PCIe的前生:PCI-X-MindSharePCIe3.0-1背景 - 1.5 PCI-X简介
1.5 PCI-X简介
PCI - X对PCI的软件和硬件均能实现向后兼容,同时,PCI - X还可提供更优的性能和更高的效率。它与PCI所采用的连接器相同,所以PCI - X与PCI的设备能够插入彼此的插槽。此外,二者还采用相同的配置模型,因此在PCI系统中能够使用的设备、操作系统以及应用程序,在PCI - X系统中依旧可以使用。
为了在不改变PCI信号传输模型的前提下实现更高的速率,PCI - X运用了几种技巧来优化总线时序。首先,它实现了PLL(锁相环)时钟发生器,借助其在内部提供相移时钟。这使得输出信号在相位上提前,而输入信号在相位上稍作延迟后进行采样,进而改善总线上的时序。同时,PCI - X的输入信号均在Target设备的输入引脚处被寄存(锁存),这样能使建立时间更短。通过这些方法节省下来的时间,能够有效增加信号在总线上传输的可用时间,并使总线能够进一步提升时钟频率。
1.5.1 PCI-X系统示例(PCI-X System Example)
如图 1‑15所示,这是一个基于Intel 7500服务器芯片组的系统平台。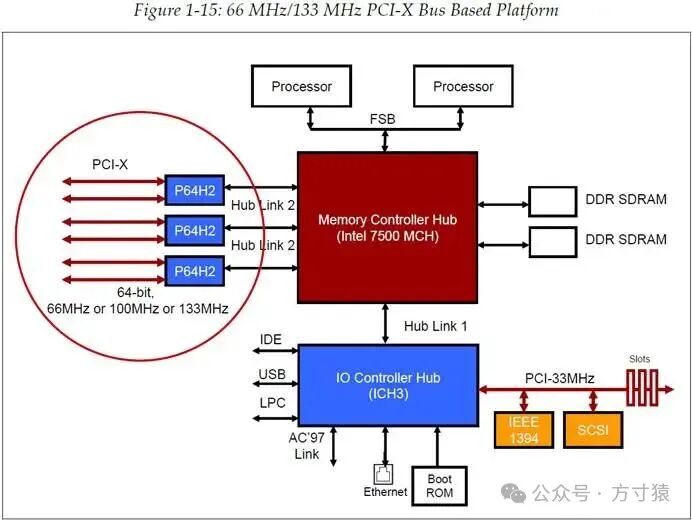 图 1‑15基于66MHz/33MHz PCI-X总线的平台
图 1‑15基于66MHz/33MHz PCI-X总线的平台
MCH(Memory Controller Hub)芯片提供了3个额外的高性能的Hub-Link 2.0端口,它们各与一个PCI-X 2 Bridge(P64H2)相连接。每个Bridge支持两条PCI - X总线,总线的最高时钟频率能够达到133MHz。Hub Link 2.0可支持PCI - X更高带宽的数据流。需要留意的是,在PCI - X上,我们仍面临着当初改进66MHz PCI时所遇到的相同负载问题。这意味着,若要支持更多设备,就需要借助Bridge来生成更多总线,而这会是一个成本相对较高的解决方案。不过,目前的带宽确实有了显著提升。
1.5.2 PCI-X事务(PCI-X Transactions)
如图 1‑16所示,这是一个PCI-X总线上Memory突发读取(burst memory read)事务。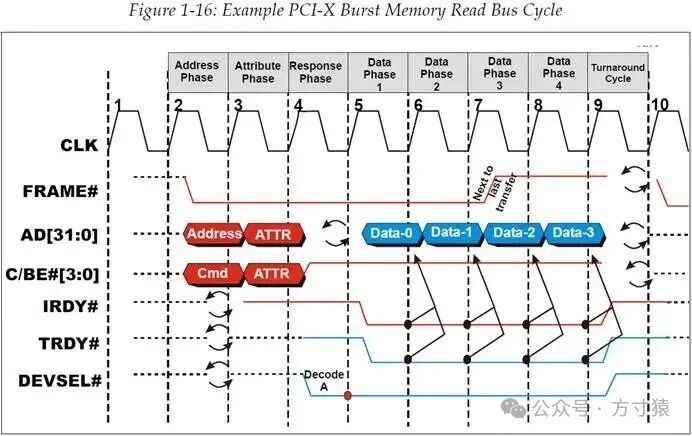 图 1‑16 PCI-X Memory突发读取的总线时序周期示例
图 1‑16 PCI-X Memory突发读取的总线时序周期示例
需要留意的是,PCI - X不允许在首个数据阶段(first data phase)之后插入等待状态。之所以如此,是因为在PCI - X里,会在事务的属性阶段(Attribute Phase)告知Target设备需要传输的数据总量。所以,与PCI不同,Target清楚自身需要传输的数据量。此外,多数PCI - X总线时序周期是连续的,这是由于采用了突发模式,而且数据通常以128Bytes为一个数据块(block)进行传输。这些特性不仅提升了总线利用率,还提高了设备buffer管理的效率。
1.5.3 PCI-X特性(PCI-X Features)
1.5.3.1 拆分事务模型(Split-Transaction Model)
在传统的PCI读事务里,总线主控器向总线上的某个设备发起读取操作。如前文所述,若目标设备尚未准备就绪,无法完成该事务,那么它既能够在获取数据时使总线维持等待状态,也可以发起重试以推迟该事务。
PCI-X则不同,它使用拆分事务的方法来处理这些情况,如图 1‑17所示。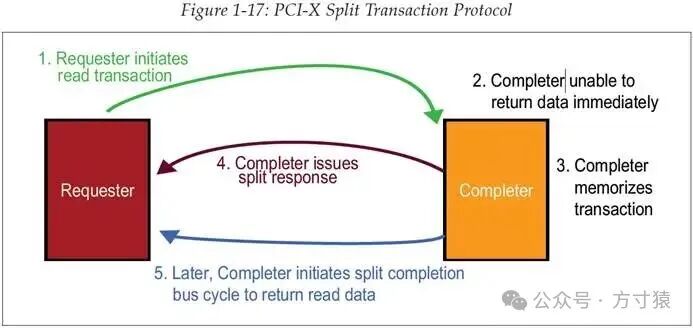 图 1‑17 PCI-X 拆分事务处理协议
图 1‑17 PCI-X 拆分事务处理协议
为便于描述并追踪每个设备正在执行的操作,我们现将例子中发起读取操作的一方称作Requester(请求方),将完成读取请求并提供数据的一方称作Completer(完成方)。若Completer无法立即对请求提供相应服务,它会存储该事务的相关信息(地址、事务类型、总数据量、Requester ID),并发出拆分响应信号。这告知Requester可将此事务暂时置于队列中,并结束当前的总线时序周期,释放总线使其回归空闲状态。
如此一来,在Completer等待所请求数据的期间,总线上能够执行其他事务。Requester在此期间也可自由开展其他工作,例如发起另一个请求,甚至向之前的那个Completer发起请求也没问题。
一旦Completer收集到所请求的数据,它将申请总线占用仲裁。获取总线使用权后,它会发起一个拆分完成(Split Completion)操作,返回此前Requester所请求的数据。Requester会响应并参与拆分完成该事务的总线时序周期,在此过程中接收来自Completer的数据。
对于系统而言,拆分完成事务实际上与写事务颇为相似。这种拆分事务模型(Split Transaction Model)的可行之处在于,在请求发起时便通过属性阶段(Attribute Phase)指明了总共需要传输的数据量,同时也让Completer知晓是哪一方发起了该请求(通过提供Requester自身的Bus:Device:Function号码),这使得Completer在发起拆分完成事务时能够精准找到目标。
对于上述整个数据传输过程而言,需通过两个总线事务来完成。不过,在读请求和拆分完成这两个事务之间的时间段内,总线能够执行其他任务。Requester无需反复轮询设备以检查数据是否准备就绪。Completer只需简单申请总线占用仲裁,待能够使用总线时,将被请求的数据返回给Requester即可。就总线利用率来说,这样的操作流程使事务模型更为高效。
截至目前,对PCI - X所进行的这些协议增强改进,让PCI - X的传输效率提升至约85%,而使用标准PCI协议时仅为50% - 60%。
1.5.3.2 MSI消息式中断(Message Signaled Interrupts)
PCI-X设备需支持MSI中断(Message Signaled Interrupts)。在传统中断体系结构中,常出现多个设备共享中断的情况,开发此功能旨在减少或消除这种需求。
若要产生一个MSI中断请求,设备需发起一个内存写事务,其操作地址为一段预先定义好的地址区域。在该地址区域内的一次写入操作会被视作一个中断,此信息将被传送给一个或多个CPU。写入的数据即为发起中断的设备的中断向量,该中断向量在系统中是唯一的,仅指向这一个设备。
对CPU而言,拥有中断号后便可迅速跳转至对应设备的中断服务程序,如此便能避免额外开销去查找是哪个设备发起的中断。此外,这种中断方式无需额外的中断引脚。
1.5.3.3 事务属性(Transaction Attributes)
最后,我们来介绍一下PCI - X在每个事务开始时新增的一个阶段,即属性阶段(如图1‑16所示)。在这段时间里,请求者(Requester)会将所发起事务的一些信息传递给完成者(Completer),这些信息包括请求的总数据量大小、请求者的身份(总线:设备:功能号码)。这些信息能够有效提升总线上事务的执行效率。
除此之外,还新引入了2位的信号来描述所发起的事务,分别是“无窥探(No Snoop)”位和“宽松排序(Relaxed Ordering)”位。
No Snoop(NS):一般而言,当一项事务需要将数据移入或移出内存(Memory)时,CPU内部的高速缓存(Cache)需要检查被操作的内存区域中是否存在已被拷贝到高速缓存里的部分。若存在,那么高速缓存在事务访问内存之前,需要将数据写回内存,或者将高速缓存内的数据按失效处理。当然,这个窥探内存内容是否出现在高速缓存中的过程会消耗一定时间,并且会增加该请求的延迟。在某些情况下,软件知晓某个请求的内存位置永远不会出现在高速缓存中(这可能是因为该位置被系统定义为不可缓存的),因此对于这些位置无需进行窥探,应跳过这一步骤。No Snoop位正是基于此原因而被引入。
Relaxed Ordering(RO):通常,当事务通过桥接器(Bridge)的缓冲区时,事务之间需要保持当初被放置到总线上的顺序。这被称为强排序模型(Strongly ordered model),PCI与PCI - X通常都会遵循此规则,个别情况除外。这是因为强排序模型能够解决相互关联的事务之间的依赖问题,例如对同一位置先进行写入再进行读取,按照强排序模型就能够使读取操作读取到写入后的正确数据,而非写入前的旧数据。然而实际上并非所有事务都存在依赖关系。如果有些事务不存在依赖关系,那么仍然强制它们保持原来的顺序会导致性能损失,这正是新添加这一属性比特位想要解决的问题。如果请求者(Requester)知道某个特定事务与此前的其他事务不相关联,那么就可以将该事务的这一位置设为有效,这样就能告知桥接器可以在队列中提前调度该事务执行,从而带来更优的性能。
1.5.4 更高带宽的PCI-X(Higher Bandwidth PCI-X)
1.5.4.1 PCI与PCI-X 1.0并行总线模型中由于公共时钟方法所带来的问题
当试图将PCI这类总线升级到更高速率时,一个问题愈发显著,即并行总线设计存在一些固有的先天局限性。图1 - 18有助于理解这一问题。这些设计通常采用公共时钟(common clock)或分布式时钟(distributed clock),其中,发送方在公共时钟的某一个时钟沿输出数据,随后接收方在公共时钟的下一个时钟沿锁存数据,也就是说,用于传输的时间预算长度为一个时钟周期。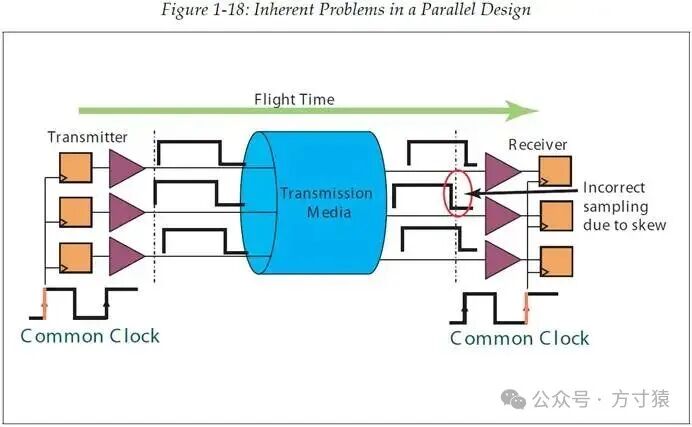 图 1‑18并行设计的固有问题
图 1‑18并行设计的固有问题
需要注意的第一个问题是信号歪斜(signal skew)。当数据的多个比特在同一时刻发出时,它们所经历的延时会存在细微差别,这导致它们到达接收方的时刻也会有细微差异。若因某些原因使这种差异过大,就会出现图中所示的信号采样错误问题。
第二个问题是多个设备间的时钟歪斜问题。公共时钟到达各个设备的时间点并非十分精确一致,这也会大幅压缩用于传输信号的时间预算长度。
最后,第三个问题与一个信号从发送方传输到接收方所需的时间有关,我们将这个时间称为渡越时间(flight time)。时钟周期或是传输时间预算必须大于信号渡越时间。为确保满足这一条件,PCB 硬件板级设计需让信号走线尽可能短,从而使信号传输时延小于时钟周期。然而,在许多电路板设计中,这种短信号走线的设计并不现实。
尽管存在这些自身局限,但为进一步提升性能,仍有几项技术可供使用。首先,可以简化现有的协议以提高效率。第二,可以将总线模型更改为源同步时钟模型(source synchronous clocking model),在这种时钟模型中,总线信号和时钟(strobe 选通脉冲)被驱动后将经历相同的传输延迟到达接收端(这里可对比一下 common clock 与其的区别)。这种方法被 PCI - X 2.0 所采用。
1.5.4.2 PCI-X 2.0源同步模型(PCI-X 2.0 Source-Synchronous Model)
PCI-X 2.0进一步提升了PCI-X的带宽。如同之前的升级一样,PCI-X 2.0依旧保持了对PCI软件和硬件的向后兼容性。为实现更高的速率,总线采用了源同步传输模型,以支持DDR(双倍数据速率)或QDR(四倍数据速率)。
“源同步”这一术语指的是,设备在传输数据时,还会提供一个与数据信号基本传输路径相同的额外信号。如图1 - 19所示,在PCI - X 2.0中,这个“额外”的信号被称作“strobe(脉冲选通)”,接收方利用它来锁存接收到的数据。发送方能够分配data与strobe信号之间的时序关系,只要data与strobe信号的传输路径长度相近,且其他影响传输延迟的条件也相近,那么当信号抵达接收方时,这种信号间的时序关系也不会改变。
这种特性可用于支持更高速率的传输,原因在于在源同步时钟模型中,接收方采样所用的strobe(类似于原来的时钟)同样由数据来源方发送,如此便避免了公共时钟到达各设备的延时不同所导致的时钟歪斜问题。因为如前文所述,此时data与strobe之间的时序关系基本保持不变,这样就把时钟歪斜的这段时间单独剔除,不再占用原本的传输时间预算。
此外,由于存在strobe信号随路指示接收方何时锁存采样数据,所以信号渡越时间不再成为问题。即便走线较长,接收方也能凭借伴随data的strobe信号正确采样数据,而无需纠结必须在下一个“时钟上升沿”进行采样,现在strobe何时指示就何时采样。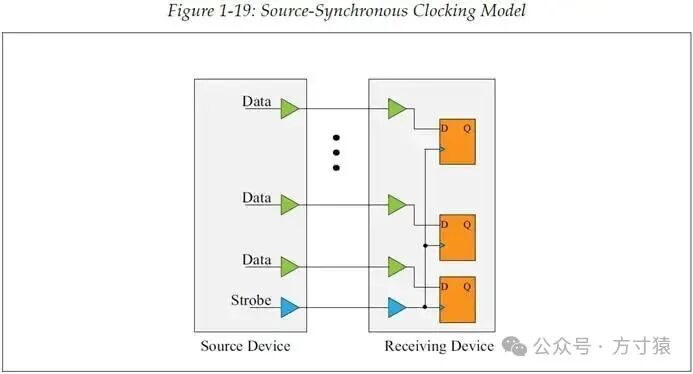 图 1‑19源同步时钟模型
图 1‑19源同步时钟模型
需要再次强调的是,这种超高速的信号时序致使共享总线模型无法被采用,它只能被设计成点对点的传输形式。因此,若要增加更多设备,就需要更多的Bridge来生成更多的总线。为实现这样的使用方式,可以设计一种设备,它具备3个PCI - X 2.0接口,其内部还有一个Bridge结构,以便让这三者能够相互通信。然而,这样的设备引脚数量会很多,成本也会更高,这使得PCI - X 2.0只能局限于高端市场,无法大面积普及。
由于协议制定者意识到PCI - X 2.0昂贵的解决方案仅能吸引更多高端开发者,而非普通开发者,所以PCI - X 2.0提供了更契合高端设计的技术标准,例如支持ECC的生成与校验。PCI - X的ECC比PCI中使用的奇偶校验更为复杂,鲁棒性(robust)也高得多,它能够动态自动纠正单bit错误,并对多bit错误进行可靠检测。这种改进后的错误处理方法虽然增加了成本,但对于高端平台而言,其所提升的可靠性才是更为重要的,因此即便增加了成本,这也是一个合理的选择。
尽管PCI - X 2.0提升了带宽、效率以及可靠性,但并行总线终究还是走到了尽头,需要一种新的模型来满足人们对更高带宽且更低成本的持续需求。最终被选中的新型总线模型采用的是串行接口,从物理层面来看,它与PCI是完全不同的总线,但在软件层面保留了对PCI的向后兼容性。
这个新模型,就是我们所熟知的PCI Express(PCIe)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)