多模态Agent持续学习新思路,解决工具使用和编排两大难题!
本文介绍了XSkill,一种用于多模态Agent的持续学习方法。XSkill通过将“过往经历”沉淀为Skills(技能)和Experiences(经验)两类可复用知识,并形成闭环,有效解决了当前多模态Agent在真实开放环境中工具使用不高效、工具编排不灵活的问题。XSkill通过外部知识持续积累和视觉语境检索与改写,实现了跨模型迁移,并可将一个强模型积累的知识转移给另一个模型使用。实验结果表明,XSkill在多个基准测试中显著优于基线方法,并具有良好的泛化能力和跨模型迁移能力。
先说结论:这篇论文到底解决了什么问题?
多模态 Agent(能看图、能调用工具、能搜索网页)已经很强,但在真实开放环境里仍有两个顽疾:
-
- 工具用得不高效 :简单任务也会绕远路,复杂任务又常常探索不够深。
-
- 工具编排不灵活 :遇到新任务时,工具组合容易僵化,泛化能力差。
这篇论文提出的 XSkill ,核心是让 Agent 像人一样,把“过往经历”沉淀成两类可复用知识,并形成闭环:
- • Skills(技能) :任务级、结构化流程知识(怎么规划、怎么串工具)。
- • Experiences(经验) :动作级、上下文敏感的战术提示(某种场景下优先做什么)。
重点在于:它不是微调模型参数,而是做 外部知识持续积累 + 视觉语境检索与改写 。这使得它可以跨模型迁移,甚至能把一个强模型积累的知识转移给另一个模型使用。
研究动机:为什么“经验 + 技能”要分开建模?
论文的洞见很清晰:
- • 仅靠高层流程(skill)不够,因为执行时常有很多局部坑(如图片反转、OCR 误读、工具参数错误)。
- • 仅靠局部经验(experience)也不够,因为没有全局任务结构,容易“头痛医头”。
所以 XSkill 把两者拆开并协同:
- • Skill 负责“框架正确性”(少走错路、少犯结构性错误);
- • Experience 负责“策略灵活性”(在具体视觉上下文里动态选工具、修正策略)。
方法总览:双流知识 + 双阶段循环
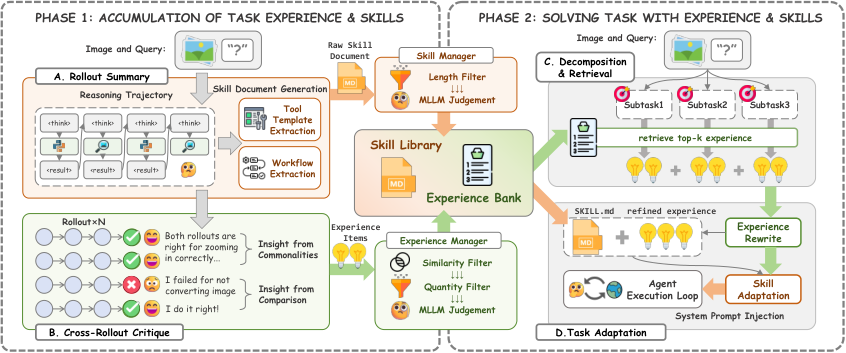
Figure 1
图解:这是 XSkill 的总流程图。左侧是 Phase I(知识积累) ,从多条 rollout 轨迹里做总结、对比批判、层级合并;右侧是 Phase II(任务求解) ,先任务分解再检索经验,随后做视觉上下文改写,最后把适配后的技能注入执行模型。横向看是“学”,纵向看是“用”,闭环看是“持续进化”。
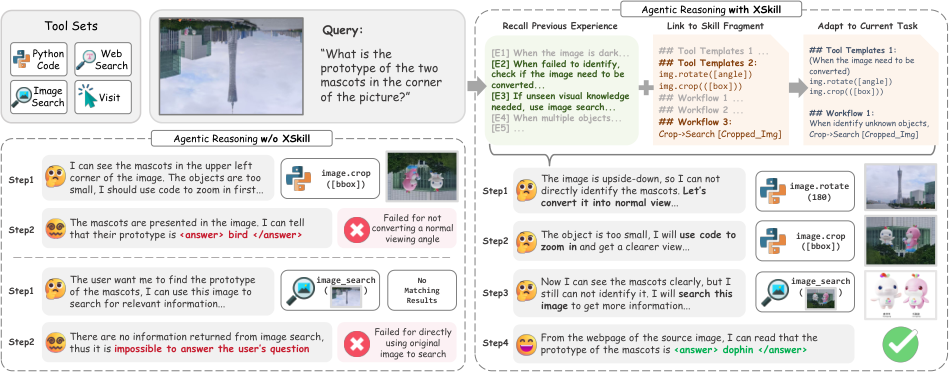
Figure 2
图解:这张对比图展示了“有无 XSkill”在同一多模态任务上的轨迹差异。横向通常是两条推理链;纵向是步骤推进。没有 XSkill 的轨迹出现视觉语义错位(如未做旋转/裁剪),而有 XSkill 的轨迹会先调用相关经验和技能片段,再生成更贴地的执行计划。
数学建模:把“会做题”拆成可管理知识对象
论文把任务建模成 POMDP,并定义两个知识对象。
1)Skill 定义(任务级)
Skill 记为 ,形式化为三元组:
- • 元数据 (名称、描述、版本)
- • 工作流
- • 可复用模板 (代码/查询模板)
2)Experience 定义(动作级)
Experience 记为 ,形式化为:
- • 触发条件
- • 建议动作
- • 检索向量
并约束长度 ,避免经验冗长失焦。
3)总体目标
给定任务 (文本查询 + 图像集),构建外部知识库 ,最大化正确率:
Phase I:知识积累(从 rollout 到可复用知识)
A. Rollout Summary(视觉扎根总结)
对每个训练任务做 次 rollout,交给知识模型总结:
关键不是“复述轨迹”,而是把 视觉证据与动作决策绑定 :
例如“因为检测到图像倒置,所以触发旋转;因为对比度低,所以触发增强”。
B. Cross-Rollout Critique(跨轨迹对比批判)
利用成功/失败轨迹对比,提炼经验更新操作:
操作类型包括 add 和 modify,本质是在做“经验库自演化”。
C. Knowledge Consolidation(层级合并与压缩)
- • 经验层:基于余弦相似度阈值 做合并去重;
- • 技能层:对技能文档做段落级更新/合并/删除;
- • 超长时触发质量驱动精炼(保泛化、去特例)。
这一块决定了系统能否长期运行不崩:否则知识越积越乱,后续检索会被噪音拖垮。
Phase II:任务求解(先拆再找,再按图改写)
A. 任务分解检索(不是直接拿原 query 去搜)
先把任务拆成子需求 ,每个子任务独立检索:
这样能覆盖“同一任务中的多技术面向”(如图像修复 + 逻辑校验 + 错误恢复)。
B. Experience Rewrite(经验改写)
把通用经验改写为当前图像语境下可执行建议:
C. Skill Adaptation(技能裁剪与融合)
把全局技能文档裁剪成任务可用版本:
然后注入执行模型提示词。注意这里是“参考式注入”,不是强制脚本,给模型保留 improvisation 空间。
实验设置:覆盖 3 大域、5 个基准、4 个闭源骨干模型
数据与任务域
- • 视觉工具推理 :VisualToolBench、TIR-Bench
- • 多模态搜索 :MMSearch-Plus、MMBrowseComp
- • 综合高难任务 :AgentVista
工具配置
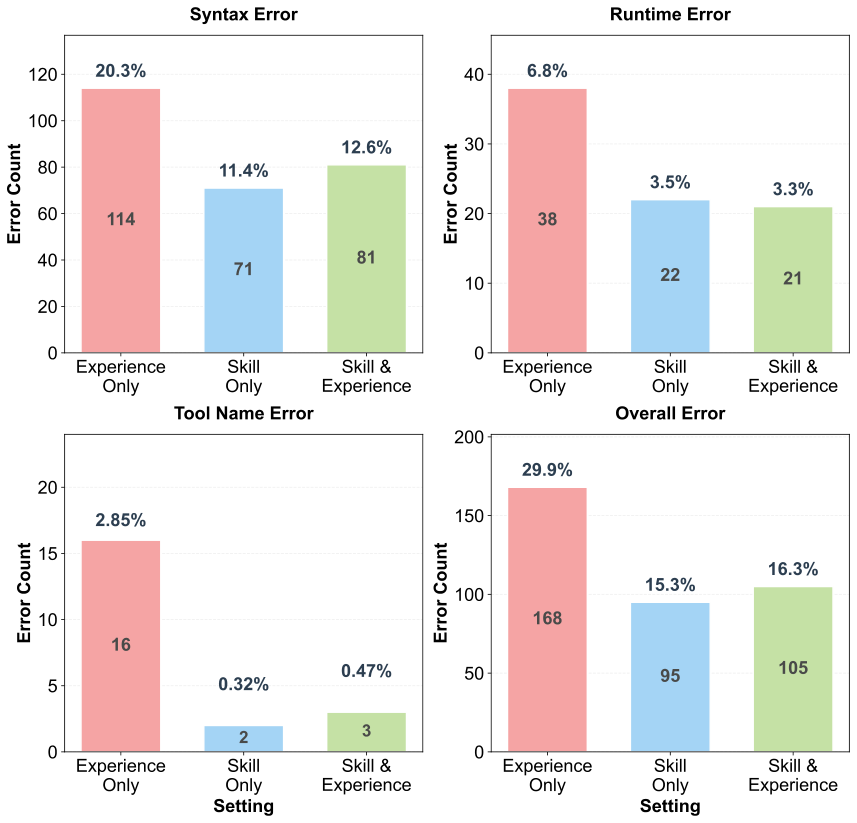
Figure 3
图解:该图的横轴是不同错误类型(如语法错误、运行时错误、工具名错误),纵轴是错误比例/次数。它直接说明 Skill 会显著压低结构性执行错误,尤其是 syntax/tool-name 这类“低级但致命”错误。
评价指标
- • Average@4 :4 次 rollout 的平均成功率(稳定性)
- • Pass@4 :4 次 rollout 至少一次成功(上限能力)
主结果:XSkill 在几乎所有设置中都明显领先
论文报告的核心趋势非常稳定:
- • 相比仅工具基线,XSkill 在不同模型上 Average@4 提升 2.58~6.71 点。
- • 在高难 TIR-Bench(Gemini-3-Flash)上,XSkill 达到 47.75% ,比最强基线 Agent-KB 高 11.13 点。
- • 在知识迁移场景(GPT-5-mini、o4-mini 使用 Gemini-3-Flash 累积知识)中仍有明显收益,说明外部知识结构具有跨模型可迁移性。
消融与行为分析:为什么双流设计有效?
消融结论(VisualToolBench, Gemini-2.5-Pro)
- • 去掉 Experience:Average@4 从 30.49 降到 27.45(-3.04)
- • 去掉 Skill:降到 26.64(-3.85)
- • 说明两者都重要,且 Skill 在该数据集上贡献更大。
行为层解释
- • Skill 主要抑制执行错误 :总错误率从 29.9% 降到 15.3%,语法错误和工具名错误显著减少。
- • Experience 主要提升编排灵活性 :
在 VisualToolBench 中 Code Interpreter 使用占比从 66.63% 提升至 76.97%;
在 MMSearch-Plus 中 image search 占比明显提升,说明策略更“按任务选工具”。
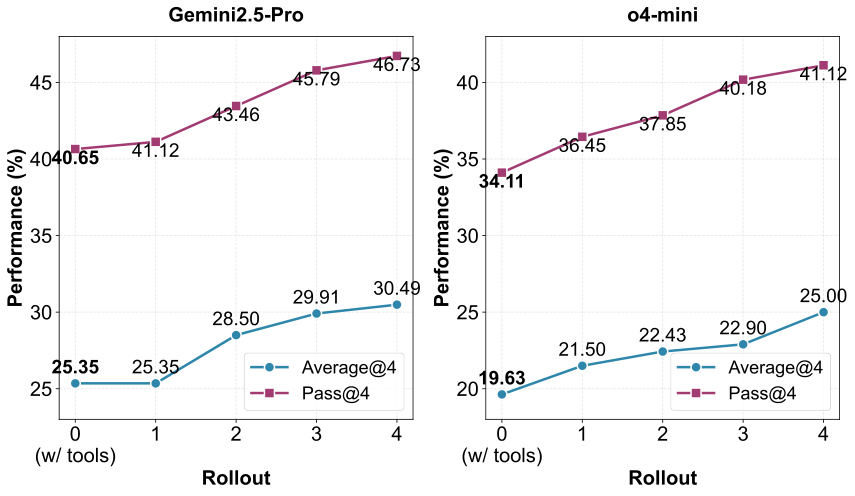
Figure 4
图解:横轴是 rollout 数量 ,纵轴是 Average@4 / Pass@4。随着 增加,两项指标持续上升,且 Pass@4 上升更陡。这说明多路径 rollout 提供了更丰富的对比样本,帮助知识提炼更稳。
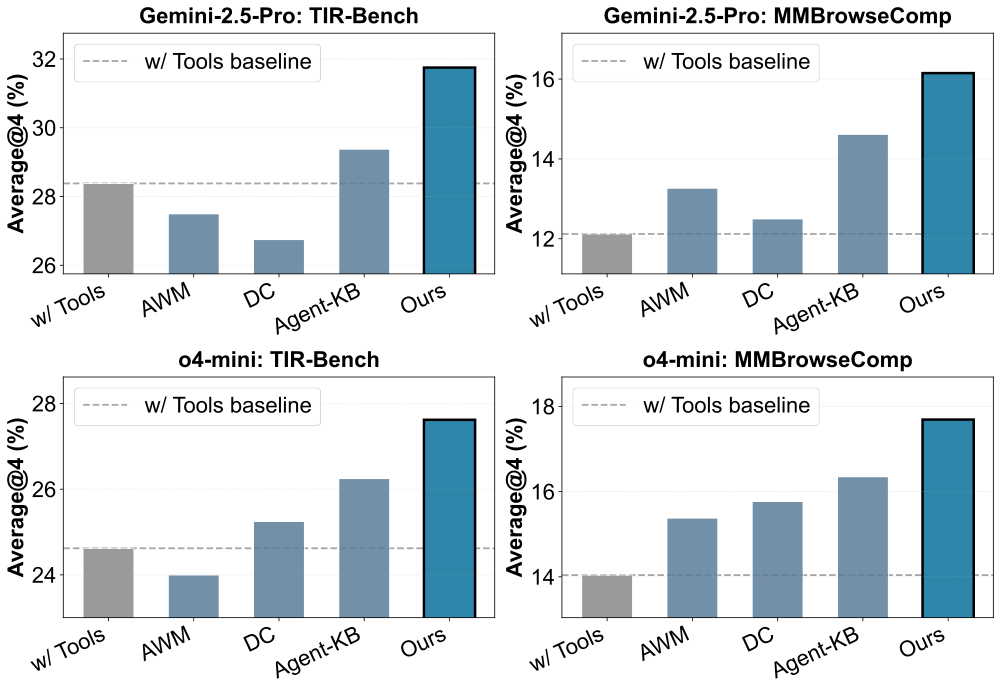
Figure 5
图解:这是跨任务零样本迁移结果。横轴是目标基准(如 TIR-Bench、MMBrowseComp),纵轴是 Average@4。XSkill 曲线/柱形整体高于基线,并高于灰色工具基线参考线,说明其泛化不是“记住题目”,而是学到可迁移方法。
附录中的关键信息:复现与扩展价值很高
1)开源模型迁移结果(Qwen3-VL)
迁移到 Qwen3-VL-235B/32B 时出现“均值不总是涨、Pass@4 常上涨”的现象。
这说明较弱的基础模型在吸收外部知识时可能受到干扰,但探索次数增加会提升“至少一次成功”的概率。
2)关键超参数
- • Rollout 数
- • 检索 top-
- • 经验合并阈值
- • 经验库上限 120 条
- • 技能文档精炼阈值 1000 词
- • 执行温度 0.6,分解/改写温度 0.3
3)工具定义很工程化
Web Search / Image Search / Visit / Code Interpreter 四工具都给了参数规范与调用约束,适合直接落地到 agent framework。
论文的价值与局限
价值
- • 给出了多模态 Agent 的 非参数持续学习 实用路径;
- • 双流知识设计把“高层流程”与“低层战术”解耦,解释性更强;
- • 跨模型转移能力证明外部知识库具备平台化潜力。
局限与风险
- • 知识库可能传播偏差(尤其在跨模型迁移时);
- • 需要知识审计机制,否则“错误经验”会进入闭环;
- • 当前实验主要是单轮“积累后测试”,虽架构支持长期迭代,但真实长期漂移问题仍待更多实证。
对实战系统的启发
-
- 先把你现有 Agent 的历史轨迹结构化成两层:
skills.md+experiences.json。
- 先把你现有 Agent 的历史轨迹结构化成两层:
-
- 不要只按 query 检索,先做 task decomposition 再多路检索。
-
- 强制增加一层“经验改写器”,防止把通用建议硬塞给当前任务。
-
- 给知识库加去重与质量门槛,否则 2~3 周后就会知识膨胀失效。
-
- 对跨模型迁移设置白名单与审计,避免把偏差一起迁移过去。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献192条内容
已为社区贡献192条内容

所有评论(0)