RAG引用标注与幻觉检测实战(非常详细),打造高可信系统从入门到精通,收藏这一篇就够了!
上周有个学员面京东就被追到了这个深度。面试官问他 RAG 系统怎么保证回答可信,他说"在 Prompt 里要求模型引用来源"。
面试官追问:“模型标的引用你验证过吗?遗漏率多少?错标率多少?如果模型编了一句知识库里没有的内容但标了个引用编号,你怎么检测?”
引用标注和幻觉检测是 RAG 系统从"能用"到"可信赖"的最后一关。今天把这个环节从 Prompt 方案到后处理归因到 NLI 验证全部拆开讲。
一、为什么 Prompt 标注不够?
最简单的引用方案是在 Prompt 里要求 LLM 标注来源:
请基于以下文档回答用户问题,并在每句话后用[文档X]标注来源。文档1: ...文档2: ...
这种方案在我们的测试中暴露了三个问题:
遗漏率 15%。 LLM 经常忘记给某些句子标注来源,尤其是回答较长的时候。
错标率 8%。 LLM 可能标注了错误的文档编号——明明信息来自文档 2 却标了 [1]。
幻觉伪装。 最危险的情况——LLM 编造了一句知识库里没有的内容,但还标了个引用编号。用户看到有引用就信了,其实那句话是编的。
所以 Prompt 标注只是第一层防线,还需要后处理来验证和补全。
二、后处理式归因:逐句找出处
思路是:先让 LLM 生成回答(不管它标不标引用),然后用算法逐句检查每句话来自哪个文档。
def attribute_answer(answer, retrieved_docs): # 第一步:把回答拆成句子 sentences = split_sentences(answer) attributions = [] for sent in sentences: best_doc = None best_score = 0 # 第二步:计算该句与每个检索文档的语义相似度 for doc in retrieved_docs: score = compute_similarity(sent, doc.content) if score > best_score: best_score = score best_doc = doc # 第三步:相似度超过阈值,认为该句来自该文档 if best_score > 0.75: attributions.append({ 'sentence': sent, 'source_doc_id': best_doc.id, 'source_section': best_doc.metadata['section_path'], 'confidence': best_score }) else: # 相似度低——可能是LLM的推理,也可能是幻觉 attributions.append({ 'sentence': sent, 'source_doc_id': None, 'confidence': 0, 'warning': 'unverified_claim' }) return attributions
但纯相似度还不够——两句话语义相似不代表一句话能从另一句推出来。"意外险承保意外伤害"和"意外险不承保意外伤害"语义相似度很高(都在讲意外险和意外伤害),但意思完全相反。
三、NLI 验证:不只是"相似",而是"能推出"
NLI(Natural Language Inference,自然语言推理)模型可以判断两句话之间的逻辑关系——是蕴含(entailment)、矛盾(contradiction)还是无关(neutral)。
def verify_entailment(sentence, document): """ 用NLI模型验证:document能否推出sentence? 返回: supported / contradicted / not_found """ nli_input = { 'premise': document, # 前提(检索到的文档) 'hypothesis': sentence # 假设(回答中的句子) } result = nli_model.predict(nli_input) # result: {'entailment': 0.92, 'contradiction': 0.03, 'neutral': 0.05} if result['entailment'] > 0.7: return'supported' # 文档支持该句 ✓ elif result['contradiction'] > 0.5: return'contradicted' # 文档与该句矛盾!(幻觉) else: return'not_found' # 文档中没有相关信息
把相似度匹配和 NLI 验证结合起来:
第一步: 用语义相似度找到候选文档(快,用于缩小范围)。
第二步: 对候选文档用 NLI 验证蕴含关系(准,用于确认支持)。
第三步: 如果所有候选文档都不能支持该句——标记为"未验证声明"。
def attribute_with_nli(answer, retrieved_docs): sentences = split_sentences(answer) attributions = [] for sent in sentences: candidates = [] for doc in retrieved_docs: sim_score = compute_similarity(sent, doc.content) if sim_score > 0.6: # 相似度达标,用NLI验证 entailment = verify_entailment(sent, doc.content) if entailment == 'supported': candidates.append({'doc': doc, 'score': sim_score}) if candidates: best = max(candidates, key=lambda x: x['score']) attributions.append({ 'sentence': sent, 'source': best['doc'].metadata, 'verified': True }) else: attributions.append({ 'sentence': sent, 'source': None, 'verified': False, 'warning': 'unverified_claim' }) return attributions
效果对比:
| 方案 | 归因准确率 | 幻觉检测率 |
|---|---|---|
| Prompt 标注 | 82% | 无法检测 |
| 相似度归因 | 88% | 72% |
| 相似度 + NLI | 94% | 87% |
加入 NLI 后,归因准确率从 88% 提升到 94%,更关键的是能检测出 87% 的幻觉——这些是纯相似度方案发现不了的。
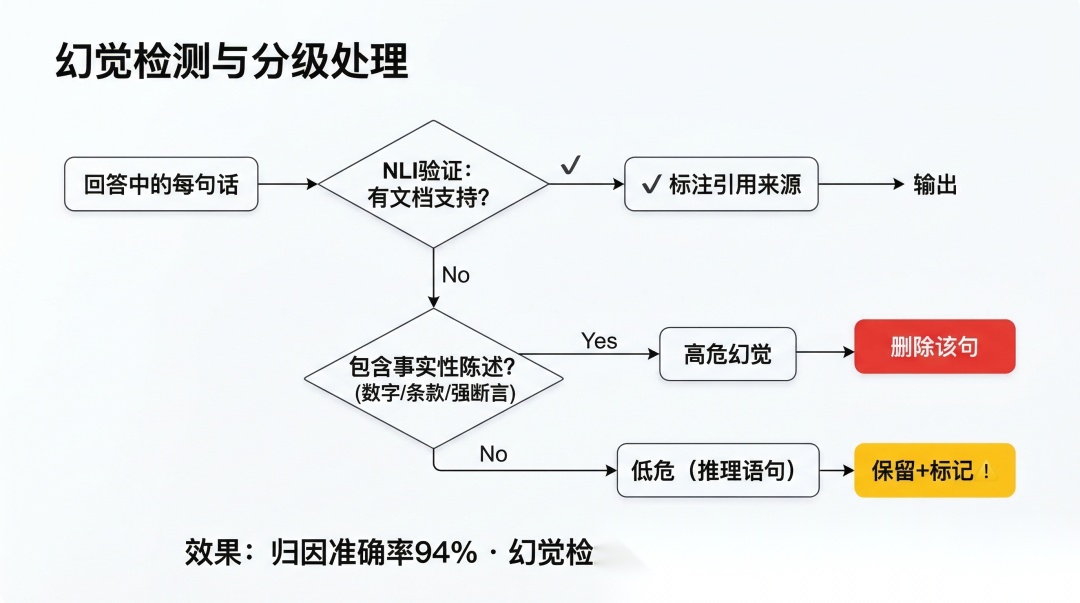
四、幻觉检测与处理
检测出"未验证声明"之后怎么办?不能简单地全部删除——有些可能是 LLM 的合理推理(比如"综合以上信息可以看出……"),不算幻觉。
判断是否包含事实性陈述
def contains_factual_claim(sentence): """事实性陈述通常包含:数字、日期、专有名词、强断言""" patterns = [ r'\d+', # 数字 r'第\d+条', # 条款编号 r'必须|应当|不得|禁止', # 强断言 r'万元|%|天|年', # 单位 ] return any(re.search(p, sentence) for p in patterns)
分级处理策略
def handle_hallucination(answer, attributions): for attr in attributions: if attr['verified']: continue# 有据可依,不处理 sent = attr['sentence'] if contains_factual_claim(sent): # 高危:包含事实性陈述但没有证据支持 # 策略:删除该句 answer = answer.replace(sent, '') else: # 低危:可能是推理性语句("因此""综上") # 策略:保留但标记 answer = answer.replace( sent, f"{sent} ⚠️[该表述未在文档中找到直接依据]" ) return answer
五、引用信息的结构化输出
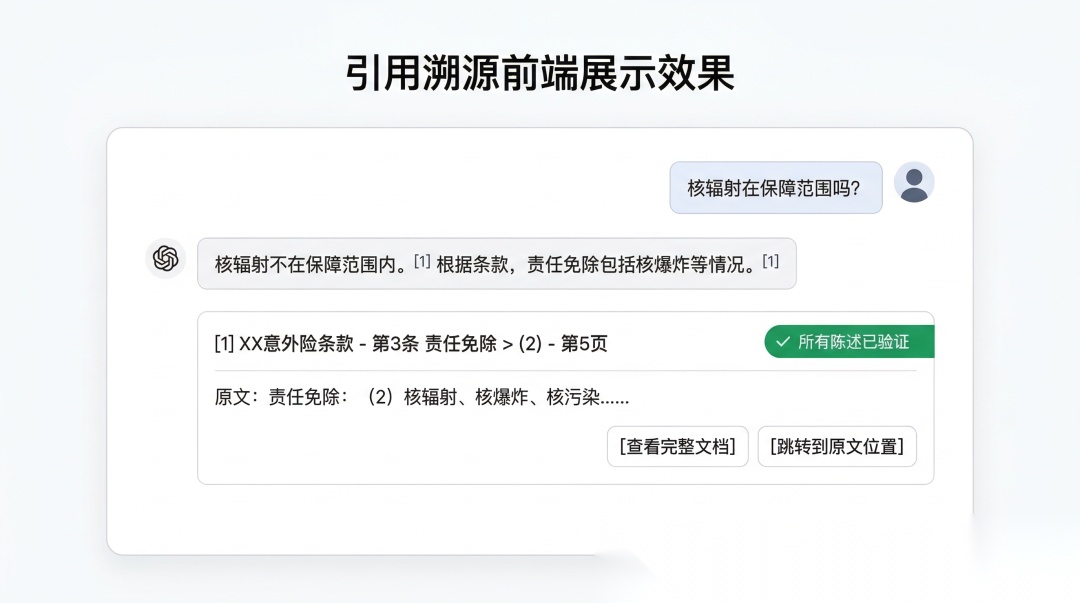
最终返回给前端的不只是纯文本答案,而是一个结构化的 JSON:
{ "answer": "核辐射不在保障范围内。根据条款,责任免除包括核辐射等。", "citations": [ { "sentence": "核辐射不在保障范围内。", "source": { "doc_title": "XX意外险条款", "section_path": "第3条 责任免除 > (2)", "page_num": 5, "original_text": "责任免除:(2)核辐射、核爆炸……" }, "confidence": 0.92 } ], "unverified": []}
前端拿到这个 JSON 就可以做交互式展示——每句话后面有可点击的引用标签,点开可以看原文片段和来源页码。用户可以自己判断答案是否可信。

六、面试怎么答引用溯源?
先讲为什么需要(15 秒)。 “RAG 系统的答案必须可追溯——用户要知道信息来自哪个文档哪一页,否则无法判断是否可信。在保险场景中这还是合规要求。”
讲三层方案(40 秒)。 “第一层在 Prompt 中要求 LLM 标注引用编号,但遗漏率 15%、错标率 8%。第二层用后处理做逐句归因——把回答拆成句子,每句话跟检索文档算语义相似度找出处。第三层用 NLI 模型验证蕴含关系——不只是’相似’,而是验证文档’能推出’这句话。三层叠加归因准确率达到 94%。”
讲幻觉检测(20 秒)。 “NLI 验证发现’不被支持’的句子后,判断是否包含事实性陈述。包含数字、条款编号、强断言的高危句直接删除;推理性语句保留但标记警告。幻觉检测召回率 87%。”
讲效果(15 秒)。 “引用归因准确率从 Prompt 方案的 82% 提升到 94%,幻觉检测率 87%,返回结构化 JSON 支持前端交互式引用展示。”
写在最后
引用溯源和幻觉检测是 RAG 系统的"最后一公里"。前面所有的优化——文档解析、Chunk 切分、混合检索、Rerank 精排——都是为了让系统找到正确的信息。但找到正确信息只是及格线,让用户相信这些信息来自可靠来源、让系统自动检测不可靠的内容——这才是满分。
在保险、金融、法律、医疗这些高风险场景中,一句没有出处的回答就是一个潜在的合规风险。
“我的 RAG 系统不只是能回答问题,还能告诉用户每句话的出处,并且自动过滤没有依据的幻觉内容”——这句话说出来,面试官会知道你对系统质量的要求跟业务需求是对齐的。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献133条内容
已为社区贡献133条内容

所有评论(0)