计算机毕业设计Django+LLM多模态大模型游戏推荐系统 游戏可视化 大数据毕业设计(源码+LW文档+PPT+详细讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
以下是一份关于《Django+LLM多模态大模型游戏推荐系统》的开题报告框架及内容示例,结合多模态数据融合与生成式AI技术进行设计:
开题报告
题目:基于Django与多模态大语言模型(LLM)的游戏推荐系统设计与实现
一、研究背景与意义
1.1 研究背景
随着游戏行业快速发展,Steam、Epic等平台游戏数量突破数十万款,用户面临信息过载与选择困难问题。传统推荐系统存在以下局限:
- 单模态依赖:仅基于用户评分、游戏标签等结构化数据,忽略游戏画面、剧情文本、音频等非结构化信息。
- 冷启动问题:新游戏缺乏历史行为数据,难以生成有效推荐。
- 个性化不足:无法理解用户对游戏风格、叙事主题等复杂需求的语义描述(如“喜欢开放世界+赛博朋克风格”)。
多模态大语言模型(LLM)(如GPT-4V、Llama 3.1)可同时处理文本、图像、音频等多模态数据,结合Django框架的快速开发能力,可构建语义理解+多模态感知的智能推荐系统,提升推荐准确性与用户满意度。
1.2 研究意义
- 理论意义:探索多模态大模型在推荐系统中的应用,完善跨模态语义对齐与个性化推荐理论。
- 实践意义:
- 帮助游戏平台提升用户留存率与付费转化率。
- 为独立游戏开发者提供公平的曝光机会(缓解冷启动问题)。
- 推动AI技术在文娱领域的落地,如游戏内容生成、玩家社区运营等。
二、国内外研究现状
2.1 游戏推荐系统研究现状
- 传统方法:
- 协同过滤(CF):基于用户-游戏评分矩阵相似性推荐,但存在数据稀疏性问题。
- 基于内容的推荐(CBR):提取游戏标签(如RPG、FPS)与用户偏好匹配,但依赖人工标注。
- 深度学习方法:
- 神经网络协同过滤(NCF):通过嵌入层学习用户/游戏隐向量,但未利用多模态信息。
- 图神经网络(GNN):建模用户-游戏交互图,但需大量异构数据训练。
- 多模态推荐:
- MMGCN(2021):利用图像、文本特征增强推荐,但未结合大模型语义理解能力。
- CLIP4Rec(2023):基于CLIP模型对齐文本-图像特征,但未针对游戏场景优化。
2.2 多模态大模型应用现状
- LLM能力扩展:
- GPT-4V:支持图像理解与文本生成,可分析游戏截图、封面艺术风格。
- Llama 3.1:开源模型,支持微调以适配游戏领域知识(如角色、关卡设计)。
- 推荐系统融合:
- 检索增强生成(RAG):通过LLM生成用户偏好描述,检索候选游戏后重新排序。
- 微调LLM:直接在用户-游戏交互数据上训练,生成个性化推荐理由(如“这款游戏适合喜欢探索与解谜的玩家”)。
2.3 现有问题
- 多模态融合不足:未充分利用游戏画面、剧情文本、音频等跨模态关联信息。
- 语义理解局限:传统模型无法处理用户自然语言描述的复杂需求(如“想要一款类似《塞尔达传说》但难度更低的开放世界游戏”)。
- 实时性挑战:大模型推理延迟高,难以支持实时推荐场景。
三、研究目标与内容
3.1 研究目标
设计并实现一个基于Django与多模态LLM的游戏推荐系统,实现以下功能:
- 多模态游戏特征提取:自动分析游戏截图、宣传视频、剧情文本等,生成结构化特征向量。
- 语义理解推荐:支持用户通过自然语言描述需求(如“适合情侣玩的合作类游戏”),生成匹配推荐列表。
- 冷启动缓解:为新游戏提供基于多模态内容的初始推荐权重。
- 可解释推荐:生成推荐理由(如“因您喜欢科幻题材,推荐《星空》”),提升用户信任度。
3.2 研究内容
- 系统架构设计
- 分层架构:
- 数据层:
- 结构化数据:游戏ID、标签、用户评分(存储于PostgreSQL)。
- 非结构化数据:游戏截图、视频、剧情文本(存储于MinIO对象存储)。
- 模型层:
- 多模态编码器:使用CLIP提取图像特征,BERT提取文本特征,Wav2Vec提取音频特征。
- 大语言模型:Llama 3.1(微调后)处理用户查询与推荐理由生成。
- 应用层:Django提供RESTful API与Web界面,支持用户交互与管理员后台管理。
- 数据层:
- 推荐引擎:
- 离线引擎:每日更新游戏特征库与用户画像(基于历史行为)。
- 实时引擎:通过FastAPI调用LLM,处理用户即时查询并返回推荐结果。
- 分层架构:
- 关键技术实现
- 多模态特征融合:
- 使用跨模态注意力机制(Cross-Attention)对齐图像、文本、音频特征。
- 通过PCA降维生成统一的游戏特征向量(如256维)。
- 用户偏好建模:
- 显式反馈:用户评分、收藏、游玩时长。
- 隐式反馈:点击行为、停留时间、社交互动(如加入游戏社群)。
- LLM增强:将用户历史行为转化为自然语言描述(如“您常玩MMORPG,且偏好PVE内容”),作为模型输入。
- 推荐算法:
- 双塔模型:用户向量与游戏向量计算余弦相似度,筛选Top-K候选。
- LLM重排序:对候选列表进行语义匹配度打分(如“用户查询‘休闲解谜游戏’与《纪念碑谷》的匹配度为0.92”)。
- 冷启动策略:
- 新游戏:基于多模态特征与已有游戏相似度分配初始曝光权重。
- 新用户:通过快速问卷(如“您喜欢哪种游戏类型?”)生成初始偏好向量。
- 推荐理由生成:
- 使用微调Llama 3.1,输入为用户查询、游戏信息,输出为自然语言解释(如“推荐《哈迪斯》因其roguelike玩法与快节奏战斗符合您的偏好”)。
- 多模态特征融合:
- 系统优化
- 延迟优化:
- 模型量化:将LLM从FP32压缩至INT8,减少推理时间。
- 缓存机制:缓存热门查询的推荐结果(如“Steam畅销榜游戏推荐”)。
- 数据安全:
- 用户数据脱敏:匿名化处理用户ID与行为日志。
- 模型防护:防止LLM生成恶意推荐(如诱导付费内容)。
- 延迟优化:
- 系统测试与评估
- 评估指标:
- 推荐准确率:HR@10(Top-10推荐命中率)、NDCG@10(归一化折损累积增益)。
- 用户满意度:通过A/B测试对比传统推荐系统与本系统的点击率、停留时长。
- 冷启动效果:新游戏曝光量与用户转化率提升比例。
- 对比实验:
- 与基于协同过滤的推荐系统对比推荐多样性(如覆盖的游戏类型数量)。
- 与单模态(仅文本或图像)推荐系统对比特征表达能力。
- 评估指标:
四、研究方法与技术路线
4.1 研究方法
- 文献研究法:分析多模态推荐、LLM应用相关论文(如ACL、WWW会议论文)与开源项目(如Hugging Face Transformers、Django-REST-framework)。
- 实验法:基于Steam公开数据集(如游戏元数据、用户评分)或合作游戏平台真实数据验证模型。
- 系统开发法:采用敏捷开发模式,分模块实现数据采集、特征提取、推荐引擎与可视化。
4.2 技术路线
- 环境搭建:
- Django + PostgreSQL(用户/游戏数据管理)。
- MinIO(多模态文件存储) + FastAPI(LLM推理服务)。
- PyTorch + Hugging Face(多模态模型训练与部署)。
- 数据处理流程:
1原始数据(游戏截图/视频/文本 + 用户行为) → MinIO存储 → 多模态特征提取 → 特征融合 → 用户画像构建 → LLM推荐生成 → Django API返回结果 2 - 模型部署:
- 使用ONNX Runtime加速LLM推理。
- 通过Docker容器化部署各服务,Kubernetes管理集群资源。
五、预期成果与创新点
5.1 预期成果
- 完成系统原型开发,支持游戏推荐全流程(从用户查询到结果展示)。
- 在核心期刊或国际会议(如RecSys、SIGIR)发表1-2篇论文。
- 申请1项软件著作权或专利(如“基于多模态LLM的游戏冷启动推荐方法”)。
5.2 创新点
- 多模态语义对齐:通过跨模态注意力机制融合游戏画面、文本、音频特征,提升特征表达能力。
- LLM增强推荐:利用大模型理解用户自然语言查询,生成个性化推荐理由,解决传统系统“黑盒”问题。
- 动态冷启动策略:结合多模态内容相似度与用户实时反馈,动态调整新游戏推荐权重。
六、进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 1 | 第1-2月 | 文献调研、需求分析、数据集收集(Steam API、Kaggle游戏数据) |
| 2 | 第3-4月 | 系统架构设计、环境搭建、多模态特征提取模块开发 |
| 3 | 第5-7月 | 用户偏好建模与推荐算法实现、LLM微调与重排序模块开发 |
| 4 | 第8-9月 | 推荐理由生成与冷启动策略优化、系统集成与测试 |
| 5 | 第10-12月 | 论文撰写、答辩准备、系统部署与A/B测试 |
七、参考文献
[1] Wang X, et al. Multimodal Recommendation with Cross-Modal Transformer. WWW 2023.
[2] OpenAI. GPT-4V Technical Report. 2023.
[3] Zhao Z, et al. RAG-enhanced Recommendation with Large Language Models. RecSys 2023.
[4] Steamworks Documentation. Game Metadata API.
[5] Hugging Face. Transformers Library Documentation.
备注:可根据实际研究深度补充以下内容:
- 增加“伦理与隐私保护”章节,讨论用户数据使用合规性(如GDPR)。
- 补充具体模型伪代码(如跨模态注意力机制实现)。
- 添加系统界面设计图或架构图。
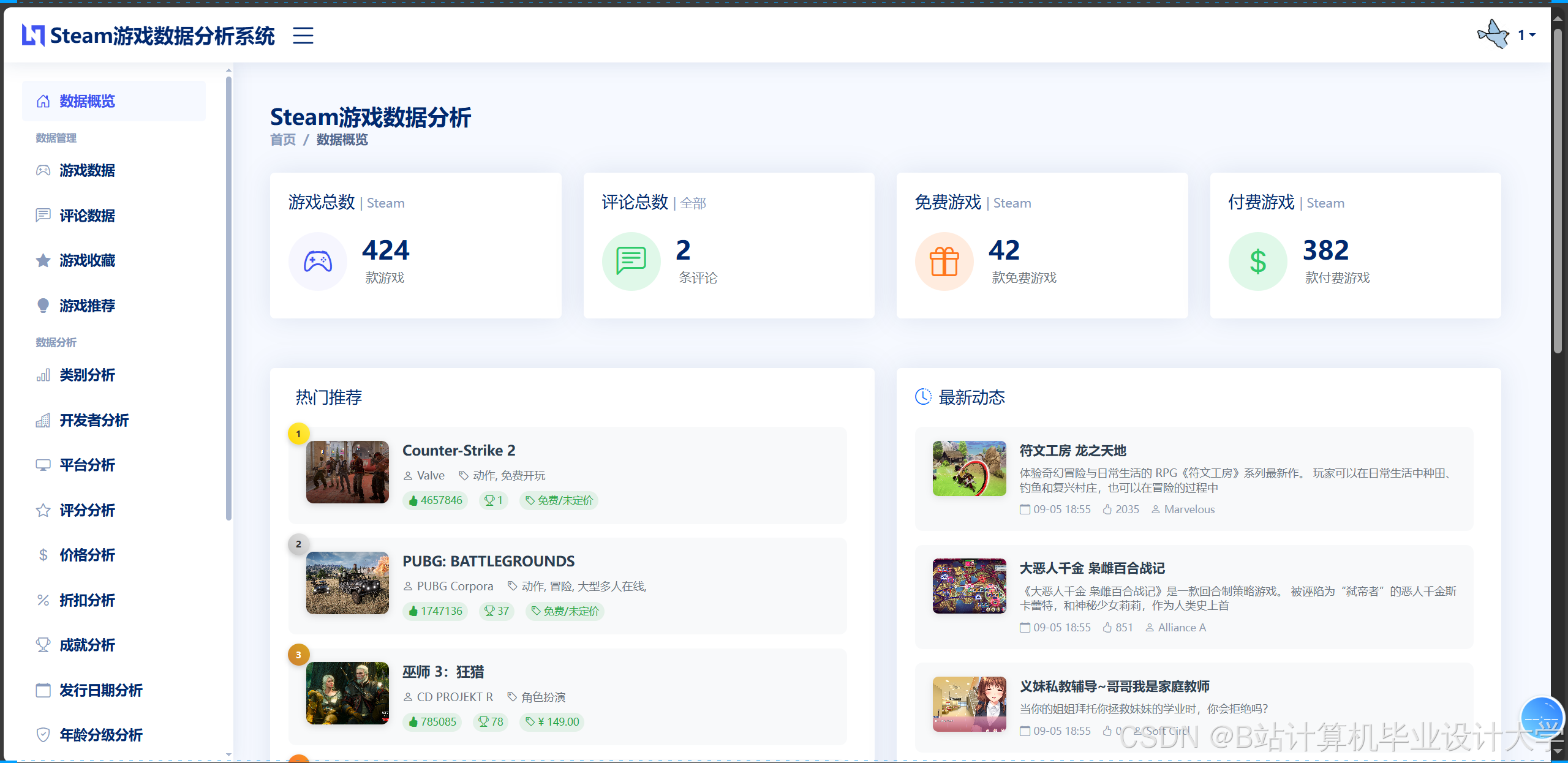
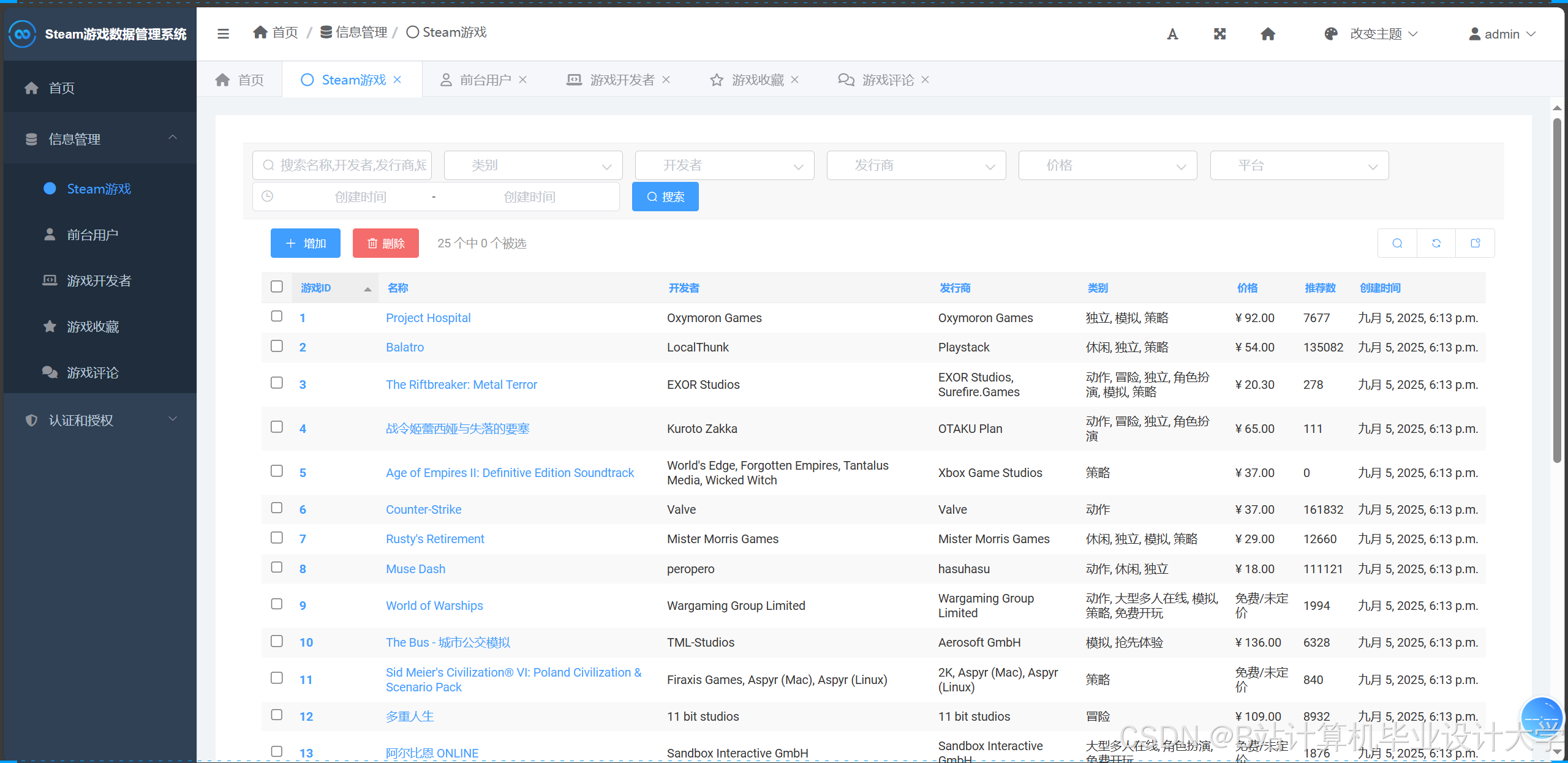
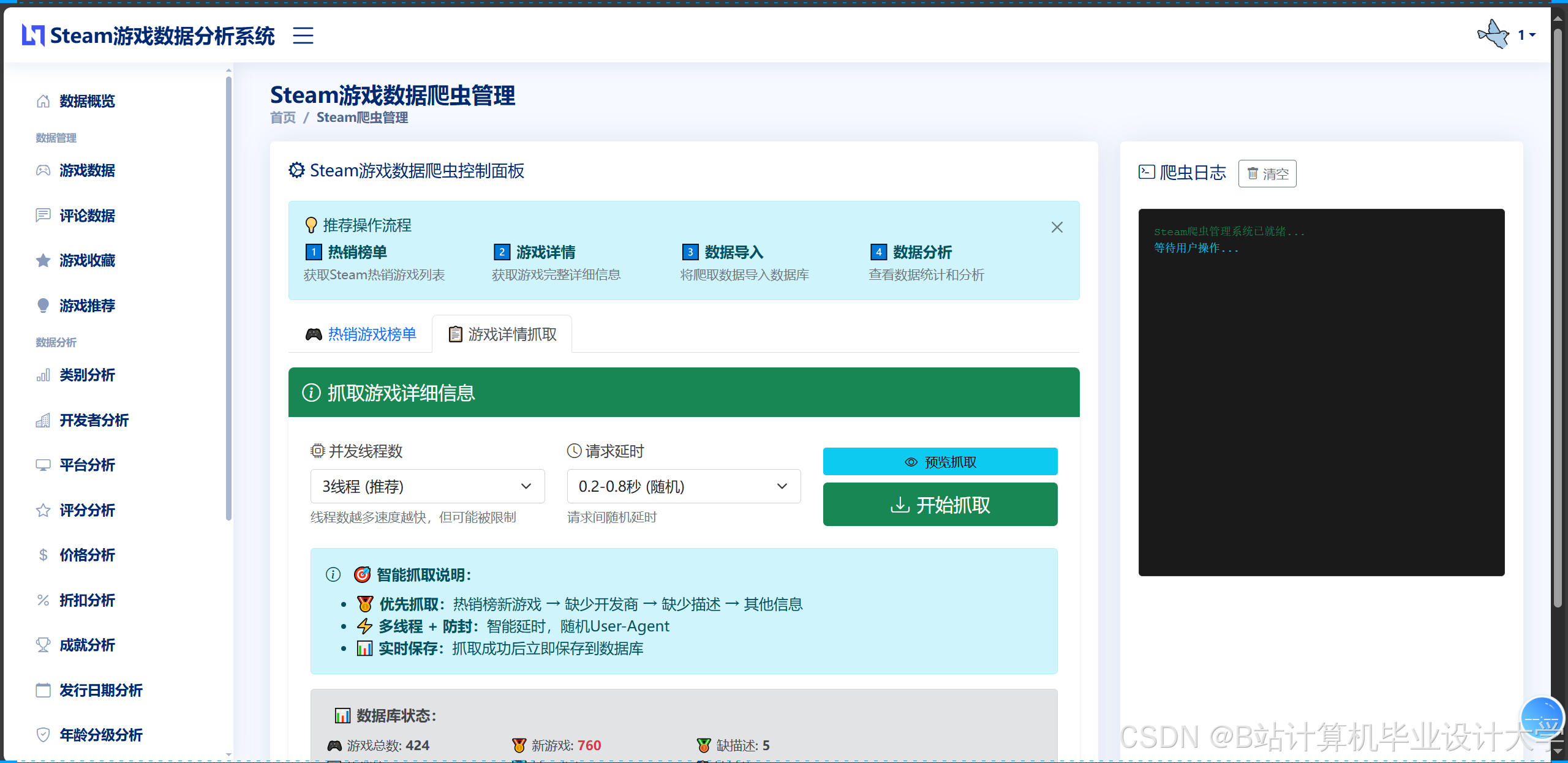
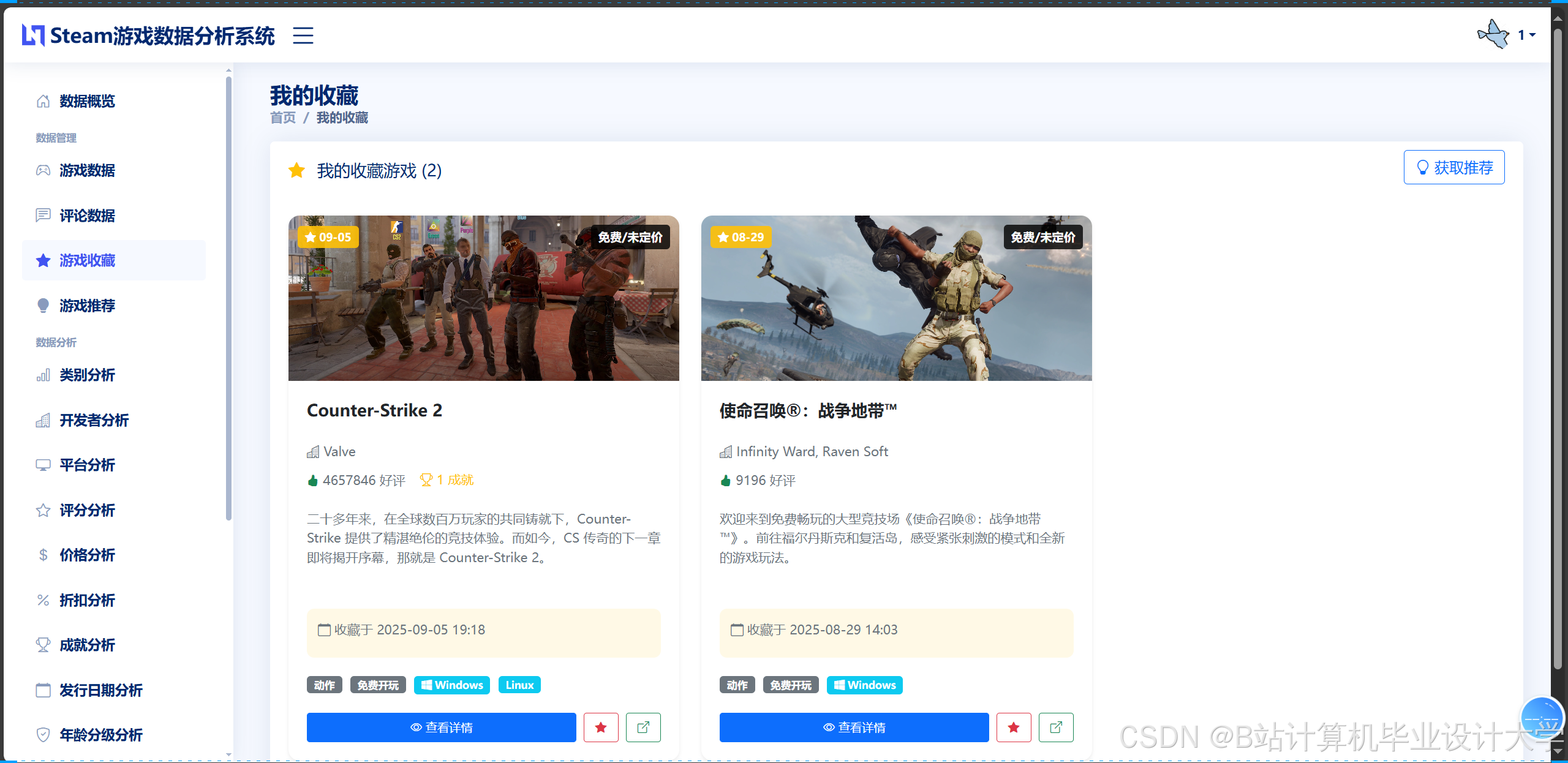
运行截图
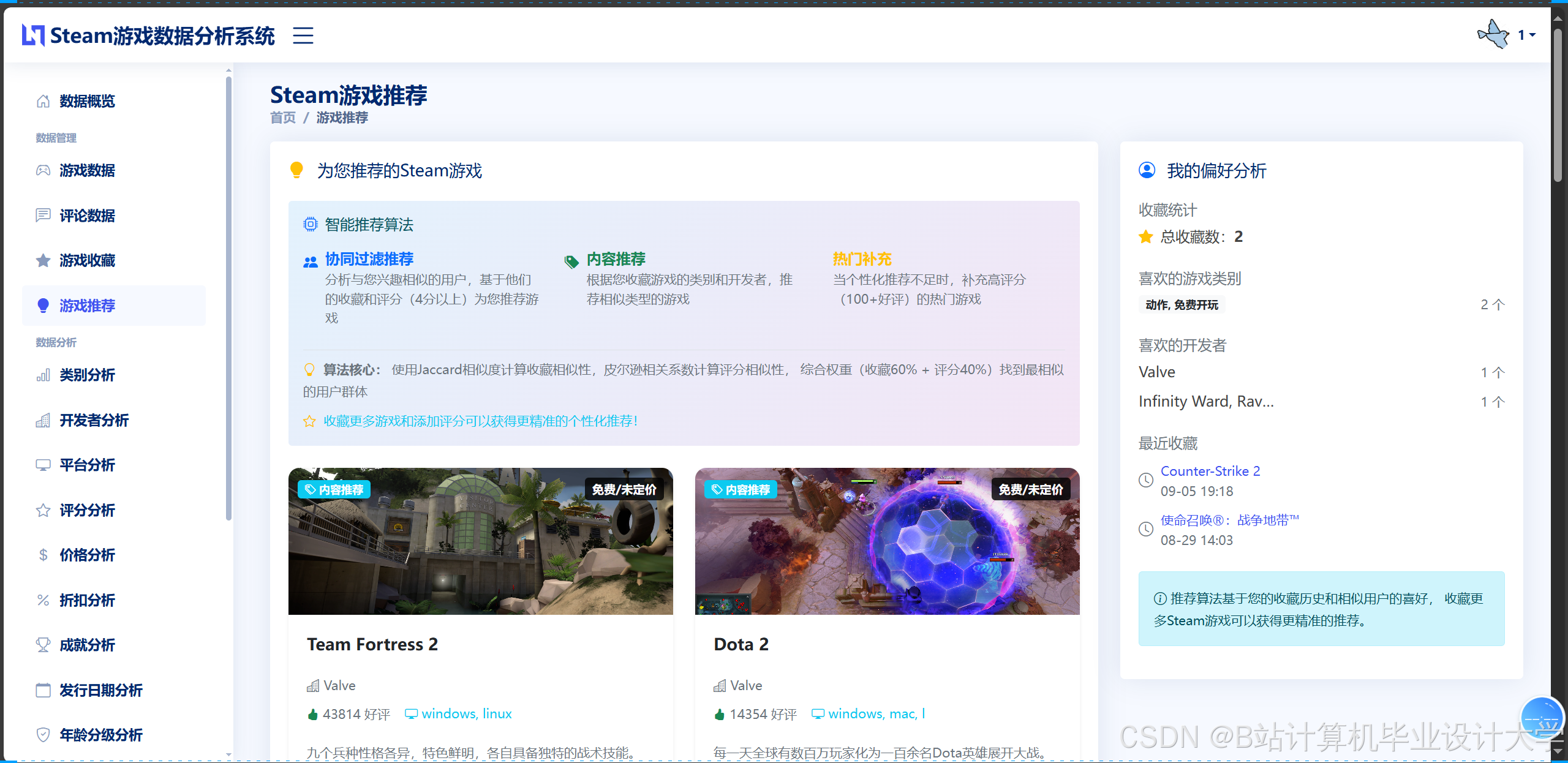
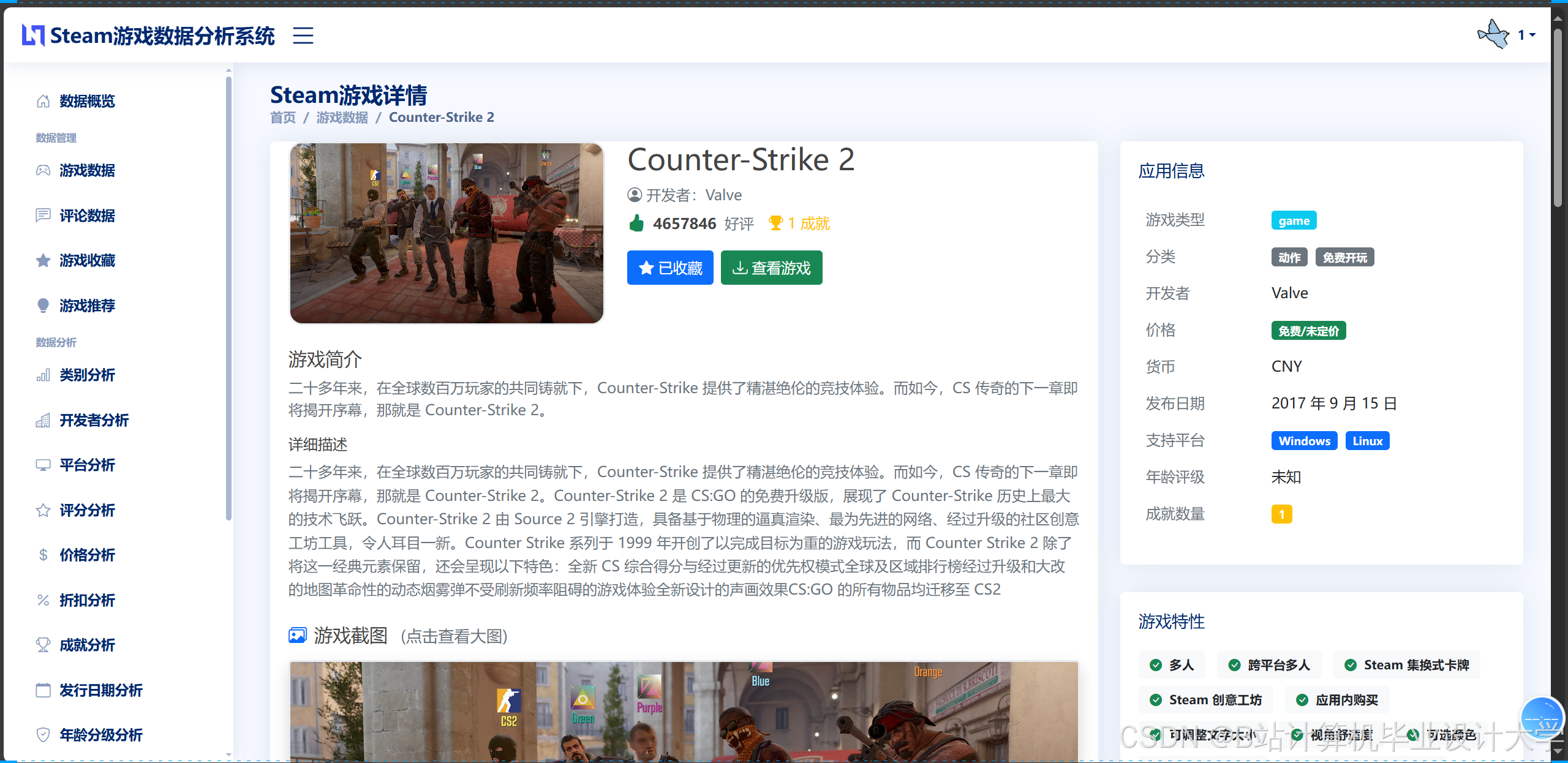
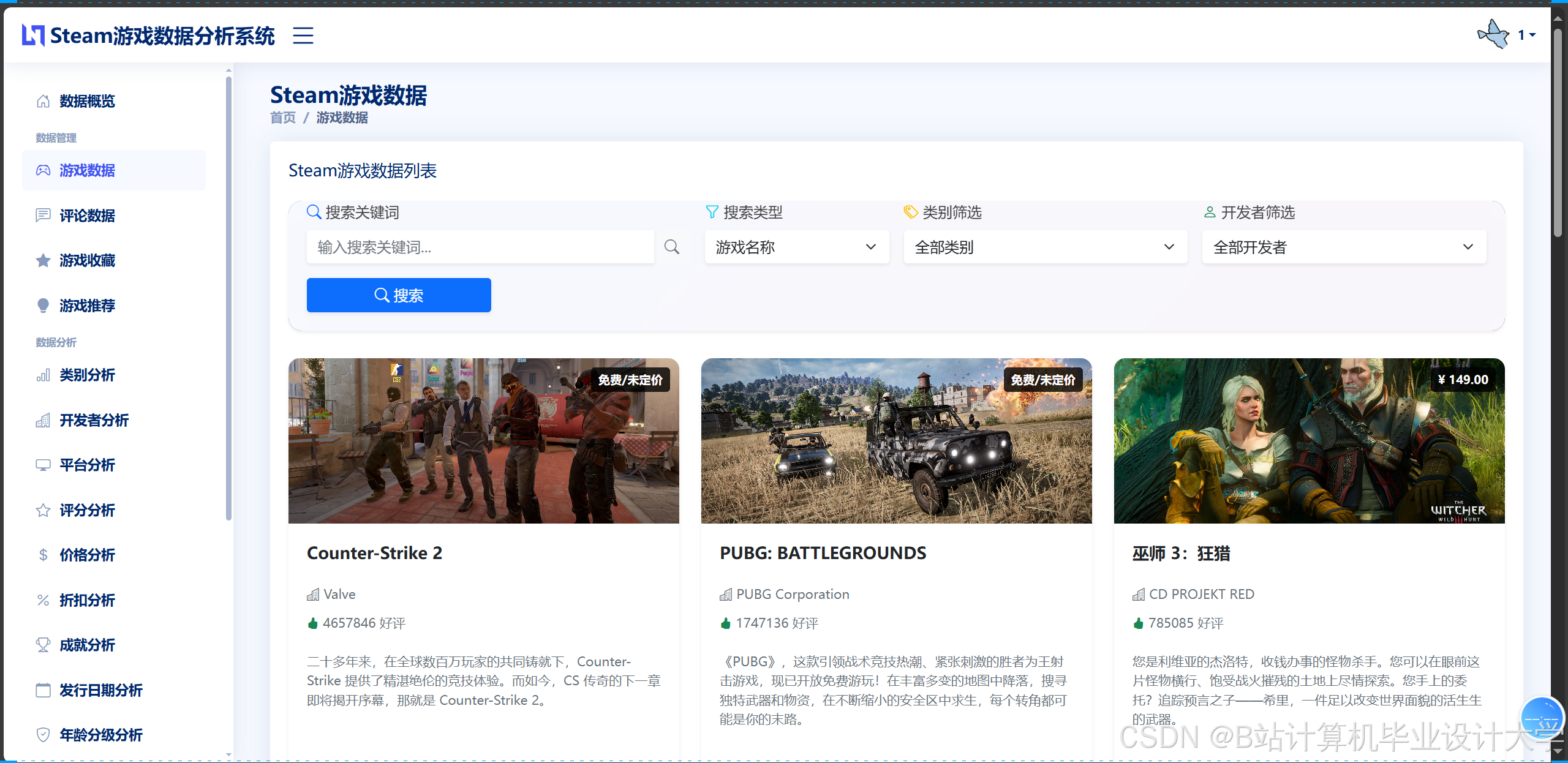
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献284条内容
已为社区贡献284条内容

所有评论(0)