【WEB3.0零基础转行笔记】Rust编程篇-第3讲:数据类型
目录
3.2.4 Booleans: Truth Values in Rust
3.2.7 探索数值类型的限制:最小值(MIN)和最大值(MAX)
3.10.1 掌握 Rust 中的字符串:String对比&str
3.10.2 理解 Rust 的主要字符串类型String 和 &str
3.10.5 搭建桥梁:String 与 &str 之间的转换
3.1 GMX介绍

Learn more about GMX @ https://gmx.io.
3.1.1 GMX 去中心化交易协议详解
概述:GMX 是 一个基于 Arbitrum 和 Avalanche 的去中心化永续合约和现货交易协议,采用独特的双代币模型和流动性池设计。
3.1.2 核心特性
1. 交易功能
-
永续合约交易: 支持高达 50 倍杠杆的多空交易
-
现货交易: 零滑点、低手续费兑换
-
支持资产: BTC、ETH、AVAX、LINK、UNI 等主流资产
-
跨链支持: 主要在 Arbitrum 和 Avalanche 上运行
2. 技术创新
GLP 流动性池
GLP = 一篮子资产组成的指数基金
├── 资产构成: BTC、ETH、稳定币等
├── 功能: 作为交易对手方
├── 收益来源: 交易手续费、资产增值、资金费率
└── 风险: 承担交易者的盈亏独特的定价机制
-
使用 Chainlink 预言机和 TWAP(时间加权平均价格)
-
避免闪电贷攻击和价格操纵
3. 代币经济模型
|
代币 |
功能 |
收益来源 |
|---|---|---|
|
GMX |
治理和效用代币 |
• 30%平台手续费(ETH/AVAX) • esGMX奖励 • 协议治理权 |
|
GLP |
流动性提供代币 |
• 70%平台手续费(ETH/AVAX) • esGMX奖励 • 资金费率收益 |
|
esGMX |
激励代币 |
• 可转换为 GMX • 提升质押收益 |
3.1.3 收益机制对比
|
角色 |
参与方式 |
主要收益 |
风险 |
|---|---|---|---|
|
交易者 |
杠杆交易 |
交易利润 |
清算风险、手续费 |
|
GMX 质押者 |
质押 GMX |
手续费分成、esGMX |
代币价格波动 |
|
GLP 提供者 |
提供流动性 |
手续费分成、资金费率 |
交易对手风险 |
3.1.4 优势亮点
✅ 优点
-
资本效率高
-
单一流动性池支持多资产交易
-
流动性提供者享受多重收益
-
-
用户体验佳
-
类似 CEX 的交易界面
-
低 gas 费(基于 L2)
-
无滑点现货交易
-
-
可持续的代币经济
-
真实收益模型
-
手续费直接分配给参与者
-
通胀率可控
-
⚠️ 风险与挑战
-
智能合约风险
-
预言机依赖风险
-
监管不确定性
-
竞争加剧(dYdX、Perpetual Protocol 等)
3.1.5 关键数据(截至最近)
-
TVL: 通常位居 DeFi 协议前列
-
累计交易量: 超过数百亿美元
-
手续费分配: 已向质押者分配数万 ETH/AVAX
-
多链扩展: 已部署至 Arbitrum、Avalanche
3.1.6 发展路线图
-
V2 升级: 改进风险管理,增加资产支持
-
跨链扩展: 考虑更多 Layer2 部署
-
产品创新: 期权、结构化产品等
3.1.7 使用建议
-
新手: 从现货交易开始,熟悉界面
-
交易者: 注意杠杆风险和清算价格
-
投资者: 研究 GLP 资产构成,分散风险
-
质押者: 考虑锁定期和收益再投资
3.1.8 社区与资源
-
官网: https://gmx.io
-
文档: https://docs.gmx.io
-
数据看板: https://app.gmx.io/#/dashboard
-
社区: Discord、Twitter 活跃
总结: GMX 通过创新的 GLP 模型和双代币系统,在去中心化衍生品赛道占据重要地位,为交易者、流动性提供者和质押者创造了独特的价值捕获机制。不过,参与时仍需充分了解相关风险。
3.2 标量类型
3.2.1 理解 Rust 的标量数据类型
在 Rust 中,标量数据类型表示单个值。它们是构建更复杂数据结构和程序逻辑的基本单元。Rust 提供了四种主要的标量类型:整数、浮点数、布尔值和字符。每种类型都有其特定的特性和使用场景,我们将在下文中详细探讨。Rust 的主要标量类型如下表所示:
|
类型分类 |
具体类型 |
大小(字节) |
描述 |
示例 |
|---|---|---|---|---|
|
整数类型 |
|
1 |
有符号 8 位整数 |
|
|
|
2 |
有符号 16 位整数 |
|
|
|
|
4 |
有符号 32 位整数(默认) |
|
|
|
|
8 |
有符号 64 位整数 |
|
|
|
|
16 |
有符号 128 位整数 |
|
|
|
|
架构相关 |
有符号指针大小整数 |
|
|
|
|
1 |
无符号 8 位整数 |
|
|
|
|
2 |
无符号 16 位整数 |
|
|
|
|
4 |
无符号 32 位整数 |
|
|
|
|
8 |
无符号 64 位整数 |
|
|
|
|
16 |
无符号 128 位整数 |
|
|
|
|
架构相关 |
无符号指针大小整数 |
|
|
|
浮点类型 |
|
4 |
单精度浮点数(约6-7位小数精度) |
|
|
|
8 |
双精度浮点数(默认,约15位小数精度) |
|
|
|
布尔类型 |
|
1 |
布尔值,只能是 |
|
|
字符类型 |
|
4 |
Unicode 标量值(U+0000 到 U+D7FF,U+E000 到 U+10FFFF) |
|
这些标量类型是 Rust 类型系统的基础,具有明确的尺寸和范围,有助于编写内存安全且高效的程序。
3.2.2 Rust 中的整数:整数
整数是不包含小数或小数部分的数值。Rust 提供了一套全面的整数类型,这些类型根据其大小(在内存中占用的位数)以及是有符号(可以表示负数)或无符号(只能表示非负数)来区分。
1、有符号整数(i8,i16,i32,i64,i128)
有符号整数可以存储正整数和负整数。i类型名称中的“int”代表“整数”,后面的数字表示位数。
-
i8: 8 位有符号整数。 -
i16:16 位有符号整数。 -
i32:32 位有符号整数(如果未指定,则这是默认的整数类型)。 -
i64:64 位有符号整数。 -
i128:128 位有符号整数。
n 位有符号整数的取值范围是 -(2^(n-1)) 到 2^(n-1) - 1。
#![allow(unused)]
fn main() {
// Signed integers
// Range: -(2^(n-1)) to 2^(n-1) - 1
let type1: i8 = -1; // Range: -128 to 127
let type2: i16 = 2; // Range: -32,768 to 32,767
let type3: i32 = 3; // Range: -2,147,483,648 to 2,147,483,647
let type4: i64 = -4; // Range: -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807
let type5: i128 = 5; // A very large range
println!("type1 = {type1}");
println!("type2 = {type2}");
println!("type3 = {type3}");
println!("type4 = {type4}");
println!("type5 = {type5}");
}
2 无符号整数(u8, u16, u32, u64, u128)
无符号整数只能存储非负整数(零和正数)。u类型名称中的“-”表示“无符号”,后面的数字表示位数。
-
u8:8 位无符号整数。 -
u16:16 位无符号整数。 -
u32:32 位无符号整数。 -
u64:64 位无符号整数。 -
u128:128 位无符号整数。
n 位无符号整数的取值范围是0 到 2^n - 1。
#![allow(unused)]
fn main() {
// Unsigned integers
// Range: 0 to 2^n - 1
let type1: u8 = 1; // Range: 0 to 255
let type2: u16 = 2; // Range: 0 to 65,535
let type3: u32 = 3; // Range: 0 to 4,294,967,295
let type4: u64 = 4; // Range: 0 to 18,446,744,073,709,551,615
let type5: u128 = 5; // A very large range, up to 2^128 - 1
println!("type1 = {type1}");
println!("type2 = {type2}");
println!("type3 = {type3}");
println!("type4 = {type4}");
println!("type5 = {type5}");
}
3、 架构相关整数(isize,usize)
Rust 还包含整数类型,其大小取决于编译和运行程序的计算机架构。
-
isize:一个有符号整数,其大小与目标架构的指针大小相匹配。 -
usize:一个无符号整数,其大小与目标架构的指针大小相匹配。
在 32 位架构上,isize等价于i32,usize等价于u32。在 64 位架构上,isize是i64,usize是u64。该usize类型意义重大,因为 Rust 使用它来索引数组和向量等集合,以及表示内存大小和项目数量。
// 允许编译器忽略未使用的变量警告,便于示例代码演示
#![allow(unused)]
// 主函数入口点
fn main() {
// isize 是架构相关的有符号整数类型
// 在32位系统上为i32,在64位系统上为i64
// 常用于表示数组索引、内存偏移量或数据长度
let i5: isize = -6; // 这里显式指定类型,值可以是负数
// usize 是架构相关的无符号整数类型
// 在32位系统上为u32,在64位系统上为u64
// 常用于表示集合大小、内存地址或数组索引(必须为非负数)
let u5: usize = 6; // usize 不能为负数
// 使用格式化字符串打印变量的值
// {} 是占位符,会被对应变量的值替换
println!("i5 = {i5}");
println!("u5 = {u5}");
// 补充:可以在运行时查看类型的实际大小
// std::mem::size_of::<usize>() 是 Rust 标准库中的函数,用于返回类型 usize 在编译目标平台上的大小,单位是字节(byte)
println!("当前平台指针大小: {} bits", std::mem::size_of::<usize>() * 8);
// 补充:isize和usize的最大/最小值
println!("isize范围: {} 到 {}", isize::MIN, isize::MAX);
println!("usize范围: 0 到 {}", usize::MAX);
// 使用场景示例:数组索引必须使用usize
let arr = [10, 20, 30, 40, 50];
let index: usize = 2; // 索引必须为usize类型
println!("arr[{}] = {}", index, arr[index]);
}3.2.3 浮点数:处理小数
浮点数用于表示带有小数点的数字。Rust 提供了两种用于表示浮点数的基本类型:
-
f32:一个单精度浮点数,占用 32 位。 -
f64:一个双精度浮点数,占用 64 位。
如果您声明浮点数时未明确指定其类型,Rust 会默认采用 f64,因为其精度通常更适合大多数计算场景。f32 和 f64 类型均遵循 IEEE 754 标准的浮点运算规范。
// 允许编译器忽略未使用的变量警告,便于示例代码演示
#![allow(unused)]
fn main() {
// Floating point numbers
let f0: f32 = 0.01;
let f1: f64 = 0.02; // f64 is the default if not specified
println!("f0 = {f0}");
println!("f1 = {f1}");
}
3.2.4 Booleans: Truth Values in Rust
Rust 中的布尔类型是 bool。它是最简单的标量类型之一,因为它只有两个可能的值:true、false
布尔值主要用于条件逻辑(例如,在if语句中)。一个布尔值占用一个字节的内存空间。
// 允许编译器忽略未使用的变量警告,便于示例代码演示
#![allow(unused)]
fn main() {
// Boolean
let b: bool = true;
let is_active: bool = false;
println!("b = {b}");
println!("is_active = {is_active}");
}
3.2.5 字符:表示单个 Unicode 值
Rust 的 char 类型用于表示单个 Unicode 标量值。这意味着 char 所能容纳的远不止基础 ASCII 字符,它还可以表示带重音的字母、来自全球各种语言的字符、表情符号乃至控制字符。
字符字面量使用单引号(')定义,以此与使用双引号(")的字符串字面量区分开来。Rust 中的 char 类型大小为四个字节,使其能够涵盖完整的 Unicode 标量值范围。
Unicode 是 ASCII 的超集扩展。ASCII(美国信息交换标准代码)仅包含128个字符(如英文字母、数字和基础符号),用一个字节表示;而 Unicode 则旨在涵盖全球所有文字系统的字符(包括中文、阿拉伯文、表情符号等),采用多字节编码(如 UTF-8)。关键联系:Unicode 完全兼容 ASCII——前128个 Unicode 码点与 ASCII 字符完全相同(例如
A在两者中均为数字65),因此 ASCII 文本可直接视为 Unicode 的一种特例。
// 允许编译器忽略未使用的变量警告,便于示例代码演示
#![allow(unused)]
fn main() {
// Characters
let c: char = 'c';
let z: char = 'ℤ';
let heart: char = '❤';
let e: char = '🦀'; // Emojis are valid char values
// Note: "c" (with double quotes) would be a string slice (&str), not a char.
println!("c = {c}");
println!("z = {z}");
println!("heart = {heart}");
println!("e = {e}");
}
3.2.6 显式类型转换as
Rust 是一种静态类型语言,它优先考虑类型安全。为了防止因意外的类型强制转换而导致的潜在错误,Rust 不会在基本类型之间执行隐式类型转换(也称为强制转换)。如果您需要将值从一种基本类型转换为另一种基本类型,则必须使用 as 关键字显式地进行转换类型。
转换时请注意,值的底层位模式可能会被重新解释。这会导致不同的数值,尤其是在有符号整数和无符号整数之间转换,或者将较大的类型转换为较小的类型时(如果值超出目标类型的范围,则可能导致截断)。
例如,将一个负的有符号整数转换为无符号整数会得到一个很大的正数。这是因为负数在内存中的表示方式(例如,使用二进制补码)。
二进制补码是一种用于表示有符号整数的编码方案,它将负数的表示转换为与其绝对值相加后等于零的二进制形式。具体来说,正数的补码就是其本身,而负数的补码则通过将其对应正数的二进制表示取反(按位取反)后加1得到。这种设计使得计算机可以用同一套加法电路同时处理加减法运算,因为减法可转换为“加上负数的补码”,并自动忽略超出位数的溢出,从而极大简化了硬件实现。例如,在8位系统中,
-1的补码是11111111,它与1(00000001)相加结果为00000000(溢出被舍去),完美对应数学上的1 + (-1) = 0。
// 允许编译器忽略未使用的变量警告,便于示例代码演示
// 这是一个 crate 级别的属性,对整个模块生效
#![allow(unused)]
// Rust 程序的入口函数,每个可执行的 Rust 程序都从这里开始执行
fn main() {
// ================================================
// 类型转换示例:有符号整数到无符号整数的显式转换
// ================================================
// 声明一个 i32 类型的有符号整数变量 i,并初始化为 -1
// i32 表示32位有符号整数,可以存储负值
let i: i32 = -1;
// 使用 as 关键字进行显式类型转换
// 将 i32 类型的变量 i 转换为 u32 类型(32位无符号整数)
// 这种转换是"重新解释位模式",而不是数学上的值转换
// 在二进制补码表示中,i32 的 -1 所有位都是 1,转换为 u32 后会成为 u32 的最大值
let u: u32 = i as u32; // 显式从 i32 转换到 u32
// ================================================
// 打印结果以观察转换效果
// ================================================
// 打印原始 i32 变量的值
println!("i = {i}"); // 输出: i = -1
// 打印转换后的 u32 变量的值
println!("u = {u}"); // 输出: u = 4294967295 (在32位系统上)
// ================================================
// 补充解释和验证
// ================================================
// 验证:打印转换后的 u 的十六进制表示
println!("u 的十六进制表示 = 0x{:x}", u); // 输出: 0xffffffff
// 验证:u32 的最大值
println!("u32 的最大值 = {}", u32::MAX); // 输出: 4294967295
println!("-1 的二进制补码(32位)所有位都是 1");
// 补充:不同类型转换的注意事项
println!("\n=== 类型转换注意事项 ===");
// 1. 有符号整数到无符号整数的转换可能导致数据解释变化
// 正数转换通常保持值不变(如果值在目标类型范围内)
let positive_i: i32 = 42;
let positive_u: u32 = positive_i as u32;
println!("正数转换: {} -> {}", positive_i, positive_u);
// 2. 值超出目标类型范围的转换会"截断"
// 例如:将较大的 i32 转换为 i8 会进行模运算
let large_i32: i32 = 300;
let i8_from_large: i8 = large_i32 as i8; // 300 超出 i8 范围(-128~127)
println!("溢出转换: {} -> {}", large_i32, i8_from_large); // 输出: 44
// 3. 使用安全的转换方法(返回 Option 类型)
match i32::try_from(u) {
Ok(value) => println!("安全转换成功: u32({}) -> i32({})", u, value),
Err(e) => println!("安全转换失败: {}", e),
}
}
// ================================================
// 运行此程序可能得到的输出(基于64位系统):
// ================================================
// i = -1
// u = 4294967295
// u 的十六进制表示 = 0xffffffff
// u32 的最大值 = 4294967295
// -1 的二进制补码(32位)所有位都是 1
//
// === 类型转换注意事项 ===
// 正数转换: 42 -> 42
// 溢出转换: 300 -> 44
// 安全转换失败: out of range integral type conversion attempted如果运行这段代码并打印出这些值,输出结果将是:
(-1) as u32 = (4294967295)这是因为在 i32 类型中(采用二进制补码表示),-1 对应的二进制位全部为 1。当这些位被重新解释为 u32 类型时,它们所表示的就是 u32 的最大可能值。
3.2.7 探索数值类型的限制:最小值(MIN)和最大值(MAX)
Rust 提供了一种便捷的方式来获取特定数值类型所能表示的最小值与最大值。这是通过使用该类型本身所定义的关联常量 MIN 和 MAX 来实现的。
例如,若要获取 i32 类型的最大值或 u32 类型的最小值:
// 允许编译器忽略未使用的变量警告,便于示例代码演示
// 这是一个 crate 级别的属性,对整个模块生效
#![allow(unused)]
// Rust 程序的入口函数,每个可执行的 Rust 程序都从这里开始执行
fn main() {
// ================================================
// 数值类型的最小值和最大值示例
// ================================================
// Rust 标准库为所有数值类型提供了关联常量 MIN 和 MAX
// 这些常量允许我们安全地获取类型的有效值范围
// 获取 i32 类型(32位有符号整数)的最大值
// i32::MAX 的值为 2,147,483,647 (2³¹ - 1)
let i_max: i32 = i32::MAX;
// 获取 u32 类型(32位无符号整数)的最小值
// u32::MIN 的值为 0(所有无符号整数的最小值都是 0)
let u_min: u32 = u32::MIN;
// ================================================
// 打印结果以观察类型的取值范围
// ================================================
// 打印 i32 的最大值
println!("i_max = {i_max}"); // 输出: i_max = 2147483647
// 打印 u32 的最小值
println!("u_min = {u_min}"); // 输出: u_min = 0
// ================================================
// 补充:展示更多类型的边界值
// ================================================
// 整数类型的边界值
println!("\n=== 整数类型边界值 ===");
println!("i8::MIN = {}, i8::MAX = {}", i8::MIN, i8::MAX);
println!("i16::MIN = {}, i16::MAX = {}", i16::MIN, i16::MAX);
println!("i32::MIN = {}, i32::MAX = {}", i32::MIN, i32::MAX);
println!("i64::MIN = {}, i64::MAX = {}", i64::MIN, i64::MAX);
println!("i128::MIN = {}, i128::MAX = {}", i128::MIN, i128::MAX);
println!("\nu8::MIN = {}, u8::MAX = {}", u8::MIN, u8::MAX);
println!("u16::MIN = {}, u16::MAX = {}", u16::MIN, u16::MAX);
println!("u32::MIN = {}, u32::MAX = {}", u32::MIN, u32::MAX);
println!("u64::MIN = {}, u64::MAX = {}", u64::MIN, u64::MAX);
println!("u128::MIN = {}, u128::MAX = {}", u128::MIN, u128::MAX);
// 平台相关类型
println!("\n=== 平台相关类型边界值 ===");
println!("isize::MIN = {}, isize::MAX = {}", isize::MIN, isize::MAX);
println!("usize::MIN = {}, usize::MAX = {}", usize::MIN, usize::MAX);
// 浮点类型的边界值
println!("\n=== 浮点类型边界值 ===");
println!("f32::MIN = {:e}, f32::MAX = {:e}", f32::MIN, f32::MAX);
println!("f64::MIN = {:e}, f64::MAX = {:e}", f64::MIN, f64::MAX);
// 特殊浮点值
println!("\n=== 特殊浮点值 ===");
println!("f32::INFINITY = {}", f32::INFINITY);
println!("f32::NEG_INFINITY = {}", f32::NEG_INFINITY);
println!("f32::NAN = {}", f32::NAN);
// ================================================
// 实际应用示例:边界检查
// ================================================
println!("\n=== 边界检查示例 ===");
// 示例 1:防止算术溢出
let x: i32 = i32::MAX - 100;
let y: i32 = 200;
// 使用 checked_add 进行安全的加法操作
match x.checked_add(y) {
Some(result) => println!("{x} + {y} = {result}"),
None => println!("加法溢出!{x} + {y} 超出了 i32 的范围"),
}
// 示例 2:使用饱和加法(saturating_add)
let saturated = x.saturating_add(y);
println!("饱和加法: {x}.saturating_add({y}) = {saturated}");
// 示例 3:值范围验证
let user_input: i32 = 5000;
if user_input >= i32::MIN && user_input <= i32::MAX {
println!("用户输入值 {} 在有效范围内", user_input);
} else {
println!("用户输入值超出有效范围");
}
}这对于理解数据的边界和进行数据验证极其有用。
在尝试运行这些示例时,你可以将它们放在 Rust 文件(例如 Cargo 项目中的 examples/scalar.rs)的 fn main() { ... } 代码块中。如果只是为了演示而声明变量,可以在文件顶部使用 #[allow(unused)] 属性来抑制编译器关于未使用变量的警告。然后可以编译并运行代码,例如在 Cargo 项目中可以通过 cargo run --example scalar 命令来执行(如果代码已按示例项目结构组织)。
理解这些标量类型的特性、取值范围、内存占用以及转换规则,对于编写高效、正确且性能优良的 Rust 程序至关重要。它们构成了所有其他数据结构和操作的基础。
3.2.8 char、string和&str区别
在 Rust 中,char、String 和 &str 是三种核心的字符串相关类型,它们各有不同的用途和特性:
1. char — 单个 Unicode 字符
-
定义:
char表示一个 Unicode 标量值,即单个字符,例如字母、数字、汉字、表情符号等。 -
字面量:用 单引号 括起来,如
'a'、'中'、'😊'。 -
内存大小:固定为 4 字节(32 位),因为 Unicode 标量值的范围是
U+0000到U+D7FF以及U+E000到U+10FFFF。
-
特点:
-
每个
char都是一个完整的 Unicode 码点。 -
它不包含任何编码信息,可以直接用于比较、匹配等操作。
-
char不能直接包含多个字符(如字符串)。
-
-
示例:
#![allow(unused)] fn main() { let heart_emoji: char = '❤'; println!("heart_emoji = {heart_emoji}"); }
2. &str — 字符串切片(String Slice)
-
定义:
&str是一个对 UTF-8 字节序列 的不可变引用,通常被称为 字符串切片。它指向一段有效的 UTF-8 文本。 -
字面量:用 双引号 括起来,如
"hello"。字符串字面量的类型实际上是&'static str(拥有静态生命周期的切片)。 -
内存布局:由两个部分组成:指向字节数据的指针 + 长度(usize),因此它本身存储在栈上,而实际数据可能存储在:
-
可执行文件的只读数据段(对于字符串字面量)。
-
String的堆内存中的一部分(通过切片获得)。
-
-
特点:
-
不可变(不能通过
&str修改内容)。 -
不拥有数据,只是借用。
-
总是有效的 UTF-8 序列。
-
-
常见用途:
-
函数参数:接收字符串数据而不需要所有权(高效、灵活)。
-
字符串分割、提取子串等操作。
-
-
示例:
#![allow(unused)] fn main() { let s: &str = "Hello, Rust!"; // 字符串字面量 let part: &str = &s[0..5]; // 切片,指向 "Hello" println!("s = {s},part = {part}"); }
3. String —— 拥有所有权的堆分配字符串
-
定义:
String是一个 可增长、可变、拥有所有权 的 UTF-8 字符串类型。它在堆上分配内存,类似于Vec<u8>,但保证内容总是有效的 UTF-8。 -
创建方式:
-
String::from("content") -
"content".to_string() -
使用
push_str、push等方法动态构建。
-
-
内存布局:由三部分组成(存储在栈上):指向堆内存的指针、长度、容量。堆内存中存放实际的 UTF-8 字节。
-
特点:
-
可变:可以追加、插入、删除内容。
-
拥有数据:当
String变量被丢弃时,堆内存会被自动释放。 -
可通过
as_str()或&s轻松获得&str切片。
-
-
常见用途:
-
需要构建、修改或拥有字符串数据时。
-
从文件、网络读取的文本数据。
-
-
示例:
#![allow(unused)] fn main() { let mut s: String = String::from("Hello"); s.push_str(",rust!"); println!("s = {s}"); }
4、核心区别总结表
|
维度 |
|
|
|
|---|---|---|---|
|
表示内容 |
单个 Unicode 字符 |
一串 UTF-8 文本(只读视图) |
一串 UTF-8 文本(可修改) |
|
字面量语法 |
单引号: |
双引号: |
无字面量,需通过函数创建 |
|
内存位置 |
栈上(4 字节) |
栈上(指针+长度),数据可能在静态区或堆 |
栈上(指针+长度+容量),数据在堆上 |
|
所有权 |
有(变量持有值) |
无(借用) |
有(拥有堆内存) |
|
可变性 |
不可变(变量本身可重新赋值) |
不可变 |
可变 |
|
编码 |
Unicode 码点(固定 4 字节) |
UTF-8(变长) |
UTF-8(变长) |
|
典型用途 |
处理单个字符,如遍历字符串的字符 |
函数参数、字符串切片、子串引用 |
动态构建、修改、拥有字符串 |
5、相互关系与转换
-
String↔&str:-
&String自动解引用为&str(因Dereftrait)。 -
显式转换:
let s: &str = &string;或string.as_str()。 -
从
&str创建String:String::from(slice)或slice.to_string()。
-
-
String↔char:-
遍历
String的字符:for c in string.chars() { ... }得到char。 -
从
char构建String:let s: String = c.to_string();或String::from(c)。
-
理解这三者的区别是掌握 Rust 字符串处理的关键。
3.3 标量型练习
练习 1:比较两个char输入值是否相等,并返回一个bool结果。
#![allow(unused)]
pub fn add(x: char, y: char) -> bool {
if x == y {
return true;
} else {
return false;
}
}
fn main() {
let z: bool = add('h', 'h');
println!("{z}");
}练习 2:将三个相同类型的输入相加f32,并返回总和。
#![allow(unused)]
pub fn cast(x: u8, y: i8, z: f32) -> f32 {
let x: f32 = x as f32;
let y: f32 = y as f32;
x + y + z
}
fn main() {
let sum: f32 = cast(25, 36, 18.23);
println!("sum = {sum}");
}
3.4:溢出
3.4.1 理解 Rust 中的整数溢出
编程语言中的整数类型,例如u3232 位无符号整数 (unsigned int) 或i3232 位有符号整数 (signed int),其可表示的值范围有限。当算术运算试图生成超出给定位数所能表示范围的数值时,就会发生整数溢出。例如,尝试将最大值加1,u32就会导致溢出。类似地,当运算结果低于最小可表示值时,就会发生下溢。Rust 有专门处理这些情况的方法,调试版本和发布版本的方法有所不同。
3.4.2 默认溢出行为:调试模式与发布模式
Rust 处理整数溢出的方法默认取决于编译配置文件:调试模式(开发期间的默认模式)或发布模式(使用标志编译生产版本时--release)。
1、调试模式(默认)
当您以调试模式编译并运行 Rust 代码时(例如,使用 --debug cargo run),Rust 会检查整数溢出。如果算术运算导致溢出,程序会 panic,立即终止并发出警报。此行为旨在帮助在开发过程早期发现 bug。
请看以下示例:
// main.rs or examples/overflow.rs
fn main() {
let mut x = u32::MAX; // x is the maximum value a u32 can hold (2^32 - 1)
println!("Initial x: {}", x);
x += 1; // Attempt to increment beyond the maximum
println!("u32 max: {}, x after increment: {}", u32::MAX, x);
}如果在调试模式下运行此代码(例如,使用 --debug 命令cargo run),则输出结果为:
Initial x: 4294967295
thread 'main' panicked at 'attempt to add with overflow', src/main.rs:5:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace程序在该行崩溃x += 1;,因为u32::MAX + 1无法用u32类型表示。
2、发布模式(--release)
--release使用 --proto-perform 标志(例如 --proto-perform)编译生产版本时cargo run --release,Rust 会优先考虑性能。在这种模式下,整数溢出检查默认被禁用。不会触发 panic,溢出的无符号整数运算会使用二进制补码表示进行“回绕”。例如,对于 a u32,这意味着 u32::MAX + 1a 变为 b 0,u32::MAX + 2`b` 变为1`c`,依此类推。类似地,a0 - 1也会回绕到 `b` u32::MAX。
运行与上述相同的代码,但使用以下--release标志进行编译:
// main.rs or examples/overflow.rs
fn main() {
let mut x = u32::MAX; // x is the maximum value a u32 can hold
println!("Initial x: {}", x);
x += 1; // Attempt to increment beyond the maximum, will wrap in release mode
println!("u32 max: {}, x after increment: {}", u32::MAX, x);
}输出结果为:
Initial x: 4294967295
u32 max: 4294967295, x after increment: 0这里, x 的值x递增超过了u32::MAX,由于溢出,它的值回绕到了0。虽然这种回绕行为在某些算法(例如密码学或某些嵌入式环境)中可能是理想的,但如果没有预先预料到,也可能导致一些不易察觉的错误。
3.4.3 显式处理整数溢出
Rust 在整数类型上提供了一系列方法,用于显式控制如何处理溢出,无论代码是在调试模式还是发布模式下编译。这些方法允许进行更安全、更可预测的算术运算。所有基本整数类型(例如 u8、u32、i64、isize)都提供了这些方法。这里,我们来看两种常见的加法方法:
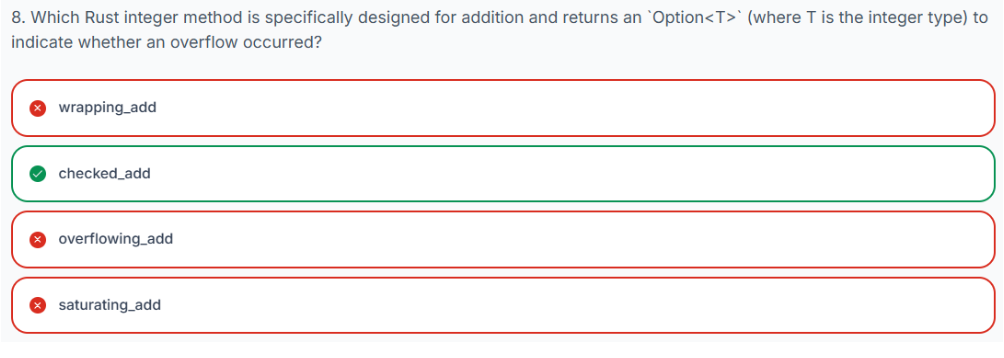
1. checked_add
checked_add 方法执行加法并返回一个 Option<T>,其中 T 是整数类型。
-
如果加法导致溢出,checked_add 会返回 None。
-
如果加法成功(无溢出),它会返回 Some(result),其中 result 是计算出的和。
Option 枚举是 Rust 中用于表示可能不存在的值的标准方式。None 表示值不存在(在这里是因为溢出),而 Some 则包裹了一个成功计算出的值。
案例:
fn main() {
// 调用 u32 类型的 checked_add 方法,尝试计算 u32::MAX (4294967295) + 1
// 由于结果会超出 u32 的范围(最大值 4294967295),发生溢出,因此返回 None
let result_overflow: Option<u32> = u32::checked_add(u32::MAX, 1);
// 打印结果,预期输出:checked_add(u32::MAX, 1):None
println!("checked_add(u32::MAX, 1):{:?}", result_overflow);
// 调用 checked_add 计算 3 + 1,结果在 u32 范围内,不会溢出
// 返回 Some(4),包裹在 Option 枚举中
let result_valid: Option<u32> = u32::checked_add(3, 1);
// 打印结果,预期输出:checked_add(3, 1):Some(4)
println!("checked_add(3, 1):{:?}", result_valid);
}输出(调试模式和发布模式下的行为一致):
checked_add(u32::MAX, 1): None
checked_add(3, 1): Some(4)这样,您可以通过检查结果是否为真来优雅地处理潜在的溢出None。
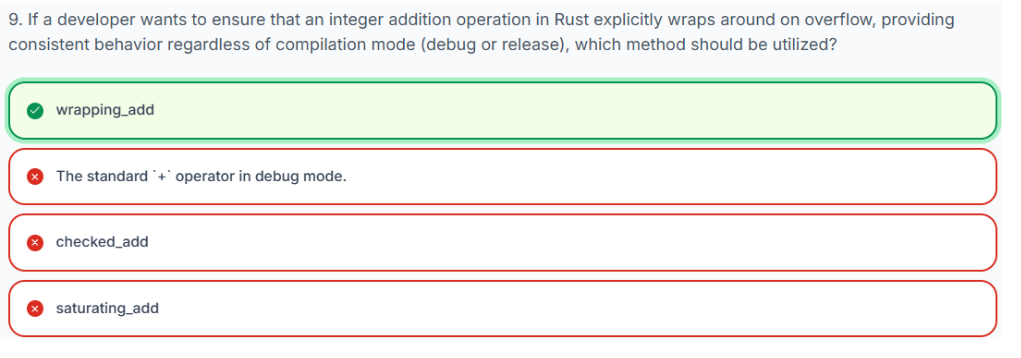
2、wrapping_add
该wrapping_add方法显式地使用二进制补码运算执行加法运算。
-
如果发生溢出,则值会循环,这与释放模式下标准算术运算符的行为类似。
-
它总是直接返回结果值(而不是一个
Option)。
当您有意想要实现包装行为时,此方法非常有用,它可以使您的代码意图清晰明了,而无需考虑编译模式。
例子:
fn main() {
// 使用 wrapping_add 方法对 u32 类型的最大值 (4294967295) 进行加 1 操作
// wrapping_add 在溢出时会自动回绕:最大值加 1 会绕回到 0
let result_wrap = u32::wrapping_add(u32::MAX, 1);
// 打印结果,预期输出:wrapping_add(u32::MAX, 1): 0
println!("wrapping_add(u32::MAX, 1): {}", result_wrap);
// 使用 wrapping_add 进行一个不会溢出的正常加法:3 + 1
// 由于结果仍在 u32 范围内,直接返回 4
let result_valid = u32::wrapping_add(3, 1);
// 打印结果,预期输出:wrapping_add(3, 1): 4
println!("wrapping_add(3, 1): {}", result_valid);
}输出(调试模式和发布模式下的行为一致):
wrapping_add(u32::MAX, 1): 0
wrapping_add(3, 1): 4这里,u32::MAX + 1显式地包装到0。
3.4 应对溢出的关键要点
-
生产代码(--release):请注意,当使用
--release进行编译时,整数溢出的默认行为会从 panic(崩溃)变为回绕(针对无符号类型)。这是一种优化,但需要仔细考虑潜在的算术问题。 -
安全性与性能:调试模式下溢出即 panic 的行为非常适合在开发过程中捕获错误。发布模式下的回绕行为可以提供更好的性能,但如果没有有意识地处理溢出,可能会隐藏逻辑错误。
-
通过显式控制确保健壮性:使用
checked_add、wrapping_add、saturating_add(它会将结果限制在类型的最大值/最小值)以及overflowing_add(它返回一个包含结果和表示是否溢出的布尔值的元组)等方法,可以提供精细的控制。这些显式方法能使你的代码意图清晰,并且在调试和发布模式下行为一致。其他运算如减法(checked_sub)、乘法(wrapping_mul)等也都有对应的方法。 -
Option<T> 枚举:像
checked_add这样的方法会返回一个Option<T>,这是 Rust 中用于处理可能不存在的值的基础枚举。你可以使用match语句或unwrap_or、expect等方法来处理Option值。 -
调试打印:为了打印
Option类型或其他复杂的数据结构以便检查,请在println!和其他格式化宏中使用{:?}格式说明符。 -
通用性:这些显式的溢出处理方法适用于 Rust 中所有的原始整数类型(例如
u8、i16、u64、isize)。
理解并有意识地决定如何处理潜在的整数溢出和下溢,对于编写健壮、正确且安全的 Rust 程序至关重要,尤其是在 Web3、系统编程或任何数值精度和可靠性至关重要的应用中。通过利用 Rust 的类型系统和显式溢出处理方法,开发者可以构建更安全、更可预测的应用程序。
3.4 测试







3.5 元组
3.5.1 理解 Rust 中的元组
在 Rust 中,元组是一种复合数据类型,它允许你将一组值组合在一起。元组是该语言的基础组成部分,它提供了一种管理相关数据的简单方法。元组具有以下几个关键特性:
-
固定大小:元组一旦声明,其元素数量就不能改变。此大小是固定的,必须在编译时确定。
-
混合类型:与数组不同,元组中的元素可以是不同的数据类型。例如,一个元组可以包含一个整数、一个布尔值和一个字符。
-
编译时已知: Rust 程序编译时必须确定元素的数量(大小)和每个元素的具体数据类型。
这些特性使得元组适用于需要少量、固定集合且可能异构的项的场景。
3.5.2 创建和声明元组
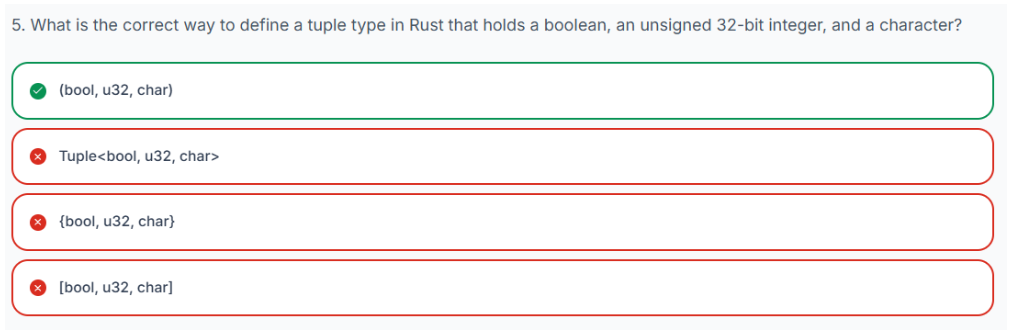
在 Rust 中创建元组非常简单。只需将值放在圆括号内(),并用逗号分隔每个值即可。声明元组时,还可以提供类型注解来显式定义每个元素的类型。
请看以下示例:
// Tuples - fixed size, mixed types, known at compile time
fn main() {
let t: (bool, char, u32) = (true, 'a', 1);
// ...
}在这段代码片段中:
-
let t: (bool, char, u32)将变量声明t为元组。类型注解(bool, char, u32)指定此元组将包含三个元素:一个布尔值、一个字符和一个 32 位无符号整数,顺序如此。 -
= (true, 'a', 1);t使用相应的值初始化元组:true布尔值、'a'字符和1u32 整数。
3.5.3 访问元组元素
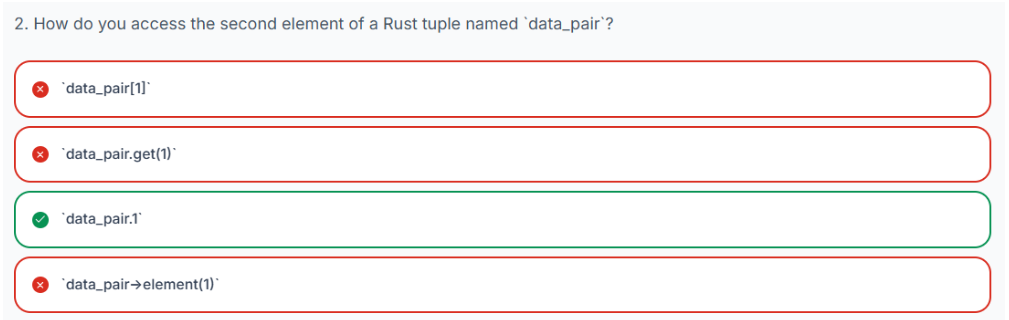
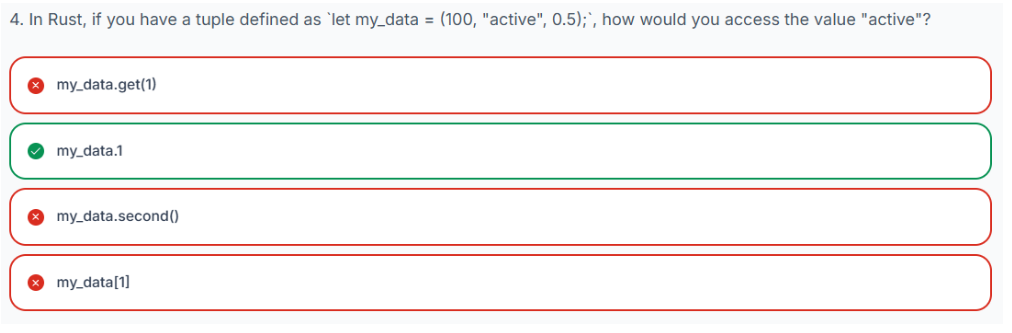
要访问元组中的各个元素,Rust 使用点表示法,后跟要检索的元素的从零开始的索引。
-
tuple_name.0访问第一个元素。 -
tuple_name.1访问第二个元素。 -
如此往复,对元组中的每个元素都进行此操作。
让我们在之前的例子基础上,进一步演示元素访问:
fn main() {
let t: (bool, char, u32) = (true, 'a', 1);
println!("{}, {}, {}", t.0, t.1, t.2);
}当这段代码被编译并运行(例如,使用 cargo run --example tuple)时,println! 宏会访问 t.0(其值为 true)、t.1(其值为 'a')和 t.2(其值为 1)。输出结果将是:
true, a, 13.5.4 空元组:Rust 的单位类型
Rust 具有一种特殊的元组:空元组,记作 ()。这种空元组拥有一个独特的类型,称为单元类型。单元类型表示不存在有意义的数值。它在概念上类似于 C 或 Java 等语言中的 void,但在 Rust 中,() 是一个真实的类型,并且拥有一个唯一的值(也是 ())。
// Empty tuple = unit type
let t = (); // 't' is now of the unit type单位类型在多种情况下都起着重要作用:
-
函数的隐式返回:如果 Rust 中的函数没有显式指定返回类型,它会隐式返回单元类型() 。
fn no_return() {} // Implicitly returns ()-
显式返回单元类型:函数也可以显式声明其返回单元类型。
fn return_empty_tuple() -> () {} // Explicitly returns ()从功能上讲,no_return() 和 return_empty_tuple() 是等价的。
-
使用场景:单元类型经常与
Result<T, E>枚举一起使用,特别是当操作可以成功而不需要返回特定数据,或者可能因错误而失败时。例如,Result<(T), String)>表示成功时函数返回Ok((T))(表示成功但没有特定值),失败时返回Err(String)(包含错误信息)。
// Example of how unit type is used with Result
// A function returning Result<(), String> would yield:
// Ok(()) on success, or
// Err("some error message") on failure.-
虽然单元类型最初可能看起来很抽象或不太有用,但在使用 Rust 时,你会经常遇到它,尤其是在惯用的错误处理和函数签名中。
3.5.5 使用嵌套元组
Rust 中的元组还可以包含其他元组作为元素。这使得创建嵌套数据结构成为可能。这些嵌套元组本身可以拥有不同的数据类型和大小。
以下是一个嵌套元组的示例:
// Nested tuple
let nested = (('a', 1.23), (true, 1u32, -1i32), ());在此声明中:
-
nested是一个包含三个元素的元组。 -
第一个元素是
('a', 1.23),一个包含 achar和 an 的元组f64(Rust 默认推断1.23为f64)。 -
第二个元素是
(true, 1u32, -1i32)一个元组,包含一个bool、一个u32和一个i32。 -
第三个元素是
()空元组(单元类型)。
要访问内部元组中的元素,首先需要使用索引访问内部元组本身,然后再使用索引访问该内部元组中所需的元素。为了清晰起见或出于运算符优先级规则的考虑,初始访问操作可能需要使用()括号。
// In main() after 'nested' tuple is declared:
println!("nested.0.1: {}", (nested.0).1);让我们来分析一下(nested.0).1:
-
nested.0访问元组的第一个元素nested,即内部元组('a', 1.23)。 -
然后,
.1对这个内部元组应用('a', 1.23),访问其第二个元素(索引为 1),即1.23。
该println!语句的输出结果为:
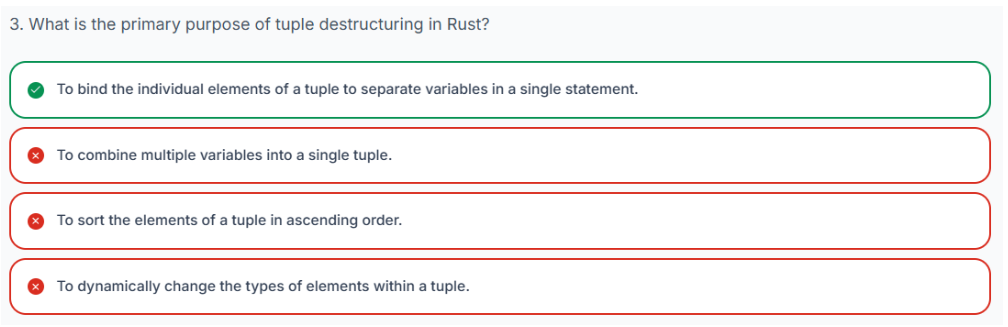
nested.0.1: 1.233.5.6 解构元组以便更轻松地访问
解构是 Rust 中一个强大且便捷的特性,它允许你在单个 let 语句中将元组拆开,并将其各个值绑定到不同的变量上。这是通过在 let 赋值的左侧使用一个与元组结构相匹配的模式来实现的。
请看下面这个解构元组的示例:
// Destructuring a tuple
let t: (bool, char, u32) = (true, 'a', 1); // Original tuple
let (a, b, c) = t; // Destructuring assignment
println!("a = {}, b = {}, c = {}", a, b, c);在这一行中let (a, b, c) = t;:
-
该模式
(a, b, c)与元组的结构相匹配t。 -
t(t.0,即)的第一个元素true绑定到变量a。 -
t(t.1,即)的第二个元素'a'绑定到变量b。 -
t(t.2,即)的第三个元素1绑定到变量c。
输出结果为:
a = true,b = a,c = 1部分解构(忽略值):
有时,你可能只对元组中的某些元素感兴趣,而希望忽略其他元素。Rust 允许你使用下划线_作为占位符来表示不需要的值,从而实现这一点。
// Partial destructuring (ignore first and last values)
let t: (bool, char, u32) = (true, 'a', 1); // Assuming 't' is available
let (_, b, _) = t;
// Now, 'b' holds the value of t.1, which is 'a'.
// 'a' (from the previous destructuring) and 'c' are not affected here;
// the values t.0 and t.2 are simply ignored in this specific destructuring.在这种情况下,let (_, b, _) = t;它将的第二个元素t(即'a')赋值给变量b。t的第一个和第三个元素实际上被这种解构赋值忽略了。
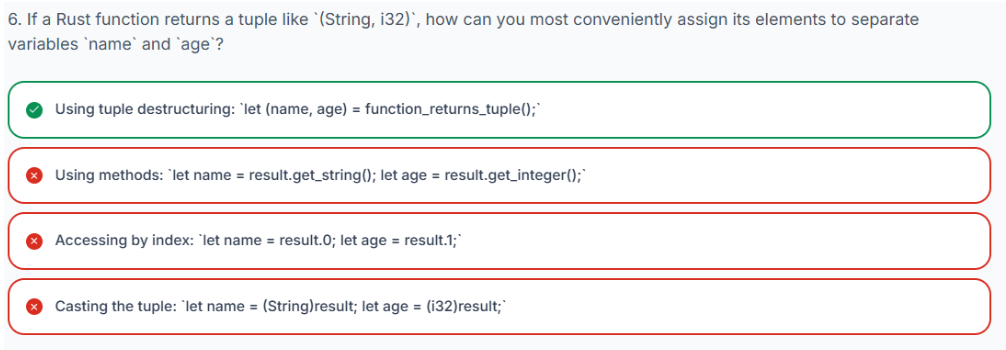
3.5.7 返回元组多个值的函数
在 Rust 中,元组最常见且最符合语言习惯的用途之一,就是让函数能够返回多个值。函数不再局限于只返回一个值,而是可以返回一个包含多个(可能类型不同的)值的元组。
要实现这一点,需要将函数的返回类型声明为一个元组,并在其中明确指定它将要返回的各个值的类型。
fn return_many() -> (u32, bool) {
(1u32, true) // Returns a tuple containing a u32 and a bool
}在这里,函数 return_many 被声明为返回一个元组 (u32, bool)。在函数内部,(1u32, true) 创建并返回一个与此类型匹配的元组实例。
当你调用这样的函数时,你可以直接将返回的元组解构成单独的变量,从而方便地处理多个返回值:
// In main():
// Function that returns multiple values using a tuple
let (num_value, bool_value) = return_many();
// After this line:
// 'num_value' will hold 1u32
// 'bool_value' will hold true
// You can then use num_value and bool_value as needed.
// For example: println!("Number: {}, Boolean: {}", num_value, bool_value);这种返回和解构元组的模式是 Rust 中处理函数多个输出的一种简洁高效的方式,增强了代码的可读性和表达能力。
3.6 :元组练习
练习 1:返回元组中的第一个元素t。
#![allow(unused)]
pub fn first(t: (bool, u32, char)) -> bool {
return t.0;
}
fn main() {
let tu: (bool, u32, char) = (true, 23, 'g');
let mut bo: bool = first(tu);
println!("{bo}");
}
练习 2:返回元组中的最后一个元素t。
#![allow(unused)]
pub fn first(t: (bool, u32, char)) -> char {
// 通过解构的方式来完成元组最后一个元素的提取
let (_,_,to) = t;
return to;
}
fn main() {
let tu: (bool, u32, char) = (true, 23, 'g');
let mut bo: char = first(tu);
println!("{bo}");
}
练习3:交换元组的第一个元素和第二个元素t。
#![allow(unused)]
pub fn swap(t: (u32, u32)) -> (u32, u32) {
let T: (u32, u32) = t;
return (T.1, T.0);
}
fn main() {
let tu: (u32, u32) = (23, 25);
let bo: (u32, u32) = swap(tu);
println!("为交换之前的元组:tu = {:?},交换后的元组:bo = {:?}", tu, bo);
}
3.7 数组
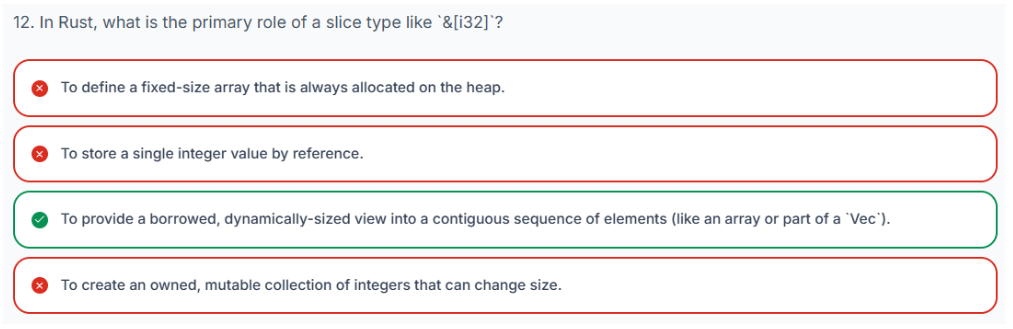
3.7.1 Rust 数组与切片:核心区别
在 Rust 中,数组和切片都用于处理相同类型的元素集合。然而,它们在长度管理方式上存在根本差异,这对它们的用法有重大影响。
-
数组:数组是一种元素集合,其长度在编译时是已知的。这意味着数组的大小必须是一个常量值,在 Rust 程序编译时确定。这种固定大小的特性使其可以分配在栈上并实现高效访问。
-
切片:另一方面,切片是一种元素集合,其长度不一定在编译时已知。切片的长度可以在运行时确定。切片通常是数组或其他集合类型(如 Vector)中某一部分的视图或“切片”。这种动态大小的特性提供了灵活性。
理解这一核心差异对于在 Rust 中有效使用这些数据结构至关重要。
注意:rust中的数组和切片的长度问题与go语言中存在相同之处。
7.2 Rust 中数组的使用
数组是 Rust 中将相同类型的固定数量元素连续存储在内存中的基本方式。
7.2.1 声明和初始化
数组的类型签名同时包含了其元素类型和固定长度。其形式为 [T; N],其中 T 是元素类型,N 是编译时常量长度。
考虑以下示例:
// Array
let arr: [u32; 3] = [1, 2, 3];
let arr:声明了一个名为arr的不可变变量。
[u32; 3]:这是类型标注。它表示一个包含u32类型(无符号 32 位整数)元素、固定长度为3的数组([ ])。
= [1, 2, 3];:使用值 1、2 和 3 初始化该数组。
7.2.2 访问数组元素
数组中的元素使用从 0 开始的索引进行访问,这意味着第一个元素的索引为 0,第二个元素的索引为 1,依此类推。
// Accessing an element from the 'arr' defined above
println!("arr[0]: {}", arr[0]);这段代码访问了arr数组的第一个元素(索引为 0)。执行后,输出结果为:
arr[0]: 17.2.3 数组的可变性和写入
在 Rust 中,变量(包括数组)默认是不可变的。要在数组声明之后修改其内容,必须使用 mut关键字将其声明为可变的。
// Write
let mut arr: [u32; 3] = [1, 2, 3];
arr[1] = 99;
// To observe the change, you can print the array:
// println!("{:?}", arr); // This would output: [1, 99, 3]-
let mut arr:声明一个名为arr的可变数组。 -
arr[1] = 99;:将索引为 1 的元素(第二个元素)的值修改为99。
7.2.4 使用默认值初始化数组
Rust 提供了一种便捷的简写语法,可以将数组中的所有元素初始化为相同的默认值。
#![allow(unused)]
fn main() {
let arr: [i32; 10] = [0; 10];
println!("arr:{:?}", arr)
}-
[0; 10]:此语法创建一个包含u32类型元素、长度为 10 的数组。该数组中的每个元素都被初始化为0。 -
println!("arr: {?}", arr);:使用调试格式化({?})打印整个数组。
这段代码的输出结果为:
arr: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]7.3 理解 Rust 中的切片
在 Rust 中,切片提供了一种强大且灵活的方式来引用另一个集合(如数组或 Vector)中的一段连续元素序列。与数组不同,切片并不拥有其指向的数据;它们是数据的“视图”或“引用”。
为了说明切片的使用,我们首先定义一个基础数组:
// Slice
let nums: [i32; 10] = [-1, 1, -2, 2, -3, 3, -4, 4, -5, 5];
// Corresponding indices: 0 1 2 3 4 5 6 7 8 9nums数组包含十个有符号的 32 位整数(i32)。
7.3.1 创建切片
切片本质上就是引用。因此,它们以与号(&)为前缀。一个不可变切片的类型是 &[T],其中 T 是它所引用的元素类型。从数组 arr_name 创建切片的语法是:
&arr_name[start_index...end_index]
需要注意的是,start_index 是包含的,而 end_index 是不包含的。
示例:取前 3 个元素的切片。要获得一个包含 nums 数组前三个元素(索引为 0、1、2 的元素)的切片:
let s: &[i32] = &nums[0..3]; // References elements -1, 1, -2这将创建一个类型为 &[i32] 的切片 s,它引用了 nums 数组中的子序列 [-1, 1, -2]。
示例:取最后 3 个元素的切片
要获得一个包含最后三个元素(索引 7、8 和 9)的切片:
let s: &[i32] = &nums[7..10]; // References elements 4, -5, 5此切片s将引用子序列[4, -5, 5]。
示例:截取中间 4 个元素
要获取数组中间的四个元素(例如,索引 3、4、5 和 6):
let s: &[i32] = &nums[3..7]; // References elements 2, -3, 3, -4
println!("mid 4: {:?}", s);该println!语句将输出:
mid 4: [2, -3, 3, -4]7.3.2 切片语法简写
Rust 为常见的切片操作提供了方便的简写形式:
-
从开头开始切片:如果你想要从数组的开头(索引 0)切片到某个特定的
end_index(不包含),可以省略0。
&array[...end_index] 等同于 &array[0...end_index]
例如,&nums[...3] 与 &nums[0...3] 相同-
切片到末尾:如果你想要从某个
start_index(包含)切片到数组的末尾,可以省略end_index。Rust 会将其推断为数组的长度。
&array[start_index..] 等同于 &array[start_index..array.len()]
例如,对于长度为 10 的 nums 数组,&nums[7..] 与 &nums[7..10] 相同。-
切片整个数组:要创建一个引用整个数组的切片,可以使用:
&array[..]7.3.3 切片的本质:它们是引用
一个关键点是,切片会从它们的来源(例如数组或 Vector)借用数据。它们本身并不拥有这些数据。这是 Rust 所有权和借用系统的核心概念,确保了内存安全。切片的生命周期不能超过它所引用的数据的生命周期。虽然这些例子中没有详细说明,但如果底层数据源是可变的,你也可以拥有可变切片(&mut [T]),从而允许修改借用的数据。
3.8 数组练习
练习 1:返回一个包含 100 个元素的数组,所有元素的值均为 0。
#![allow(unused)]
pub fn zeros() -> [u32; 100] {
let tu: [u32; 100] = [0; 100];
return tu;
}
fn main() {
let arr: [u32; 100] = zeros();
println!("arr:{:?}", arr)
}
练习 2:返回前 3 个元素的切片s
#![allow(unused)]
pub fn first_3(s: &[u32]) -> &[u32] {
return &s[..3];
}
fn main() {
let spl: &[u32] = &[12, 23, 56, 89, 45, 65];
let arr: &[u32] = first_3(spl);
println!("arr = {:?}", arr)
}
练习3:返回数组最后 3 个元素的切片s。
#![allow(unused)]
// 此函数为考虑输入切片数量小于3的情况
// pub fn last_3(s: &[u32]) -> &[u32] {
// let le: usize = s.len() - 3;
// return &s[le..];
// }
pub fn last_3(s: &[u32]) -> &[u32] {
if s.len() < 3 {
&[] // 或者 panic,根据需求决定
} else {
let start: usize = s.len() - 3;
&s[start..]
}
}
fn main() {
let spl: &[u32] = &[12, 23, 56, 89, 45, 65];
let arr: &[u32] = last_3(spl);
println!("arr = {:?}", arr)
}
3.9 测试






3.10 字符串
3.10.1 掌握 Rust 中的字符串:String对比&str
欢迎阅读这本关于 Rust 中文本处理的全面指南。理解 Rust 如何管理字符串,是编写高效且安全代码的基础。Rust 提供了两种主要的字符串类型:String,一种拥有的、堆分配的字符串;以及 &str(读作"字符串切片"),它是对字符串数据的引用。本课将深入探讨它们的特点、使用场景、创建方式、操作方法以及它们之间的相互关系。
3.10.2 理解 Rust 的主要字符串类型String 和 &str
Rust 字符串处理的核心是 String 和 &str。让我们逐一探讨。
1、String (大写 'S')
-
本质:
String是一种拥有类型。这意味着当你拥有一个String时,你的变量直接拥有存储在堆上的字符串数据。这使得字符串可以增长和修改。 -
何时使用
String:-
需要所有权:当字符串数据需要比当前函数调用或作用域存活更长时间,或者需要从函数返回时,
String是合适的选择。 -
需要可变性:如果你打算修改字符串(例如,追加字符、清空内容、插入子串),你需要一个
String。
-
2、&str (字符串切片)
-
本质:
&str是一种借用类型,具体来说是"切片"。它是一个对 UTF-8 编码字节序列的不可变引用。可以将其视为对字符串数据的"视图",这些数据可能由一个String拥有,也可能是直接嵌入在程序二进制文件中的字符串字面量。 -
字符串字面量:当你编写
let message = "hello";时,message的类型是&'static str。&表示它是一个引用,str表示它是一个字符串切片,而'static是一个生命周期注解,表明该字符串数据在整个程序运行期间都是有效的。 -
何时使用
&str:-
只读访问:当你只需要读取或检查字符串数据而无需修改时。
-
处理字符串字面量:字符串字面量本质上就是
&str。 -
函数参数(灵活性):当函数只需要读取字符串时,通常首选将其用作函数参数。这是因为,得益于一种称为解引用强制转换的特性,
&str既可以接受字符串字面量,也可以接受对String的引用,从而使你的函数更加通用。
-
解引用强制转换是 Rust 中一种编译时自动将实现了
Dereftrait 的类型的引用(如&String)转换为目标类型的引用(如&str)的机制。例如,因为String实现了Deref<Target=str>,所以当函数需要&str参数时,可以直接传入&String,Rust 会自动进行转换,无需手动调用as_str()或切片操作。这一特性让代码更简洁灵活,同时保持了零运行时开销,并常见于智能指针(如Box<T>、Vec<T>)与它们所包裹类型之间的转换。
3.10.3 String:创建和基本操作
我们来看看如何创建 String 类型并对其执行基本操作。
1、 创建一个String
有多种创建拥有型 String 的惯用方法:
(1)使用 String::from():这是一种常见的方法,用于将字符串字面量(即 &str)或其他实现了 Into<String> trait 的类型转换为拥有型 String。
// fn main() {
let msg: String = String::from("Hello Rust");
// }(2)使用 .to_string() 方法:许多类型,包括字符串字面量(即 &str),都实现了 ToString trait,该 trait 提供了 .to_string() 方法来创建一个 String。
// fn main() {
let msg: String = "Hello Rust".to_string();
// }(2)获取长度String
你可以使用 .Len() 方法确定 String 的长度。需要注意的是,.Len()返回的是字符串的字节大小,不一定是字符数量。这是因为 Rust 字符串是 UTF-8 编码的,单个字符可能占用多个字节。
// fn main() {
let msg: String = String::from("Hello Rust");
let length: usize = msg.len(); // length will be 10 (number of bytes)
// println!("Length: {}", length);
// }usize 类型是一种无符号整数类型。其大小(例如,32位或64位)取决于程序编译所针对的计算机架构,这使其非常适合用于索引和表示内存大小。
usize类型的大小与目标平台的指针大小一致(32位系统上为4字节,64位系统上为8字节),因此它能完整覆盖该平台下所有可能的内存地址范围,确保任何索引或内存大小都不会超出平台的寻址能力,从而安全、高效地用于集合索引和内存操作,同时使代码在不同架构间无缝迁移。
3.10.4 操作 &str(字符串切片):创建
字符串切片(&str)是对字符串数据的引用。以下是获取它们的方法:
1、从字符串字面量获取:如前所述,字符串字面量本身就是字符串切片。
// fn main() {
let s: &str = "Hello World"; // s is a &'static str
// }2、通过引用 String 创建:你可以创建一个 &str,它引用现有 String 的整个内容。
// fn main() {
let msg: String = String::from("Hello Rust");
let s: &str = &msg; // s is a slice referencing all of msg
// }在这里,s 借用了 msg 拥有的数据。
3、通过切片 String:你可以使用范围语法创建一个 &str,它引用 String 的特定部分(即:切片)。
// fn main() {
let msg: String = String::from("Hello Rust");
// Create a slice containing "Hello" (indices 0 up to, but not including, 5)
let s: &str = &msg[0..5];
println!("s = {}", s);
// }输出结果为:
s = Hello切片时需谨慎:如果范围边界未落在有效的 UTF-8 字符边界上,程序将会 panic。
3.10.5 搭建桥梁:String 与 &str 之间的转换
Rust 提供了在两种字符串类型之间转换的无缝方式。
-
将
&str转换为String: 如果你有一个字符串切片(&str)并且需要一个拥有型String(可能为了修改它或从函数返回它),可以使用.to_string()或String::from():
// fn main() {
let s_slice: &str = "Hello World";
let owned_string_v1: String = s_slice.to_string();
let owned_string_v2: String = String::from(s_slice);
// }-
将
&String转换为&str(解引用强制转换): 这是一种强大且通常是隐式的转换。Rust 可以自动将对String的引用(即&String)转换为字符串切片(&str)。这得益于一种称为“解引用强制转换”的特性。String类型实现了Dereftrait,使得它在许多上下文中(尤其是在传递函数参数时)可以被当作&str来使用。
考虑一个设计用于打印其接收到的任意字符串数据的函数:
#![allow(unused)] // 这个属性允许编译器忽略未使用的代码警告,方便示例运行
// 定义一个函数,它接受一个字符串切片(&str)作为参数
// 使用 &str 可以让函数更灵活,因为它既可以接收字符串字面量,也可以接收 String 的引用
fn print_message(s: &str) {
println!("{s}"); // 打印传入的字符串内容
}
fn main() {
// 创建一个拥有所有权的 String 类型变量,内容为 "Hello from String"
let msg_string: String = String::from("Hello from String");
// 调用 print_message 时传入 &msg_string,即对 String 的引用
// 由于 String 实现了 Deref<Target=str>,Rust 会自动将 &String 转换为 &str
// 这就是解引用强制转换,因此这里可以顺利编译并运行
print_message(&msg_string);
// 创建一个字符串字面量,它的类型是 &'static str,本质上就是一个字符串切片
let s_literal: &str = "Hello from literal";
// 直接传入字符串字面量,因为参数类型就是 &str,完美匹配
print_message(s_literal);
}-
如果将
print_message定义为fn print_message(s: &String),那么尝试直接传递字符串字面量(即&str)将导致编译时错误。通过接受&str,函数变得更加灵活和符合 Rust 习惯,因为它可以处理任何字符串数据,而无需获取所有权。
3.10.6 修改与构建字符串
虽然 &str 是不可变的,但 String 被设计用于修改和动态构建。
1、向 String 追加 &str 你可以使用 += 运算符或 push_str 方法将字符串切片(&str)追加到可变的 String 中。+= 运算符在底层调用的是 push_str 方法。
// fn main() {
let mut msg: String = String::from("Hello Rust");
msg += " World"; // Appends the string slice " World"
// Alternatively: msg.push_str(" World");
println!("{}", msg); // Output: Hello Rust World
// }请注意,msg 必须声明为 mut(可变)才允许修改。
2、字符串插值(使用 format! 进行格式化)
当你需要从各种数据片段(其他字符串、数字等)构建一个新的 String 时,使用 format! 宏是比手动使用 + 或 += 拼接更推荐的方式。String 的 + 运算符在复杂情况下效率较低且可读性较差。
#![allow(unused)]
fn main() {
let name = "Rust"; // name is a &str
let version = 1.76; // version is an f64
let emoji = "🦀"; // emoji is a &str
// Desired string: "Learning Rust version 1.76 is fun! 🦀"
// Using format!
let s: String = format!("Learning {} version {} is fun! {}", name, version, emoji);
println!("{}", s); // Output: Learning Rust version 1.76 is fun! 🦀
}format! 宏的工作方式与 println! 类似,但不同的是,它不会将内容打印到控制台,而是返回一个新的、在堆上分配的 String。
3.10.7 关键考虑因素与最佳实践
1、在 String 和 &str 之间做选择:
-
当你需要字符串数据的所有权时(例如,从函数返回字符串、将其存储在比当前作用域存活时间更长的结构体中),或者当你需要修改字符串时,请使用
String。 -
对于字符串数据的只读视图,请使用
&str。它特别适用于那些不需要获取所有权或修改字符串的函数参数,因为这使得函数既能接受String的引用,也能接受字符串字面量。
2、利用解引用强制转换:请记住,Rust 的解引用强制转换(例如,将 &String 转换为 &str)能使 API 更加符合人体工程学。当只读访问足够时,应设计你的函数以接受 &str。
3、理解字符串字面量:字符串字面量(例如 "hello")的类型始终是 &'static str。这意味着它们是保证在整个程序运行期间都有效的字符串切片,因为它们通常被直接嵌入到编译后的二进制文件中。
3.10.8 实际用例回顾
本课涵盖了涉及 String 和 &str 的几种常见场景:
-
创建空的
String对象,或使用字面量中的数据预填充的String对象。 -
使用
.len()确定String的字节长度。 -
从现有的
String(整个字符串或部分字符串)或直接从字符串字面量创建字符串切片(&str)。 -
将字符串数据传递给函数,重点说明了由于解引用强制转换,使用
&str作为参数类型所带来的灵活性。 -
通过追加额外的字符串数据(切片)来修改
String。 -
使用
format!宏从各种组件构建新的、格式化的String。
通过掌握 String 和 &str 之间的区别与交互,你将能够在 Rust 程序中有效且符合习惯地处理文本数据。这些基础知识对于构建健壮且高性能的应用程序至关重要。
3.11 字符串练习
练习 1:创建一个返回String结果的函数 "Hello Rust"。
pub fn hello() -> String {
return "Hello Rust".to_string();
}
fn main() {
let hello: String = hello();
println!("{hello}");
}
练习 2:创建一个函数,返回“Hello”后跟name。
// 用于将标准库中的 LineWriter 类型引入当前作用域,以便在代码中直接使用 LineWriter,
// 而无需每次都写出完整的路径 std::io::LineWriter。
use std::io::LineWriter;
pub fn greet(name: &str) -> String {
let mut hello: String = "Hello ".to_string();
hello += name;
return hello;
}
fn main() {
let helloName: String = greet("zhangsan");
println!("{helloName}");
}
练习3:创建一个函数,将 "!" 追加到 s 上。
// 用于将标准库中的 LineWriter 类型引入当前作用域,以便在代码中直接使用 LineWriter,
// 而无需每次都写出完整的路径 std::io::LineWriter。
use std::io::LineWriter;
pub fn append(mut s: String) -> String {
let mut sss: String = s;
let mut appS = format!("{} !", sss);
return appS;
}
fn main() {
let helloName: String = append("zhangsan".to_string());
println!("{helloName}");
}
3.12 枚举
3.12.1 理解 Rust 中的枚举
枚举(enums)是 Rust 中一项强大的特性,它允许你通过列举所有可能的值(称为变体)来定义自定义数据类型。枚举类型的变量在任意时刻只能持有这些预定义变体中的一个。这使得枚举在表示状态、命令或任何值必须是几种不同可能性之一的场景时极为有用,从而增强了类型安全性和代码清晰度。
3.12.2 定义和使用自定义枚举
让我们通过一个实际示例来探索如何定义和使用枚举:一组用于视频播放器的命令。
我们在 main 函数外部定义一个名为 Command 的枚举。这个枚举将表示用户可以执行的各种操作。
// Placed at the top, outside fn main()
enum Command {
Play, // Simple variant, no associated data
Stop, // Simple variant, no associated data
Skip(u32), // Tuple-like variant, holds a u32 (timestamp)
Back(u32), // Tuple-like variant, holds a u32 (timestamp)
Resize { // Struct-like variant, holds named fields
width: u32,
height: u32,
},
}我们的 Command 枚举包含几个变体:
-
Play和Stop:这些是简单变体。它们不存储任何附加数据,类似于其他编程语言中的枚举值。 -
Skip(u32)和Back(u32):这些是元组结构体式变体。它们可以持有关联数据。在这个例子中,每个变体存储一个u32值,可以表示以秒为单位的时间戳。数据是未命名的,通过其位置来标识。 -
Resize { width: u32, height: u32 }:这是一个结构体式变体。它也存储关联数据,但与元组结构体式变体不同,它的字段是命名的(width和height),很像传统的结构体。
1、实例化枚举变体
一旦定义完成,我们就可以创建 Command 枚举的实例(或值)。以下是在 fn main() 或任何其他函数中执行此操作的方法:
(1)简易版:要创建命令实例Play:
let cmd: Command = Command::Play;(2)元组式变体:要创建该命令的一个实例Skip,指示玩家跳到 10 秒标记处:
let cmd: Command = Command::Skip(10); // Skip to timestamp 10(3)结构化变体:要创建该命令的实例Resize,请将播放器尺寸设置为 100x50 像素:
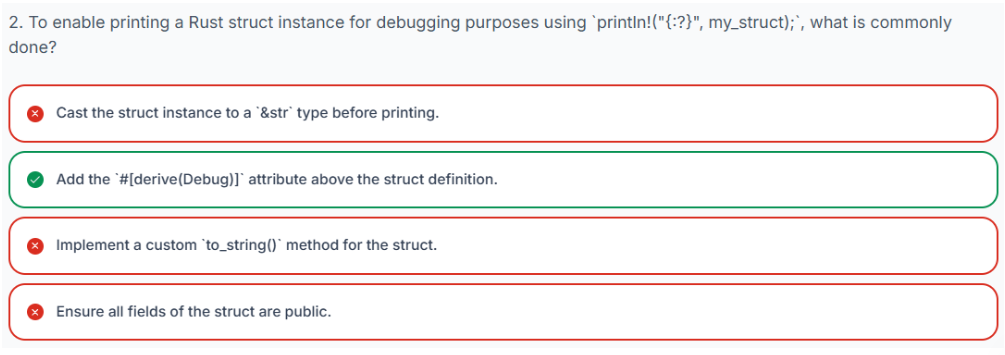
let cmd: Command = Command::Resize { width: 100, height: 50 };3.12.3 使枚举可打印#[derive(Debug)]
如果你尝试直接使用 printf("\{", cmd); 打印我们的 Command 枚举的一个实例,你将遇到编译错误。错误消息通常会指出 Command 没有实现 std::fmt::Display trait,这意味着 Rust 默认不知道如何将其格式化为面向用户的输出。
出于调试目的,Rust 提供了 Debug trait。我们可以使用 #[derive] 属性指示编译器为我们的枚举自动生成 Debug 的实现:
#[derive(Debug)] // Add this line above the enum definition
enum Command {
Play,
Stop,
Skip(u32),
Back(u32),
Resize {
width: u32,
height: u32,
},
}添加此功能后,您现在可以在宏中#[derive(Debug)]使用调试格式化程序打印枚举实例:{:?}println!
fn main() {
let cmd: Command = Command::Resize { width: 100, height: 50 };
println!("{:?}", cmd);
}这将产生类似如下的输出:
Resize { width: 100, height: 50 }3.12.4 使用 #[derive(PartialEq)] 比较枚举实例
通常,你需要比较两个枚举实例是否相同。假设我们有两个 Command 实例:
let cmd0: Command = Command::Play;
let cmd1: Command = Command::Skip(10);如果你尝试直接使用 cmd0 == cmd1 比较它们,你会遇到另一个编译错误。这次,编译器会指出 Command 可能缺少 PartialEq(部分相等)trait 的实现。与 Debug 类似,我们可以为枚举自动派生 PartialEq:
#[derive(Debug, PartialEq)] // Add PartialEq to the derive attribute
enum Command {
Play,
Stop,
Skip(u32),
Back(u32),
Resize {
width: u32,
height: u32,
},
}现在,比较功能将按预期运行:
#![allow(unused)] // 这个属性允许编译器忽略未使用的代码警告,使示例可以顺利编译
// 使用 derive 属性让编译器自动实现 Debug 和 PartialEq trait
// Debug 允许使用 {:?} 格式化打印枚举实例
// PartialEq 允许使用 == 和 != 比较枚举实例
#[derive(Debug)]
#[derive(PartialEq)] // 也可以合并为 #[derive(Debug, PartialEq)]
enum Command {
Play, // 简单变体,无关联数据
Stop, // 简单变体,无关联数据
Skip(u32), // 元组结构体式变体,包含一个 u32 数据(表示跳过的秒数)
Back(u32), // 元组结构体式变体,包含一个 u32 数据(表示后退的秒数)
Resize { width: u32, height: u32 }, // 结构体式变体,包含两个命名字段
}
fn main() {
// 创建一个 Command::Resize 实例,并指定 width 和 height 字段的值
let cmd: Command = Command::Resize {
width: 100,
height: 50,
};
// 使用 {:?} 格式化输出,因为 Command 实现了 Debug trait
println!("{:?}", cmd);
// 创建两个 Command 实例用于比较
let cmd0: Command = Command::Play; // Play 变体
let cmd1: Command = Command::Skip(10); // Skip 变体,数据为 10
// 比较 cmd0 和 cmd1 是否相等,由于 PartialEq 的存在,可以直接使用 ==
// Play 和 Skip 是不同的变体,所以结果为 false
println!("cmd0 == cmd1:{}", cmd0 == cmd1);
// 创建两个相同的 Play 实例
let cmd_play1: Command = Command::Play;
let cmd_play2: Command = Command::Play;
// 两个 Play 变体没有数据,因此它们相等,结果为 true
println!("cmd_play1==cmd_play2:{}", cmd_play1 == cmd_play2);
// 创建两个相同的 Skip 实例,都包含数据 10
let cmd_skip1: Command = Command::Skip(10);
let cmd_skip2: Command = Command::Skip(10);
// 两个 Skip 变体数据相同,因此相等,结果为 true
println!("cmd_skip1==cmd_skip2:{}", cmd_skip1 == cmd_skip2);
// 创建一个 Skip 实例,数据为 20
let cmd_skip3: Command = Command::Skip(20);
// 比较 cmd_skip1(数据 10)和 cmd_skip3(数据 20),数据不同,结果为 false
println!("cmd_skip1==cmd_skip3:{}", cmd_skip1 == cmd_skip3)
}枚举的工作原理PartialEq:
-
相同简单变体的实例是相等的(例如
Command::Play == Command::Play)。 -
不同变体的实例永远不相等(例如
Command::Play ≠ Command::Skip(10))。 -
持有数据的相同变体实例,当且仅当它们关联的数据也相等时才相等。例如,
Command::Skip(10)等于Command::Skip(10),但Command::Skip(10)不等于Command::Skip(20)。结构体式变体会逐个字段进行比较。
3.12.5 枚举Option<T>:处理可选值
Rust 的标准库提供了几个极其有用的枚举。其中最基本的一个是 Option<T>。该枚举旨在表达某个值可能存在也可能缺失的可能性。它的概念定义如下:
// enum Option<T> {
// Some(T), // Represents the presence of a value of type T
// None, // Represents the absence of a value
// }在这里,T 是一个泛型类型参数,意味着 Option 可以持有任何类型的值。
-
Some(T):表示存在一个类型为T的值。 -
None:表示没有值。
Option<T> 的主要目的是帮助开发者避免其他语言中常见的“空指针”或“空引用”错误。通过将值可能缺失的可能性直接编码到类型系统中,Rust 强制你处理 None 的情况,从而生成更健壮的代码。
Option<T> 的示例:
let x: Option<i32> = Some(5); // x contains the integer value 5
let y: Option<i32> = None; // y contains no value
let z: Option<f64> = Some(3.14);
let name: Option<String> = None;Option<T> 的一个常见用例是安全地访问集合(如数组或向量)中的元素。与直接索引(例如 my_array[index])不同——如果索引越界,直接索引可能导致程序崩溃——像 .get(index) 这样的方法会返回一个 Option。如果索引有效,.get 返回 Some(&element);否则返回 None。这使你能够优雅地处理元素可能不存在的情况。
案例:
fn main() {
// 示例1: 直接创建 Option 值
// Some(42) 表示存在一个 i32 类型的值 42
let some_number: Option<i32> = Some(42);
// None 表示没有值,类型仍需标注为 Option<i32>
let no_number: Option<i32> = None;
// 使用 match 表达式处理 Option,必须处理所有可能的分支
println!("处理 some_number:");
match some_number {
Some(value) => println!(" 存在值: {}", value), // 当 some_number 是 Some 时,取出内部值
None => println!(" 没有值"), // 当 some_number 是 None 时执行
}
println!("处理 no_number:");
match no_number {
Some(value) => println!(" 存在值: {}", value),
None => println!(" 没有值"),
}
// 示例2: 使用 if let 简化处理(只关心 Some 情况)
// 如果 some_number 是 Some,则将内部值绑定到 value 并执行代码块;否则忽略
if let Some(value) = some_number {
println!("if let 捕获到值: {}", value);
}
// 示例3: 从向量中安全获取元素
let fruits = vec!["苹果", "香蕉", "橙子"];
let index = 5; // 超出范围的索引,直接使用 fruits[index] 会导致 panic
// 使用 .get() 方法返回 Option<&T>,避免越界 panic
match fruits.get(index) {
Some(fruit) => println!("索引 {} 对应的水果: {}", index, fruit),
None => println!("索引 {} 超出范围,没有水果", index),
}
// 示例4: 组合 Option 操作(如 map、unwrap_or)
let maybe_number: Option<i32> = Some(10);
// map 方法:如果 Option 是 Some,则对其内部值应用闭包,返回新的 Some(闭包结果)
// 如果是 None,则直接返回 None
let doubled = maybe_number.map(|n| n * 2); // 如果存在则乘以2
println!("doubled: {:?}", doubled); // 输出 Some(20)
// unwrap_or 方法:如果 Option 是 Some,返回内部值;如果是 None,返回指定的默认值
let value = maybe_number.unwrap_or(0); // 存在则取值,否则返回默认值 0
println!("value: {}", value);
let none_value: Option<i32> = None;
let result = none_value.unwrap_or(42); // 使用默认值 42
println!("none_value 解包为: {}", result);
// 注意: 直接 unwrap 空值会导致 panic,通常不推荐在生产代码中使用
// 下面的代码如果取消注释,程序会崩溃
// let panic_value = none_value.unwrap(); // 这行会 panic
}3.12.6 枚举Result<T, E>:管理成功与失败
Rust 标准库中另一个关键的枚举是 Result<T, E>。该枚举用于可能成功或失败的操作。其概念定义如下:
// enum Result<T, E> {
// Ok(T), // Represents success, contains a value of type T
// Err(E), // Represents an error, contains an error value of type E
// }-
T:表示操作成功时返回的值的类型。 -
E:表示操作失败时返回的错误值的类型。
Result<T, E> 提供了一种标准且符合 Rust 习惯的方式来处理那些可能无法成功完成的操作,例如将字符串解析为数字、读取文件或发起网络请求。它强制程序员显式地考虑并处理成功(Ok)和失败(Err)这两种路径。
Result<T, E> 的示例:考虑将一个字符串解析为整数。如果字符串是有效的数字,此操作可以成功;如果不是,则会失败。
成功案例:
// The .parse() method on strings returns a Result.
// For "100".parse::<i32>(), the type would be Result<i32, std::num::ParseIntError>
let x: Result<i32, String> = Ok(100); // Successfully parsed to 100
// In a real scenario, you'd typically match on the result:
// match "100".parse::<i32>() {
// Ok(number) => println!("Parsed number: {}", number),
// Err(e) => println!("Error parsing: {:?}", e),
// }失败案例:
// Attempting to parse "123zcxcv?" into an i32 will fail.
let y: Result<i32, String> = Err("Failed to parse string into number".to_string());
// match "123zcxcv?".parse::<i32>() {
// Ok(number) => println!("Parsed number: {}", number), // This arm won't be reached
// Err(e) => println!("Error parsing: {:?}", e), // This arm will execute
// }通过使用 Result<T, E>,Rust 鼓励开发者将错误处理作为程序控制流中显式的一部分,从而构建更具弹性的应用程序。
完整示例:
// 引入标准库中的文件、IO和错误处理相关模块
use std::fs::File; // 文件操作
use std::io::{self, Read}; // IO操作,包括读取 trait
use std::num::ParseIntError; // 整数解析错误类型
// 自定义错误类型,用于除法函数
#[derive(Debug)] // 自动实现 Debug trait,便于打印错误信息
enum DivError {
DivisionByZero, // 除零错误变体,无附加数据
}
// 一个可能失败的操作:除法
// 返回 Result 类型,成功时返回 i32 商,失败时返回 DivError
fn divide(numerator: i32, denominator: i32) -> Result<i32, DivError> {
if denominator == 0 {
// 除数为零,返回错误变体
Err(DivError::DivisionByZero)
} else {
// 正常除法,返回商
Ok(numerator / denominator)
}
}
// 另一个可能失败的操作:将字符串解析为整数
// 使用标准库的 parse 方法,它返回 Result<i32, ParseIntError>
fn parse_number(s: &str) -> Result<i32, ParseIntError> {
// s.parse() 尝试将字符串解析为 i32,返回 Result
s.parse::<i32>()
}
// 读取文件内容并解析为数字(展示 ? 运算符的错误传播)
// 返回 Result,成功时返回 i32 数字,失败时返回一个可以容纳多种错误的 trait 对象
fn read_number_from_file(path: &str) -> Result<i32, Box<dyn std::error::Error>> {
// ? 运算符:如果 File::open 返回 Err,则提前从函数返回该 Err(并转换为 Box<dyn Error>)
let mut file = File::open(path)?;
let mut contents = String::new();
// 如果读取失败,? 提前返回错误
file.read_to_string(&mut contents)?;
// 去除字符串首尾空白,然后解析为 i32,如果解析失败,? 提前返回错误
let number = contents.trim().parse::<i32>()?;
// 成功,返回数字
Ok(number)
}
fn main() {
// 示例1:处理除法 Result
println!("=== 除法示例 ===");
let result1 = divide(10, 2); // 调用 divide,成功返回 Ok(5)
match result1 {
Ok(value) => println!("10 / 2 = {}", value), // 匹配成功分支,输出结果
Err(e) => println!("错误:{:?}", e), // 匹配错误分支,打印错误
}
let result2 = divide(5, 0); // 调用 divide,失败返回 Err(DivisionByZero)
match result2 {
Ok(value) => println!("5 / 0 = {}", value),
Err(e) => println!("错误:{:?}", e), // 输出 DivError::DivisionByZero
}
// 示例2:处理解析 Result
println!("\n=== 解析示例 ===");
let num_str = "42";
match parse_number(num_str) {
Ok(n) => println!("解析成功:{}", n),
Err(e) => println!("解析失败:{}", e), // 成功时不会执行
}
let bad_str = "not_a_number";
match parse_number(bad_str) {
Ok(n) => println!("解析成功:{}", n),
Err(e) => println!("解析失败:{}", e), // 输出解析错误信息
}
// 示例3:使用 unwrap_or 提供默认值
println!("\n=== 使用 unwrap_or ===");
let a = parse_number("100").unwrap_or(0); // 成功,返回 100
let b = parse_number("xyz").unwrap_or(0); // 失败,返回默认值 0
println!("a = {}, b = {}", a, b); // a=100, b=0
// 示例4:使用 ? 运算符传播错误(此处故意读取不存在的文件)
println!("\n=== 文件读取与 ? 运算符 ===");
match read_number_from_file("nonexistent.txt") {
Ok(num) => println!("文件中的数字是:{}", num),
Err(e) => println!("读取失败:{}", e), // 输出文件不存在错误
}
// 示例5:组合 Result 操作(map, and_then 等)
println!("\n=== 组合器 ===");
let parsed = parse_number("10") // 解析成功得到 Ok(10)
.map(|x| x * 2) // 如果 Ok,对其值应用闭包,变为 Ok(20)
.and_then(|x| divide(x, 2)); // 如果 Ok,调用 divide,若成功则返回 Ok(10),否则返回 Err
match parsed {
Ok(val) => println!("最终结果:{}", val),
Err(e) => println!("出错:{:?}", e),
}
// 示例6:unwrap 和 expect(谨慎使用,仅在确定不会失败时)
// 下面的代码如果取消注释且传入非法字符串,会直接 panic
// let sure = parse_number("42").unwrap(); // 安全,因为 "42" 可解析
// println!("unwrap 结果:{}", sure);
// let panic_example = parse_number("oops").expect("必须提供数字"); // 会 panic
}3.12.7 Rust 枚举的关键要点
-
定义:枚举允许你通过列举其所有可能的变体来定义一个类型。
-
变体类型:变体可以是简单的(无数据)、元组结构体式的(未命名的关联数据)或结构体式的(命名的关联数据)。
-
可派生特质:
-
#[derive(Debug)]:允许使用{:?}格式化器打印枚举实例以进行调试。 -
#[derive(PartialEq)]:允许比较枚举实例的相等性(==)和不相等性(!=)。
-
-
标准库枚举:
-
Option<T>:表示一个可选值,要么是Some(T)(值存在),要么是None(值不存在)。对于安全处理可能缺失的数据至关重要。 -
Result<T, E>:表示可能失败的操作的结果,要么是Ok(T)(成功并带有值),要么是Err(E)(失败并带有错误)。这是进行健壮错误处理的基础。
-
枚举是 Rust 类型系统的基石,极大地增强了其安全性、表达能力,以及有效建模复杂数据状态和结果的能力。
3.12.8 Rust枚举在智能合约开发中的应用场景
Rust 的枚举(Enum)在智能合约开发中是一种极其强大的工具,其核心价值在于能够将合约的状态、指令和错误处理显式地编码为类型安全的变体,从而在编译阶段就排除大量无效状态和非法操作。在 Solana、NEAR、Stellar 等支持 Rust 开发的区块链平台上,枚举的应用贯穿合约开发的始终。
以下是 Rust 枚举在智能合约中的三大核心应用场景:
1、核心应用场景
|
应用维度 |
核心作用 |
典型案例 |
关键优势 |
|---|---|---|---|
|
状态机建模 |
精确表示合约生命周期的不同阶段,确保状态转换的合法性。 |
托管合约的 |
非法状态消除:将合约状态空间限定在预设的合法变体内,杜绝因状态变量错误组合导致的逻辑漏洞。 |
|
指令/事件编码 |
将用户操作(指令)和合约输出(事件)统一封装为类型安全的枚举。 |
处理用户请求的 |
统一入口与接口安全:合约的入口函数通过 |
|
错误处理 |
取代传统错误码,将错误原因作为类型信息显式返回。 |
自定义 |
显式错误处理:调用方必须处理 |
2、深入案例:以托管合约为例
结合上述模式,让我们通过一个具体的托管合约(Escrow)案例,看看枚举是如何协同工作的:
(1)状态机建模:合约定义了一个枚举 EscrowState,精确地代表了交易的三个必经阶段 。
pub enum EscrowState {
AwaitingPayment, // 等待买家付款
AwaitingDelivery, // 买家已付款,等待确认收货
Closed, // 交易完成
} 在合约的核心结构体 Escrow 中,state: EscrowState 字段确保了合约状态只能是这三种之一,不可能出现「已关闭但仍可付款」的非法组合。
(2)指令处理:合约定义一个 EscrowAction 枚举来代表所有可能的用户指令。
pub enum EscrowAction {
Deposit, // 买家存入资金
ConfirmDelivery, // 买家确认收货
} 在合约的入口函数 handle 中,通过 match action 对指令进行分发。当处理 Deposit 指令时,首先会断言当前状态必须是 AwaitingPayment,否则交易失败。这就通过枚举和模式匹配,在逻辑上强制了正确的状态转换路径 。
(3)错误处理:在整个流程中,任何可能失败的操作(如解析输入、转账)都会返回 Result 类型。调用者必须显式处理 Ok 和 Err 分支,这确保了错误不会被「静默失败」 。
3、为何这是智能合约的最佳实践?
-
编译期保障:枚举将业务逻辑的约束直接编码进了类型系统。如果你试图添加一个不在枚举定义中的「新状态」,编译器会直接报错。这相当于将运行时检查提前到了编译时。
-
可读性与可维护性:新人阅读合约代码时,通过查看
enum定义,就能立刻理解合约的所有可能状态、支持的操作和可能发生的错误类型,无需深入散落在各处的函数逻辑中去猜测。 -
模式匹配的强大:Rust 的
match表达式与枚举是天作之合。match的穷尽性检查确保了你必须处理所有枚举变体。这在处理Option<T>时尤其重要——你无法「忘记」处理值为None的情况,从而彻底消灭了困扰其他语言许久的「空指针」异常 。
总结来说,在智能合约这个对正确性要求极高的领域,Rust 枚举通过「让非法状态无法表达」和「强制处理所有可能」的设计哲学,成为了构建安全、可靠、易维护链上逻辑的基石。
3.13 枚举练习
练习1:创建一个名为 Color 的 enum,其值包括:
-
Red
-
Green
-
Blue
-
Rgba(u8, u8, u8, f32)
在 enum 前加上关键字 pub。这将使该 enum 成为公开的,从而可以被导入到其他 Rust 文件中,包括测试文件。
pub enum Color{
Red,
Green,
Blue,
Rgba(u8,u8,u8.f32),
}3.14 测试





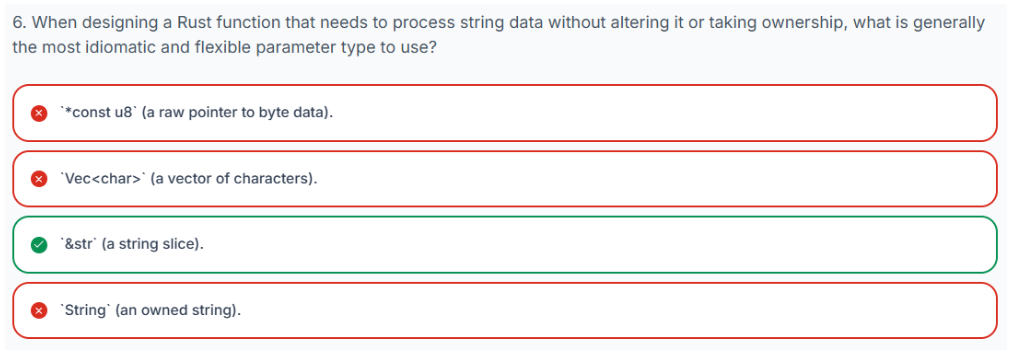





3.15 结构体
3.15.1 理解 Rust 中的结构体
Rust 中的结构体是自定义数据类型,它使你能够将相关的、可能不同类型的值组合成一个有意义的单元。它们是 Rust 程序中组织数据的基础。例如,你可以使用结构体来表示二维平面上点的 x 和 y 坐标。
3.15.2 Rust 中结构体的类型
Rust 提供了几种结构体的变体,每种都适用于不同的场景。
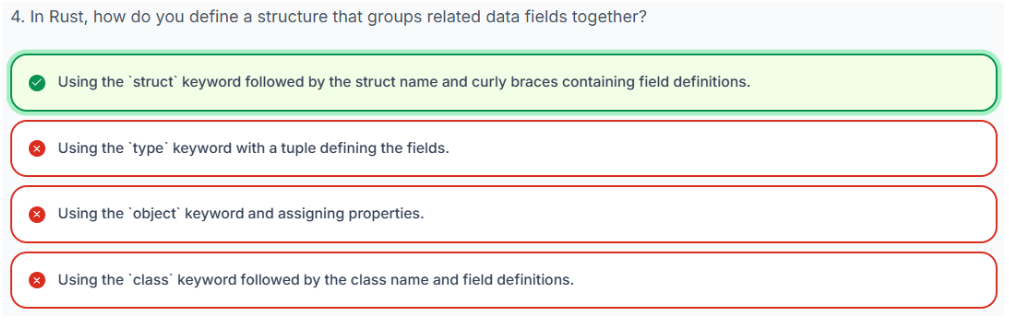
1、命名结构体
这是最常用的结构体类型。结构体中的每条数据(称为字段)都有一个名称和一个特定的数据类型。
定义:要定义一个命名结构体,你需要使用 struct 关键字,后跟结构体的名称,然后用花括号 {} 将字段定义括起来。每个字段定义由一个 名称: 类型 对组成。
代码示例:
struct Point {
x: i32,
y: i32,
}解释:上面的代码定义了一个名为 Point 的结构体。它有两个字段:类型为 i32(32位有符号整数)的 x 和同样类型为 i32 的 y。
2、元组结构体
元组结构体类似于元组。它们拥有一个名称,但字段是匿名的,并且通过数字索引(从0开始)来访问。当你希望给元组一个独特的类型名称时,尤其是如果给每个字段命名会显得过于冗长或冗余时,这些结构体非常有用。
定义:元组结构体使用 struct 关键字、结构体名称以及包含字段类型的圆括号 () 来定义。
代码示例:
struct Point3D(i32, i32, i32);解释:上述代码定义了一个名为 Point3D 的元组结构体。它包含三个 i32 值,可以用来表示三维空间中点的 x、y 和 z 坐标。
3、类单元结构体(空结构体)
类单元结构体,或称空结构体,是指没有任何字段的结构体。它们主要在你需要为一个类型实现某个 trait(一种定义共享行为的方式),但该类型本身无需存储任何数据时非常有用。
定义:类单元结构体使用 struct 关键字及其名称进行定义,后面跟一个分号。
代码示例:
struct Empty;解释:Empty 结构体在定义时不包含任何字段。
4、嵌套结构体
结构体可以嵌套在其他结构体中,这意味着一个结构体的字段类型可以是其他结构体。这使得我们可以创建更复杂的数据结构。
定义:你定义一个结构体,并将另一个结构体类型作为其字段之一。
代码示例:
// Assuming the Point struct is already defined:
struct Point {
x: i32,
y: i32,
}
struct Circle {
radius: u32,
center: Point, // Nested struct
}解释:这里定义了一个名为 Circle 的结构体。它有一个类型为 u32 的 radius 字段(u32 是无符号 32 位整数,适用于不能为负的值,如半径)和一个 center 字段,后者是先前定义的 Point 结构体的一个实例。
3.15.3 操作结构体实例
一旦定义了结构体,你就可以创建它的实例并与其数据进行交互。
1、初始化命名结构体
要创建一个命名结构体的实例(具体值),你需要指定结构体名称,后跟花括号,其中包含每个字段的 key:value 对。
代码示例:
// Assuming Point struct is defined:
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 1, y: 1 };
}解释:创建了一个名为 p 的 Point 结构体实例。其 x 字段被初始化为 1,y 字段被初始化为 1。
2、打印结构体:Debug 特征
尝试直接使用 printfn!("{}", instance_name); 打印结构体实例会导致编译时错误。Rust 的默认格式化器不知道如何显示自定义的结构体类型。
错误提示:编译器通常会指出你的结构体类型未实现 std::fmt::Display 特征。
解决方案:为了能够打印结构体以进行调试,你可以自动派生 Debug 特征。这可以通过在结构体定义的正上方添加 #[derive(Debug)] 属性来实现。
代码修改(结构体定义):
#[derive(Debug)] // Add this line
struct Point {
x: i32,
y: i32,
}
#[derive(Debug)] // Also needed for nested structs if they are to be printed
struct Circle {
radius: u32,
center: Point,
}代码修改(打印): 在 println! 宏中使用 {:?} 说明符进行调试打印。
// In main(), assuming p is an instance of Point
let p = Point { x: 1, y: 1 };
println!("{:?}", p);
Output: Point { x: 1, y: 1 }对于更易读的多行("美化打印")输出,请使用 {:#?} 说明符。
// Assuming circle is initialized:
let circle = Circle { radius: 1, center: Point { x: 0, y: 0 } };
println!("{:#?}", circle);美化打印输出示例:
Circle {
radius: 1,
center: Point {
x: 0,
y: 0,
},
}3、访问结构体字段
你可以使用点号表示法访问结构体字段中存储的数据。
4、命名结构体
使用 instance_name.field_name
#[derive(Debug)]
struct Point { x: i32, y: i32 }
let p = Point { x: 1, y: 1 };
println!("x: {}, y: {}", p.x, p.y);
Output: x: 1, y: 14、元组结构体
使用 实例名称.索引(索引从 0 开始)。
// #[derive(Debug)]
// struct Point3D(i32, i32, i32);
// let p3d = Point3D(-1, 0, -1);
// println!("point 3D: ({}, {}, {})", p3d.0, p3d.1, p3d.2);
// Output: point 3D: (-1, 0, -1)注意:要直接使用 {:?} 打印 p3d,Point3D 也需要 #[derive(Debug)]。
5、初始化类单元结构体
由于类单元结构体没有字段,你只需使用结构体名称即可初始化它们。
代码示例:
// #[derive(Debug)] // Needed for printing
// struct Empty;
// let empty_instance = Empty;
// To print, Empty would also need #[derive(Debug)]
// println!("{:?}", empty_instance);5、初始化嵌套结构体
当初始化一个包含另一个结构体作为字段的结构体(即嵌套结构体)时,你需要将内部结构体作为外部结构体字段初始化的一部分进行初始化。
代码示例:
// Ensure Point and Circle have #[derive(Debug)]
// #[derive(Debug)]
// struct Point { x: i32, y: i32 }
// #[derive(Debug)]
// struct Circle { radius: u32, center: Point }
// In main():
let circle_instance = Circle {
radius: 1,
center: Point { x: 0, y: 0 },
};
// println!("{:#?}", circle_instance);3.15.4 常见结构体操作
Rust 提供了便捷的语法来处理涉及结构体的常见操作。
1、字段初始化简写
如果用于初始化结构体字段的变量与结构体字段的名称完全相同,Rust 提供了一种简写语法。你只需要写一次字段名即可。
代码示例:
// #[derive(Debug)]
// struct Point { x: i32, y: i32 }
// In main():
// let x_coord: i32 = 1;
// let y_coord: i32 = 1;
// Long form:
// let p_long = Point { x: x_coord, y: y_coord };
// Shorthand (if variable names match field names):
// let x: i32 = 1; // Variable name 'x' matches field name 'x'
// let y: i32 = 1; // Variable name 'y' matches field name 'y'
// let p_short = Point { x, y }; // x field gets value of variable x, y field from variable y
// println!("{:?}", p_short);在这种简写形式 Point { x, y } 中,x 代表 x: x,y 代表 y: y。
2、结构体更新语法:从旧实例创建新实例
我们经常需要创建一个新的结构体实例,它复用现有实例的大部分值,但修改其中几个。结构体更新语法 .. 允许你简洁地实现这一点。它指定任何未显式设置的剩余字段应从另一个实例中取值。
代码示例:
#[derive(Debug)]
struct Point { x: i32, y: i32 }
// In main():
let p0 = Point { x: 1, y: 2 };
// Create p1, change x to a new value (e.g., 5), but keep y from p0
// Long form:
let p1_long = Point { x: 5, y: p0.y };
// Using struct update syntax:
// Let's create p1 with x = 5, and y copied from p0.y
let p1 = Point { x: 5, ..p0 };
println!("p0: {:?}", p0);
println!("p1 (updated from p0): {:?}", p1);
// Output for p1: Point { x: 5, y: 2 }3、关于所有权与 Copy trait 的重要说明:
... 语法在相关字段的类型未实现 Copy trait 时会移动数据。对于像 Point 中使用的 i32 这样的简单类型(它们确实实现了 Copy),在创建 p1 后,原始实例(示例中的 p0)仍然可用。然而,如果 Point 包含一个像 String 这样未实现 Copy 的字段,那么在结构体更新语法中使用 p0 为 p1 赋值时,String 数据将被移动。因此,p0(或至少其 String 字段)将不再可用,除非 Point 结构体本身显式实现了 Copy trait(但如果它包含像 String 这样的非 Copy 类型,默认情况下这是不可能的)。
4、修改结构体字段
要在创建结构体实例后更改其字段的值,该实例必须使用 mut 关键字声明为可变的。然后,你可以使用点号表示法访问该字段并为其赋予新值。
代码示例:
// #[derive(Debug)]
// struct Point { x: i32, y: i32 }
// In main():
// let mut p_update = Point { x: 1, y: 1 };
// println!("Initial p_update: {:?}", p_update);
// p_update.x += 1; // Increment x
// p_update.y = 99; // Set y to a new value
// println!("Updated p_update: {:?}", p_update);
// Output: Updated p_update: Point { x: 2, y: 99 }3.15.5 关键概念回顾
-
结构体:通过将相关数据分组到一个命名的结构中来创建自定义数据类型的蓝图。
-
字段:结构体内的各个数据项,每个字段(在命名结构体中)都有一个名称和一个类型。
-
实例:根据结构体蓝图创建的具体值。
-
#[derive(Debug)]:一个属性,用于自动为结构体实现Debugtrait,使其实例能够使用{:?}(标准调试格式)或{:#?}(美化调试格式)进行调试打印。
-
-
可变性(
mut):声明结构体实例为可变所需的关键字,允许在初始化后更改其字段值。 -
字段初始化简写:当用于初始化的局部变量名与结构体字段名完全一致时,可以使用的一种简洁初始化语法。
-
结构体更新语法(
..):-
一种便捷的方式,通过从现有实例复制部分字段的值,同时显式设置其他字段,来创建新的结构体实例。需注意对于未实现
Copy的字段类型,该语法会导致数据移动。
-
3.16 结构体练习
练习1:创建一个名为 Account 的结构体,其字段如下:
-
address,类型为String -
balance,类型为u32
在所有结构体字段前加上 pub 关键字。
struct Account{
pub address:String,
pub balance:u32
}练习2:创建一个函数,该函数根据输入的 address 返回 Account 结构体,且 balance 设置为 0。
// 为 Account 派生 Debug trait,方便打印调试信息
#[derive(Debug)]
struct Account {
pub address: String,
pub balance: u32,
}
/// 根据给定的地址创建一个新的 Account 实例,余额初始化为 0
fn create_account(address: String) -> Account {
Account {
address, // 使用字段初始化简写,等价于 address: address
balance: 0,
}
}
fn main() {
// 示例:创建一个地址字符串
let addr = String::from("0x742d35Cc6634C0532925a3b844Bc454e4438f44e");
// 调用函数创建账户
let account = create_account(addr);
// 打印账户信息(使用 Debug 格式)
println!("{:?}", account);
}3.17 向量
3.17.1 理解和使用 Rust 中的向量
向量是 Rust 中一种基础且通用的集合类型,它提供了一种动态存储元素列表的方式。本课将引导你掌握使用向量的基本知识,从创建和操作,到访问和切片其内容。
3.17.2 向量简介
在 Rust 中,向量本质上与数组类似:它们都是元素集合,且所有元素必须具有相同的数据类型。然而,它们之间有一个关键区别,使得向量在众多编程场景中极为有用且与众不同。
核心区别在于它们的大小管理方式:
-
数组:具有固定大小,该大小在编译时确定并已知。一旦以特定长度声明数组,该长度就无法改变。
-
向量:具有动态大小。随着元素的添加或删除,它们的大小可以在运行时增长或缩小。这种灵活性使得向量在元素数量事先未知或预计在程序执行期间会发生变化时成为理想选择。
3.17.3 创建向量
Rust 提供了多种创建向量的方式,以满足不同的初始化需求。
1、使用 Vec::new() 创建空向量
要创建一个空向量,你可以使用 Vec::new() 关联函数。此时,你必须显式指定向量将持有的元素类型。如果你打算稍后向此向量添加元素,则必须使用 mut 关键字将其声明为可变的。
fn main() {
let mut v: Vec<i32> = Vec::new();
}在此示例中,let mut v: Vec<i32> = Vec::new(); 初始化了一个名为 v 的空向量,该向量被指定用于存储 i32(32位整数)值。mut 关键字允许我们在 v 创建后对其进行修改。
2、使用 push() 添加元素
一旦你拥有一个可变的向量,就可以使用 push() 方法将元素添加到其末尾。
fn main() {
let mut v: Vec<i32> = Vec::new();
v.push(1);
v.push(2);
v.push(3);
}在这里,我们将整数 1、2 和 3 依次添加到我们的向量v中。
3、打印向量
要检查向量的内容,可以使用println!宏结合调试格式化程序来打印它{:?}。
fn main() {
let mut v: Vec<i32> = Vec::new();
v.push(1);
v.push(2);
v.push(3);
println!("v: {:?}", v);
}执行此代码将产生以下输出:v: [1, 2, 3]。
4、使用 vec! 宏创建带有初始值的向量
如果你在创建向量时已知其初始元素,vec! 宏提供了一种更简洁方便的语法。Rust 编译器通常能够推断出向量元素的类型。对于数值类型,它默认会推断为 i32。
fn main() {
let v = vec![1, 2, 3]; // Rust infers v is Vec<i32>
// For explicit type annotation:
// let v: Vec<i32> = vec![1, 2, 3];
}该vec![1, 2, 3]宏创建了一个新向量,并用元素 1、2 和 3 初始化。
5、使用 vec! 宏指定元素类型
如果你需要一个不同于编译器默认推断的类型(例如,8位有符号整数 i8 或 8位无符号整数 u8)的向量,可以通过以下两种方式指定类型:
(1)显式类型注解:直接在变量声明中添加类型注解。
fn main() {
let v: Vec<i8> = vec![1, 2, 3];
}(2)在元素上添加类型后缀:在 vec! 宏内的某个元素上添加类型后缀(如 u8、i16 等)。编译器随后会根据该特定元素推断出向量的类型。
fn main() {
let v = vec![1u8, 2, 3]; // v is now Vec<u8>
}在这种情况下,由于指定了 1u8,v 成为 Vec<u8> 类型。
6、使用重复值创建向量
vec! 宏还提供了一种便捷的语法,用于创建包含指定数量相同元素的向量:vec![值; 数量]。
fn main() {
// Create a vector of 100 elements, all initialized to 0 of type i8.
let v: Vec<i8> = vec![0i8; 100];
println!("v: {:?}", v);
}运行这段代码将打印一个包含一百个 0 的向量,例如:v: [0, 0, 0, ..., 0]。
3.17.4 访问向量中的元素
Rust 提供了两种主要方法来访问向量中的元素,每种方法的安全性含义不同。
1、使用索引表示法(不安全)
可以使用方括号符号直接访问元素:v[索引]。此方法提供对指定零基索引处元素的直接访问。
重要提示: 这种方法被认为是“不安全的”,因为如果你尝试访问越界的索引(即索引大于等于向量的长度,或负数索引),程序将在运行时发生 panic 并终止。
fn main() {
let v: Vec<i8> = vec![10, 20, 30];
println!("Element at index 1: {}", v[1]); // Accesses the element 20
// The following line would cause a panic:
// println!("Accessing out of bounds: {}", v[5]);
}如果对一个长度为 100 的向量尝试越界访问如 v[1000],程序将会 panic,并显示类似以下的消息: thread 'main' panicked at 'index out of bounds: the len is 100 but the index is 1000'。
2、使用 get() 方法(安全)
一种更安全、更健壮的访问元素的方式是使用 get() 方法。该方法在提供无效索引时不会导致 panic。相反,v.get(index) 返回一个 Option<&T>,其中 T 是向量中元素的类型。
-
如果
index有效(在向量范围内),get()返回Some(&value),其中&value是该索引处元素的引用。 -
如果
index越界,get()返回None。
这种机制允许你使用 Rust 的 Option 枚举(通常通过 match 语句或像 unwrap_or 这样的方法)优雅地处理潜在的越界访问。
fn main() {
let v: Vec<i8> = vec![0i8; 100]; // Vector of 100 zeros
// Accessing a valid index:
// v.get(1) returns Option<&i8>
// Since index 1 is valid, it returns Some(&value_at_index_1)
println!("v.get(1): {:?}", v.get(1));
// Accessing an invalid index:
// Since index 1000 is invalid, it returns None
println!("v.get(1000): {:?}", v.get(1000));
}执行此代码将输出:
v.get(1): Some(0)
v.get(1000): None3.17.5 更新元素
要修改向量中特定索引处的现有元素,向量必须首先声明为可变的(使用 mut)。然后你可以在赋值操作的左侧使用索引符号。
fn main() {
let mut v: Vec<i8> = vec![1, 2, 3];
println!("Original v: {:?}", v); // v: [1, 2, 3]
v[0] = 99; // Updates the element at index 0 from 1 to 99
println!("Updated v: {:?}", v); // v: [99, 2, 3]
}与访问元素一样,尝试使用此方法更新超出范围索引的元素将导致 panic。
3.17.6 使用 pop() 删除元素
pop() 方法提供了一种从向量中移除最后一个元素的方式。它同时会返回这个被移除的元素。要使用 pop(),向量必须是可变的。与 get() 方法类似,pop() 返回一个 Option<T>(注意:是 Option<T>,而不是 Option<&T>),因为 pop() 会获取被移除元素的所有权,将其移出向量。
-
如果向量不为空,
pop()会移除最后一个元素并返回Some(value),其中value是被移除的元素。 -
如果向量为空,
pop()不对向量做任何操作,并返回None。
fn main() {
let mut v: Vec<i8> = vec![1, 2, 3];
println!("Initial v: {:?}", v);
let x1: Option<i8> = v.pop();
println!("Popped: {:?}, v after pop: {:?}", x1, v); // Popped: Some(3), v after pop: [1, 2]
let x2: Option<i8> = v.pop();
println!("Popped: {:?}, v after pop: {:?}", x2, v); // Popped: Some(2), v after pop: [1]
let x3: Option<i8> = v.pop();
println!("Popped: {:?}, v after pop: {:?}", x3, v); // Popped: Some(1), v after pop: []
let x4: Option<i8> = v.pop(); // Vector is now empty
println!("Popped: {:?}, v after pop: {:?}", x4, v); // Popped: None, v after pop: []
}这展示了 pop() 如何从末尾移除元素,以及当向量变空时的行为。
3.17.7 来自向量的切片
与数组类似,你可以从向量创建切片。切片是对向量中一段连续元素的引用。切片允许你借用向量的一部分,而无需获取所有权或复制数据。
创建切片的语法涉及对向量的一个范围进行引用:&v[start_index..end_index]。
-
start_index是包含的(该索引处的元素包含在切片中)。 -
end_index是不包含的(该索引处的元素不包含在切片中)。
fn main() {
let v = vec![1, 2, 3, 4, 5];
// Create a slice containing elements from index 1 up to (but not including) index 4.
// This will include v[1], v[2], and v[3], which are the values 2, 3, and 4.
let s: &[i32] = &v[1..4];
println!("Slice s: {:?}", s);
}执行此代码将输出:Slice s: [2, 3, 4]。切片是高效引用集合各部分的强大功能。
3.18 向量练习
练习1:返回一个包含元素 x、y 和 z 的向量。
// 定义一个函数 init,接收三个 u32 类型的参数 x, y, z,
// 并返回一个包含这些元素的 Vec<u32>
pub fn init(x: u32, y: u32, z: u32) -> Vec<u32> {
vec![x, y, z]
}
// 主函数,用于演示调用 init 并打印结果
fn main() {
let result = init(10, 20, 30);
println!("{:?}", result); // 输出: [10, 20, 30]
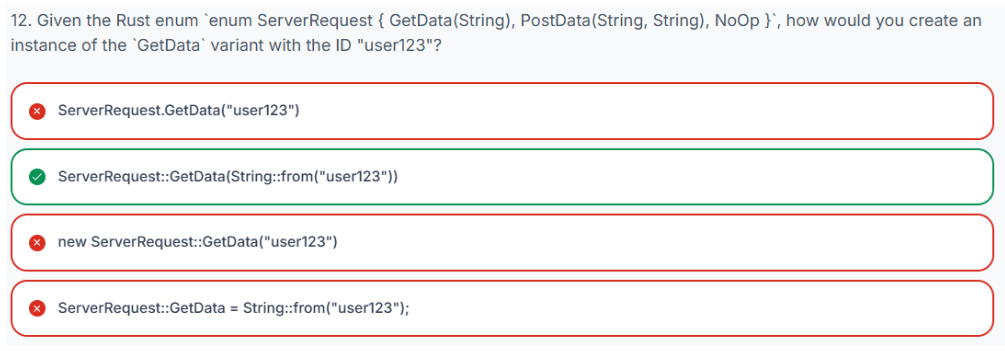
}3.19 测试


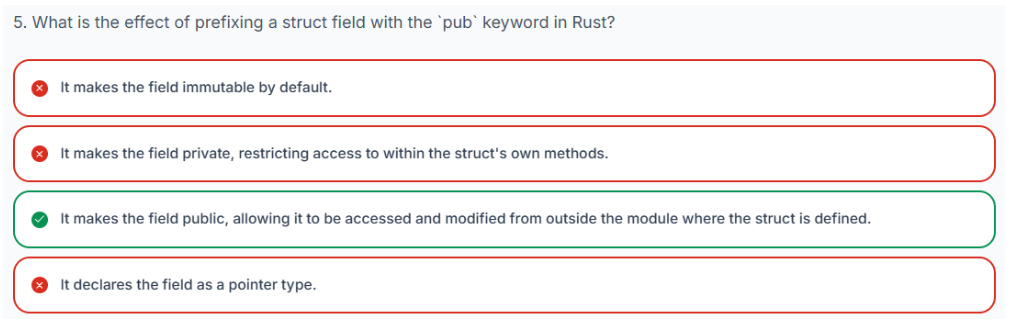
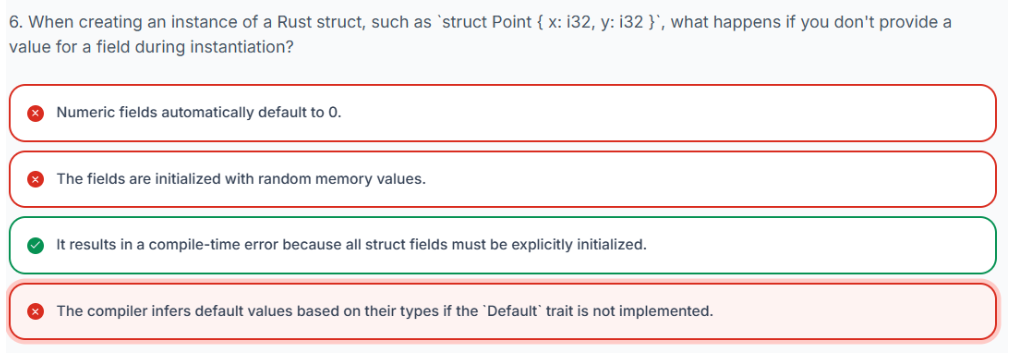

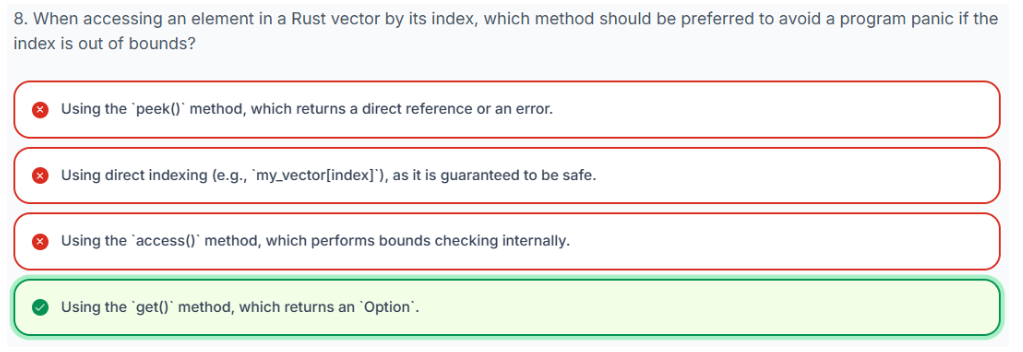


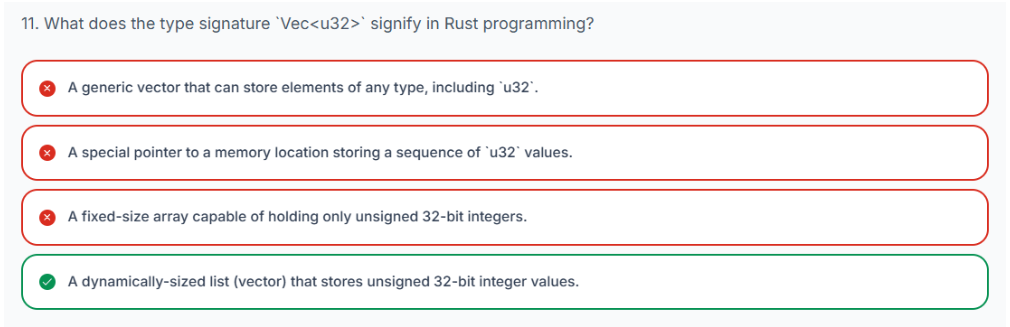
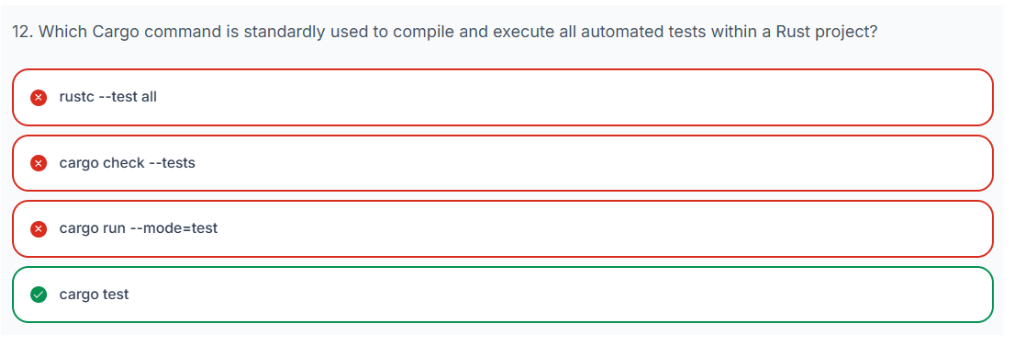
3.20 哈希映射
3.20.1 理解与使用 Rust 中的 HashMap
HashMap 是 Rust 中一种基础且通用的集合类型,专为以键值对形式存储数据而设计。与向量类似,它们提供了一种管理数据集合的方式,但额外具有基于唯一键进行快速查找的优势。本课将引导你掌握在 Rust 中使用 HashMap 的基本知识,从初始化到常见操作,如插入、检索和更新数据。
3.20.2 导入 HashMap
在 Rust 代码中使用 HashMap 之前,你需要将其引入作用域。HashMap 位于标准库的 collections 模块中。你可以使用 use 关键字导入它:
use std::collections::HashMap;此行将 HashMap 类型引入当前模块,使其可用。
3.20.3 初始化 HashMap
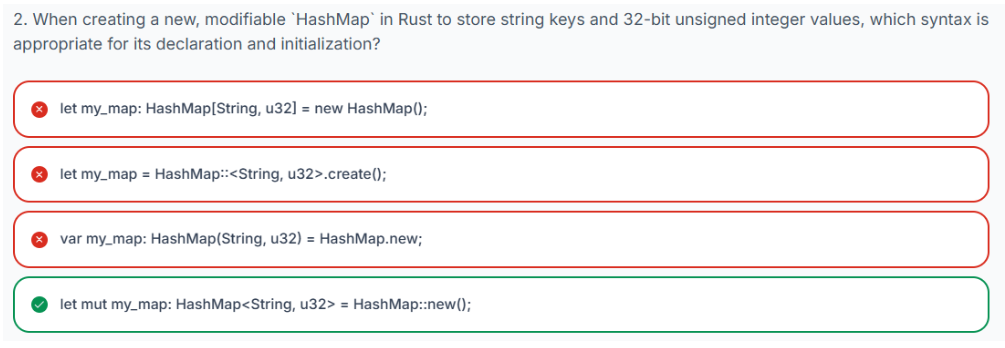
要开始使用 HashMap,首先需要创建它的一个实例。通常使用关联函数 HashMap::new() 创建一个新的空 HashMap。
在声明 HashMap 时,必须指定其键和值的数据类型。如果计划在创建后添加或修改条目,则必须使用 mut 关键字将 HashMap 变量声明为可变的。
让我们考虑一个示例,我们想要存储团队名称(作为 String)及其对应的分数(作为 u32 整数):
// Inside fn main() {
let mut scores: HashMap<String, u32> = HashMap::new();
// }在此声明中:
-
let mut scores:声明了一个名为scores的可变变量。 -
HashMap<String, u32>:指定此HashMap将存储类型为String的键和类型为u32的值。 -
HashMap::new():调用函数创建一个新的空哈希映射。
3.20.4 插入键值对
一旦你的 HashMap 初始化完成,就可以使用 insert 方法向其中添加数据。该方法接受两个参数:键以及你想要与该键关联的值。
如果你的键是 String 类型,而你使用的是字符串字面量(类型为 &str),则需要将它们转换为 String 对象。一种常见的方法是调用 .to_string() 方法。
继续我们的 scores 示例:
// Continuing inside fn main() {
scores.insert("red".to_string(), 100);
scores.insert("blue".to_string(), 200);
// }这几行代码向我们的 scores HashMap 中添加了两个条目:
-
键
"red"与值100关联。 -
键
"blue"与值200关联。
3.20.5 显示 HashMap 内容
要检查 HashMap 的内容,可以使用 println! 宏。对于像 HashMap 这样的复杂类型,通常使用调试格式化器,通过 {:?} 指定。要获得更易读的“美化打印”输出,可以使用 {:#?}。
// Continuing inside fn main() {
println!("{:#?}", scores);
// }执行此代码将打印存储在 scores HashMap 中的键值对。输出可能类似于:
{
"red": 100,
"blue": 200,
}需要注意的是,HashMap 不保证其元素的任何特定顺序。条目打印的顺序可能会有所不同。
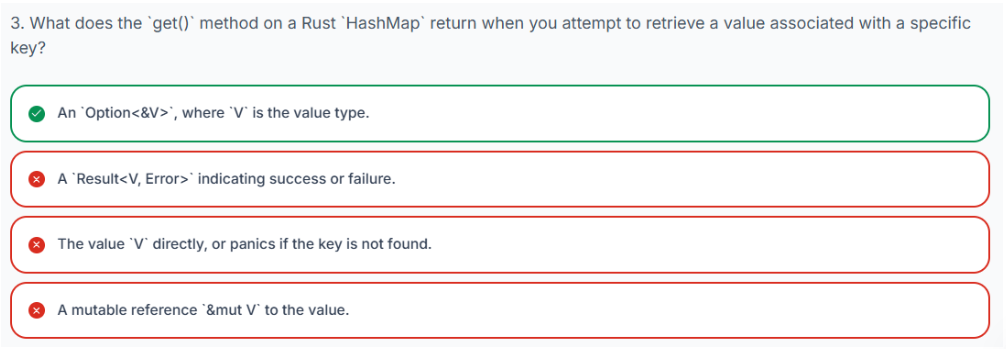
3.20.6 从 HashMap 中检索值
要访问与特定键关联的值,需要使用 get 方法。该方法接受一个对键的引用作为参数。如果你的 HashMap 使用 String 作为键,你可以方便地传递字符串字面量(一个 &str),因为 Rust 可以自动将 String 借用为 &str。
get 方法不会直接返回值。相反,它返回一个 Option<&V>,其中 V 是存储在 HashMap 中的值的类型。这个 Option 类型对于处理键可能不存在的情况至关重要:
-
如果找到键,
get返回Some(&value),其中&value是对HashMap中值的引用。 -
如果未找到键,
get返回None。
让我们看看实际效果:
// Continuing inside fn main() {
// Get score for "red" team
let score: Option<&u32> = scores.get("red");
println!("Red score: {:?}", score); // Output: Red score: Some(100)
// Try to get score for a non-existent "green" team
let score: Option<&u32> = scores.get("green");
println!("Green score: {:?}", score); // Output: Green score: None
// }这展示了 get 如何安全地处理成功的查找和尝试检索不存在的键这两种情况。
3.20.7 更新 HashMap 中的值
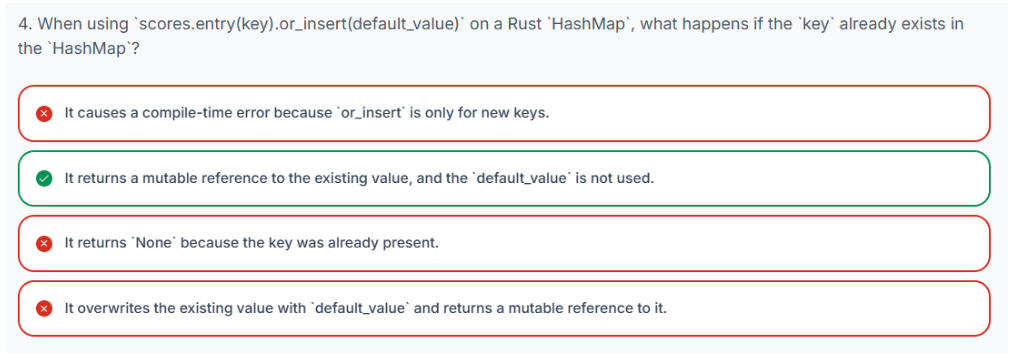
Rust 提供了一种强大且符合语言习惯的方式来更新 HashMap 中的值,即结合使用 entry 方法和 or_insert。当你想要在键不存在时插入一个默认值,或者在键存在时修改现有值时,这种模式特别有用。
以下是这些方法协同工作的方式:
-
entry(key):此方法接受一个键作为参数(通常是拥有所有权的键,例如String)。它返回一个Entry枚举。这个Entry代表了对映射中特定位置的一个视图,该位置要么是空的(键不存在),要么是被占用的(键存在)。 -
or_insert(default_value):此方法在entry(key)返回的Entry上调用。-
如果
Entry是空的(意味着键在HashMap中不存在),or_insert会将default_value插入到HashMap的该键下。然后它返回一个指向这个新插入值的可变引用(&mut V)。 -
如果
Entry是被占用的(意味着键已存在),or_insert将不会使用default_value。相反,它只是返回一个指向现有值的可变引用(&mut V)。
-
一旦你拥有了这个可变引用(&mut V),就可以通过使用 * 运算符解引用来直接修改 HashMap 中的值。
示例 1:插入新队伍或更新现有队伍;
让我们添加一个 "black" 队伍。如果它不存在,我们将其分数初始化为 0,然后加上 100 分。
// Continuing inside fn main() {
// Get a mutable reference to the score for "black", inserting 0 if it doesn't exist.
let score: &mut u32 = scores.entry("black".to_string()).or_insert(0);
// At this point:
// - If "black" was not in `scores`, it's now inserted with the value 0.
// - `score` is a mutable reference to this 0.
// - If "black" was already in `scores`, `score` would be a mutable reference to its existing value.
// Increment the score
*score += 100; // Dereference `score` to modify the value in the HashMap
// Verify the update
let black_score = scores.get("black");
println!("Black score: {:?}", black_score); // Output: Black score: Some(100)
// }在这种情况下,"black" 最初并不在 scores 映射中。.or_insert(0) 将其添加进去,并赋值为 0。随后的 *score += 100; 将此分数更新为 100。
示例 2:更新现有队伍的分数;
现在,让我们更新 "blue" 队伍的分数,该队伍已存在且分数为 200。我们将再加上 100 分。
// Continuing inside fn main() {
// The "blue" team already exists with a score of 200.
let score: &mut u32 = scores.entry("blue".to_string()).or_insert(0);
// Because "blue" exists, `or_insert(0)` does not insert 0.
// `score` is now a mutable reference to the existing score of 200 for "blue".
*score += 100; // The score of "blue" (initially 200) is incremented by 100.
// Verify the update
let blue_score = scores.get("blue");
println!("Blue score: {:?}", blue_score); // Output: Blue score: Some(300)
// }在这种情况下,因为 "blue" 已经存在于映射中,or_insert(0) 不会改变它的值。score 变量接收到一个指向现有值(200)的可变引用,然后该值被增加到 300。
3.20.8 关键概念与最佳实践
在 Rust 中使用 HashMap 时,请记住这些重要概念:
-
可变性:要插入新的键值对或修改现有值,你的
HashMap实例必须声明为可变的(let mut scores ...)。 -
所有权与借用:
-
如果键和值是拥有所有权的类型(如
String),HashMap会获取它们的所有权。这就是为什么在插入时,字符串字面量(&str)通常需要使用.to_string()转换为String。 -
get()方法会高效地借用其键。即使键是String类型,你也可以向get()传递一个&str。 -
entry()方法通常期望一个拥有所有权的键(例如String)。
-
-
Option 类型:
get()方法返回一个Option。这是 Rust 的核心特性,用于优雅地处理值可能不存在的情况,防止因直接访问不存在的键而导致的意外程序崩溃(panic)。 -
可变引用与解引用:
entry(...).or_insert(...)模式会产生一个指向HashMap中值的可变引用(&mut V)。要通过此引用更改映射中存储的实际值,必须使用星号(*)运算符对其进行解引用(例如*score = new_value;或*score += amount;)。
存储和更新队伍分数的示例展示了 HashMap 一个常见且实用的用例。它们将唯一键与值相关联的能力使其在各种数据管理任务中不可或缺。通过理解这些操作和概念,你可以在 Rust 项目中有效地利用 HashMap。
3.21 哈希表练习
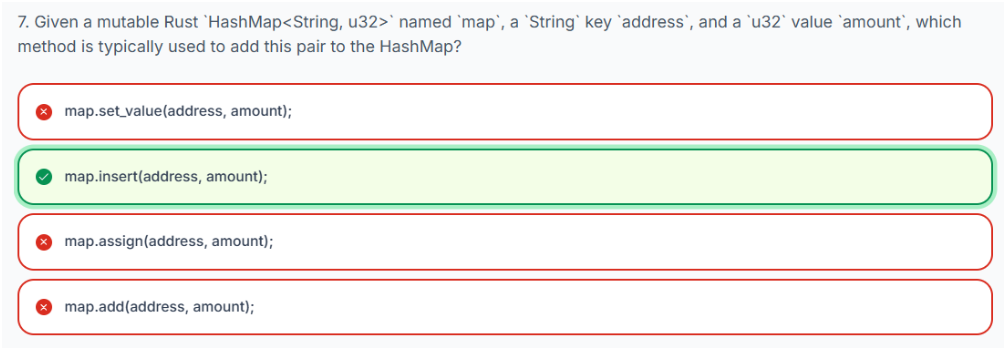
练习1:初始化一个 HashMap,在键 address 处插入值 amount。
// 导入标准库中的 HashMap 集合类型,用于存储键值对
use std::collections::HashMap;
/**
* 初始化一个 HashMap,并将给定的地址和金额作为键值对插入
*
* # 参数
* - `address`: 作为键的字符串,类型为 `String`(拥有所有权的字符串)
* - `amount`: 作为值的金额,类型为 `u32`(无符号32位整数)
*
* # 返回值
* - 返回一个 `HashMap<String, u32>`,其中包含传入的键值对
*/
pub fn init(address: String, amount: u32) -> HashMap<String, u32> {
// 创建一个新的空 HashMap,显式指定键类型为 String,值类型为 u32
// 由于返回值类型已声明,这里的类型注解 `: HashMap<String, u32>` 可以省略
let mut map: HashMap<String, u32> = HashMap::new();
// 将传入的 address 和 amount 作为键值对插入到 map 中
// insert 方法会获取 address 和 amount 的所有权(因为 address 是 String,amount 实现了 Copy)
map.insert(address, amount);
// 返回填充后的 map(所有权被移出函数)
map
}
// 程序的主函数,用于演示 init 函数的用法
fn main() {
// 创建一个字符串 "0x123" 作为地址,显式标注类型(可省略)
let address: String = String::from("0x123");
// 定义一个金额值 100,类型为 u32(可省略)
let amount: u32 = 100;
// 调用 init 函数,传入 address 和 amount,返回一个 HashMap
// 变量 map 的类型为 HashMap<String, u32>,注解可省略
let map: HashMap<String, u32> = init(address, amount);
// 使用调试格式 `{:?}` 打印 map 的内容
// 输出示例:{"0x123": 100}
println!("{:?}", map);
}3.22 测试




AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)