8.llamafactory-webui难点参数理论
·
一、LLaMA-Factory WebUI各功能介绍
- 傻瓜式训练界面:提供主流模型的简易操作界面,通过拖拉拽方式完成配置,大幅降低使用门槛
- 多样化训练配置:支持多种量化模式(如4bit/8bit等)和加速策略选择,可根据硬件条件灵活调整
- 训练过程可视化:实时展示训练阶段的各项指标变化曲线,便于监控模型训练状态
1. 简易界面
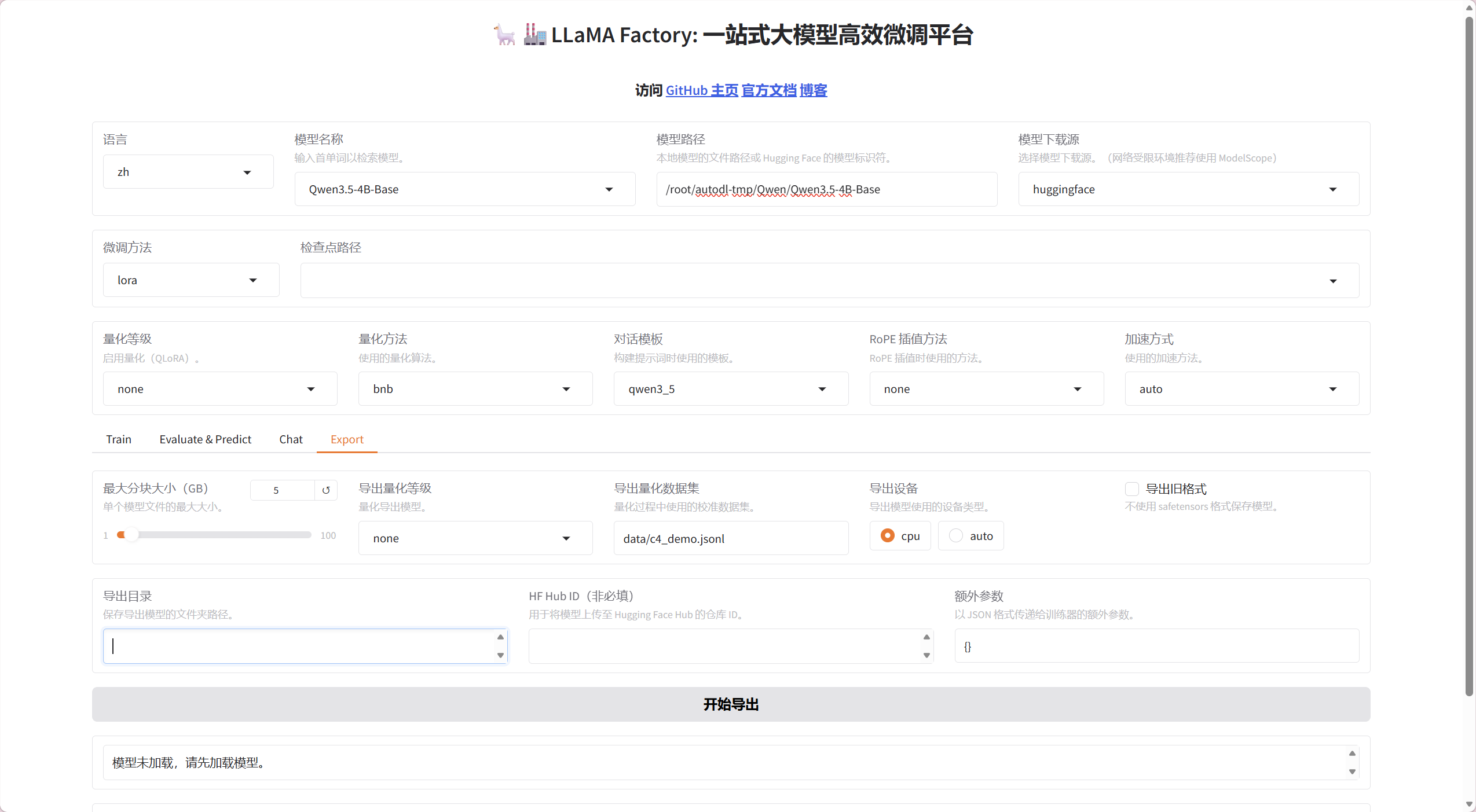
- 参数配置方式:采用表单式交互设计,所有训练参数(学习率、批次大小等)均可通过下拉菜单或输入框直接调整
- 核心训练参数:
- 模型选择:支持100+主流LLM模型(如Qwen3-4B等)
- 微调方法:提供LoRA等适配器选择
- 量化设置:包含none/half等精度选项
- 训练阶段:支持完整训练/预测/导出等模式切换
2. 实践操作
- 标准操作流程:
- 选择基础模型(如Qwen3-4B-Base)
- 加载默认数据集
- 配置SFT微调参数
- 启动训练并监控指标
- 功能限制说明:
- 仅支持单机多卡训练,不提供分布式训练功能
- WebUI无法直接实现多机多卡配置
- 训练产物管理:
- 自动按日期保存检查点
- 保留完整训练日志和配置
- 支持训练适配器与主干模型的合并导出
二、调参难点理论介绍
1. 量化类型选择
- BitsAndBytes(bnb):
- 原理: 训练后量化,通过最小化量化误差寻找最优缩放因子和零点,可集成到训练中(QLoRA)
- 优点: 精度保持最好,成熟稳定,社区支持好,支持量化训练(QLoRA)
- 缺点: 量化过程较慢(需少量数据校准),类比"专业厨师精心准备食材"
- 流程: 训练后量化/QLoRA微调→量化模型→推理
- 适用: 对精度要求高或需量化微调的场景
- HQQ(Half-Quadratic Quantization):
- 原理: 数据无关量化,使用半二次规划理论,无需输入数据即可计算最优参数
- 优点: 速度极快(秒级量化),免校准,简单易用,精度优秀
- 缺点: 仅支持推理,不能用于训练,生态工具链较新
- 流程: 原模型→HQQ量化→推理
- 适用: 快速尝鲜和部署推理的场景,类比"微波炉加热"
- EETQ(NVIDIA):
- 原理: NVIDIA推出的硬件感知推理运行时库,专为GPU优化
- 优点: 在NVIDIA GPU上推理效率最高,延迟最低
- 缺点: 仅支持NVIDIA GPU,需先用其他工具量化
- 流程: 原模型→(用bnb/HQQ量化)→转EETQ格式→GPU推理
- 适用: 企业级生产环境,类比"高速公路VIP通道"
2. 训练阶段选择
- Supervised Fine-Tuning:
- 特点: 使用QA格式数据集进行有监督微调
- 数据格式: 必须包含问题和答案对
- Reward Modeling:
- 作用: 训练奖励模型评估输出质量
- 机制: 驱动强化学习模型向高分参数方向调整
- 目标: 使模型输出与人类偏好对齐
- 预训练(Pre-Training):
- 特点: 仅需纯文本数据(text字段)
- 区别: 不同于微调需要QA格式
3. 学习率调节器
- Warmup机制:
- 目的: 防止初始阶段参数调整过大导致模型偏离
- 实现: 学习率从0开始逐步增加到正常水平(如500步)
- constant(常数):
- 特点: 全程保持固定学习率
- 缺点: 实际训练中很少使用
- linear(线性):
- 特点: Warmup后线性递减到0
- 优势: 简单可靠,是微调任务默认选择
- cosine(余弦):
- 特点: Warmup后按余弦曲线平滑下降
- 优势: 适合长时训练,有助于收敛到更优解
- cosine with restarts:
- 特点: 周期性重启学习率
- 优势: 帮助跳出局部最优解
- polynomial(多项式):
- 特点: 按多项式函数下降,可调power参数
- 优势: 提供比线性更灵活的下降方式
4. RoPE插值方法
- none(无插值):
- 适用: 短文本任务(如分类)
- 优势: 在模型预设长度内保持最佳保真度
- linear(线性插值):
- 原理: 按比例缩小超出训练长度的位置索引(如pos=pos/scale)
- 问题: 长序列末端位置编码高度拥挤(如10000/3和10001/3差异极小)
- 适用: 快速测试和低重要性长上下文场景
- dynamic(动态插值):
- 原理: 动态调整缩放因子,远距离缩放多,近距离缩放少
- 优势: 显著优于线性插值,免训练即可使用
- 适用: 需要直接扩展上下文(如8k→16k)的首选方案
- yarn:
- 特点: 引入温度缩放和注意力矩阵修正
- 优势: 支持超长上下文(128k+),性能衰减最小
- 要求: 通常需结合少量微调
- 适用: 追求极致长文本性能的场景
5. 加速方式
- auto:
- 特点: 自动选择可用加速方法
- flashattn2:
- 原理: 优化显存与缓存间数据搬运
- 优势: 显著加速注意力计算,尤其擅长长序列
- unsloth:
- 特点: 重写LoRA/QLoRA底层内核
- 优势: 单机单卡下显存占用低、速度快
- 适用: 目前最高效的微调加速方案
- liger_kernel:
- 现状: 目前基本不使用
三、知识小结
|
知识点 |
核心内容 |
考试重点/易混淆点 |
难度系数 |
|
量化类型选择 |
bitsandbytes(训练中/后量化,需少量数据校准)、HQQ(无数据依赖,自动计算最优参数)、ETQ(仅限NVIDIA GPU,推理速度最快) |
bitsandbytes vs HQQ(数据依赖差异) ETQ的硬件限制 |
⭐⭐⭐ |
|
训练阶段类型 |
SFT(监督微调)、Reward Modeling(奖励模型训练)、PPO/DPO/KTO(强化学习)、Pretrain(预训练,需纯文本数据) |
预训练与微调的数据格式差异(text vs QA) |
⭐⭐ |
|
学习率调节器 |
Warmup(启动阶段递增)、线性衰减/余弦衰减(收敛阶段递减)、Constant(固定值,不推荐) |
不同衰减策略的适用场景(如余弦衰减适合平滑收敛) |
⭐⭐⭐⭐ |
|
RoPE插值方法 |
无插值(短文本保真)、线性插值(长文本末端编码拥挤)、动态插值(自适应缩放)、YaRN(超长文本优化) |
线性插值的位置编码敏感度问题 |
⭐⭐⭐⭐ |
|
加速方法 |
Flash Attention 2(显存优化)、Auto(自动选择)、On-Sloss量化(单卡高效微调,优化LoRA内核) |
On-Sloss对LoRA微调的专项优化 |
⭐⭐⭐ |
|
Web UI功能 |
拖拉拽式操作、单机单卡支持、训练指标可视化、模型合并输出、在线对话评估 |
多机多卡训练的局限性 |
⭐⭐ |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)