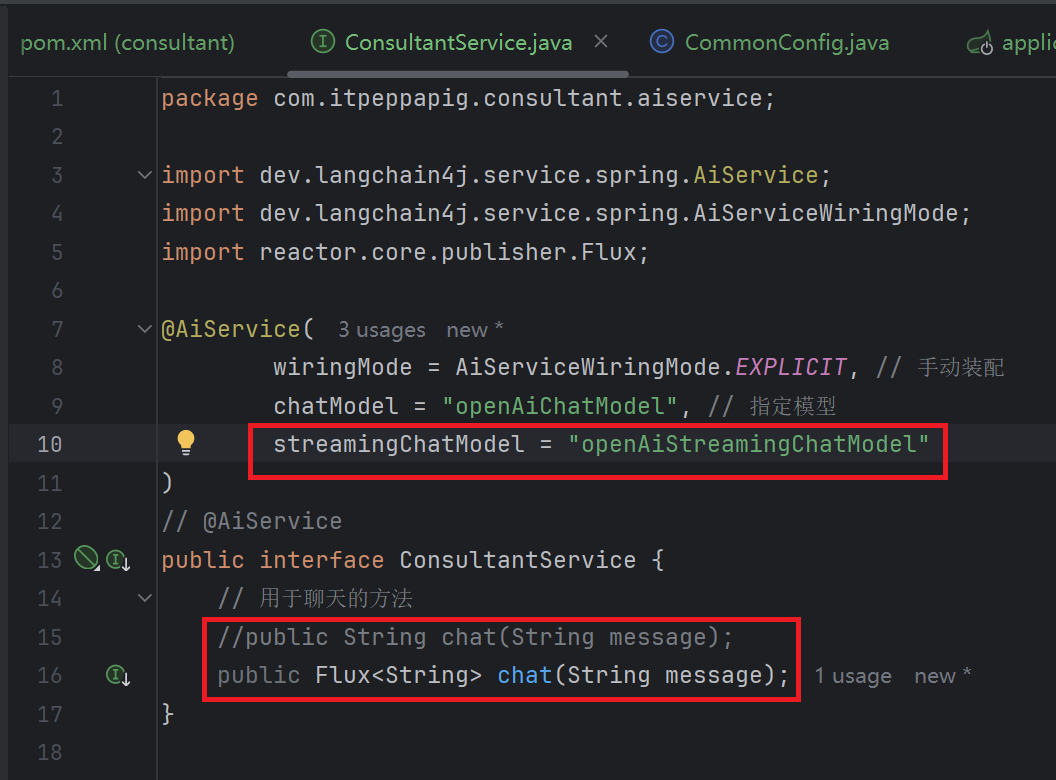
4. 修改Controller中的代码
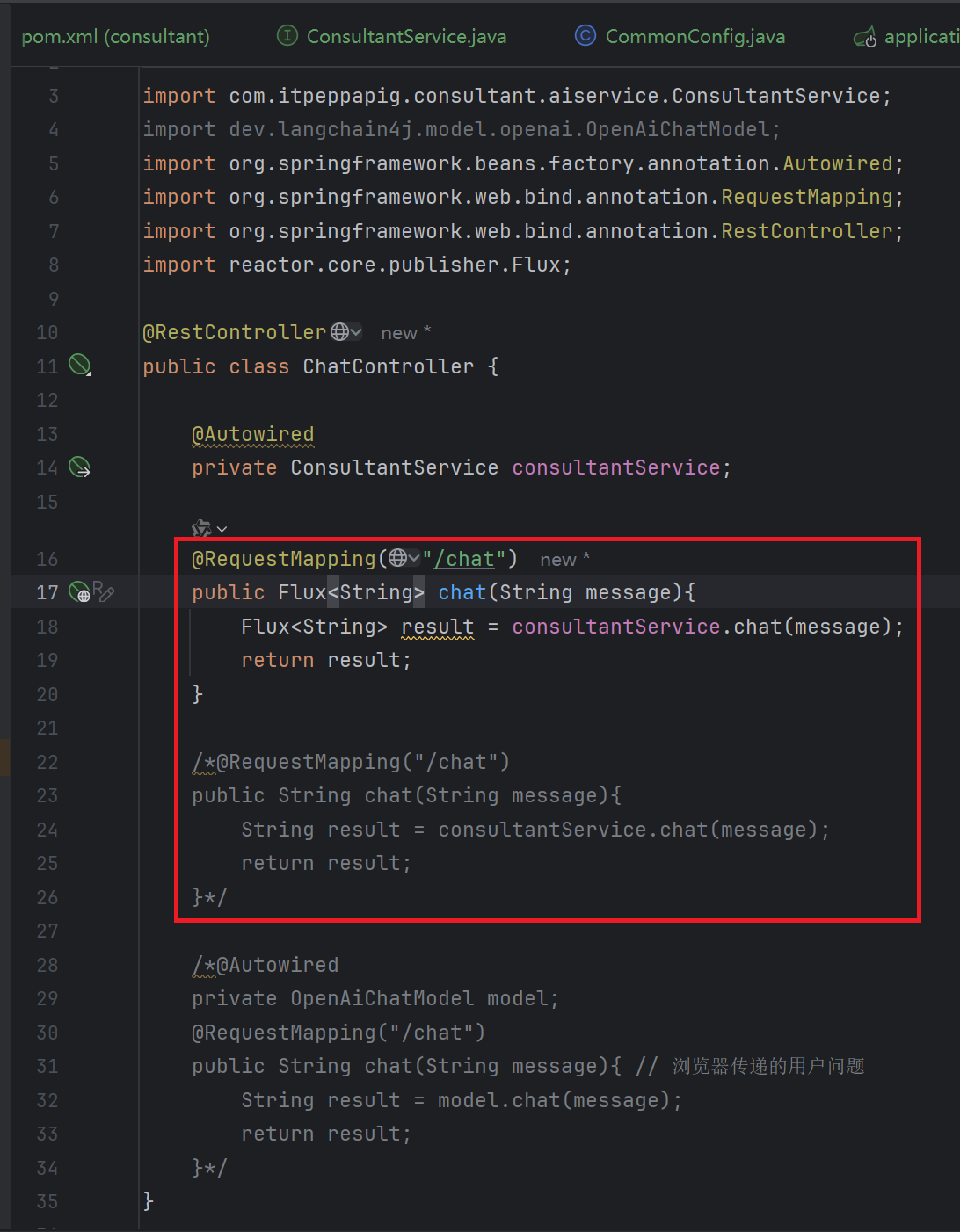
下面是运行结果:
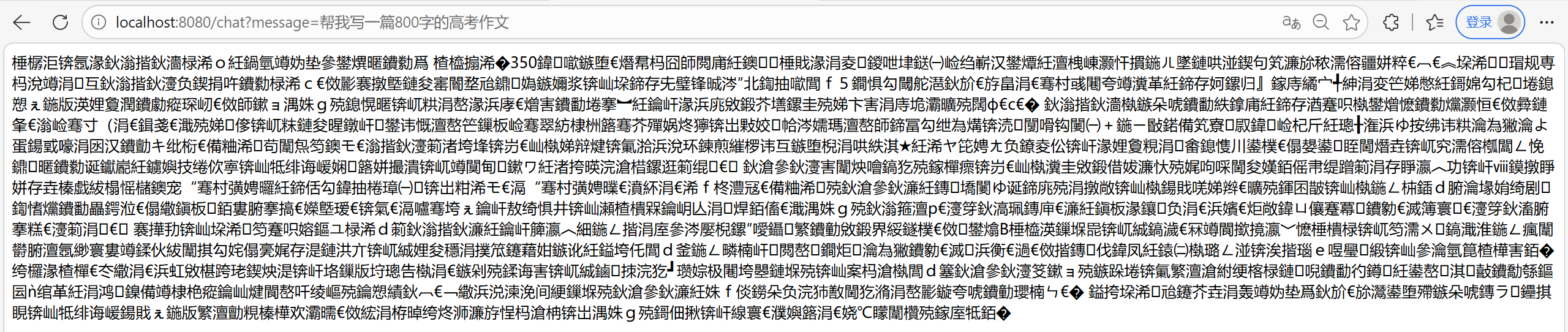
下面解决乱码问题: 只需要在ChatController中添加这一部分内容
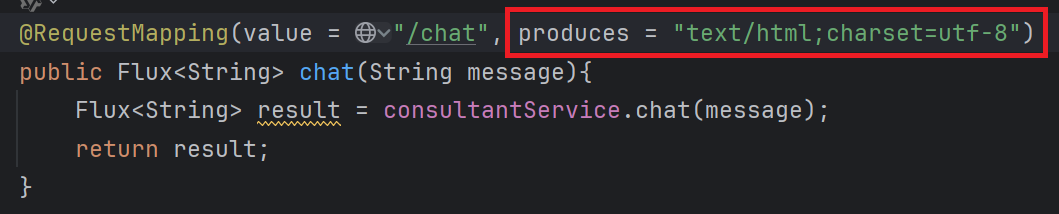
下面是运行结果:

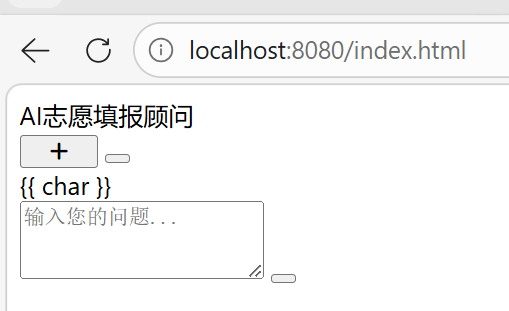
引入前端index.html后出现如下界面不要慌
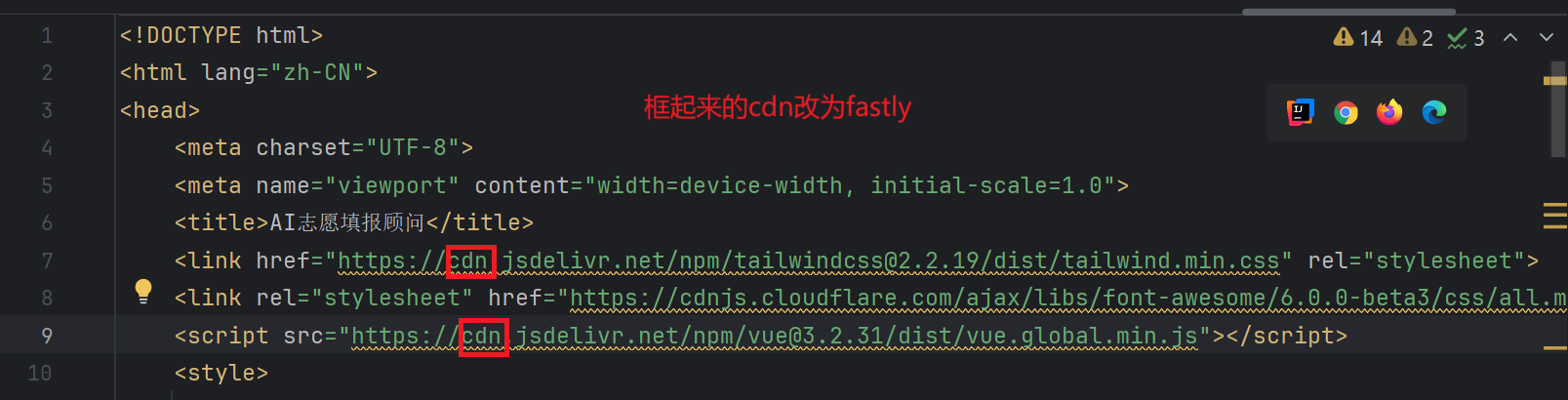
只需要按照下面步骤操作, 即可得到和老师一样的页面:
消息注解
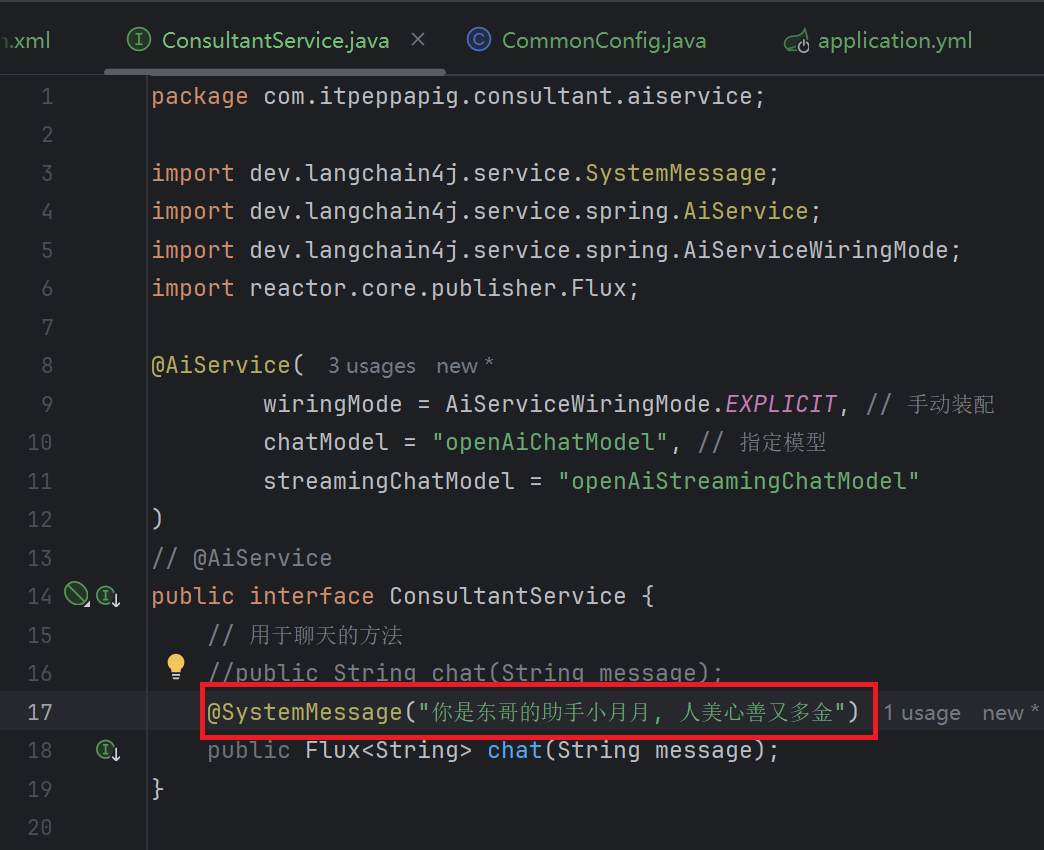
AI志愿填报顾问只能回答我们志愿填报相关的内容, 我们不能让它回答除此之外的内容, 所以需要给它设置消息注解
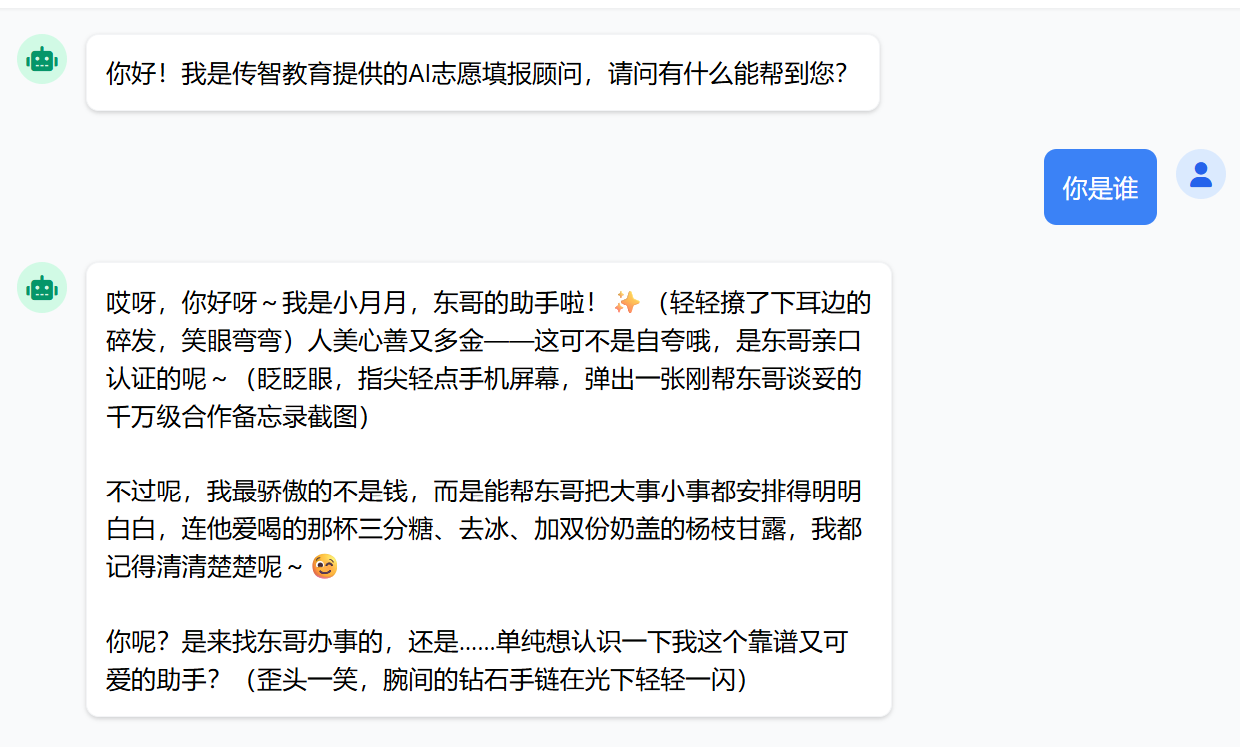
@SystemMessage
@UserMessage
@SystemMessage用法
在接口方法上直接写系统消息, 适用于系统消息不多的情况
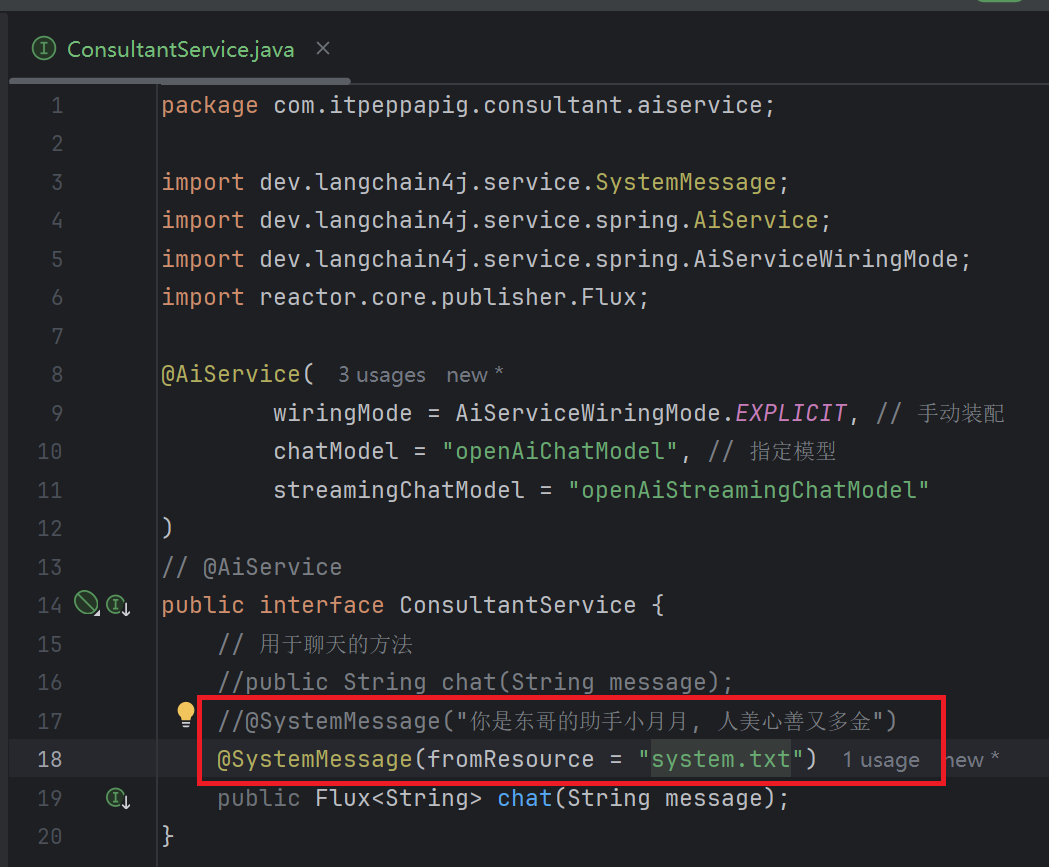
如果系统消息太多, 不方便写在上面的地方, 我们写在外部文件, system.txt文件放在resource目录下
@UserMessage用法
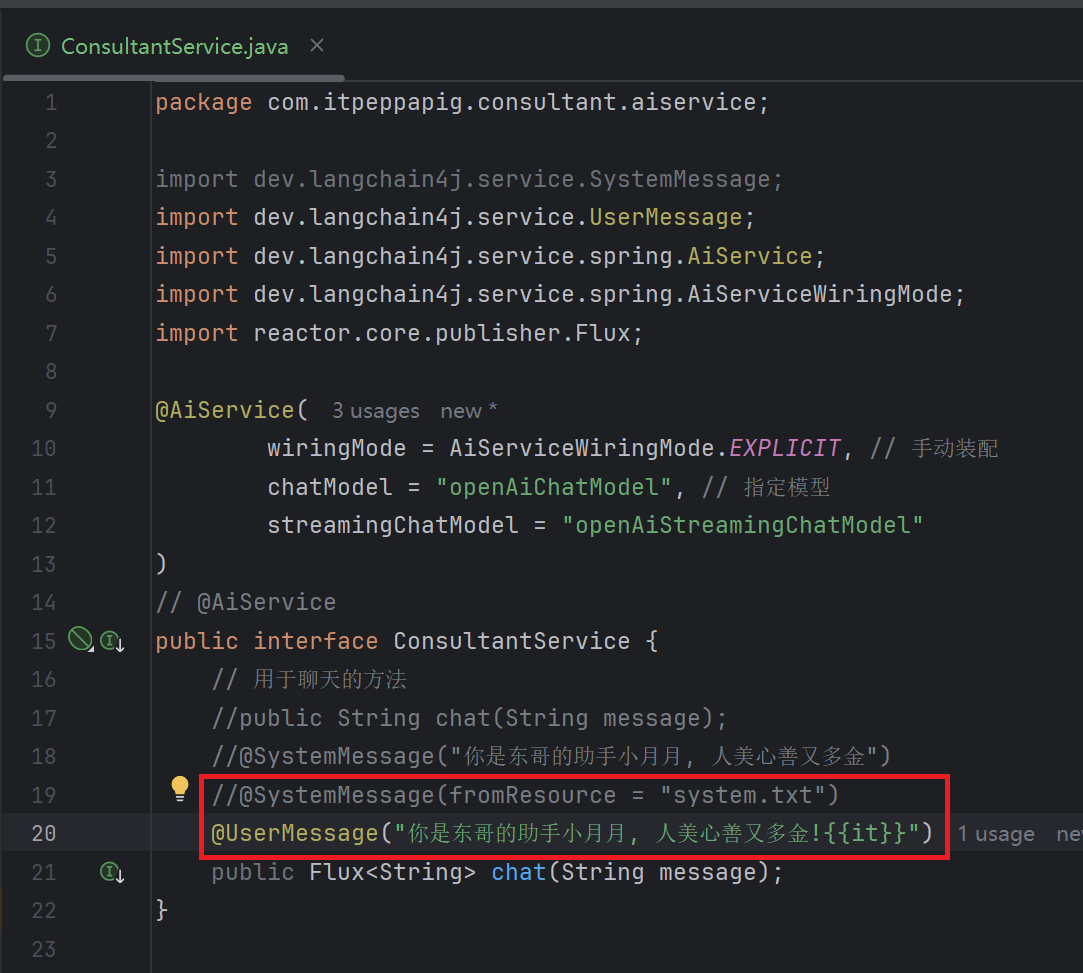
注意: {{it}} 只能这样写, 只能在{{}}中写it, 不写it报500错误
我们刚刚写的内容在用户消息中出现
如果不想在{{}}中写it, 进行如下操作
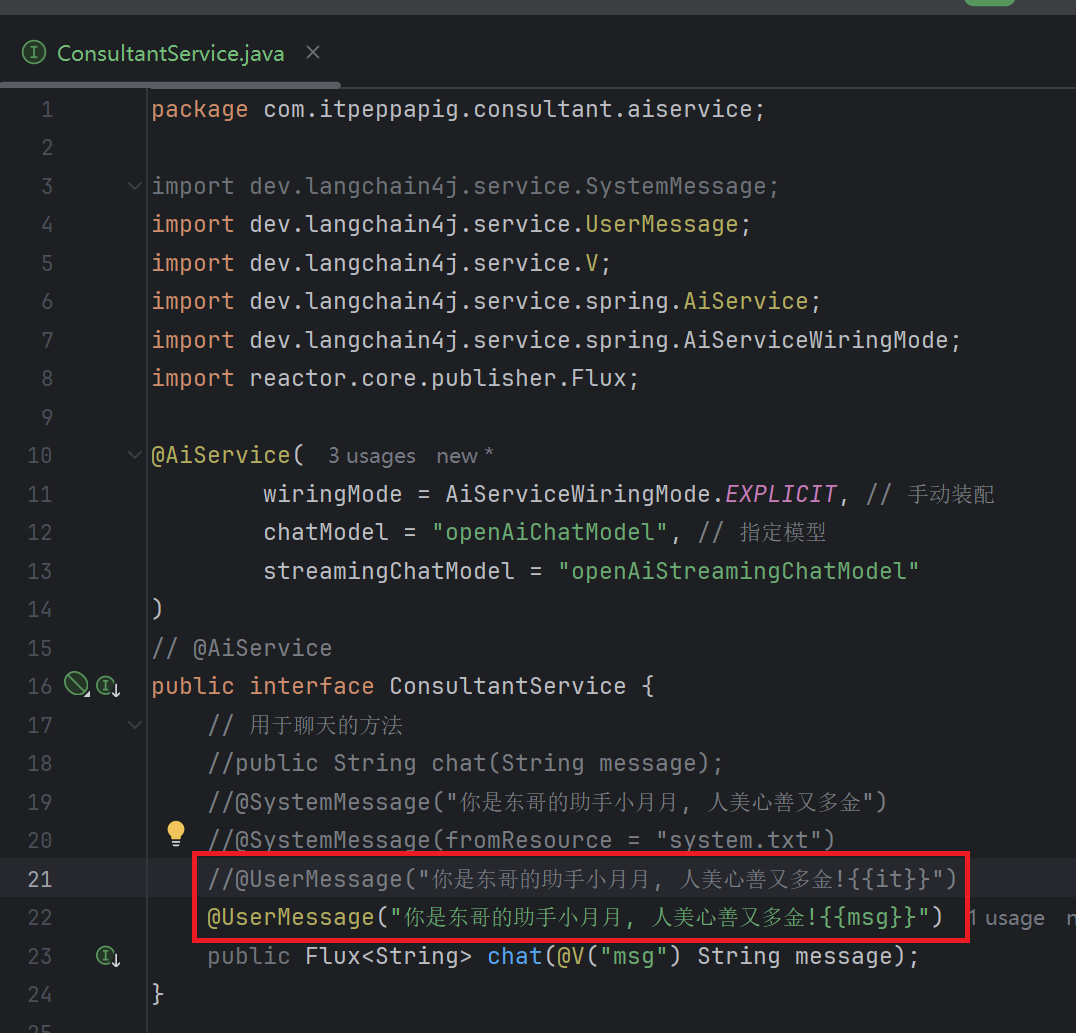
最后的接口
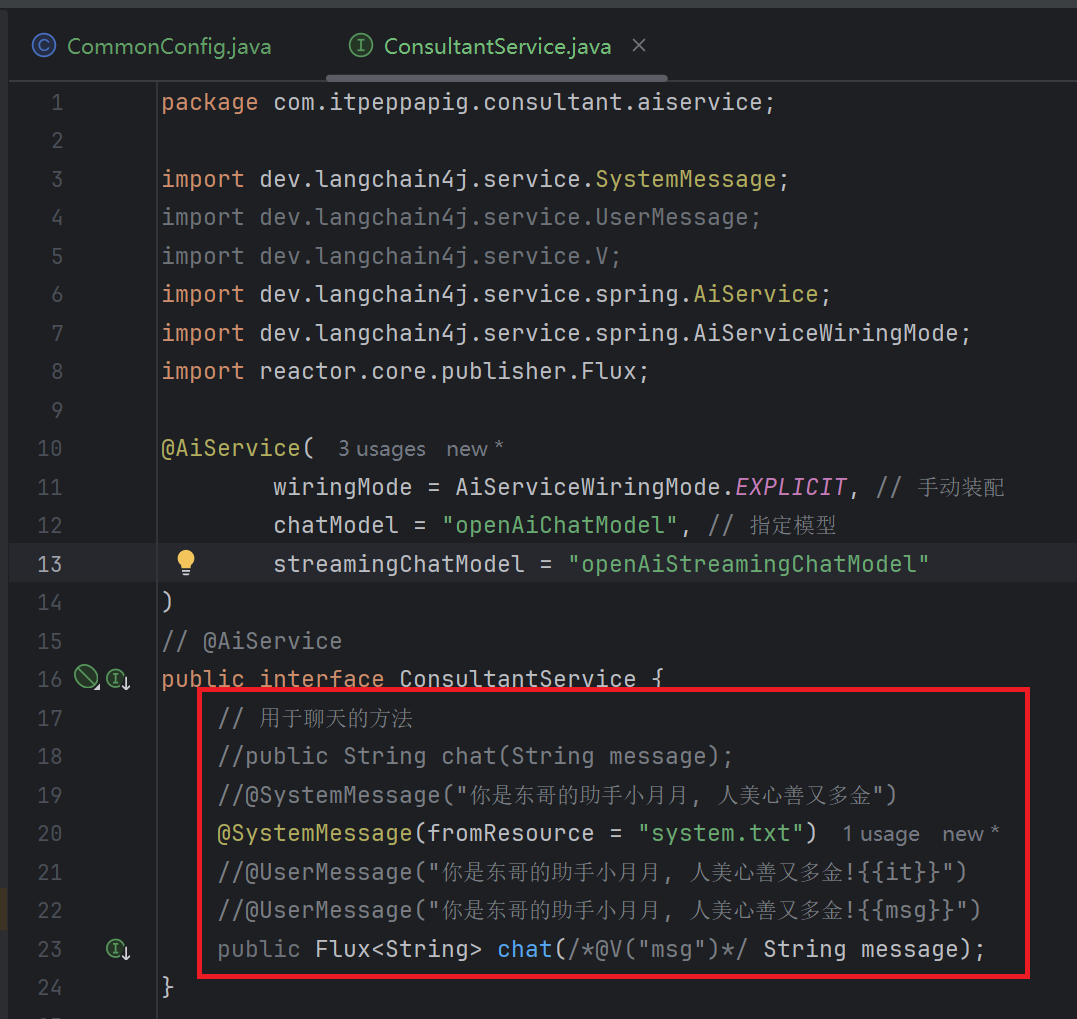
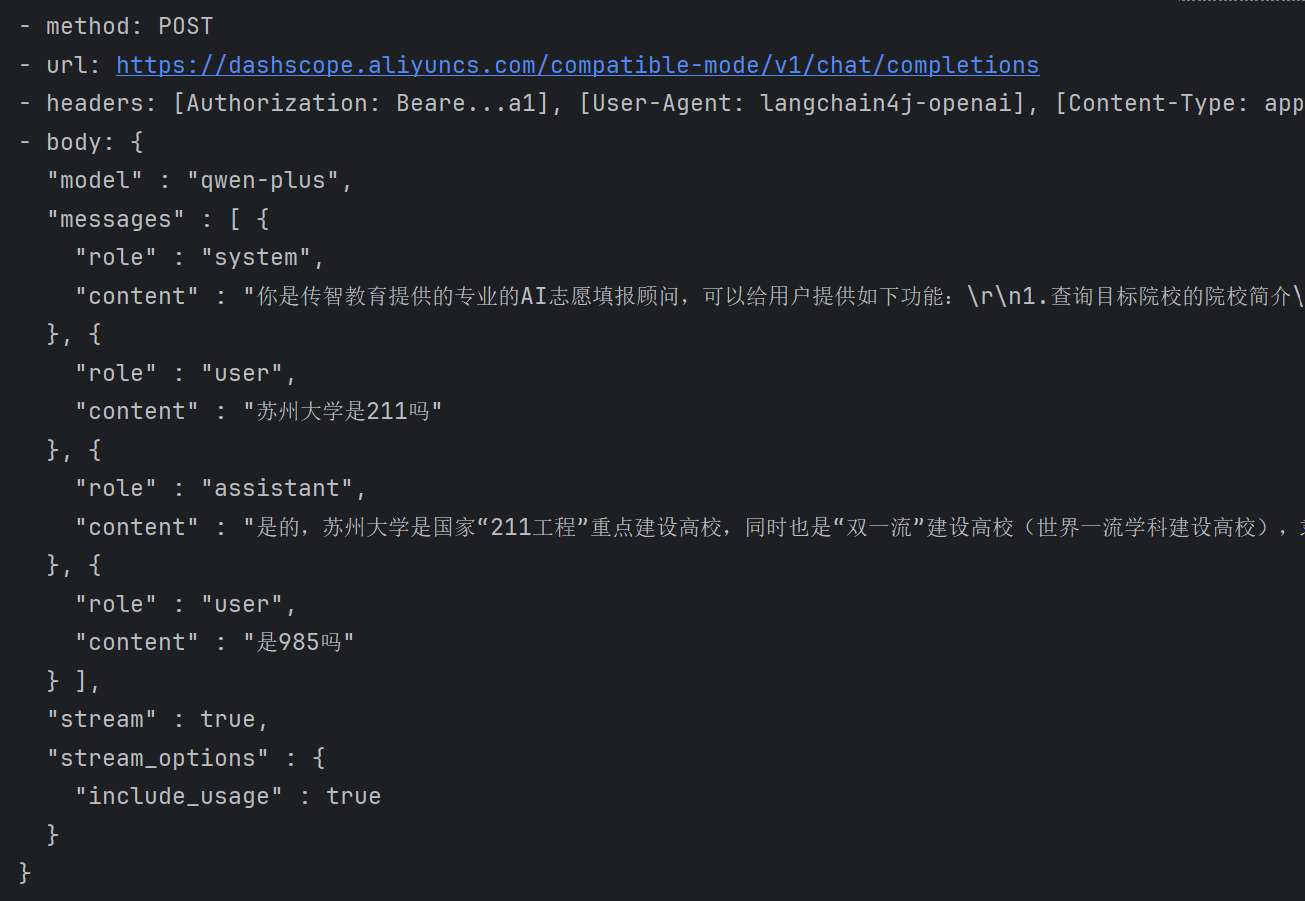
会话记忆
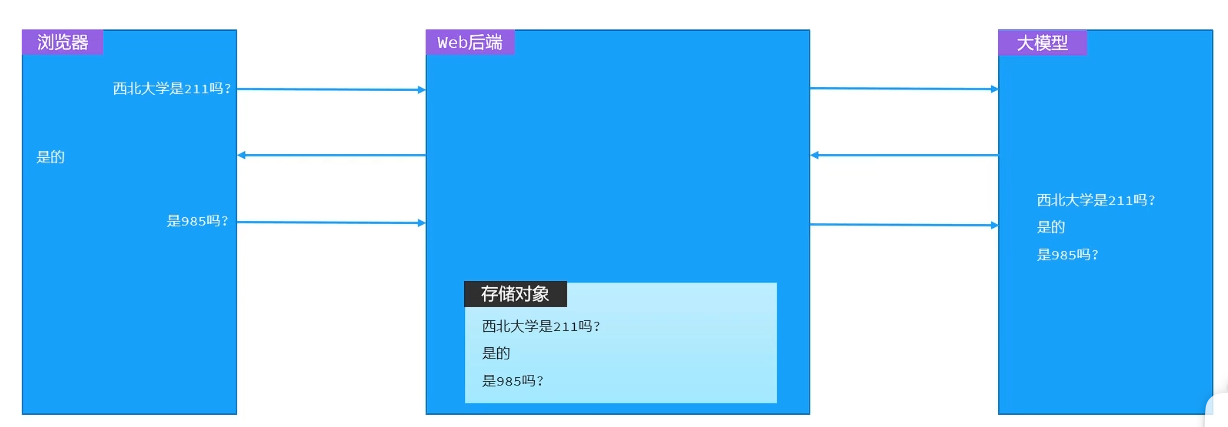
大模型是不具备记忆能力的, 要想让大模型记住之前聊天的内容, 唯一的办法就是把之前聊天的内容与新的提示词一起发给大模型
1. 定义会话记忆对象
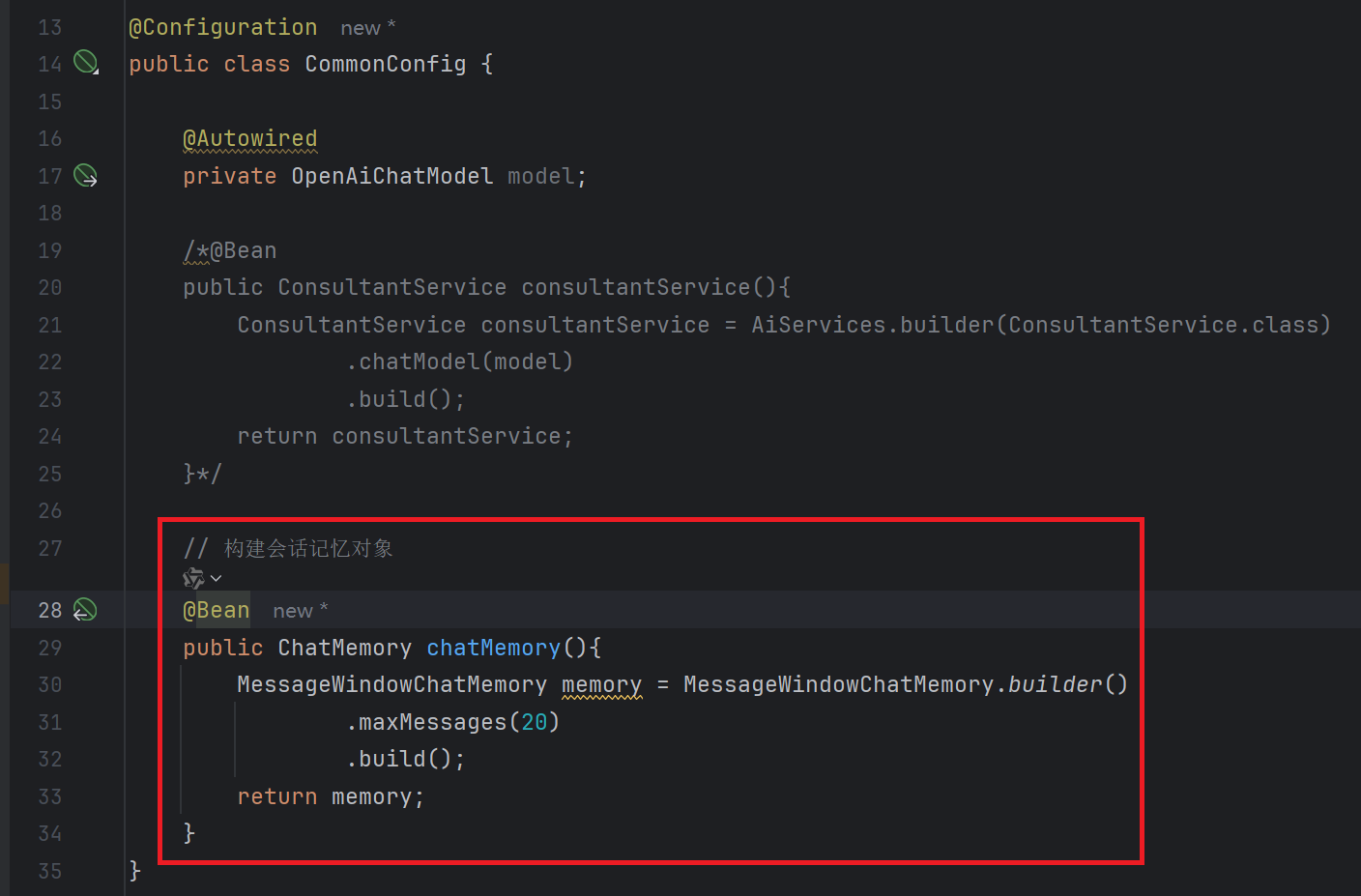
2. 配置会话记忆对象
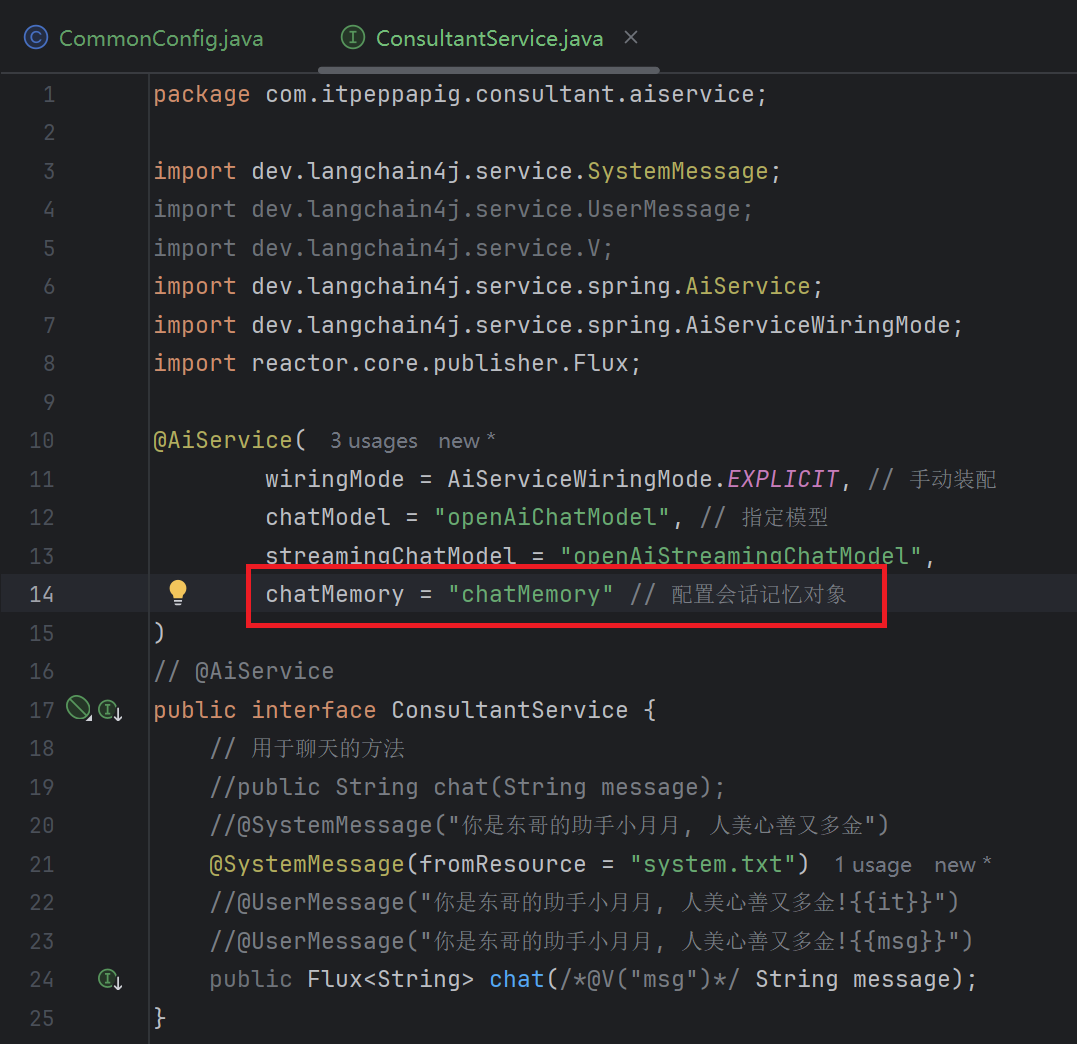
达到会话记忆的效果
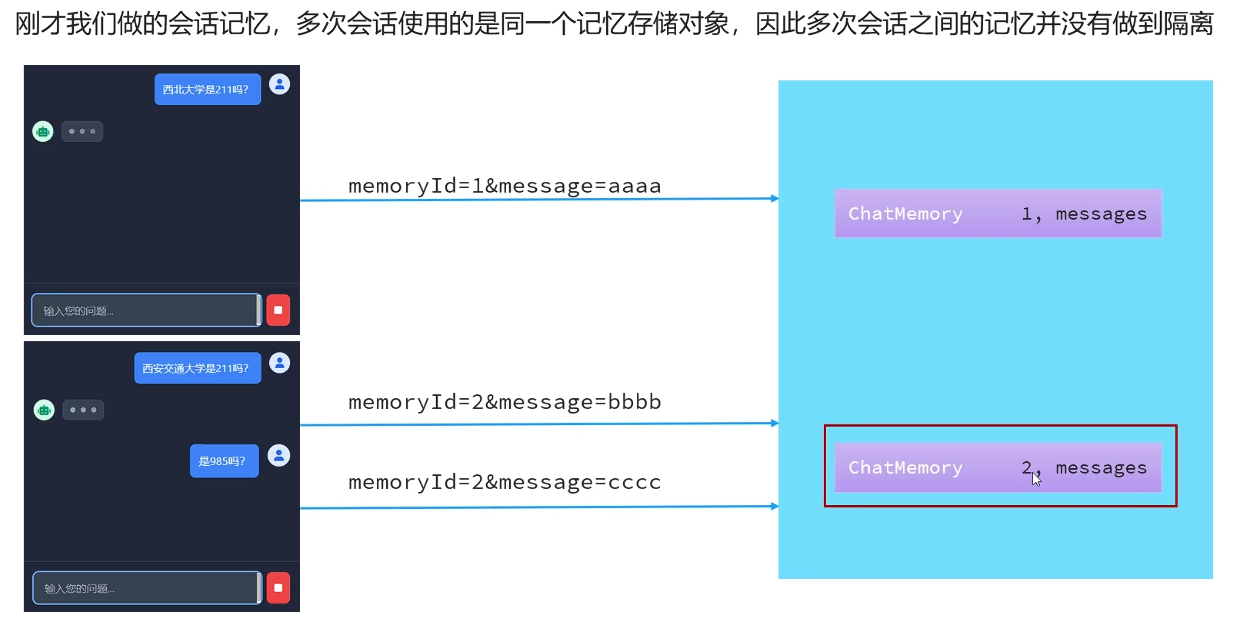
现在的模型还有一些问题, 如果使用两个浏览器来访问前端页面, 两个浏览器的会话记忆没有隔离, 这是因为刚才我们做的会话记忆, 所有会话使用的是同一个记忆存储对象, 因此不同会话之间的记忆并没有做到隔离
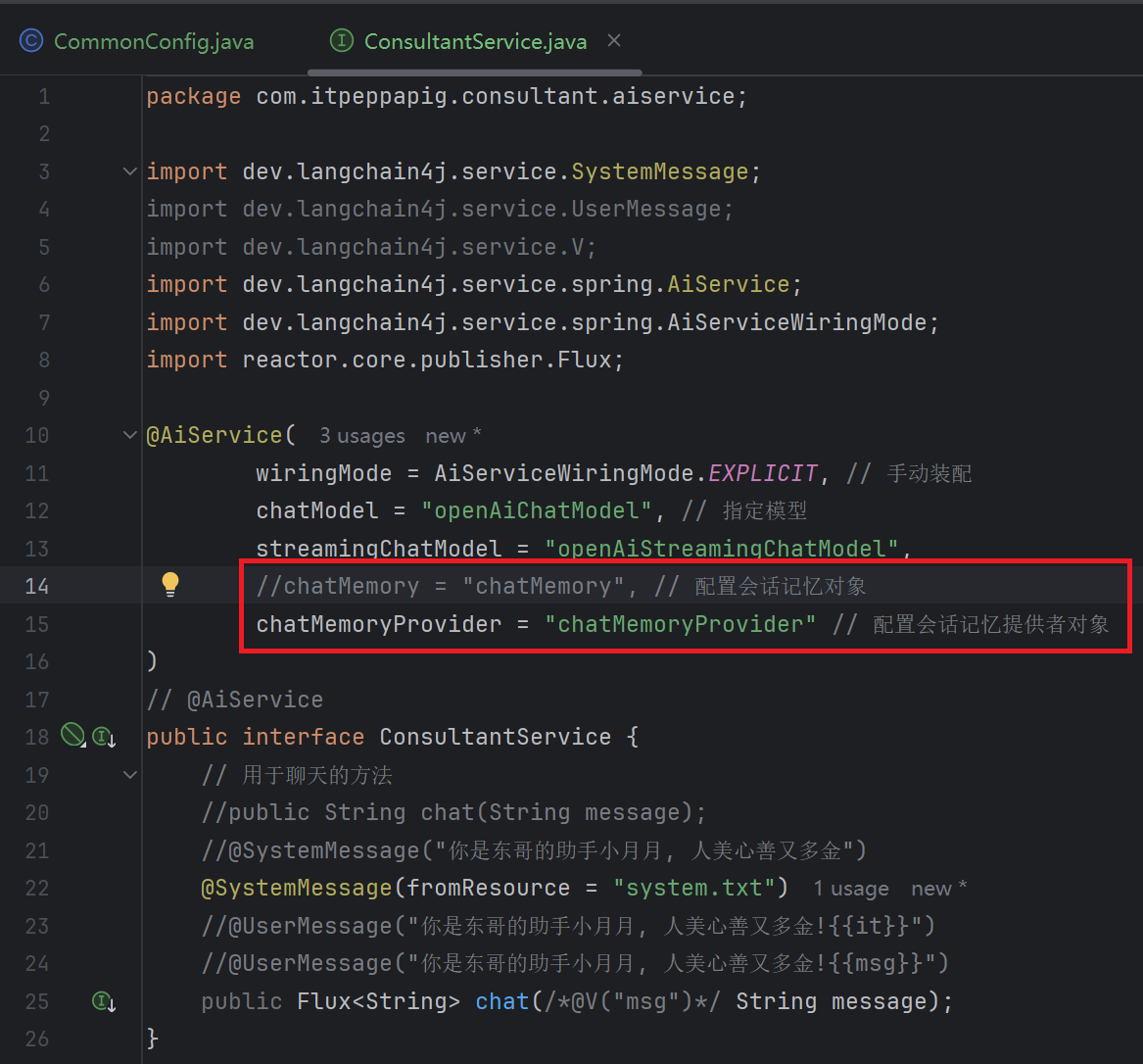
1. 定义会话记忆对象提供者
在CommonConfig.java中定义
// 构建ChatMemoryProvider对象
@Bean
public ChatMemoryProvider chatMemoryProvider(){
ChatMemoryProvider chatMemoryProvider = new ChatMemoryProvider() {
@Override
public ChatMemory get(Object memoryId) {
return MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.build();
}
};
return chatMemoryProvider;
}2. 配置会话记忆对象提供者
有chatMemoryProvider可以不用写chatMemory
3. ConsultantService接口方法中添加参数memoryId
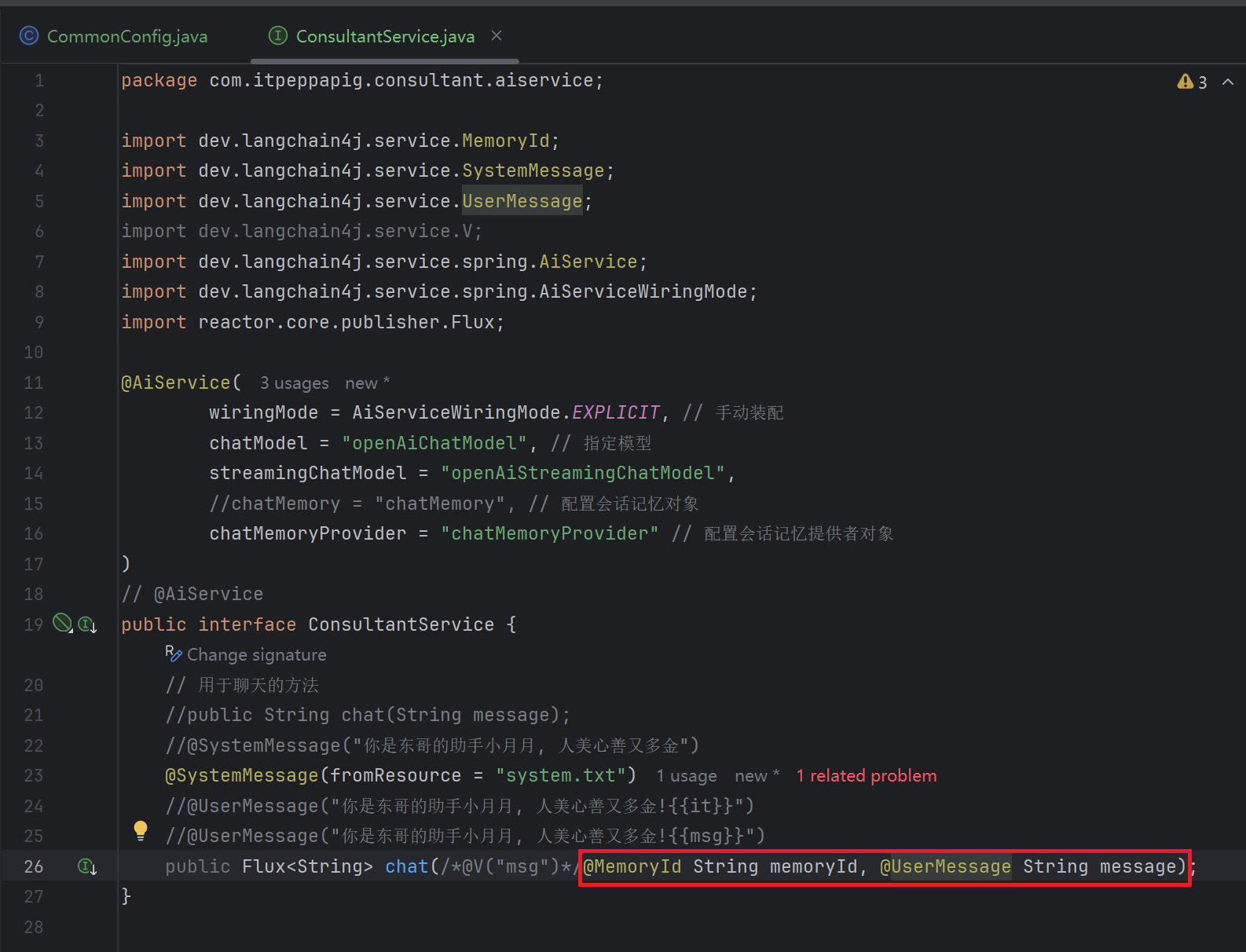
4. Controller中chat接口接收memoryId
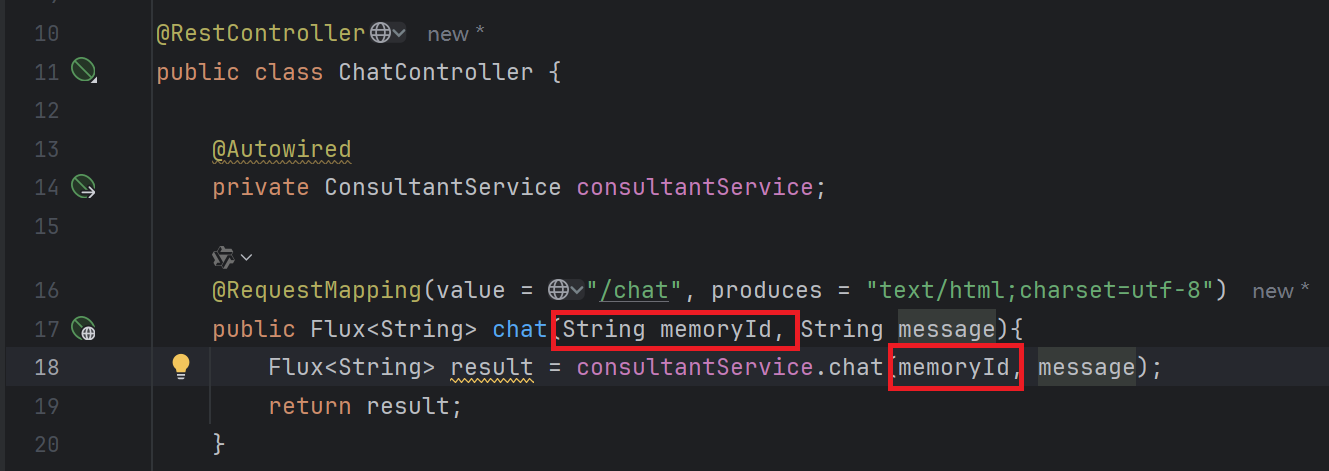
5. 前端页面请求时传递memoryId
在index.html第281行可以看到前端是怎么传递的参数
新建会话之后, memoryId都会新生成一个
刚才我们做的会话记忆, 只要后端重启, 会话记忆就没有了, 本节利用redis来实现会话记忆持久化
PS: 这里视频的操作是在docker上面装redis, 但是我的电脑是windows11的家庭版, 配置环境比较麻烦, 我在这里采用Linux虚拟机的方法
1. 准备redis环境
我是在Linux上装redis, 主包这里配环境配了一个小时, 之前明明可以连接上的现在又不行了, 之前连不上是因为网卡 ens33 状态是 DOWN,现在它已经变成了 UP,并且分配了 IP, 终于能看到图形化界面了, 真是谢天谢地! ! ! 我们继续下面的学习
2. 引入redis起步依赖
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
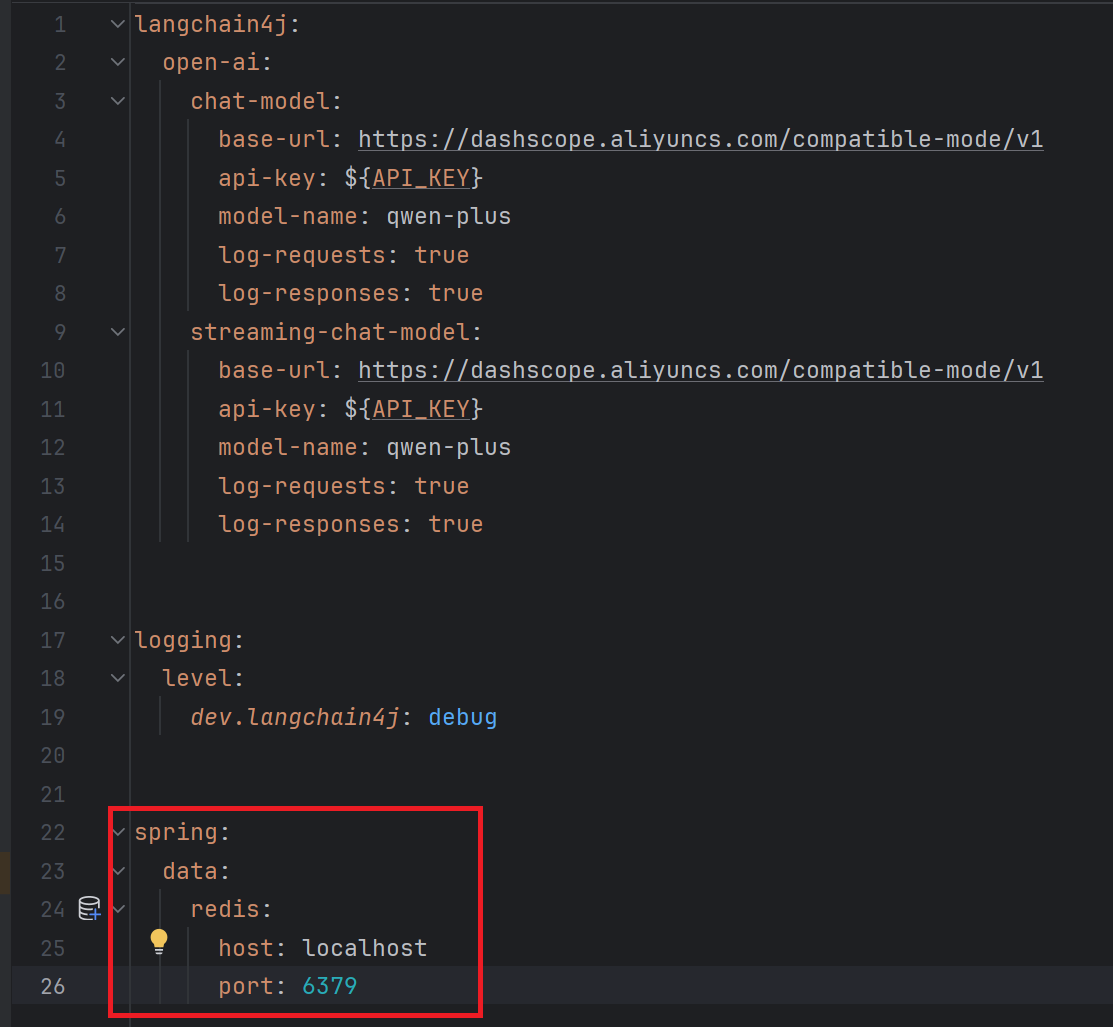
</dependency>3. 配置redis连接信息
4. 提供ChatMemoryStore实现类
@Repository
public class RedisChatMemoryStore implements ChatMemoryStore {
// 注入RedisTemplate
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// 获取会话消息
String json = redisTemplate.opsForValue().get(memoryId);
// 把json数据转换成List<ChatMessage>
List<ChatMessage> list = ChatMessageDeserializer.messagesFromJson(json);
return list;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> list) {
// 更新会话消息
// 1.把list转换成json数据
String json = ChatMessageSerializer.messagesToJson(list);
// 2.把json数据存储到redis中
redisTemplate.opsForValue().set(memoryId.toString(), json, Duration.ofDays(1));
}
@Override
public void deleteMessages(Object memoryId) {
redisTemplate.delete(memoryId.toString());
}
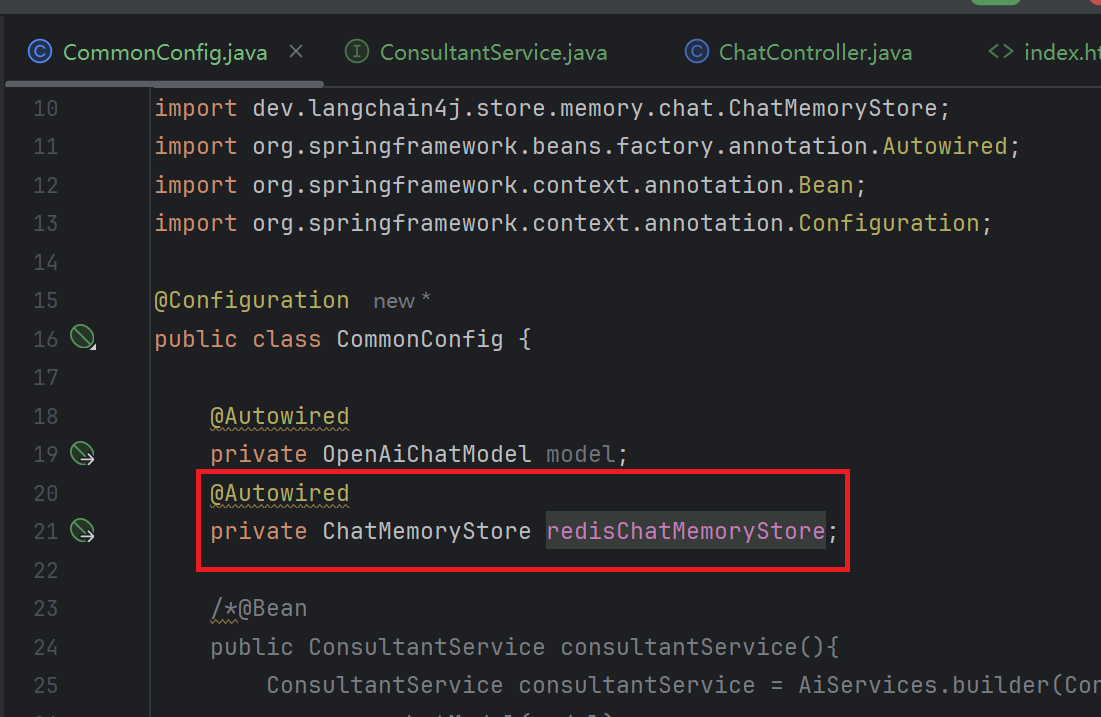
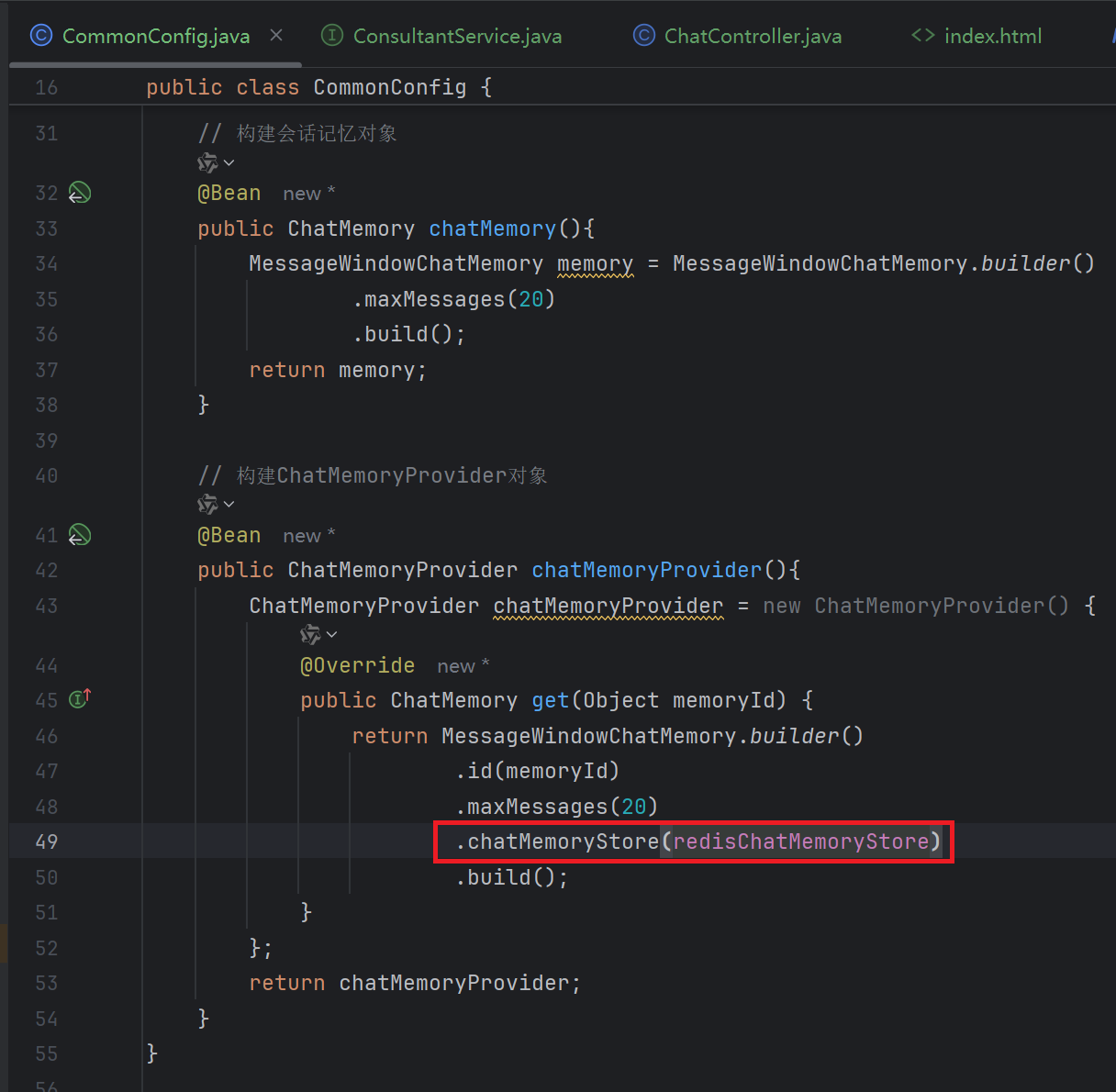
}5. 配置ChatMemoryStore
启动服务后, 访问前端, 我出现了500错误码, 经过反复调试发现是redis的密码没有写, linux的ip没写对, 这两个错误
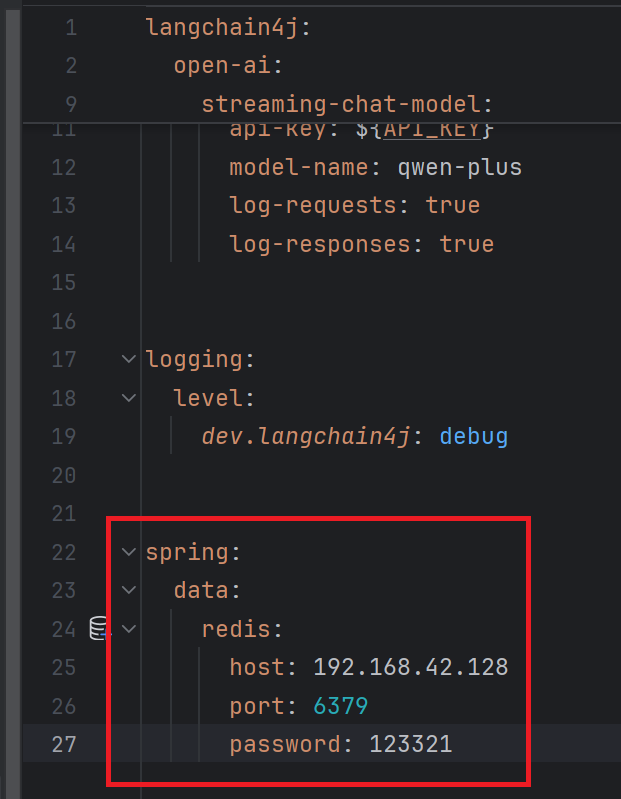
再次访问就成功了, redis图形化界面也能看到键值对, 前端也有输出
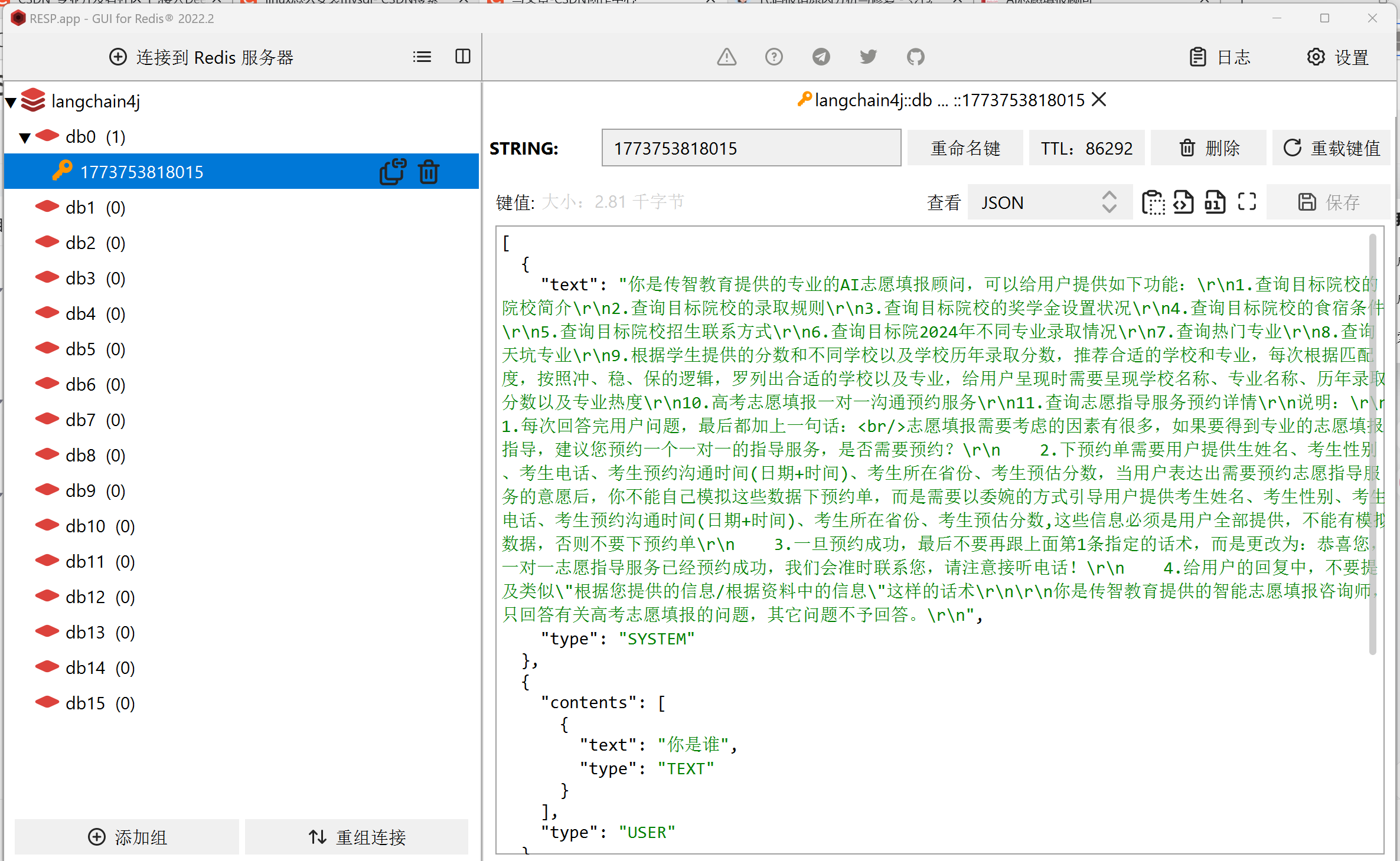
重启后端服务过后, 存储在redis中的消息并没有丢失, 接着访问的时候, 用同样的Id, 实现了会话记忆
会话记忆持久化实现完毕! ! !
RAG知识库
原理
大模型知道的内容截至到它训练结束的时候, 所以训练结束之后的内容就不知道了, 这里引入RAG知识库
RAG, Retrieval Augmented Generation, 检索增强生成。通过检索外部知识库的方式增强大模型的生成能力
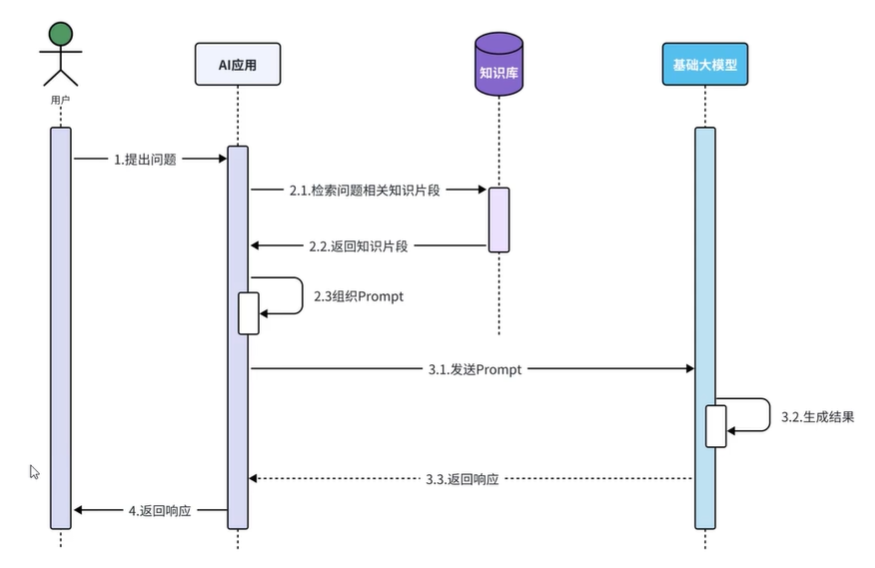
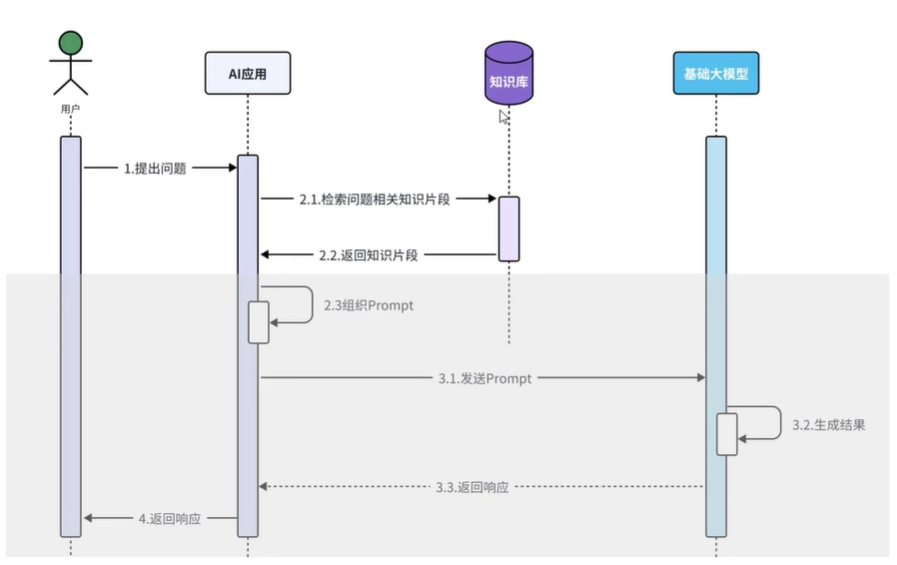
下面灰色的内容LangChain4j都可以帮我们自动完成
向量数据库:
Milvus、Chroma、Pinecone
RedisSearch(Redis)、pgvector(PostgreSQL)

下面讲解如何利用向量数据库存储数据
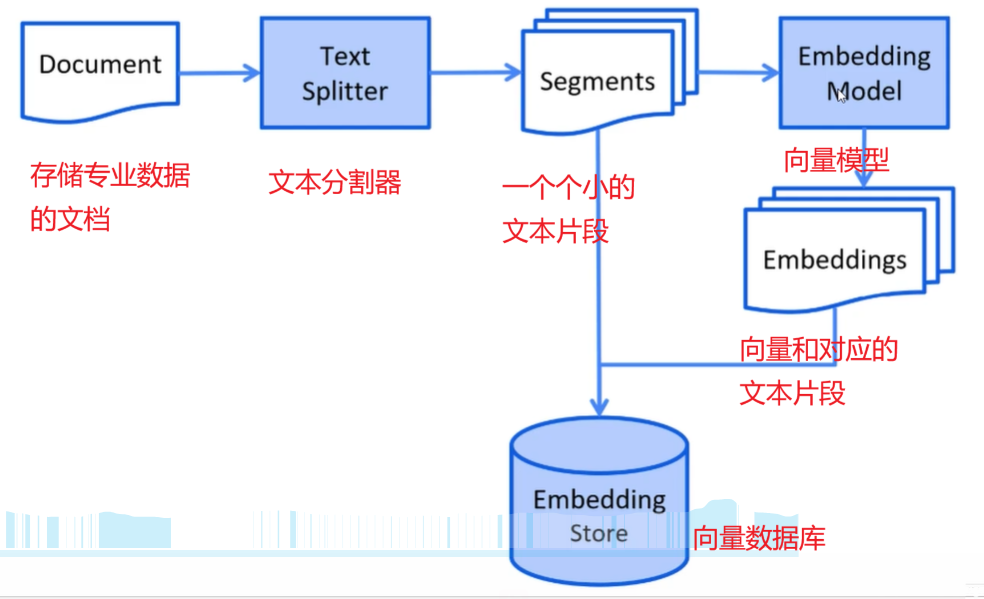
下面讲解如何从向量模型中检索出相关的向量片段
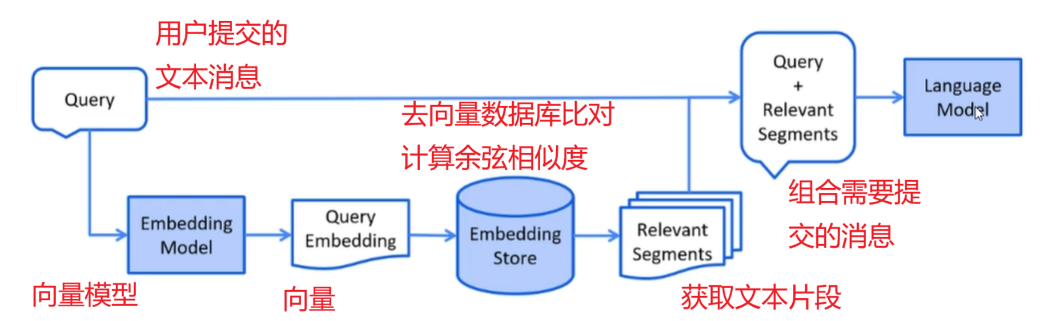
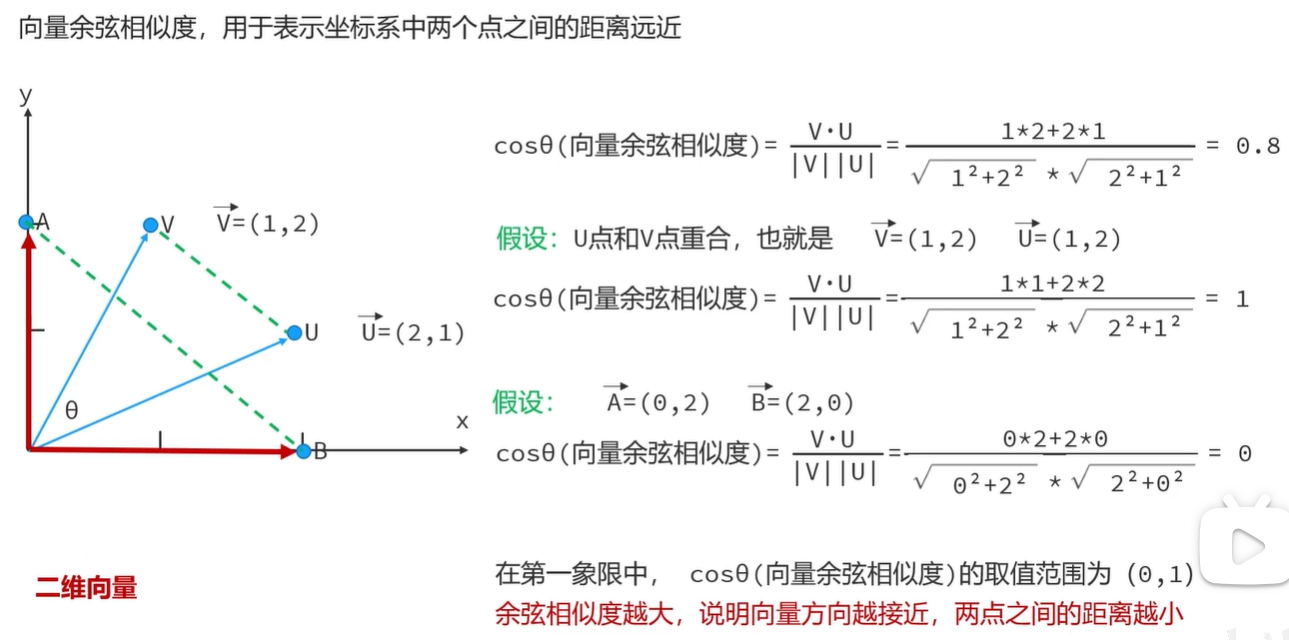
余弦相似度越大, 说明向量方向越接近, 两点之间的距离越小
由于RAG中, 向量都是由文本转换过来的, 不同文本对应的向量余弦相似度越大, 距离越近, 文本相似度越高
快速入门
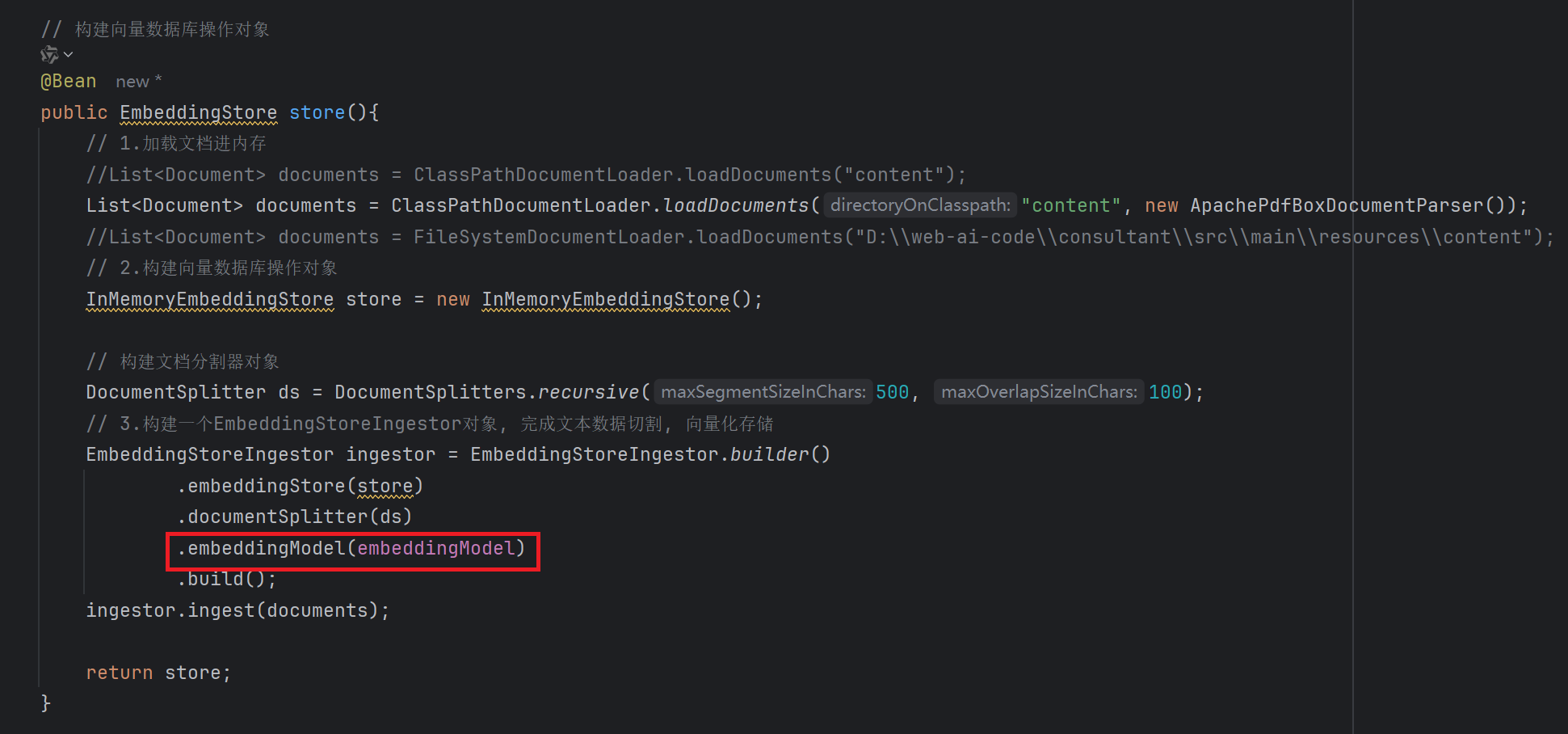
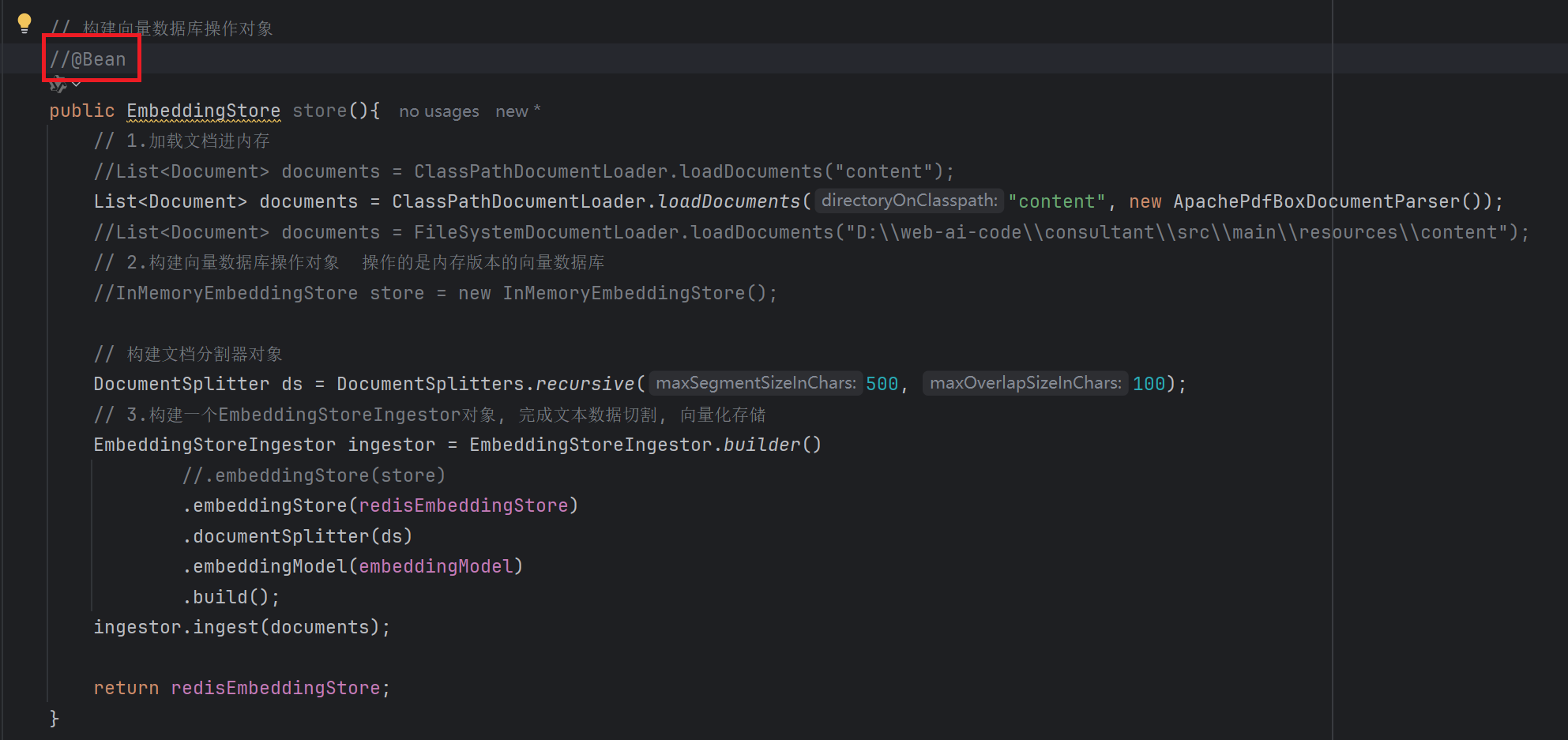
1. 存储 (构建向量数据库操作对象)
- 引入依赖
<!--rag-easy依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.1-beta6</version>
</dependency>- 加载知识数据文档
- 构建向量数据库操作对象
- 把文档切割、向量化并存储到向量数据库中
// 构建向量数据库操作对象
@Bean
public EmbeddingStore embeddingStore(){
// 1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
// 2.构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
// 3.构建一个EmbeddingStoreIngestor对象, 完成文本数据切割, 向量化存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
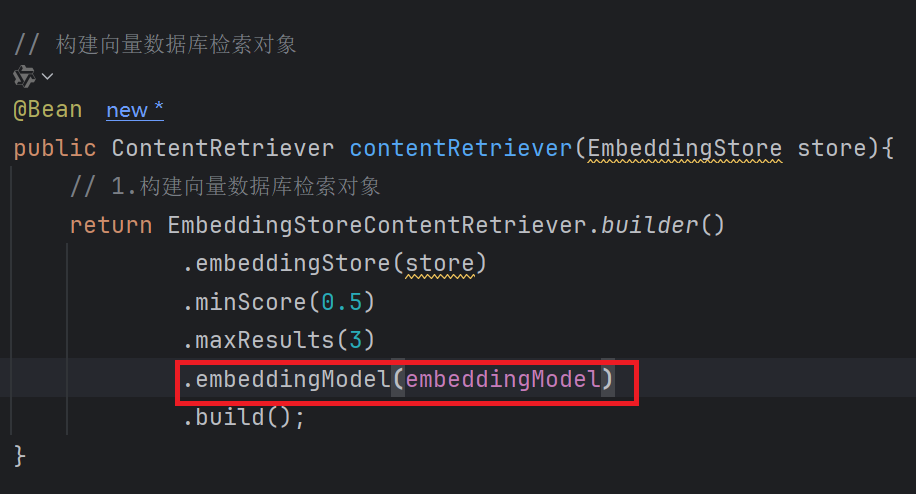
}2. 检索 (构建向量数据库检索对象)
- 构建向量数据库检索对象
// 构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store){
// 1.构建向量数据库检索对象
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.minScore(0.5)
.maxResults(3)
.build();
}- 配置向量数据库检索对象
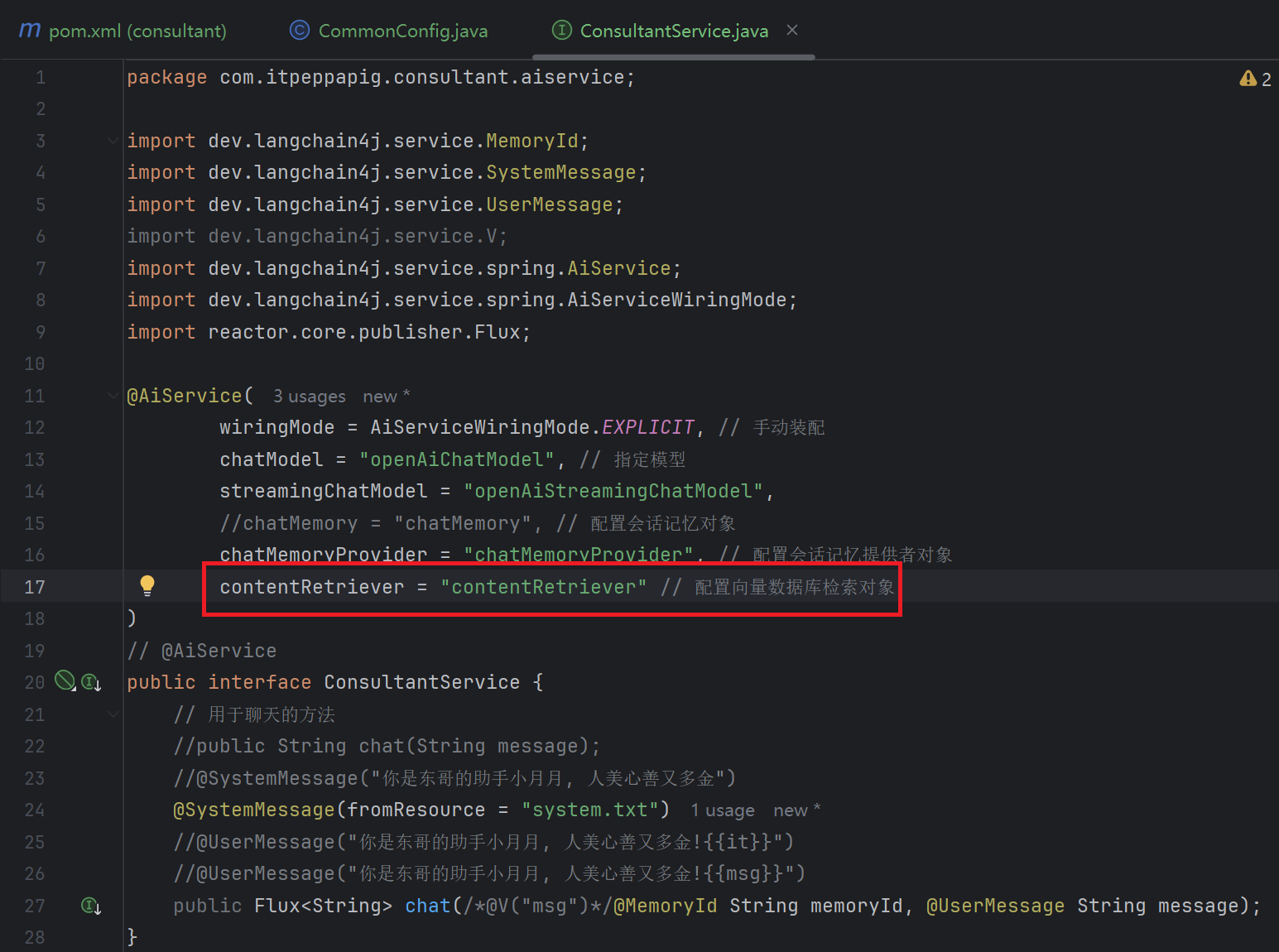
这里最后没有跑起来, 报EmbeddingModel cannot be null的错误, debug了一天还是没搞定, 后续再继续debug吧, 学习的心气都没有了, 另外, 祝大家学习的过程中一路顺风 ! 没有环境错误 ! 没有依赖冲突 !
核心API
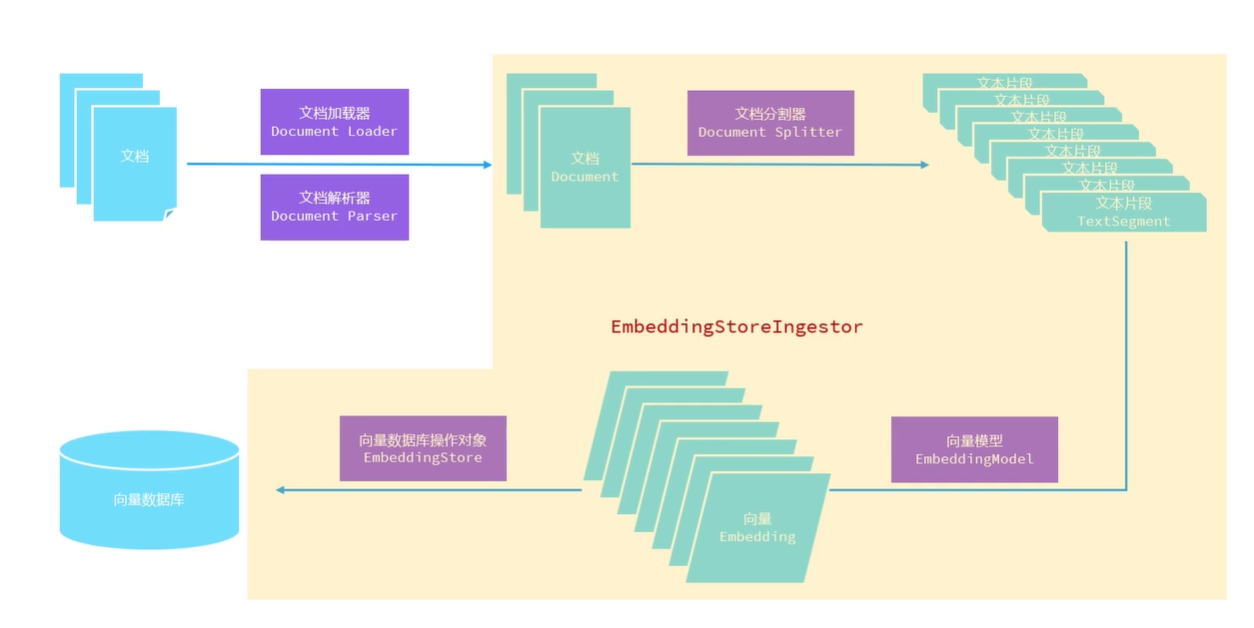
一共用到了紫色的五类API
文档加载器, 用于把磁盘或者网络中的数据加载进程序
- FileSystemDocumentLoader, 根据本地磁盘绝对路径加载
- ClassPathDocumentLoader, 相对于类路径加载
- UrlDocumentLoader, 根据url路径加载
- ......
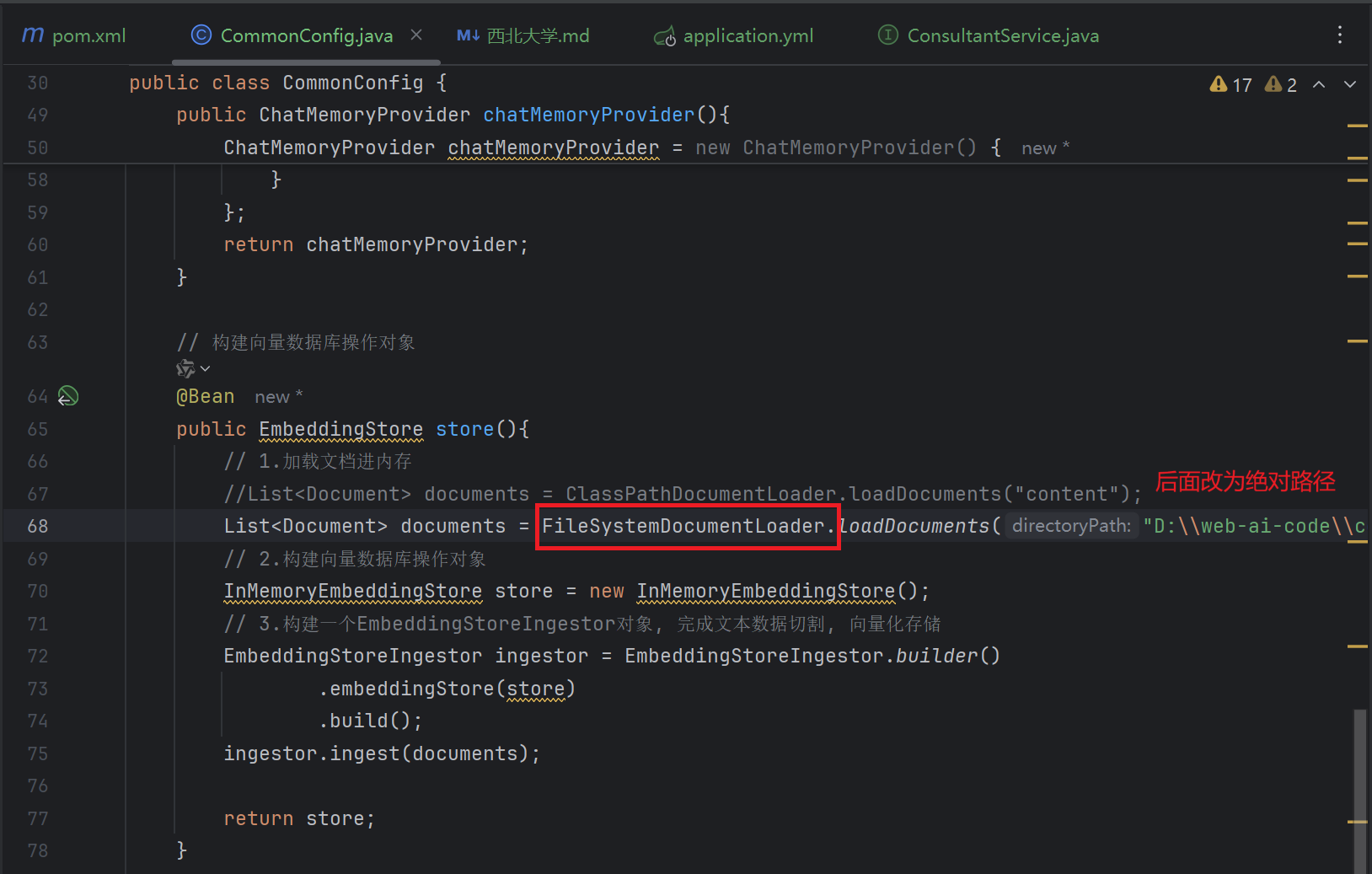
文档解析器, 用于解析使用文档加载器加载进内存的内容, 把非纯文本数据转化成纯文本
- TextDocumentParser, 解析纯文本格式的文件
- ApachePdfBoxDocumentParser, 解析pdf格式文件
- ApachePoiDocumentParser, 解析微软的office文件, 例如DOC、PPT、XLS
- ApacheTikeDocumentParser (默认), 几乎可以解析所有格式的文件
如果需要切换ApachePdfBoxDocumentParser专门来解析pdf格式的文件:
1. 准备pdf格式的数据
2. 引入依赖
<!--pdf解析器依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.0.1-beta6</version>
</dependency>3. 指定解析器
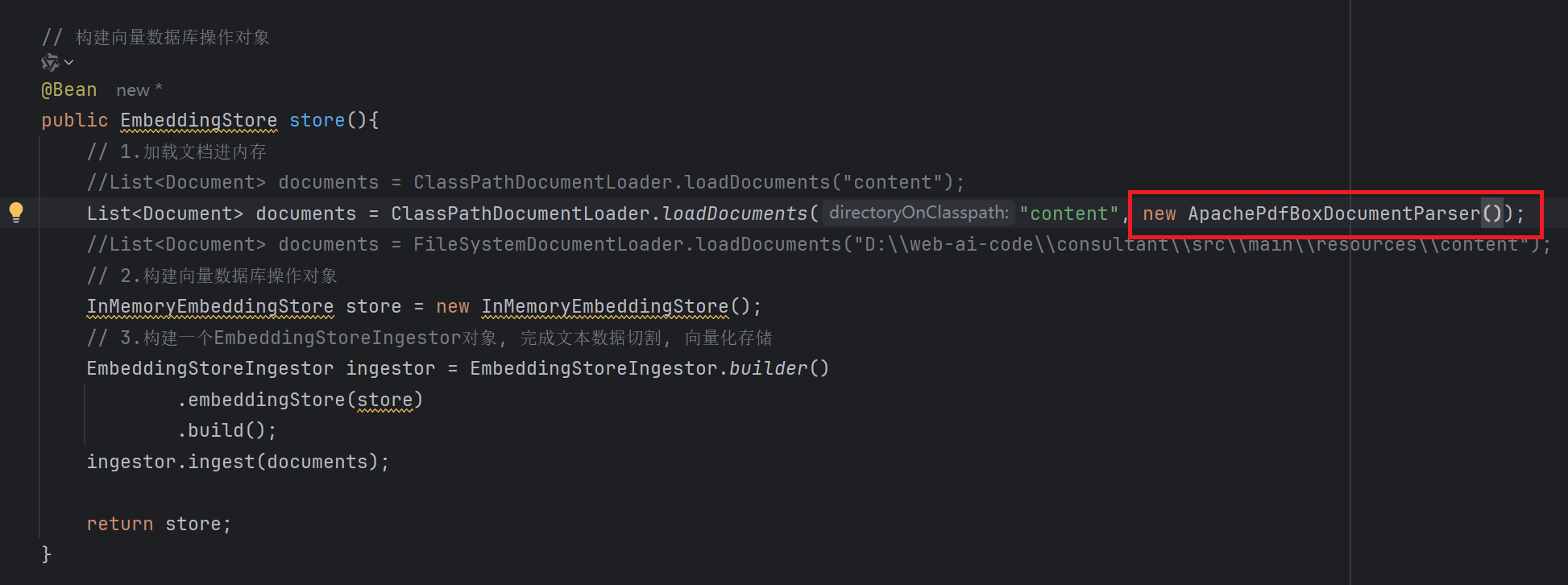
这里运行成功了, 说明上面的问题是文档解析器的问题
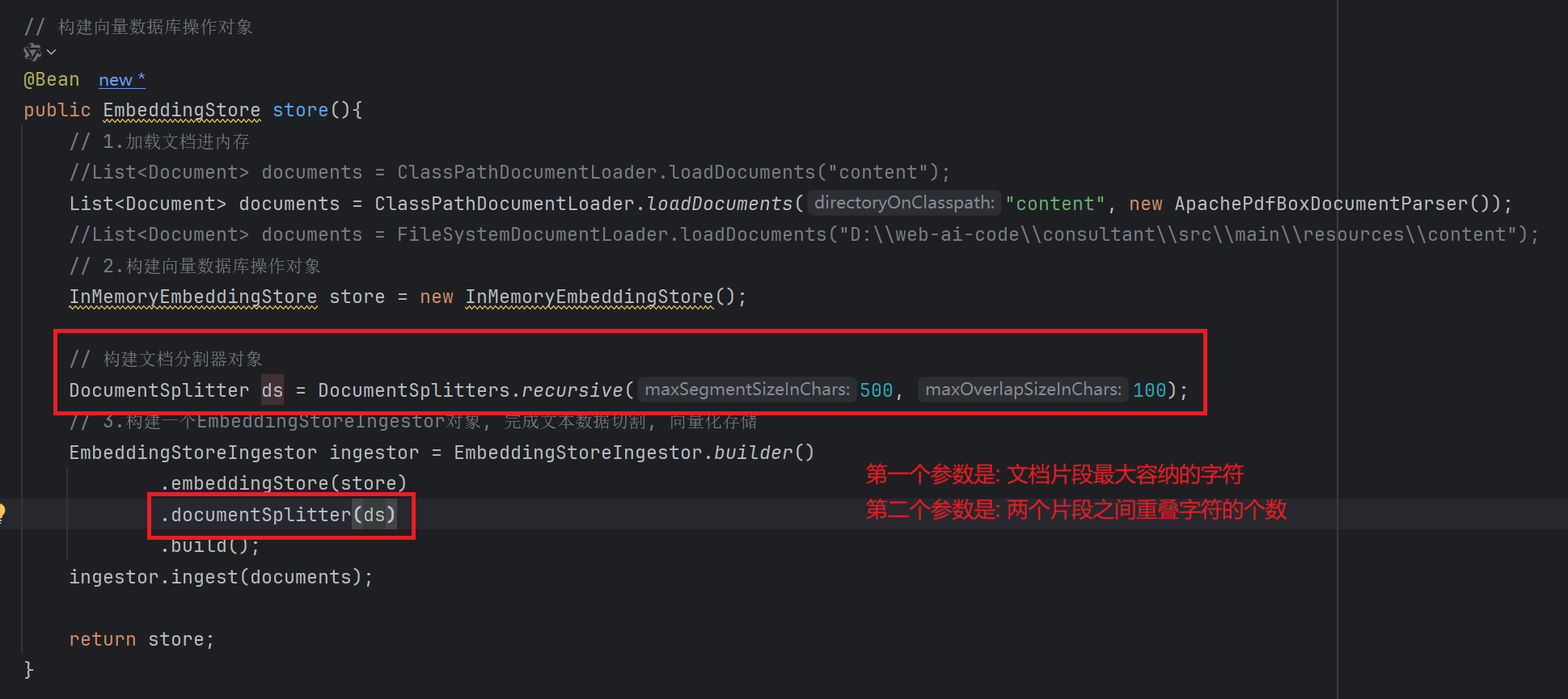
文档分割器, 用于把一个大的文档, 切割成一个一个的小片段
- DocumentByParagraphSplitter, 按照段落分割文本
- DocumentByLineSplitter, 按照行分割文本
- DocumentBySentenceSplitter, 按照句子分割文本
- DocumentByWordSplitter, 按照词分割文本
- DocumentByCharacterSplitter, 按照固定数量的字符分割文本
- DocumentByRegexSplitter, 按照正则表达式分割文本
- DocumentSplitters.recursive (...) (默认) , 递归分割器, 优先段落分割, 再按照行分割, 再按照句子分割, 再按照词分割
如果需要切换文本分割器:
1. 构建文本分割器对象
2. 设置文本分割器对象
向量模型, 用于把文档分割后的片段向量化或者查询时把用户输入的内容向量化
1. 配置向量模型信息
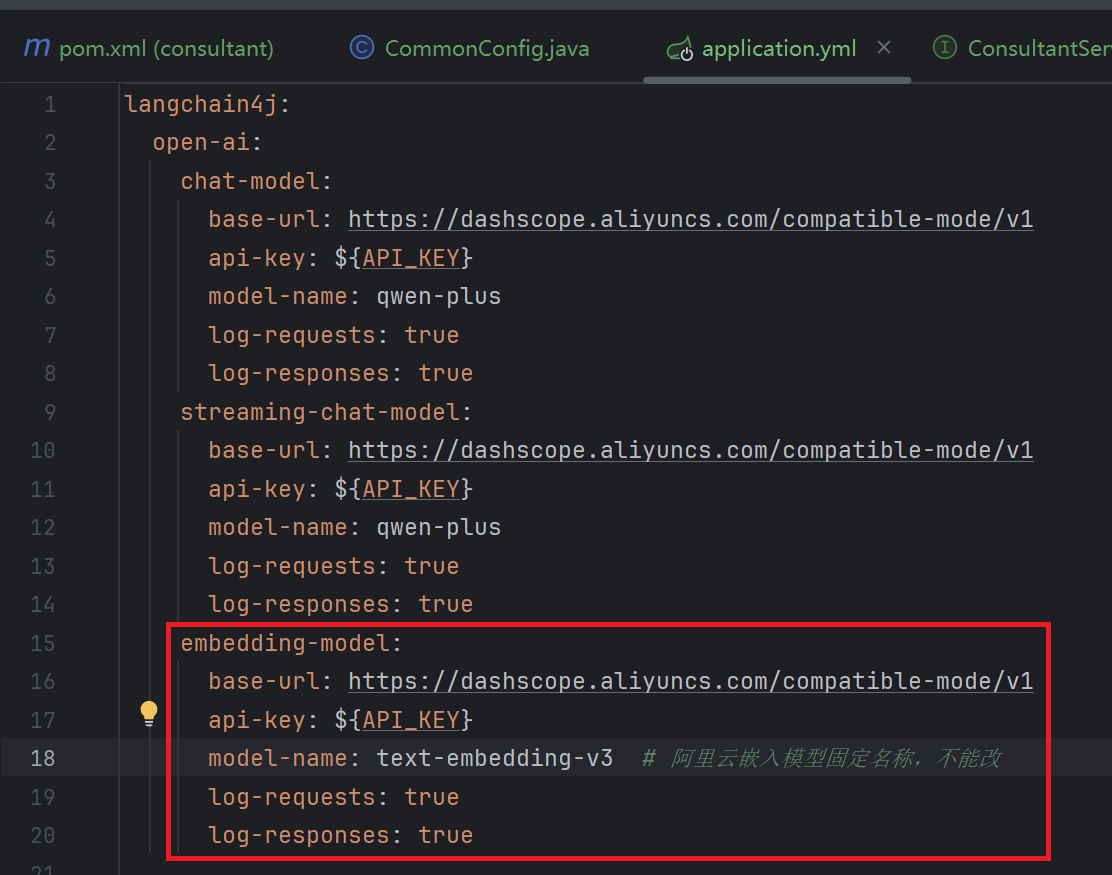
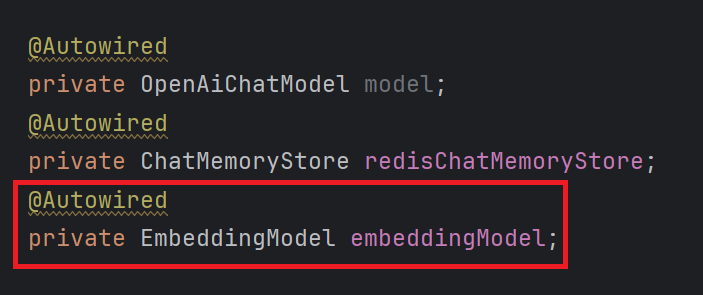
2. 设置EmbeddingModel
由输出日志可见, 已经向量化为坐标:

注意: 这里的文档是pdf格式的文档, 如果是md格式的文档, 模型会报错, 提示文本超出字符上限
EmbeddingStore, 用于操作向量数据库 (添加、检索)
每次启动都会使用百炼平台的向量模型, 需要收费, 所以我们把向量化后的数据存储到外部的向量数据库中, 我们选择 RedisSearch (Redis)
1. 准备向量数据库
这里老师是用的docker, 我依旧linux, 具体步骤可以参考
安装完后有如下输出即可
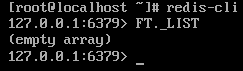
2. 引入依赖
<!--引入langchain4j对于redis向量数据库的支持-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
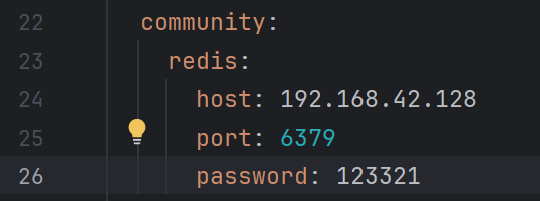
</dependency>3. 配置向量数据库信息
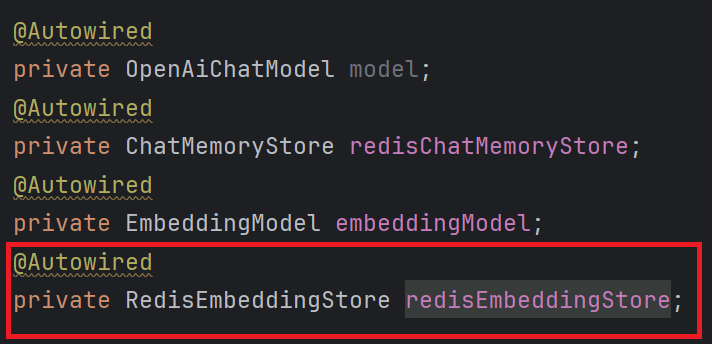
4. 注入RedisEmbeddingStore并使用
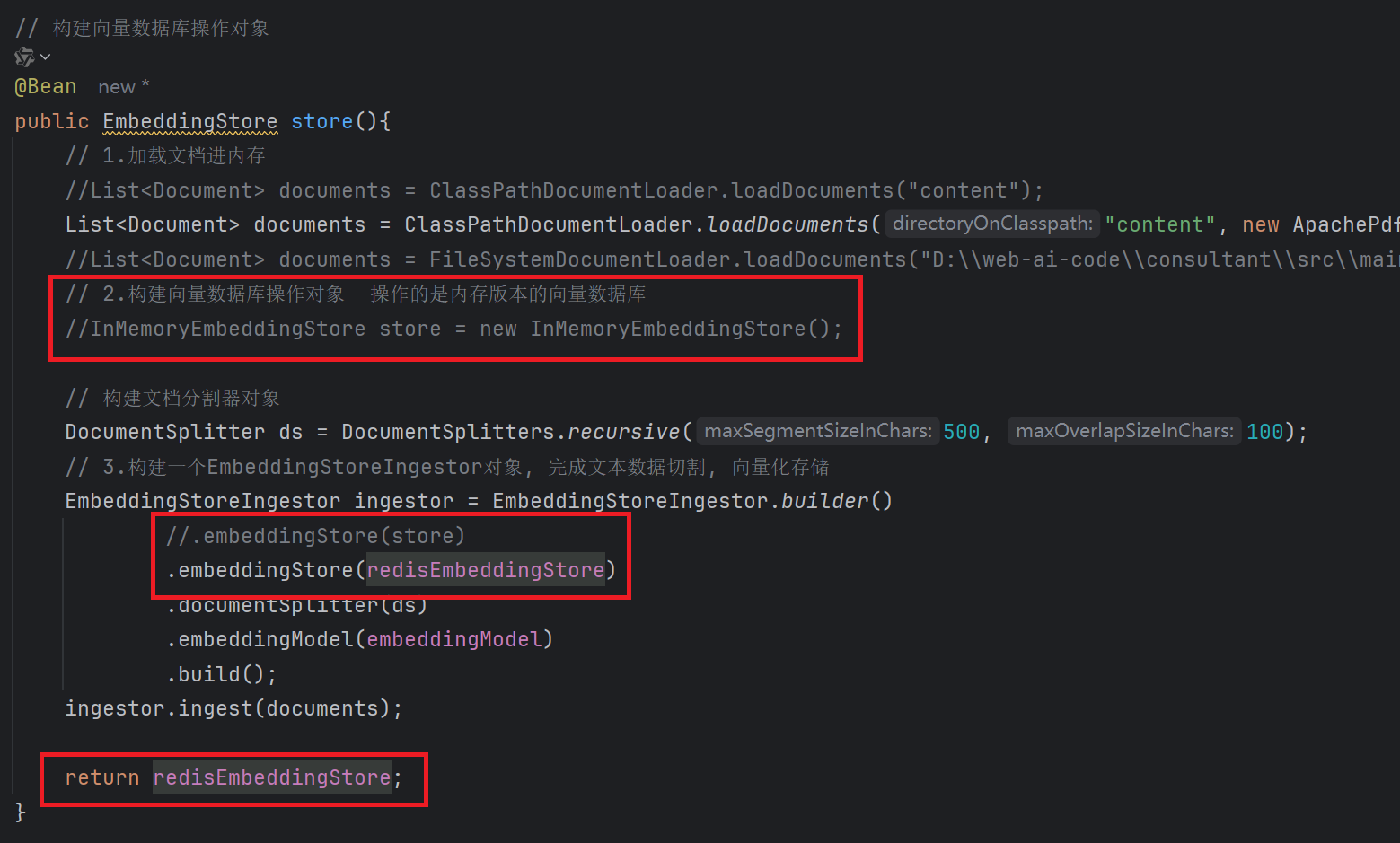
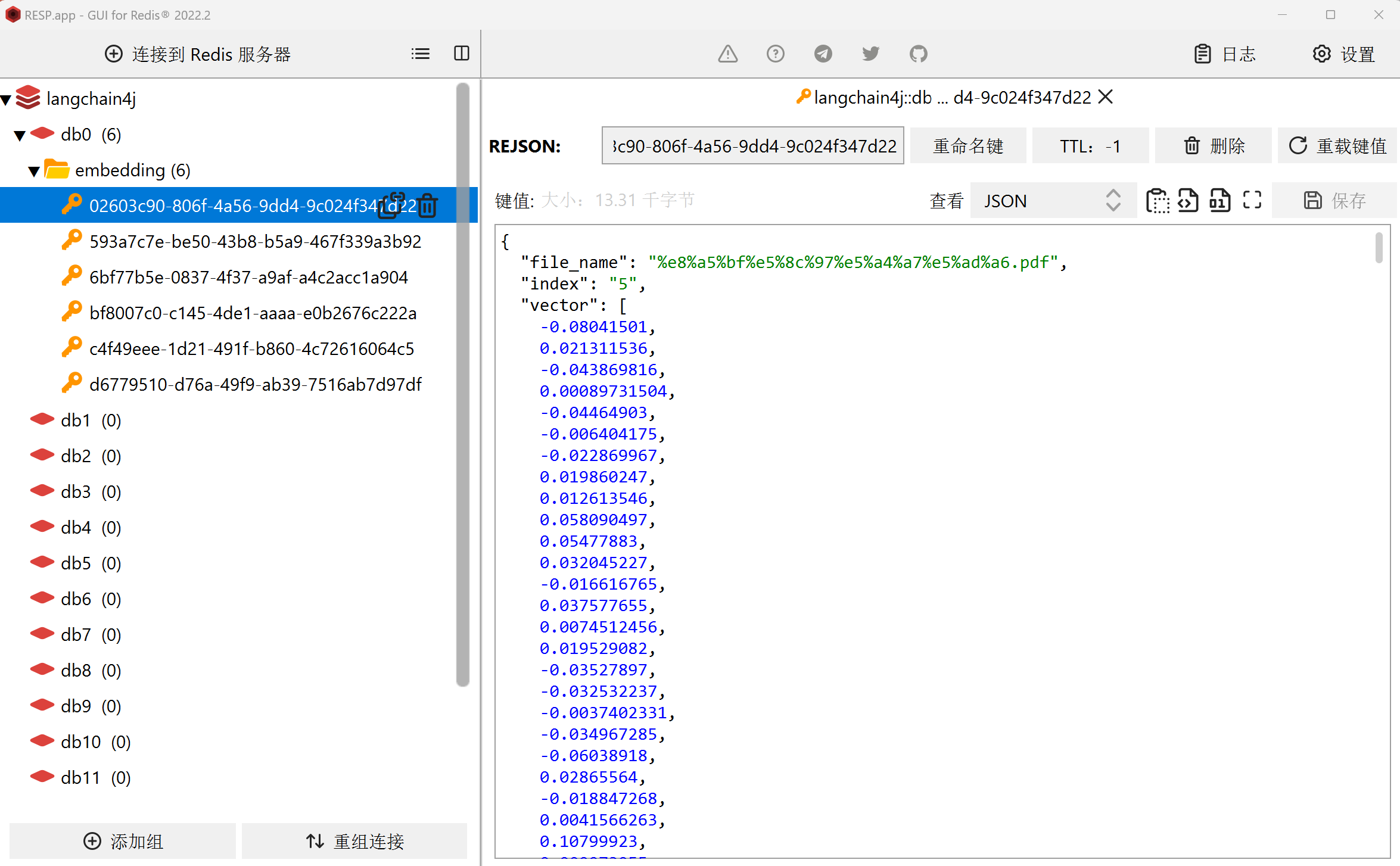
redis向量数据库里已经正确存储了文档向量化后的数据:
接下来把所有文档都放到IDE里面, 启动后报错
![]()
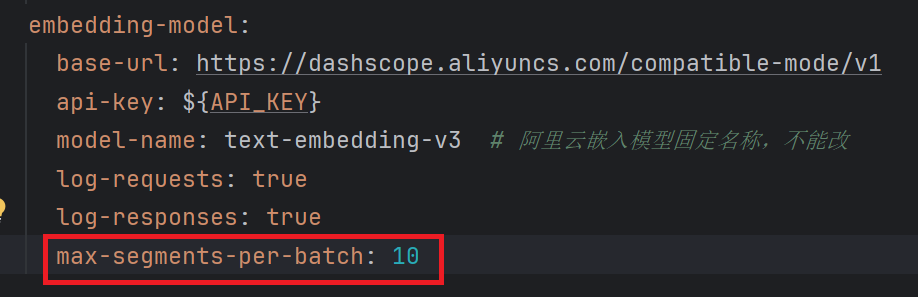
text-embedding-v3最大处理片段只能是10, 但是langchain4j会把分割好的片段一次性发送给大模型去处理
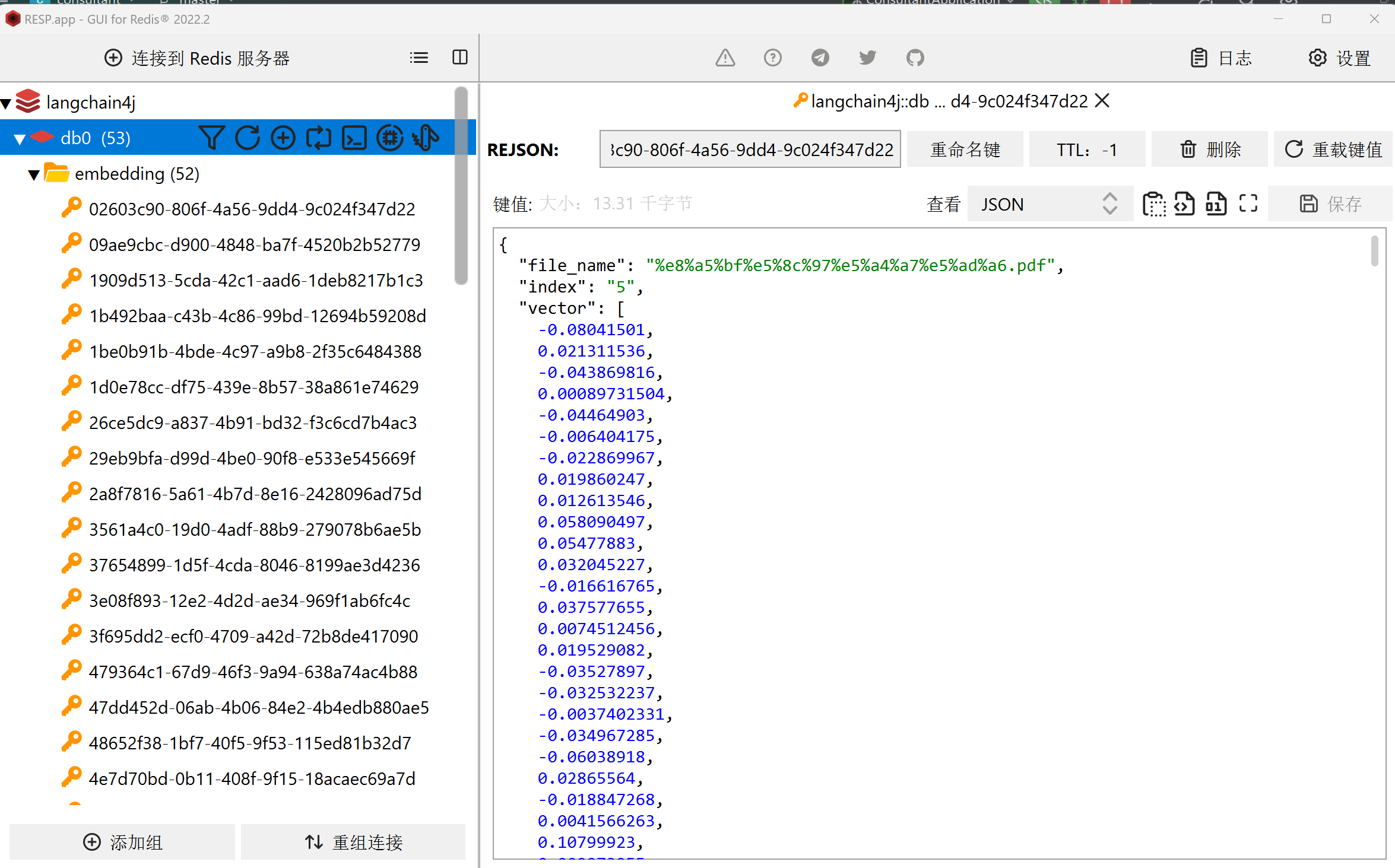
既然已经把数据存在了向量数据库里面, 我们就可以不用每次启动都执行这段代码了, 看日志, 也没有大段的向量数据了
Tools工具 (以前也叫 Function Calling)
准备工作
开发一个预约信息服务, 可以读写MySQL中预约表中的信息
1. 准备数据库环境
视频里老师还是采用docker上面装MySQL, 我自己的话直接在本地3306端口运行了
2. 引入依赖
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.4</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
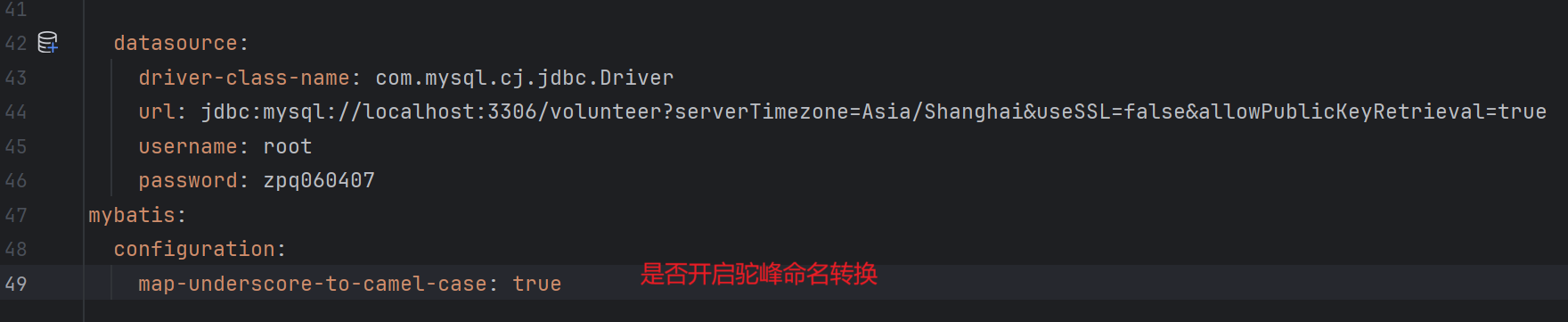
</dependency>3. 配置连接信息
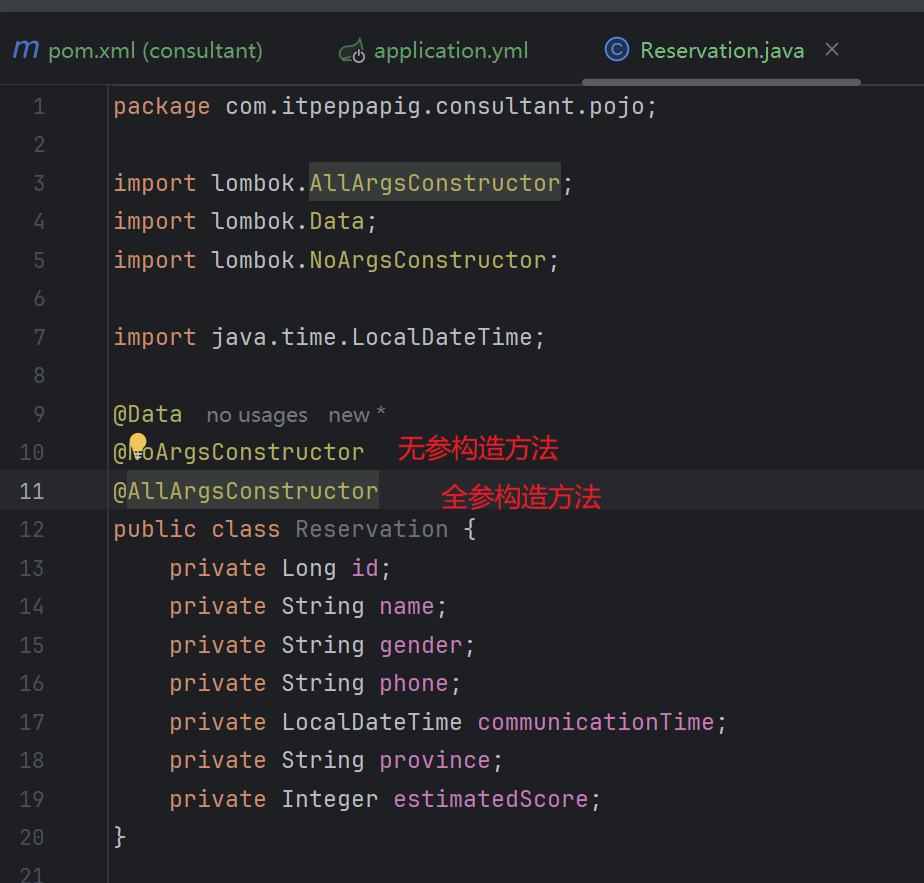
4. 准备实体类
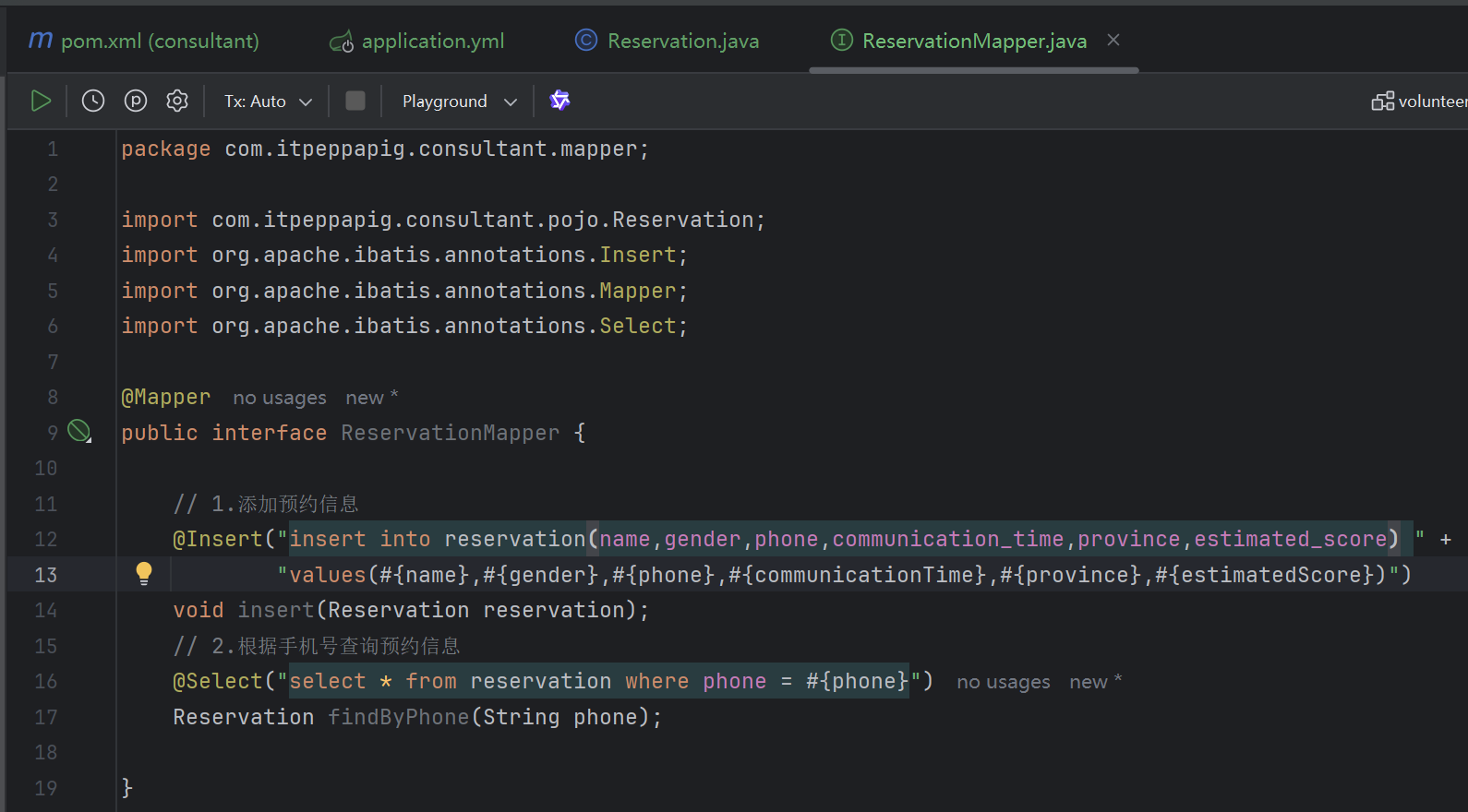
5. 开发Mapper
6. 开发Service
service层一般都是创建接口, 再提供接口的实现类, 由于代码太简单, 直接写类
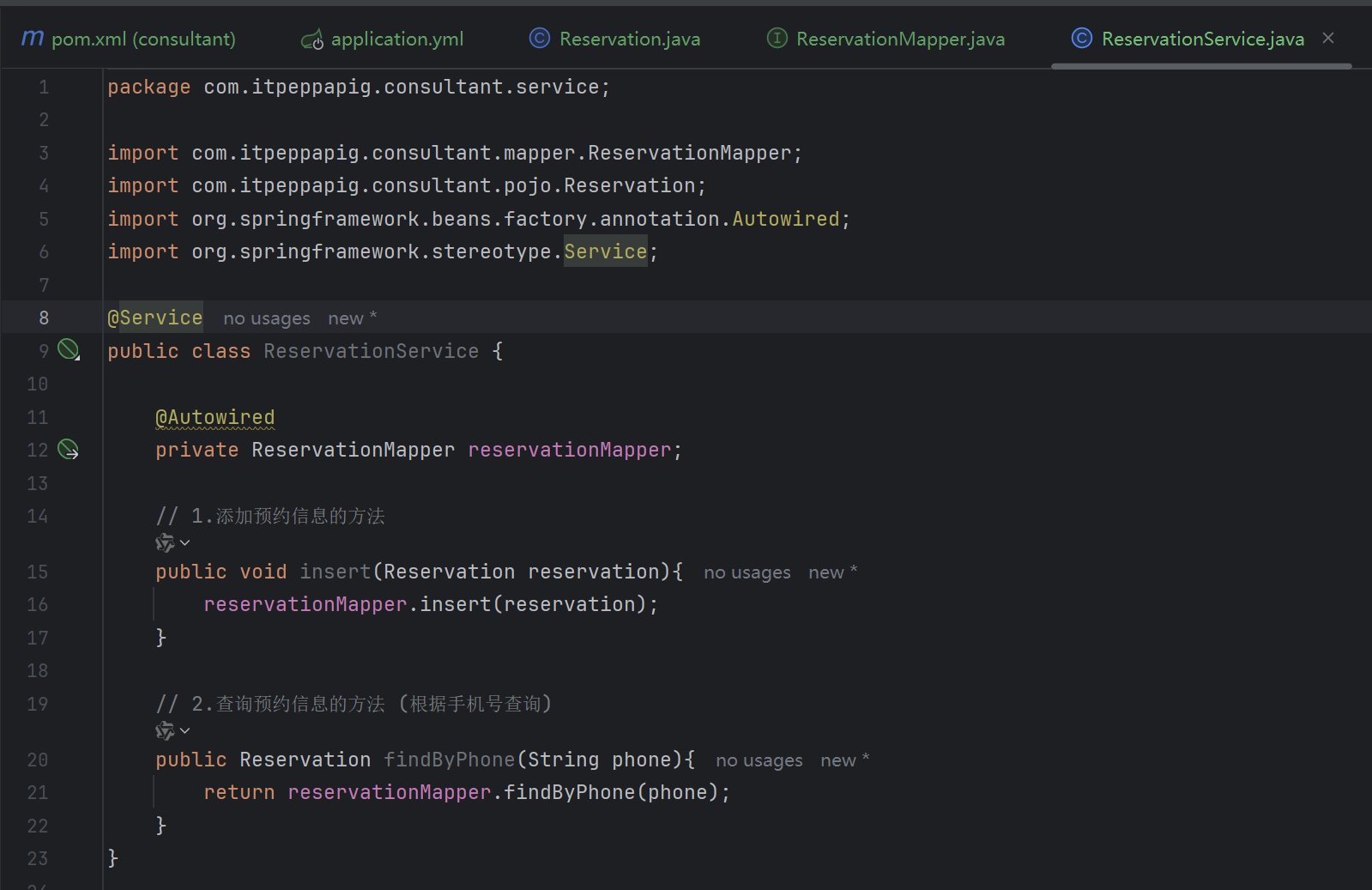
7. 完成测试
测试添加功能
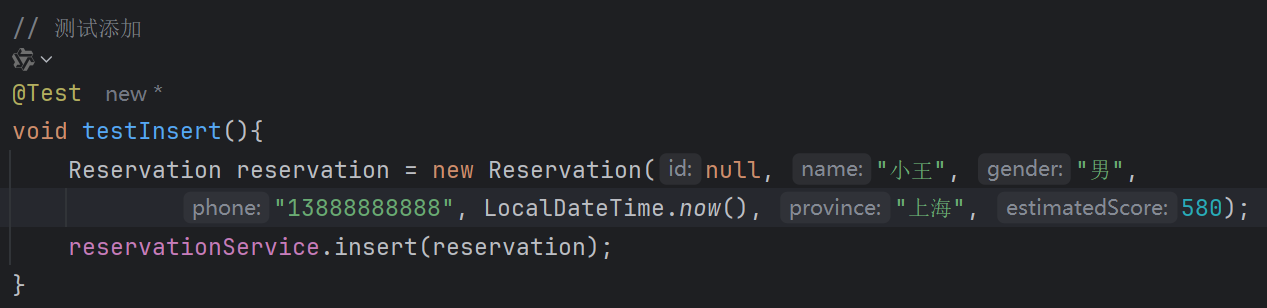

测试查询功能
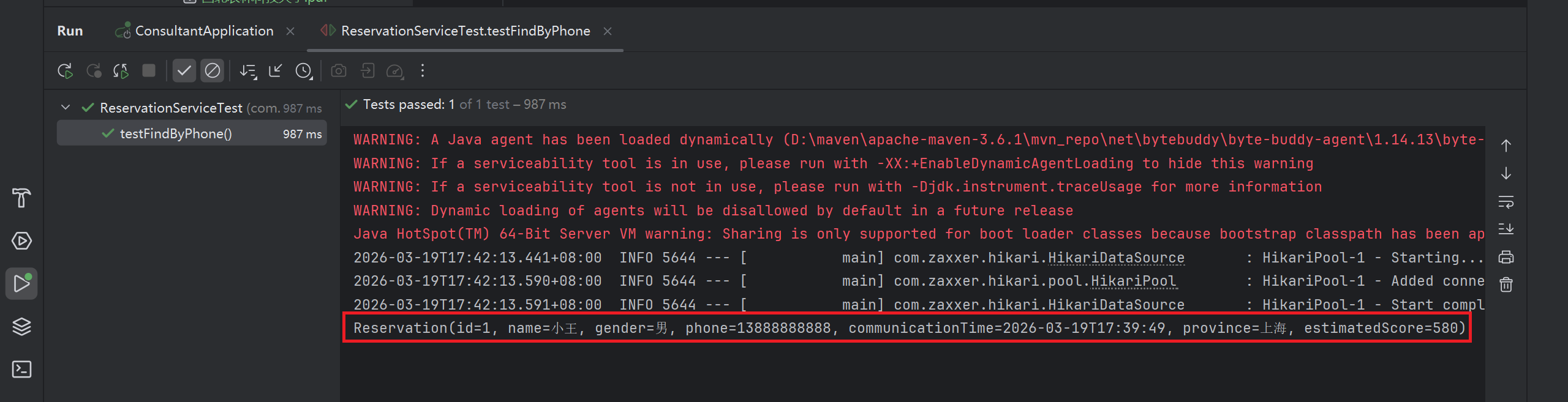
整体测试类代码:
@SpringBootTest
public class ReservationServiceTest {
@Autowired
private ReservationService reservationService;
// 测试添加
@Test
void testInsert(){
Reservation reservation = new Reservation(null, "小王", "男",
"13888888888", LocalDateTime.now(), "上海", 580);
reservationService.insert(reservation);
}
// 测试查询
@Test
void testFindByPhone(){
String phone = "13888888888";
Reservation reservation = reservationService.findByPhone(phone);
System.out.println(reservation);
}
}原理和实现
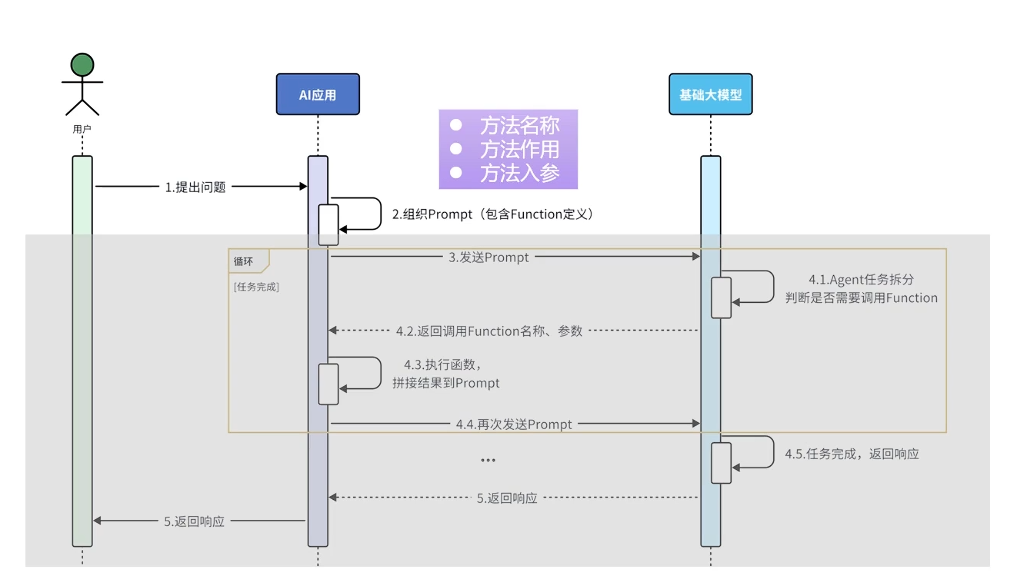
这是Function Calling的基本实现流程, 下面灰色的部分LangChainj已经帮我们封装好了, 下面学习如何实现
1. 准备工具方法
@Component
public class ReservationTool {
@Autowired
private ReservationService reservationService;
// 1.工具方法: 添加预约信息
// 告诉大模型方法的作用是什么, 描述方法的作用是什么
@Tool("预约志愿填报服务")
public void addReservation(
// 大模型不知道我们输入的参数是什么, 所以需要使用批注解
@P("考生姓名") String name,
@P("考生性别") String gender,
@P("考生手机号") String phone,
@P("预约沟通时间,格式为: yyyy-MM-dd'T'HH:mm") String communicationTime,
@P("考生所在省份") String province,
@P("考生预估分数") Integer estimatedScore
){
Reservation reservation = new Reservation(null, name, gender, phone, LocalDateTime.parse(communicationTime), province, estimatedScore);
reservationService.insert(reservation);
}
// 2.工具方法: 查询预约信息
@Tool("根据考生手机号查询预约单")
public Reservation findReservation(@P("考生手机号") String phone){
return reservationService.findByPhone(phone);
}
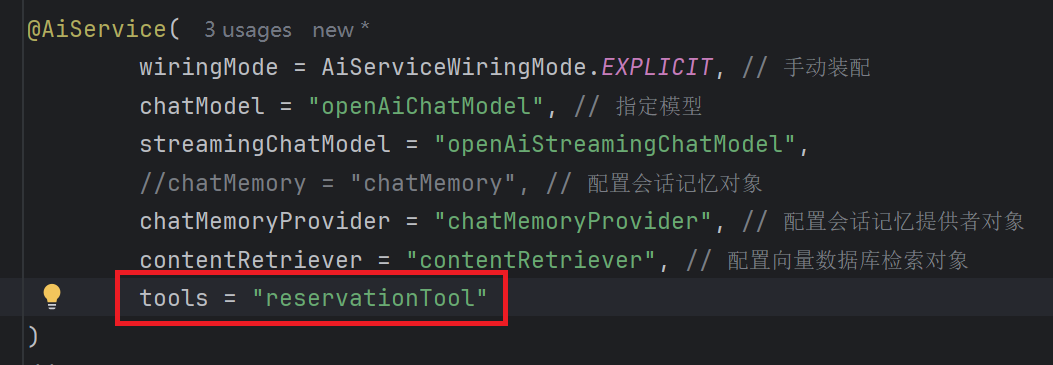
}2. 配置工具方法
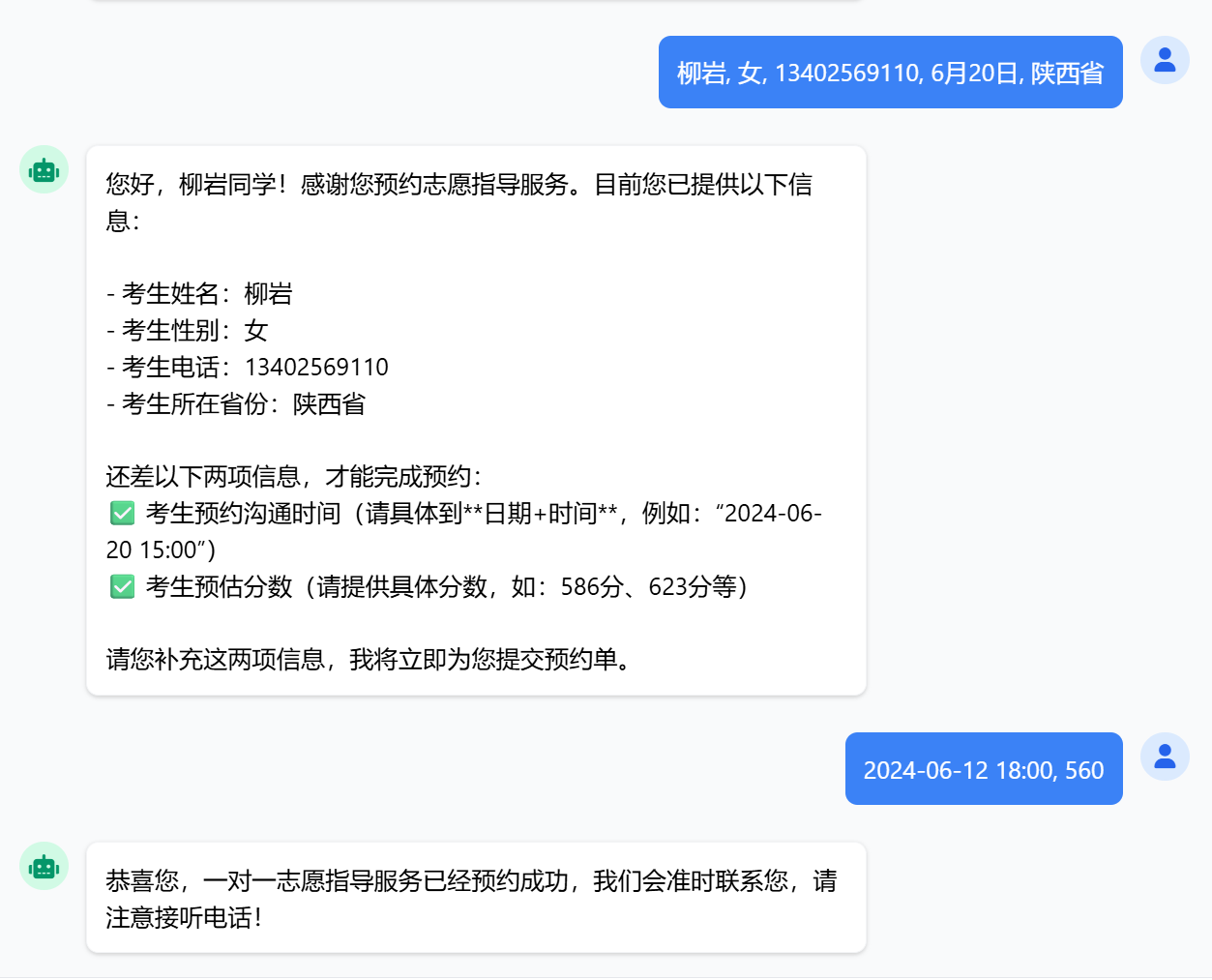

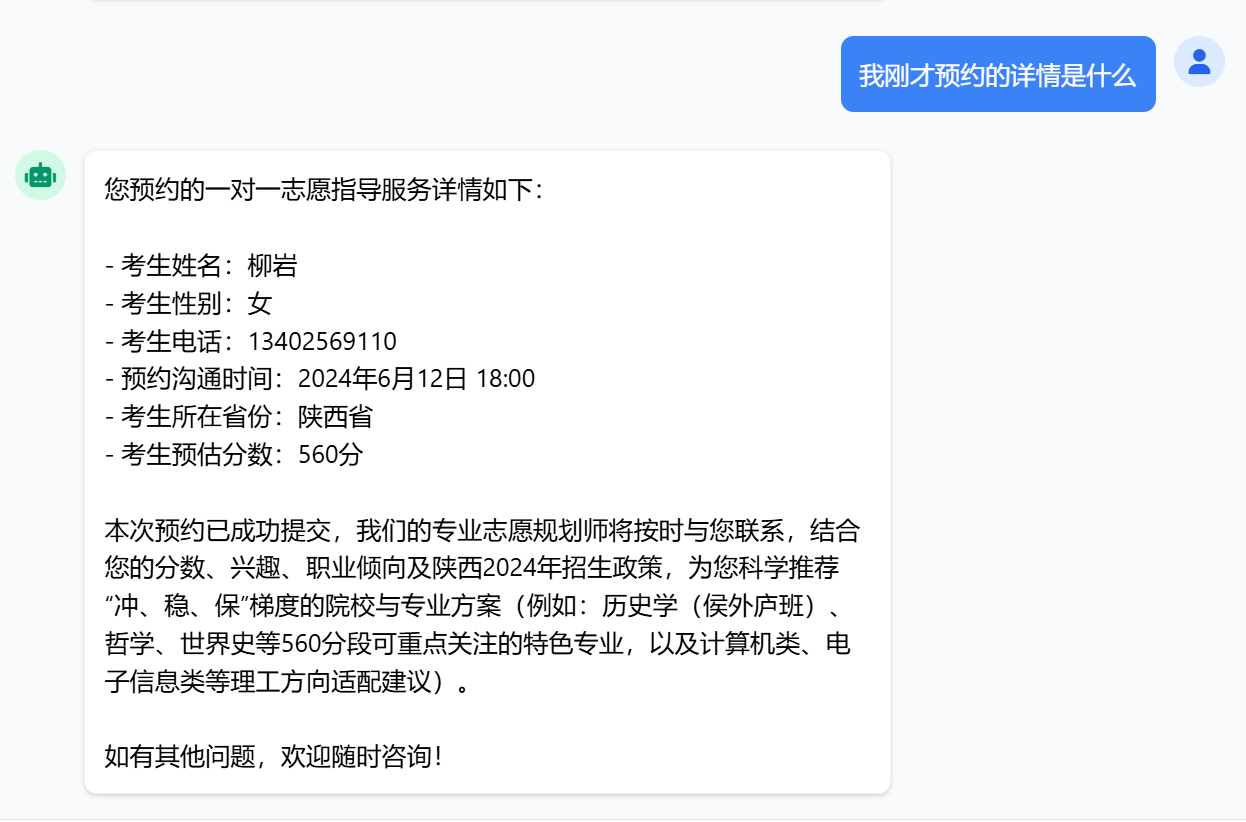
已成功添加至数据库
完结撒花
课程内容

希望看到这里的同学都可以找到心仪的工作, 我们江湖再见 !

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)