BP神经网络建模与优化MATLAB代码功能说明
bp神经网络交叉验证算法和确定最佳隐含层节点个数matlab 程序,直接运行即可。 数据excel格式,注释清楚,效果清晰,一步上手。
一、代码概述
本文档所分析的两套MATLAB代码,均围绕BP(Back Propagation)神经网络展开,聚焦于解决回归类建模问题。两套代码的核心目标一致,即通过数据驱动的方式构建高精度预测模型,但在模型优化策略与实现细节上各有侧重。其中一套代码以K折交叉验证为核心,旨在通过严谨的交叉验证流程筛选最佳模型参数并评估模型泛化能力;另一套代码则专注于隐含层节点数的系统性筛选,通过遍历不同节点配置并比较模型误差,确定最优网络结构。两套代码均具备完整的数据处理、模型训练、参数优化、结果评估与可视化功能,可直接应用于各类基于表格数据的回归预测任务,如工程参数预测、经济指标分析、环境因子建模等场景。
二、核心功能模块解析
(一)数据预处理模块
数据预处理是确保神经网络模型训练效果的关键前置步骤,两套代码均实现了标准化的数据处理流程,主要包含数据读取与归一化两个核心操作。
- 数据读取:代码通过调用MATLAB内置函数读取Excel格式的数据文件,支持灵活指定数据范围。数据被明确划分为输入特征变量(Input Features)和输出目标变量(Target Output)。在数据划分策略上,两套代码均采用“训练集-测试集”的经典分割模式:训练集用于模型的参数学习,测试集(外部验证集)则用于评估模型在未见过的数据上的泛化性能。其中,训练集样本数量可通过代码中的参数直接调整,以适应不同规模的数据集(如从数百到数千样本)。
- 数据归一化:为消除不同特征变量间数量级差异对模型训练的干扰(例如,一个特征的取值范围是0-1,另一个是0-1000,后者会主导梯度更新),代码采用
mapminmax函数对输入和输出数据分别进行归一化处理。归一化过程会将数据压缩到指定区间(如[0,1]或[-1,1]),并保存对应的归一化参数(如数据的最大值、最小值或均值、标准差)。在模型预测阶段,需使用相同的参数对新输入数据进行归一化,并对预测输出进行反归一化,以还原为真实的物理量或实际数值范围。
(二)模型优化模块
模型优化是两套代码的核心差异点,分别从“交叉验证”和“隐含层节点筛选”两个维度提升模型性能,旨在解决BP神经网络易过拟合、参数选择依赖经验的问题。
- K折交叉验证优化(代码1)
- 核心逻辑:该代码引入10折交叉验证(10-fold Cross Validation)机制,将训练集随机划分为10个大小相近的子集。每次迭代中,使用9个子集作为训练数据,1个子集作为验证数据,重复10次以确保每个子集都充当过验证集。通过这种方式,可有效评估模型在不同数据分布下的稳定性,避免因单次数据划分导致的模型性能误判。
- 参数搜索:在交叉验证的每一轮迭代中,代码会遍历隐含层节点数(默认范围为4-10),为每个节点数配置构建对应的BP神经网络。网络采用tansig(双曲正切S型)作为隐含层激活函数,purelin(线性函数)作为输出层激活函数,使用trainlm(Levenberg-Marquardt)算法进行训练——该算法收敛速度快,是解决中小型回归问题的常用优化算法。
- 最优模型选择:代码以验证集的决定系数(R²)作为核心评价指标,同时参考均方误差(MSE)。在所有交叉验证轮次和所有节点数配置中,筛选出R²最大、MSE最小的模型作为最终的“最佳模型”,并保存该模型的网络参数与归一化参数。 - 隐含层节点数系统性筛选(代码2)
- 核心逻辑:隐含层节点数是BP神经网络结构设计中最关键的参数之一——节点数过少会导致模型欠拟合(无法学习数据规律),节点数过多则会导致过拟合(对训练数据噪声过度学习,泛化能力差)。该代码基于“经验公式+遍历验证”的思路,首先参考经验公式(如节点数p=√(输入维度+输出维度)+a,其中a为0-10的整数)确定节点数搜索范围(默认3-15),再通过步长遍历(默认步长1)的方式,对每个节点数配置进行独立的模型训练与误差评估。
- 误差评估与最优节点选择:对于每个候选的隐含层节点数,代码会训练一个完整的BP神经网络,并计算训练集的均方误差(MSE)。将所有节点数对应的MSE记录后,筛选出MSE最小的节点数作为“最佳隐含层节点数”。此外,代码还支持灵活调整搜索范围(如下限3、上限15)和步长(如1、2、3),以适应不同复杂度的数据集。
- 网络参数精细化配置:相比代码1,该代码对神经网络的训练参数配置更为精细,除了设置训练次数(默认1000次)、训练目标误差(默认1e-8)、显示频率(默认每25次迭代显示一次)外,还额外配置了动量因子(默认0.01,用于加速收敛、避免局部最优)、最小性能梯度(默认1e-6,用于判断收敛状态)和最高失败次数(默认6,用于早停、防止过拟合)。
(三)模型预测与性能评估模块
两套代码均实现了完整的模型预测流程,并通过多维度的评价指标量化模型性能,确保结果的可靠性与可解释性。
- 模型预测:在确定最佳模型(代码1)或最佳隐含层节点数(代码2)后,代码会使用该模型对“外部测试集”(即训练过程中未接触过的数据)进行预测。预测前,需先使用训练阶段保存的归一化参数对测试集输入数据进行归一化;预测后,再对模型输出的预测值进行反归一化,得到与真实值同量级的最终预测结果。
- 多维度性能指标计算:为全面评估模型性能,两套代码均计算了多个经典的回归问题评价指标,具体包括:
- 均方误差(MSE):反映预测值与真实值之间的平均平方偏差,MSE越小,模型精度越高。
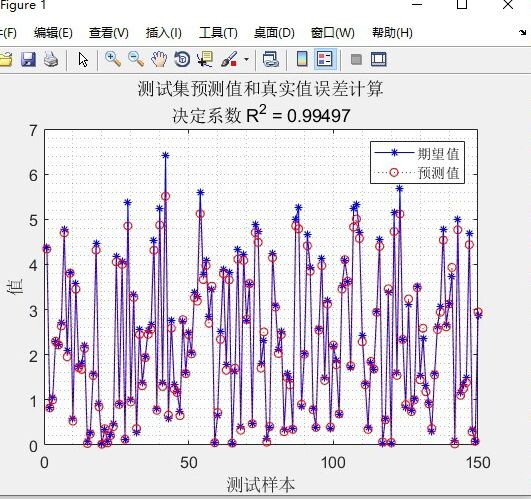
- 决定系数(R²):反映模型对数据变异的解释能力,R²越接近1,说明模型预测效果越好(R²=1表示完全拟合,R²<0表示模型预测效果差于直接使用均值预测)。
- 平均绝对误差(MAE,代码2):反映预测值与真实值之间的平均绝对偏差,MAE对异常值的敏感性低于MSE,更能反映预测的“平均误差水平”。
- 均方根误差(RMSE,代码2):是MSE的平方根,其单位与真实值一致,更便于直观理解误差的实际大小。
- 相对误差(代码2):包括最小相对误差、最大相对误差和平均相对误差,主要用于评估预测结果的“相对精度”,尤其适用于对误差比例敏感的场景(如工业生产中的精度控制)。 - 结果可视化:为更直观地展示模型预测效果,两套代码均提供了专业的可视化图表:
- 预测值与真实值对比图:以折线图的形式,将测试集的真实值(如红色实线)与预测值(如蓝色虚线)绘制在同一坐标系中,可直观观察两者的吻合程度。
- 误差变化图(代码1):通过训练过程的误差下降曲线,展示模型从初始状态到收敛状态的误差变化趋势,可判断模型的收敛速度与稳定性。
- 相对误差图(代码2):以柱状图或折线图的形式,展示每个测试样本的相对误差,可快速定位误差较大的异常样本,为后续数据清洗或模型优化提供方向。
- MSE随隐含层节点数变化图(代码2):将不同隐含层节点数对应的MSE绘制成折线图,可清晰观察MSE随节点数变化的“先降后升”趋势,直观验证最佳节点数的选择依据。
(四)辅助功能模块
除核心功能外,两套代码还包含若干辅助功能,提升了代码的易用性、可读性与稳定性。
- 环境初始化:代码开头通过
clear(清除工作区变量)、close all(关闭所有图形窗口)、clc(清空命令行窗口)三个命令初始化MATLAB环境,避免历史变量或图形对当前运行结果的干扰。 - 进度显示(代码1):在交叉验证与节点数搜索的双重循环中,代码通过
waitbar函数创建进度条,实时显示当前的计算进度(如“正在寻找最优化参数.... 50%”),尤其适用于数据量大、迭代次数多的场景,帮助用户判断程序运行状态。 - 结果打印与日志输出:两套代码均通过
disp函数,在命令行窗口实时打印关键信息,包括:交叉验证轮次、当前隐含层节点数、训练集/测试集的MSE与R²、最佳模型参数(如最佳节点数)、最终的性能评估指标(如MAE、RMSE、R²)等。这些信息可作为模型训练的“日志”,便于用户追溯过程、排查问题。 - 网络结构可视化(代码2):代码通过
view(net)函数调用MATLAB的神经网络可视化工具,以图形化的方式展示BP神经网络的层级结构(输入层-隐含层-输出层)、各层节点数、激活函数类型等,帮助用户直观理解网络拓扑,尤其适合初学者学习与调试。
三、代码适用场景与使用建议
(一)适用场景
两套代码均适用于单输出回归问题(即模型输入为多个特征变量,输出为单个连续值),典型应用场景包括:
- 工程预测:如基于原材料成分、工艺参数预测产品的性能指标(如强度、硬度);基于设备运行参数(如温度、压力、转速)预测设备剩余寿命。
- 经济与金融分析:如基于宏观经济指标(GDP、CPI、利率)预测某商品的价格;基于企业财务数据(营收、成本、利润)预测下期盈利。
- 环境与气象预测:如基于历史气象数据(温度、湿度、气压)预测次日降水量;基于污染物排放数据预测区域空气质量指数(AQI)。
- 生物与医疗数据分析:如基于患者的生理指标(血压、血糖、心率)预测某种疾病的风险等级;基于药物浓度、给药时间预测药物在体内的血药浓度。
(二)使用建议
- 数据准备:
- 确保Excel数据文件格式正确,输入特征与输出目标变量按列组织,无缺失值或异常值(建议先通过MATLAB的isnan、isinf函数检查数据,对异常值进行删除或插值处理)。
- 根据数据集规模调整训练集与测试集的划分比例(如小规模数据可采用7:3或8:2的划分比例,大规模数据可采用9:1的划分比例),代码1中通过num参数调整,代码2中通过m参数调整。 - 参数调整:
- 交叉验证折数(代码1):默认采用10折交叉验证,对于样本量极小的数据集(如<100样本),可调整为5折;对于样本量极大的数据集(如>10000样本),可调整为5折或3折以减少计算时间。
- 隐含层节点数搜索范围(两套代码):默认范围(代码1为4-10,代码2为3-15)适用于中小型数据集,若数据集特征维度高、复杂度高,可扩大搜索范围(如5-20);若数据集简单,可缩小范围(如2-8)。
- 训练参数(两套代码):若模型训练不收敛(如迭代1000次后仍未达到目标误差),可适当增加训练次数(如2000次)或提高学习速率(代码2中lr参数,如从0.01调整为0.1);若模型过拟合(训练集R²高、测试集R²低),可增加早停机制(代码2中max_fail参数)或减少隐含层节点数。 - 结果解读:
- 重点关注测试集的R²与MSE,若测试集R²远低于训练集R²,说明模型存在过拟合,需通过增加数据量、调整网络结构(如减少节点数)或加入正则化机制优化。
- 对于代码2的相对误差图,若某几个样本的相对误差显著高于其他样本,需检查这些样本是否为异常值(如数据录入错误、极端工况数据),必要时可剔除这些样本后重新训练模型。 - 性能优化:
- 若数据集规模极大(如样本数>10000),可采用“分批训练”(如MATLAB的trainscg算法)替代trainlm算法,以减少内存占用。
- 若需同时优化多个参数(如学习速率、动量因子、隐含层节点数),可在现有代码基础上引入“网格搜索”或“随机搜索”逻辑,进一步提升模型性能。
四、总结
本文档分析的两套BP神经网络MATLAB代码,是“数据驱动建模”的典型实现,具备功能完整、逻辑严谨、易用性强的特点。代码1通过K折交叉验证确保了模型的泛化能力与稳定性,适用于对模型可靠性要求高的场景;代码2通过隐含层节点数的系统性筛选与精细化参数配置,为网络结构设计提供了清晰的优化路径,适用于对模型结构优化要求高的场景。两套代码均覆盖了从数据预处理到模型优化、预测、评估、可视化的全流程,不仅可直接应用于各类回归预测任务,其核心逻辑与实现思路也为初学者学习BP神经网络、掌握“参数优化”与“性能评估”方法提供了高质量的参考案例。

bp神经网络交叉验证算法和确定最佳隐含层节点个数matlab 程序,直接运行即可。 数据excel格式,注释清楚,效果清晰,一步上手。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)