论文导读 | 关系型数据库基础模型的演进之路
近年来,基础模型(Foundation Models)在自然语言处理(NLP)和计算机视觉(CV)领域掀起了革命性的浪潮,展现出了跨领域、跨任务的通用泛化能力 。然而,在企业界最为广泛应用的数据存储形式——关系型数据库(Relational Database, RDB)领域,构建一个通用的基础模型却面临着巨大的挑战 。
由于关系型数据库包含了多张通过主键(Primary Keys, PKs)和外键(Foreign Keys, FKs)相互关联的表,数据呈现出复杂的图结构和异构的模式(Schemas) 。长期以来,业界只能依赖“一库一模”的定制化方案,这种特定于实例(Instance-specific)的方法存在诸多痛点:首先,收集训练数据和训练模型的开销极高 ;其次,模型泛化能力差,难以应对工作负载或数据的偏移(Data drift) ;最后,对于每一个新的数据库和新任务,都需要从头开始重新训练模型,造成了巨大的重复劳动 。为了打破这一局限,基于预训练的关系型数据基础模型成为研究热点。
在这条充满挑战的探索之路上,学术界近期涌现了三项具有里程碑意义的工作:TabPFN [1]、Griffin [2] 和 Relational Transformer(RT)[3]。本文将深入梳理这一领域的演进脉络,了解“关系型基础模型”的最新进展。
一、TabPFN:单表数据的Transformer奇迹
在探索关系型数据库的基础模型之前,我们必须先攻克“单表数据(Tabular Data)”这一基础难题。在过去的20年中,梯度提升决策树(Gradient-Boosted Decision Trees, GBDT)在表格数据处理上一直占据主导地位,而传统的深度学习方法往往难以与之匹敌 。TabPFN [1](发表于 Nature 2025)的出现打破了这一僵局,它是一种专门针对表格数据设计的基础模型 。
-
上下文学习(In-Context Learning, ICL)框架:TabPFN借鉴了大语言模型中取得巨大成功的上下文学习机制 。它将整个数据集作为输入,在一个前向传播(Forward pass)过程中同时完成训练和预测 。
-
新颖的架构设计:TabPFN将表格中的每一个单元格(Cell)视为一个独立的Token 。模型在行和列两个方向上应用自注意力机制(Self Attention),从而有效地捕捉数据间的依赖关系 。
-
合成数据预训练:为了避免数据隐私问题并提供无限的训练数据,TabPFN完全在合成数据集上进行预训练 。这些数据是通过结构因果模型(Structural Causal Models, SCMs)生成的,能够模拟真实的复杂特征和因果关系 。
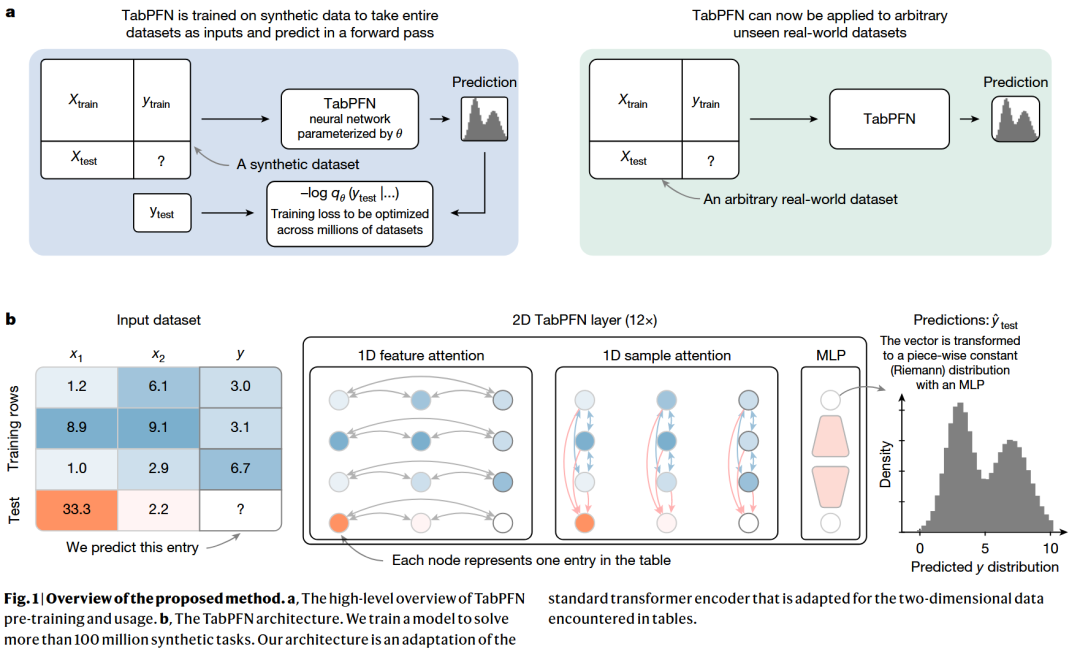
通过这种设计,TabPFN在处理包含最多10,000个样本和500个特征的小型数据集时,展现出了极其卓越的性能 。在分类任务中,它仅需2.8秒就能击败经过4小时精心调优的最强基线模型组合 。
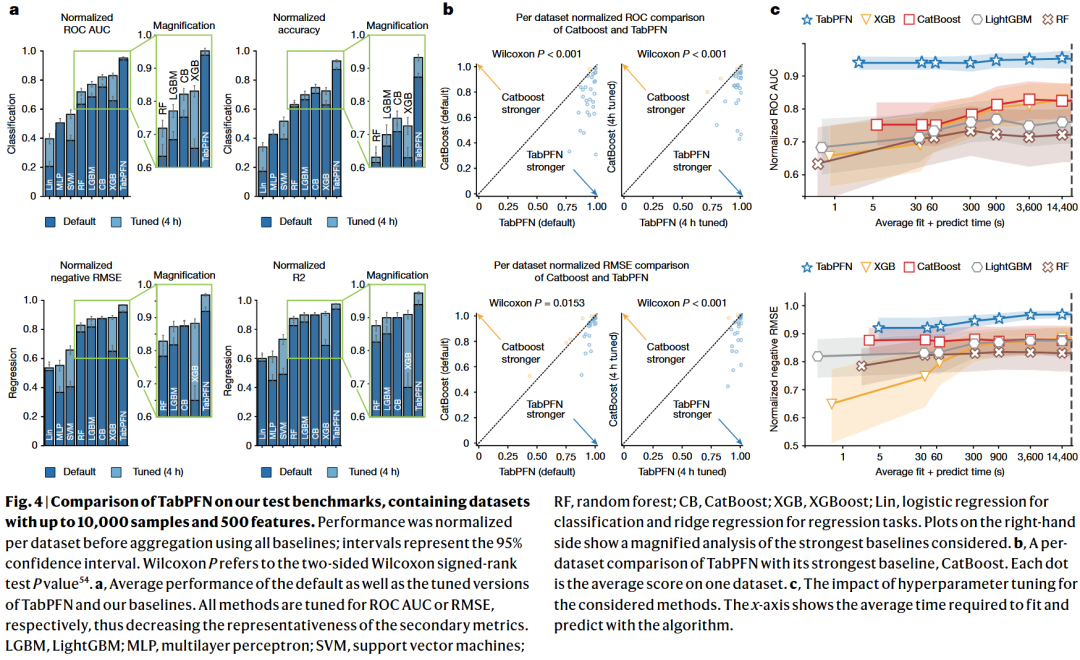
局限性:尽管TabPFN在单表任务上大放异彩,但它仅能处理单一表格 。而在真实的商业场景中,简单地将关系型数据库展平(Flattening)为一张单表,会导致严重的信息丢失 。因此,我们需要真正能够理解表间关系的图驱动模型。
二、Griffin:迈向图驱动的关系型基础模型
为了解决跨表学习的难题,Griffin [2](被 ICML 2025 接收)作为首个专为关系型数据库(RDBs)设计的基础模型尝试,提供了一套行之有效的解决方案 。
Griffin的核心思路是将关系型数据库转化为异构图(Heterogeneous Graph) 。在图中,表格中的每一行(Row)被建模为一个节点(Node),而主键和外键(PK-FK)之间的关联则构成了节点之间的边(Edges) 。
-
统一的输入编码器(Unified Data Encoder):与以往为每个任务单独设计嵌入层的做法不同,Griffin采用了一个预训练的文本编码器来处理所有的分类和文本特征,同时使用一个预训练的浮点编码器(Float encoder)来处理数值型特征 。这使得模型能够将异构数据映射到统一的语义空间中 。
-
交叉注意力与MPNN架构:为了提取节点(即表格行)内部的丰富信息,Griffin引入了交叉注意力模块(Cross-attention module),允许模型在同一行内灵活地收集各个单元格的信息 。随后,模型利用增强的消息传递神经网络(Message-Passing Neural Networks, MPNNs),在同一关系类型内部进行聚合,再跨越不同关系类型融合特征,从而完美捕捉表间的结构依赖 。
-
统一的任务解码器:该模型共享了一个浮点解码器用于处理各类回归任务,并使用了一个集成了目标类别文本嵌入的分类头,实现了任务输出的统一 。
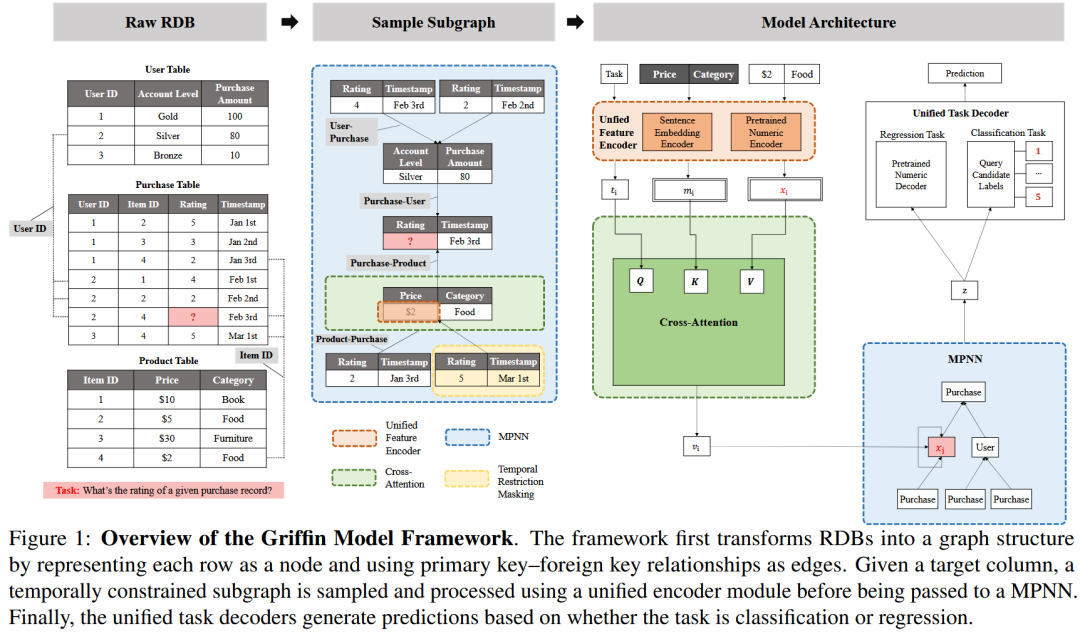
在训练策略上,Griffin在一个包含超过1.5亿个节点的庞大数据集上进行了训练 。它首先在单表数据集上进行掩码单元格补全任务(Masked cell completion task)的无监督预训练 。随后,在多种单表和关系型数据库任务上进行联合监督微调(Joint Supervised Fine-Tuning, SFT) 。
Griffin的实验揭示了关于模型迁移能力(Transferability)的重要洞察:预训练数据集与下游任务的相似性(Similarity)和多样性(Diversity)是驱动模型迁移成功的关键 。与没有经过预训练的基线模型相比,Griffin在多种下游任务和低数据场景中展现出了更强或相当的性能 。
三、Relational Transformer (RT):完全基于注意力机制的关系型预训练模型
虽然Griffin证明了将关系型数据库转化为图结构并应用GNN的有效性,但预训练Transformer架构在实现零样本(Zero-Shot)泛化方面展现出了更大的潜力。Relational Transformer [3](RT,被 ICLR 2026 接收)彻底颠覆了此前的设计,它无需针对特定任务或数据集进行微调,也无需提供上下文示例,即可直接对未知数据库进行零样本预测 。
RT之所以能够跨越异构模式(Heterogeneous schemas)实现Zero-Shot泛化,主要归功于以下三大核心创新 :
-
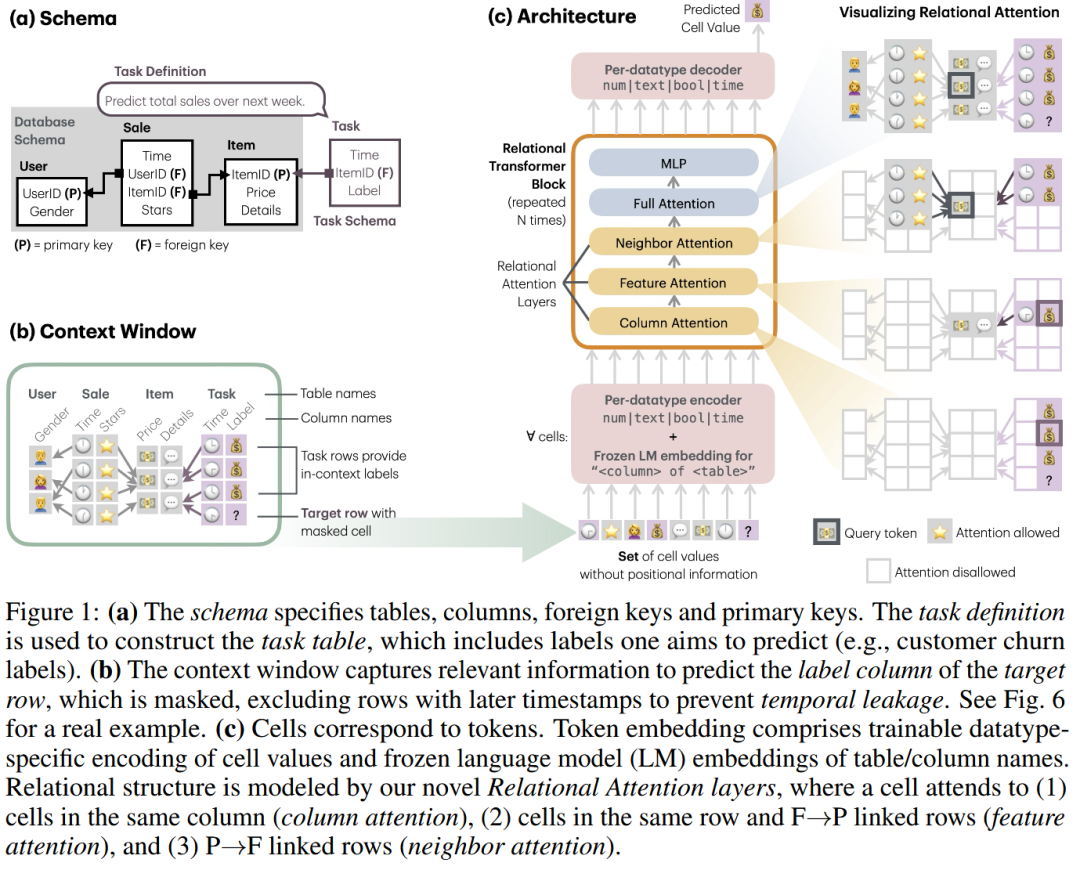
单元格级分词(Cell-level Tokenization):RT没有像传统GNN那样将整行视为一个节点,而是将数据库中的每一个单元格都作为一个Token 。每一个Token的嵌入向量,不仅仅包含单元格的具体数值,还融合了来自冻结语言模型(Frozen LM)生成的表名和列名元数据(Metadata)嵌入 。这种细粒度的表示方法使得任意的下游任务都可以被自然地转化为掩码Token预测(Masked token prediction)问题 。
-
任务表提示(Task Table Prompting):在面对全新任务时,RT通过向数据库中追加一张虚拟的“任务表”来进行任务描述 。这张表中包含了需要预测的目标以及相关的外键和时间戳 。通过这种基于提示(Prompting)的方式,模型可以在不更新权重的情况下,直接理解各类预测任务(如用户流失预测、销售额预测等) 。
-
关系注意力机制(Relational Attention):为了显式地捕捉关系型数据库的内在结构,RT设计了一种新颖的注意力机制,替代了标准的全局注意力 。它包含四种特殊的注意力掩码(Masks) :
-
列注意力(Column attention):限定Token只能与同一列的Token计算注意力,帮助模型学习该列的数值分布规律 。
-
特征注意力(Feature attention):允许Token与同一行的单元格,以及通过外键指向主键(F->P)链接的父行进行信息交互,实现实体的特征融合 。
-
邻居注意力(Neighbor attention):允许Token与通过主键指向外键(P->F)链接的子行进行注意力计算,这起到了类似GNN消息传递的作用,能够聚合来自子实体的信号 。
-
全注意力(Full attention):在上述结构化约束的基础上,补充了不受限制的成对交互,保证了Transformer强大的表达能力 。
-
惊艳的零样本表现:在RelBench基准测试上,RT展现出了极强的Zero-Shot能力 。对于二分类任务,一个仅有22M(两千两百万)参数的RT模型,只需一次前向传播,其零样本预测的AUROC就能达到完全监督训练状态下93%的性能 。作为对比,高达27B(两百七十亿)参数的Gemma大语言模型,在相同任务上的表现仅为84% 。更重要的是,RT在所有分类任务中稳定地超越了基于实体均值(Entity Mean)的朴素基线模型,证明了其切实掌握了关系型数据的深度模式 。
四、结语
从解决单表数据痛点的TabPFN ,到首次构建图驱动跨表学习框架的Griffin ,再到实现异构模式间真正零样本泛化的Relational Transformer (RT) ,关系型数据库基础模型正在经历一场从无到有、从弱到强的技术蜕变。
未来,随着数据生成技术的完善和神经网络架构的进一步创新,关系型基础模型(Relational Foundation Models)不仅将大幅降低企业构建预测性分析的门槛,更有望深入数据库引擎的底层,彻底改变数据库系统的优化和运行方式 。这无疑是机器学习社区与数据库社区双向奔赴的最具潜力的研究方向之一!
参考文献
[1] Hollmann, Noah, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model. Nature 2025.
[2] Wang, Yanbo, Xiyuan Wang, Quan Gan, Minjie Wang, Qibin Yang, David Wipf, and Muhan Zhang. Griffin: Towards a graph-centric relational database foundation model. ICML 2025.
[3] Ranjan, Rishabh, Valter Hudovernik, Mark Znidar, Charilaos Kanatsoulis, Roshan Upendra, Mahmoud Mohammadi, Joe Meyer, Tom Palczewski, Carlos Guestrin, and Jure Leskovec. Relational Transformer: Toward Zero-Shot Foundation Models for Relational Data. ICLR 2026.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
实验室开源产品图数据库gStore:
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)