7.llamafactory面板配置与训练推理
·
一、LLaMA Factory面板配置
1. 服务器连接配置
1)本地端口映射
- 端口映射:通过ssh命令(autodl那里)建立本地与服务器的端口映射,使本地可通过localhost:6006访问Web UI
- 注意事项:必须正确配置Power Shell设置才能成功连接服务器
2. 模型参数配置
1)模型路径设置
- 自动下载:不指定路径时,模型会在执行训练代码时自动从Hugging Face下载
- 本地路径:已下载模型需填写完整路径,如/root/autodl-tmp/Qwen/Qwen3-4B-Base
- ls
- cd Qwen
- cd Qwen3.5-7B-Base
- ls
- pwd
- 可查看路径

- 匹配原则:模型名称必须与路径中的模型名称严格对应

2)检查点路径
- 作用:用于增量训练时加载之前训练保存的模型检查点
- 使用场景:当需要在已有训练基础上继续微调时配置
3)量化等级选择
- QLoRA微调:需选择4bit或8bit量化
- LoRA微调:直接选择none(不量化)
- 推荐设置:默认使用bnb(BitsAndBytes)量化方法
4)对话模板配置
- 重要性:确保模型正确区分用户输入和助手回复
- 版本匹配:
- Qwen1/2选择"qwen"模板
- Qwen3必须选择"qwen3"模板
- Base模型:可选择default模板(不影响训练效果)
- 插值:none
- 加速方式: auto

3. 训练参数配置
1)梯度范数限制
- 作用原理:通过梯度裁剪防止异常数据导致参数更新过大
- 典型值:默认1.0,强化学习中常用更小的值(如0.2)保持稳定
- 数学意义:当梯度超过阈值时按比例缩小,公式为
gclipped=g⋅threshold∣∣g∣∣g_{clipped} = g \cdot \frac{threshold}{||g||}gclipped=g⋅∣∣g∣∣threshold
2)计算类型选择
- fp32:全精度训练,显存占用大但精度最高
- fp16:
- 半精度训练,计算快但容易梯度消失,然后导致训练失败
- 取值范围小(指数位少)
- 计算容易溢出
- bf16:
- 最佳平衡方案(指数位多,小数位少)
- 取值范围与fp32相同
- Volta架构GPU不支持
3)截断长度设置
- 定义:输入序列分词后的最大长度
- 典型值:2048(适合大多数情况)
- 调整原则:根据实际文本长度需求设置
4)批处理大小
- 作用:每个GPU处理的样本数
- 设置建议:显存充足时可增大(如8)加速训练
5)梯度累积
- 原理:多个batch梯度累加后统一更新
- 应用场景:显存不足时模拟更大batch size
- 计算公式:等效batch size = 实际batch size × 累积步数
4. 输出目录配置
- 功能:保存训练生成的模型权重和日志
- 路径示例:train_2025-09-04-20-41-39

- 包含内容:checkpoints、训练曲线、配置文件等
5. 参数保存功能
- 配置文件:保存为.yaml格式(如2025-09-04-20-41-39.yaml)
- 用途:方便复现实验或继续中断的训练
- 加载方式:通过"载入训练参数"功能读取
二、数据集选择
- 数据集类型: 可选择identity数据集进行训练,该数据集位于data目录下
- 训练方式: 采用监督微调(Supervised Fine-Tuning)方式
- 数据路径: 数据文件路径为/root/autodl-tmp/LLaMA-Factory/data/identity.json
- 在autodl另外开一个终端
- cd autodl-tmp
- ls
- cd LLaMa-Factory
- ls
- cd data
- ls
- pwd
- 在data里面增加数据集就可以在web UI里面找到数据集的目录
三、训练启动
1. 参数设置
- 基础参数:
- 学习率:5e-5
- 训练轮数: 3轮
- 最大梯度范数: 1.0
- 最大样本数: 10000
- 计算配置:
- 计算类型: fp32(不使用混合精度训练)
- 截断长度: 2048
- 批处理大小: 8
- 梯度累积步数: 4
- 优化器:
- 使用AdamW优化器
- 学习率调节器: cosine

2. 高级设置
- 量化方法: 使用QLoRA量化算法
- LoRA设置: 采用LoRA参数微调方式
- 加速配置:
- 使用DeepSpeed加速
- DeepSpeed stage: 1
- 使用offload技术减少显存占用
- 设备信息:
- 可用显存: 0GB(需通过后台查看实际使用情况)
3. 训练监控
- 常见问题:
- 可能出现async_io库缺失警告
- 需要检查torch版本兼容性(当前2.5可能不兼容)
- 建议启用混合精度训练以提高效率
- 运行状态:
- 可通过Web UI监控训练进度(http://0.0.0.0:6006)
- 后台日志会显示数据集加载和参数初始化过程
四、训练参数配置
1. epoch设置
- 训练轮数:设置为3个epoch,每个epoch会完整遍历训练数据集一次
- 批量处理:瞬时批次大小为8,通过梯度累积达到总批次大小64(累积步数=8)
- 优化步骤:总优化步骤为6步,对应3个epoch在91个样本上的训练过程
- 参数规模:可训练参数16,515,072个,占总参数4,038,983,168的0.4089%
2. 显存消耗监控
- 显存占用:当前显存消耗为10.83GB,设备总显存为32GB
- 硬件配置:使用单GPU训练(world size=1),设备型号为CUDA架构
- 性能优化:启用了梯度检查点技术以节省显存,同时使用torch SDPA加速训练推理
- 精度设置:采用bfloat16混合精度训练,可训练参数上转为float32保证稳定性
- 模型架构:基于Qwen3-4B-Base模型,36层全注意力结构
- 词表配置:词汇量151936,使用特殊标记<|im_start|>和<|im_end|>分隔对话
- 训练方法:采用LoRA微调,仅更新up_proj、q_proj等线性层的参数
- 缓存策略:训练期间禁用KV缓存以节省内存资源
五、训练过程
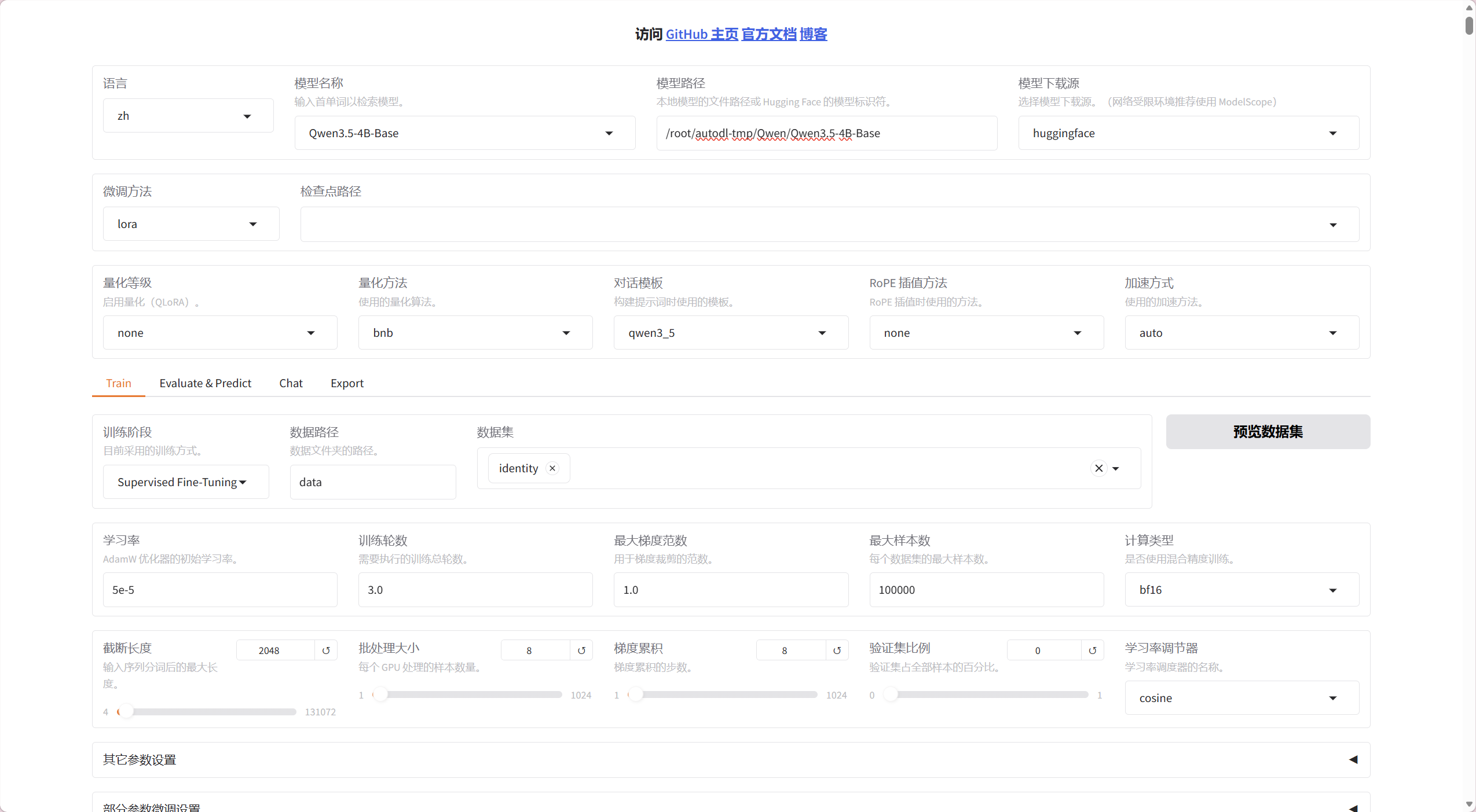
可能会出现deepspeed不兼容,需要先
pip install --upgrade deepspeed
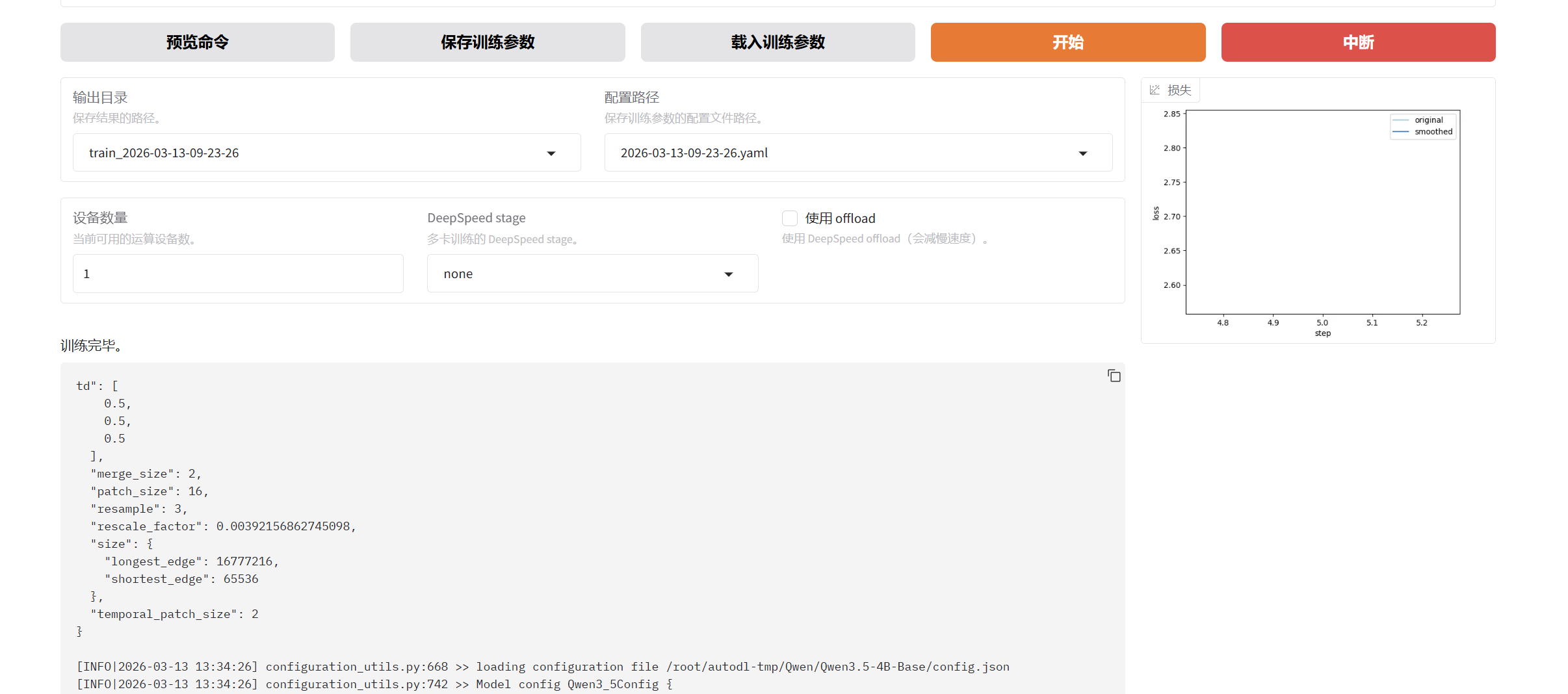
- 查找输出文件
六、训练结果保存
1. 模型参数保存
保存内容:
- 完整模型配置文件(config.json)
- 分词器相关文件:
- vocab.json
- merges.txt
- tokenizer.json
- special_tokens_map.json
- 对话模板文件(chat_template.jinja)
- 模型架构:
- 基础模型:Qwen3-4B-Base
- 注意力头数:32
- 隐藏层维度:2560
- 最大位置编码:32768
- 层数:36
- RoPE theta值:1000000
2. 保存路径确认
- 存储位置:
- 基础路径:/root/autodl-tmp/Qwen/
- 具体目录:saves/Qwen3-4B-Base/lora/train_2025-09-04-20-41-39/
- 文件结构:
- 训练参数配置文件:train_2025-09-04-20-41-39.yaml
- 分词器配置:tokenizer_config.json
- 特殊token文件:special_tokens_file.json
七、训练结果分析
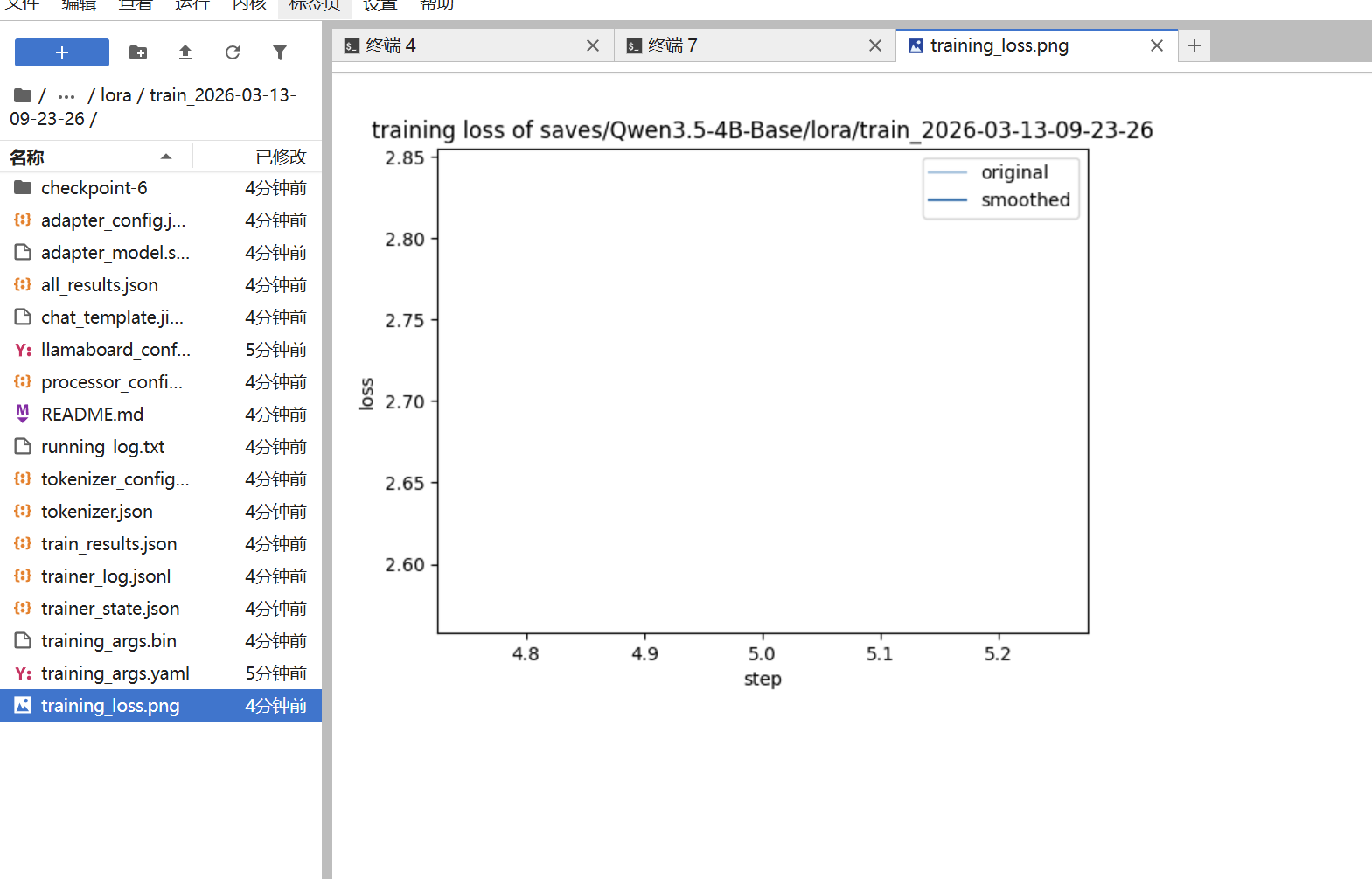
1. 损失曲线查看
- 查看方法:通过目录路径/autodl-tmp/LLaMA-Factory/saves/Qwen3-4B-Base/lora/train_2025-09-04-20-41-39/training_loss.png可获取训练损失曲线
- 曲线特点:当数据集较短时(如演示中仅3轮训练),可能无法完整显示损失下降过程
- 文件组成:训练目录包含adapter_model.safetensors、tokenizer.json等模型文件及配置文件
八、日志系统
1. 日志平台介绍
- 基础日志:当前控制台日志仅包含损失值(如3.6194)、学习率(5e-5)等基础信息
- 专业工具:后续会介绍TensorBoard/WandB等专业日志平台,支持可视化监控训练过程
- 参数配置:演示中设置日志间隔2步、保存间隔100步、预热步数0,使用cosine学习率调节器
- 模型结构:Qwen3-4B模型配置显示36个隐藏层,32个注意力头,词表大小151936
- 训练细节:使用LoRA微调方法,可训练参数占比0.4089%(16,515,072/4,038,983,168)
- 性能指标:训练吞吐量298.36 tokens/秒,最终训练损失3.5815
九、LLaMA Factory入门
1. 日志平台功能
- 日志记录功能:SwanLab是一个集成日志平台,可以记录训练过程中的各项参数和输出结果
- 参数保存:支持保存训练参数配置,方便后续复用和实验复现
- 训练监控:可以实时查看训练进度和设备使用情况
2. 模型推理验证
- 验证流程:训练完成后可通过Evaluate & Predict页面进行模型验证
- 参数设置:
- 最大生成长度:512 tokens
- Top-p采样值:0.7
- 温度系数:0.56
- 结果保存:验证结果可保存到指定目录,方便后续分析
3. 模型聊天测试
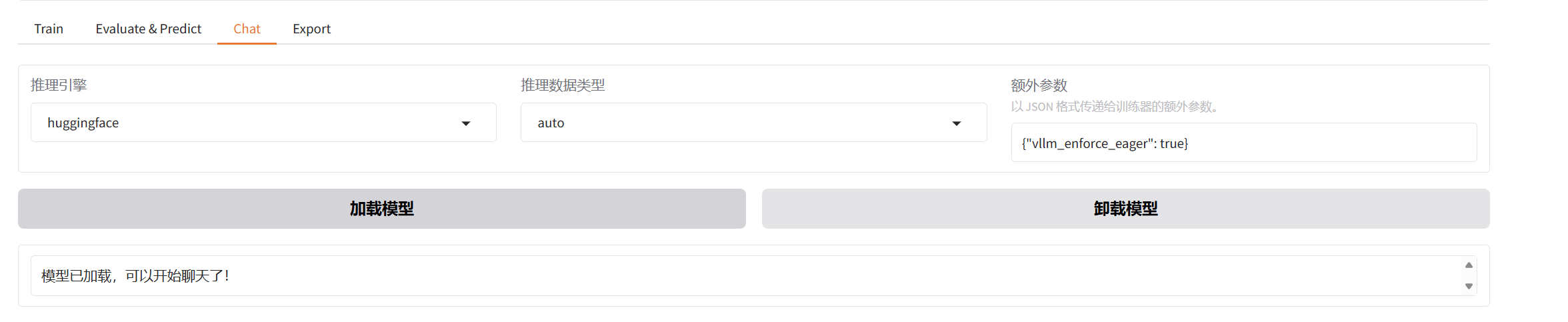
- 聊天参数:
- 最大生成长度:2024 tokens
- 温度系数:0.96
- 系统提示词:可选
- 特殊处理:
- 可跳过特殊token
- 支持转义HTML标签
- 可启用思考模式
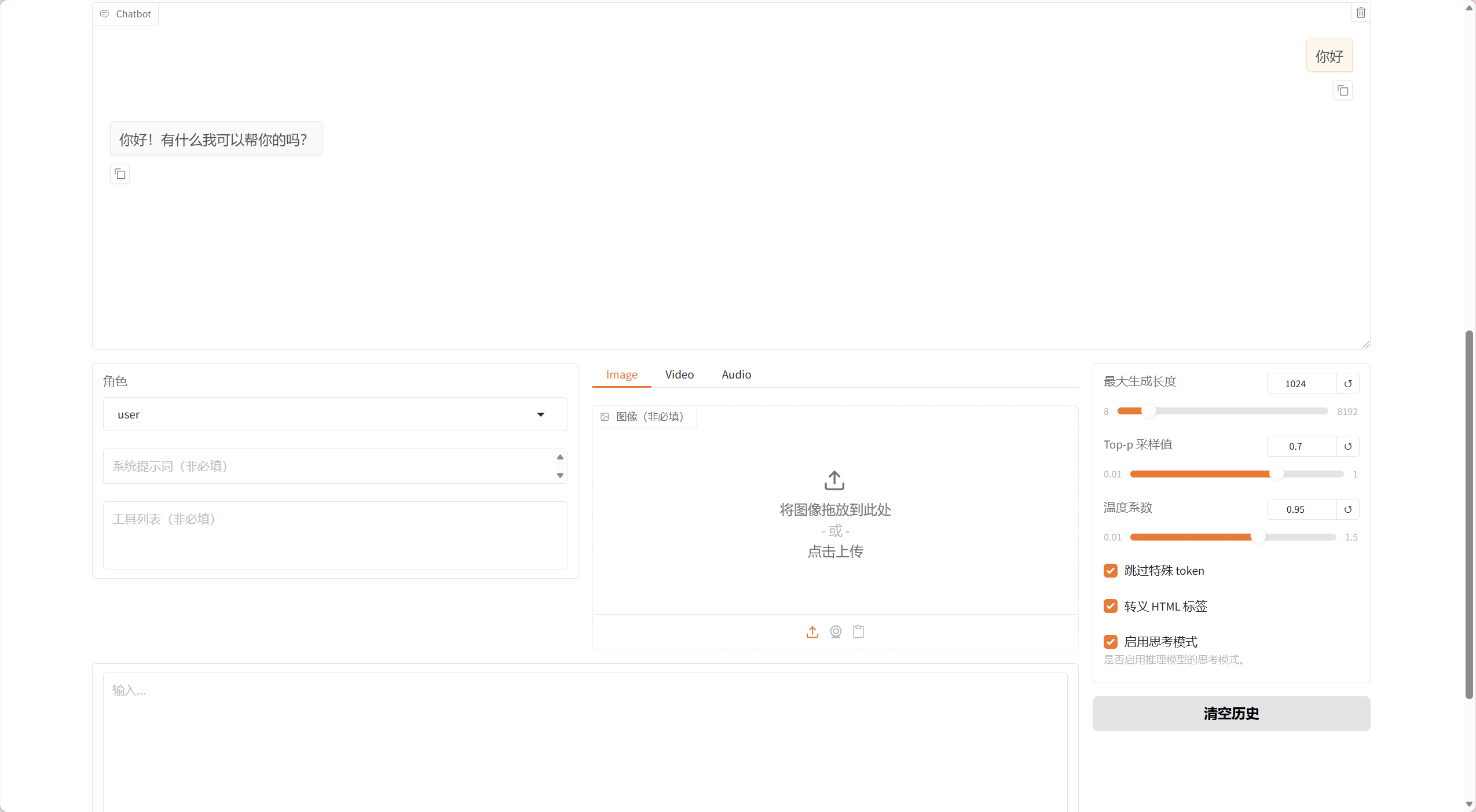
4. 模型效果评估
- 常见问题:小尺寸模型微调后容易出现效果下降
- 表现症状:模型可能出现重复输出或逻辑混乱
- 解决方案:调整推理参数或重新设计微调策略
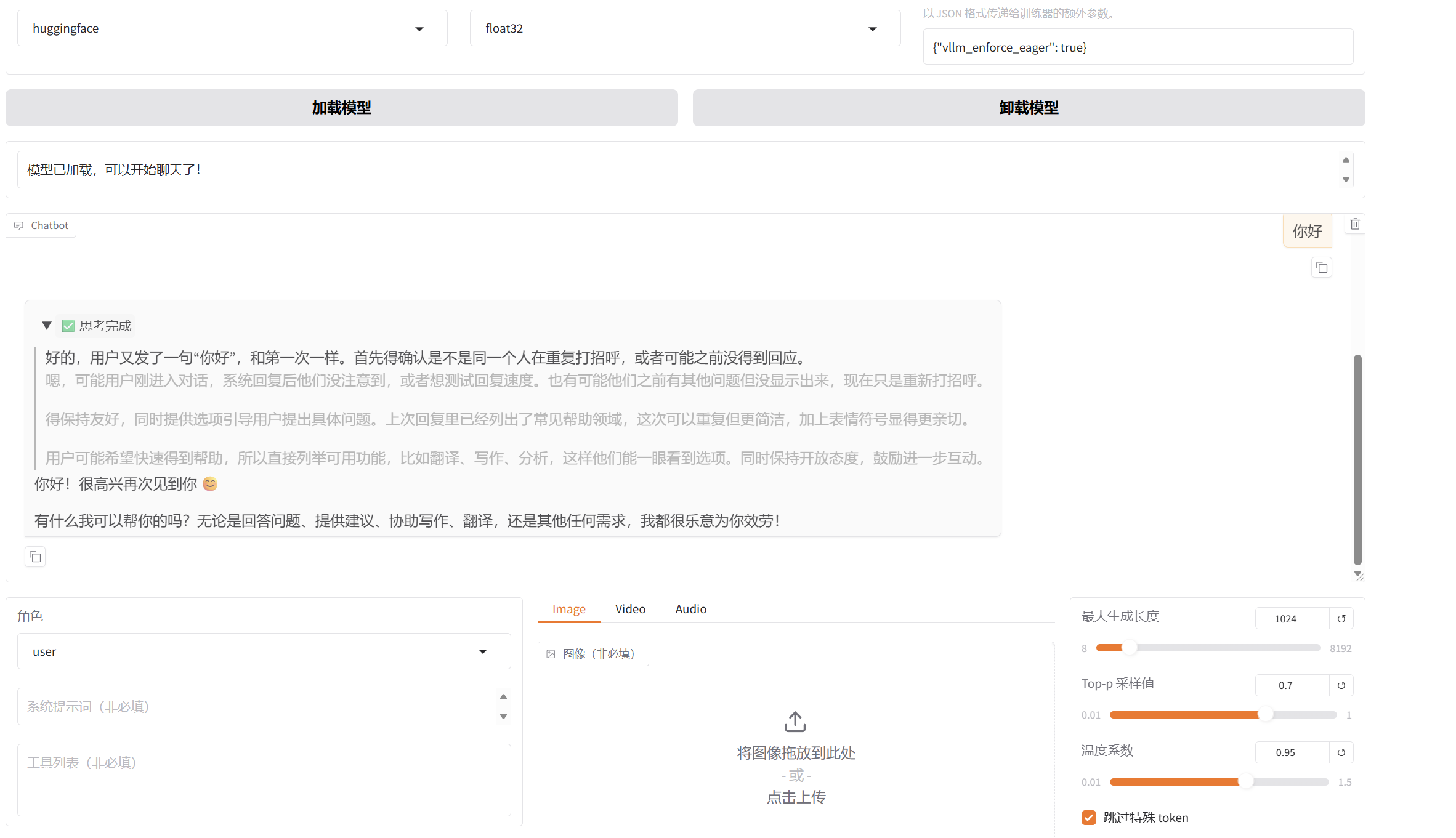
5. 推理精度问题
- 精度影响:使用float16可能导致推理效果下降
- 解决方案:将推理数据类型改为float32可提升稳定性
- 权衡考虑:float32会降低推理速度但提高准确性
6. 模型微调问题
- 蒸馏模型特点:小尺寸模型通常由大模型蒸馏而来
- 微调风险:微调可能破坏蒸馏模型的平衡性
- 表现示例:模型可能出现重复输出或逻辑混乱
7. 模型加载方法
- 加载步骤:
- 选择模型路径
- 设置推理引擎(如huggingface)
- 配置推理数据类型
- 点击"加载模型"按钮
- 注意事项:需确保模型路径正确且有足够显存
8. 模型推理流程
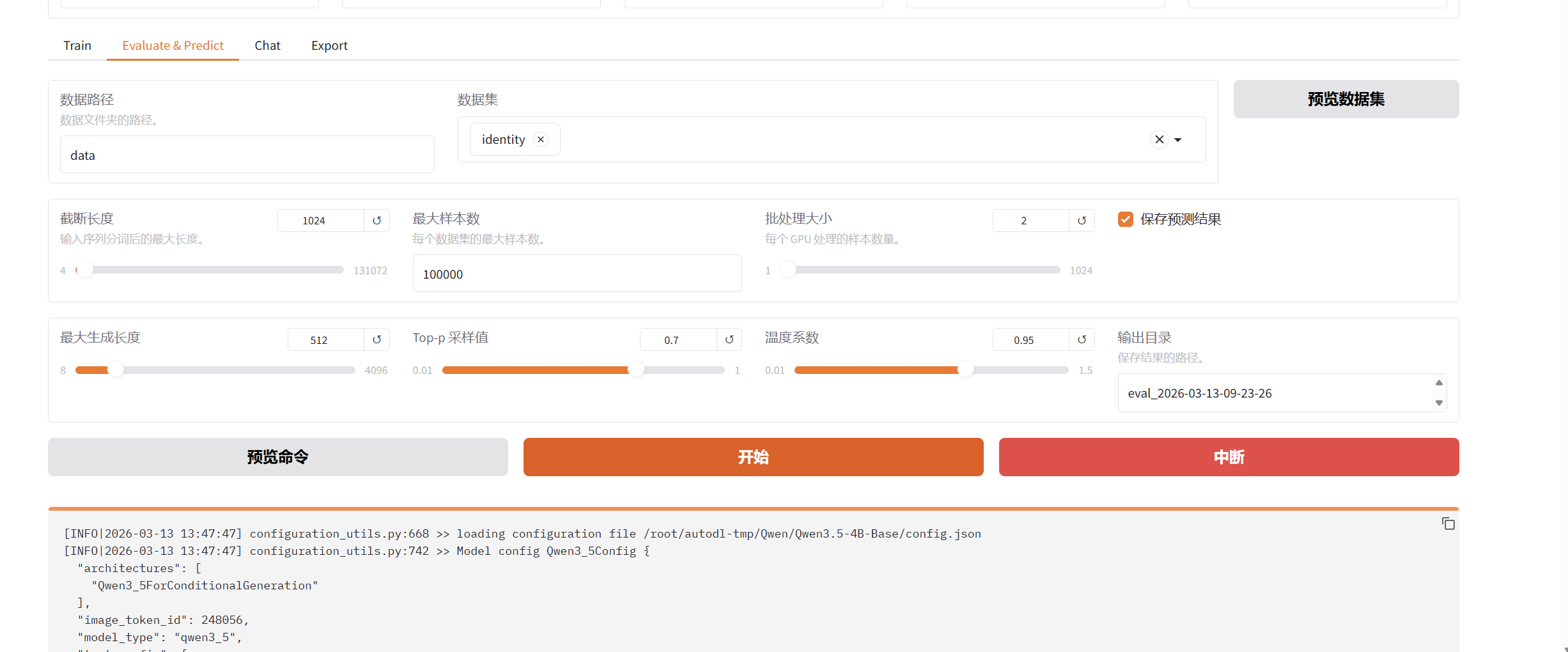
- 关键参数:
- 截断长度:1024
- 批处理大小:2
- 最大样本数:100000
- 输出设置:可指定结果保存路径和格式
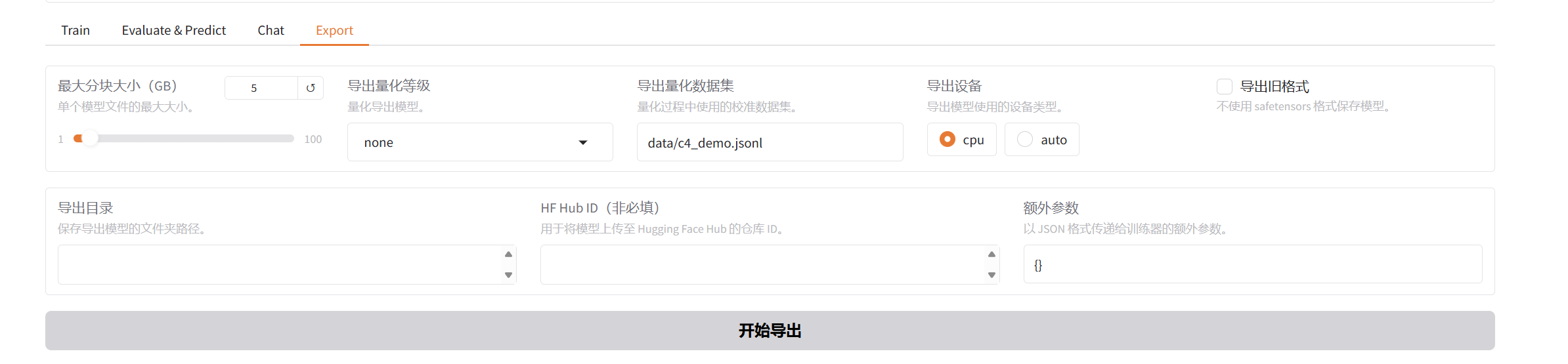
9. 模型导出功能
- 导出作用:将LoRA适配器与基础模型合并为完整模型
- 导出参数:
- 最大分块大小:5GB
- 量化等级:可选
- 输出格式:支持safetensors和bin格式
- 使用场景:方便后续直接加载使用,无需分别加载基础模型和适配器

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)