四策略融合改进SSA优化BP神经网络分类预测(MISSA-BP) 改进点文献 目前相关分类文章...
四策略融合改进SSA优化BP神经网络分类预测(MISSA-BP) 改进点文献 目前相关分类文章数量中外都不是很多 改进创新足,抓紧入手抓紧发个人感觉英文开源中文核心都不是问题 改进点:中文注释清晰 融合spm映射、自适应-正余弦算法、levy机制、步长因子动态调整4种策略改进 改进后效果非常好 收敛速度和收敛精度极少代数即完成收敛,显示均方误差 最大迭代次数:500(根据具体图像可调) 独立运行次数:30 初始种群数量:30 代码注释明确,替换数数据集即可使用,该价格只是代码
一、模型概述
MISSA-BP 分类预测模型是一款融合改进麻雀搜索算法(Modified Improved Sparrow Search Algorithm, MISSA)与反向传播(Back Propagation, BP)神经网络的智能分类工具。该模型通过 MISSA 算法优化 BP 神经网络的初始权值与阈值参数,有效解决了传统 BP 神经网络易陷入局部最优、收敛速度慢等问题,显著提升了分类预测的准确性与稳定性。模型适用于多类别数据分类场景,支持从数据集读取、预处理、模型训练到性能评估的全流程自动化执行,具备良好的通用性与工程实用性。
二、核心功能模块
(一)数据处理模块
- 数据读取与初始化:支持读取 Excel 格式数据集,自动识别数据中的类别信息与样本特征。数据集需满足“最后一列为类别标签,其余列为特征变量”的格式规范,模型会自动统计类别数量与总样本数,为后续数据划分提供基础。
- 数据集划分:采用分层抽样策略划分训练集与测试集,默认训练集占比 70%,测试集占比 30%。该策略可保证各分类在训练集与测试集中的分布比例一致,避免因数据分布不均导致的模型偏倚。支持通过参数调整训练集比例,满足不同场景需求。
- 数据预处理:
- 数据转置:将特征矩阵调整为 BP 神经网络要求的输入格式(特征数×样本数);
- 归一化处理:采用 mapminmax 函数将特征数据映射至 [0,1] 区间,消除不同特征量纲差异对模型训练的影响;
- 标签编码:通过 ind2vec 函数将类别标签转换为独热编码格式,适配神经网络的输出层设计。
(二)BP 神经网络构建模块
- 网络结构配置:采用“输入层-隐藏层-输出层”的三层神经网络结构,各层节点数动态适配数据集特征:
- 输入层节点数:等于数据集特征维度;
- 隐藏层节点数:默认设为 5,支持通过参数手动调整;
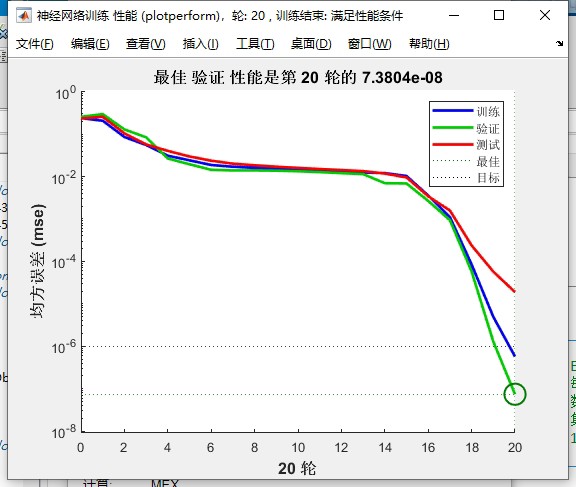
- 输出层节点数:等于数据集中的类别数量。 - 训练参数设置:默认训练次数为 1000 次,目标误差为 1e-6,学习率为 1e-4。支持关闭训练过程中的可视化窗口以提升运行效率,也可根据需求调整训练参数以平衡训练速度与模型精度。
(三)MISSA 优化模块
- 优化目标定义:以 BP 神经网络的分类错误率作为优化目标函数,通过最小化错误率实现权值与阈值的最优搜索。目标函数计算基于训练集预测结果,错误率越低表示模型分类性能越好。
- 优化参数维度:优化参数包含 BP 神经网络的全部权值与阈值,具体维度为“输入层-隐藏层权值数 + 隐藏层偏置数 + 隐藏层-输出层权值数 + 输出层偏置数”,确保覆盖神经网络的核心可优化参数。
- 改进麻雀搜索算法核心机制:
- 种群初始化:采用分段非线性映射策略生成初始种群,提升种群多样性,为全局搜索奠定基础;
- 生产者更新:融合正余弦算法的搜索策略,通过自适应权重与随机因子动态调整搜索方向,平衡全局探索与局部开发能力;
- 跟随者更新:引入 Levy 飞行机制,增强算法跳出局部最优的能力,对不同位置的跟随者采用差异化更新策略,提升搜索效率;
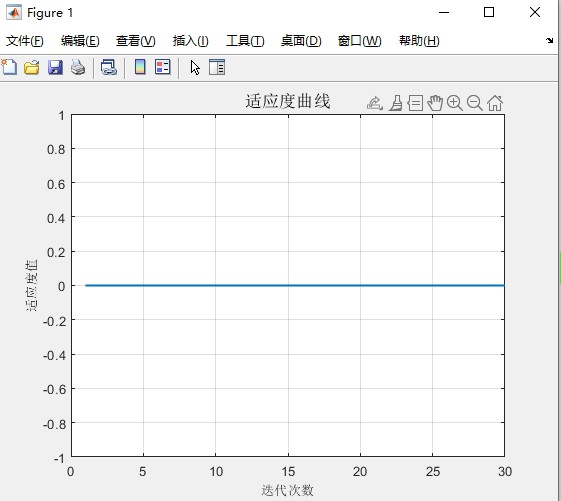
- 危险感知机制:随机选取 20% 的种群个体作为“危险感知麻雀”,通过动态调整步长因子,进一步降低算法陷入局部最优的概率。 - 优化过程控制:支持配置种群规模(默认 20)与最大迭代次数(默认 30),优化过程中实时记录全局最优适应度值,生成收敛曲线,直观反映算法搜索过程。
(四)模型训练与预测模块
- 最优参数赋值:MISSA 算法搜索完成后,将得到的最优参数(权值与阈值)赋值给 BP 神经网络,替代随机初始化的参数,为模型训练提供优质初始条件。
- 模型训练:基于优化后的参数启动 BP 神经网络训练,训练过程遵循梯度下降原理,通过反向传播不断调整参数,直至达到预设训练次数或目标误差。
- 预测推理:训练完成后,分别对训练集与测试集进行预测,通过 sim 函数得到神经网络的输出结果,再通过 vec2ind 函数将独热编码格式的预测结果转换为原始类别标签,用于后续性能评估。
(五)性能评估与可视化模块
- 核心评估指标:
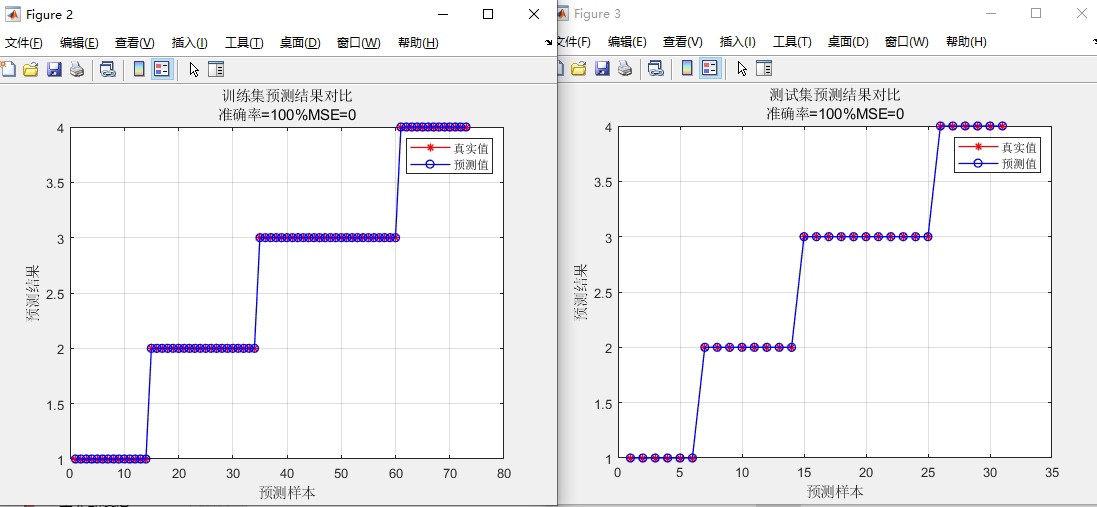
- 准确率:统计预测结果与真实标签一致的样本占比,直观反映模型分类能力;
- 均方误差(MSE):衡量预测值与真实值的偏差程度,MSE 越小表示预测精度越高。 - 可视化输出:
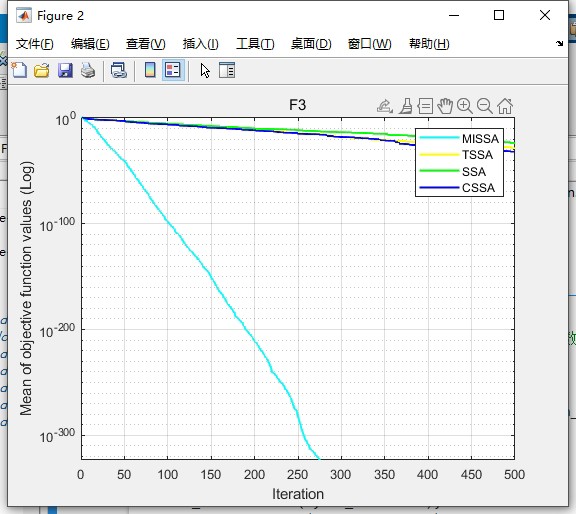
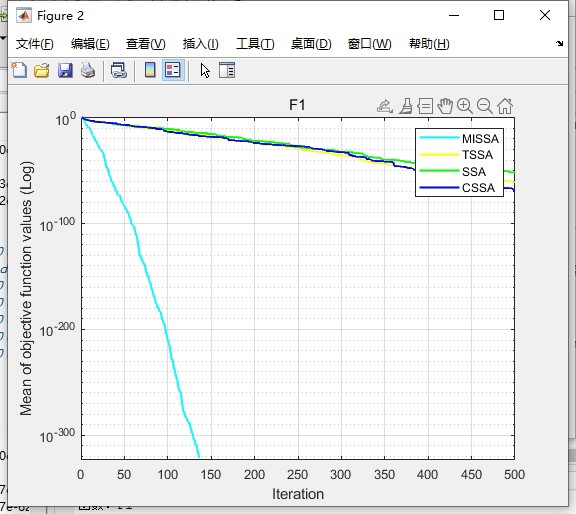
- 适应度曲线:展示 MISSA 算法迭代过程中全局最优适应度值的变化趋势,反映算法收敛速度与稳定性;
- 预测结果对比图:分别绘制训练集与测试集的真实标签与预测标签对比曲线,直观呈现模型预测效果;
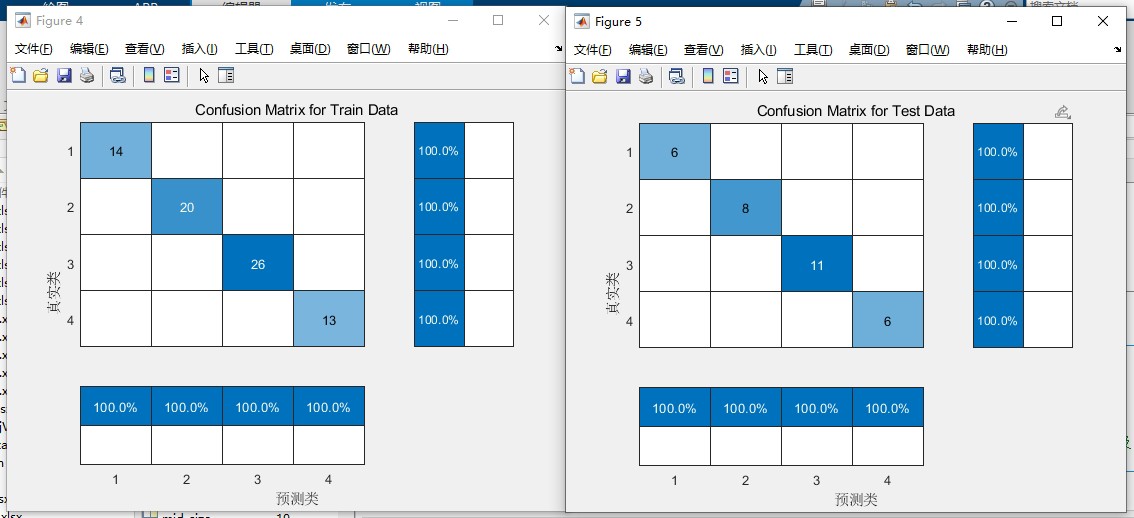
- 混淆矩阵:通过 confusionchart 函数生成训练集与测试集的混淆矩阵,支持行列归一化显示,可详细分析模型在各分类上的预测性能(如精确率、召回率等)。
三、模型工作流程
- 环境初始化:清空工作空间变量,关闭报警信息,为模型运行提供干净的环境;
- 数据处理:读取数据集,完成划分、预处理与标签编码;
- 神经网络构建:根据数据特征动态配置网络结构与训练参数;
- MISSA 优化:启动改进麻雀搜索算法,搜索最优权值与阈值参数;
- 模型训练:将最优参数赋值给神经网络,启动训练过程;
- 预测推理:对训练集与测试集进行预测,转换预测结果格式;
- 性能评估:计算准确率与 MSE,生成可视化图表;
- 结果输出:展示评估指标与可视化结果,完成分类预测任务。
四、适用场景与使用说明
(一)适用场景
适用于多类别分类任务,如故障诊断、图像识别、数据挖掘等领域。数据集需满足“特征变量为数值型,类别标签为离散型”的要求,建议样本数量不少于 100 条,以保证模型训练的充分性。
(二)使用说明
- 数据集准备:将数据整理为 Excel 格式,确保最后一列为类别标签,其余列为特征变量,保存为“数据集.xlsx”并置于工作目录下;
- 参数调整(可选):根据实际需求修改训练集比例、隐藏层节点数、种群规模、最大迭代次数等参数;
- 运行模型:执行主函数,模型将自动完成数据处理、优化训练、预测评估全流程;
- 结果解读:通过输出的准确率、MSE 指标与可视化图表评估模型性能,混淆矩阵可用于分析模型在特定类别上的表现短板。
五、模型优势
- 优化机制先进:MISSA 算法融合正余弦搜索、Levy 飞行等策略,有效提升了参数搜索的全局最优性,解决了传统 BP 神经网络初始参数敏感问题;
- 自动化程度高:从数据读取到结果输出全程自动化,无需手动干预数据预处理与参数配置,降低使用门槛;
- 评估体系完善:提供准确率、MSE、混淆矩阵等多维度评估指标,配合可视化图表,便于用户全面掌握模型性能;
- 扩展性强:支持调整神经网络结构、优化算法参数、训练集比例等关键参数,可根据具体场景灵活适配,具备良好的工程扩展性。
四策略融合改进SSA优化BP神经网络分类预测(MISSA-BP) 改进点文献 目前相关分类文章数量中外都不是很多 改进创新足,抓紧入手抓紧发个人感觉英文开源中文核心都不是问题 改进点:中文注释清晰 融合spm映射、自适应-正余弦算法、levy机制、步长因子动态调整4种策略改进 改进后效果非常好 收敛速度和收敛精度极少代数即完成收敛,显示均方误差 最大迭代次数:500(根据具体图像可调) 独立运行次数:30 初始种群数量:30 代码注释明确,替换数数据集即可使用,该价格只是代码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 24
24 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)