人工智能与数据驱动方法加速金属材料设计与应用
人工智能在材料设计中的应用
人工智能通过机器学习算法分析海量材料数据,识别成分-结构-性能之间的复杂关系。深度学习模型如卷积神经网络(CNN)可处理材料微观结构图像,图神经网络(GNN)适合解析原子间键合关系。
材料基因工程结合AI技术,实现高通量计算与实验数据的自动关联。主动学习算法能优化实验设计,减少传统试错法的资源消耗。生成对抗网络(GANs)可逆向设计满足特定性能需求的新材料。
数据驱动的材料发现流程
建立标准化材料数据库是关键环节,包含晶体结构、相图、力学性能等多维度数据。数据清洗需要处理缺失值和不一致性,特征工程涉及提取晶格常数、电子密度等关键描述符。
集成多尺度模拟数据与实验数据时,需注意不同来源的数据偏差。迁移学习可解决小样本问题,将已有材料体系的知识迁移到新体系。贝叶斯优化等方法能高效搜索广阔的材料参数空间。
典型应用案例
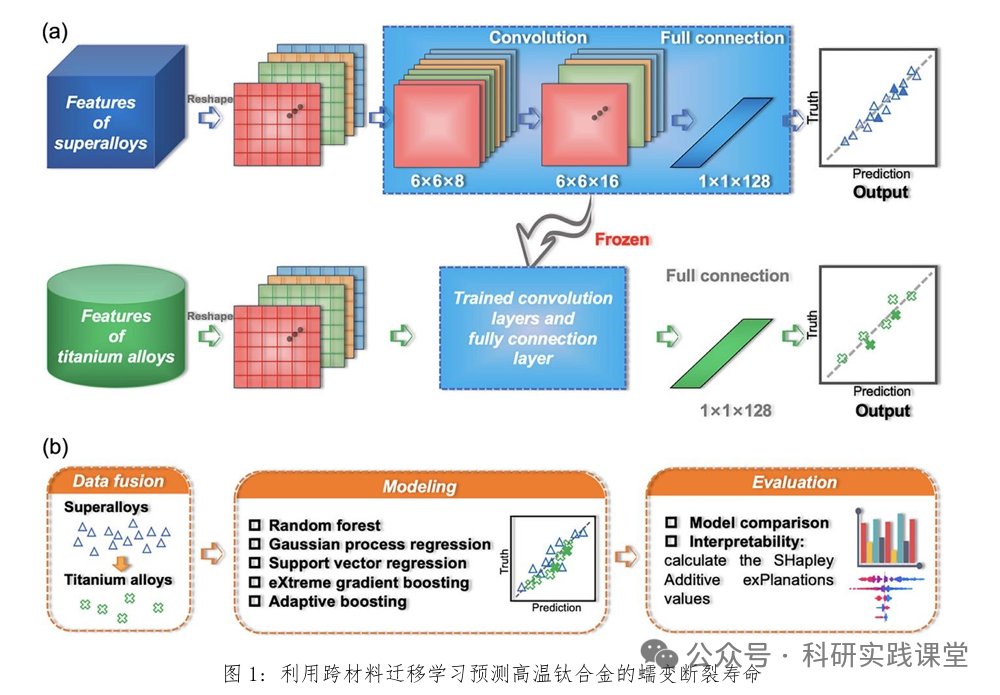
在高温合金开发中,随机森林算法预测了Ni-Co-Cr体系相稳定性,准确率达92%。强化学习已用于优化增材制造工艺参数,将钛合金疲劳寿命提升30%。
自然语言处理技术挖掘了数百万篇文献,发现潜在的超导体候选材料。符号回归发现了材料性能的新解析表达式,比传统经验公式更具物理可解释性。
技术挑战与解决方案
数据质量问题通过开发自动标定实验装置改善。模型可解释性不足的问题,可采用SHAP值等解释性AI方法。领域知识嵌入网络架构,如将晶体对称性约束加入神经网络。
跨机构数据共享需要区块链等安全技术。小数据场景下,物理信息神经网络(PINNs)结合第一性原理计算能提升预测可靠性。持续学习机制使模型能适应新材料体系的发现。
未来发展方向
自主材料实验室(Self-driving Lab)整合机器人实验、实时表征和AI决策。量子机器学习将处理更复杂的电子结构问题。多智能体系统可能协调不同尺度的材料设计任务。
数字孪生技术实现材料全生命周期管理。联邦学习促进跨机构协作同时保护数据隐私。因果推理方法将区分材料性能的真实影响因素与虚假关联。

|
第一部分 Python与材料科学数据分析基础 |
1. 理论内容: 1.1. 数据驱动材料设计的范式革命与核心流程 1.2. Python材料数据科学生态系统 1.3. 材料数据库与数据标准化概述 2. 实践内容:从环境搭建到数据分析 ◇ Case 1:Python科学计算环境搭建与核心库(NumPy, Pandas等) ◇ Case 2:准备或数据库下载特定材料数据 □ 高温合金体系,获取其原子结构、成分、相溶解温度等基本信息 □ 钛合金体系,重点关注蠕变性能和拉伸力学性能 □ 下载/准备钛合金或高温合金的数据,并将结果保存为DataFrame ◇ Case 3:数据清洗、探索与可视化分析 |
|
|
第二部分 描述符工程与特征优化 |
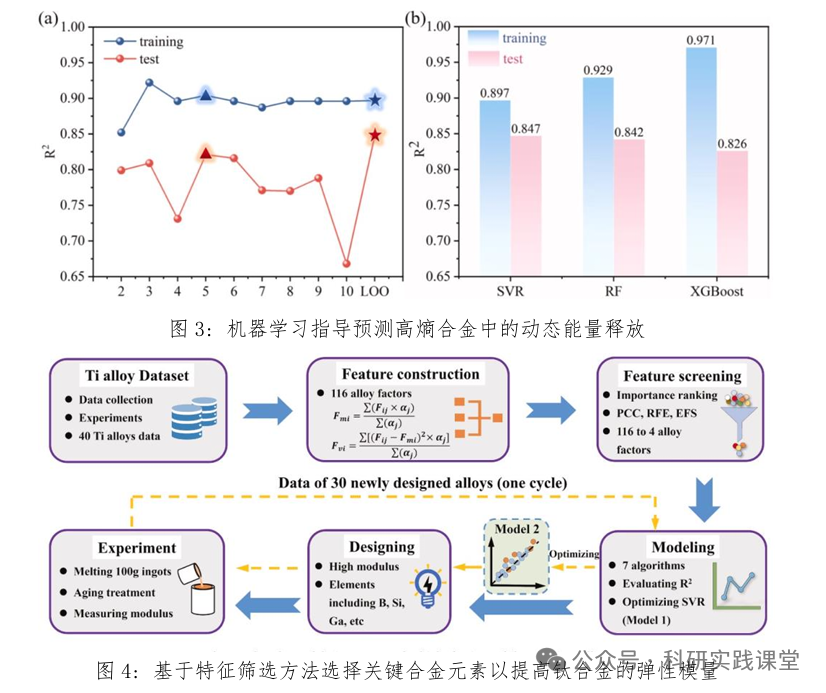
1. 理论内容: 1.1. 材料描述符的核心概念:如何数字化表征材料 1.2. 成分描述符、工艺描述符、晶体结构描述符与电子结构描述符详解 1.3. 特征选择、降维与特征重要性分析方法及原理 2. 实践内容:从生成描述符到优化特征空间 ◇ Case 1:使用Matminer批量生成多元化描述符 □ 为钛合金体系生成描述符 □ 为高温合金体系生成描述符 □ 获得包含原始材料信息和数十至上百个描述符列的DataFrame ◇ Case 2:无监督学习与数据可视化 □ 数据预处理: 对生成的大量描述符进行标准化,确保处于同一量纲 □ 主成分分析:对钛合金/高温合金体系描述符数据进行PCA分析 □ t-SNE可视化:使用t-SNE对钛合金体系/高温合金体系进行可视化 ◇ Case 3:特征选择与优化 □ 过滤法:计算描述符与目标性能的相关系数 □ 随机森林或其他回归模型进行训练。 以“预测钛合金的蠕变断裂寿命或其他性能”为例,分析模型哪些描述符最为重要。 □ 递归特征消除:使用RFECV工具,自动确定最佳特征数量。 |
|
|
第三部分 经典与集成机器学习算法 |
1. 理论内容: 1.1. 监督学习的基本框架与材料数据的建模流程 1.2. 经典机器学习算法的核心思想与比较 1.3. 集成学习方法及其在复杂材料体系中的优势 1.4. 模型评估、误差分析与模型选择策略 2. 实践内容——从基础建模到集成算法应用 ◇ Case 1:基于经典算法的材料性能预测入门实践 □ 使用给定合金属性数据集(如晶体结构/力学性能 - 元素特征数据)建立初始化线性回归、支持向量机回归、决策树回归/分类器等模型 □ 完成训练–测试流程,可视化预测误差 ◇ Case 2:超参数调优实战:使用交叉验证和自动化搜索工具来寻找模型的最佳超参数组合 ◇ Case 3:集成模型在复杂材料任务中的应用与解释 □ 针对合金力学性能等,分别训练基于随机森林、GBDT等性能预测模型,调整主要超参数,比较不同集成模型的预测精度与训练效率 □ 模型解释性:使用SHAP库,对合金力学性能预测模型进行分析 |
|
|
第四部分 主动学习与多目标优化 |
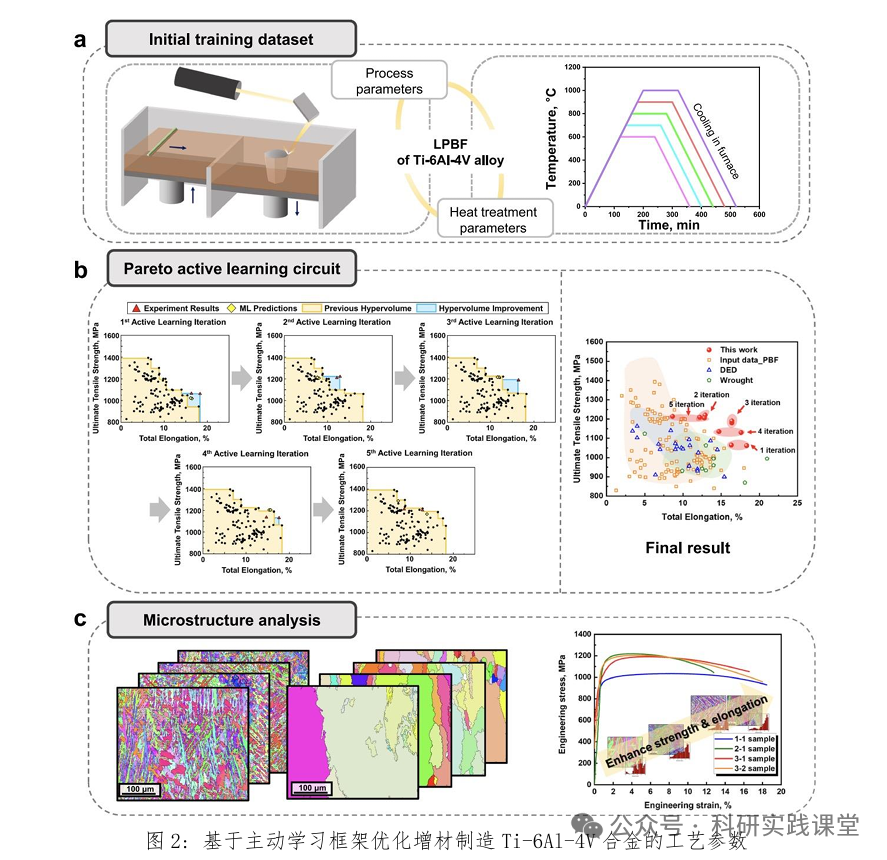
1. 理论内容: 1.1. 材料研发的瓶颈与主动学习的核心 1.2. 主动学习优化框架:建模与决策 1.3. 单目标优化与多目标优化介绍 2. 实践内容: ◇ Case 1:在一个简单一维函数上实现主动学习循环,理解其工作原理 ◇ Case 2:综合案例—钛合金增材制造工艺参数优化 □ 问题定义 □ 构建初始代理模型 □ 设计主动学习循环 □ 执行循环,绘制每一轮中发现的最佳性能的进化图 □ 循环结束后,分析最终推荐出的增材制造工艺参数 论文实例复现与解读: 1.Active learning framework to optimize process parameters for additive-manufactured Ti-6Al-4V with high strength and ductility. Nature Communication, 2025: 16: 931. |
|
|
第五部分 “灰箱”模型与可解释AI |
1. 理论内容: 1.1. “灰箱”模型的核心思想与优势 1.2. 物理信息神经网络核心原理与应用 1.3. 符号回归 1.4. 模型可解释性技术(全局与局部解释、SHAP 理论) 2. 实践内容——构建与解读下一代AI模型(结合相关论文) ◇ Case 1:物理约束神经网络实战 ◇ Case 2:符号回归发现新材料规律 □ 输入系统或材料相关的多维数据,运行符号回归寻找关键描述符 □ 对发现的公式进行合理性评估,判断其是否具有实际解释意义 □ 运用SHAP工具解读一个高性能集成学习模型,获得材料设计指南 □ 全局解释:计算并绘制SHAP特征重要性条形图,识别出影响合金性能的最关键描述符,绘制SHAP摘要图,观察每个描述符与目标性能的单调性或非线性关系 □ 局部解释:选择一个模型预测为超高力学性能的特定合金成分,生成该样本的SHAP力力图,直观展示描述符(特征) |
|
6.
部分案例图展示

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)