【腾讯云智能体】高中学生成绩分析问答
教学数据分析并不是把成绩交给模型,再等它生成一段结论那么简单。真正落到业务场景里,往往同时涉及班级统计、学生画像、分数分布、学科相关性、成绩趋势和知识点表现等多个维度。只要分析边界不够清楚,输出就很容易从数据解读变成泛化发挥,最终看起来完整,实际上难以落地。
尤其在教育场景中,数据解释对口径一致性和输出稳定性要求很高。班级统计、学生画像、趋势分析和单次表现不能混在一起写,统计现象和原因推断也必须严格区分。因此,教学分析类智能体不能只追求“能回答”,更要做到“边界清楚、路由准确、输出稳定”。
智能体介绍
这套工作流的定位非常明确,它不是一个开放式教育问答助手,而是一个围绕教学成绩统计结果进行解释输出的分析型工作流。外部系统通过 API 传入不同的问题类型后,流程会自动将请求分发到对应的专项分析节点,让模型只针对当前这一类数据结果进行说明,而不是在一次回答里把班级概述、学生画像、趋势判断和知识点分析全部揉在一起。
从整体能力来看,这个工作流围绕“班级统计分析”和“学生个体分析”两大方向展开,内部又进一步细分为九类固定能力,包括班级成绩概述、整体班级分布概述、分数段统计、质量分档统计、学科相关性分析、学生基础画像、学生单次横向对比、学生多次考试趋势以及知识点表现趋势等。也就是说,它处理的不是一个模糊的“成绩分析问题”,而是一组被提前标准化定义好的分析任务集合。
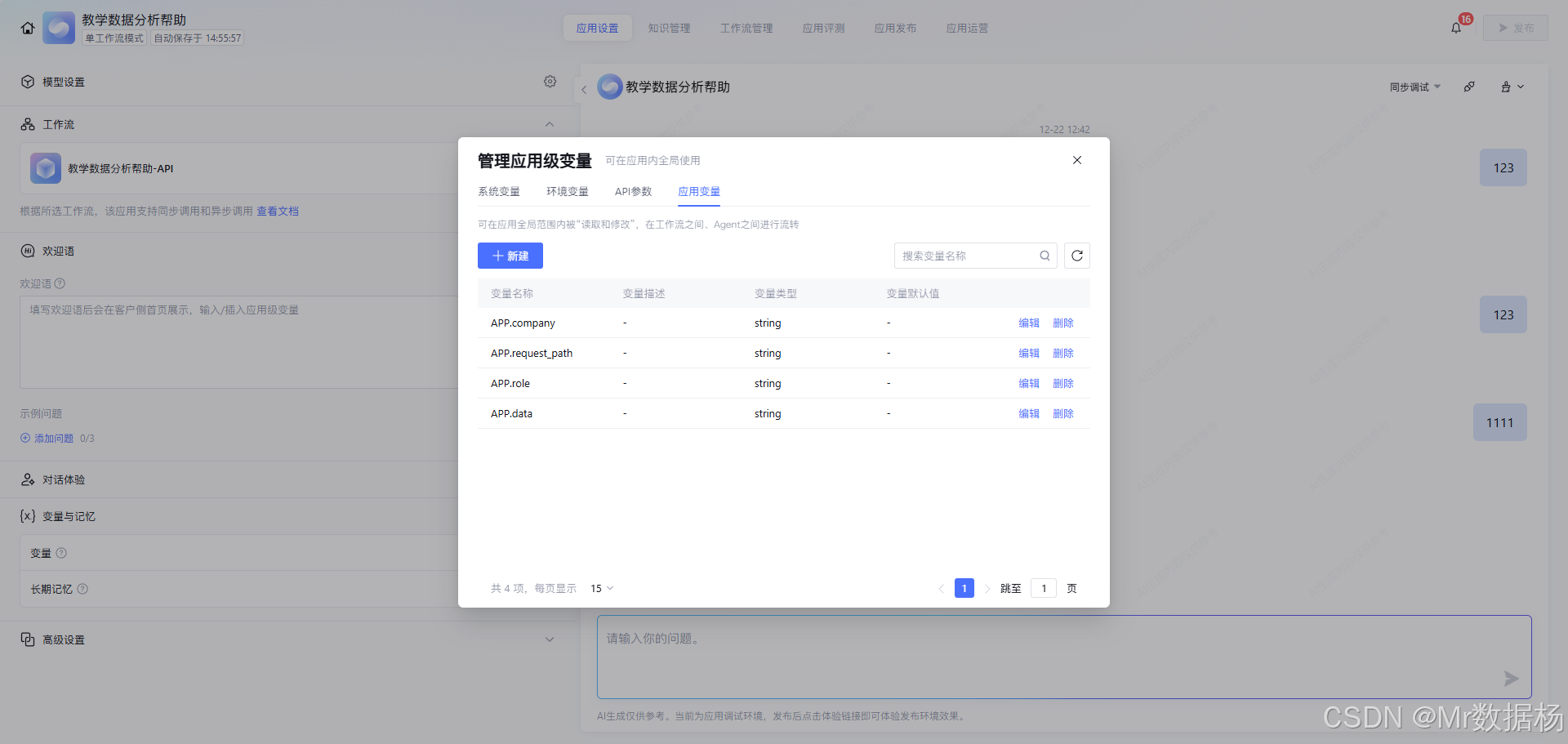
工作流在代码层的入口参数目前为 request_path、data、role,其中 request_path 用于区分当前分析内容的类别,data 承载提交需要分析的表单信息,role 是确定身份从什么角色来分析这个数据;把 company 字段贯穿整个链路用于区分是做培训还是普通高中,做法就是在工作流入口参数里补上对应变量并在分支提示词中引用,保证后续节点能稳定取数。
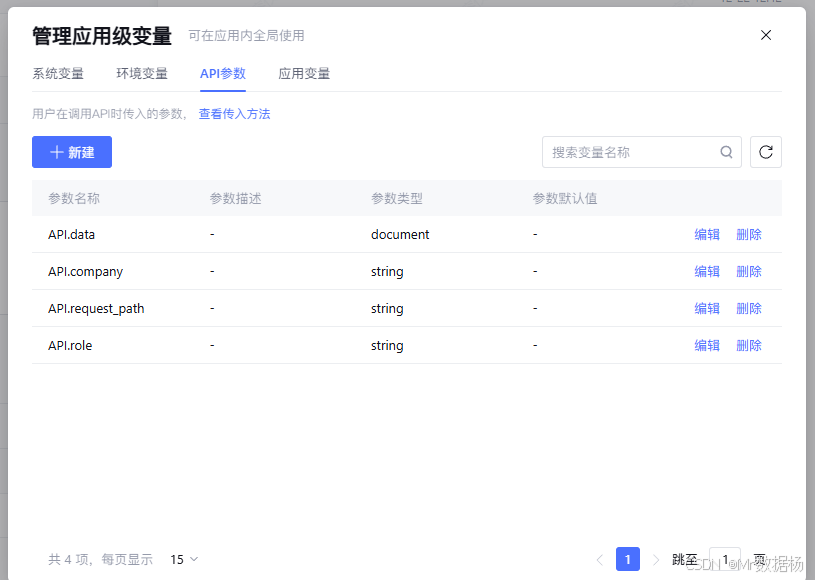
核心模型
在模型配置层面,这套工作流采用的是“统一模型口径、分角色承担职责”的设计思路。它并没有为每种能力使用完全不同的模型,而是让逻辑分流节点和专项分析节点围绕同一类模型体系运转,确保分流口径和输出口径尽可能一致。这样做的好处是,模型在判断请求应该进入哪条链路时,和最终生成分析结论时,使用的是相近的语义理解方式,从而降低“分流理解正确但输出风格跑偏”的风险。
更关键的是,在这个工作流里,模型并不承担计算职责,而只承担解释职责。无论是班级分布、质量分档,还是学生趋势、知识点变化,模型都不是用来重新加工原始数据的,而是用来对已有统计结果进行客观、克制、边界明确的文本表达。也就是说,业务计算逻辑并不交给模型完成,模型只负责把数据结果转换成可读的分析结论。
这种模式在教育场景中特别重要。因为成绩分析一旦脱离统计结果本身,模型很容易进一步延伸到原因归纳、能力判断甚至教学建议,最终超出原始结果可以支持的范围。而通过系统提示词和节点职责限制,这套工作流把模型牢牢约束在“解释现象、不做推断、不做评价”的安全边界内,让输出更适合正式场景使用。
| 模型名称 | 使用位置 | 主要职责 | 配置价值 |
|---|---|---|---|
| Deepseek/deepseek-v3-250324 | 条件判断节点 | 根据输入请求进行语义分流,命中对应分析分支 | 保证路由口径统一,减少错误分支命中 |
| Deepseek/deepseek-v3.2 | 多个班级统计类 LLM 节点 | 对班级成绩统计结果做概述、分布、结构性解释 | 强化群体统计场景下的稳定表达 |
| Deepseek/deepseek-v3-250324 | 多个学生画像与趋势类 LLM 节点 | 对学生画像、趋势、知识点数据做解释性表达 | 适合在强约束提示下输出克制文本 |
从表格可以看到,核心模型配置虽然不复杂,但职责划分非常清晰。逻辑节点负责判断“该去哪”,专项节点负责生成“该怎么说”。这种组织方式本质上不是追求模型多,而是追求模型行为一致、输出稳定。对于教学数据分析这类需要长期运行、频繁调用、强依赖口径统一的业务来说,这种设计比追求模型自由发挥更实用。
Node 节点
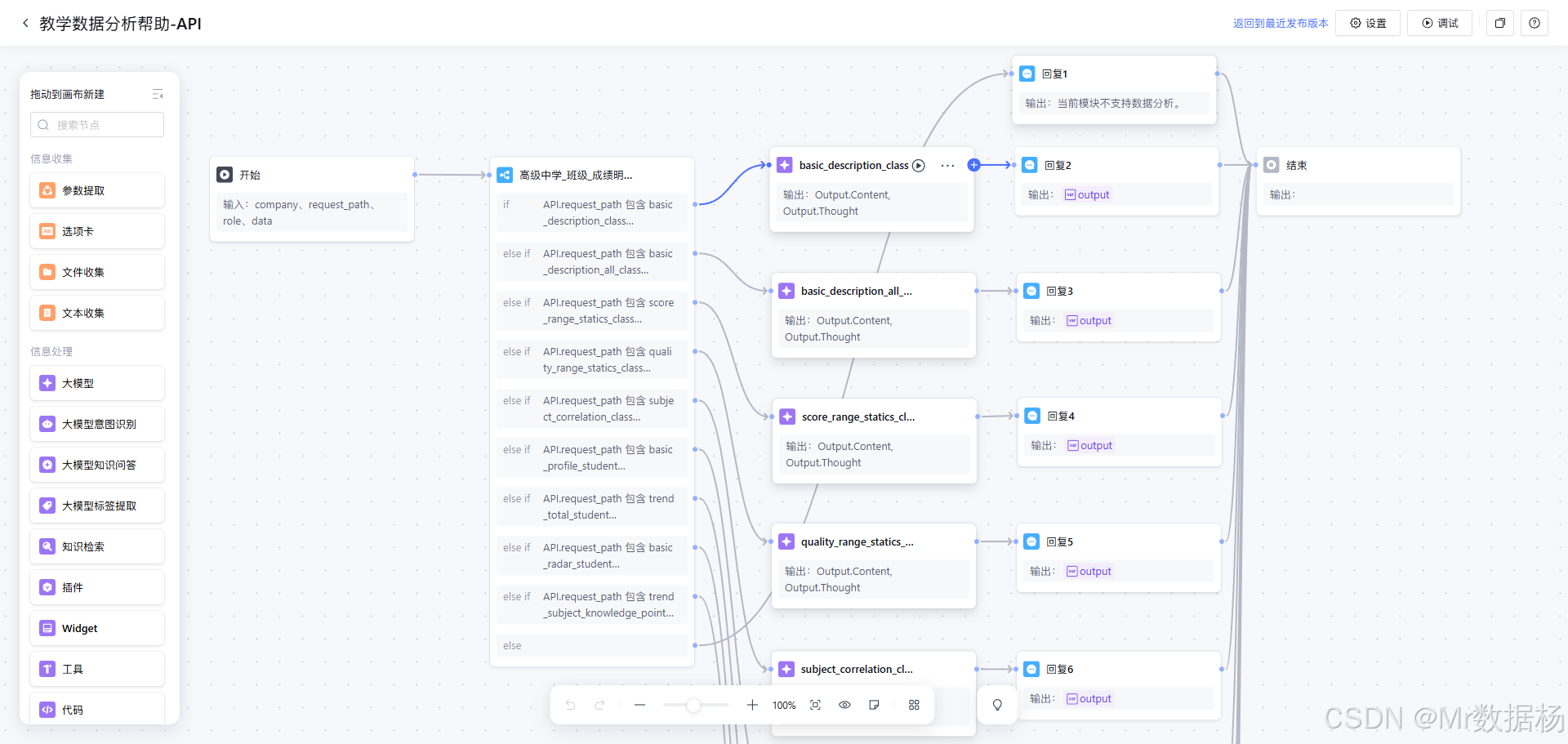
如果从节点编排角度来看,这套工作流采用的是非常典型的“入口统一、中心分流、专项执行、结果收口”结构。开始节点负责接收外部 API 请求,中心条件节点负责判断当前问题类型,命中某一能力后即进入对应的 LLM 节点生成结果,再通过回复节点统一向外返回。整个流程几乎没有多余的绕行节点,也没有复杂的多智能体协同,而是把重点放在分支清晰和执行稳定上。
这种节点设计有两个非常明显的优势。第一,结构简单但职责明确,任何一个分支出现问题时,都可以迅速定位到对应节点排查。第二,扩展性很强,如果后续要新增新的分析能力,只需要复制现有模式,补充一个条件分支和一组专项节点即可,不必重构整个流程骨架。对于需要持续迭代的业务系统来说,这样的结构既利于维护,也利于后续快速扩容。
从节点职责汇总表可以更直观地看出,整条链路中每个节点只做一件事。开始节点不参与分析,条件节点不负责输出,LLM 节点不负责封装,回复节点不负责判断。正是这种低耦合的设计,保证了流程在复杂场景下仍然能保持较高稳定性。
| 节点类型 | 节点名称 | 节点职责 | 结构作用 |
|---|---|---|---|
| 开始节点 | 开始 | 接收工作流入口参数,承接外部 API 请求 | 统一输入入口 |
| 分流节点 | 高级中学_班级_成绩明细 | 根据输入能力标识将请求路由到九个分析分支之一 | 核心路由中枢 |
| LLM 节点 | basic_description_class |
解释单个班级成绩统计结果 | 班级概述分析 |
| LLM 节点 | basic_description_all_class |
解释群体层面的整体成绩统计结果 | 整体概述分析 |
| LLM 节点 | score_range_statics_class |
解释分数段分布结果 | 分数区间分析 |
| LLM 节点 | quality_range_statics_class |
解释质量分档与结构占比结果 | 质量结构分析 |
| LLM 节点 | subject_correlation_class |
解释学科间相关性统计结果 | 学科关联分析 |
| LLM 节点 | basic_profile_student |
解释学生单次考试画像结果 | 个体画像分析 |
| LLM 节点 | trend_total_student |
解释学生与班级、年级横向对比结果 | 学科结构分析 |
| LLM 节点 | basic_radar_student |
解释多次考试成绩与等级趋势结果 | 成绩趋势分析 |
| LLM 节点 | trend_subject_knowledge_point_student |
解释知识点表现与趋势统计结果 | 知识点趋势分析 |
| 回复节点 | 回复2—回复10 | 接收各分析节点输出并统一向外返回 | 分支收口输出 |
| 回复节点 | 回复1 | 处理未命中或兜底场景 | 异常兜底 |
| 结束节点 | 结束 | 结束流程并完成最终回传 | 统一终点 |
从这张节点汇总表可以发现,这套工作流虽然覆盖的分析能力不少,但它的实现方式并不复杂。真正起关键作用的,不是节点数量,而是节点关系是否足够清楚、边界是否足够明确。对于教育分析类智能体来说,这种清晰结构比复杂链路更重要,因为只有先把流程做稳,后续的分析质量、业务复用和系统扩展才有基础。
工作流程
从工作流层面看,这套系统的核心不是“让模型理解教学场景”,而是“让流程先把场景分清楚,再交给模型解释”。因此,它的重点不在多轮对话能力,而在问题路由能力和分析边界控制能力。工作流通过开始节点承接外部请求,再由中心分流节点根据问题类型进入不同分析分支,每个分支仅负责一种固定职责,最后统一通过回复节点对外输出。这种结构使整条链路非常适合 API 化调用,也天然适合后续做产品级封装。
| 类型归属 | 分析能力 | 工作流职责 | 输出边界 |
|---|---|---|---|
| 班级统计 | basic_description_class |
对单个班级成绩统计结果做概述性解释 | 只描述班级统计现象,不做个体评价 |
| 班级统计 | basic_description_all_class |
对整体班级群体统计结果做群体分布概述 | 只看整体分布,不推断原因 |
| 班级统计 | score_range_statics_class |
对分数分段结果做区间分布解释 | 只解释区间分布,不进行优劣判断 |
| 班级统计 | quality_range_statics_class |
对质量分档与占比结构做解释 | 只看档位结构,不给教学建议 |
| 班级统计 | subject_correlation_class |
对学科间相关性结果做说明 | 只说统计关联,不推断因果 |
| 学生画像 | basic_profile_student |
对学生单次考试画像结果做概述 | 只描述相对位置与结构,不作长期判断 |
| 学生画像 | trend_total_student |
对单次考试中个人与班级、年级对比结果做说明 | 只看横向差异,不做趋势推断 |
| 学生趋势 | basic_radar_student |
对多次考试成绩与等级变化做趋势解释 | 只描述趋势,不作确定性预测 |
| 学生趋势 | trend_subject_knowledge_point_student |
对多次考试知识点表现与趋势结果做说明 | 只解释知识点统计表现,不给复习建议 |
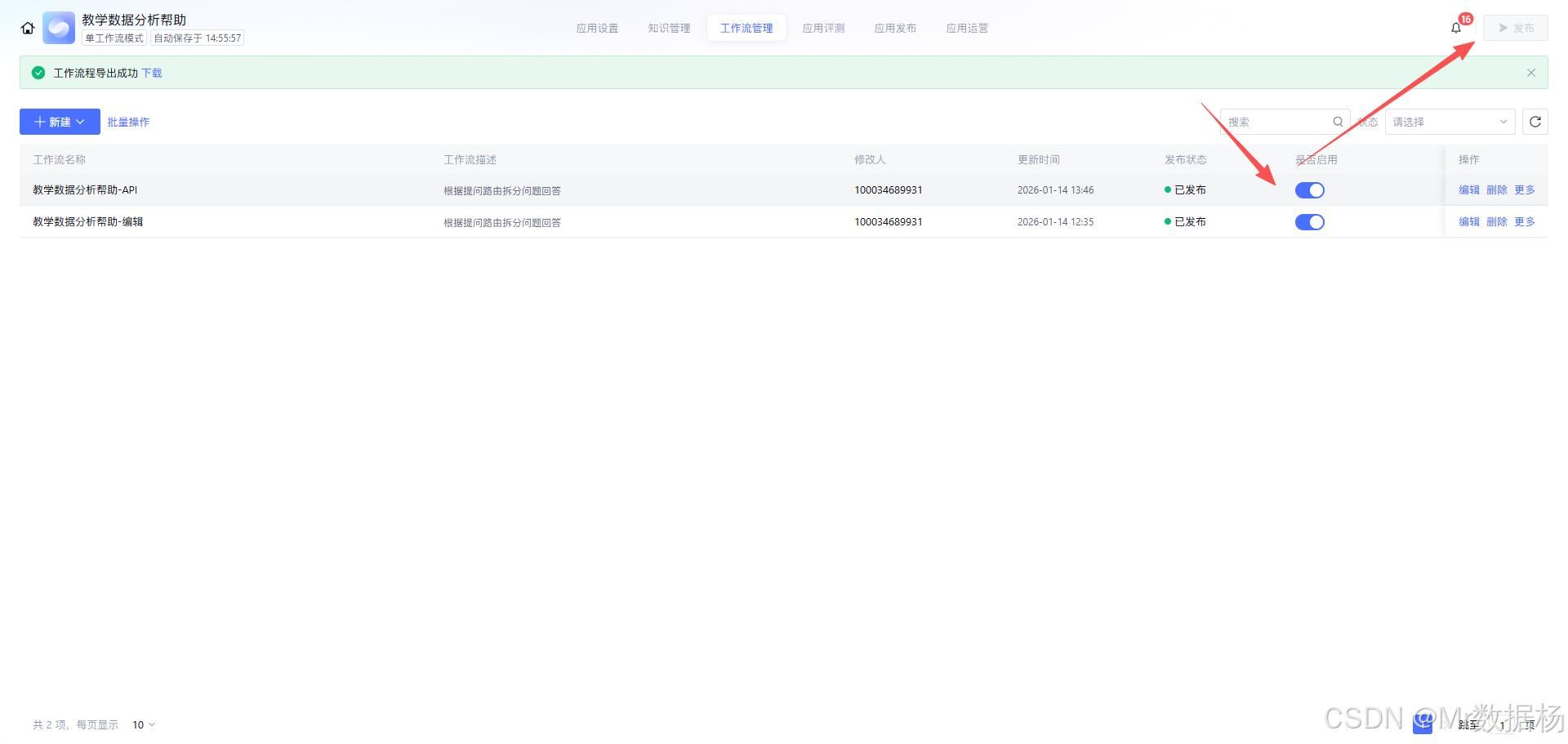
工作流启用与发布的位置,属于“搭建动作”的最后一步。这里的重点不是点一下发布那么简单,而是确认你已经把入口参数、分支条件与节点配置都固定下来,发布后外部调用才能拿到稳定一致的执行结果,避免上线后出现“跑不到分支”或“取不到变量”的问题。
结合能力划分来看,整个流程本质上是在把“教学分析”拆成九种可单独运行的解释任务。班级维度下,系统负责处理整体概况、分布结构、区间统计和学科关联;学生维度下,系统负责处理基础画像、横向对比、纵向趋势和知识点变化。这样的拆分方式非常关键,因为它让工作流从结构上避免了多维问题混写,也让输出更容易被上层业务直接消费。
工作流启用与发布属于整条链路上线前的最后一步。这里的重点并不只是完成发布操作,而是确保你已经把知识库内容、检索配置、模型提示词和输出方式全部固定下来。只有这样,外部调用时才能持续得到边界一致、来源明确的帮助回答,避免出现“同样的问题每次回答都不一样”或者“回答超出知识库范围”的情况。
应用场景
这个工作流最适合的场景,是需要“输出口径统一、分析边界清楚、结果可直接展示”的教学数据分析产品形态。由于它将复杂的成绩分析问题拆成固定类型的专项输出,因此既可以在考试分析系统中按页面模块分别调用,也可以在数据看板、班级报告、学生画像页中按需组合展示。对于同一场考试,系统既可以面向班级维度输出整体概况、分数分布、质量分档和学科相关性分析,也可以面向学生维度输出个人画像、横向对比、成绩趋势和知识点变化结果。这样做的价值在于,不同场景调用的虽然是同一套工作流,但每一次输出都只聚焦当前分析目标,不会出现群体分析和个体分析混杂、单次表现和长期趋势混写的问题。结合调用记录与使用反馈,后续还可以持续优化分流规则、补充分析类型和调整提示词口径,逐步提升系统在教学场景中的稳定性与解释一致性。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 班级成绩概述分析 | 快速了解单个班级整体成绩表现 | 班主任、年级组长、教务管理者 | 班级总体成绩概况、整体表现描述 | 输出聚焦班级整体表现,适合首页概览展示 |
| 全班整体分布分析 | 查看班级群体成绩分布结构 | 班主任、教学管理人员 | 平均水平、集中程度、整体分布情况 | 便于快速识别班级成绩结构特征 |
| 分数段统计分析 | 解释不同分数区间人数分布 | 教师、教务人员、数据分析人员 | 高分段、中间段、低分段人数及占比 | 让区间分布结果更直观、更适合报告展示 |
| 质量分档统计分析 | 分析成绩档位结构与层次分布 | 教学管理者、年级负责人 | 各档人数、占比结构、层次分布描述 | 输出聚焦结构特征,不混入教学建议 |
| 学科相关性分析 | 理解学科之间统计关联关系 | 教研组长、数据分析人员 | 学科间相关强弱、关联特征说明 | 帮助观察学科联动关系,避免因果误读 |
| 学生基础画像分析 | 展示学生单次考试的成绩位置与结构 | 学生、家长、班主任 | 总体水平、学科表现、相对位置描述 | 形成可直接展示的学生成绩画像卡片 |
| 学生横向对比分析 | 对比学生与班级、年级之间的差异 | 学生、家长、教师 | 学科对比、整体对比、相对差距说明 | 强化“个人在群体中的位置”解释能力 |
| 学生成绩趋势分析 | 观察学生多次考试成绩变化情况 | 学生、家长、班主任 | 多次考试变化、等级变化、趋势描述 | 适合生成阶段性成长跟踪内容 |
| 知识点趋势分析 | 追踪学生知识点表现变化 | 学生、教师、学情分析人员 | 知识点掌握情况、波动变化、趋势表现 | 适合学情复盘和知识结构变化展示 |
总结
该工作流通过明确的问题分流机制,将原本容易混杂的教学数据分析任务拆解为班级统计、学生画像、成绩趋势和知识点表现等多条独立链路。每条链路都在固定节点和明确提示词约束下运行,使模型只负责当前分析目标的解释工作,不跨越到其他维度,也不延伸到原因推断、价值判断或教学建议层面。这样一来,输出结果就具备了更清晰的边界、更稳定的结构和更高的复用价值。
从工程实现角度看,这套工作流真正解决的,不只是“模型如何回答教学分析问题”,而是“如何让教学分析结果稳定、可控并适合产品化接入”。在现有结构基础上,后续还可以通过新增分析类型、补充入口参数、优化分流逻辑或细化节点提示词,持续扩展系统能力。随着调用数据和业务场景不断积累,这类“先分流、再分析、后收口”的工作流模式,也会比单纯依赖大模型自由生成更适合长期落地,尤其适合面向学校平台、考试分析系统和学生成长档案产品的持续迭代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)