MCP、Tools、Skills深度对比(非常详细),AI Agent能力扩展从入门到精通,收藏这一篇就够了!
如果AI Agent是操作系统,MCP就是USB协议,Tools是插在外设上的功能按钮,Skills就是应用程序。
开篇:一位架构师的困惑
上周,我在技术交流群里看到这样一段对话:
开发者A:“我们团队正在构建企业级AI Agent系统,但是MCP、Tools、Skills这三个概念把我搞晕了。它们到底有什么区别?什么时候该用哪个?”
开发者B:“我也在纠结这个问题。有人说MCP已经过时了,应该全用Skills;也有人说Skills只是MCP的补充。”
开发者C:“面试官昨天问我这个问题,我答得一塌糊涂…”
这个困惑,我相信很多开发者和架构师都遇到过。AI Agent工具圈每隔几周就会冒出新概念,每次新东西出来,就有人喊旧的"已死"。
但真相是:MCP、Tools、Skills根本不是竞争关系,而是不同层次的能力扩展机制。
今天,我们就用一篇文章,彻底讲清楚这三者的区别、联系和最佳实践。
第一部分:AI Agent的能力困境
1.1 大模型的"先天缺陷"
在深入讨论之前,我们先要理解一个根本问题:为什么AI Agent需要能力扩展?
想象一下,你招聘了一位超级聪明的实习生。这位实习生:
- • ✅ 读过互联网上几乎所有公开的知识
- • ✅ 能写代码、能分析数据、能写文章
- • ✅ 精通多国语言,理解能力超强
但是,这位实习生有一个致命问题:
- • ❌ 不知道你们公司的内部流程
- • ❌ 无法访问公司的数据库和系统
- • ❌ 不会使用你们团队的专用工具
- • ❌ 知识停留在训练截止日期,不知道最新动态
这就是大模型的"先天缺陷":知识封闭、能力有限、无法行动。
为了解决这个问题,业界提出了三种主要的扩展方式:
- Tools(工具):给AI一双"手",让它能执行具体操作
- MCP(Model Context Protocol):定义一套标准协议,让AI能即插即用地连接任何工具
- Skills(技能):给AI一本"操作手册",教它怎么完成特定任务
1.2 从Function Calling到Agent能力扩展
要理解这三者的关系,我们需要回顾一下技术演进史。
第一代:Function Calling(函数调用)
2023年初,OpenAI推出了Function Calling功能。它的核心思想是:
用户输入
LLM判断需要调用函数
返回函数名和参数
外部系统执行
返回结果给LLM
但Function Calling有一个问题:每个AI应用都要自己实现与每个工具的集成。
假设有10个AI应用,要连接20个工具,理论上需要10×20=200个定制集成。每家都在重复造轮子,开发者苦不堪言。
第二代:MCP(Model Context Protocol)
2024年11月,Anthropic开源了MCP。它做的事情,和USB-C统一充电接口一模一样:
定义一套标准协议,让任何AI都能即插即用地连接任何工具。
有了MCP,10个AI应用+20个工具=10+20=30个MCP实现,而不是200个定制集成。数学上叫把M×N问题变成了M+N问题,实践中意味着开发成本断崖式下降。
第三代:Skills(技能)
2025年10月,Anthropic推出了Agent Skills。它解决的是另一个层面的问题:
不是让AI能"连接"什么,而是教AI怎么"思考"和"做事"。
Skills将专业知识、工作流程、最佳实践打包成AI能理解的操作手册,让AI在特定领域变得专业。
第二部分:深度解析MCP——AI世界的USB协议
2.1 MCP是什么?
**MCP(Model Context Protocol,模型上下文协议)**是Anthropic在2024年11月发布的开源协议,用于标准化AI应用与外部系统的交互方式。
官方的比喻是"AI应用的USB-C接口"——就像USB-C提供了一种通用的方式连接各种设备,MCP提供了一种通用的方式连接各种工具和数据源。
关键点:MCP不是Claude专属的。
它是一个开放协议,理论上任何AI应用都可以实现。截至2026年初,已经被多个平台采用:
- • Anthropic:Claude Desktop、Claude Code
- • OpenAI:ChatGPT、Agents SDK、Responses API
- • Google:Gemini SDK
- • Microsoft:Azure AI Services
- • 开发工具:Zed、Replit、Codeium、Sourcegraph
到2026年2月,已经有超过1000个开源MCP连接器。
2.2 MCP的架构设计
MCP基于JSON-RPC 2.0协议,采用客户端-主机-服务器(Client-Host-Server)架构:
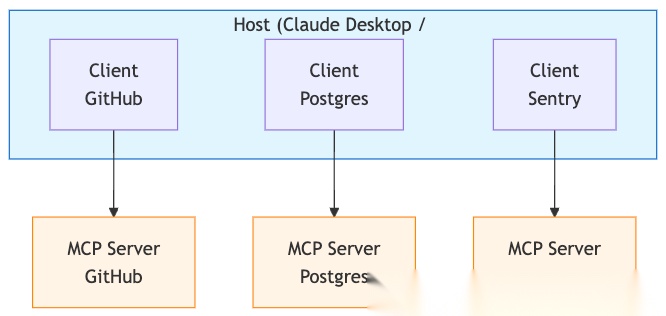
- • Host(主机):用户直接交互的应用(Claude Desktop、Cursor、Windsurf)
- • Client(客户端):Host应用中管理与特定Server通信的组件
- • Server(服务器):连接外部系统的桥梁(数据库、API、本地文件等)
这个架构的精妙之处在于:Host不需要知道Server的具体实现细节,只需要遵循MCP协议即可。
2.3 MCP的三个核心原语
MCP定义了三种Server可以暴露的原语:
1. Tools(工具)——模型控制
Tools是可执行的函数,AI可以调用来执行操作。

关键特征:
- • ✅ 有明确的输入输出schema
- • ✅ 执行具体操作(读、写、更新、删除等)
- • ✅ 由AI自主决定何时调用
2. Resources(资源)——应用控制
Resources是数据源,为AI提供上下文信息。
关键特征:
- • ✅ 提供静态或动态数据
- • ✅ 不执行操作,只提供信息
- • ✅ 由应用(而非AI)控制加载时机
3. Prompts(提示)——用户控制
Prompts是预定义的提示模板,帮助结构化与AI的交互。eview code.py
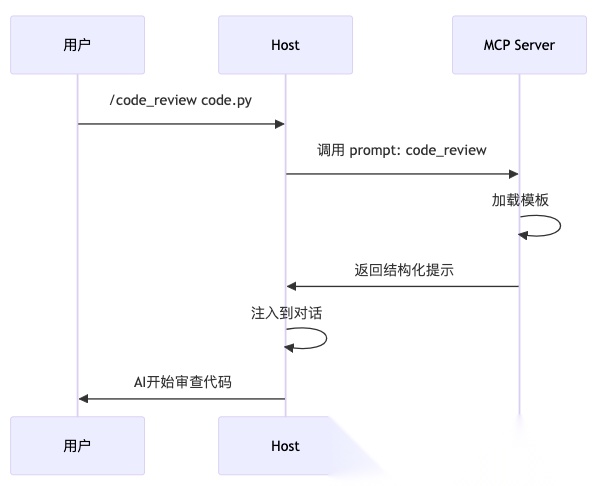
关键特征:
- • ✅ 预定义的工作流程
- • ✅ 由用户显式触发
- • ✅ 可以参数化
2.4 MCP vs Function Calling
很多人会问:MCP和OpenAI的Function Calling、Anthropic的Tool Use有什么区别?
Function Calling是LLM的能力——把自然语言转换成结构化的函数调用请求。LLM本身不执行函数,只是告诉你"应该调用什么函数,参数是什么"。
MCP是在Function Calling之上的协议层——它标准化了"函数在哪里、怎么调用、怎么发现"。
两者的关系:
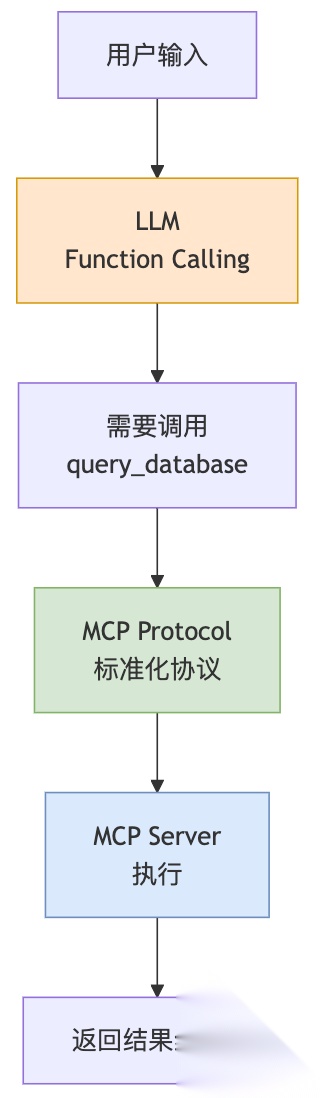
Function Calling解决"决定做什么",MCP解决"怎么做到"。
2.5 MCP的致命问题:上下文爆炸
但MCP有一个严重的副作用:吃掉你的上下文窗口。
每个MCP Server连接到AI时,必须把所有工具的定义(名称、描述、参数、示例)一次性塞进上下文。一个工具的定义大概500-800 tokens,一个MCP Server通常有10-20个工具。
来看几个真实数据:
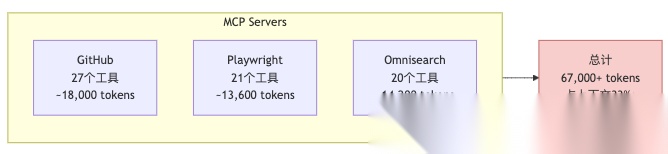
有开发者配了7个MCP Server,还没开始对话,上下文就被吃掉了67,000 tokens——占AI上下文窗口的33%。更夸张的案例是82,000 tokens,占41%。
这意味着什么?你问AI"2+2等于几",它回答"4"只需要5个token,但工具定义已经消耗了15,000 tokens。简单问题的成本被放大了3000倍。
更糟糕的是,当上下文被工具定义挤占后,AI选错工具、传错参数的概率会显著上升。实践中,连接2-3个以上的MCP Server,工具使用准确性就会明显下降。
2.6 MCP的解决方案:Tool Search
Anthropic意识到了这个问题。2026年1月,Claude Code推出了Tool Search功能:
- • MCP工具不再预加载,而是按需发现
- • 当工具定义超过上下文的10%时自动启用
- • AI需要用某个工具时,先搜索再加载
效果立竿见影:从77,000 tokens降到8,700 tokens,减少85%。
但这只是在给MCP打补丁。问题的根源在于:MCP的设计假设是"把所有工具摆出来让AI挑",这在工具数量少的时候没问题,工具多了就撑不住。
第三部分:深度解析Skills——AI的操作手册
3.1 Skills是什么?
Skill(全称Agent Skill)是Anthropic在2025年10月推出的特性。官方定义:
“Skills are organized folders of instructions, scripts, and resources that agents can discover and load dynamically to perform better at specific tasks.”
翻译一下:Skill是一个文件夹,里面放着指令、脚本和资源,AI会根据需要自动发现和加载。
Skill在架构层级上和MCP不同。
用Anthropic的话说:
“Skills are at the prompt/knowledge layer, whereas MCP is at the integration layer.”
Skill是"提示/知识层",MCP是"集成层"。两者解决不同层面的问题。
打个比方:
- • MCP是AI的"手"(能触碰外部世界)
- • Skill是AI的"技能书"(知道怎么做某件事)
你需要两者配合:MCP让AI能连接数据库,Skill教AI怎么分析查询结果。
3.2 Skills的核心设计:渐进式披露
Skill最精妙的设计是渐进式披露(Progressive Disclosure)。这是Anthropic在上下文工程(Context Engineering)领域的重要实践。
官方的比喻:
“Like a well-organized manual that starts with a table of contents, then specific chapters, and finally a detailed appendix.”
就像一本组织良好的手册:先看目录,再翻到相关章节,最后查阅附录。
Skill分三层加载:
第1层:元数据(始终加载)
- • Skill名称 + 描述
- • 约100 tokens
- • 就像浏览书架上的书名和简介,不打开书
第2层:核心指令(按需加载)
- • SKILL.md完整内容
- • 通常<5k tokens
- • 当AI判断某个Skill与任务相关时,才读取
第3层:参考资料(深度按需加载)
- • reference.md、脚本、模板等
- • 理论上可以包含无限内容
- • 只有任务真正需要时才加载
这个设计的好处是什么?
传统方式(比如MCP)在会话开始时就把所有信息加载到上下文。如果你有10个MCP Server,每个暴露5个工具,那就是50个工具定义——可能消耗数千甚至上万Token。
Skill的渐进式加载让你可以有几十个Skill,但同时只加载一两个。上下文效率大幅提升。
用官方的话说:
“This means that the amount of context that can be bundled into a skill is effectively unbounded.”
理论上,单个Skill可以包含无限量的知识——因为只有需要的部分才会被加载。
3.3 Skills的文件结构
一个标准的Skill长这样:
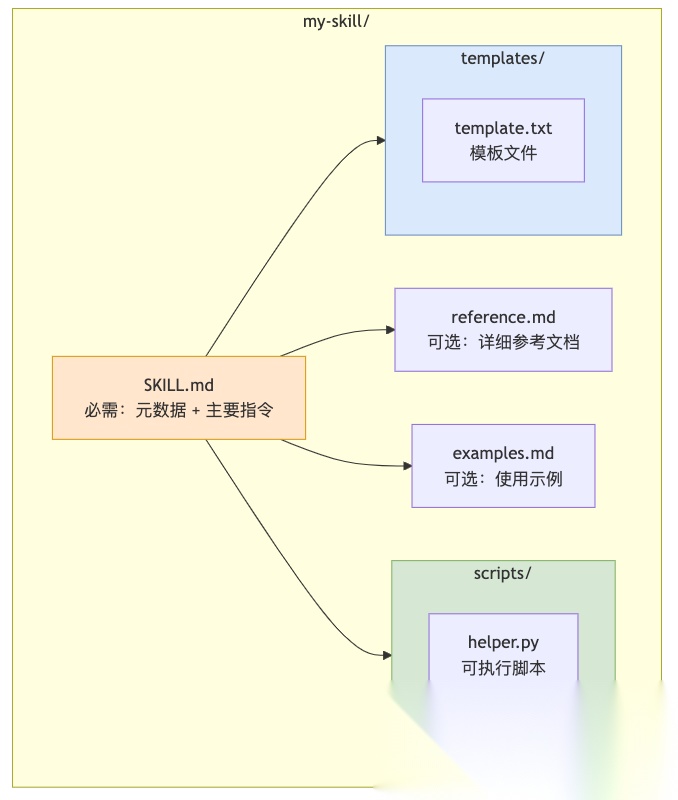
SKILL.md是核心,必须包含YAML格式的元数据:
---name:code-reviewdescription:> Review code for bugs, security issues, and style violations. Use when asked to review code, check for bugs, or audit PRs.---# Code Review Skill## InstructionsWhenreviewingcode,follow these steps:1.Firstcheckforsecurityvulnerabilities...2.Thencheckforperformanceissues...3.Finallycheckforcodestyle...## ExamplesExample 1:Input: def foo(x):returnx+1Output:Missingtypehints,consideraddingtype annotations.
关键字段:
- •
name:Skill的唯一标识,小写字母+数字+连字符,最多64字符 - •
description:描述做什么、什么时候用,最多1024字符
description的质量直接决定Skill能不能被正确触发。
3.4 Skills的触发机制
Skill是自动触发的,这是它和Slash Command的关键区别。
工作流程:
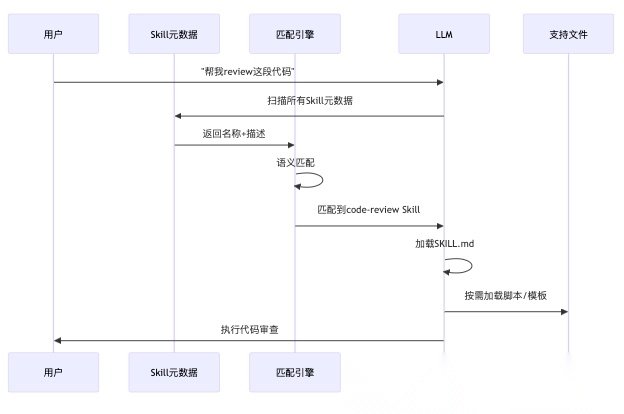
- 扫描阶段:Claude读取所有Skill的元数据(名称+描述)
- 匹配阶段:将用户请求与Skill描述进行语义匹配
- 加载阶段:如果匹配成功,加载完整的SKILL.md
- 执行阶段:按照Skill里的指令执行任务,按需加载支持文件
用户不需要显式调用。比如你有一个code-review Skill,用户说"帮我review这段代码",Claude会自动匹配并加载。
Skill的本质是什么?
技术上,Skill是一个元工具(Meta-tool),Skill不是执行具体动作,而是注入指令到对话历史中,动态修改Claude的执行环境。
3.5 Skills的杀手锏:自带脚本
Skills还有一个很多人忽略的能力:它可以自带可执行脚本。
一个典型的Skill文件夹结构是这样的:
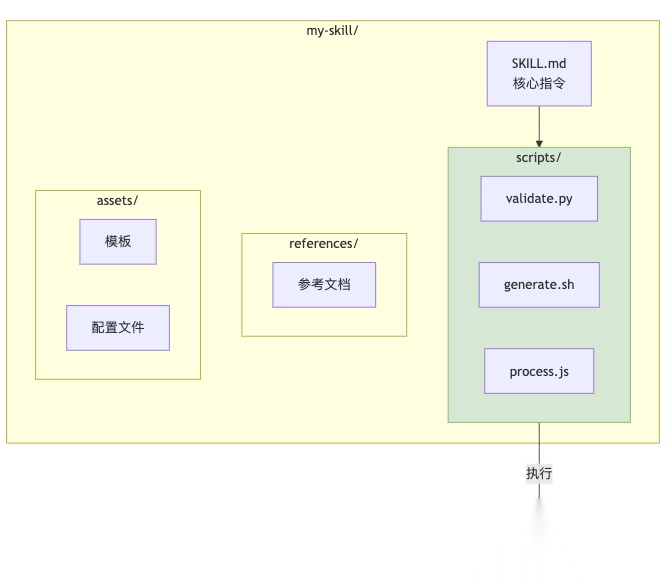
关键来了:当AI运行scripts/validate.py时,脚本代码本身不会加载到上下文,只有执行结果会返回。
这是什么概念?
假设你有一个500行的Python脚本,用来处理PDF表单。用传统方式,AI要么自己写代码(消耗大量tokens生成),要么读取你的脚本再执行(脚本内容占用上下文)。而用Skills,AI直接运行预写好的脚本,整个过程可能只消耗50 tokens的输出结果。
脚本执行 = 零上下文成本 + 确定性结果
更重要的是:这些脚本通过Agent内置的bash工具执行,不需要MCP。
Skills支持的脚本语言包括Python、Bash、JavaScript等,基本上你系统能跑的都能用。这意味着:
- • ✅ 文件读写?Skill脚本搞定
- • ✅ 数据处理?Skill脚本搞定
- • ✅ 格式转换?Skill脚本搞定
- • ✅ 本地API调用?Skill脚本搞定
3.6 写好Skill的关键:description的质量
Skill能不能被正确触发,90%取决于description写得好不好。
❌ 差的description:
description: Helps with data
太宽泛,Claude不知道什么时候该用。
✅ 好的description:
description: > Analyze Excel spreadsheets, generate pivot tables, and create charts. Use when working with Excel files (.xlsx), spreadsheets, or tabular data analysis. Triggers on: "analyze spreadsheet", "create pivot table", "Excel chart"
好的description应该包含:
- 做什么:具体的能力描述
- 什么时候用:明确的触发场景
- 触发词:用户可能说的关键词
第四部分:MCP vs Skills——终极对比
4.1 架构层级对比
现在我们可以从架构层级来理解两者的区别:
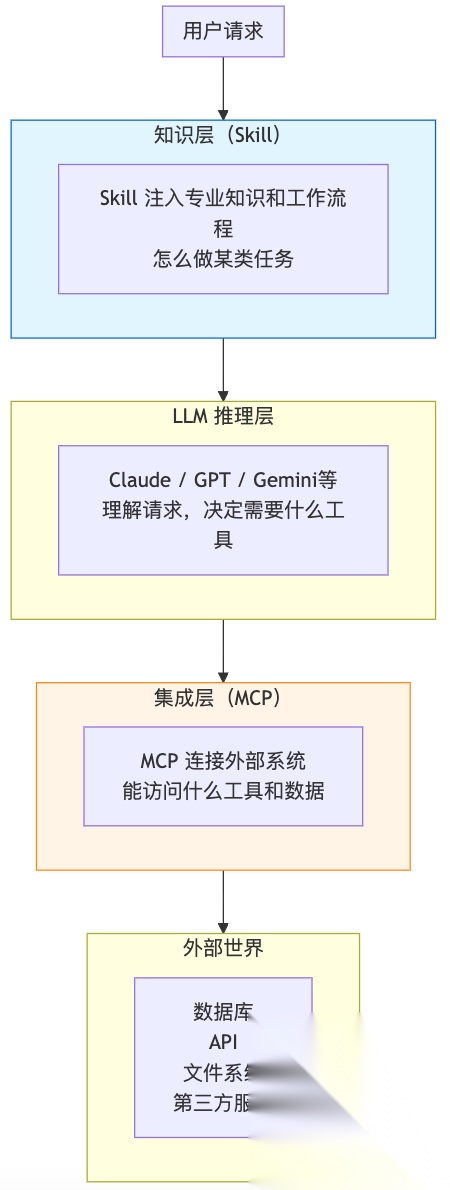
Skill在上层(知识层),MCP在下层(集成层)。
两者不是替代关系,而是互补关系。你可以:
- • 用MCP连接GitHub
- • 用Skill教AI如何按照团队规范做Code Review
4.2 详细对比表
| 维度 | MCP | Skills |
|---|---|---|
| 核心作用 | 连接外部系统 | 编码专业知识和方法论 |
| 架构层级 | 集成层(底层) | 知识层(上层) |
| 类比 | USB协议 | 应用程序 |
| 问的问题 | “AI能访问什么?” | “AI知道怎么做什么?” |
| 协议基础 | JSON-RPC 2.0 | Markdown文件 |
| 跨平台 | ✅ 是(开放协议) | ❌ 否(Anthropic专属) |
| 触发方式 | 持久连接,随时可用 | 语义匹配,自动触发 |
| Token消耗 | ❌ 高(工具定义始终占用) | ✅ 低(渐进式加载) |
| 能访问外部系统 | ✅ 可以 | ❌ 不能(需配合MCP或内置工具) |
| 实现复杂度 | 高(需要运行Server) | 低(写Markdown就行) |
| 适用场景 | 查数据库、调API | 代码审查、文档生成 |
| 分发方式 | URL接入,面向外部用户 | 文件复制,面向内部团队 |
| 可执行性 | API调用 | 脚本执行 |
| 安全性 | 外部内容带来prompt injection风险 | Skill文件本身可能包含恶意指令 |
4.3 什么时候用MCP,什么时候用Skills?
✅ 用MCP的场景:
- 需要访问外部数据:数据库查询、API调用、文件系统访问
- 需要操作外部系统:创建GitHub Issue、发送Slack消息、执行SQL
- 需要实时信息:监控系统状态、查看日志、搜索引擎结果
- 需要跨平台复用:同一个工具在Claude Desktop、Cursor、其他支持MCP的应用中使用
- 对外提供服务:做一个服务让外部用户都能用
✅ 用Skills的场景:
- 重复性的工作流程:代码审查、文档生成、数据分析
- 公司内部规范:代码风格、提交规范、文档格式
- 需要多步骤的复杂任务:需要详细指导的专业任务
- 团队共享的最佳实践:标准化的操作流程
- Token敏感场景:需要大量知识但不想一直占用上下文
- 优化自己或团队的工作流:本地自动化
4.4 组合使用:最佳实践
很多时候,两者是配合使用的:
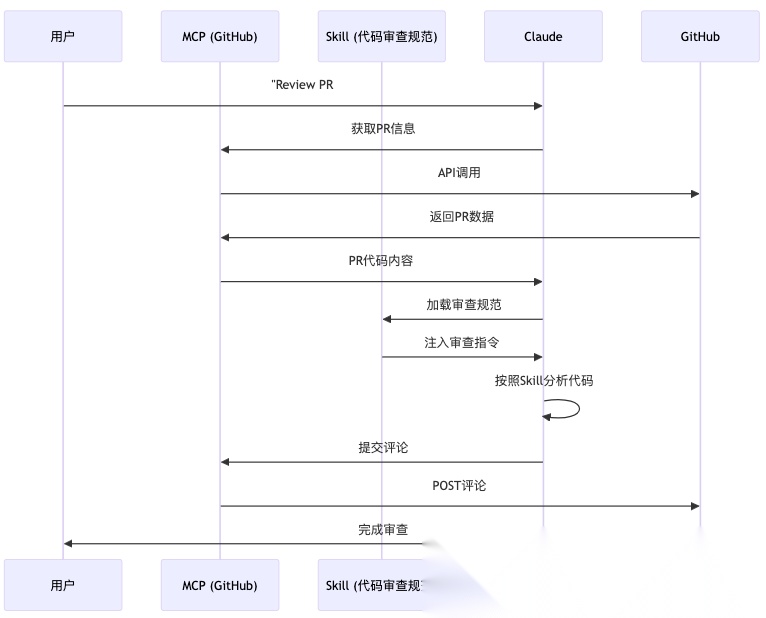
MCP负责"能访问什么",Skill负责"怎么做"。
第五部分:真实案例——从MCP到Skills的演进
5.1 案例:自动发布X Article
这是一个真实发生的演进过程,完美展示了从MCP到Skills的转变。
需求:把Markdown文章自动发布到X(Twitter)的长文功能X Article。
方案一:Playwright MCP
王树义老师开发了x-article-publisher-skill,流程是这样的:

提示词很简洁,功能也很强大。但问题来了:上下文消耗得飞快。
Playwright MCP有22个工具,光工具定义就占用约8,000-10,000 tokens。更要命的是,每次浏览器交互,MCP都要返回页面的accessibility tree(无障碍树)快照——这是为了让AI理解当前页面状态。一个复杂页面的快照可能就是几千tokens。
发布一篇文章,可能需要:打开页面、等待加载、点击编辑器、粘贴内容、上传图片、调整位置、保存草稿……每一步都是一次MCP交互,每一次交互都在消耗上下文。
结果:一篇文章发完,上下文可能已经用掉50,000+ tokens。
方案二:Skills + CDP脚本(改进版本)
baoyu-post-to-x把Playwright MCP部分完全改成了脚本:
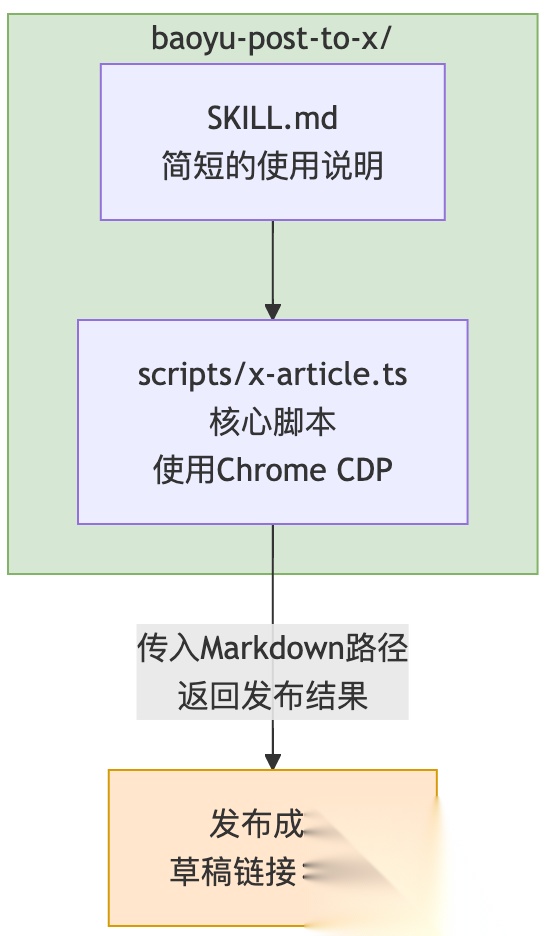
核心变化:
- 脚本直接调用Chrome CDP(Chrome DevTools Protocol),绕过MCP
- 传入Markdown文件路径,脚本自己解析内容
- 脚本自己完成所有浏览器操作:打开页面、填充内容、上传图片、保存草稿
- 只返回最终结果给Agent:“发布成功,草稿链接:xxx”
整个过程,AI只需要做一件事:调用脚本,传入文件路径。
上下文消耗:可能只有几百tokens。
对比分析:
| Playwright MCP | Skills + CDP脚本 | |
|---|---|---|
| 工具定义 | ~10,000 tokens(22个工具) | 0(脚本不需要工具定义) |
| 每次交互 | 返回页面快照(数千tokens) | 无中间交互 |
| AI参与度 | 每一步都要AI决策 | 只需调用一次脚本 |
| 总消耗 | 50,000+ tokens | 几百tokens |
关键洞察:MCP的设计是让AI一步步操作,每一步都要理解、决策、执行。而脚本的设计是把整个流程封装起来,AI只需要说"开始"和"结束"。
这就是为什么即使MCP支持了Tool Search(按需加载工具),上下文问题也没有根本解决——因为工具定义只是一部分,真正的大头是交互过程中产生的中间结果。
而Skills的脚本执行模式,天然避开了这个问题:脚本代码不进入上下文,中间过程不进入上下文,只有最终结果进入上下文。
第六部分:Tools的定位——MCP的能力单元
6.1 Tools是什么?
在前面的讨论中,我们一直在说MCP和Skills,那么Tools到底扮演什么角色?
Tools是MCP暴露的具体能力单元。
回想一下MCP的三个核心原语:
- Tools(工具):可执行的函数
- Resources(资源):数据源
- Prompts(提示):预定义的提示模板
Tools是其中最常用、最核心的部分。
6.2 Tools vs MCP的关系
可以把MCP理解为一个协议框架,而Tools是这个框架中具体的能力实现。
类比:
- • MCP = HTTP协议
- • Tools = RESTful API端点
HTTP定义了请求响应的标准,而具体的API端点(如GET /users、POST /articles)才是实际的能力。
一个MCP Server通常会暴露多个Tools
每个Tool都有:
- • 名称(name)
- • 描述(description)
- • 参数schema(parameters)
6.3 Tools vs Skills的区别
虽然Tools和Skills都能"扩展AI能力",但它们的本质完全不同:
Tools(工具):
- • ✅ 是执行单元:执行具体操作
- • ✅ 有明确的输入输出schema
- • ✅ 确定性执行:同样的输入,得到同样的输出
- • ✅ 由AI自主决定何时调用
- • ✅ 通常是API调用或函数执行
Skills(技能):
- • ✅ 是知识单元:提供方法论和指导
- • ✅ 用自然语言描述
- • ✅ 非确定性:AI需要理解并执行指令
- • ✅ 自动触发:基于语义匹配
- • ✅ 通常是工作流程或最佳实践
打个比方:
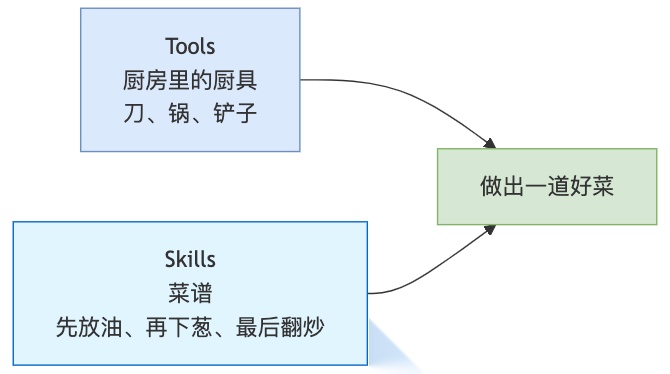
厨具是执行工具,菜谱是操作指南。两者配合,才能做出一道好菜。
第七部分:未来趋势与最佳实践
7.1 随着Skills普及,MCP的需求会大幅减少
这是一个正在发生的趋势。
想想看,什么时候你真正需要MCP?
需要MCP的场景:

不需要MCP的场景:
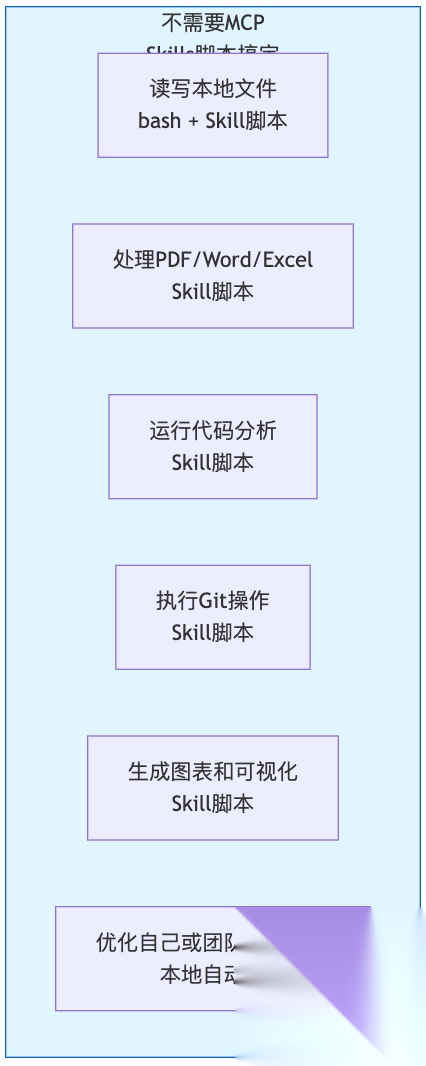
事实上,Anthropic的工程博客提到:他们用"代码执行+MCP"的方法,把一个150,000 token的工作流压缩到了2,000 tokens——核心思路就是让AI写代码调用工具,而不是预加载所有工具定义。
这正是Skills的设计方向:用脚本封装能力,用渐进式披露管理知识,最大限度减少上下文消耗。
未来的格局可能是这样的:
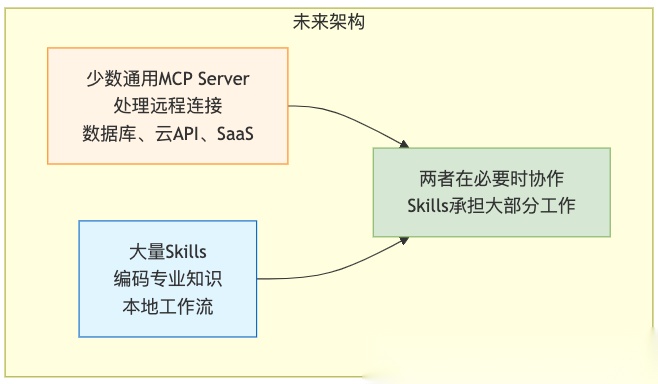
- 少数通用MCP Server处理远程连接(数据库、云API、SaaS集成)
- 大量Skills编码专业知识和本地工作流
- 两者在必要时协作,但Skills会承担绝大部分"教AI怎么做事"的工作
7.2 给开发者和架构师的建议
对于个人开发者:
- 优先学习Skills:它更轻量、更高效、更容易上手
- 用Skills封装你的工作流程:把重复性任务自动化
- 只在必须连接远程系统时才用MCP:避免不必要的上下文消耗
- 复杂逻辑用脚本:不要让AI一步步操作
对于团队/企业:
- 建立Skills库:将团队的最佳实践、代码规范、工作流程打包成Skills
- 用Git管理Skills:版本控制、代码审查、持续集成
- MCP用于对外服务:如果要给客户提供AI服务,用MCP标准化接口
- 两者结合使用:MCP连接外部系统,Skills编码内部流程
对于架构师:
- 理解架构层级:MCP在集成层,Skills在知识层
- 设计混合架构:MCP + Skills + 内置工具
- 关注Token效率:渐进式披露优于预加载
- 考虑安全性:审查MCP Server和Skills的来源
7.3 三个关键问题帮你做决策
到底选MCP还是Skills?问自己三个问题:
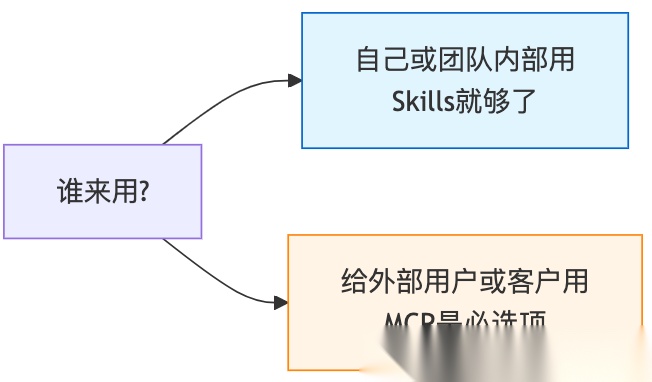
1. 谁来用?
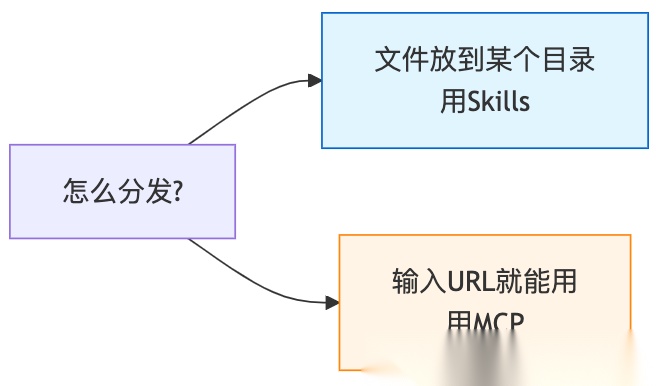
2. 怎么分发?
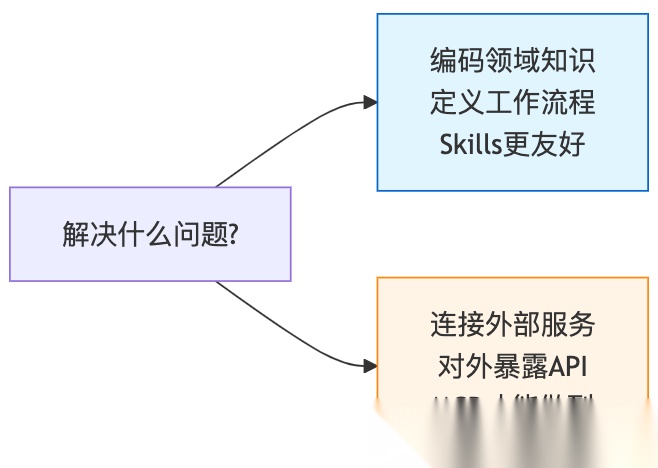
3. 要解决什么问题?
结尾:回到最初的问题
所以,回到文章开头那位开发者的问题:“MCP、Tools、Skills到底有什么区别?”
现在我们可以给出清晰的答案:
一句话总结:

- • MCP是AI世界的USB协议,定义了AI与外部世界的连接标准
- • Tools是MCP暴露的具体能力,是AI可以调用的函数
- • Skills是AI的操作手册,教AI怎么完成特定任务
它们的关系:

- • MCP vs Skills:不是竞争关系,而是不同层次的能力(集成层 vs 知识层)
- • MCP vs Tools:框架 vs 实现,MCP是协议,Tools是协议中的能力单元
- • Tools vs Skills:执行工具 vs 操作指南,一个是"能做什么",一个是"怎么做"
最佳实践:
用Skills编码你的领域知识,用MCP连接外部服务。
比如你们公司有一套特定的工作流程:先查这个系统,再查那个系统,按某个顺序处理。这种领域知识用Skills写出来,让AI理解。但具体连接那些系统的能力,靠MCP提供。两层配合,各司其职。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献198条内容
已为社区贡献198条内容

所有评论(0)