【AI大模型前沿】Qwen3-VL-Embedding:阿里通义开源的多模态信息检索模型,助力高效跨模态理解与检索
系列篇章💥
前言
在人工智能领域,多模态信息检索一直是研究热点。随着技术的不断发展,如何高效地处理文本、图像、视频等多种模态数据,并实现跨模态的理解与检索,成为亟待解决的问题。阿里通义推出的Qwen3-VL-Embedding模型,凭借其强大的多模态处理能力和高效的检索性能,为这一领域带来了新的突破。
一、项目概述
Qwen3-VL-Embedding是阿里通义基于Qwen3-VL架构开发的多模态信息检索模型,专为处理文本、图像、可视化文档和视频等多种模态输入而设计。该模型能够将不同模态的数据映射到统一的语义空间,生成语义丰富的高维向量,广泛应用于图文检索、视频内容检索、视觉问答等任务。
二、核心功能
(一)多模态输入支持
Qwen3-VL-Embedding支持处理文本、图像、可视化文档和视频等多种模态输入,以及这些模态的任意组合。这种多模态支持使得模型能够处理复杂的输入场景,如图文混合内容、视频与文本描述的结合等,极大地扩展了其应用场景。
(二)统一语义表示
该模型将不同模态的数据映射到同一语义空间,生成语义丰富的高维向量。这种统一表示使得跨模态相似度计算和检索成为可能,例如可以将文本与图像、视频等进行匹配,实现高效的跨模态信息检索。
(三)高效检索能力
采用双塔架构,Qwen3-VL-Embedding能够支持大规模数据的并行处理,快速召回候选结果。这种架构特别适合处理海量数据的检索任务,显著提高了检索效率和响应速度。
(四)灵活性与扩展性
Qwen3-VL-Embedding支持灵活的向量维度选择(64-2048维),并具备量化后仍保持优秀性能的能力。这种灵活性使得模型能够适应不同的存储和计算需求,适用于多种实际部署场景。
(五)任务指令定制
模型支持任务指令定制,开发者可以根据具体任务优化模型表现,提升检索精度。这种定制化能力使得Qwen3-VL-Embedding能够更好地适应不同的应用场景和任务需求。
三、技术揭秘
(一)多模态嵌入
Qwen3-VL-Embedding通过预训练的Qwen3-VL基础模型,将不同模态的数据编码为统一的语义向量。利用对比学习方法,模型学习不同模态之间的对齐表示,确保语义相似的内容在向量空间中距离更近。这种多模态嵌入技术为跨模态检索提供了坚实基础。
(二)双塔架构
模型采用双塔架构,将查询和文档分别编码为独立的向量表示。查询和文档的向量通过余弦相似度计算相关性,实现高效的检索能力。这种架构特别适合处理海量数据的并行计算,显著提升了检索效率。
(三)Matryoshka Representation Learning(MRL)
Qwen3-VL-Embedding支持灵活的向量维度选择,允许用户根据存储和计算需求调整嵌入维度,而无需重新训练。通过在训练过程中同时优化多个维度的嵌入,模型在不同维度下都能保持良好的性能。
(四)量化感知训练(Quantization-Aware Training, QAT)
在训练过程中引入量化感知训练,使生成的嵌入向量在低精度表示(如 int8 或二进制)下仍能保持较高的性能。这种方法显著降低了存储和计算成本,提高了模型在实际部署中的效率。
(五)多阶段训练
Qwen3-VL-Embedding采用多阶段训练范式,包括对比预训练、多任务对比学习和知识蒸馏。通过这些阶段,模型充分利用Qwen3-VL的强大语义理解能力,提供高质量的语义表示和精确的检索机制。
四、性能表现
(一)MMEB-V2基准测试
Qwen3-VL-Embedding-8B模型在MMEB-V2基准测试中取得了最佳性能,超越了所有之前的开源模型。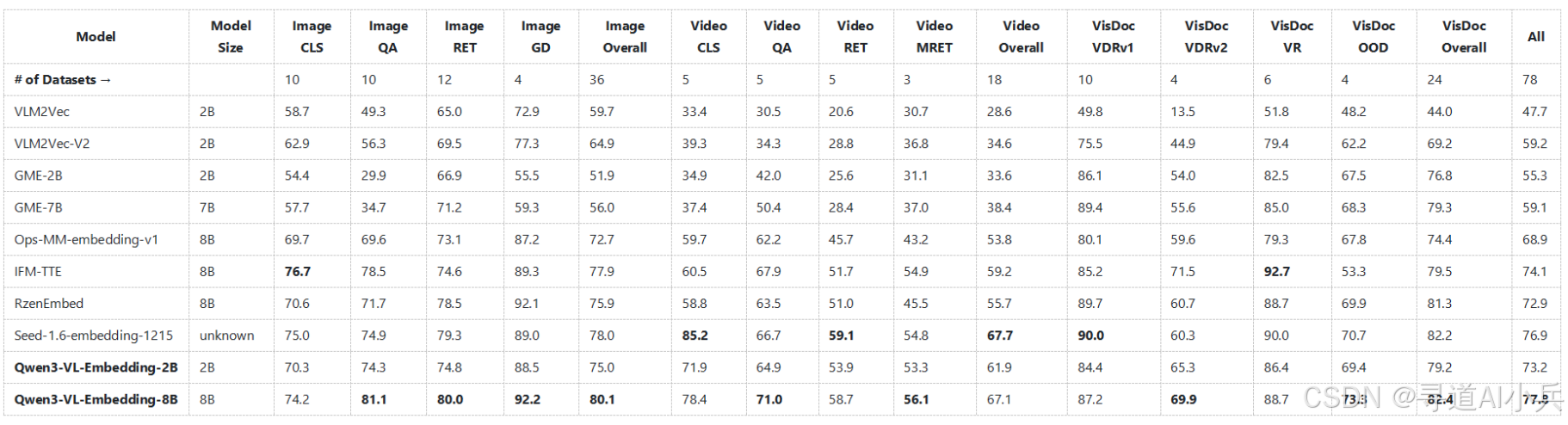
(二)多语言性能
在MTEB多语言基准测试中,Qwen3-VL-Embedding-4B和Qwen3-VL-Embedding-8B模型表现出色,取得了最佳性能。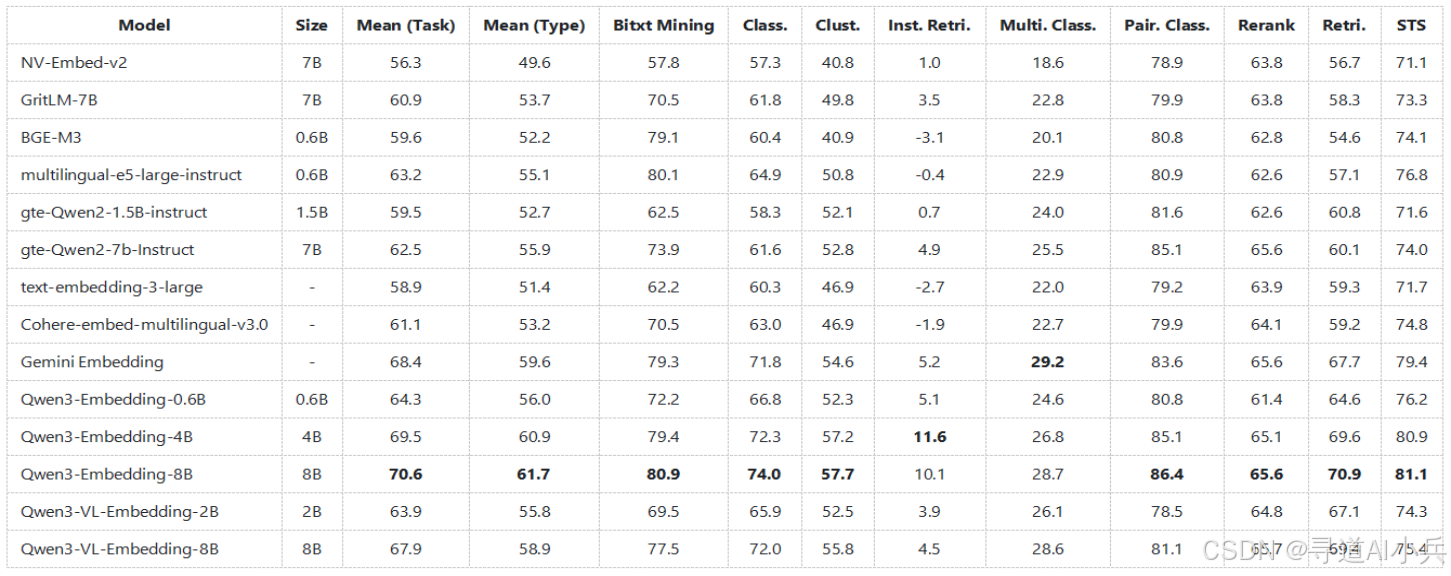
(三)英语、中文和代码性能
在MTEB(英语,v2)、CMTEB(中文)和MTEB(代码)上的评估结果显示出相似的趋势,Qwen3-VL-Embedding-4B和Qwen3-VL-Embedding-8B模型持续优于其他模型。
五、应用场景
(一)图文检索
Qwen3-VL-Embedding在图文检索中表现出色,用户只需输入文本描述,模型即可快速从海量数据中检索出与之相关的图像或视频。这一功能广泛应用于电商平台和社交媒体,帮助用户更高效地发现所需内容,提升用户体验和内容发现效率。
(二)视频内容检索
通过文本或视频片段检索相关视频,Qwen3-VL-Embedding能够精准匹配视频内容,适用于视频平台和新闻媒体。它帮助用户快速找到所需视频片段,支持视频推荐和视频内容管理,提升视频检索的效率和准确性。
(三)视觉问答(VQA)
在视觉问答任务中,用户可以对图像或视频提问,Qwen3-VL-Embedding能够生成准确的答案。这一功能可用于教育平台和智能客服,提供即时的视觉内容解析,帮助用户更好地理解和交互视觉信息。
(四)多模态内容聚类
Qwen3-VL-Embedding能够自动将文本、图像、视频等多模态内容进行分类,便于内容管理系统和企业知识库的组织与管理。这一功能支持内容的自动分类和管理,提高内容管理的效率和准确性。
(五)跨模态推荐系统
Qwen3-VL-Embedding可以根据用户的行为(如浏览、点赞等)推荐相关多模态内容,提升电商平台和社交媒体的个性化体验。它支持跨模态推荐,帮助用户发现更多感兴趣的内容,增强用户参与度。
六、快速使用
(一)环境搭建
克隆项目仓库并进入项目目录:
git clone https://github.com/QwenLM/Qwen3-VL-Embedding.git
cd Qwen3-VL-Embedding
运行脚本设置环境:
bash scripts/setup_environment.sh
激活环境:
source .venv/bin/activate
(二)模型下载
从Hugging Face下载模型:
huggingface-cli download Qwen/Qwen3-VL-Embedding-2B --local-dir ./models/Qwen3-VL-Embedding-2B
(三)示例代码
使用Transformers加载模型并生成嵌入向量:
import torch
from src.models.qwen3_vl_embedding import Qwen3VLEmbedder
model = Qwen3VLEmbedder(model_name_or_path="./models/Qwen3-VL-Embedding-2B")
inputs = [
{"text": "A woman playing with her dog on a beach at sunset."},
{"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"}
]
embeddings = model.process(inputs)
print(embeddings @ embeddings.T)
七、结语
Qwen3-VL-Embedding凭借其强大的多模态处理能力和高效的检索性能,为多模态信息检索领域带来了新的突破。它不仅支持多种模态输入,还通过先进的技术架构和训练方法,实现了卓越的性能表现。无论是图文检索、视频内容检索还是视觉问答等应用场景,Qwen3-VL-Embedding都能提供高效、准确的解决方案。希望本文的介绍能帮助读者更好地了解和使用Qwen3-VL-Embedding模型。
八、项目地址
- GitHub仓库:https://github.com/QwenLM/Qwen3-VL-Embedding
- Hugging Face模型库:https://huggingface.co/collections/Qwen/qwen3-vl-embedding
- 技术论文:https://github.com/QwenLM/Qwen3-VL-Embedding/blob/main/assets/qwen3vlembedding_technical_report.pdf

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)