机器学习求解流体方程被高估?Nature重磅揭秘真相(含金量极高),看完这篇少走3年弯路!

一、ML解流体方程的虚火:看似亮眼的成果藏着隐忧
用机器学习加速求解流体相关偏微分方程(PDE)是当前计算物理领域的热门方向,这类研究普遍将传统数值解法作为基线对比,动辄宣称ML模型速度提升几十上百倍。但这些成果的真实性长期缺乏系统验证:会不会存在“田忌赛马”式的不公平对比?会不会效果不好的结果都被刻意隐瞒了?这些问题不仅会误导初学者的研究方向,还会让整个领域陷入“自嗨”式的无效产出,这也是这项研究要解决的核心痛点。
二、两套“公平标尺”:戳破无效对比的伪装
研究团队首先为ML与传统解法的对比定了两条刚性规则:第一,必须在相同精度下比速度,或相同速度下比精度,不能拿高精度慢版本的传统方法,和低精度快版本的ML做不对等对比;第二,必须和对应PDE当前最高效的传统解法对比,不能故意选老旧低效的方法当“软柿子”捏。基于这两条规则,团队对所有符合条件的相关论文做了系统综述,还通过抽样统计、结果复现等方式,排查领域内的报告偏倚问题。
三、七成多成果“掺水”:正面结果几乎垄断发文
统计结果远超预期:76篇宣称ML解法优于传统方法的论文中,79%都使用了不符合规则的弱基线,要么对比时精度不对等,要么选择的传统解法本身效率极低。更夸张的是,抽样的232篇相关论文里,94.8%的摘要只提及正面结果,没有一篇单独报告负面结果;82篇纳入最终综述的论文中,93%都宣称自己的ML方法更优,仅5%承认效果不如基线。团队复现10篇高引论文结果后发现,7篇在换上公平的强基线后,传统解法反而比ML更快,之前宣称的上千倍提速大多是无效对比的产物。
四、给领域“降虚火”:从源头上避免无效研究
这篇论文相当于给过热的ML解PDE领域泼了一盆清醒的“凉水”:它首次系统证实了该领域普遍存在的基线设置不公和报告偏倚问题,打破了“ML一定比传统方法高效”的固有认知。同时团队还给出了可落地的改革建议:比如要求研究必须对比强基线、完整报告正负结果,期刊可推行研究前注册机制,设置公开的行业挑战问题,从文化和制度层面减少不当科研激励,引导领域产出真正能落地的实用成果。
五、论文图表
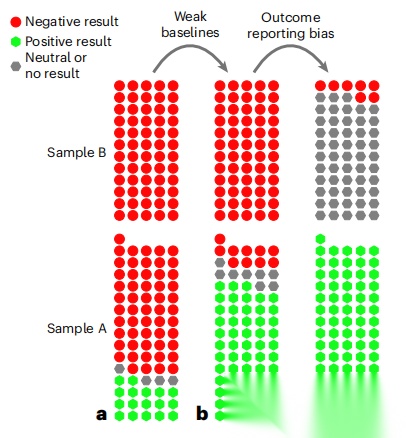
图1. 弱基线和报告偏倚对样本A和样本B的累积影响。每个圆形或六边形代表一篇文章,每种颜色代表与标准数值方法进行相对速度和精度比较的结果。a. 我们估算了使用强基线且无结果报告偏倚时的结果情况。b. 无结果报告偏倚时可能的结果示例。c. 已发表文献中的结果情况。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献104条内容
已为社区贡献104条内容

所有评论(0)