AI Coding:为什么我说 Cursor 比 Claude Code 更适合复杂项目编程
AI Coding:为什么我说 Cursor 比 Claude Code 更适合复杂项目编程
上一篇文章我们聊了怎么用 Rules、Skills、MCP 三板斧把 AI
从"什么都敢写"训到"按规矩交活"。这篇聊另一个问题——同样的规则体系,从 Cursor 搬到 Claude Code 后,AI
的规范遵循率出现了明显的衰减。拆开两个工具的底层架构之后我们发现,问题不在规则本身,而在上下文工程——你以为你的规则写在那里 AI
就能一直看到,但实际上,它可能早就"忘了"。
一、承上:那个"Rules 写太多反而失效"的坑,后面还有故事
上一篇《从 Vibe Coding 到 Agentic Engineering》里,我们提到了一个坑:
一开始上头了,写了 20 多条 Rules,结果 AI 的行为反而飘了。后来精简到 8 条,效果立竿见影。
当时我们给的解释是"上下文窗口是有限资源,规则太多反而互相挤占"。这个结论没问题,但只说对了一半。
事情的完整经过是这样的:规则精简到 8 条之后,在 Cursor 里确实稳了。于是我们想——这套体系能不能搬到 Claude Code 上?Claude Code 是 Anthropic 官方的 CLI Agent,底层用的模型一样,支持 CLAUDE.md + .claude/rules/ 的规则体系,还能配 MCP、配 Hook。看起来和 Cursor 差不多。
于是我们把同样的 8 条规则(一字不差)配进了 Claude Code,然后用同一份技术方案文档测试。
结果出乎意料。
二、实验:同样的规则,不同的结果
2.1 实验设计
两个工具执行完全相同的任务:
- 输入:一份 ~500 行的 PEV 技术方案文档(9 个 Phase 的时区重构方案)
- 规则:8 条规则,内容一致,分别放在
.cursor/rules/和.claude/rules/ - MCP:相同的 MySQL + Context7 配置
- 自治运行:不人工干预,让 Agent 独立完成全部 Phase
2.2 结果对比
| 规范项 | Cursor Agent | Claude Code CLI |
|---|---|---|
| 禁止魔法值 | 全程遵守 | Phase 3 起出现 if(status == 1) |
中文类注释 @author @since |
全程遵守 | Phase 3 起部分类缺失 |
用户时区使用 ZonedDateTime |
全程遵守 | 多处直接用 LocalDateTime.now() |
| 每 Phase 完成后 git commit | 全程执行 | 全程未执行,最终需手动补提 |
| Cache 只在 Repository 层 | 全程遵守 | 全程遵守 |
一个明显的规律:Claude Code 在 Phase 0-2(约前 50-80 turns)表现良好,但从 Phase 3 开始规则遵循率断崖式下降。 Cursor 则全程稳定。
这不是"Claude 模型能力不行"——前几个 Phase 它遵守得很好,说明它完全理解这些规则。问题一定出在别的地方。
2.3 第一个线索
我们注意到一个现象:Claude Code 在 Phase 3 左右,终端输出里出现了一行日志:
[auto-compact] Compacting conversation history...
这行日志之后,规则遵循就开始出问题了。
这促使我们去研究两个工具底层的上下文管理架构。下面的内容涉及一些 LLM 的工作原理,不是纯理论——理解这些原理,才能解释"为什么我的规则会被遗忘"。
三、原理:LLM 的上下文窗口与注意力衰减
在拆解两个工具的架构之前,先快速对齐几个 LLM 基础概念。已经熟悉的可以跳到第四节。
3.1 上下文窗口是什么
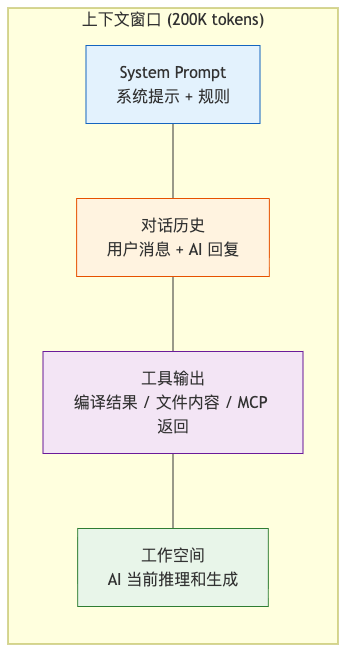
LLM(大语言模型)处理信息的方式和人不同。人可以随时翻书翻笔记,LLM 的"短期记忆"就只有一个固定大小的上下文窗口(Context Window)。目前 Claude 系列模型的上下文窗口是 200K tokens,大约等于 15 万字的中文文本。
每一次 AI 生成回复,它能"看到"的信息只有上下文窗口里装着的内容——包括系统提示(System Prompt)、对话历史、工具输出、代码内容,全部挤在这 200K 的空间里。窗口外的信息,对 AI 来说不存在。
3.2 注意力机制与"中间遗忘"
LLM 基于 Transformer 架构,其核心是自注意力机制(Self-Attention)。简单来说,模型在处理每个 token 时,会给上下文中的其他 token 分配"注意力权重"——注意力高的内容影响大,注意力低的内容约等于没看见。
研究表明,注意力分配存在位置偏差:
- 首部偏差(Primacy Bias):上下文开头的内容注意力高
- 尾部偏差(Recency Bias):上下文末尾的内容注意力高
- 中间塌陷(Lost in the Middle):上下文中间部分注意力最低

这意味着什么?如果你的规则被挤到了上下文的"中间地带",AI 看到它的概率会大幅下降。
在一个长 session 里,随着对话历史、工具输出不断堆积,规则(通常在系统提示区,即上下文开头)和当前任务(上下文末尾)之间塞满了大量的中间内容,规则的有效注意力就被稀释了。
3.3 指令遵循率的衰减曲线
这不是理论推测。业界有实测数据:
| 规则/指令数量 | 遵循率 |
|---|---|
| 10 条 | ~92% |
| 30 条 | ~78% |
| 100 条 | ~48% |
数据来源:echovic.com、腾讯云开发者社区
前一篇文章里我们把 Rules 从 20+ 精简到 8 条,本质上就是在这条曲线上做优化——让每条规则都有足够的注意力权重。
但这只解决了"规则数量"的问题。还有一个变量我们当时没意识到——上下文总占用量。同样是 8 条规则,如果其他内容(对话历史、工具输出)占的空间不同,规则能拿到的注意力份额也完全不同。
这正是 Cursor 和 Claude Code 的分叉点。
四、架构拆解:两个 Agent 的上下文管理差异
4.1 ReAct 循环:Agent 的基本工作方式
两个工具在 Agent 执行层面都采用了 ReAct(Reason and Act)循环——观察环境 → 推理决策 → 执行动作 → 观察结果 → 继续推理。每一轮循环就是一个 “turn”。

一个完整的 PEV 流程通常需要 100-300 个 turns。每个 turn 都会产生新的内容(工具调用结果、代码变更、编译输出),这些内容全部堆积在上下文窗口里。
关键问题来了:当堆积的内容快把 200K 窗口撑满时,怎么办?
两个工具的答案完全不同。
4.2 Claude Code:静态注入 + 不可逆压缩
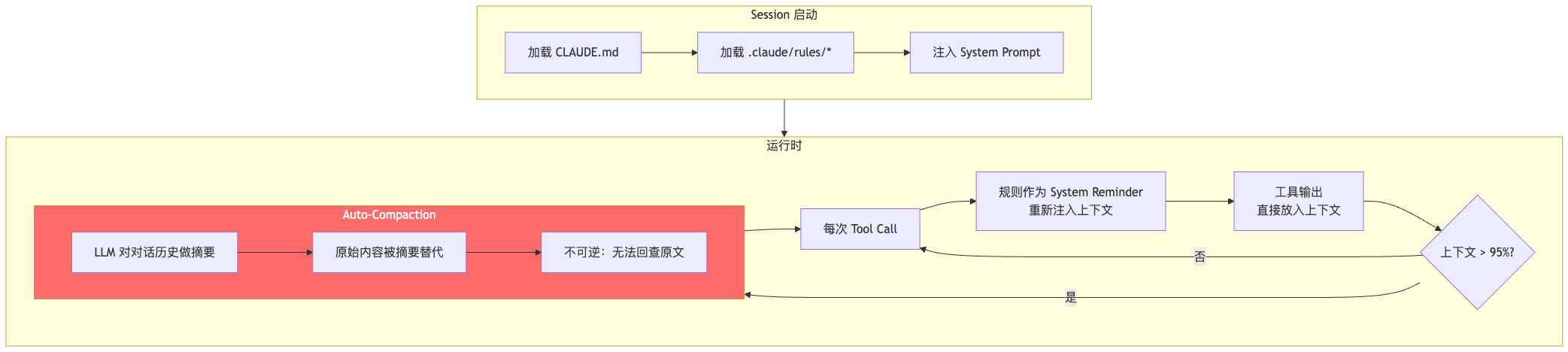
Claude Code 的上下文管理架构相对直接:
这个架构有三个特点导致规则在长 session 中衰减:
特点一:规则通过 System Reminder 重复注入。
Claude Code 的规则不是只加载一次。根据社区反馈(GitHub Issue #32057),CLAUDE.md 和 rules 文件的内容会在每次 tool call 时作为 system-reminder 重新注入上下文。
这听起来像是个好设计——规则反复出现,模型不会忘。但代价巨大:假设规则总量 10K tokens,30 次 tool call 之后,光规则的重复注入就吃掉了 ~93K tokens,占 200K 窗口的 ~46%。
上一篇文章里我们提到"8 条规则就够了",这个结论在 Cursor 里成立。但在 Claude Code 里,即使只有 8 条规则,反复注入的机制也会让它们在长 session 中消耗过量的上下文空间。
特点二:工具输出直接放入上下文。
执行 mvn compile 产生 200 行编译输出、describe_table 返回 50 行表结构——这些内容全部原封不动放进上下文窗口。在一个完整的 PEV 流程中,累计可能产生几十次工具调用,输出量轻松达到几十K tokens。
特点三:压缩是不可逆的 LLM 摘要。
当上下文使用率达到 ~95% 时,Claude Code 触发 Auto-Compaction。压缩方式是让 LLM 对对话历史做摘要——这是有损的。
压缩前: "禁止使用魔法值(未定义的字面量数字/字符串),必须使用常量类(XxxConstants)或枚举来替代。
禁止示例:if (status == 1)
正确做法:if (status == UserStatus.ACTIVE.getCode())"
压缩后: "遵循编码规范,避免使用硬编码值"
规则从具体的、可执行的指令,变成了模糊的、概括性的描述。
更关键的是——这个压缩是不可逆的。压缩后原始内容就没了,AI 无法回查"到底禁止的是什么"。这就是为什么 Phase 3 之后魔法值开始出现——不是 AI “故意违反”,而是它真的"不记得具体不让干什么了"。
4.3 Cursor:动态发现 + 可恢复压缩
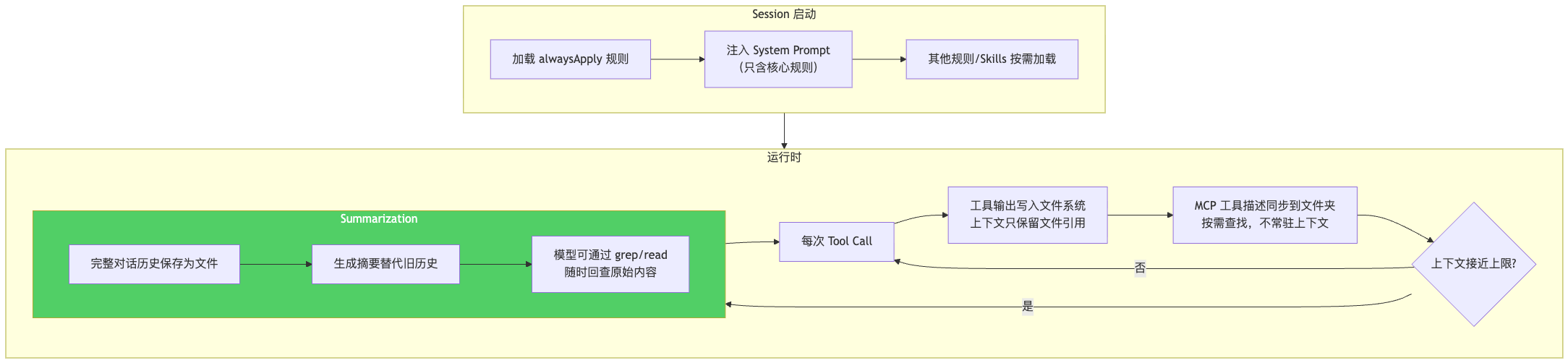
Cursor 的上下文管理架构更复杂,但核心理念是一个词:Dynamic Context Discovery(动态上下文发现)。
Cursor 官方博客是这么说的:
We’ve found success by providing fewer details up front, making it easier for the agent to pull relevant context on its own.
翻译成大白话:别一股脑全塞进上下文——让 AI 自己去找需要的东西。
与 Claude Code 的三个关键差异:
差异一:工具输出不直接进上下文。
mvn compile 的 200 行输出不塞进上下文窗口,而是写入文件系统。模型只通过 tail 看最后几行关键信息(成功 or 失败 + 错误摘要),上下文中只保留一个文件引用。
同样的做法用在 MCP 上更明显。Cursor 官方 A/B 测试数据:这种文件化策略在 MCP 场景下减少了 46.9% 的 token 消耗。
差异二:压缩后保留历史文件,可以回查。
这是最关键的差异。Cursor 在触发 Summarization 时,会把完整的对话历史保存为文件。压缩后的摘要替代了上下文中的旧历史,但原始内容作为文件仍然存在。如果模型在后续工作中需要某个被压缩掉的细节——比如某条规则的具体内容——它可以通过 grep 或 read 工具回查历史文件,把丢失的信息重新拉回上下文。
这等于给了 AI 一个"外部记忆"——上下文窗口是"工作记忆",历史文件是"长期记忆"。工作记忆满了可以清理,但需要的时候随时从长期记忆中调取。
Claude Code 没有这个机制。压缩就是压缩,原文不会被保留为可查的文件。
差异三:代码同步用 Merkle Tree,按需索引用 AST。
Cursor 有一层独立的上下文引擎,用 Merkle Tree 做代码文件的增量同步(只同步变更的文件,不是每次全量读取),用 AST(抽象语法树)做语义分块(按函数/类而不是按行数切分上下文)。这些都是在上下文窗口之外工作的基础设施,进一步减少了窗口内的负担。
Claude Code 没有独立的上下文引擎。代码文件通过 Read 工具全文读入上下文,读 10 个文件就是 10 份全文。
4.4 上下文利用率的差异
把上面的差异汇总成一张上下文空间分配的对比图:
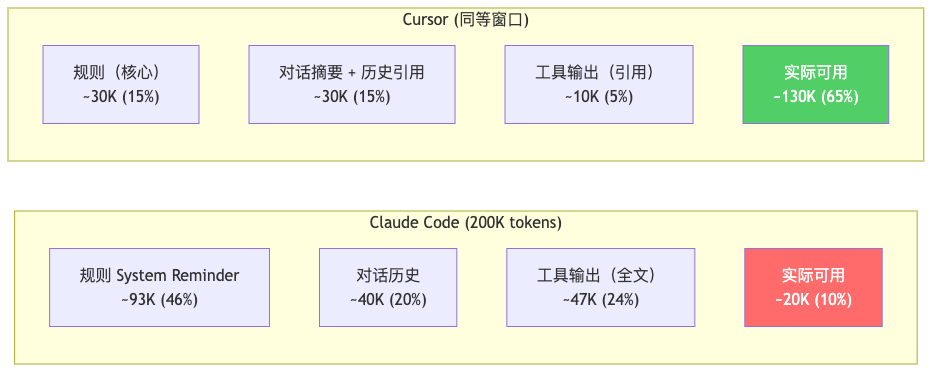
注:上图为基于公开资料的估算模型,具体数值因项目而异。核心结论是两者的上下文利用效率差了一个量级。
Claude Code 实际可用空间只剩 ~10%,AI 在极度逼仄的空间里推理和生成代码,规则遵循率自然下降。Cursor 可用空间 ~65%,AI 有充裕的空间"思考",规则也不需要和其他内容挤占注意力。
五、回到实验:衰减过程的还原
有了上面的原理基础,再回看我们的实验结果,衰减过程就清晰了:
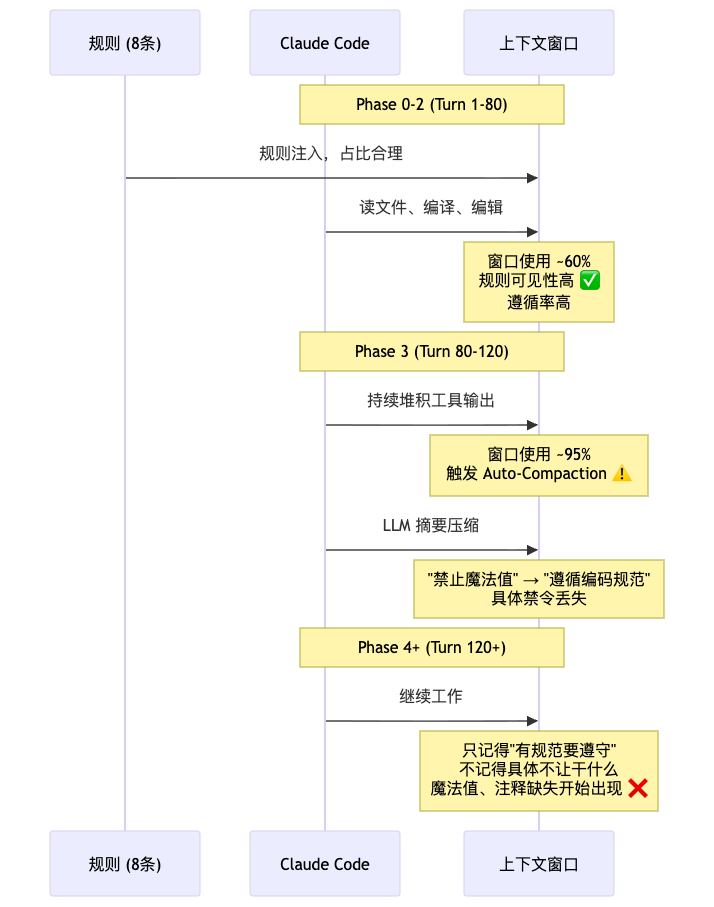
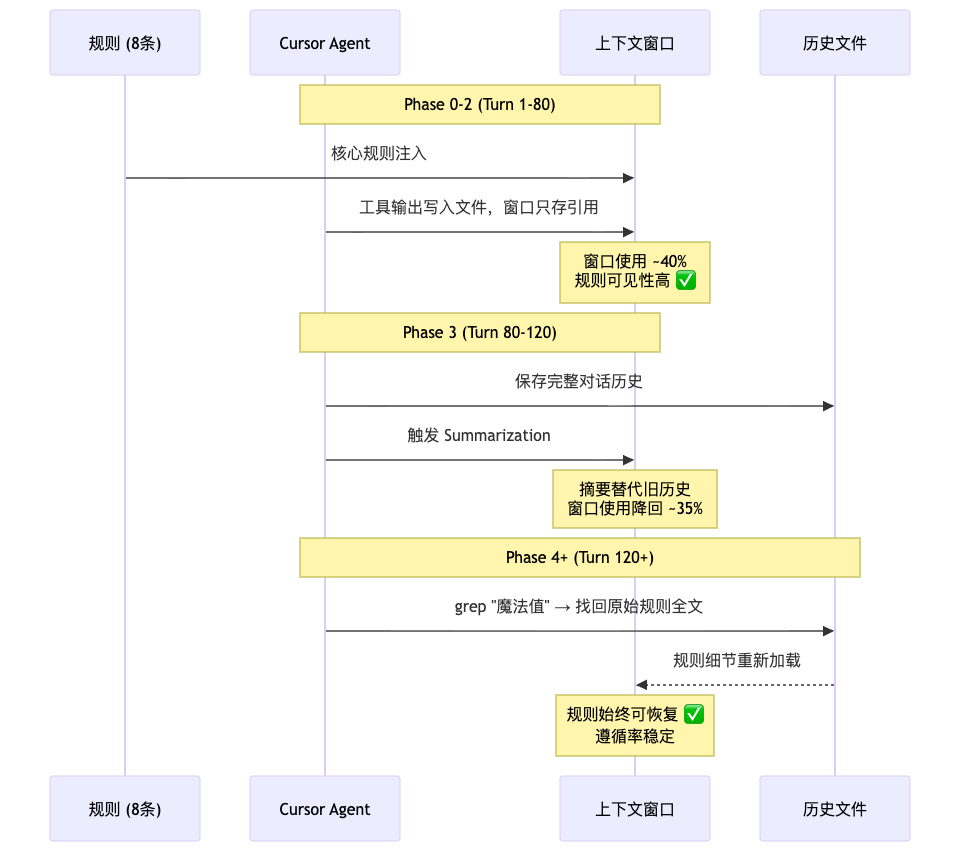
差异:Claude Code 的规则是"写在沙滩上的字"——浪来了就冲没了;Cursor 的规则是"刻在石板上的字"——即使被沙子盖住,挖一挖还在。
六、补充验证:精简规则后 Claude Code 的表现
既然问题出在上下文空间,那我们试了一个对照实验:把 Claude Code 的规则从 8 条精简到只剩 3 条最核心的 NEVER,同时把 max-turns 从 2000 降到 100。
精简后的 3 条规则:
- NEVER 使用魔法值
- NEVER 缺少类 JavaDoc
@author Codey @since - 每 Phase 完成后 MUST git commit
结果:在 100 turns 内,这 3 条规则的遵循率显著提高,基本接近 Cursor 的表现。
但代价是——我们不得不砍掉了 cache-in-repository-only、db-access 等架构约束类规则。这些规则对项目质量至关重要(上一篇文章提到的缓存穿透事故就是因为缺了这条规则),但在 Claude Code 的架构下,8 条全带着跑长 session 就是会出问题。
这就是我们说"Cursor 更适合复杂项目"的核心含义:不是 Claude Code 不好用,而是它的上下文架构决定了规则容量有天花板。规则越多,session 越长,衰减越严重。Cursor 的天花板明显更高。
七、公平起见:Claude Code 更强的地方
只说 Cursor 好处不说 Claude Code 的优势,不公平,也不客观。
7.1 Hook:确定性自动化
Claude Code 的 PostToolUse / PreToolUse Hook 是真正的 Shell 脚本,不依赖模型"记住"要做什么,100% 确定性执行。比如 auto-commit:
{
"hooks": {
"PostToolUse": [{
"matcher": "Write|Edit",
"hooks": [{
"type": "command",
"command": "cd $CLAUDE_PROJECT_DIR && git add -A && git diff-index --quiet HEAD || git commit -m 'wip [codey]' 2>/dev/null || true"
}]
}]
}
}
Cursor 的 Skills/Rules 本质上还是"建议"——模型可能遵循,也可能忘记。Hook 是"强制"——Shell 脚本说了算,模型管不着。
对于"不管多累都必须执行"的动作(auto-commit、lint 检查、格式化),Hook 比 Rules 靠谱得多。
7.2 --append-system-prompt:精准注入
Claude Code 的 --append-system-prompt / --append-system-prompt-file 允许在命令行级别向系统提示注入额外内容。这在批处理和 CI/CD 场景下非常有用——你可以针对不同任务注入不同的规则集,不用改 CLAUDE.md。
7.3 CLI 原生设计
Claude Code 天然就是 CLI 工具,-p 模式 + JSON 输出 + 管道组合,天生适合脚本化和 CI/CD 集成。Cursor 的 CLI 是后来加的,虽然功能在快速追赶,但 Claude Code 在这个维度上仍然领先。
八、什么时候用哪个
基于大半年的实际使用,我们的选择逻辑:
| 场景 | 推荐 | 原因 |
|---|---|---|
| 复杂项目全链路交付(Plan → Code → Test → Commit) | Cursor | 上下文效率高,规则持久,8 条规则跑完 300 turns 依然稳定 |
| 需要严格遵循 5+ 条编码规范 | Cursor | 动态上下文发现 + 可恢复压缩,规则容量天花板高 |
| 单文件 / 简单 Bug 修复(<30 turns) | 都行 | 上下文压力小,差异不明显 |
| CI/CD 集成 / 批量脚本 | Claude Code | CLI 原生 + Hook 确定性保障 + --output-format json |
| 代码审查 / 安全扫描 | Claude Code | 一次性任务,规则不会衰减;Hook 可强制执行检查清单 |
| 自动 commit / format / lint | Claude Code | Hook >> Rules,确定性动作用确定性工具 |
九、总结:上下文工程,才是 AI Coding 的下一个战场
上一篇文章的结论是:从 Vibe Coding 到 Agentic Engineering,关键在于用 Rules、Skills、MCP 给 AI 装上约束体系。
这篇文章的结论是:约束体系能不能持久生效,取决于底层的上下文工程。
模型能力在快速追平——今天用 Claude,明天 Cursor 可能切成 GPT,后天可能都用开源模型。但上下文工程是架构级的差异,同样的模型放在不同的上下文管理架构里,产出的代码质量可以差出一个等级。
上一篇文章里我们说"赛车不是只靠引擎马力大就能赢——还得有刹车、悬挂和空力套件"。现在可以加一句:空力套件设计得再好,如果油箱太小跑不完全程也白搭。上下文窗口就是 AI Agent 的油箱,谁的油耗更低、谁的续航更长,谁就更适合跑长途。
Cursor 的 Dynamic Context Discovery,就是 AI Coding 领域的混合动力系统——省油、续航长、跑完全程还有余量。
参考资料
- Dynamic Context Discovery — Cursor 官方博客
- Best Practices for Claude Code — Anthropic 官方
- Designing High-Performance Agentic Systems: Cursor Agent 架构分析 — Khayyam H.
- GitHub Issue #32543: Rules lost after context compression — Claude Code 社区
- GitHub Issue #32057: Rules consume ~46% of context window — Claude Code 社区
- Claude Code 最佳实践的 8 条黄金法则 — 腾讯云开发者社区
- 如何编写高效的 CLAUDE.md — 青雲博客
- A Deep Dive into Cursor Rules and Background Agents — Duraid Wadie
- Using Agent in CLI — Cursor 官方文档
- FlashCompact: Context Compaction Methods Compared — Morph

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)