计算机毕业设计源码:Python 城市房价数据分析系统 Flask框架 可视化 scikit-learn机器学习 requests爬虫 大数据 大模型 房屋 房子(建议收藏)✅
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
Python语言、MySQL数据库、Flask框架、Echarts可视化工具、scikit-learn机器学习库、决策树预测算法(CART分类回归树)、requests爬虫
功能模块
• 用户注册登录模块
• 数据采集模块
• 房屋数据列表展示模块
• 房源数量分析模块
• 房屋均价分析模块
• 房价热力地图展示模块
• 房价随时间变化分析模块
• 词云图分析模块
• 房屋朝向分析模块
• 房屋居室分析模块
• 房屋面积大小分析模块
• 房屋数量折线图分析模块
• 房价预测模块
• 房屋信息管理模块
• 用户信息管理模块
项目介绍
本项目是基于Python语言构建的58同城房产数据分析与预测平台,整合数据采集、分析、预测与可视化全流程技术。系统采用requests爬虫实现58同城房产数据的自动化采集,经MySQL数据库高效存储后,依托Flask框架搭建Web应用层,保障前后端交互稳定性。数据可视化层面借助Echarts生成房源数量分布、房屋均价对比、房价时序变化、词云图、朝向与居室分布等多维度图表,直观呈现房产市场特征。核心技术亮点在于集成scikit-learn机器学习库中的CART分类回归树算法,构建房价预测模型,为用户提供精准的房价参考。系统配备注册登录权限管理功能,支持房屋与用户信息的高效增删改查操作,数据采集模块可灵活更新最新房源信息,房屋数据列表清晰呈现房源详情,满足用户查询与管理需求。
2、项目界面
(1)房源数量分析、房屋均价分析
该页面是房价数据可视化分析系统界面,包含数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过饼图与柱状图分别展示指定区域房屋数量分布与对应均价情况,辅助用户直观了解区域房价与房源分布特征。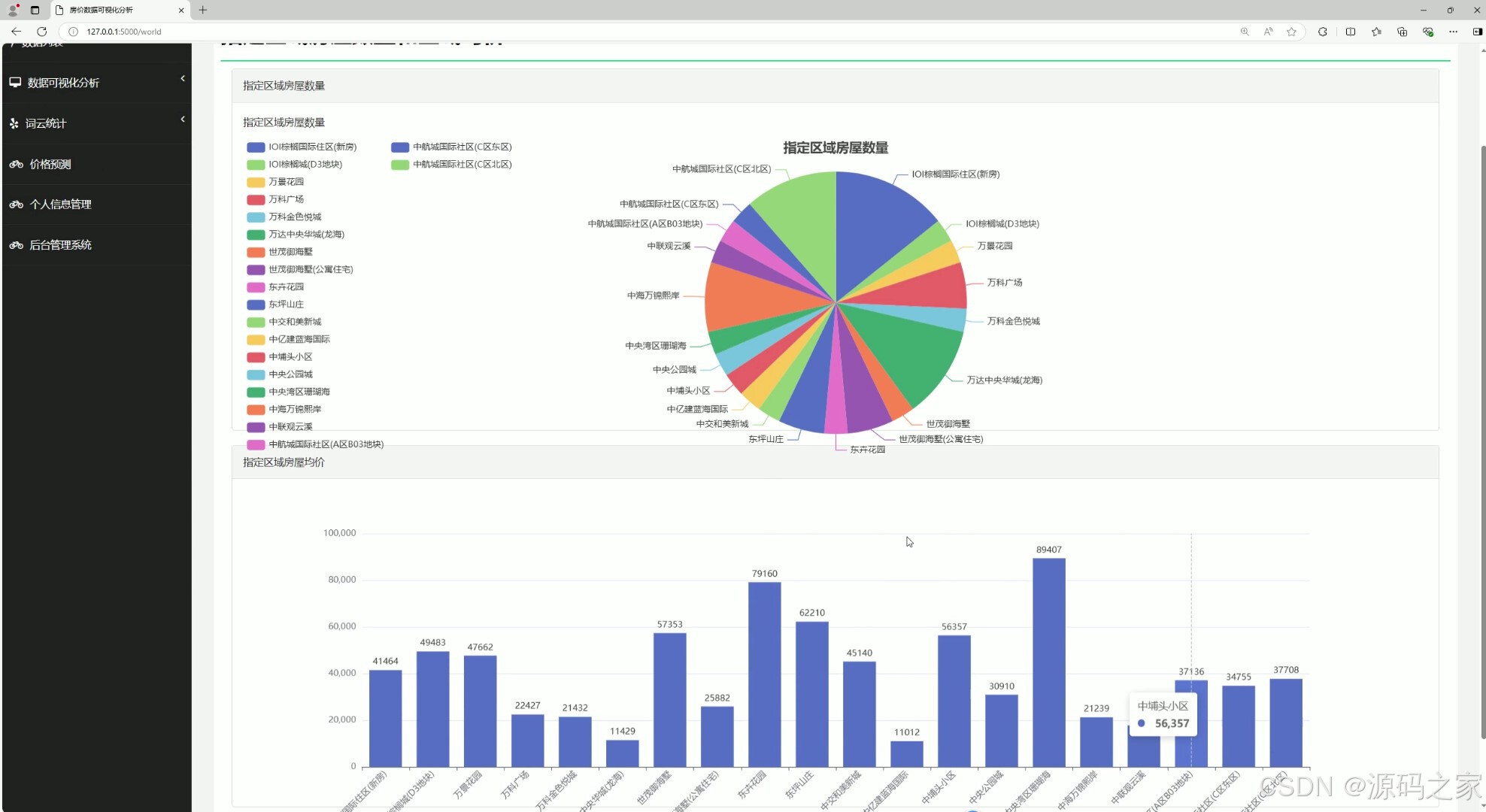
(2)首页
该页面是房价数据可视化分析系统界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过中国房价热力地图直观展示各区域房价分布,辅助用户把握全国房价格局。
(3)房价随时间变化分析
该页面是房价数据可视化分析系统界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过柱状图直观展示 2000 年至 2024 年房价随时间的变化趋势,辅助用户把握房价长期波动规律。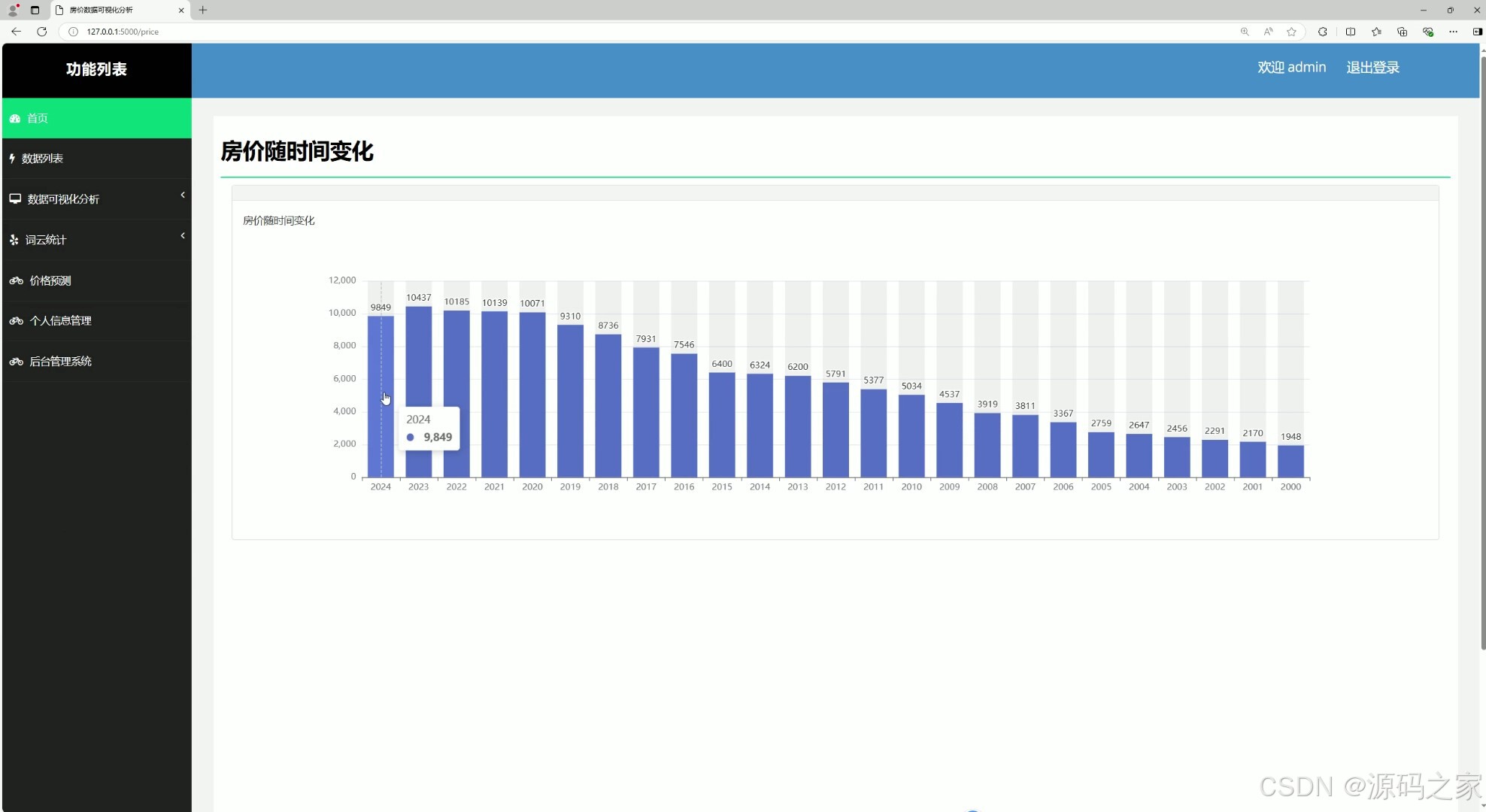
(4)词云图分析
该页面是房价数据可视化分析系统界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过词云图直观展示房源描述中的高频关键词,帮助用户快速把握房源核心特征与市场关注重点。
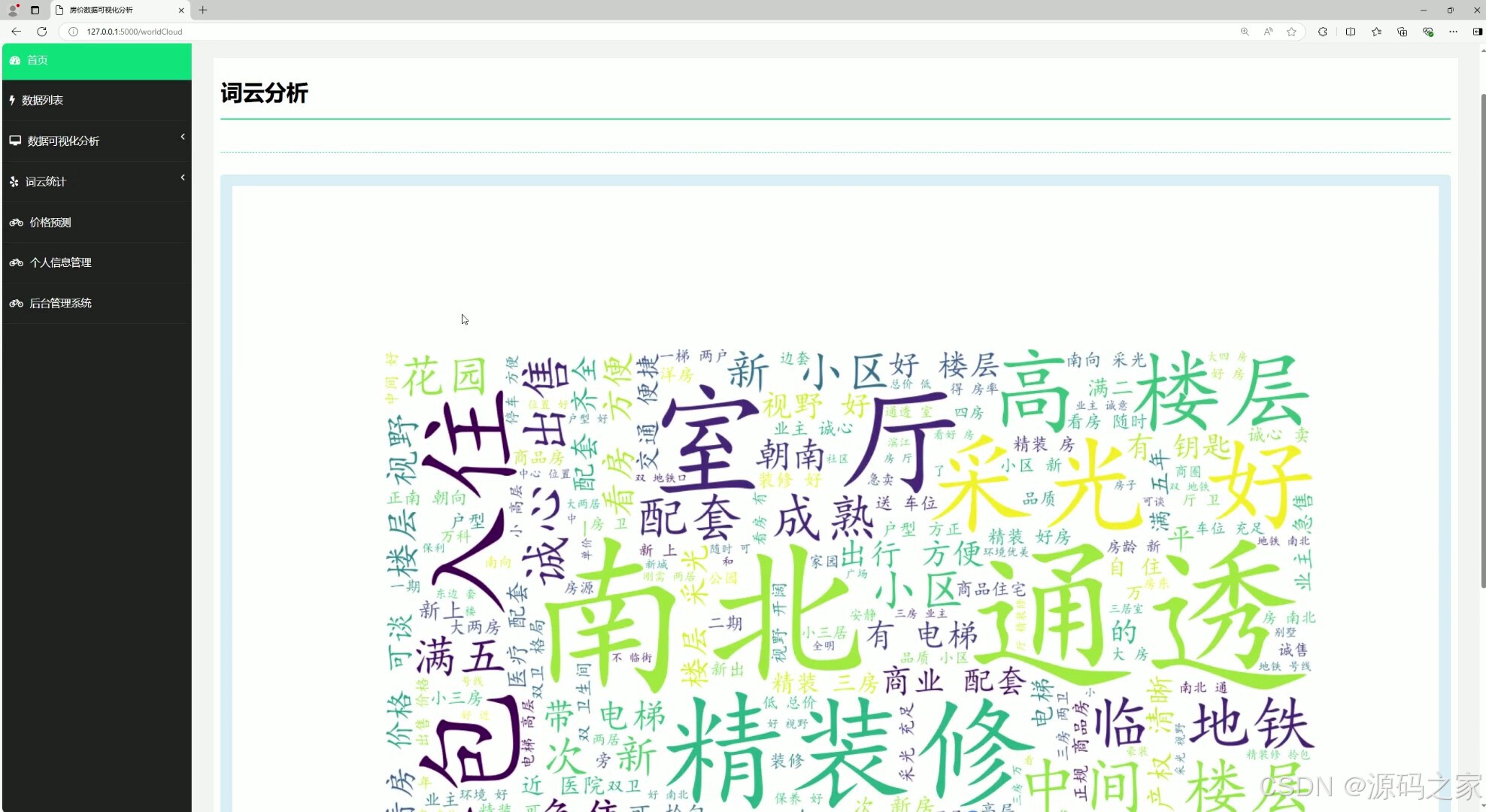
(5)房屋朝向分析
该页面是房价数据可视化分析系统界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过饼图与箱线图分别展示房屋朝向数量占比与不同朝向的价格分布,辅助用户分析朝向对房源数量及房价的影响。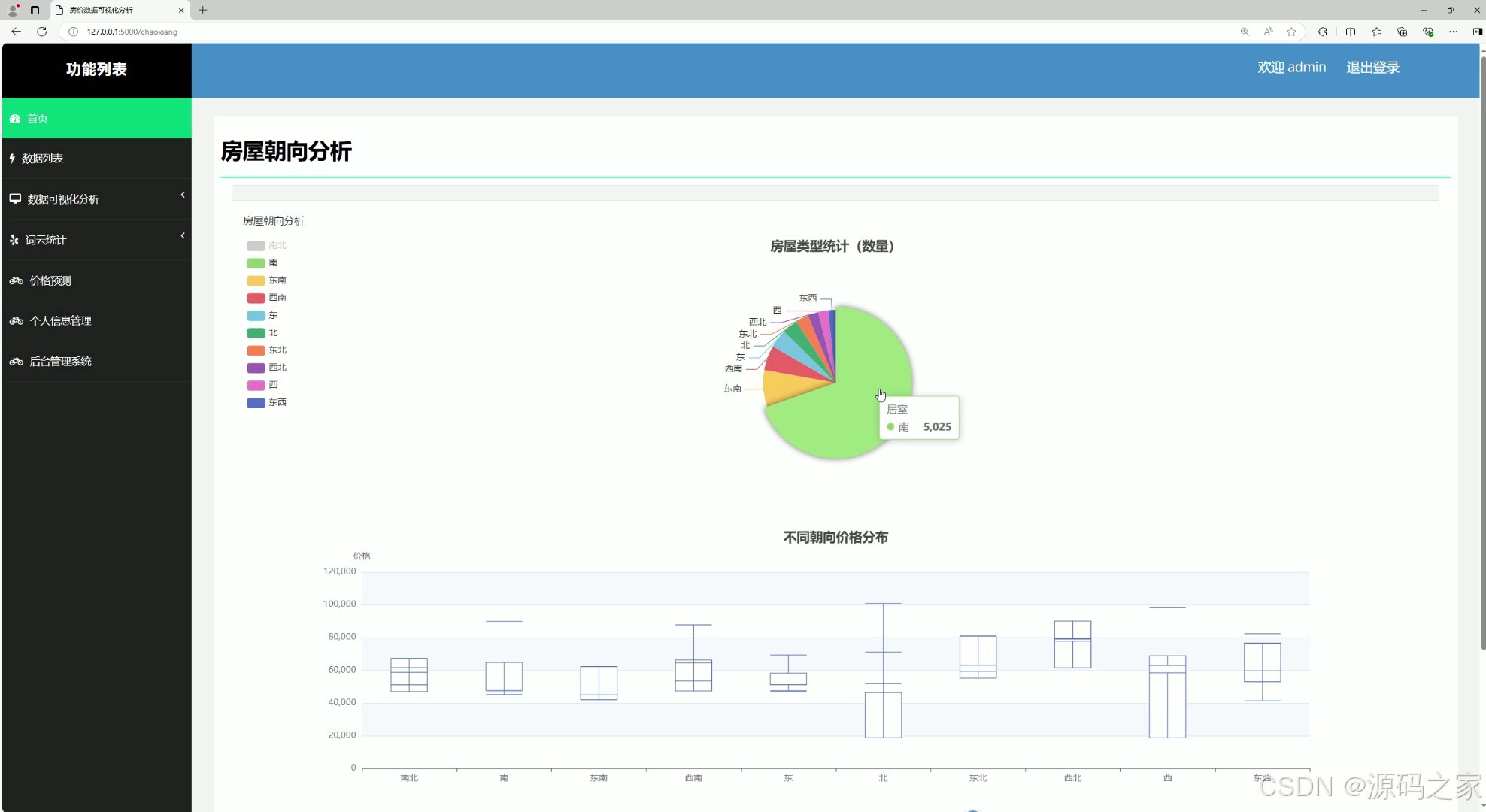
(6)房屋居室分析
该页面是房价数据可视化分析系统界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过饼图与箱线图分别展示不同居室数量的占比与对应价格分布,辅助用户分析居室数量对房源结构及房价的影响。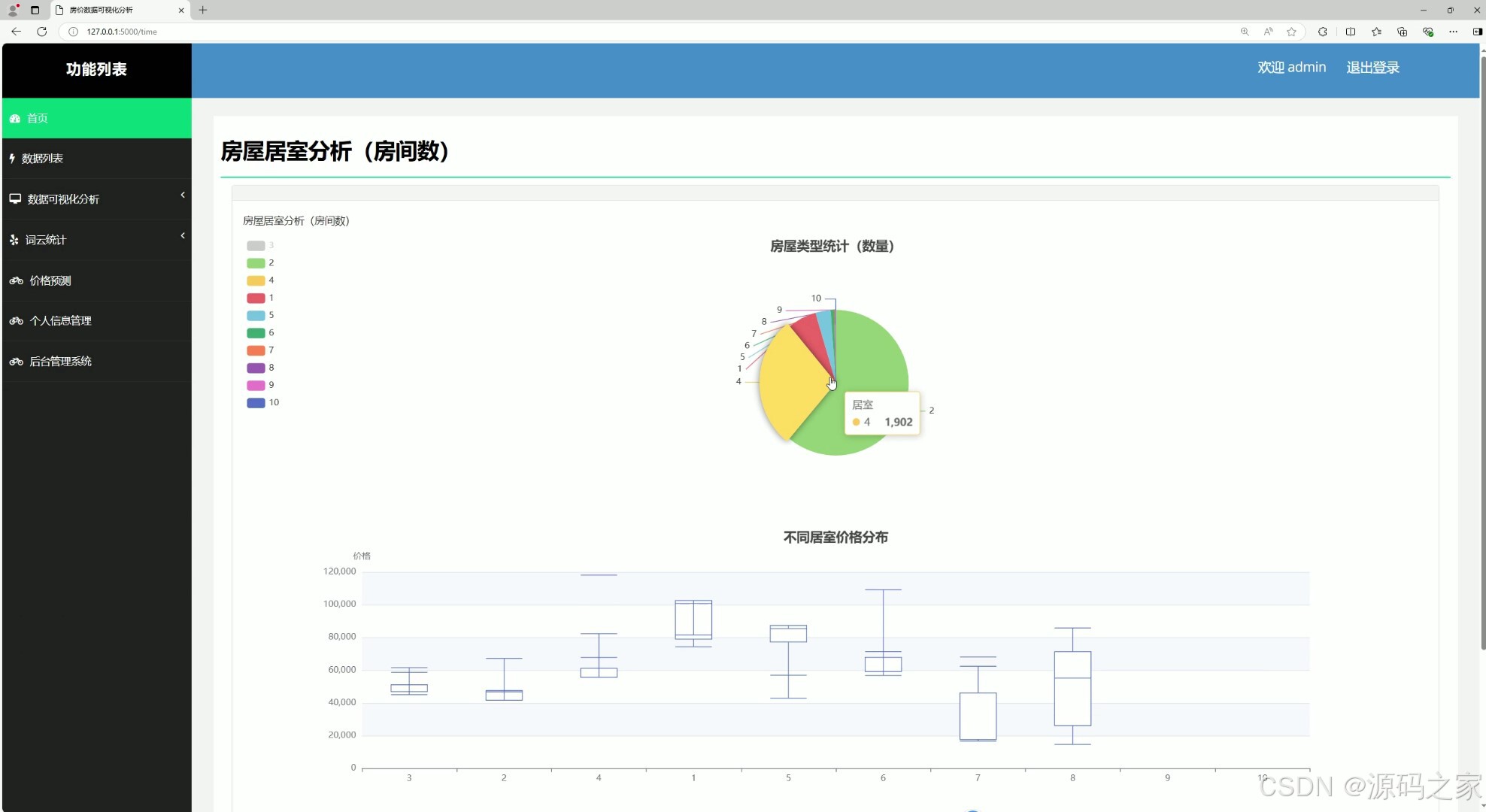
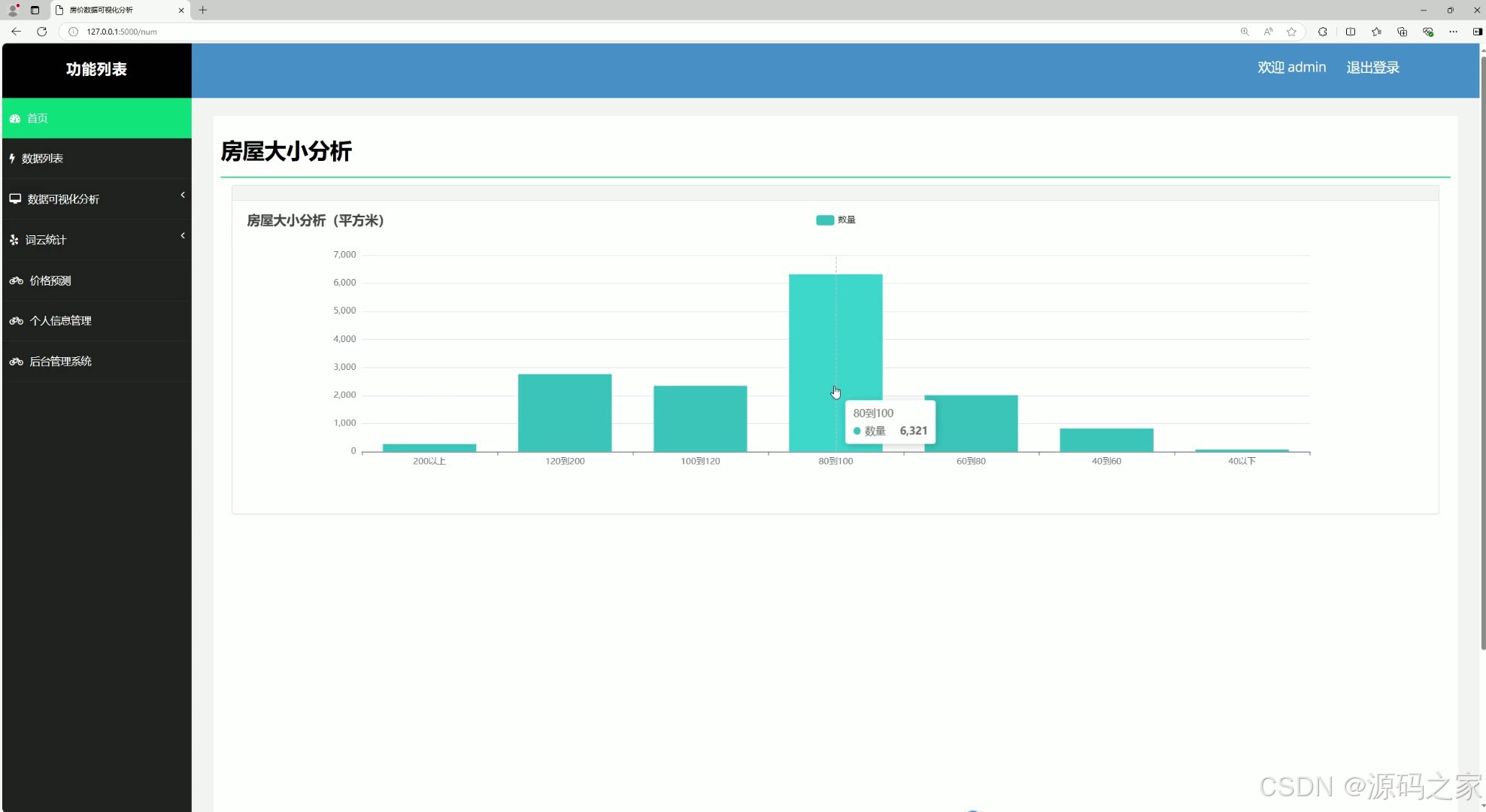
(7)房屋面积大小分析
该页面是房价数据可视化分析系统界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过柱状图直观展示不同面积区间房屋的数量分布,辅助用户把握房源面积结构特征与市场规律。
(8)房屋数量折线图分析
该页面是房价数据可视化分析系统界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,可通过折线图直观展示历年房屋数量的变化趋势,辅助用户分析房源供给的时间波动规律。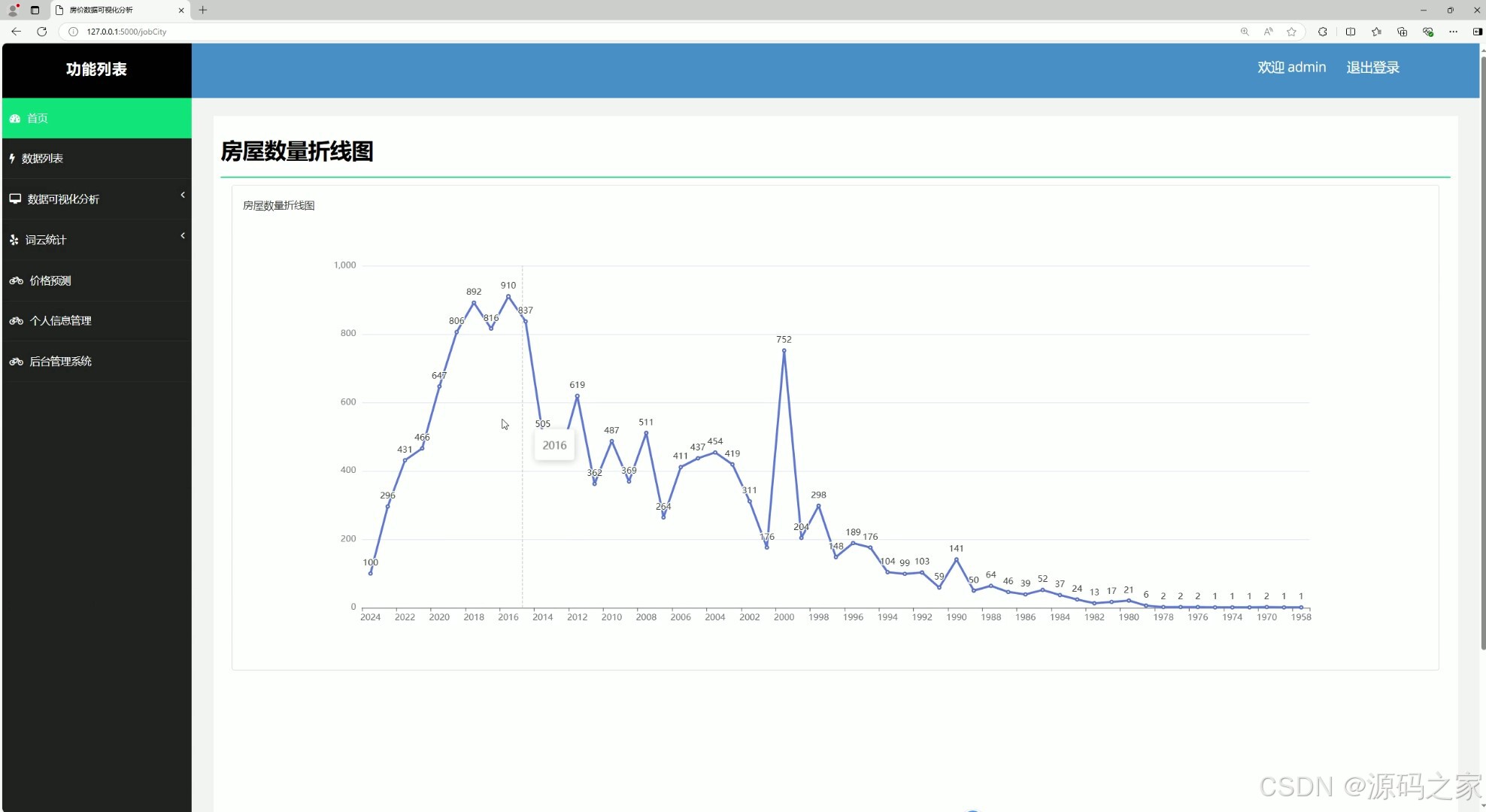
(9)房屋数据列表
该页面是房价数据可视化分析系统的数据列表界面,涵盖首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理及后台管理系统等功能模块,以表格形式清晰呈现房源的各类详细信息,便于用户快速检索、管理房源数据。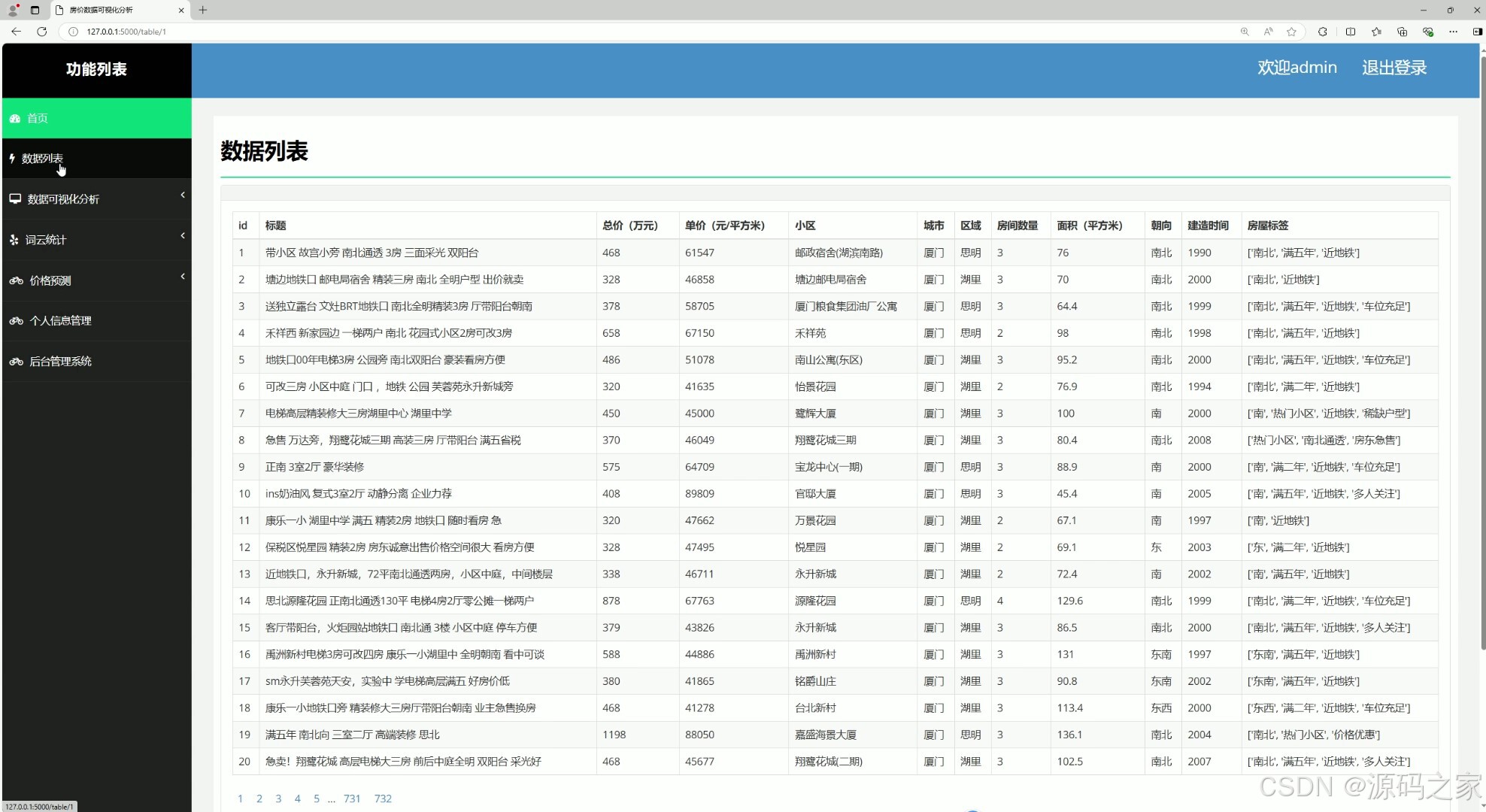
(10)房价预测
该页面是房价数据可视化分析系统的价格预测界面,包含首页、数据列表、数据可视化分析、词云统计、价格预测、个人信息管理、后台管理系统等功能模块,支持用户通过选择城市、区域、朝向等参数进行房价预测,并以折线图展示价格走势,辅助用户预判房价趋势。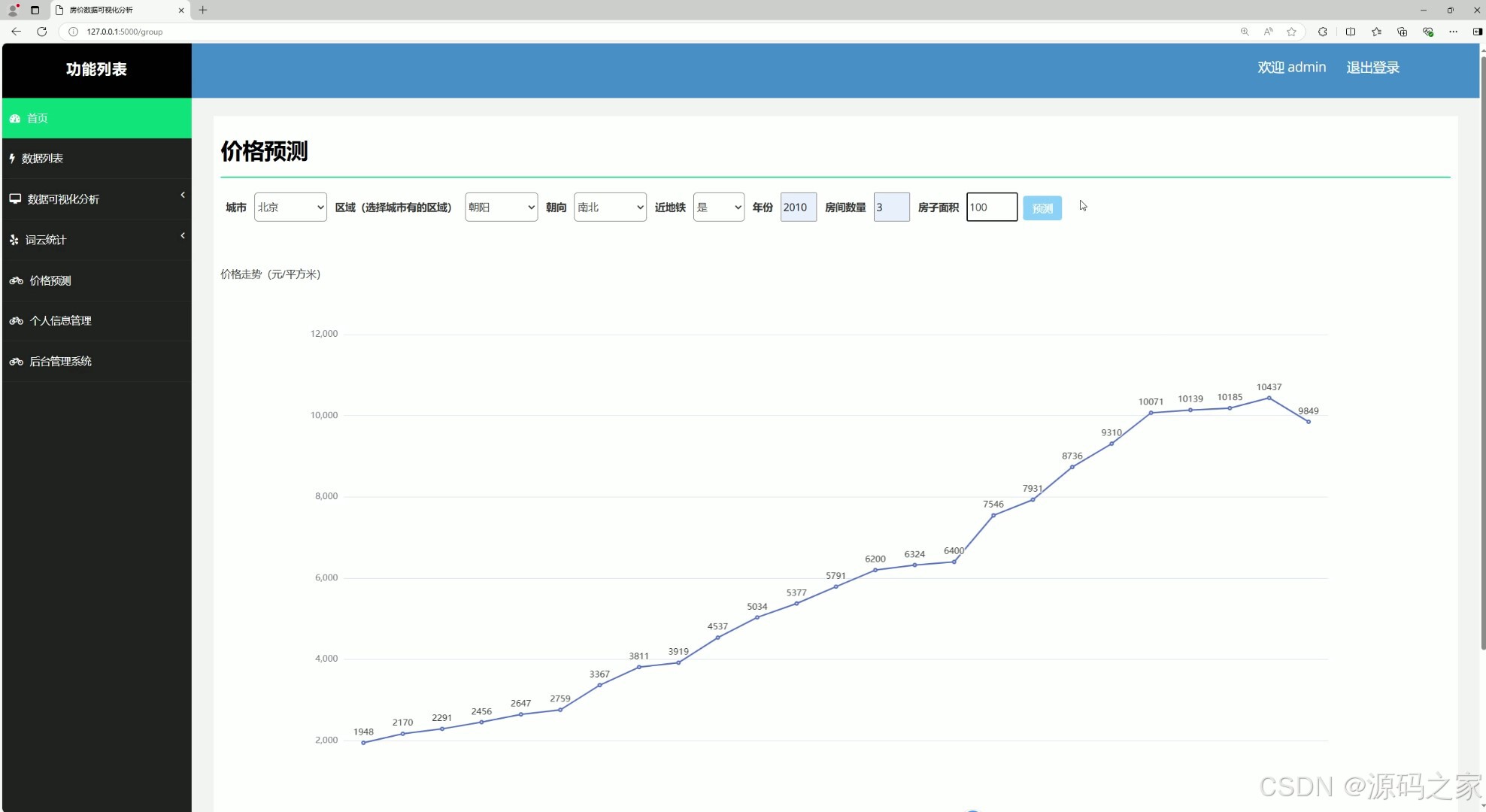
(11)房屋信息管理
该页面是房价数据可视化分析系统的后台管理界面,包含后台首页、用户数据管理、房屋数据管理等功能模块,支持对房产信息进行查询、添加、编辑、删除等操作,实现房源数据的高效管理与维护。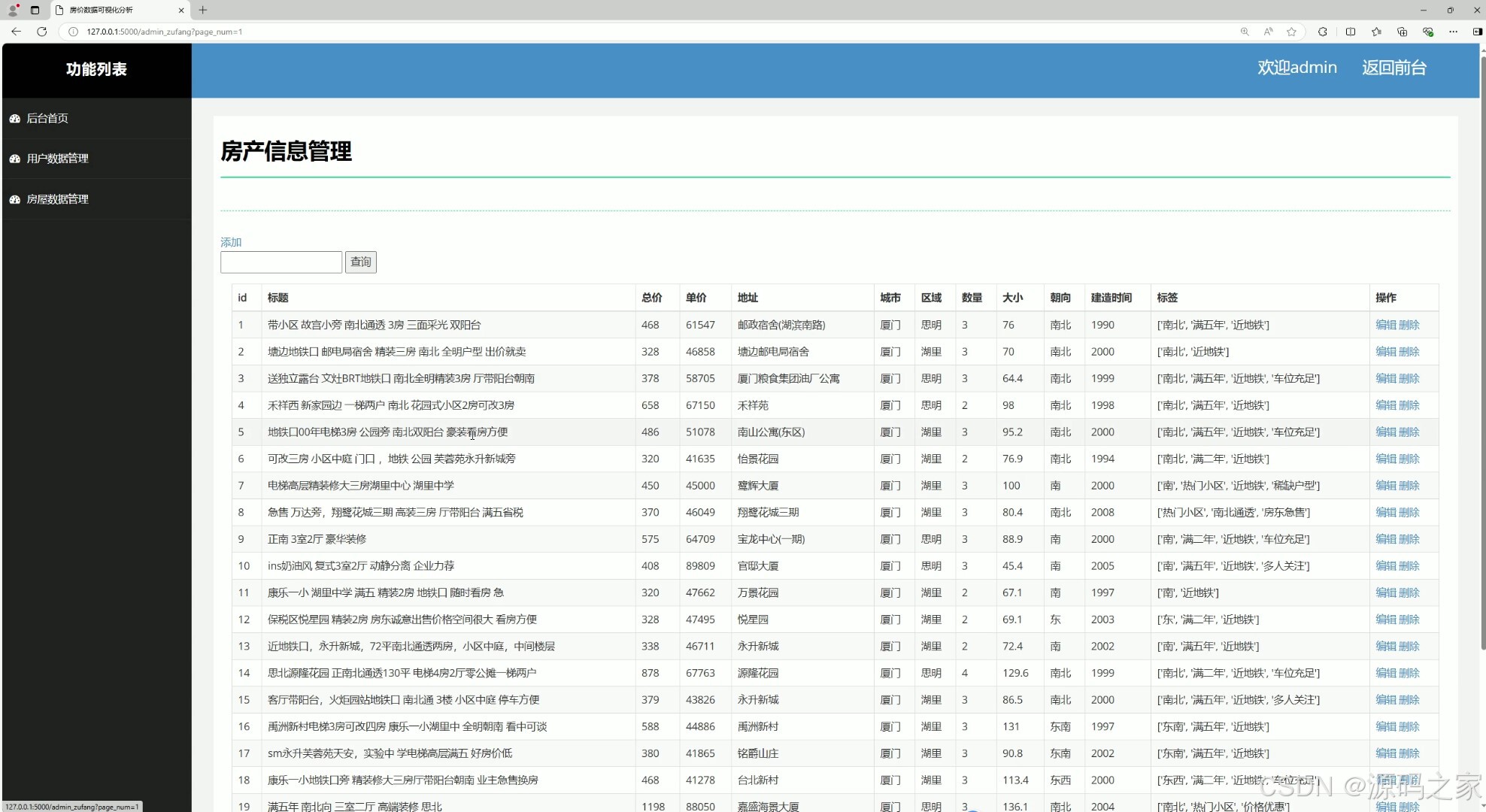
(12)用户信息管理
该页面是房价数据可视化分析系统的后台用户信息管理界面,包含后台首页、用户数据管理、房屋数据管理等功能模块,支持对用户信息进行查询、添加、编辑、删除等操作,实现用户数据的高效管理与维护。
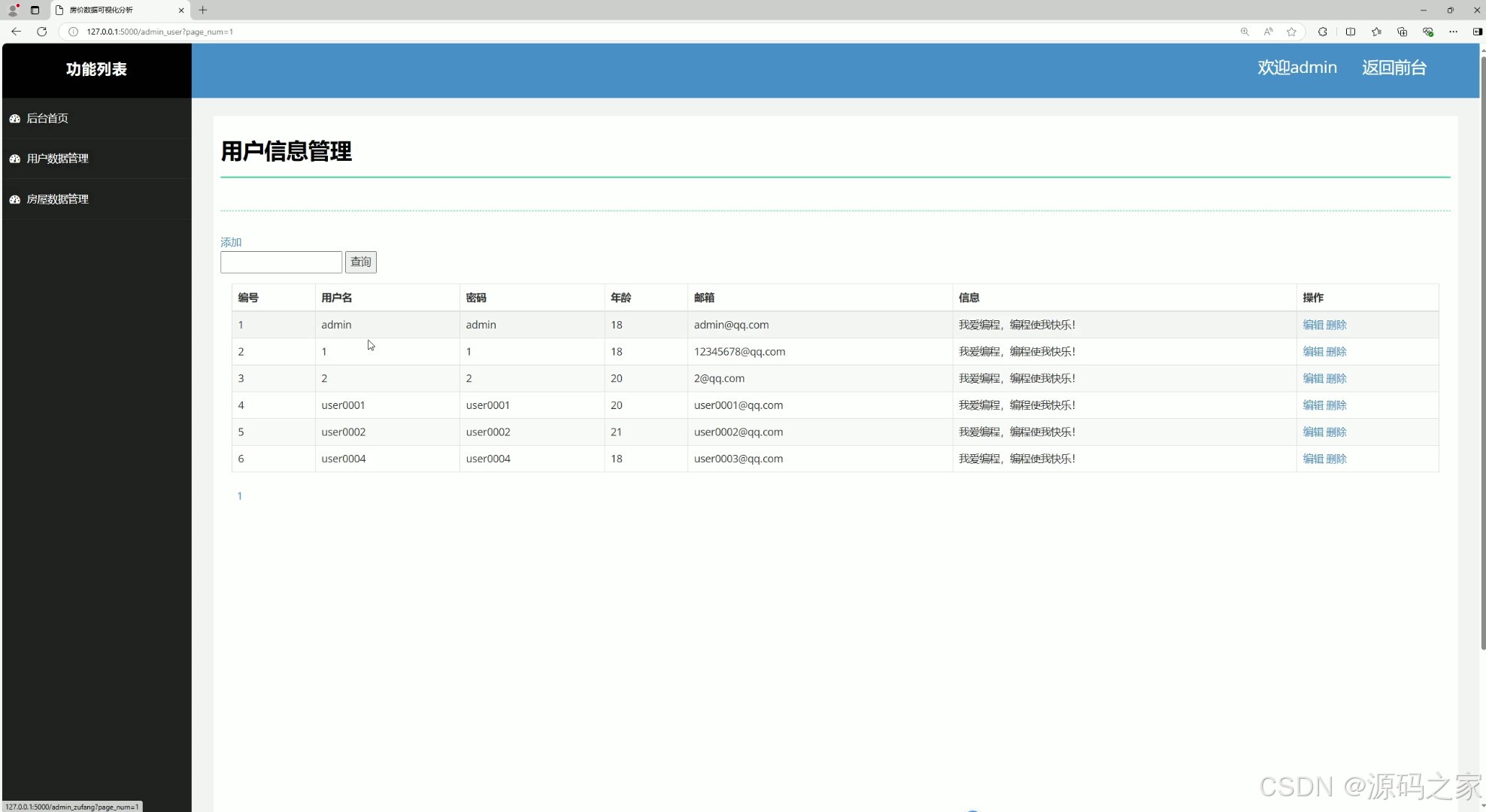
(13)注册登录
该页面是系统的登录界面,包含账号密码输入框、登录按钮及注册入口等功能模块,支持用户输入账号密码完成身份验证登录,也可跳转至注册页面创建新账号,是系统访问的身份验证入口。
(14)数据采集
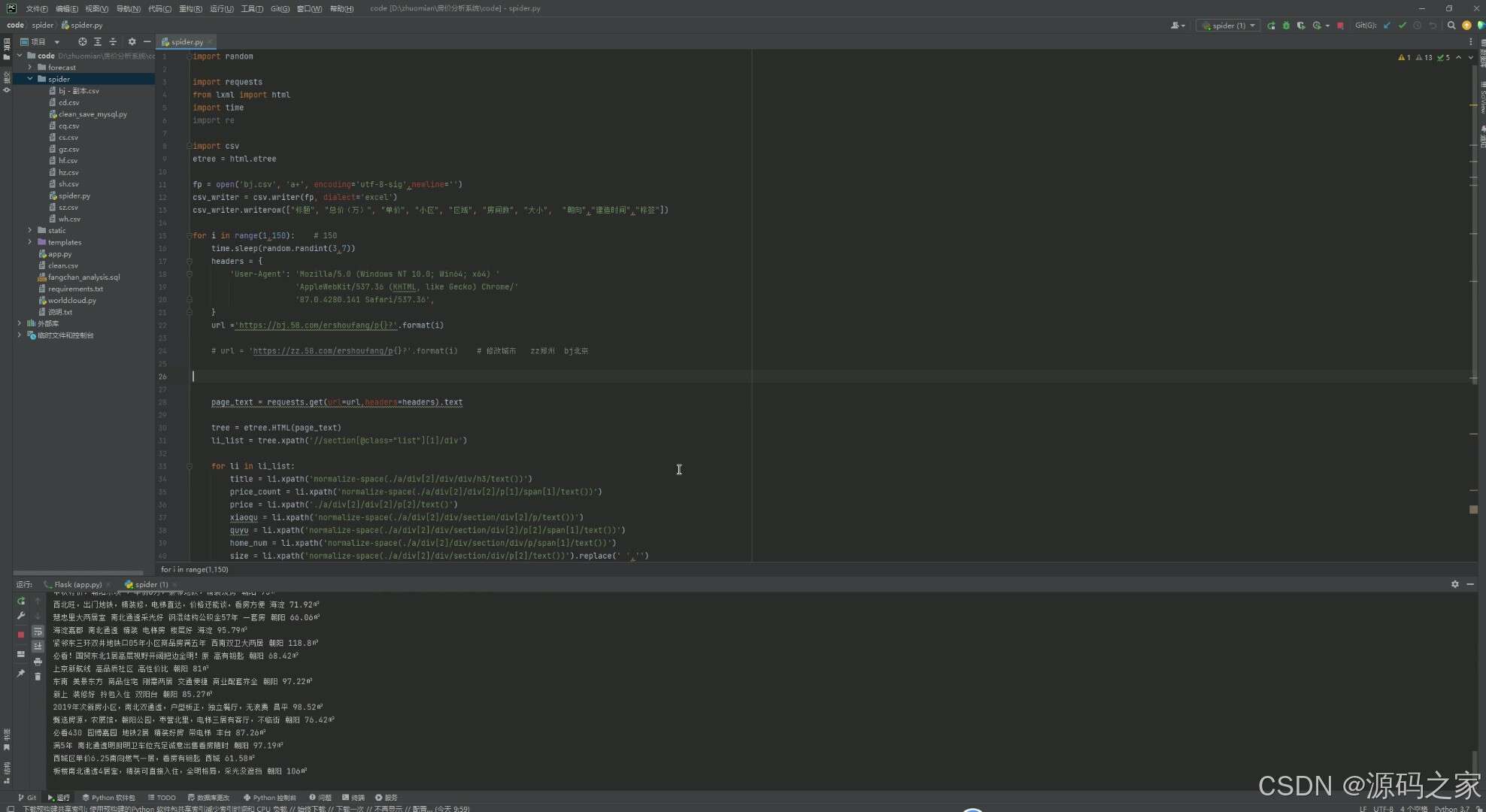
该页面展示了集成了数据爬取、数据处理与程序运行的开发环境界面,包含代码编辑区可编写与编辑爬虫代码,通过请求库与解析库实现数据爬取与提取,同时具备运行控制台展示爬取结果以及项目文件管理功能,完成数据从采集到初步呈现的流程。
3、项目说明
一、技术栈简要说明
本系统后端基于Python语言开发,采用Flask框架搭建Web应用层,负责处理HTTP请求与业务逻辑;使用MySQL数据库作为数据存储介质,管理房源核心数据与用户信息;数据采集环节采用requests爬虫实现58同城房产数据的定向抓取;数据可视化层面引入Echarts工具生成多维度交互图表;机器学习部分集成scikit-learn库中的CART分类回归树算法,构建房价预测模型。
二、功能模块详细介绍
• 用户注册登录模块
该模块作为系统访问入口,提供账号密码输入与登录验证功能,支持新用户通过注册页面创建账户。系统对输入信息进行基础校验,保障用户身份认证准确性与账户信息安全。
• 数据采集模块
模块基于requests爬虫技术,实现对58同城房产数据的自动化采集,涵盖房源价格、区域位置、房屋朝向、居室数量、建筑面积等核心字段,支持数据更新与增量采集,为系统分析提供实时数据源。
• 房屋数据列表展示模块
该模块以表格形式分页展示采集到的全部房源信息,包含房屋标题、所在区域、具体价格、户型结构、建筑面积、房屋朝向等详细字段,支持用户快速检索与浏览房源基础数据。
• 房源数量分析模块
模块对房源数据按区域进行分类统计,通过Echarts生成饼图直观展示各区域房源数量占比,帮助用户了解不同行政区域的房源供给密度与分布特征。
• 房屋均价分析模块
该模块计算各区域房屋的平均价格,通过柱状图展示区域间均价对比,辅助用户快速把握不同板块的价格水平差异,为购房区域选择提供数据参考。
• 房价热力地图展示模块
模块集成中国地图可视化能力,通过Echarts生成房价热力地图,以颜色深浅直观呈现全国各区域房价分布格局,帮助用户从宏观层面把握房价格局。
• 房价随时间变化分析模块
该模块提取房源历史价格数据,通过柱状图展示2000年至2024年房价的年度变化趋势,直观呈现房价长期波动规律与市场发展阶段特征。
• 词云图分析模块
模块对房源描述文本进行分词处理,统计关键词出现频率,利用Echarts生成词云图进行可视化展示,字号大小代表词频高低,直观呈现房源核心特征与市场关注热点。
• 房屋朝向分析模块
该模块对房屋朝向数据进行分类统计,通过饼图展示不同朝向房源数量占比,同时结合箱线图呈现各朝向对应的价格分布情况,辅助分析朝向对房源数量及房价的影响。
• 房屋居室分析模块
模块对不同居室数量进行分类统计,通过饼图展示一居、两居、三居等户型占比,同时结合箱线图呈现各居室类型对应的价格分布,揭示居室数量与房价关联规律。
• 房屋面积大小分析模块
该模块将房屋建筑面积划分为多个区间段,通过柱状图展示各面积区间内的房源数量分布,帮助用户把握市场房源面积结构特征与供给规律。
• 房屋数量折线图分析模块
模块提取历年房源数量数据,通过折线图展示房源供给的时间变化趋势,直观呈现市场房源数量的波动规律与增长态势。
• 房价预测模块
该模块基于scikit-learn库中的CART分类回归树算法,选取城市、区域、朝向、居室、面积等特征构建房价预测模型,用户输入房屋参数后系统返回预测价格,同时以折线图展示价格走势辅助决策。
• 房屋信息管理模块
模块为管理员提供房源数据维护功能,支持对房屋信息进行查询、添加、编辑、删除等操作,实现房源数据的高效管理与实时更新。
• 用户信息管理模块
该模块为管理员提供用户账户管理功能,支持对注册用户信息进行查询、添加、编辑、删除等操作,保障用户数据的规范管理与维护。
三、项目总结
本系统以58同城房产数据为核心,构建了一套集数据采集、存储、分析、预测与可视化于一体的综合房产数据平台。后端采用Python与Flask框架搭建稳定Web应用,MySQL保障房源与用户数据高效存储;数据采集环节通过requests爬虫实现自动化抓取,确保数据源实时可靠;可视化层面借助Echarts生成房源数量分布、均价对比、时序变化、词云图、朝向与居室分布等多维度图表,直观呈现房产市场特征。核心技术亮点在于集成scikit-learn机器学习库中的CART分类回归树算法,构建房价预测模型为用户提供精准参考。系统功能覆盖数据采集、列表展示、多维度分析、房价预测、后台管理等全流程环节,配备注册登录权限管理机制,满足普通用户查询分析与管理员数据维护的双重需求,为购房者、房产从业者提供数据支撑,助力理性决策与市场研判。
4、核心代码
# 房屋数量折线图
@app.route("/jobCity")
def jobCity():
sql = 'select * from part1'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
sj_list = []
zj_list = []
for item in list:
sj_list.append(item[0])
zj_list.append(item[1])
print(sj_list)
return render_template("jobCity.html", sj_list=sj_list, zj_list=zj_list, list=list)
# 指定区域房屋数量和区域均价
@app.route("/world")
def world():
sql = 'select * from part2 limit 20'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
qy_list = []
sl_list = []
mean = []
for item in list:
qy_list.append(item[0])
sl_list.append(item[1])
mean.append(item[2])
return render_template("world.html", mean=mean, qy_list=qy_list, sl_list=sl_list, list=list)
# 房价随时间变化
@app.route("/price")
def price():
sql = 'select * from part3'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
sj_list = []
mean = []
for item in list:
sj_list.append(item[0])
mean.append(float(item[1]))
print(mean)
return render_template("price.html", mean=mean, x_list=sj_list)
# 房屋大小分析 size
@app.route("/num")
def num():
# df = pd.read_csv('clean.csv')
df = pd.read_csv('clean.csv', encoding='utf-8')
# 删除id列和tags列,并在原地修改df
df.drop(columns=['id', 'tags'], inplace=True)
df['size'] = df['size'].astype(int)
res_dict = {
'200以上': 0,
'120到200': 0,
'100到120': 0,
'80到100': 0,
'60到80': 0,
'40到60': 0,
'40以下': 0
}
for item in list(df['size']):
if item > 200:
res_dict['200以上'] += 1
elif 200 > item >= 120:
res_dict['120到200'] += 1
elif 120 > item >= 100:
res_dict['100到120'] += 1
elif 100 > item >= 80:
res_dict['80到100'] += 1
elif 80 > item >= 60:
res_dict['60到80'] += 1
elif 60 > item >= 40:
res_dict['40到60'] += 1
elif item < 40:
res_dict['40以下'] += 1
x_list = []
y_list = []
for k, v in res_dict.items():
x_list.append(k)
y_list.append(v)
return render_template("num.html", x_list=x_list, y_list=y_list)
# 房型分析 home_num 房间数
@app.route("/time")
def time():
# df = pd.read_csv('clean.csv')
df = pd.read_csv('clean.csv', encoding='utf-8')
# 删除id列和tags列,并在原地修改df
df.drop(columns=['id', 'tags'], inplace=True)
v_list = list(df['home_num'].value_counts().sort_values(ascending=False))[:30]
k_list = list(df['home_num'].value_counts().sort_values(ascending=False).index)[:30]
result = []
for item in range(len(v_list)):
result.append((v_list[item], k_list[item]))
xiangxing = []
for n in k_list:
xiangxing.append(list(df[df['home_num'] == n]['price']))
return render_template("time.html", result=result, k_list=k_list, xiangxing=xiangxing)
# 朝向分析 chaoxiang
@app.route("/chaoxiang")
def chaoxiang():
# df = pd.read_csv('clean.csv')
df = pd.read_csv('clean.csv', encoding='utf-8')
# 删除id列和tags列,并在原地修改df
df.drop(columns=['id', 'tags'], inplace=True)
v_list = list(df['chaoxiang'].str.split(' ', expand=True)[0].value_counts())
k_list = list(df['chaoxiang'].str.split(' ', expand=True)[0].value_counts().index)
result = []
for item in range(len(v_list)):
result.append((v_list[item], k_list[item]))
xiangxing = []
for n in k_list:
xiangxing.append(list(df[df['chaoxiang'] == n]['price']))
return render_template("chaoxiang.html", result=result, k_list=k_list, xiangxing=xiangxing)
# 词云
@app.route("/worldCloud")
def worldCloud():
return render_template("worldCloud.html")
# 价格预测
@app.route("/group")
def group():
sql = 'select * from line'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
qy_list = []
mean = []
for item in list:
qy_list.append(item[1])
mean.append(item[2])
return render_template("group.html", k_list=qy_list, p_list=mean)
# 房产推荐
@app.route("/rec")
def rec():
uname = session['uname']
user1 = User.query.filter(User.username == uname)[0]
sql = 'select * from rec where userid=' + str(user1.id)
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
f_list = []
for f in list:
f_list.append(Fangwu.query.filter(Fangwu.id == f[2]).first())
print(f_list)
return render_template("rec.html", k_list=f_list)
# 后台房产添加api
@app.route("/admin_zufangaddapi", methods=['POST'])
def admin_zufangaddapi():
fangwuid = request.values.get("fangwuid")
title = request.values.get("title")
price_count = request.values.get("price_count")
price = request.values.get("price")
xiaoqu = request.values.get("xiaoqu")
quyu = request.values.get("quyu")
home_num = request.values.get("home_num")
size = request.values.get("size")
chaoxiang = request.values.get("chaoxiang")
jianzao = request.values.get("jianzao")
tags = request.values.get("tags")
result = Fangwu.query.filter(Fangwu.title == title)
if result.count():
print('error')
return json.dumps({"id": False})
try:
fangwu = Fangwu(title=title, price_count=price_count, size=size, chaoxiang=chaoxiang, home_num=home_num,
price=price, xiaoqu=xiaoqu,
quyu=quyu, jianzao=jianzao, tags=tags)
db.session.add(fangwu)
db.session.commit()
return json.dumps({"id": True})
except:
return json.dumps({"id": False})
# 后台房产修改
@app.route("/admin_zufangedit")
def admin_zufangedit():
room_id = request.args.get("room_id")
fangwu1 = Fangwu.query.filter(Fangwu.id == room_id)[0]
print(room_id)
return render_template("admin/admin_zufangedit.html", fangwu1=fangwu1)
@app.route("/admin_zufangeditapi", methods=['POST'])
def admin_zufangeditapi():
fangwuid = request.values.get("fangwuid")
title = request.values.get("title")
price_count = request.values.get("price_count")
price = request.values.get("price")
xiaoqu = request.values.get("xiaoqu")
quyu = request.values.get("quyu")
home_num = request.values.get("home_num")
size = request.values.get("size")
chaoxiang = request.values.get("chaoxiang")
jianzao = request.values.get("jianzao")
tags = request.values.get("tags")
fangwuid = int(fangwuid)
try:
fangwu1 = Fangwu.query.get(fangwuid)
print(fangwu1.title)
fangwu1.title = title
fangwu1.price_count = price_count
fangwu1.price = price
fangwu1.xiaoqu = xiaoqu
fangwu1.quyu = quyu
fangwu1.home_num = home_num
fangwu1.size = size
fangwu1.chaoxiang = chaoxiang
fangwu1.tags = tags
fangwu1.jianzao = jianzao
db.session.add(fangwu1)
db.session.commit()
return json.dumps({"id": True})
except:
return json.dumps({"id": False})
# 后台房产删除
@app.route("/admin_zufangdel")
def admin_zufangdel():
room_id = request.values.get("room_id")
try:
fangwu = Fangwu.query.get(room_id)
db.session.delete(fangwu)
db.session.commit()
return json.dumps({"id": True})
except:
return json.dumps({"id": False})
# 价格预测
@app.route('/calculate', methods=['POST'])
def calculate():
sql = 'select * from line'
cursor = conn.cursor()
cursor.execute(sql)
list = cursor.fetchall()
qy_list = []
mean = []
for item in list:
qy_list.append(item[1])
mean.append(item[2])
# 从前端接收数据
if request.form['city'] and request.form['area'] and request.form['chaoxiang'] and request.form['tags'] and \
request.form['yaer'] and request.form['num'] and request.form['size']:
city = int(request.form['city'])
area = int(request.form['area'])
chaoxiang = int(request.form['chaoxiang'])
tags = int(request.form['tags'])
year = int(request.form['yaer'])
num = int(request.form['num'])
size = int(request.form['size'])
# if area in [0, 1, 2, 3, 4, 5, 6]: # 区域字段
if 19 <= area <= 62:
# if area in [0, 1, 2, 3, 4, 5, 6]: # 区域字段
X = [[area, num, size, chaoxiang, year, tags, city]]
X = pd.DataFrame(X, columns=['quyu', 'home_num', 'size', 'chaoxiang', 'jianzao', 'tags', 'city'])
a = recommend(X)
result = f'预测结果为:{a} 元/每平方'
return render_template('group.html', result=result, k_list=qy_list, p_list=mean)
else:
result = f'区域选择错误'
return render_template('group.html', result=result, k_list=qy_list, p_list=mean)
else:
result = f'输入框不可为空'
return render_template('group.html', result=result, k_list=qy_list, p_list=mean)
# 决策树预测算法
def recommend(X):
dataX = pd.read_csv("./forecast/data.csv", index_col=0)
dataY = pd.read_csv("./forecast/target.csv", index_col=0)
trainX, testX, trainY, testY = train_test_split(dataX, dataY, test_size=0.3)
# 创建CART回归树
dtr = DecisionTreeRegressor(max_depth=13, min_impurity_decrease=0.02, min_samples_leaf=10)
# 拟合构造CART回归树
dtr.fit(trainX, trainY)
# 设置列名
X.columns = dataX.columns
# 将X的值转换为数值类型
X = X.astype(float)
a = float(str(dtr.predict(X))[1:-1])
a = '{:.2f}'.format(a)
return a
if __name__ == '__main__':
app.run(debug=True)
# db.create_all()
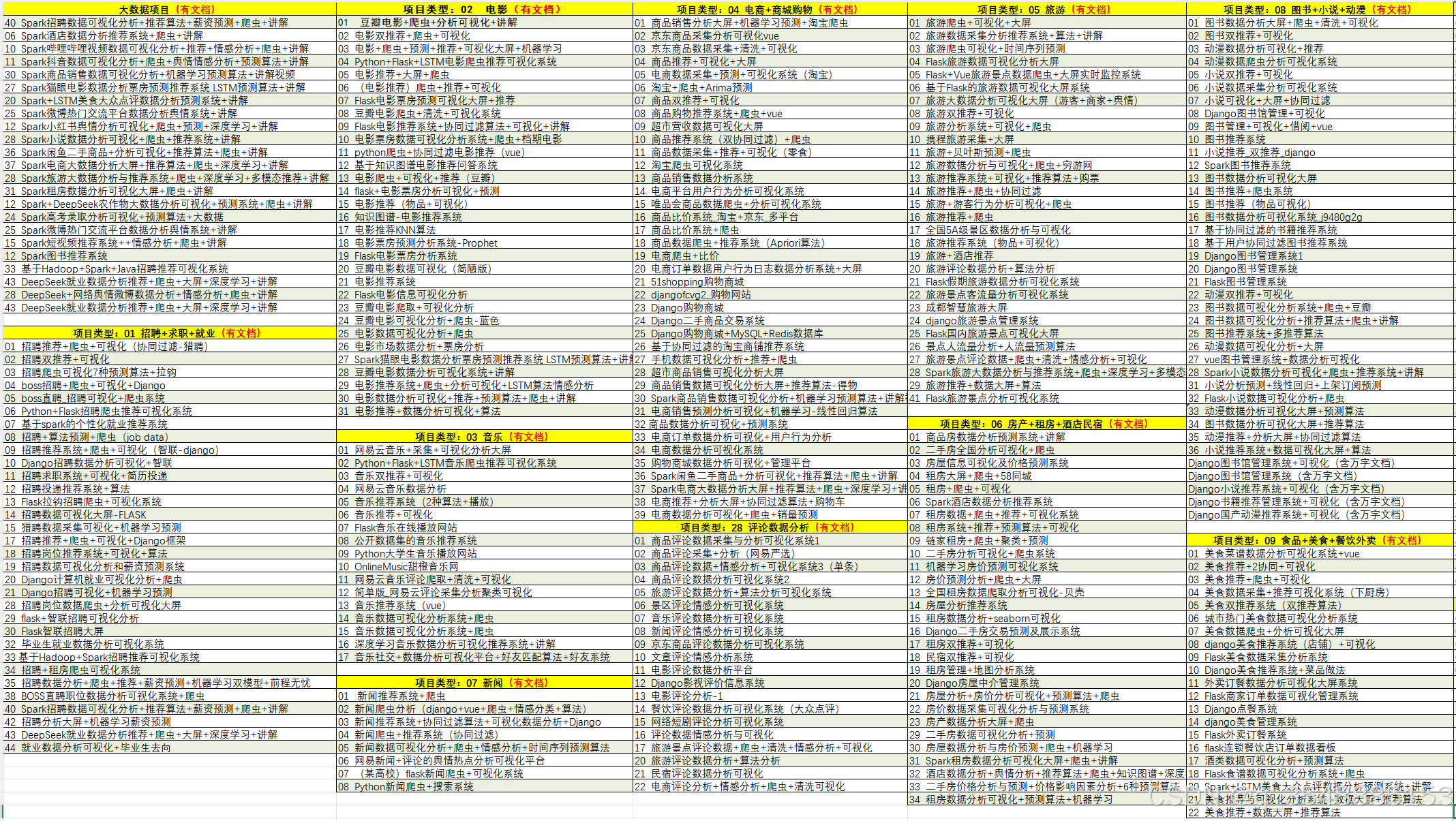
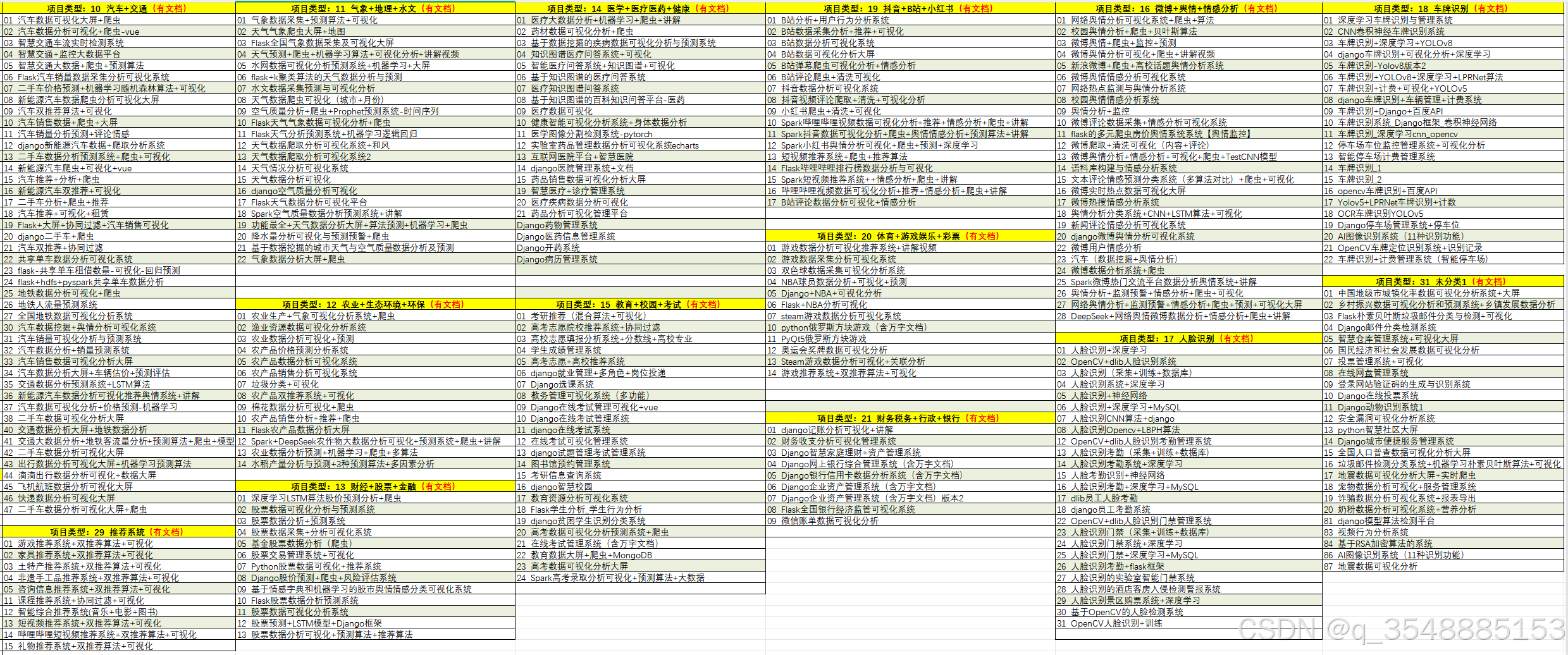
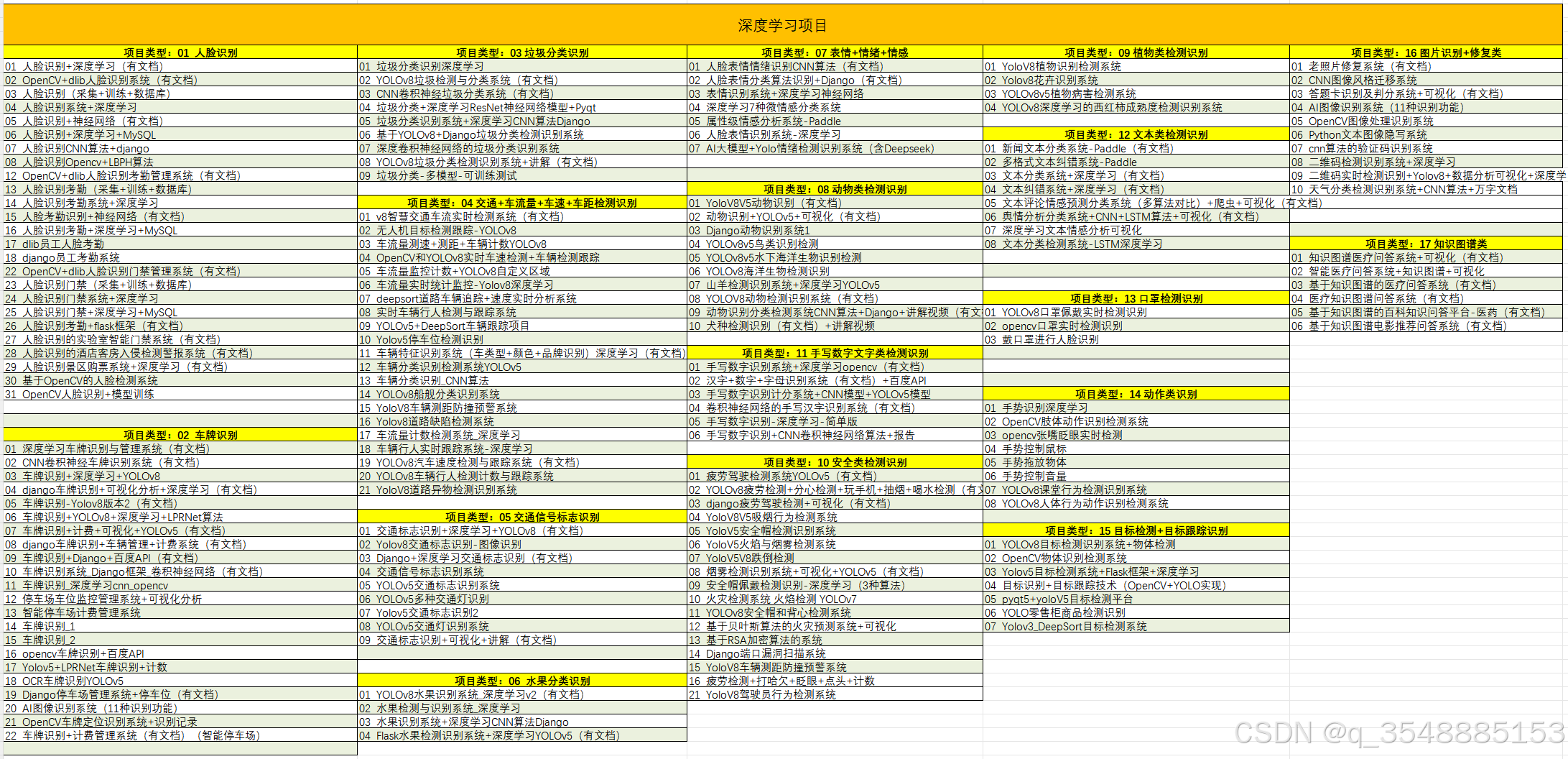
5、项目列表
6、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)