PCI总线体系结构透视探究 MindSharePCIe3.0-1背景- - 1.4 PCI Bus Architecture Perspective
1.4 PCI总线体系结构透视探究(PCI Bus Architecture Perspective)
1.4.1 PCI事务模型
PCI与先前的总线模型相同,在数据传输方面采用三种模式:Programmed I/O(PIO)、Peer-to-peer以及DMA。这些模式的图示如图1‑6所示,接下来的几个小节将对其进行详细描述。
1.4.1.1 Programmed I/O(PIO)
PIO在早期个人计算机(PC)中得到广泛应用,原因在于设计者不愿增加设备因事务管理逻辑产生的成本开支,以及额外增加的复杂性。彼时,处理器的运行速度比其他任何设备都要快,所以在这一模型里,处理器承担了所有工作。
举例而言,当一个PCI设备向CPU发出中断信号,表明它需要向内存(memory)中写入数据时,最终由CPU将数据从PCI设备中读取出来,并放入一个内部寄存器,接着再将该内部寄存器中的值复制到内存里。反之,若数据要从内存传输到PCI设备,软件会指示CPU将内存中的数据读取到内部寄存器,然后再将内部寄存器的值写入PCI设备。
这样的操作流程虽具备可行性,但效率较为低下,主要有两个原因。其一,每次数据传输都需要CPU消耗两个总线周期。其二,在数据传输期间,CPU需专注于数据传输,无法执行其他更具价值的任务。在早期,这是最快的数据传输方式,并且单任务处理器也没有其他任务需要处理。
然而,这种低效的方式显然不适用于更为先进的系统,因此它已不再是数据传输的常用方式,取而代之的首选方法是下一节将要讲述的直接内存访问(DMA)方法。不过,为了实现软件与设备的交互,程序控制输入输出(Programmed IO)仍然是一种必要的事务模型。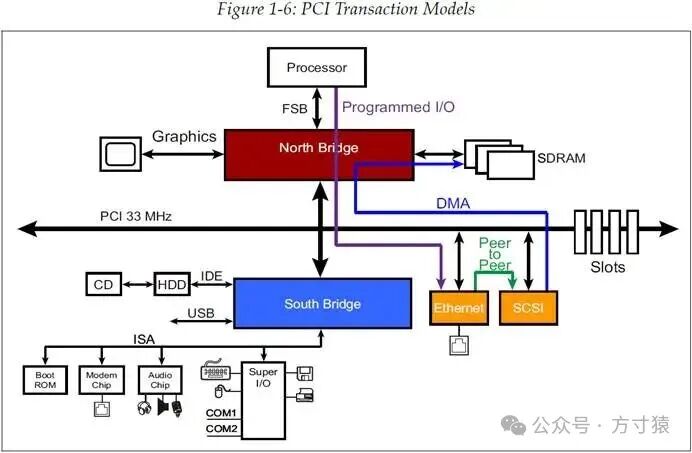 图 1‑6 PCI事务模型
图 1‑6 PCI事务模型
1.4.1.2 Direct Memory Access(DMA)
在数据传输方法方面,有一种更为高效的方式名为DMA(Direct Memory Access,直接内存访问)。在该模型中,存在另一种被称作DMA Engine的设备,由它代表处理器负责掌控从内存向外设进行数据传输的各类细致操作,这便将这项繁杂的任务从CPU中卸载下来。一旦CPU将起始地址(starting address)和数据字节总量(byte count)写入DMA Engine,DMA Engine便会自动处理总线协议与地址序列。这无需对PCI外设进行任何更改,还能使其保持低成本设计。
后来,经过集成性改良,外设自身能够集成这种DMA功能,如此一来,它们便不再需要外部的DMA Engine。这些具备处理自身发起的总线传输能力的设备,被我们称作总线主设备(Bus Master device)。
图1 - 3展示的是PCI总线上的总线主设备正在进行事务的过程。北桥能够对地址进行译码,以此识别自身是否为该事务的目标(Target)。例如,北桥译码后若发现地址与自身匹配,便会认定自己是该事务的目标。在总线周期的数据传输阶段,数据在总线主设备与北桥之间传输,此时北桥即为数据传输的目标。北桥随后会依据请求的事务内容,发起DRAM读写操作,与系统内存进行数据通信。数据传输完成后,PCI外设能够产生一个中断以通知系统。
DMA提高了数据传输效率,因为这种方式在搬运数据时无需CPU参与。对CPU而言,仅需一个总线周期的开销,将起始地址和总数据量写入DMA Engine,便可完成高效的数据块搬移(move a block of data)。
1.4.1.3 Peer-to-Peer(点对点)
如果一个设备具备作为总线主设备的能力,那么它便发挥着一种有趣的作用。一个PCI总线主控设备能够发起针对其他PCI设备的数据传输,而对于PCI总线本身而言,整个事务都是在本地进行的,并未引入任何其他系统资源。由于这个事务是在总线上的两个设备之间开展的,且这两个设备被视为总线中两个对等的节点,所以这个事务被称作一个“点对点”的事务。显然,这种事务极为高效,因为系统的其余部分仍可自由地完成其他任务。然而,在实际场景中,点对点事务很少被运用,这是因为发起方和目标方通常不会采用相同的数据格式,除非二者均由同一家供应商制造。因此,数据一般必须先发送到内存,在那里由CPU在数据传输至目标方之前对其进行格式转换,而这就阻碍并违背了点对点传输的设计目标。
1.4.2 PCI总线仲裁
由图 1 - 2 可知,如今的 PCI 设备基本都能够作为总线主设备(Bus Master device),所以它们均可以进行 DMA 与 peer - to - peer 的数据传输。在如 PCI 这类共享总线的体系结构中,各个设备需轮流占用总线。因此,当一个设备想要发起事务时,必须先向总线仲裁器请求总线所有权(ownership)。仲裁器会查看当前所有的请求,并运用一些特定的仲裁实现算法来确定哪个主设备(Master)可以下一个占用总线。PCI 协议规范并未描述该仲裁算法,但声明了此仲裁必须是“公平”的,在访问过程中不得对任何一个设备有差别对待。
仲裁器可以在上一个占用总线的主设备(Master)仍在进行数据传输时,就确定出下一个占用总线的设备,如此一来,总线上便无需引入额外的时延来对下一个总线所有者进行排序。所以,总线仲裁器的仲裁作用在“幕后”发挥,被称作“隐藏”的总线仲裁,这是对早期总线协议的一种改进。
1.4.3 PCI低效的地方(PCI Inefficiencies)
1.4.3.1 PCI重试协议(PCI Retry Protocol)
当一个PCI主控发起一项事务,以访问目标设备,而此时目标设备未处于就绪状态,那么目标设备会给出事务重试信号,这种场景的示意图如图1 - 7。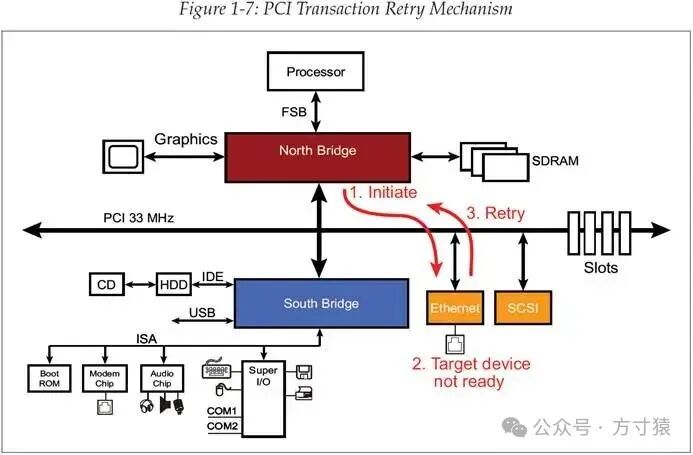 图 1‑7 PCI事务重试机制
图 1‑7 PCI事务重试机制
考虑接下来给出的例子:北桥发起一个读取内存事务,期望从以太网设备中读取数据。该以太网设备(Target)对这个事务作出响应,请求并参与到总线周期中。然而,此以太网设备(Target)并未立即将数据返回给北桥(Master)。此时,这个以太网设备有两种方法来推迟数据传输。
第一种方法是在数据传输中插入等待态(wait - state)。若仅需插入少量等待态,数据传输仍可保持较高效率。但如果Target设备需要延迟更长时间(从事务发起后延迟16个时钟周期以上),则需采用第二种方法。第二种方法是Target发出一个STOP#信号,表示事务重试(retry)。Retry操作是通知Master在数据未传输前提前结束总线周期,这样能防止总线长时间处于等待状态,从而避免降低总线效率。
当Master接收到Target发来的Retry请求后,至少等待2个时钟周期,然后必须重新向总线发起仲裁请求。再次获得总线使用权后,重新发起相同的总线周期。在当前总线Master处理Retry的这段时间内,仲裁器可将总线使用权授予其他Master,以便更高效地利用PCI总线。
当此前执行Retry的Master再次占用总线并重新启动相同的总线周期时,Target可能已准备好要传输的数据,并参与到总线周期中进行数据传输。若Target仍未准备好,它将再次发起Retry,如此循环,直至Master成功完成数据传输。
1.4.3.2 PCI断开连接协议(PCI Disconnect Protocol)
当一个PCI主控发起一个事务以访问一个目标设备,且该目标设备能够传输至少一个双字(doubleword,后文简称为dw)的数据,但无法完成整个数据量的传输时,它会在无法继续传输的时刻中断与事务操作的连接。这种场景的示意图如图1 - 8所示。
下面考虑给出的例子:北桥发起一个突发读内存事务(burst memory read),期望从以太网设备中读取数据。以太网目标设备响应了该请求并参与到这个总线周期中,传输了部分数据,但不久后已有的数据全部发送完毕,仍未达到主控所需的数据总量。此时,以太网目标设备有两种方式来延迟数据传输。
第一种方式是在数据传输阶段插入等待状态,同时自身也在等待接收新的数据。若只需插入少量等待状态,数据传输仍可保持较高效率。然而,若目标设备需要延迟更长时间(PCI协议规范允许在数据传输中途最多有8个时钟周期的等待状态,这与上一节Retry中的16个周期不同,因为Retry时传输尚未开始,而这8个周期是针对传输已经开始一段时间后的中途等待),目标设备必须发出断开连接的信号。要断开连接,目标设备需在总线周期运行时将STOP#置为有效,以此告知主控提前结束总线周期。
断开连接(Disconnect)与重试(Retry)的区别在于,断开连接已有数据被传输,而重试则是数据传输根本未开始。这种断开连接的操作也避免了总线长时间处于等待状态。主控至少等待2个时钟周期后,才能再次向总线发起仲裁请求,再次获得总线使用权后,便可再次访问刚才断开连接的设备地址,继续完成此前未完成的总线周期。
在当前总线主控正在经历断开连接的这段时间里,仲裁器可将总线使用权授予其他主控,以便更高效地利用PCI总线。当此前经历断开连接的主控再次占用总线并准备继续未完成的总线周期时,目标设备可能已准备好继续传输的数据,并参与到总线周期中继续完成数据传输。否则,若目标设备仍未准备好,它将再次发起重试或断开连接,如此循环,直至主控成功完成所有数据的传输。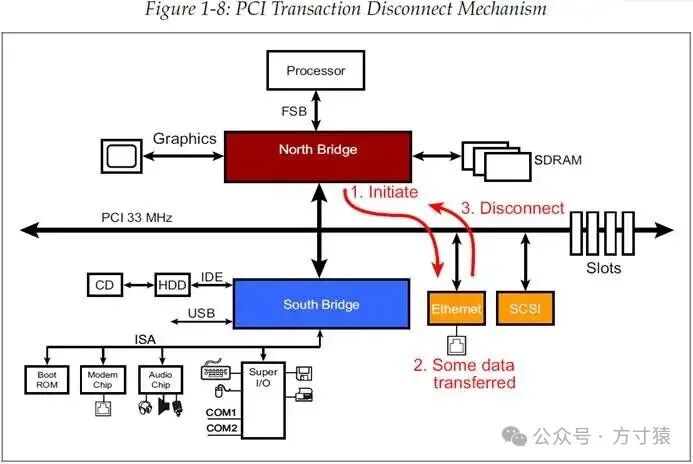 图 1‑8 PCI事务断开连接机制
图 1‑8 PCI事务断开连接机制
1.4.4 PCI中断处理(PCI Interrupt Handling)
PCI设备采用4个边带信号(sideband)作为中断信号,分别为INTA#、INTB#、INTC#、INTD#,并从中挑选一个向系统发送中断请求,也就是利用4个中断信号中的1个来发送中断请求。
当其中一个中断引脚被设为有效时,单CPU系统的中断控制器会对该中断作出响应,具体响应方式是将INTR(interrupt request)信号设为有效,进而将中断请求发送给CPU。
后来出现的多CPU系统不再适合采用单信号线输入作为中断的方式,因此进行了改进,将中断模式改为APIC(Advanced Programmable Interrupt Controller)模型。在这种模型下,中断控制器会向多CPU发送报文(message),而非向其中一个CPU发送INTR信号。
不过,无论采用何种中断传输模型,接收到中断的CPU都必须确认中断来源,然后为中断提供服务。传统模型需要多个总线周期来完成确认中断和服务中断的操作,效率较低。APIC模型虽优于传统模型,但仍有改进空间。
1.4.5 PCI错误处理(PCI Error Handling)
可选地,PCI设备能够在事务进行期间,检测并报告接收地址或数据信号中的奇偶校验错误。在事务进行过程中,PCI会对总线上的大部分信号进行奇偶校验,并通过PAR信号呈现计算得出的偶校验位结果。若传输的数据或地址信息里逻辑电平为1的比特数量为奇数,则将PAR信号置为1,从而使“电平1”的比特数量变为偶数。Target设备在接收到数据或地址时会进行校验以检查错误。奇偶校验(此处为偶校验)方法仅在有奇数个信号出错时才能被检测到。若设备检测到数据的奇偶校验错误,会将PERR#(奇偶错误)置为有效。这可能是一个可恢复的错误,例如在进行内存读取时,只需再次发起相同的事务即可解决问题。然而,PCI本身并不具备任何自动或基于硬件的错误恢复机制,因此软件需全权负责错误处理。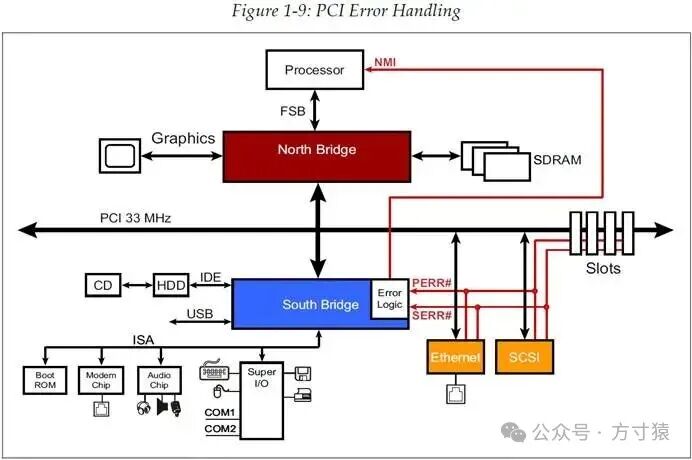 图 1‑9 PCI错误处理
图 1‑9 PCI错误处理
然而,上述提及的是数据出错的情形,若地址校验出现错误,则情况有所不同。在图 1 - 9 的示例中,地址信息遭到损坏,这使得一个目标(Target)匹配到了这个错误的地址。我们既无法知晓损坏后的地址信息变成了何种内容,也无法得知总线上哪个设备匹配到了这个错误的地址。所以,针对这种情况,并不存在能够简单实现错误恢复的方法。
因此,这类错误会致使 SERR#(系统错误,system error)被置为有效状态,之后系统通常会调用错误处理程序。在老式机器里,为避免引发更严重的错误,会强制让系统停止运行,进而导致“蓝屏死机”现象的出现。
1.4.6 PCI地址空间映射(PCI Address Map)
PCI体系结构支持三种地址空间,如图1 - 10所示,分别为:Memory(内存)、I/O、Configuration Address Space(配置地址空间)。x86处理器能够直接访问Memory和I/O空间。一个PCI设备映射到处理器内存地址空间时,可支持32位或64位寻址。在I/O地址空间中,PCI设备可支持32位寻址,但由于x86 CPU仅使用16位的I/O地址空间,因此许多平台会将I/O空间限制在64KB(对应16bit)。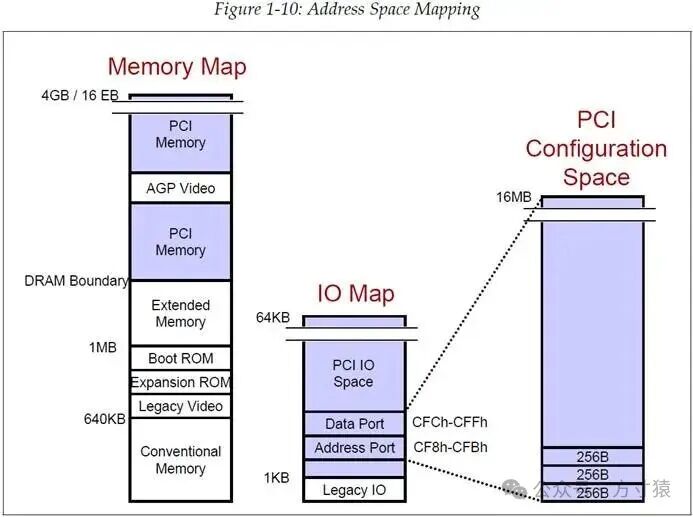 图 1‑10地址空间映射
图 1‑10地址空间映射
PCI还引入了第三种地址空间,名为配置空间,CPU仅能对其进行间接访问,无法直接访问。PCI设备中的每个功能(Function)都配备了专门用于配置空间的内部寄存器,这些寄存器对软件而言是可见的,并且软件能够通过标准化方式控制它们的地址和资源,这为PC营造了一个真正的即插即用(plug and play)环境。
每个PCI功能最多拥有256字节的配置地址空间。鉴于PCI最多可支持单个设备包含8个功能、每路总线包含32个设备、单个系统包含256路总线,那么一个系统的配置空间总量为:
256B/功能 * 8功能/设备 * 32设备/总线 * 256总线/系统 = 16MB
即一个系统的配置空间总大小为16MB。
由于x86 CPU无法直接访问配置空间,因此它必须借助IO寄存器进行索引(不过在PCI Express中,引入了一种新的访问配置空间的方法,该方法通过将配置空间映射到内存地址空间来实现)。
在传统模型里,如图1 - 10所示,采用了一种名为配置地址端口(Configuration Address Port)的IO端口,其地址位于CF8h - CFBh;同时还使用了一种名为配置数据端口(Configuration Data Port)的IO端口,其地址位于CFCh - CFFh。
有关通过这种方法以及内存映射方法访问配置空间的详细信息,将在下一节进行阐释。
1.4.7 PCI配置周期的生成(PCI Configuration Cycle Generation)
由于I/O地址空间的大小有限,传统模型在设计上对地址使用极为谨慎。在I/O空间里,常见的做法是利用一个寄存器指向一个内部位置,再用另一个寄存器进行数据的读取或写入。
PCI的配置过程包含以下两步:
第一步:CPU发起一次I/O写操作,写入位置为北桥中I/O地址为CF8h的地址端口(Address Port),以此给出需要配置的寄存器的地址,也就是“用一个寄存器指向一个内部位置”。如图1 - 11所示,这个地址主要由三部分构成,通过这三部分能够定位一个PCI Function在拓扑结构中的位置,分别是:在256条总线中要访问的总线、该总线上32个设备里要访问的设备、该设备的8个Function中要访问的Function。除此之外,唯一还需提供的信息是要确认访问这个Function的64dw(256Bytes)中的哪个dw。
第二步:CPU发起一次I/O读或I/O写操作,操作位置为北桥中地址为CFCh的数据端口(Data Port),即“用另一个寄存器进行数据的读取或写入”。在此基础上,北桥向PCI总线发起一个配置读事务(configuration read)或配置写事务(configuration write),事务要操作的地址就是步骤一中地址端口所指定的地址。 图 1‑11配置地址寄存器
图 1‑11配置地址寄存器
1.4.8 PCI Function配置寄存器空间(PCI Function Cfg Reg Space)
每个PCI Function最多可包含256字节的配置空间。该配置空间起始的64字节包含一个名为Header(配置空间头)的结构,剩余的192字节用于支持一些其他可选功能。
系统配置首先由Boot ROM固件执行,在操作系统加载完成后,它会重新对系统进行配置并重新分配资源。这意味着系统配置过程可能会执行两次。
根据Header的类型,PCI Function可分为两个基本类别。第一种Header称为Type 1 Header(类型1),其结构如图1 - 12所示,它用于标识该Function是一个Bridge,Bridge会在拓扑结构上创建另一条总线。而Type 0 Header(类型0)则用于指示该Function并非Bridge(如图1 - 13所示)。
关于Header类型的信息包含在dword3的字节2的同名字段中(Class Code字段)。当软件在系统中发现某个Function时,首要任务是检查其Header的这个字段(软件发现系统中Function的过程称为枚举enumeration)。
关于配置寄存器空间以及枚举过程的更详细讲解将稍后进行。在此,我们仅希望你先熟悉各个部分是如何协同工作的。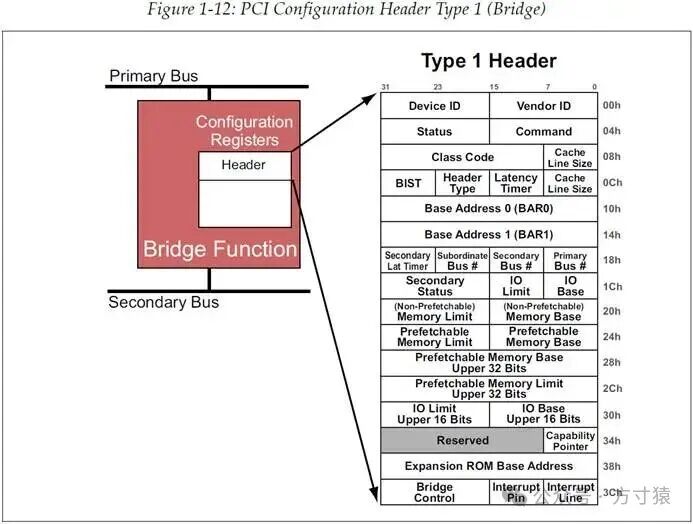 图 1‑12 PCI配置Header Type 1(Bridge)
图 1‑12 PCI配置Header Type 1(Bridge)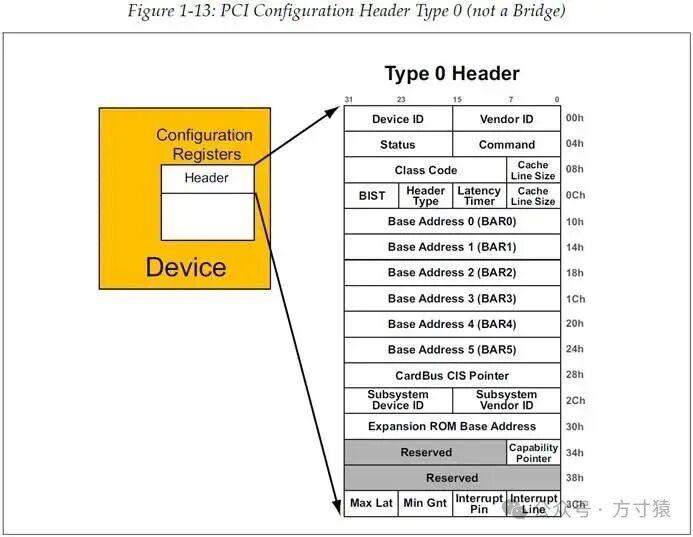 图 1‑13 PCI配置Header Type 0(非Bridge)
图 1‑13 PCI配置Header Type 0(非Bridge)
1.4.9 更高带宽的PCI(Higher-bandwidth PCI)
为支持更高带宽,PCI协议规范更新至支持更宽位宽(64bit)和更快时钟速率(66MHz)的版本,从而使其传输速率可达533MB/s。图1 - 14展示了一个采用66MHz 64bit PCI总线的系统。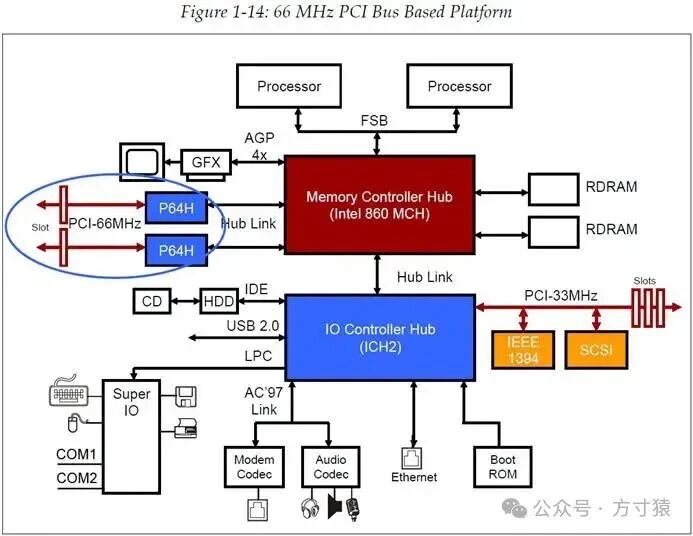 图 1‑14 基于66MHz PCI总线的平台
图 1‑14 基于66MHz PCI总线的平台
1.4.9.1 66MHz PCI总线的限制
66MHz总线的吞吐量相较于33MHz已实现翻倍,然而它存在一定问题。图1 - 14展示了其一个主要缺点:66MHz总线与33MHz总线采用相同的反射波开关模型,致使传输线上信号传输的可用时间减半,这将大幅降低总线的负载能力。最终导致的结果是,一条总线上仅能有一个插入板卡。增加更多设备意味着需要增设更多的PCI Bridge以生成更多总线,这会增加成本以及对PCB板材的要求。同时,64bit PCI总线相较于32bit增加了引脚数量,这也会提高系统成本并降低可靠性。综合上述情况,就不难看出为何这些因素限制了64bit或66MHz版本的PCI总线的广泛应用。
1.4.9.2 并行PCI总线模型在66MHz以上时出现的信号时序问题
鉴于PCI总线上的实际负载以及信号渡越时间(signal flight times),PCI总线的时钟频率无法在66MHz的基础上继续提升了。对于66MHz的时钟而言,其时钟周期为15ns,分配给接收器的建立时间(Setup time)为3ns。由于PCI采用“非寄存输入(non-registered input)”信号模型,要进一步缩短其3ns的建立时间并不现实。剩余的12ns时序预算(timing budget)则分配给了发送器的输出延迟以及信号传输时间。倘若在66MHz的基础上进一步提高频率,总线上传输的信号将因无法及时抵达接收端,无法在接收端被正确采样,进而导致传输失败。
在下一节中,我们将介绍PCI-X总线。该总线会先利用触发器对所有输入信号进行寄存处理,之后再加以使用。通过这种方式,能够将信号的建立时间缩短至1ns以下。对建立时间进行优化后,PCI-X总线能够运行在更高的频率,比如100MHz甚至133MHz。下一节我们将对PCI-X总线体系结构进行简要介绍。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)