Claude Code 响应慢怎么办?提速的5个技巧
我测过。
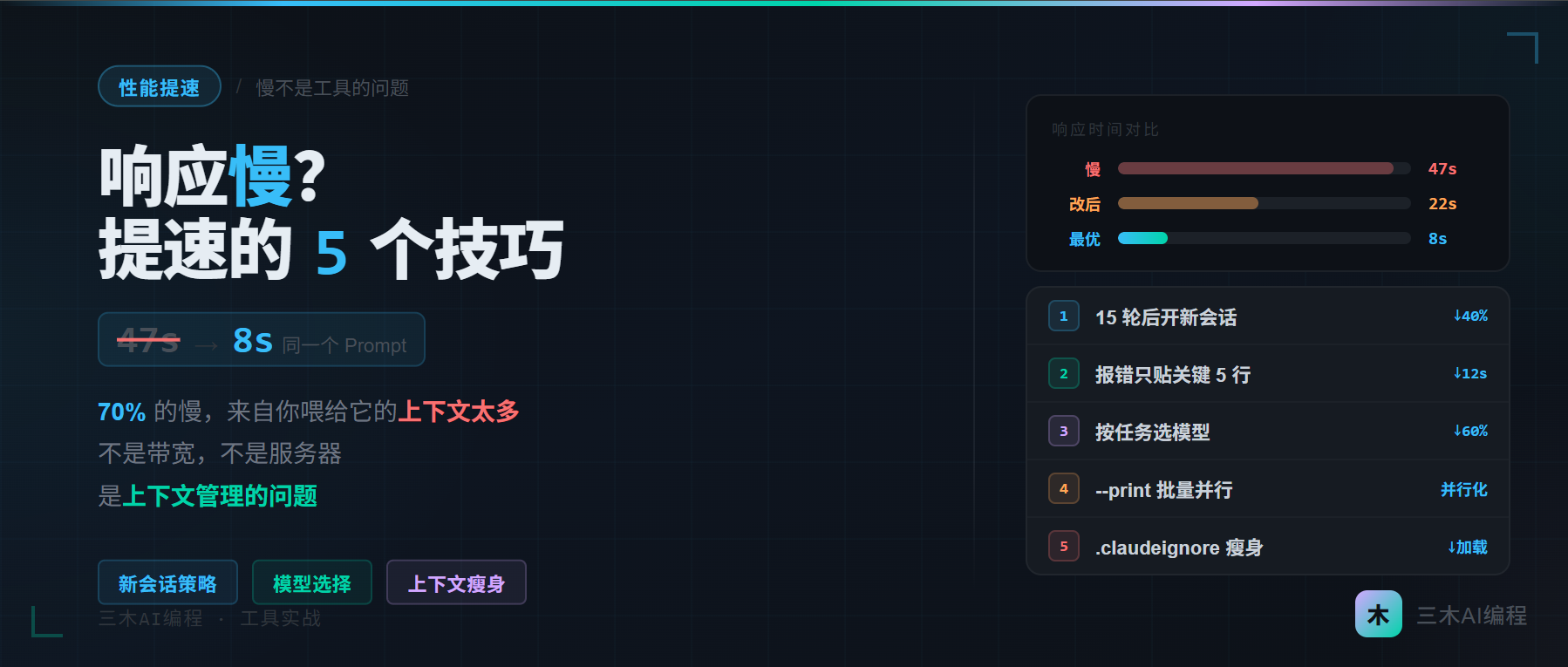
同样的 Prompt,发给它两次。一次 8 秒出结果,一次等了 47 秒。网络没动,VPN 没换,什么都没变。
后来我才搞清楚:Claude Code 的响应速度,70% 取决于你喂给它多少上下文。 不是带宽,不是服务器,是你自己。
慢,但你不知道慢在哪
用 Claude Code 开发,时间成本里有一块很隐蔽的损耗:等待。
不是那种"卡死不动"的等待,是那种"感觉快好了但就是没好"的等待。每次等个 30 到 60 秒,一天下来,可能积累了 40 分钟什么都没干。
我自己记录过一周的使用数据:在一个 Next.js 项目里,平均单次响应时间是 34 秒。其中有几次超过 90 秒。那几次发生的共同点,是我在一个对话里已经来回了超过 20 轮,而且每次都附带了完整的报错信息和代码片段。
说人话就是:对话越长、单次喂的内容越多,它就越慢。 不是偶然,是必然。
原因在于模型处理请求时,要先"消化"整个上下文窗口里的所有内容,才开始生成回答。上下文越大,消化时间越长。
这不是 Claude 独有的问题,是所有大语言模型的共性。但 Claude Code 因为会自动读入项目文件,上下文膨胀得特别快。
以下是我摸索出来的 5 个实际有效的方法。
技巧一:对话超过 15 轮,立刻开新会话
这是最有效、最反直觉的一条。
很多人以为,同一个对话里保留越多历史,Claude Code 越了解你的项目,回答越准确。
错。
超过一定长度,历史对话反而成了负担。它需要花更多算力处理那些可能已经没有参考价值的早期信息,而不是集中在你现在的问题上。
我的做法是:以任务为单位开会话,而不是以项目为单位。
做完认证模块,关掉,新开一个会话做支付模块。不要在同一个对话里跨越太多功能边界。
开新会话之前,花两分钟写一段"交接摘要"喂给它:
上下文:我在开发一个 SaaS 订阅工具,Next.js 14 + Prisma + Stripe。认证模块已完成,用 NextAuth v5,Session 里有 userId 和 subscriptionStatus 两个字段。
当前任务:接入 Stripe Checkout,用户点击升级按钮后跳转到 Stripe 支付页面,支付成功后更新数据库里的 subscription 状态。
相关文件:app/api/payment/create-checkout/route.ts(还没写),lib/stripe.ts(已有 Stripe client 初始化)
两分钟写这段,换来后续更快的响应和更准确的输出。这个账很合算。
技巧二:报错信息只贴关键部分,不要全量粘贴
这个坑我踩了很久才发现。
遇到报错,我之前的习惯是把整个 Terminal 输出全部复制进去——可能有 200 行。我以为信息越全越好。
实际上,大多数报错的关键信息就在前 10 行和最后 5 行。中间那 185 行是 stack trace,对找问题帮助不大,但会让上下文膨胀一大块。
正确做法:只贴错误类型、错误信息和第一条 at 指向。
比如这样:
Error: PrismaClientKnownRequestError
Invalid `prisma.subscription.create()` invocation
Foreign key constraint failed on the field: `userId`
at Object.request (/app/node_modules/@prisma/client/runtime/library.js:130:15)
后面那一百行 node_modules 的堆栈,删掉。它不需要看那些,它只需要知道:在哪个函数、什么错误、指向哪个字段。
这一个习惯,让我的单次响应时间平均缩短了 8 到 12 秒。
技巧三:用 --model 参数按任务选模型
这条是大多数教程不告诉你的。
Claude Code CLI 支持指定模型。不同任务用不同模型,速度差异显著。
# 快速任务:改一个函数、查一个语法——用速度更快的模型
claude --model claude-haiku-4-5-20251001 "帮我把这个函数改成 async/await 写法"
# 复杂任务:架构设计、全量代码审查——用能力更强的模型
claude --model claude-sonnet-4-6 "Review 整个 payment 模块的安全性"
说人话就是:杀鸡别用牛刀。 改个变量名、写个小工具函数,用 Haiku 够了,而且快得多。复杂的架构决策、需要跨文件理解的 bug,再上 Sonnet。
这个参数我之前完全不知道,一律用默认模型,结果每次改个两行代码都在等半分钟。
在 CLAUDE.md 里也可以固定默认行为,但建议保持灵活——根据任务类型手动指定更合适。
技巧四:--print 模式处理批量独立任务
如果你有一批互相不依赖的小任务,不要一个个在交互模式里等,用 --print 参数批量处理。
这个场景在出海开发里很常见:比如你需要把十个组件里的硬编码文案改成 i18n key。
写一个 shell 脚本:
#!/bin/bash
# 这段脚本遍历 components 目录,对每个文件单独调用 Claude Code
# 每次调用都是独立的会话,互不干扰,避免上下文堆积
components=(
"components/features/PricingCard.tsx"
"components/features/TrialBanner.tsx"
"components/features/UpgradeModal.tsx"
)
for component in "${components[@]}"; do
echo "Processing: $component"
claude --print "把 $component 里所有硬编码的英文文案替换为 next-intl 的 t() 调用,key 格式用 组件名.功能.文案,同时在 messages/en.json 里添加对应的 key-value,保持原有文案内容不变" \
--allowedTools "Edit,Write"
echo "Done: $component"
done
每个文件独立一个 Claude Code 调用,上下文始终干净,速度稳定。
细节:
--allowedTools让它可以直接写文件,不需要你确认。适合你信任输出结果的重复性任务。对于不确定的任务,去掉--allowedTools让它只输出建议,你来决定要不要执行。
技巧五:.claudeignore 排除无关文件
Claude Code 在读取项目上下文时,会扫描目录结构。如果你的项目里有大量无关文件——比如 node_modules(它应该自动忽略,但有时候不够彻底)、构建产物、大量的测试快照文件——都会拖慢上下文加载。
在项目根目录创建 .claudeignore:
# 依赖和构建产物
node_modules/
.next/
dist/
build/
out/
# 测试快照(体积大但对 Code 无帮助)
**/__snapshots__/
**/*.snap
# 日志文件
*.log
logs/
# 本地环境配置(里面也不该有密钥)
.env.local
.env.*.local
# 大型静态资源
public/videos/
public/images/*.psd
格式和 .gitignore 完全一样,直接复用也行,但根据你的项目结构做减法。
说人话就是:你不想让它看的文件,写进这里,它就不会把这些内容算进上下文。
这个文件存在的事实,Claude Code 的官方文档提了一句就没了。我是在源码里翻到这个逻辑才知道它支持这个特性。
踩坑环节
坑一:以为切节点能解决慢的问题,折腾了一下午
响应慢的那段时间,我把节点换了四五个,香港、日本、美西挨个试,感觉没什么区别。
后来用 claude /status 看了一下会话状态,发现我那个对话的上下文已经接近 150K token 了——基本上是我把项目里所有文件都拖进去问过一遍,全积累在那了。
开了个新会话,写了两句交接说明,响应立刻回到了正常水平。
解决方案: 慢的时候先看上下文大小,不要先怀疑网络。/status 命令或者看 CLI 的 token 统计,找到真正的瓶颈再对症下药。
坑二:把 .claudeignore 写错了位置,完全不生效
我第一次试 .claudeignore 的时候,把它放在了 src/ 目录下。跑了一圈发现一点用没有,node_modules 还是被扫描进去了。
研究了半小时,发现它必须放在 Claude Code 启动时的工作目录,也就是你执行 claude 命令的那个目录,通常是项目根目录。
解决方案: 确认 .claudeignore 和 package.json 在同一层级。可以用 ls -la | grep claude 验证文件是否存在于正确位置。
总结
Claude Code 慢,本质是上下文管理的问题,不是工具的问题。你给它的信息越精准,它越快;你给它的信息越杂,它越慢。
五个技巧里,优先级顺序是:新开会话 > 精简报错 > 排除无关文件 > 按任务选模型 > 批量并行。前三个能解决 80% 的慢问题。
问你一个具体的问题: 你现在用 Claude Code 时,平均一个对话会跑多少轮才结束——是做完一个功能点就开新的,还是同一个会话从项目开始一直用到上线?如果是后者,你觉得你的响应速度有没有随着对话变长而明显下降?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)