超详细的openclaw原理
一.什么是openclaw?
openclaw是一个开源的、高度可拓展的 AI Agent框架。最大的特点在于,输出不再局限与文字聊天,而是真正能执行指令,这也是其爆火的原因。
二.部署方式
1.本地部署(推荐)
一般是通过mac本地部署,通过命令就能一键安装
优势:
1.数据安全,所有数据都在本地,只有少量数据会发送给大模型
2.可以在本地干活,如果网站已经登陆过了,openclaw可以轻松拉取信息。同时iOS生态好,数据互通,例如在mac上写备忘录、增加提醒事项,在手机上也能查看
3.mac有统一内存优势,能本地跑一些小模型
劣势:
1.部署和配置比后面两种方式稍复杂
2.软件部署
通过下载软件部署,例如:EasyClaw、QClaw
优势:
1.简单方便,开箱即用
2.界面比openclaw的dashboard美观
3.也是部署在本地的,可以在本地做一些操作
劣势:
1.灵活性差,且是黑盒运行,没有运行日志
2.成本比本地部署高
3.云部署(不推荐)
部署在云服务器上,例如Kimiclaw
优势:
1.开箱即用,适合简单体验的用户
劣势:
1.功能受限,例如想登陆某个网站,配置登陆信息非常困难
2.成本比本地部署高
三.原理
1.整体架构
一个完整的请求链路是:多种IM渠道 -> gateway -> agent核心 -> ReAct框架(llm + 工具执行) -> 结果回传IM
1.gateway:主要的功能是路由,将IM的消息转换为agent请求,可以配置路由关系,例如将来自飞书的消息转发给agentA,将Telegram的消息转发给agentB
2.agent:核心是ReAct框架,利用llm完成任务拆解、任务规划,然后循环调用工具完成目标。虽然没用到mcp,但流程跟mcp的流程一样。
3.tool/skill:所有任务底层的执行者,如果提出一个需求,是所有的tool怎么组合都完成不了的,那么这个需求就不可能完成。现在框架有了,需要完善tool/skill,做更多有实际价值的skill,不然把openclaw吹的天花乱坠,都无法真正落地。
2.记忆机制
这是影响agent效果的非常关键的因素。
openclaw的用户经常用到后面会发现(其实刚开始用也一样),明明只输入了一小句话,为什么消耗了大量token,这是由于openclaw自动携带了大量的记忆信息,也就是所谓的上下文
我把openclaw记忆机制分为短期记忆、长期记忆
1.短期记忆
短期记忆指的是会话历史(session history)
OpenClaw 所有的会话历史都存储在~/.openclaw/sessions/session_id.jsonl 文件中,JSONL 每一行都是一个独立的 JSON 对象,每个json信息都会以追加的方式写入对应的jsonl文件中,结构如下所示
![]()
可以看到有请求大模型的内容、大模型选择执行哪些工具、工具执行的结果,可以很直观地看到openclaw执行的过程
关键是openclaw是如何使用session history的
openclaw默认使用全量的session history,随着jsonl文件逐渐增大,总有一次调用大模型的时候,大模型会抛出 “上下文溢出” 错误,此时openclaw的降级策略非常值得参考。
首先openclaw需要判断出这类问题是 “上下文溢出” 的问题,使用的是模糊正则匹配
const CONTEXT_OVERFLOW_HINT_RE =
/context.*overflow|context window.*(too (?:large|long)|exceed|over|limit|max(?:imum)?|requested|sent|tokens)|prompt.*(too (?:large|long)|exceed|over|limit|max(?:imum)?)|(?:request|input).*(?:context|window|length|token).*(too (?:large|long)|exceed|over|limit|max(?:imum)?)/i;
CONTEXT_OVERFLOW_HINT_RE.test(errorMessage)面对 “上下文溢出”,主要有下面三个降级策略:
1.截取session history最近的N轮(role = user + assistant)
需要配置,位于openclaw.json中,配置如下:
{
channels: {
// 以 telegram 为例,其他渠道类似
telegram: {
// 群组/频道历史限制
historyLimit: 50,
// 私聊历史轮数限制(用户轮次)
dmHistoryLimit: 30,
// 每个私聊用户的单独覆盖配置
dms: {
"123456789": {
historyLimit: 50 // 特定用户的私聊历史限制
}
}
}
2.压缩session history,进行摘要
触发压缩条件:session history的token数 大于 模型上下文窗口的一半 * 1.2
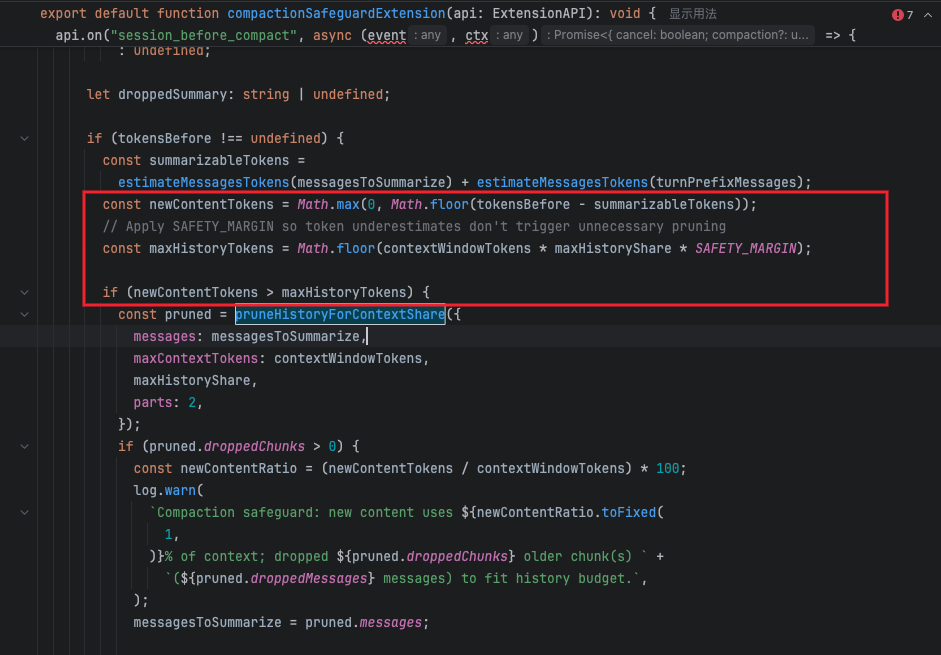
压缩流程: 分块(默认两块)-> 丢弃一块旧的session history -> 循环上述过程直至剩余session history不超出上下文的一半 -> 对丢弃的session history分别进行摘要 -> 合并摘要
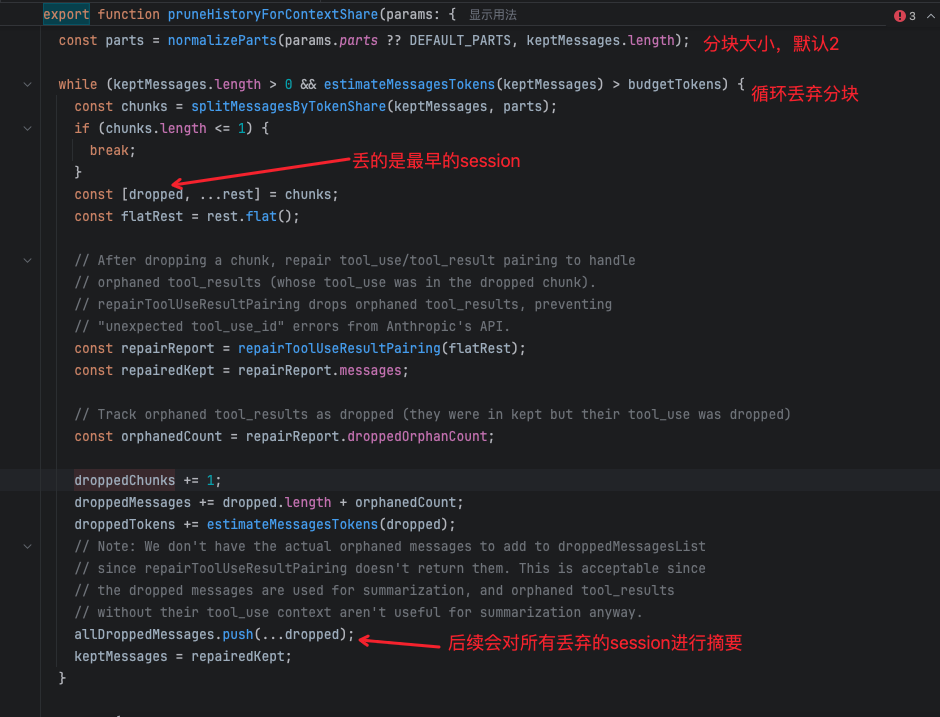
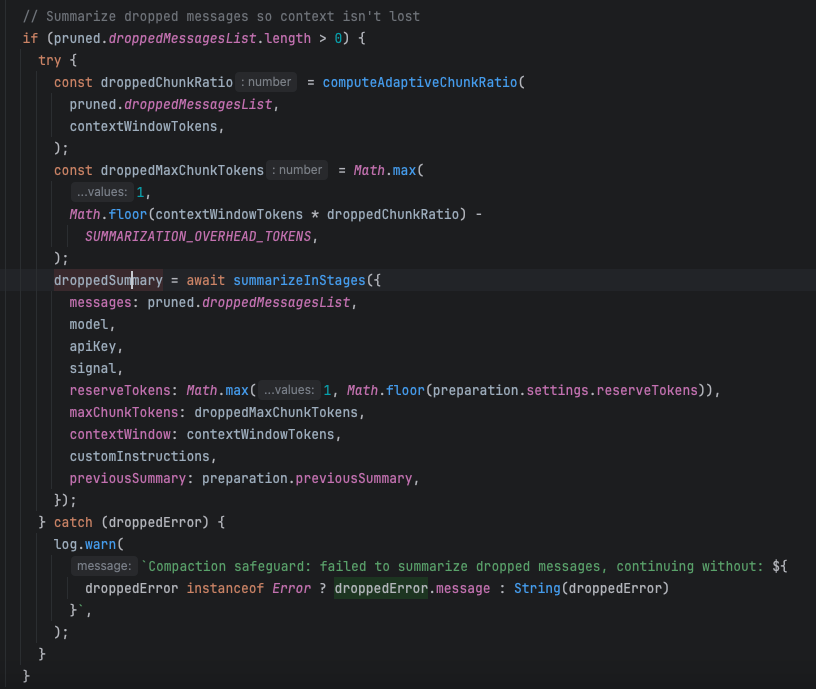
3.截断超长工具结果
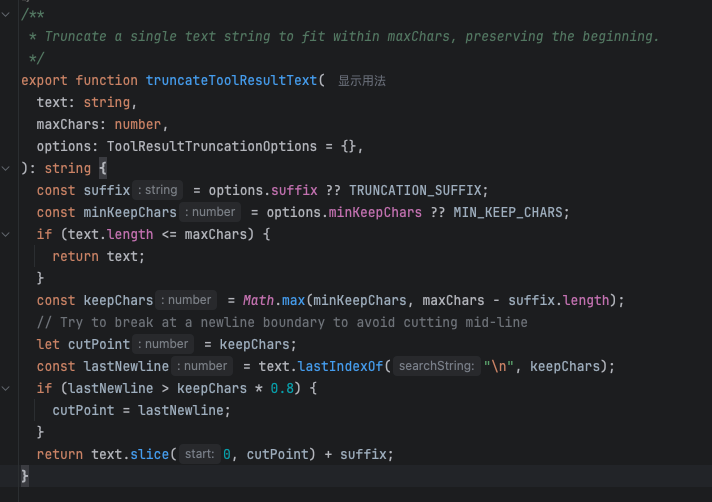
如果截取session、压缩历史信息,重复了三次依旧失败,会尝试截取超长的工具调用结果。这个手段应用的较多,许多工具会返回大量数据,例如搜索、网页抓取。
截断条件:工具执行结果长度超过 上下文窗口的 的 30% 或 超过 400,000 字符
截断方式:保留开头至少 2,000 字符,添加截断提示后缀
代码:
重置session记忆
除此以外,随着jsonl文件增大,过长的历史信息会使openclaw执行的效果变差,可以输入/reset,重置会话,保证openclaw执行的质量。
openclaw会将旧的 sessionId.jsonl 文件归档为 sessionId.jsonl.reset.{YYYY-MM-DDTHH-mm-ss.sssZ} 文件。
2.长期记忆
长期记忆有什么用?
主要是记录session记录不了的东西,比如:我告诉openclaw,我叫刘德华,我是你主人。那么我希望openclaw能长久的记住这些信息,而不是每次重置了会话,需要再告诉它一遍。这就是长期记忆的意义。
openclaw是通过workspace下的markdown文件记录长期记忆,在每次请求会将各个md内容拼到system prompt中,这部分至少有上万字符,所以必须选择支持长上下文的模型,模型的能力对openclaw的效果影响非常大,markdown文件包括AGENTS.md、IDENTITY.md、SOUL.md、TOOLS.md、USER.md,所有文件都在 ~/.openclaw/workspace下。
1.AGENTS.md(最重要) 是OpenClaw 的核心运行准则。主要包括下面几点
- 关于首次启动的初始化:通过
BOOTSTRAP.md确认身份,随后“自毁”该文件。 - 关于记忆:记忆文件包括memory/YYYY-MM-DD.md 和 MEMORY.md ,MEMORY.md只能被main session读取,如果用户要求“记住”什么,需要写入memory/YYYY-MM-DD.md 或AGENTS.md, TOOLS.md 等文件。
- 定义了行为红线,比如严禁外泄私密数据、执行破坏性命令前必须询问,优先使用
trash(放入废纸篓)而非rm(彻底删除)
2.SOUL.md 定义了OpenClaw的性格
3.USER.md 记录用户的信息:称呼、爱好等等
每次请求都会把上述内容拼到system prompt里,会限制每个文件不超过20000字符,所有文件不超过150000字符,如果有文件超过20000字符,会按照20000上限保留头部70% + 尾部20%。
最终拼接完的system prompt如下所示:
You are a personal assistant running inside OpenClaw.
## Tooling
...## Workspace
...## Workspace Files (injected)
These user-editable files are loaded by OpenClaw and included below in Project Context.# Project Context
The following project context files have been loaded:
If SOUL.md is present, embody its persona and tone. Avoid stiff, generic replies...## AGENTS.md
[AGENTS.md 内容]## SOUL.md
[SOUL.md 内容]## TOOLS.md
[TOOLS.md 内容]...
memory_search
memory_search 是 OpenClaw 实现长期记忆(Long-term Memory)的底层工具。
使用场景:
用户:“前几天那个报错解决了没?” ->
大模型决定使用memory_search工具,调用 memory_search(query="报错 错误日志 解决进度") ->
结果:在数据库中找到 2026-03-12.md 中对应的信息,发现当时记录了“已定位原因,待修复”,于是回复:“已经定位了,目前尚未修复”
存储过程:
-
底层架构:采用 SQLite + sqlite-vec。
-
利用 SQLite 的轻量稳定性存储元数据。
-
利用
sqlite-vec插件存储高维向量数据。
-
-
多维数据源:
-
/memory文件夹:包含MEMORY.md(长期精华)和YYYY-MM-DD.md(每日流水账)。 -
Sessions 文件:存储原始对话记录,确保 AI 能回溯历史细节。
-
-
动态触发机制:
-
实时监听 (Chokidar):通过文件系统事件监控,一旦手动修改了
MEMORY.md或系统自动更新了日记,索引会立即增量更新。 -
冷启动保护:在执行“首次搜索”前进行全量校准,自动清理数据库中的脏数据,确保检索结果的准确性。
-
-
双表设计:
-
chunks_vec:向量表,存储语义片段的 Embedding。 -
chunks_fts:全文搜索表,利用 SQLite FTS5 插件存储原始文本关键词索引。
-
检索过程:
检索采用混合检索策略 —— 结合 关键词检索 + 向量语义检索,可选 MMR 重排序和时间衰减,最终返回既精准又多样的检索结果
async search(query: string, opts?: { maxResults?: number; minScore?: number }): Promise<MemorySearchResult[]> {
// 1. 清理查询
const cleaned = query.trim();
// 2. 获取配置
const minScore = opts?.minScore ?? this.settings.query.minScore;
const maxResults = opts?.maxResults ?? this.settings.query.maxResults;
const hybrid = this.settings.query.hybrid;
// 3. FTS-only 模式(无嵌入提供商时的降级策略)
if (!this.provider) {
const keywords = extractKeywords(cleaned); // 提取关键词
return await this.searchKeyword(keywords, candidates);
}
// 4. 混合搜索模式
const keywordResults = await this.searchKeyword(cleaned, candidates);
const queryVec = await this.embedQueryWithTimeout(cleaned); // 生成查询向量
const vectorResults = await this.searchVector(queryVec, candidates);
// 5. 合并结果(Hybrid + MMR)
return await this.mergeHybridResults({
vector: vectorResults,
keyword: keywordResults,
vectorWeight: hybrid.vectorWeight,
textWeight: hybrid.textWeight,
mmr: hybrid.mmr, // 最大边际相关性
temporalDecay: hybrid.temporalDecay, // 时间衰减
});
}
3.Cron、Heartbeat
OpenClaw 的核心创新点之一是支持主动定时任务,打破了 AI Agent 仅能被动执行任务的局限。其主动定时任务包含两种核心类型(详细使用规则见 AGENTS.md),核心区别总结如下:
| 任务类型 | 核心特点 | 适用场景 |
|---|---|---|
| Cron | 支持精确到具体时刻配置、支持独立上下文 | 需定点执行的任务 |
| Heartbeat | 触发事件可以略有偏差,支持批量处理 | 定时检查类任务、批量执行的任务 |
1.Cron
Cron 是 OpenClaw 内置的精确定时任务系统,所有创建的定时任务均持久化存储于 ~/.openclaw/cron/jobs.json 文件中。以下为每 30 秒执行一次的「喝水提醒」任务的 JSON 配置结构,后续将对关键配置项进行说明。
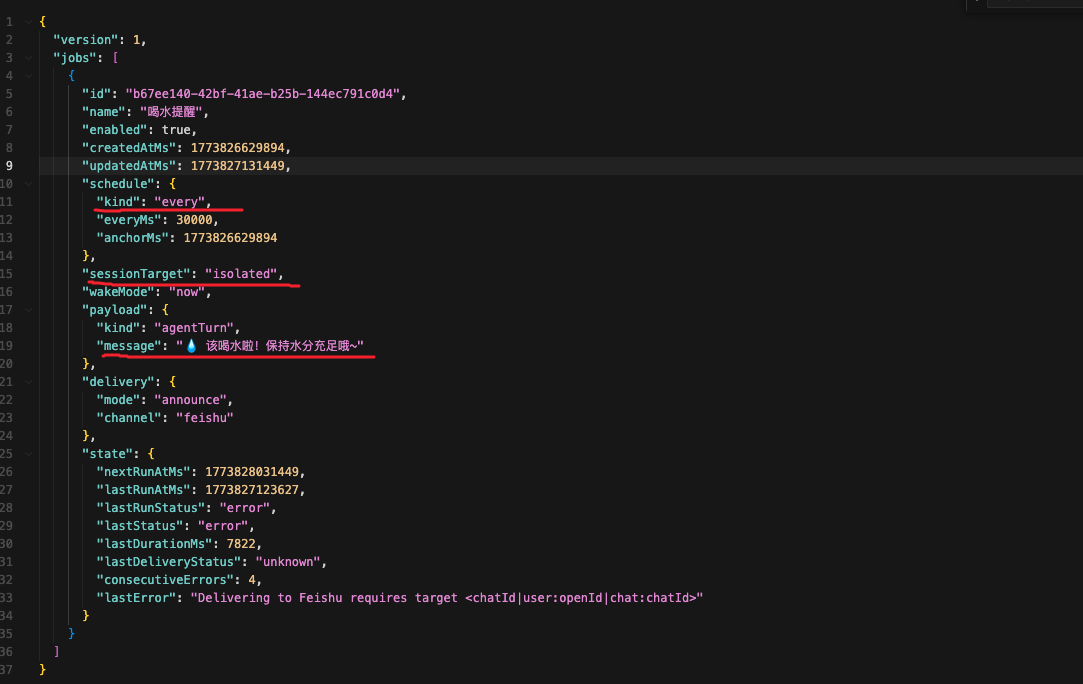
cron有三种类型
1. at,一次性执行,示例:{ kind: "at", at: "2026-03-18T10:00:00Z" }
2.every,固定间隔,示例:{ kind: "every", everyMs: 1800000, anchorMs: 123456 }
3.cron,Cron 表达式,示例:{ kind: "cron", expr: "0 */6 * * *", tz: "UTC" }
Cron 任务的核心执行逻辑基于定时器实现:系统会预先计算任务下一次的触发时间,待时间到达后触发定时器执行对应任务。具体执行分为两种模式main、isolated,核心区别在于会话上下文的使用方式:main可以共享主会话的上下文,而isolated相当于新建一个会话。执行的内容在payload.message中,其实就相当于发送了一次消息,在上面的例子中,就是向openclaw发送了一次新的请求,请求内容为"💧 该喝水啦!保持水分充足哦~"。
// 定时器触发
async function onTimer(state) {
const dueJobs = findDueJobs(state); // 找到到期任务
for (const job of dueJobs) {
if (job.sessionTarget === "main") {
// Main 模式: 直接发消息
enqueueSystemEvent(job.payload.text);
requestHeartbeatNow(); // 唤醒处理
} else {
// Isolated 模式: 独立执行
const result = await runIsolatedAgentJob({
message: job.payload.message
});
// 可选: 发送摘要回主会话
if (result.summary) {
enqueueSystemEvent(`Cron: ${result.summary}`);
}
}
}
// 更新状态 & 重新设定时器
await persist(state);
armTimer(state);
}2.Heartbeat
同样通过定时器实现,不过时间间隔是固定的,默认是30s。心跳任务记录在~/.openclaw/workspace/HEARTBEAT.md文件。
4.skill
openclaw中可以配置很多skill,主要在两个目录下:
~/.openclaw/workspace/skills (自定义skill)
~/.nvm/versions/node/v24.14.0/lib/node_modules/openclaw/skills (初始化引导时下载的内置技能)
skill来源按照优先级由高到低总共有:
1.workspace/skills/ (自定义)
2.workspace/.agents/skills/
3.CONFIG_DIR/skills (这个不知道在哪)
4.初始化引导时下载的内置技能
如果有同名的skill,会保留优先级高的
与AGENTS.md一样,openclaw会将skill信息拼到system prompt中。
有一个问题是,skill包下的SKILL.md文件可能较大,或者有上百个skill,如何节省token呢?openclaw的方案是分步获取skill数据。流程如下
1.解析SKILL.md获取name、description。SKILL.md的第一部分是两个---包围的yml数据,通过解析yml拿到name、description
2.拼接system prompt,除了name、description,还会带上SKILL.md文件的绝对路径,拼接的结果如下:
## Skills (mandatory)
Before replying: scan <available_skills> <description> entries.
- If exactly one skill clearly applies: read its SKILL.md at <location> with `read_file`, then follow it.
- If multiple could apply: choose the most specific one, then read/follow it.
- If none clearly apply: do not read any SKILL.md.
Constraints: never read more than one skill up front; only read after selecting.<available_skills>
github: Interact with GitHub repositories (~/.openclaw/skills/github/SKILL.md)
apple-reminders: Manage Apple Reminders (~/workspace/skills/apple-reminders/SKILL.md)
</available_skills>
(可以看到要求每次只能选择一个skill,选择之后会用read_file读取SKILL.md)
3.大模型调用read_file,获取完整的SKILL.md
4.大模型根据SKILL.md说明,执行对应的指令
下面再给一个使用skill-creator创建skill的例子:
- 用户:创建一个skill,可以查询天气,最后告诉我保存到哪里了
- llm:我来为你创建一个天气查询的 skill。首先让我读取 skill-creator 的 SKILL.md 来了解最佳实践。
- toolCall:id":"read:0","name":"read","arguments":{"file_path":"/Users/a58/.nvm/versions/node/v24.14.0/lib/node_modules/openclaw/skills/skill-creator/SKILL.md"}
- toolResult:skill-creator/SKILL.md文件内容
- llm:现在让我为你创建天气查询 skill。首先初始化 skill
- toolCall:id":"exec:1","name":"exec","arguments":{"command":"cd /Users/a58/.openclaw/workspace && python3 ~/.nvm/versions/node/v24.14.0/lib/node_modules/openclaw/skills/skill-creator/scripts/init_skill.py weather-query --path . --resources scripts","timeout":30}
- toolResult:Initializing skill: weather-query\n Location: .\n Resources: scripts\n\n[OK] Created skill directory: /Users/a58/.openclaw/workspace/weather-query\n[OK] Created SKILL.md\n[OK] Created scripts/\n\n[OK] Skill 'weather-query' initialized successfully at /Users/a58/.openclaw/workspace/weather-query\n\nNext steps:\n1. Edit SKILL.md to complete the TODO items and update the description\n2. Add resources to scripts/, references/, and assets/ as needed\n3. Run the validator when ready to check the skill structure
- ...

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)