PCIe的串行传输模型:MindSharePCIe3.0-2 PCIe 体系结构概述- 2.1 PCI Express 简介-2.1.2 串行传输 (Serial Transport)
2.1.2 串行传输 (Serial Transport)
2.1.2.1 对传输速率的需求 (The need for Speed)
显然,串行传输模型必须比并行设计运行得快得多,才能实现相同的带宽。这是因为串行传输每次仅发送 1 比特数据。然而,事实证明这并非难事,过去的 PCIe 在 2.5GT/s 和 5.0GT/s 速率下都能稳定运行。PCIe 之所以能够达到这样的速率,甚至高达 8GT/s,是因为串行传输模型克服了并行模型的缺陷。
解决问题。通过上一章对PCI历史的回顾,我们了解到,并行总线的性能受到一些问题的制约,图2 - 3展示了其中的三个问题。
首先,回顾一下,并行总线采用公共时钟;信号在一个时钟沿输出,然后在下一个时钟沿被接收方接收。这个模型的首个问题源于信号从发送端传输到接收端所耗费的时间,即渡越时间。渡越时间必须小于一个时钟周期,否则就会出现问题,这导致难以通过持续减小时钟周期来提高速度。因为若要继续减小时钟周期,为使信号渡越时间仍小于时钟周期,就需要更短的布线并减少负载设备的数量,但最终这种做法都会达到极限,且越来越不切实际。
第二个导致并行模型性能受限的因素是,使用公共时钟时,时钟到达发送方和接收方的时刻不一致,这被称为时钟偏斜。电路板设计人员会尽力减小时钟偏斜的值,因为时钟偏斜会降低信号传输时序预算,然而这种偏斜永远无法完全消除。
第三个因素是信号偏斜,它指的是多比特位宽数据的各个位到达接收端的时刻存在差异。显然,这样的多位宽数据在所有比特都到达且稳定之前,接收方都不能对其进行采样,这就使得我们必须等待最慢的那一比特。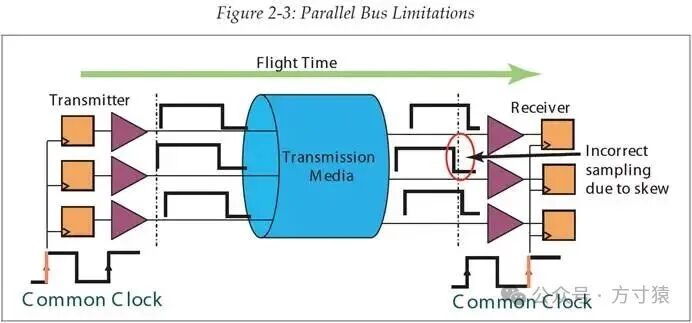 图2‑3 并行总线的局限
图2‑3 并行总线的局限
PCIe 这种串行传输方式是如何处理这些问题的呢?首先,信号渡越时间将不再是问题,因为用于指示接收端锁存数据的时钟现已被嵌入数据流中,无需额外的传输线来传输参考时钟。所以,无论时钟周期多么小,或是信号传输时间多么长,都不会出现以往的问题,这是由于内置在数据流中的时钟必定能与数据一同到达接收方。
同样地,时钟偏斜问题也将不复存在,这同样是因为时钟被嵌入数据流中。接收方通过恢复数据流中的时钟来进行数据采样,自然就不存在时钟偏斜的问题。
最后,信号偏斜问题在单个通道内得以消除,因为一个通道一次仅传输 1 比特数据。在多通道设计中,尽管信号偏斜问题再次出现,但接收端会自动对其进行纠正,能够在很大程度上补偿偏斜。
虽然串行设计克服了并行模型的诸多问题,但串行设计自身也存在一系列复杂问题。不过,我们稍后会发现,解决这些问题的方法易于掌控,且能让我们实现高速、可靠的通信。
带宽方面,PCIe 所支持的高速、多通道链路,带来了令人瞩目的带宽数值,具体如表 2 - 1 所示。这些数值的计算均源于比特率和总线特性。其中一种特性与诸多串行传输方法类似,即在 PCIe 的前两代版本中采用了名为 8b/10b 的编码过程,该编码过程会依据 8 比特的输入生成 10 比特的输出。尽管这会产生一定开销,但后续我们会提到有几个充分的理由支持这样做。就目前而言,只需了解对于 8b/10b 编码,发送 1 字节的数据实际需传送 10 比特。
第一代 PCIe(即 Gen1 或 PCIe 协议规范版本 1.x)中,比特率为 2.5GT/s,将其除以 10 便能得知一个通道的速率可达 0.25GB/s。由于链路能够同时进行发送和接收,因此聚合带宽可达到该数值的两倍,即每个通道达到 0.5GB/s。
第二代 PCIe(即 Gen2 或 PCIe 2.x)将总线频率翻倍,这也使其带宽相较于 Gen1 实现了翻倍。
第三代 PCIe(即 Gen3 或 PCIe 3.0)再次使带宽翻倍,但此次协议制定者并未选择将频率翻倍。相反,出于某些原因(我们稍后会讨论),他们仅将频率提升至 8GT/s(Gen2 中为 5GT/s,未翻倍),且不再采用 8b/10b 编码方式,而是采用了另一种编码机制,即 128b/130b 编码(关于此内容的更多信息,可阅读“物理层 - 逻辑(Gen 3)”章节)。表 2 - 1 列出了当前几代 PCIe 在不同通道数量情况下的带宽,展示了相应链路的峰值吞吐量。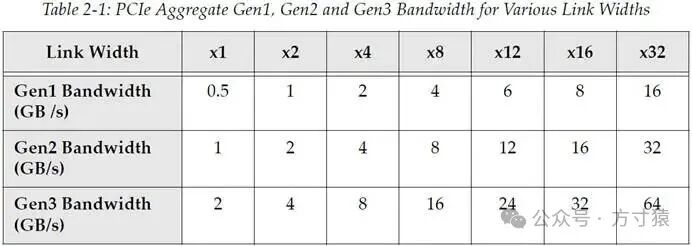 表 2‑1 PCIe Gen1,Gen2,Gen3 的各种链路宽度下的带宽汇总
表 2‑1 PCIe Gen1,Gen2,Gen3 的各种链路宽度下的带宽汇总
2.1.2.2 PCIe 带宽计算方法 (PCIe Bandwidth Calculation)
要计算上述表格中的 PCIe 带宽大小,可以参照如下的计算方法。·Gen1 PCIe 带宽 =(2.5Gb/s x 2 directions)/ 10bits per symbol = 0.5GB/s·Gen2 PCIe 带宽 =(5.0Gb/s x 2 directions)/ 10bits per symbol = 1.0GB/s需要留意的是,在上述计算中,我们除以的是 10bits 而非 8bits。这是由于 Gen1 和 Gen2 的协议规定,需将字节进行 8b/10b 编码后再进行数据包的传输。所以,原数据中的 1 字节在实际传输时,实际上需要传输 10 比特。·Gen3 PCIe 带宽 =(8.0Gb/s x 2 directions)/ 8bits per byte = 2.0GB/s我们注意到,在 Gen3 速率的计算中,我们除以的是 8bits,而非 10bits。这是因为在 Gen3 里,不再采用 8b/10b 编码方式,而是使用 128b/130b 编码方式。这种编码方式每 128 位会引入 2 比特的开销,该开销极小,在计算时我们暂时可以忽略不计。
通过上述三种方法计算得出的带宽,只需再乘以链路宽度,就能得到整个多通道链路的链路带宽。
2.1.2.3 PCIe 的差分信号 (Differential Signals)
每个通道均采用差分信号进行传输。差分信号指的是,在每次传输一个信号时,会同时发送其正信号和负信号(D+ 和 D-,这两种信号振幅相同、相位相反),如图2‑4 所示。当然,这样做会使引脚数量增加一倍。不过,相较于单端信号,差分信号在高速传输方面具备两个显著优点,足以弥补其在引脚数量上的不足:它提升了噪声容限,并且降低了信号电压。
差分信号的接收端会接收这一对相位相反的信号,通过用正信号的电压减去其反相信号的电压,得出它们的差值,进而以此判定该比特的逻辑电平值。
差分传输设计本身具备抗噪声干扰的特性,因为它要求成对的差分信号必须位于每个设备相邻的引脚上,且它们的走线必须彼此极为靠近,以维持合适的传输线阻抗。因此,任何因素在对差分对中的一个信号产生影响时,都会以同等程度且相同方向影响到另一个信号。但接收端关注的是它们的差值,而这些噪声干扰并不会改变该差值。所以,大多数情况下,噪声对信号的影响不会导致接收端对比特值做出错误判别。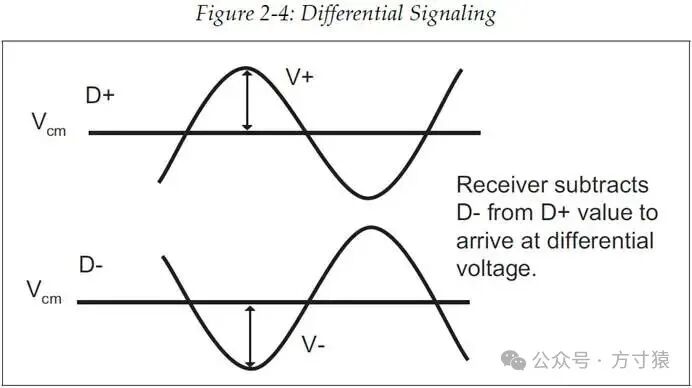 图2‑4 差分信号示意图
图2‑4 差分信号示意图
2.1.2.4 不再使用公共时钟 (No Common Clock)
在之前的内容中曾提及,PCIe 链路不再像 PCI 那样使用公共时钟,而是采用了源同步模型。这意味着发送端需要为接收端提供一个时钟,用于对输入数据进行锁存采样。对于 PCIe 链路而言,它并不包含输出时钟信号。相反,发送端会通过 8b/10b 编码将时钟嵌入数据流,随后接收端会从数据流中恢复该时钟,并用于锁存输入数据。这一过程听起来或许颇为神秘,实则十分简单。
在接收端,PLL 电路(即 Phase-Locked Loop 锁相环,如图 2 - 5)会将输入的比特流作为参考时钟,并将其时序或相位与一个输出时钟进行比较,这个输出时钟是 PLL 按照指定频率生成的。也就是说,PLL 自身会产生一个指定频率的输出时钟,然后将比特流作为参考时钟,与自身产生的输出时钟进行比较。
基于比较结果,PLL 会升高或降低输出时钟的频率,直至比较的双方达成匹配。此时,便可称 PLL 已锁定,且输出时钟(恢复时钟)的频率已精确匹配发送数据的时钟。PLL 会持续调整恢复时钟,迅速补偿修正温度、电压因素对发送端时钟频率造成的影响。
关于时钟恢复,有一点需要留意,PLL 需要输入端的信号跳变来进行相位比较。倘若在较长时间内数据都没有任何跳变,那么 PLL 恢复的时钟可能会偏离正确的时钟频率。为避免此类问题,8b/10b 编码的设计目标之一便是确保比特流中连续的 1 或 0 的数量不超过 5 个(若想了解更多关于这部分的内容,请参考“8b/10b 编码”一节)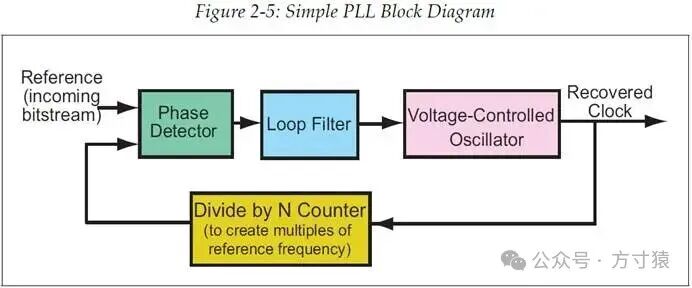 图2‑5 简单的锁相环图示
图2‑5 简单的锁相环图示
一旦时钟被恢复出来,便能够利用它来锁存输入数据流的比特,并将锁存的结果输送给解串器。有时,学生们或许会好奇,这个恢复时钟能否作为接收端所有逻辑的工作时钟,然而答案是否定的。原因之一在于,接收端不能期望用于恢复时钟的比特流参考时钟始终存在且处于活跃状态,因为链路的低功耗状态包含停止数据传输,此时自然无法继续恢复时钟。所以,接收端必须拥有自身本地生成的内部时钟。
2.1.2.5 基于数据包的协议体系 (Packet-based Protocol)
将并行传输转变为串行传输,能够极大地减少数据传输所需的引脚数量。和其他大多数串行传输协议一样,PCIe 通过消除绝大部分原本在并行总线中常用的边带控制信号,从而减少了引脚数量。然而,倘若没有控制信号来指示所接收信息的类型,接收端又如何知晓输入的比特代表什么信息呢?因此,在 PCIe 中,所有事务在发送时都采用已定义好的结构,即数据包(packets)。接收端需要找到数据包的边界,了解这个数据包所定义的结构是什么样的(也就是数据包的模板),然后解析数据包结构,以获知需要执行什么操作。
关于数据包协议体系的详细信息,将在“TLP 元素”这一章进行全面阐述,但在本章也能找到对各种包格式的介绍以及它们各自用途的概述,详见“数据链路层”一节。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)