时间序列预测新模型:TCN-Transformer
基于TCN-Transformer实现时间序列预测 模型采用共享TCN结构,用于提取Encoder Embedding和Decoder Embedding 的因果特征,在尽可能保证模型复杂度不变的情况下,提高模型预测精度 模型中Transformer部分为源码结构,模型结构清晰,数据替换简单,适合初学者学习,也适合本科毕设,研究生毕业论文 可实现多输入多输出,多输入单输出,单输入单输出,多步预测和单步预测 适合负荷预测,风电预测,光伏预测,寿命预测等一系列时间序列预测,同时也适合多特征回归预测,
一、项目概述
本项目基于TCN(Temporal Convolutional Network,时间卷积网络)与Transformer融合架构,实现时间序列预测功能。核心目标是通过共享TCN结构增强特征提取能力,结合Transformer的长序列依赖建模优势,对时序数据进行精准预测。当前代码默认以风力发电功率(wind.csv数据集中的power字段)为预测目标,支持灵活配置输入序列长度、预测步长、模型参数等,适用于各类时序预测场景。
二、代码结构总览
项目包含19个文件,按功能划分为核心执行模块、模型架构模块、网络层模块、工具辅助模块四大类,具体结构如下:
| 模块类型 | 核心文件 | 功能描述 |
|---|---|---|
| 核心执行模块 | TCN_Transformer.py | 主程序入口,包含数据加载、模型训练、测试、结果评估与可视化 |
| 模型架构模块 | Transformer/Transformer.py | 定义TCN-Transformer融合模型主体,包含TCN块、Transformer编码器/解码器 |
| 网络层模块 | layers/目录下10个文件 | 提供注意力机制、嵌入层、卷积层等基础组件,支持模型灵活搭建 |
| 工具辅助模块 | utils/目录下5个文件 | 提供时间特征提取、评估指标计算、早停机制、数据标准化等工具函数 |
三、核心模块详细解析
(一)主程序模块:TCN_Transformer.py
作为项目入口文件,整合了数据处理、模型训练、测试全流程,关键功能如下:
1. 数据加载与预处理
- 数据读取:加载wind.csv数据集,分离时间列(date)与特征列,指定power字段为预测目标。
- 时间特征工程:通过
time_features函数提取时间特征(如小时、星期、月份等),用于捕捉时序数据的周期性规律。 - 数据集划分:按7:1:2比例划分为训练集、验证集、测试集,确保模型泛化能力评估的合理性。
- 数据标准化:使用
StandardScaler对特征数据进行归一化处理,消除量纲影响,提升模型收敛速度。 - 序列构造:通过
dataloader函数构建输入序列(长度为window=48)与预测序列(长度为lengthsize=1),生成批量数据用于模型训练。
2. 模型配置与初始化
- Config类:统一管理模型超参数,核心配置如下:
| 参数名 | 含义 | 默认值 |
|--------|------|--------|
| seqlen | 输入序列长度 | 48 |
| labellen | 解码器输入标签长度 | 24(window/2) |
| predlen | 预测步长 | 1 |
| elayers/dlayers | Transformer编码器/解码器层数 | 2/1 |
| dmodel | 模型隐藏层维度 | 512 |
| n_heads | 多头注意力头数 | 8 |
| dropout | dropout概率 | 0.05 |
| lr | 初始学习率 | 0.001 |
| patience | 早停耐心值 | 3 |
- 设备选择:自动检测CUDA可用性,优先使用GPU加速训练,否则使用CPU。
3. 模型训练流程
- 模型初始化:加载
Transformer.py中定义的Model类,初始化TCN-Transformer融合模型。 - 损失函数与优化器:采用MSE(均方误差)作为损失函数,Adam优化器进行参数更新,加入权重衰减抑制过拟合。
- 早停机制:通过
EarlyStopping类监控验证集损失,若连续3个epoch无下降则停止训练,保存最优模型参数至checkpoint/bestTCNTransformer.pt。 - 学习率调整:采用
adjustlearningrate函数实现学习率衰减(type1策略:每3个epoch衰减为原来的0.5倍),平衡模型收敛速度与精度。 - 训练过程:
1. 编码器输入:原始特征序列+时间特征序列,经TCN块提取局部特征后输入Transformer编码器。
2. 解码器输入:拼接历史标签序列与零填充的预测序列,经TCN块处理后输入Transformer解码器。
3. 梯度反向传播:计算预测值与真实值的MSE损失,通过优化器更新模型参数。
4. 模型测试与结果评估
- 模型加载:加载训练过程中保存的最优模型参数。
- 预测推理:对测试集数据进行预测,输出预测结果并反归一化,恢复原始数据尺度。
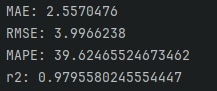
- 指标计算:计算MAE(平均绝对误差)、RMSE(均方根误差)、MAPE(平均绝对百分比误差)、R²(决定系数)四项评估指标,全面衡量模型预测精度。
- 结果保存与可视化:
1. 保存预测结果与真实值至results目录,格式为CSV文件。
2. 绘制预测值与真实值的对比曲线图,保存至images目录,直观展示模型预测效果。
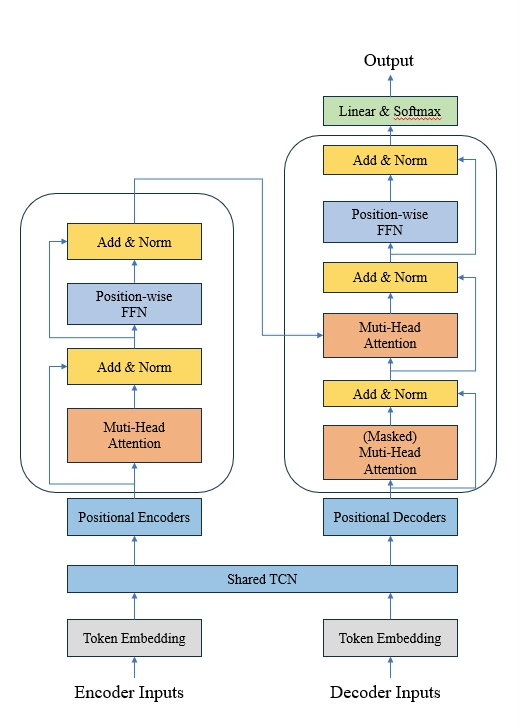
(二)模型架构模块:Transformer/Transformer.py
定义TCN-Transformer融合模型的核心结构,实现局部特征提取与长序列依赖建模的结合:
1. TCN块(TCNBlock)
- 核心功能:捕捉时序数据的局部特征与短期依赖关系,采用因果卷积(避免未来信息泄露)与残差连接(缓解梯度消失)。
- 结构细节:
1. 两层1D卷积:第一层将输入特征维度从dmodel扩展至2*dmodel,第二层压缩回d_model。
2. 激活函数与dropout:使用ReLU激活函数引入非线性,dropout层抑制过拟合。
3. 残差连接:当输入输出维度不一致时,通过1x1卷积调整维度后相加,保留原始特征信息。
2. Transformer编码器/解码器
- 编码器:由2层
EncoderLayer组成,每层包含多头注意力机制与前馈神经网络(FFN),对TCN提取的局部特征进行全局依赖建模。 - 解码器:由1层
DecoderLayer组成,包含自注意力机制、交叉注意力机制(与编码器输出交互),生成最终预测序列。 - 嵌入层:通过
DataEmbedding类实现特征嵌入、位置嵌入与时间特征嵌入的融合,将原始特征映射至高维特征空间。
3. 模型前向传播(forward)
- 编码器流程:输入特征→数据嵌入→TCN块(2层)→Transformer编码器→全局特征输出。
- 解码器流程:目标序列→数据嵌入→TCN块(2层)→Transformer解码器(与编码器特征交互)→投影层(输出预测结果)。
(三)网络层模块:layers/目录
提供模型所需的基础网络组件,关键层如下:
- Embed.py:实现数据嵌入功能,包括特征嵌入(TokenEmbedding)、位置嵌入(PositionalEmbedding)、时间特征嵌入(TemporalEmbedding),为模型提供丰富的特征表达。
- SelfAttention_Family.py:实现多种注意力机制,包括FullAttention(全注意力)、ProbAttention(概率注意力)等,本模型使用FullAttention捕捉全局依赖。
- Transformer_EncDec.py:定义Transformer的编码器层(EncoderLayer)与解码器层(DecoderLayer),包含注意力机制与前馈神经网络的核心逻辑。
- Conv_Blocks.py:提供Inception卷积块,支持多尺度特征提取(可选集成到模型中增强局部特征捕捉能力)。
(四)工具辅助模块:utils/目录
提供通用工具函数,支撑模型训练与评估:
- timefeatures.py:提取时间特征的核心工具,支持根据数据频率(如小时h、分钟t)自动选择特征类型,输出标准化后的时间特征向量。
- metrics.py:实现MAE、RMSE、MAPE、R²等评估指标的计算,用于量化模型预测精度。
- masking.py:提供注意力掩码(如TriangularCausalMask),避免解码器在训练过程中接触未来信息。
- tools.py:包含学习率调整、早停机制、数据标准化等工具类,与主程序模块协同工作。
四、关键技术亮点
- TCN与Transformer融合:TCN擅长捕捉局部特征与短期依赖,Transformer擅长建模长序列全局依赖,两者结合兼顾预测精度与效率。
- 共享TCN结构:编码器与解码器共享TCN块参数,减少模型参数量,提升训练效率,同时保证特征提取的一致性。
- 时间特征工程:充分利用时序数据的时间属性,增强模型对周期性、趋势性规律的捕捉能力。
- 完善的训练机制:集成早停、学习率衰减、权重衰减等策略,有效抑制过拟合,提升模型泛化能力。
五、使用说明与结果解读
1. 运行流程
- 确保数据集wind.csv位于data目录下,创建checkpoint、results、images目录(用于保存模型、结果与可视化图)。
- 直接运行TCN_Transformer.py,自动执行数据预处理→模型训练→测试→结果保存全流程。
- 查看输出:
- 训练过程:实时打印各epoch的训练集/验证集损失。
- 评估指标:测试完成后输出MAE、RMSE、MAPE、R²数值。
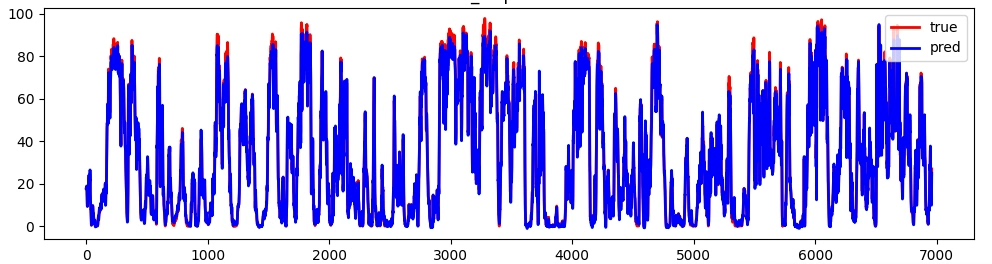
- 结果文件:results目录下的CSV文件(预测值与真实值)、images目录下的对比曲线图。
2. 结果解读
- 理想指标表现:MAE、RMSE、MAPE数值越小,R²越接近1,说明模型预测精度越高。
- 可视化图:红色曲线为真实值,蓝色曲线为预测值,两条曲线重合度越高,模型拟合效果越好。
六、扩展与优化建议
- 数据集适配:修改
filepath与datatarget参数,可适配其他时序数据集(如电力负荷、股票价格等)。 - 超参数调优:调整dmodel、nheads、window等参数,或尝试不同的学习率衰减策略,进一步提升模型性能。
- 模型结构扩展:可替换注意力机制(如ProbAttention减少计算量)、增加TCN层数或卷积核大小,适配不同长度的时序数据。
- 多步预测支持:修改
length_size参数为大于1的值,实现多步时序预测(需同步调整模型输出层与损失计算逻辑)。
七、依赖环境
- 核心库版本要求:
- Python 3.7+
- PyTorch 1.7+
- Pandas 1.0+
- NumPy 1.18+
- Matplotlib 3.3+
- 安装命令:
pip install torch pandas numpy matplotlib scikit-learn
通过上述架构设计与功能实现,TCN-Transformer模型在时序预测任务中能够有效平衡局部特征捕捉与长序列依赖建模,具备良好的泛化能力与工程实用性。

基于TCN-Transformer实现时间序列预测 模型采用共享TCN结构,用于提取Encoder Embedding和Decoder Embedding 的因果特征,在尽可能保证模型复杂度不变的情况下,提高模型预测精度 模型中Transformer部分为源码结构,模型结构清晰,数据替换简单,适合初学者学习,也适合本科毕设,研究生毕业论文 可实现多输入多输出,多输入单输出,单输入单输出,多步预测和单步预测 适合负荷预测,风电预测,光伏预测,寿命预测等一系列时间序列预测,同时也适合多特征回归预测,

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)