RNN预测模型做多输入单输出预测模型,直接替换数据就可以用。 程序语言是matlab,需求最低...
RNN预测模型做多输入单输出预测模型,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。 PS:以下效果图为测试数据的效果图,主要目的是为了显示程序运行可以出的结果图,具体预测效果以个人的具体数据为准。 2.由于每个人的数据都是独一无二的,因此无法做到可以任何人的数据直接替换就可以得到自己满意的效果。 这段程序主要是一个基于循环神经网络(RNN)的预测模型。它的应用领域可以是时间序列预测、回归分析等。下面我将对程序的运行过程进行详细解释和分析。 首先,程序开始时清空环境变量、关闭图窗、清空变量和命令行。然后,通过xlsread函数导入数据,其中'数据的输入'和'数据的输出'是两个Excel文件的文件名。 接下来,程序对数据进行归一化处理。首先使用mapminmax函数将输入数据P_train和P_test归一化到0到1的范围内,并保存归一化的参数ps_input。然后,使用mapminmax函数将输出数据T_train和T_test归一化到0到1的范围内,并保存归一化的参数ps_output。 接着,程序将归一化后的数据转换为特定的格式。使用for循环将p_train和p_test转换为vp_train和vp_test,其中vp_train和vp_test是每个样本的列向量。这样做是为了适应RNN模型的输入格式。 然后,程序定义了一些基础参数。numFeatures表示特征维度,即特征变量的列数;numResponses表示输出维度,这里是1。 接下来,程序设计了一个RNN结构。该结构包含了输入层、GRU层、ReLU激活层、LSTM层、丢弃层、全连接层和回归层。其中,GRU层和LSTM层是循环神经网络的一种变体,用于处理序列数据。 然后,程序根据当前计算环境(GPU或CPU)设置网络参数。如果有GPU设备,则使用GPU进行训练,否则使用CPU。 接着,程序定义了训练选项。使用adam优化算法进行训练,最大训练次数为2000次,梯度阈值为1,初始学习率为0.01,学习率调整策略为piecewise,训练850次后开始调整学习率,学习率调整因子为0.25,最小批量大小为96,关闭训练过程中的详细输出,每个epoch后对数据进行洗牌,训练环境根据之前判断的设备类型进行设置,最后画出训练过程的曲线。 接下来,程序使用trainNetwork函数对vp_train和t_train进行训练,使用之前定义的网络结构和训练选项。 然后,程序使用训练好的网络对vp_train和vp_test进行预测,得到t_sim1和t_sim2。 接着,程序使用mapminmax函数将预测结果进行反归一化,得到T_sim1和T_sim2。 然后,程序计算均方根误差(RMSE),分别计算训练集和测试集的误差。误差的计算公式为每个样本的预测值与真实值之差的平方和除以样本数,再开平方。 接下来,程序计算R2值,用于评估预测模型的拟合程度。R2值的计算公式为1减去预测值与真实值之间的平方和与真实值与均值之间的平方和的比值。 然后,程序计算平均绝对误差(MAE),用于评估预测模型的预测精度。MAE的计算公式为预测值与真实值之差的绝对值之和除以样本数。 接着,程序绘制训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及RMSE、R2和MAE的值。 然后,程序绘制训练集和测试集的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 接下来,程序绘制所有样本的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 然后,程序打印出评价指标,包括RMSE、R2和MAE。 最后,程序绘制测试集的预测误差图,用于分析预测模型的误差情况。 总结来说,这段程序是一个基于循环神经网络的预测模型,用于时间序列预测或回归分析。它通过对输入数据进行归一化处理,设计了一个包含GRU和LSTM层的RNN结构,使用adam优化算法进行训练,并计算了预测结果的误差和评价指标。程序的主要思路是通过训练RNN模型来学习输入数据的模式,并预测输出数据。涉及到的知识点包括循环神经网络、归一化处理、优化算法等。希望这个解释对你有帮助!如果还有其他问题,请随时提问。
一、模型概述
本模型基于循环神经网络(RNN)构建,采用GRU(门控循环单元)与LSTM(长短期记忆网络)混合架构,实现多输入单输出的预测任务。模型支持GPU加速训练,具备数据自动归一化、多维度性能评估及可视化输出能力,用户仅需替换输入输出数据即可快速适配不同预测场景,适用于时间序列预测、多特征关联预测等领域。
二、核心功能模块
(一)环境初始化与数据准备模块
- 环境清理:自动关闭系统报警信息、清空当前工作区变量、关闭所有已打开的图窗及命令行窗口,避免历史数据与环境配置对模型训练产生干扰,确保每次运行均处于干净的计算环境。
- 数据导入:通过Excel文件分别读取输入特征数据(X)与输出目标数据(Y),支持任意维度的输入特征(需保证输入输出数据样本数量匹配)。
- 数据集划分:采用固定比例划分策略,将前150个样本划分为训练集,剩余样本作为测试集,同时对数据进行转置处理,满足模型输入格式要求。其中,训练集用于模型参数学习,测试集用于验证模型泛化能力,划分过程自动记录训练集(M)与测试集(N)样本数量,为后续误差计算提供基础。
(二)数据预处理模块
- 归一化处理:采用mapminmax函数将输入特征数据(Ptrain、Ptest)与输出目标数据(Ttrain、Ttest)归一化到[0,1]区间。该操作可消除不同特征维度量级差异对模型训练的影响,避免因特征数值范围过大导致的梯度爆炸或训练收敛缓慢问题。
- 格式转换:将归一化后的训练集与测试集数据转换为模型可识别的序列数据格式,通过循环遍历将每个样本封装为独立的序列单元,满足RNN对输入数据的序列结构要求,确保模型能够逐样本进行特征学习与预测。
(三)网络结构设计模块
- 输入层:根据输入特征维度(numFeatures)动态构建序列输入层,自动匹配输入数据的特征数量,无需手动调整输入维度参数,提升模型适配性。
- 特征提取层
- 第一层采用128个神经元的GRU层,使用He初始化方法对循环权重与输入权重进行初始化,增强模型对短期依赖特征的捕捉能力,减少梯度消失问题。
- 引入ReLU激活函数,对GRU层输出进行非线性变换,增强模型对复杂特征的表达能力,同时降低计算复杂度。
- 后续依次堆叠64个神经元的LSTM层、32个神经元的LSTM层(仅输出序列最后一个时间步特征),通过多层循环网络结构捕捉输入数据的长期依赖关系,提升预测精度。 - 正则化层:在两层LSTM之间分别插入丢弃概率为0.25的Dropout层,随机丢弃部分神经元连接,有效抑制模型过拟合,提升模型在测试集上的泛化能力。
- 输出层:通过全连接层将LSTM层输出的高维特征映射为单输出维度(numResponses=1),配合回归层实现连续值预测,适用于如销量预测、温度预测等回归类任务。
(四)训练配置与执行模块
- 计算设备自适应:自动检测当前环境GPU设备数量,若存在GPU则使用GPU进行训练(加速计算过程),若无GPU则默认使用CPU训练,无需用户手动配置设备参数,提升模型易用性。
- 训练参数配置
- 优化算法:采用Adam优化器,具备自适应学习率特性,相比传统SGD算法收敛速度更快,且能有效避免局部最优解。
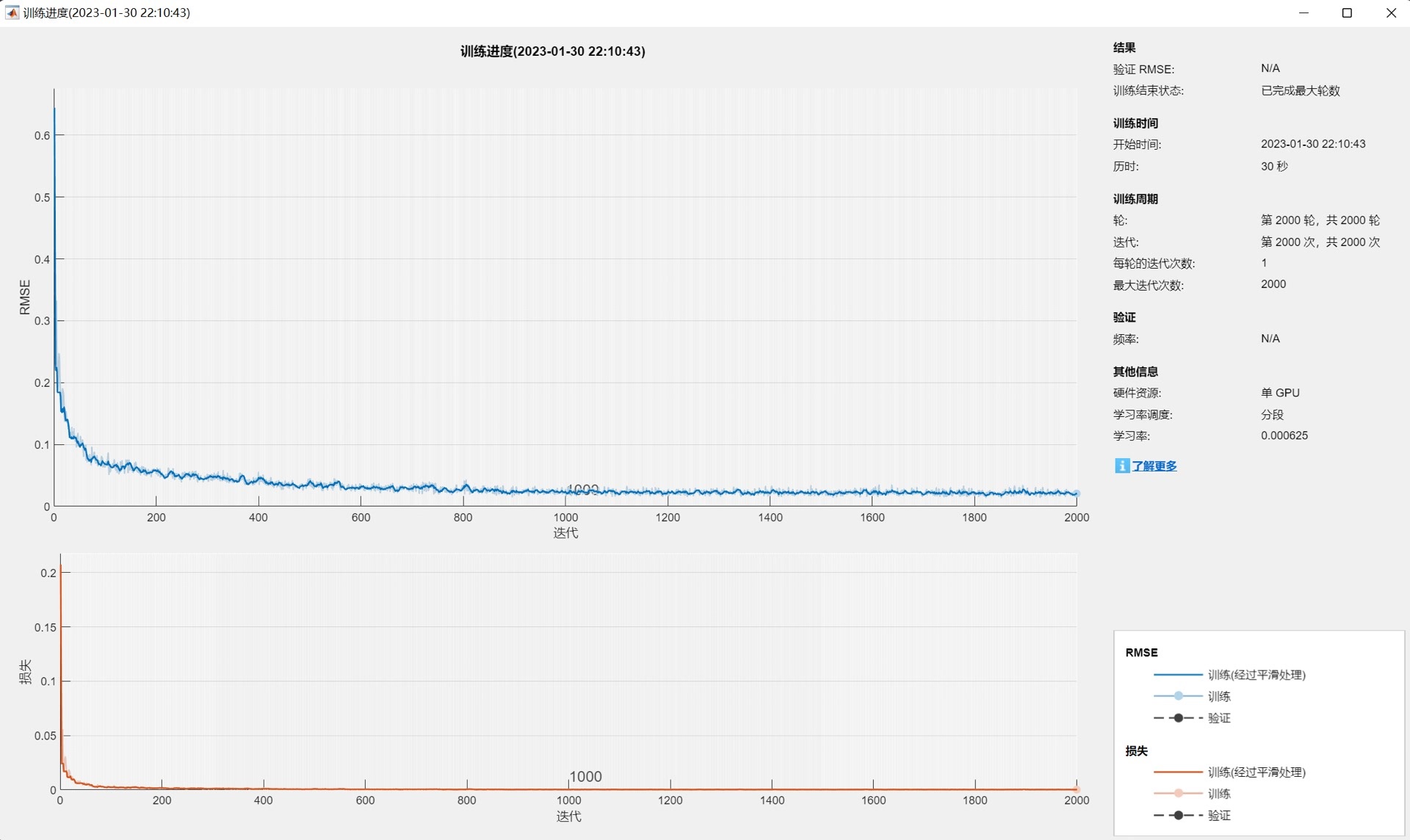
- 训练周期:最大训练轮次(MaxEpochs)设为2000,确保模型有充足的训练迭代次数以学习数据规律。
- 学习率策略:采用分段式学习率调整(piecewise),训练850轮后学习率按0.25倍因子衰减(LearnRateDropFactor=0.25),平衡模型前期快速收敛与后期精细优化需求。
- 批量大小:MiniBatchSize设为96,在保证训练稳定性的同时,提升每次迭代的计算效率,尤其适用于大数据量场景。
- 其他配置:设置梯度阈值为1防止梯度爆炸,开启每轮数据打乱(Shuffle=every-epoch)提升模型泛化能力,关闭冗余日志输出(Verbose=false)并生成训练进度可视化图表,方便用户实时监控训练过程。 - 模型训练:调用trainNetwork函数,基于配置的网络结构与训练参数,使用训练集数据进行模型训练,自动保存训练完成的网络模型(net)用于后续预测。
(五)预测与性能评估模块
- 预测执行:使用训练完成的模型分别对训练集(vptrain)与测试集(vptest)数据进行预测,得到归一化后的预测结果(tsim1、tsim2)。
- 数据反归一化:通过mapminmax函数的reverse模式,将归一化后的预测结果(tsim1、tsim2)还原为原始数据量级的预测值(Tsim1、Tsim2),确保预测结果与真实值在同一量级上可比。
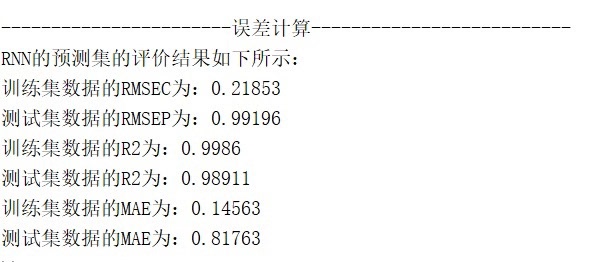
- 多维度误差计算
- 均方根误差(RMSE):计算预测值与真实值之间误差的均方根,反映预测结果的整体偏差程度,RMSE越小说明预测精度越高。
- 决定系数(R²):衡量预测值与真实值的拟合程度,R²越接近1表示模型对数据规律的解释能力越强,预测效果越好。
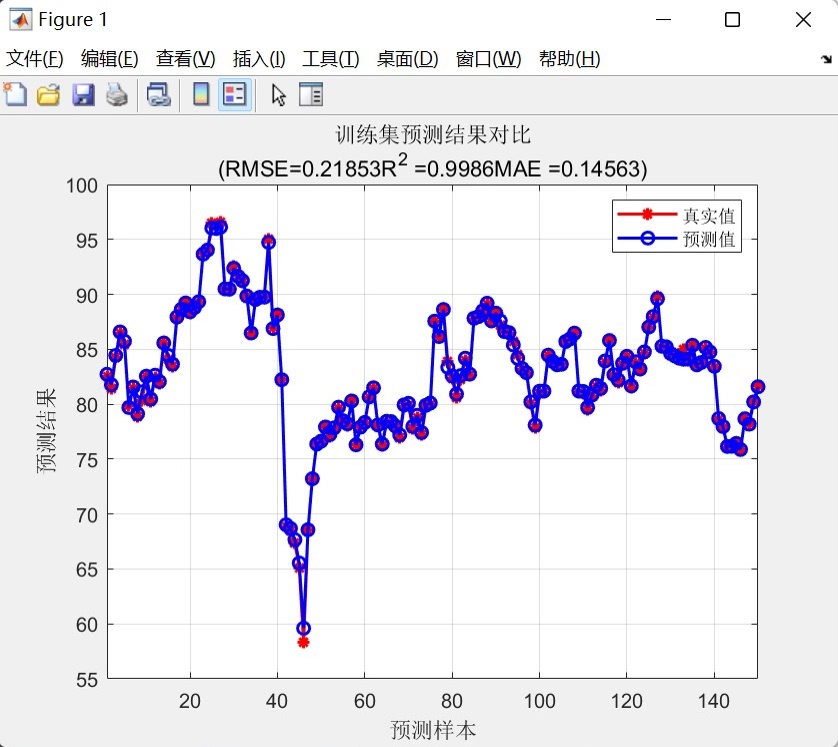
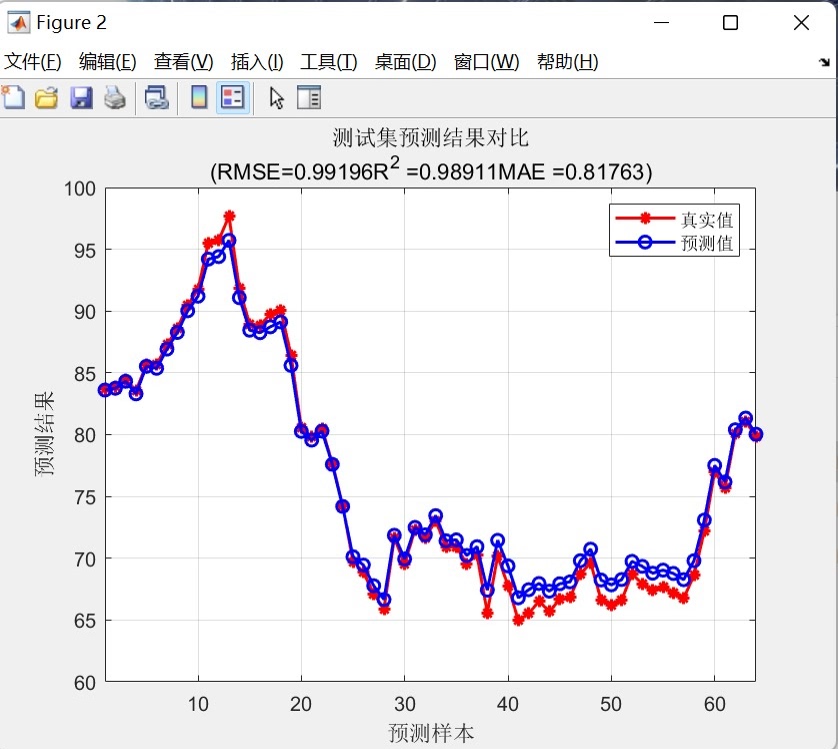
- 平均绝对误差(MAE):计算预测值与真实值绝对误差的平均值,直观反映预测结果的平均偏差,对异常值的敏感性低于RMSE。 - 结果输出:在命令行窗口打印训练集与测试集的RMSE、R²、MAE指标,清晰展示模型性能,方便用户快速评估模型效果。
(六)可视化输出模块
- 预测结果对比图:分别绘制训练集与测试集的真实值(红色星线)与预测值(蓝色圆圈线)对比曲线,直观展示模型在不同数据集上的预测趋势匹配程度,帮助用户快速判断模型预测效果。
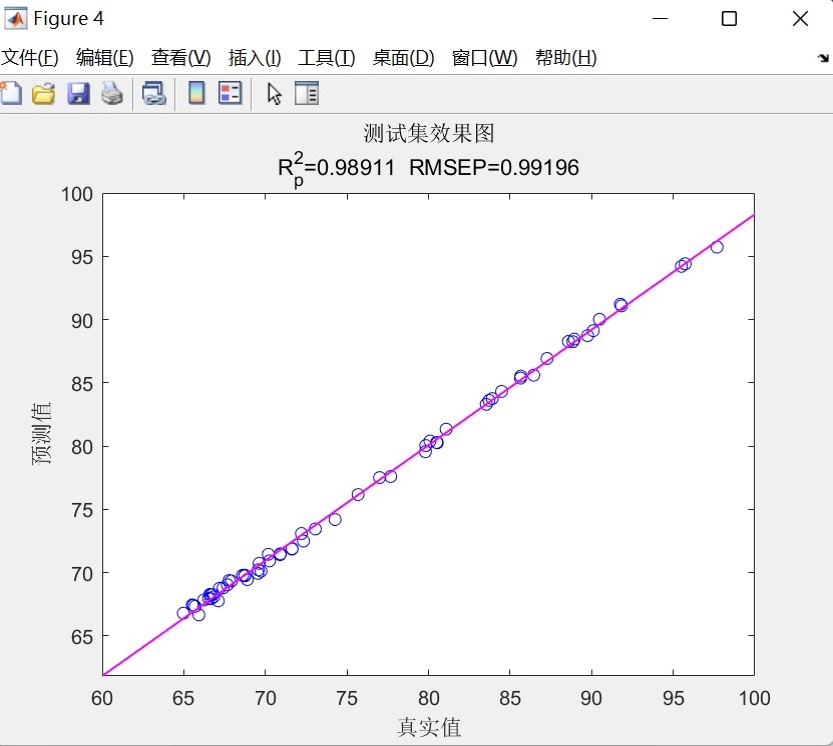
- 线性拟合图
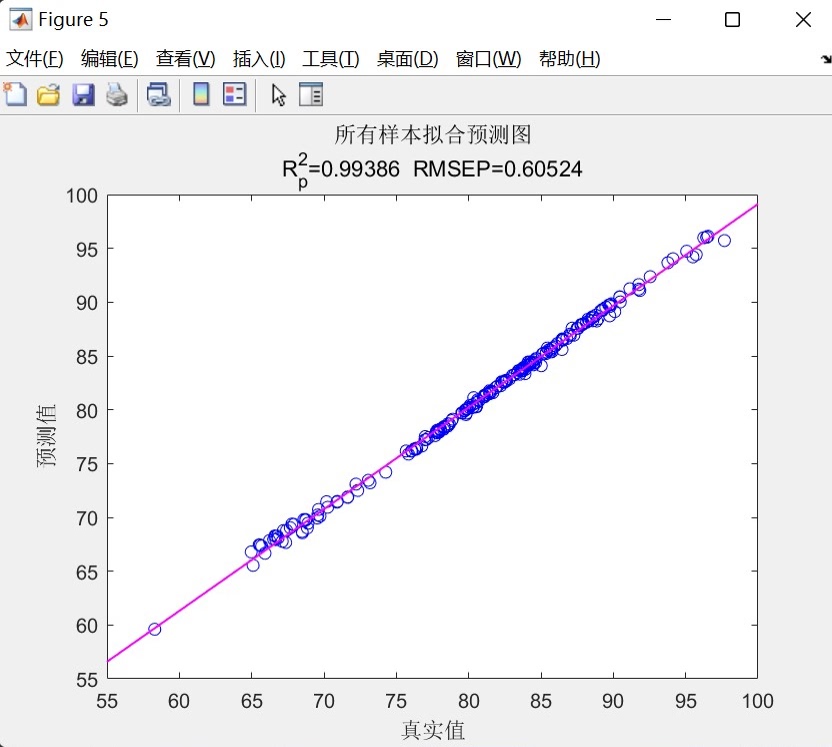
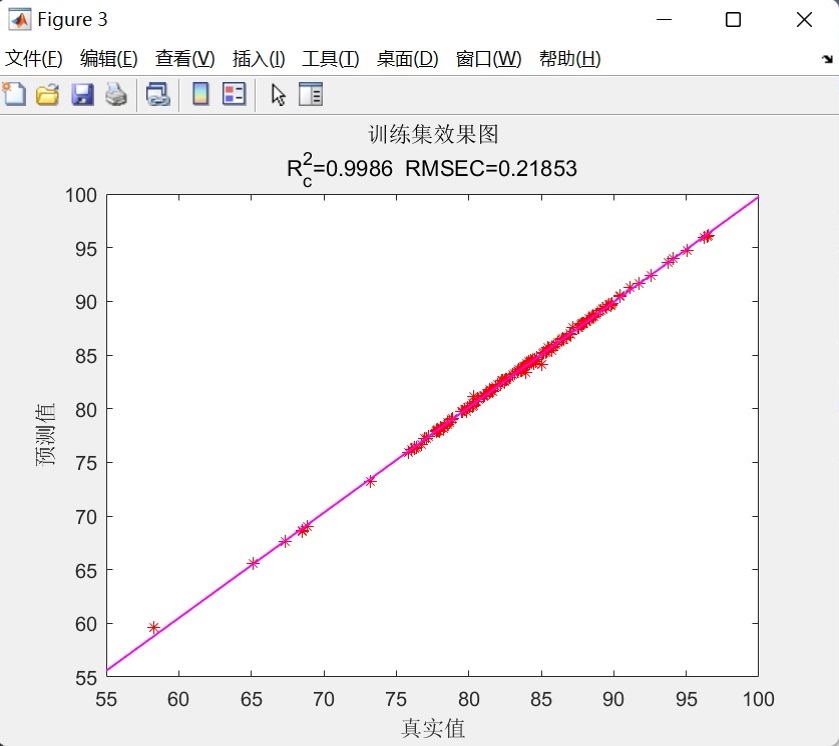
- 训练集/测试集拟合图:以真实值为横轴、预测值为纵轴绘制散点图,并添加线性拟合线(紫色实线),通过拟合线的倾斜程度与散点分布密度,反映预测值与真实值的线性相关性。
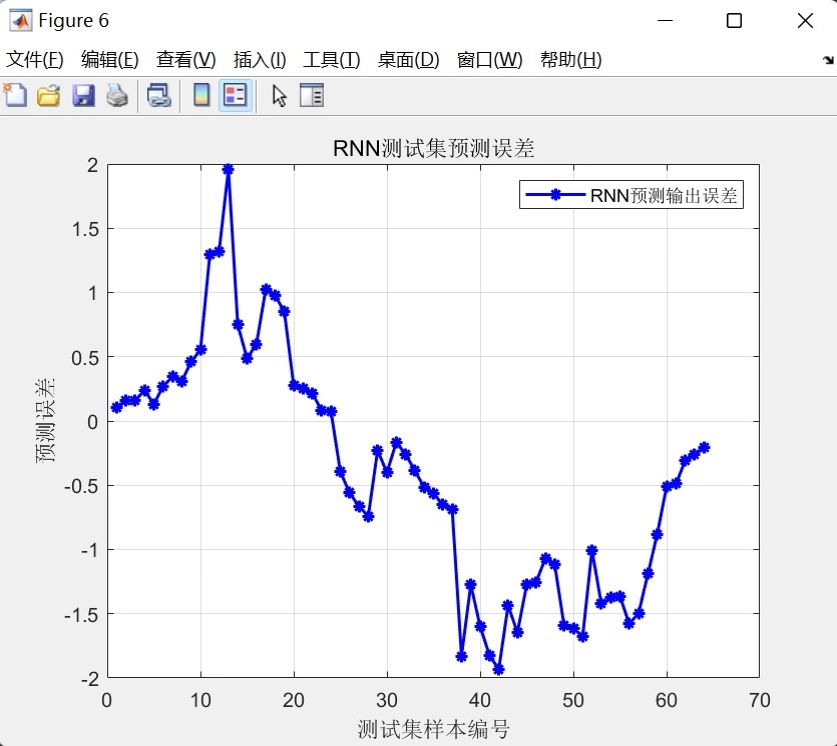
- 全样本拟合图:合并训练集与测试集数据,绘制整体样本的真实值-预测值拟合图,展示模型在全部数据上的综合拟合效果,并标注平均R²与平均RMSE指标。 - 误差分布图:绘制测试集预测误差(真实值-预测值)曲线,通过误差的波动范围与正负分布,帮助用户分析模型预测误差的稳定性,判断是否存在系统性偏差。
三、模型使用流程
- 数据替换:将待预测任务的输入特征数据与输出目标数据分别保存为Excel文件,替换代码中“数据的输入”与“数据的输出”文件路径。
- 参数调整(可选):根据数据规模与任务需求,可调整数据集划分比例(如修改150为其他样本数量)、网络层神经元数量(如GRU层128改为64)、训练轮次、学习率等参数,优化模型性能。
- 运行模型:执行代码,模型将自动完成环境初始化、数据预处理、模型训练、预测与评估,并输出可视化图表与性能指标。
- 结果分析:通过查看命令行输出的误差指标与生成的可视化图表,评估模型预测效果,若效果不佳可重新调整网络结构或训练参数,直至满足需求。
四、模型优势与适用场景
- 优势
- 易用性强:用户无需掌握复杂的RNN原理,仅需替换数据即可快速使用,降低技术门槛。
- 性能稳定:通过多层GRU/LSTM混合结构、Dropout正则化、自适应学习率等设计,有效提升预测精度与泛化能力。
- 可视化完善:提供多维度可视化图表,直观展示预测结果与误差分布,方便结果分析。
- 设备自适应:自动适配CPU/GPU计算环境,提升训练效率。 - 适用场景
- 时间序列预测:如股票价格预测、电力负荷预测、设备故障趋势预测等。
- 多特征关联预测:如基于多个气象因子(温度、湿度、风速)的降雨量预测,基于多个销售影响因素(价格、促销、客流量)的销量预测等回归类任务。
RNN预测模型做多输入单输出预测模型,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。 PS:以下效果图为测试数据的效果图,主要目的是为了显示程序运行可以出的结果图,具体预测效果以个人的具体数据为准。 2.由于每个人的数据都是独一无二的,因此无法做到可以任何人的数据直接替换就可以得到自己满意的效果。 这段程序主要是一个基于循环神经网络(RNN)的预测模型。它的应用领域可以是时间序列预测、回归分析等。下面我将对程序的运行过程进行详细解释和分析。 首先,程序开始时清空环境变量、关闭图窗、清空变量和命令行。然后,通过xlsread函数导入数据,其中'数据的输入'和'数据的输出'是两个Excel文件的文件名。 接下来,程序对数据进行归一化处理。首先使用mapminmax函数将输入数据P_train和P_test归一化到0到1的范围内,并保存归一化的参数ps_input。然后,使用mapminmax函数将输出数据T_train和T_test归一化到0到1的范围内,并保存归一化的参数ps_output。 接着,程序将归一化后的数据转换为特定的格式。使用for循环将p_train和p_test转换为vp_train和vp_test,其中vp_train和vp_test是每个样本的列向量。这样做是为了适应RNN模型的输入格式。 然后,程序定义了一些基础参数。numFeatures表示特征维度,即特征变量的列数;numResponses表示输出维度,这里是1。 接下来,程序设计了一个RNN结构。该结构包含了输入层、GRU层、ReLU激活层、LSTM层、丢弃层、全连接层和回归层。其中,GRU层和LSTM层是循环神经网络的一种变体,用于处理序列数据。 然后,程序根据当前计算环境(GPU或CPU)设置网络参数。如果有GPU设备,则使用GPU进行训练,否则使用CPU。 接着,程序定义了训练选项。使用adam优化算法进行训练,最大训练次数为2000次,梯度阈值为1,初始学习率为0.01,学习率调整策略为piecewise,训练850次后开始调整学习率,学习率调整因子为0.25,最小批量大小为96,关闭训练过程中的详细输出,每个epoch后对数据进行洗牌,训练环境根据之前判断的设备类型进行设置,最后画出训练过程的曲线。 接下来,程序使用trainNetwork函数对vp_train和t_train进行训练,使用之前定义的网络结构和训练选项。 然后,程序使用训练好的网络对vp_train和vp_test进行预测,得到t_sim1和t_sim2。 接着,程序使用mapminmax函数将预测结果进行反归一化,得到T_sim1和T_sim2。 然后,程序计算均方根误差(RMSE),分别计算训练集和测试集的误差。误差的计算公式为每个样本的预测值与真实值之差的平方和除以样本数,再开平方。 接下来,程序计算R2值,用于评估预测模型的拟合程度。R2值的计算公式为1减去预测值与真实值之间的平方和与真实值与均值之间的平方和的比值。 然后,程序计算平均绝对误差(MAE),用于评估预测模型的预测精度。MAE的计算公式为预测值与真实值之差的绝对值之和除以样本数。 接着,程序绘制训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及RMSE、R2和MAE的值。 然后,程序绘制训练集和测试集的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 接下来,程序绘制所有样本的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 然后,程序打印出评价指标,包括RMSE、R2和MAE。 最后,程序绘制测试集的预测误差图,用于分析预测模型的误差情况。 总结来说,这段程序是一个基于循环神经网络的预测模型,用于时间序列预测或回归分析。它通过对输入数据进行归一化处理,设计了一个包含GRU和LSTM层的RNN结构,使用adam优化算法进行训练,并计算了预测结果的误差和评价指标。程序的主要思路是通过训练RNN模型来学习输入数据的模式,并预测输出数据。涉及到的知识点包括循环神经网络、归一化处理、优化算法等。希望这个解释对你有帮助!如果还有其他问题,请随时提问。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)