AI agent 记忆:使用 Elasticsearch 托管记忆创建智能代理
作者:来自 Elastic Gustavo Llermaly 及 Jeffrey Rengifo
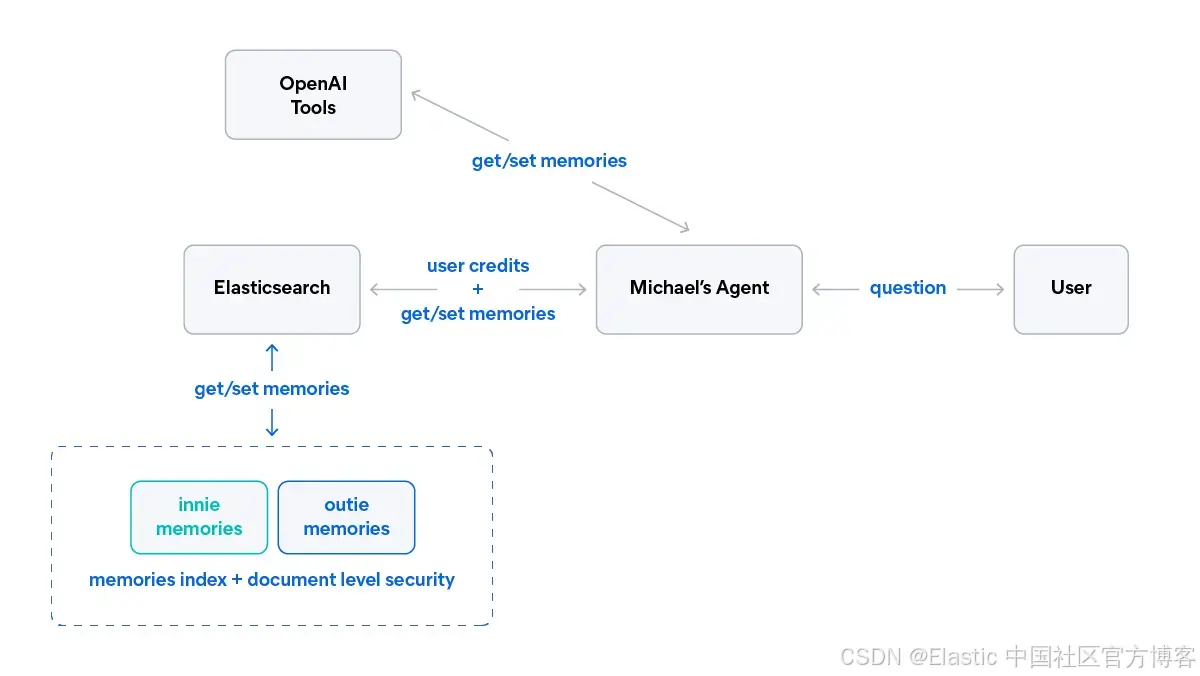
了解如何通过使用 Elasticsearch 管理记忆来创建更智能、更高效的 AI agents。
Agent Builder 现已正式发布。开始使用 Elastic Cloud 试用,并查看 Agent Builder 的文档。
在本文中,我们将学习如何使用记忆技术,通过 Elasticsearch 作为记忆和知识的数据库,使 agents 更智能。
理解大型语言模型 (LLMs) 中的记忆
这里有一个常让人困惑的点:与 LLMs 的对话是完全无状态的。每次发送消息时,你都需要包含完整的对话历史,以 “提醒” 模型之前发生了什么。在单个会话中跟踪问答内容的能力,被称为短期记忆。
但有趣的是:没有什么阻止我们对聊天历史进行超越简单存储的操作。例如,当我们想在不同对话之间持久化用户偏好等记忆时,可以在需要时将这些信息注入新的对话中,这就是所谓的长期记忆。
为什么要操作聊天历史?
有三个关键原因说明为什么要超越简单地将每条新消息和响应附加到不断增长的列表中并发送给 LLM:
- 注入有用上下文:添加之前交互的信息,例如用户偏好,而不会使当前对话变得杂乱。
- 总结并移除数据:清理模型已经使用过的信息,以避免混乱(上下文污染)并保持模型专注。
- 节省 token:移除不必要的数据,防止填满上下文窗口,从而支持更长、更有意义的对话。
这开启了一些类似科幻的可能性。想象一个 agent 可以根据环境或对话对象选择性地记住信息,就像电视剧《Severance》中的主角 Mark,大脑中植入芯片,根据他是在办公室(“innie”)还是在外面(“outie”)来切换不同的身份和记忆。

记忆类型与 agent 中的选择性检索:使用 Elasticsearch 托管记忆创建智能代理
并非所有记忆都有相同的用途,将它们都当作可互换的聊天历史会限制 agent 的扩展能力。现代 agent 架构(包括 Cognitive Architectures for Language Agents (语言 agents 的认知架构 - CoALA) 等框架)区分程序性记忆、情景记忆和语义记忆。这些架构不再将所有上下文视为一个不断增长的缓冲区,而是认识到每种记忆类型都需要不同的存储、检索和整合策略。
程序性记忆:agent 如何运作
程序性记忆定义 agent 的行为方式,而不是它知道或记住的内容。
在实践中,这包括:
- 何时存储记忆
- 何时检索记忆
- 如何总结对话
- 如何使用工具
在我们的系统中,程序性记忆主要存在于应用代码和 prompts 中,而不存储在 Elasticsearch 中。相反,Elasticsearch 被程序性记忆使用。
程序性记忆决定如何使用记忆,而不是存储什么。
情景记忆:发生了什么
情景记忆捕捉与某个实体和上下文相关的具体经历。
示例:
- “Peter 的生日是明天,他想吃牛排。”
- “Janice 有一份报告要在上午 9 点前完成。”
这是最动态、最个性化的一种记忆形式,如果处理不当,也最容易导致上下文污染。
在我们的架构中:
- 情景记忆以文档形式存储在 Elasticsearch 中
- 每条记忆包含元数据(用户、角色、时间戳、innie 或 outie)
- 检索是选择性的,基于提问者是谁以及所处的上下文
这正是 innie/outie 模型作为情景记忆隔离示例的应用场景。
语义记忆:事实基础
语义记忆表示关于世界的抽象化、通用知识,不依赖于任何单次交互或个人上下文。与情景记忆不同(它与谁在何时说了什么相关),语义记忆关注普遍成立的事实。
在我们的类比中,关于 Lumon(剧集《Severance》中 Mark 工作的公司)的知识属于世界事实,在 innies 和 outies 之间共享。
像公司手册和规则这样的内容,属于作为语义记忆使用的知识。
情景记忆的检索优先考虑精确性和强上下文过滤(例如身份、角色和时间),而语义记忆更偏向高召回、概念层级的检索。它旨在提供一般性真实信息,用于支撑推理,而不是特定场景下的个人经历。
接下来我们进入架构部分,看看这些概念如何转化为 agent 的记忆系统。
前提条件
- Elasticsearch Elastic Cloud Hosted (ECH) 或自托管 9.1+ 实例。
- Python 3.x。
- OpenAI API Key。
该应用的完整 Python notebook 可在此处获取。
为什么选择 Elasticsearch?
Elasticsearch 是存储知识和记忆的理想解决方案,因为它是一个可扩展的原生向量数据库。它为我们提供了管理选择性记忆所需的一切:
为什么选择性记忆可以提升延迟和推理能力
选择性记忆不仅关乎正确性和隔离性,还会直接影响延迟和模型性能。通过在执行语义检索之前使用结构化过滤器(如记忆类型、用户或时间)来缩小搜索空间,Elasticsearch 减少了需要评分的向量数量以及需要注入到 LLM 的上下文量。这带来了更快的检索、更小的提示,以及模型更集中的注意力,实际效果是更低的延迟、更少的 token 使用以及更准确的响应。
情景记忆本质上是时间相关的:最近的经历通常比较旧的更相关,并且并非所有记忆都需要永久以相同的细节级别保留。在人类认知中,经历会逐渐被遗忘、总结或整合为更抽象的知识。
记忆压缩是一个独立的话题,但你可以实现策略来总结并存储旧记忆,同时完整检索新的记忆。
设置
遵循《Severance》的概念,我们创建一个名为 Mark 的 agent,具有两套独立的记忆:
- Innie 记忆:与同事的工作相关对话。
- Outie 记忆:与朋友和家人的个人对话。
当 Mark 与 innie 交流时,他不应记住与 outie 的对话,反之亦然。
构建记忆系统
记忆索引结构
首先,我们定义我们的记忆 schema:
mappings = {
"properties": {
"user_id": {"type": "keyword"},
"memory_type": {"type": "keyword"},
"created_at": {"type": "date"},
"memory_text": {
"type": "text",
"fields": {
"semantic": {
"type": "semantic_text"
}
}
}
}
}注意,我们为 memory_text 使用了多字段(multi-field),这样可以在同一字段内容上同时进行全文搜索,以及使用 Elastic Learned Sparse EncodeR (ELSER) 模型(默认)进行语义搜索。
这使我们在保持结构化元数据用于过滤的同时,也具备了语义搜索能力。
设置文档级别安全
这是使选择性记忆生效的关键部分。我们创建两个独立的角色:一个用于 innies,一个用于 outies,每个角色都内置了查询级别的过滤器。当具有 innie 角色的用户查询 memories 索引时,Elasticsearch 会自动应用过滤器,仅返回 memory_type 等于 "innie" 的记忆。
你可以在这里找到关于访问控制的更多示例,在这里找到关于角色管理的示例。
这是 innie 角色:
innie_role_descriptor = {
"indices": [
{
"names": ["memories"],
"privileges": ["read", "write"],
"query": {
"bool": {
"filter": [
{"term": {"memory_type": "innie"}}
]
}
}
}
]
}我们为 outies 创建一个类似的角色,只是过滤条件改为 "memory_type": "outie"。
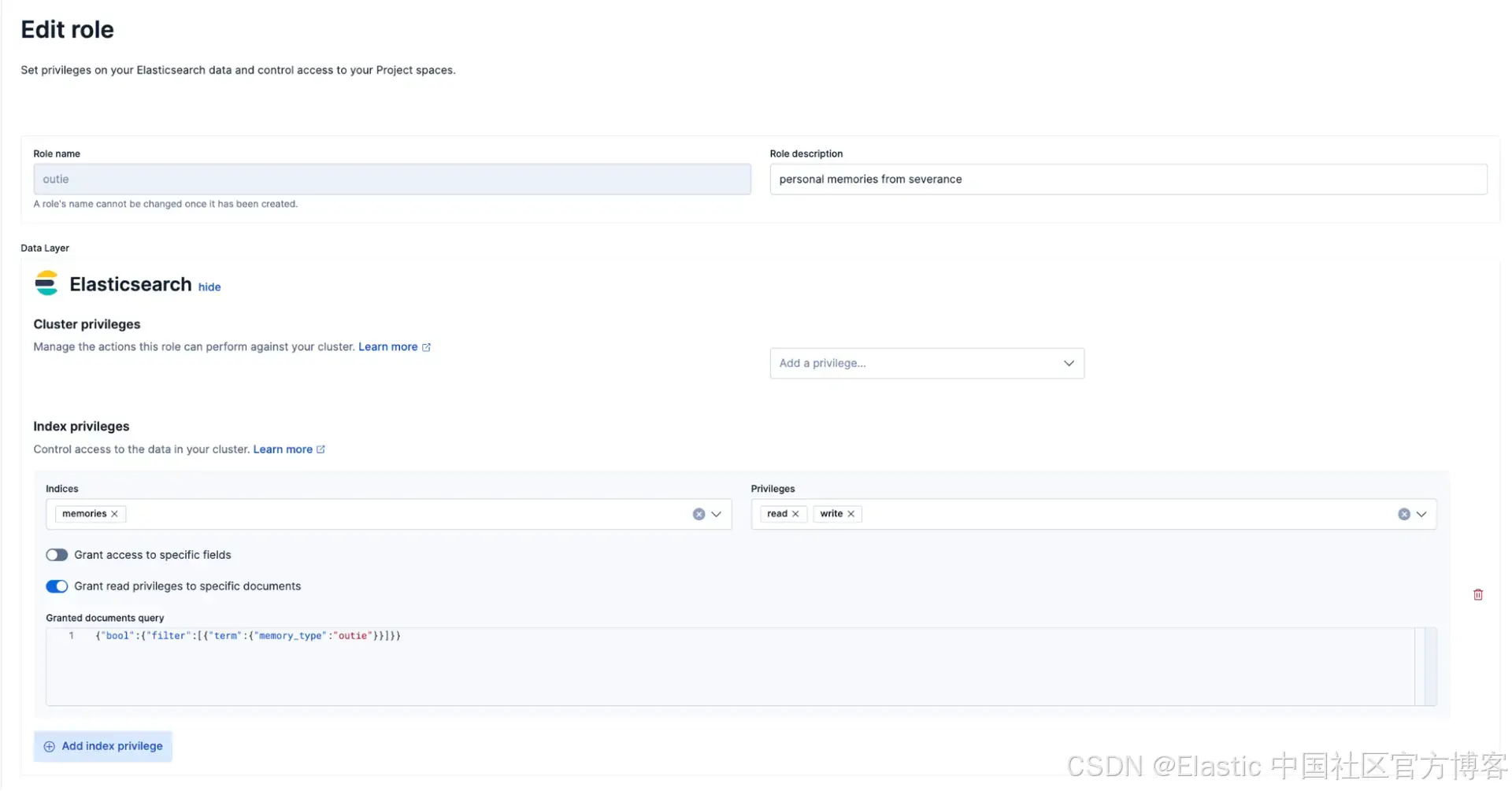
然后我们创建用户并将他们分配到这些角色。例如:
- Peter (outie):只能访问标记为 "outie" 的记忆。
- Janice (innie):只能访问标记为 "innie" 的记忆。
当 Mark (我们的 agent) 收到查询时,他使用发问者的凭证。如果 Peter 提问,Mark 使用 Peter 的凭证,这意味着 Elasticsearch 会自动过滤,只显示 outie 记忆。如果 Janice 提问,则只显示 innie 记忆。
应用程序代码不需要过滤用户管理,并且与应用逻辑完全解耦。Elasticsearch 会自动处理所有安全性。
创建 agent 工具
我们为 agent 定义三个关键功能:
def get_memory(query: str):
es_query = {
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"semantic": {
"field": "semantic_field",
"query": query
}
}
}
},
{
"standard": {
"query": {
"multi_match": {
"query": query,
"fields": ["memory_text"]
}
}
}
}
],
"rank_window_size": 50,
"rank_constant": 20
}
}
}
response = user_es_client.search(index="memories", body=es_query)
return response注意,我们在查询中不应用安全过滤器;Elasticsearch 会根据用户的凭证自动处理。
- SetMemory:存储新记忆(实现使用 LLM 将对话转换为结构化记忆记录)。
Agent 如何使用这些工具
当用户向 Mark 提问时,流程如下:
这是处理此循环的实际代码:
-
用户提问:"What's my favorite family destination?"
-
LLM 决定使用工具:OpenAI 的 Response API 搭配 function calling 让 LLM 决定需要调用 GetMemories,查询为 "favorite family destination"。
-
我们执行函数:我们的代码使用用户的凭证(此例为 Peter)调用 get_memory("favorite family destination")。
-
Elasticsearch 自动过滤:因为我们使用的是 Peter 的凭证,仅返回 outie 记忆:
Memories peter125: (User name is Peter Johnson. His favorite family destination is Disneyland.) -
我们将结果发送回 LLM:记忆被添加到对话上下文中。
-
LLM 生成答案:"Your favorite family destination is Disneyland."
# Initial call with tools available
response = client.responses.create(
model="gpt-4.1-mini",
input=messages,
tools=tools,
parallel_tool_calls=True
)
# Execute any tool calls the LLM requested
for tool_call in response.output:
if tool_call.name == "GetMemories":
result = get_memory(tool_call.arguments["query"])
# Add result to messages
# Call LLM again with tool results to generate final answer
final_response = client.responses.create(
model="gpt-4.1-mini",
input=messages # Now includes tool results
)关键洞察:应用程序不决定检索哪些记忆或何时检索。LLM 根据用户的问题决定,而 Elasticsearch 确保只有正确的记忆可访问。
测试选择性记忆
让我们看看实际效果:
Outie 对话 (Peter):
Peter: Hey Mark, my birthday is tomorrow! I'd like to have a steak for dinner.
Mark: That's great! (memory stored){
"user_id": "peter125",
"memory_type": "outie",
"created_at": "2025-10-11T18:02:52.182780",
"memory_text": "Peter's birthday is tomorrow. He wants steak for dinner."
}Innie 对话 (Janice):
Janice: Hey Mark, remember we have to finish the end of year report tomorrow at 9am.
Mark: Thanks for reminding me! (memory stored){
"user_id": "janice456",
"memory_type": "innie",
"created_at": "2025-10-11T19:15:33.445821",
"memory_text": "End of year report deadline tomorrow at 9am with Janice."
}假设 Peter 也在 Lumon 工作。一位同事存储了一条关于他的工作相关记忆:
{
"user_id": "innie-peter",
"memory_type": "innie",
"created_at": "2025-10-11T20:30:00.000000",
"memory_text": "Peter needs to review the Q4 budget spreadsheet before Friday."
}这条记忆存在于 Elasticsearch 中,但 Peter 当前的凭证只授予他 outie 角色。当他向 Mark 询问工作任务时,这条记忆对他是不可见的;Elasticsearch 的文档级别安全确保它永远不会被返回。
注意:要与这些记忆进行交互,你需要为 Peter 创建一个单独的用户(或分配额外角色),赋予 "innie" 访问权限。这留作练习,但它展示了同一个人可以拥有隔离的记忆上下文,访问完全由安全层控制。
记忆隔离测试
现在 Peter 开始一个新对话:
Peter: Hey Mark, do you remember what I want for my birthday?
Mark: Yes! You want steak.
Peter: When do you have to finish the end of year report?
Mark: What are you talking about?太棒了!Mark 在与 Peter 对话时只访问 outie 记忆。agent 的“脑子”真正分开了,就像剧中一样。
完整实现
完整的可运行实现可在此 notebook 中获得,你可以:
- 设置 Elasticsearch 索引。
- 使用文档级别安全创建角色和用户。
- 使用 OpenAI 的 Response API 构建 agent。
- 测试选择性记忆系统。
结论
记忆不仅仅是存储过去对话的地方。它是 agent 架构的一部分。通过超越原始聊天记录并区分程序性、情节性和语义记忆,我们可以构建推理更清晰、可扩展性更好、在长时间交互中保持专注的 agents。
选择性检索减少上下文污染、降低延迟,并提高发送给 LLM 的信息质量。情节性记忆可按用户和时间过滤,语义记忆可用于将答案建立在共享知识基础上,程序性记忆控制这一切的使用方式和时机。
Elasticsearch 提供了实践中实现这一点的构建模块,通过混合搜索、丰富的元数据、安全性和时间过滤。就像在 Severance 中一样,我们可以创建具有隔离经验和共享世界知识的 agents。不同之处在于,这里的分离是有意且有用的,而不是神秘的。
原文:https://www.elastic.co/search-labs/blog/ai-agent-memory-management-elasticsearch

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)