告别高昂API费用,ComfyUI助你实现免费图像生成

最近在项目上遇到了一个非常头疼的问题——成本。
最开始,我尝试使用智谱清言、豆包等大模型的图像生成 API。不可否认,它们的效果很不错,接入也非常快速。但是,如果你的应用场景需要大量生成图片(比如基于脚本逐句生成视频背景图或分镜),按照每张图5分到1毛的单价计算,跑一个完整项目的账单绝对会让你“肉痛”。
为了在保证出图质量的前提下把成本压到0元,我决定转向本地化部署方案——ComfyUI。
今天这篇文章,我就把今天踩坑、调试 ComfyUI 并将其封装为一个“免费 API 服务”的完整过程记录下来。内容从环境搭建到代码调试,由浅入深,只用ComfyUI最基础的默认工作流,小白也能轻松上手!
1. 为什么选择 ComfyUI?
在开源 AI 绘画领域,WebUI(如 Stable Diffusion WebUI)和 ComfyUI 是两座大山。
相比于 WebUI 的“重度产品化”,ComfyUI 以其节点式(Node-based)的架构设计脱颖而出。你不仅可以像搭乐高一样自由组合生图逻辑,更重要的是,它天生就适合作为 API 供第三方系统调用。
我今天的需求十分简单:只需要最纯粹的“文生图(Text-to-Image)”功能,以此替代昂贵的在线 API。
2. 环境说明:Windows 与 WSL 的“双城记”
很多开发者在部署时会纠结操作系统。我的最终方案是:ComfyUI 跑在 Windows 上,而调用它的 Python 代码跑在 WSL (Windows Subsystem for Linux) 中。
2.1 硬件与环境配置
- 显卡:NVIDIA RTX 3070(8GB 物理显存 + 8GB 共享显存,对于常规的 1080P/4K 初期生图基本够用)
- 宿主机:Windows 11(运行 ComfyUI)
- 开发机:Ubuntu (基于 WSL2,运行 Python 脚本)
2.2 为什么采用这种混合架构?
采用这种“跨次元”架构并不是因为喜欢折腾,而是基于以下考量:
- 显卡驱动与性能(Why Windows):NVIDIA 的显卡驱动和 CUDA 工具包在 Windows 原生环境下兼容性最好,ComfyUI 在 Windows 上可以通过便携包(Standalone)一键运行,省去了大量配置环境的麻烦。
- 开发体验与流水线(Why WSL):我的短视频生成核心代码逻辑(涉及视频处理、Git 管理等)都在 WSL 里面。Linux 拥有更好的开发手感和包管理体验。
为了让你更直观地理解,我们可以看下面这张架构交互图:
3. ComfyUI 安装与避坑指南
3.1 极简安装步骤
-
- 前往 ComfyUI 的 GitHub Release 页面,下载最新的 Windows 版本安装包。
-
- 成功安装后运行服务:
- 我的安装路径选在D盘了, 执行程序安装在:
D:\Users\<换成你的用户名>\AppData\Local\Programs\ComfyUI\resources\ComfyUI - ComfyUI自动把环境配置在C盘, 路径在:
C:\Users\<换成你的用户名>\Documents\ComfyUI\ - 在命令行窗口执行
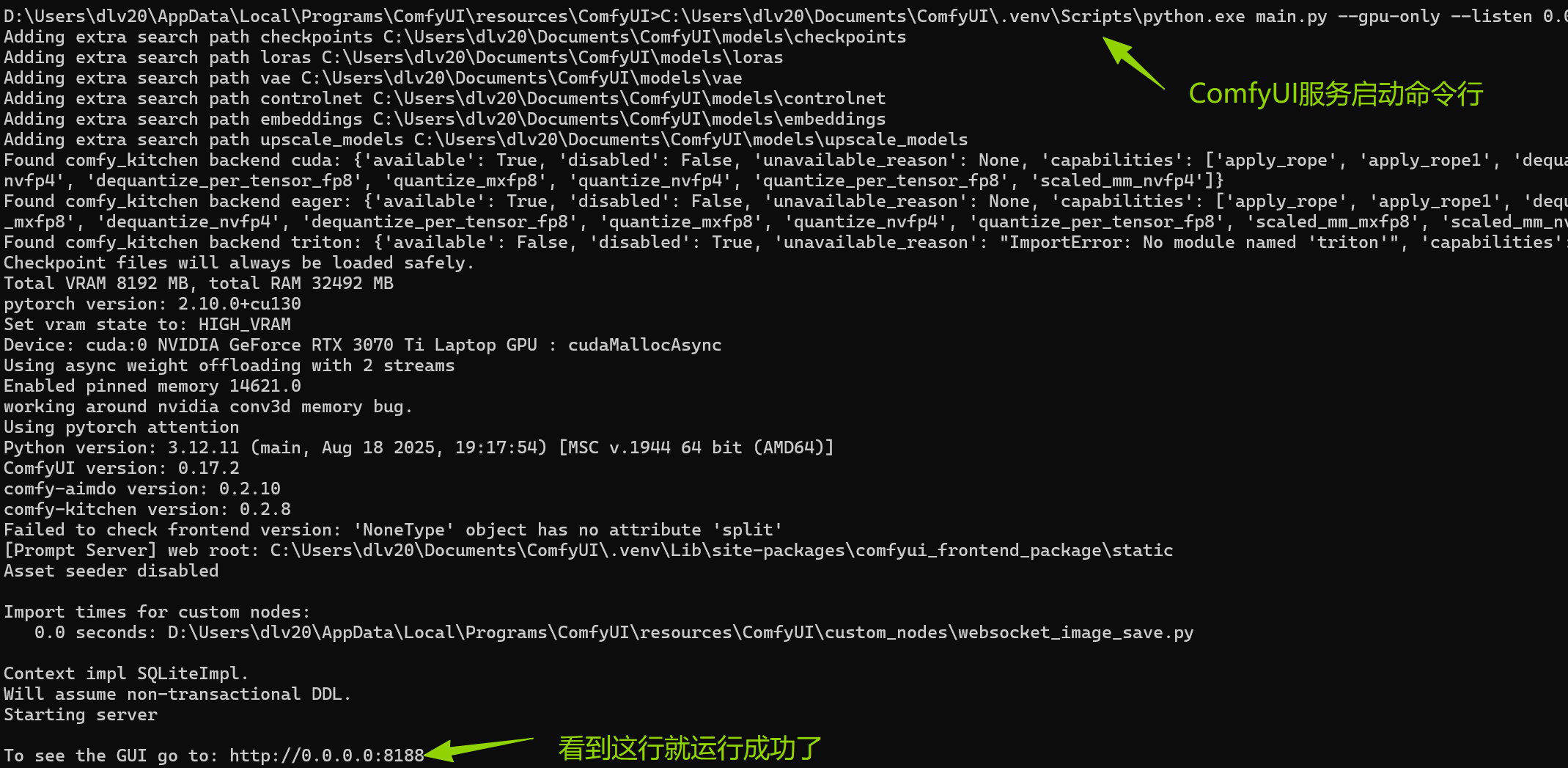
cd /d D:\Users\<换成你的用户名>\AppData\Local\Programs\ComfyUI\resources\ComfyUI C:\Users\<换成你的用户名>\Documents\ComfyUI\.venv\Scripts\python.exe main.py --gpu-only --listen 0.0.0.0 - 其中因为我的宿主机配置了GPU, 所以使用gpu-only;
- 0.0.0.0代表ComfyUI服务监听所有网络接口的请求。这是因为我的WSL并没有配置Netwoking Mirror, 所以我需要WSL上的代码可以通过宿主机的IP,而不是默认的127.0.0.1来访问ComfyUI服务.
-
- 如果运行成功后,使用浏览器访问
http://127.0.0.1:8188,这就是你的控制台。
- 如果运行成功后,使用浏览器访问
-
- SD等必要的渲染模型, 需要放在 "C:\Users<换成你的用户名>\Documents\ComfyUI\models\checkpoints"路径下。 模型文件可以在 huggingface上下载,我刚下载的版本sd_xl_base_1.0.safetensors大概6G多。
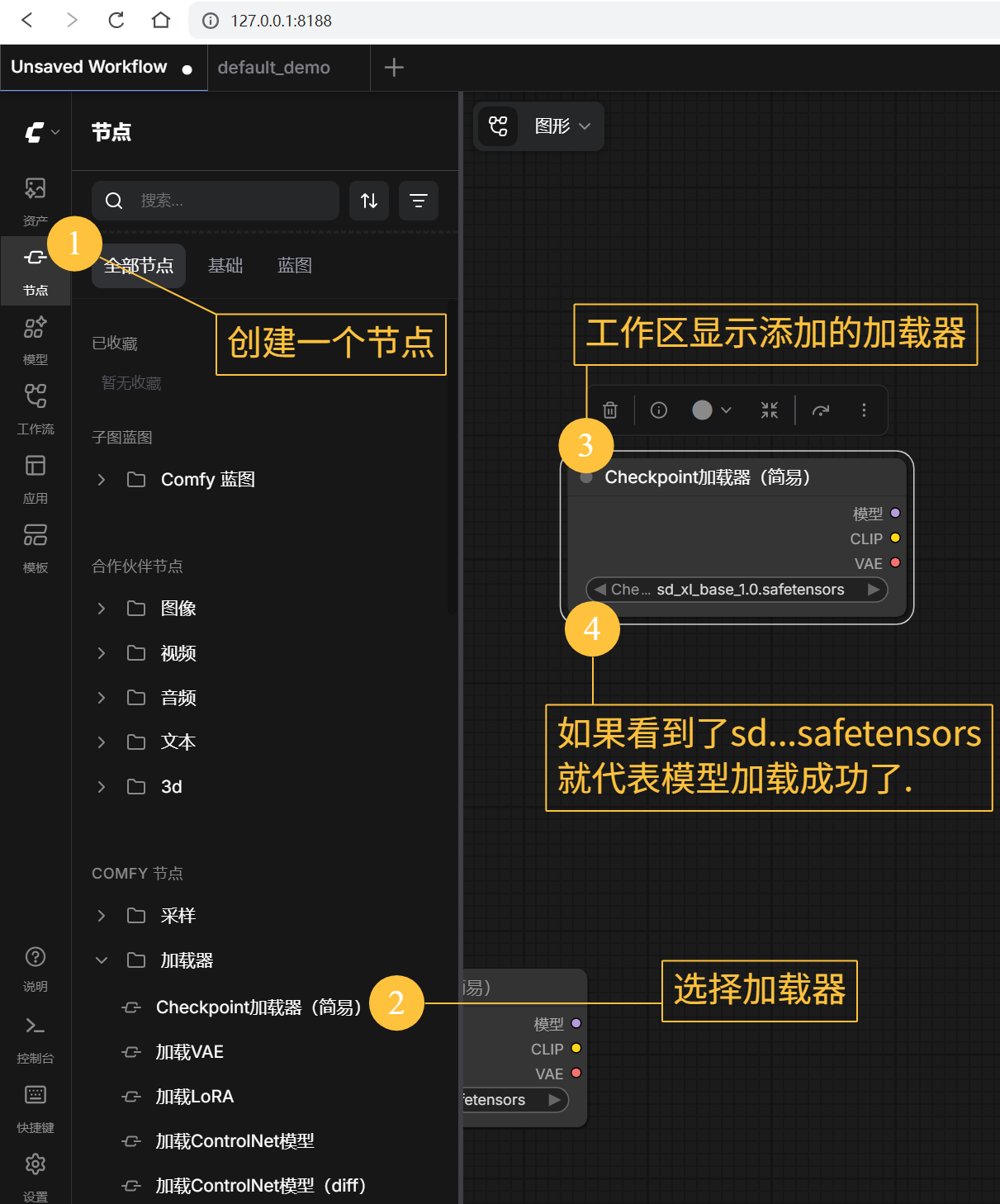
- SD等必要的渲染模型, 需要放在 "C:\Users<换成你的用户名>\Documents\ComfyUI\models\checkpoints"路径下。 模型文件可以在 huggingface上下载,我刚下载的版本sd_xl_base_1.0.safetensors大概6G多。
3.2 踩坑记录一:如何提供后台 API 服务?
很多初学者以为需要复杂的配置才能把 ComfyUI 变成服务。事实上,当你运行 main.py 后,ComfyUI 本身已经是一个标准的、提供 HTTP 完整接口的 API 服务了。
它默认监听在 8188 端口。 当然如果你并不需要通过API来调用,也可以在浏览器上直接操作了。
对于宿主机和WSL之间的通信,我遇到跨端访问的问题。我在 WSL 中无法直接通过 127.0.0.1 访问 Windows 宿主机的8188端口。而我又不想配置WSL的Networking mirror(我的windows和Ubuntu上都有80端口的web服务, mirror的话会导致端口冲突)。
💡 解决办法: 我在windows上通过ipconfig列出了所有的本地IP,然后通过ping命令,找到了WSL上Ubuntu可以访问的IP地址。这样我的Ubuntu就可以使用这个IP来访问Windows上的ComfyUI服务了。
3.3 踩坑记录二:如何建立默认工作流并导出 JSON?
我们要把界面里的连线,变成 Python 能看懂的代码。
-
- 加载默认工作流:点击右侧菜单的
模版,在搜索框中输入default,你会看到一个包含 “Load Checkpoint - CLIP Text Encode - KSampler - VAE Decode - Save Image”的经典流程。如果你不需要API调用, 你就可以试试修改图形界面的CLIP节点中的提示词, 然后点击“运行”按钮, 看看图片的输出效果了。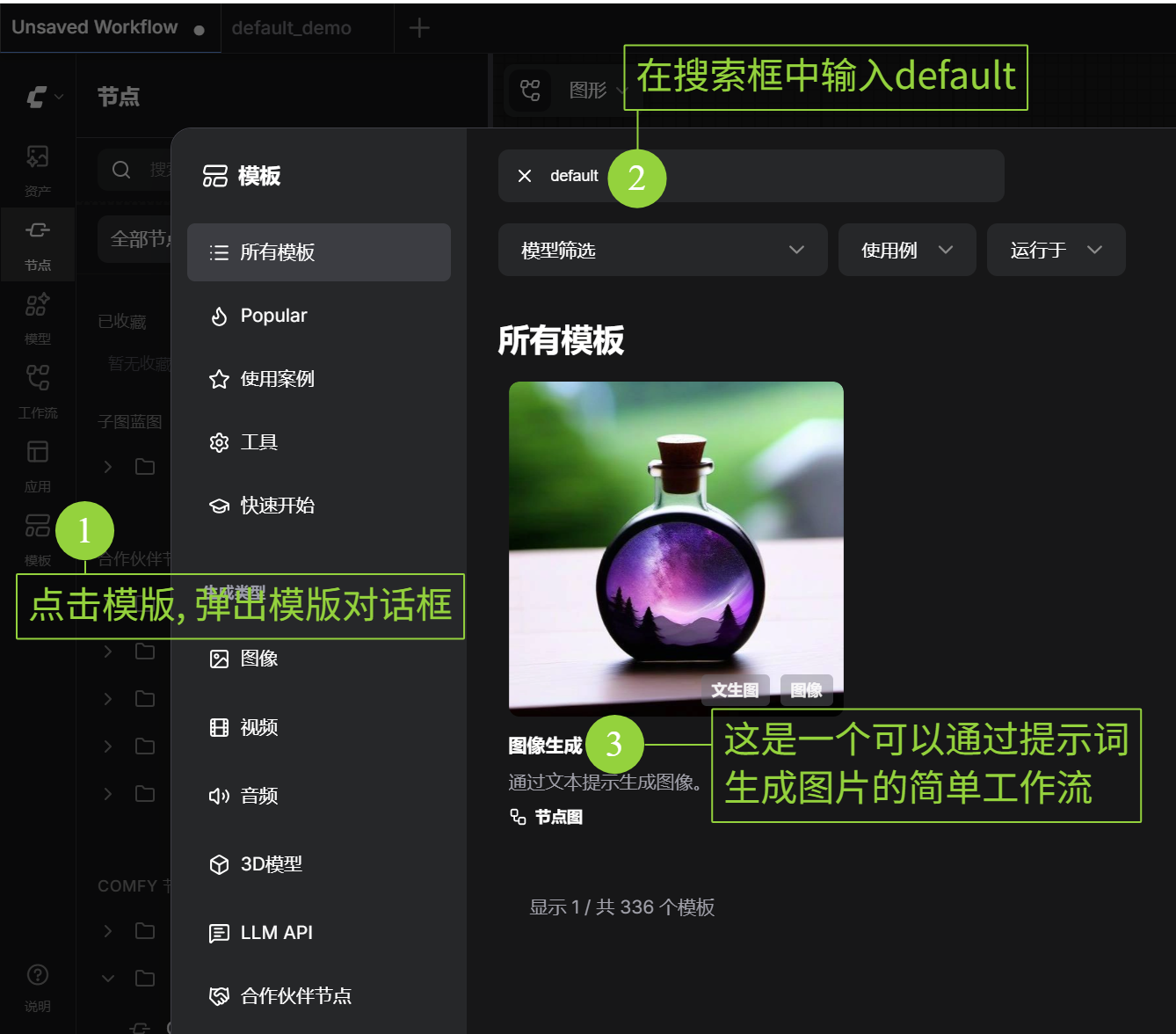
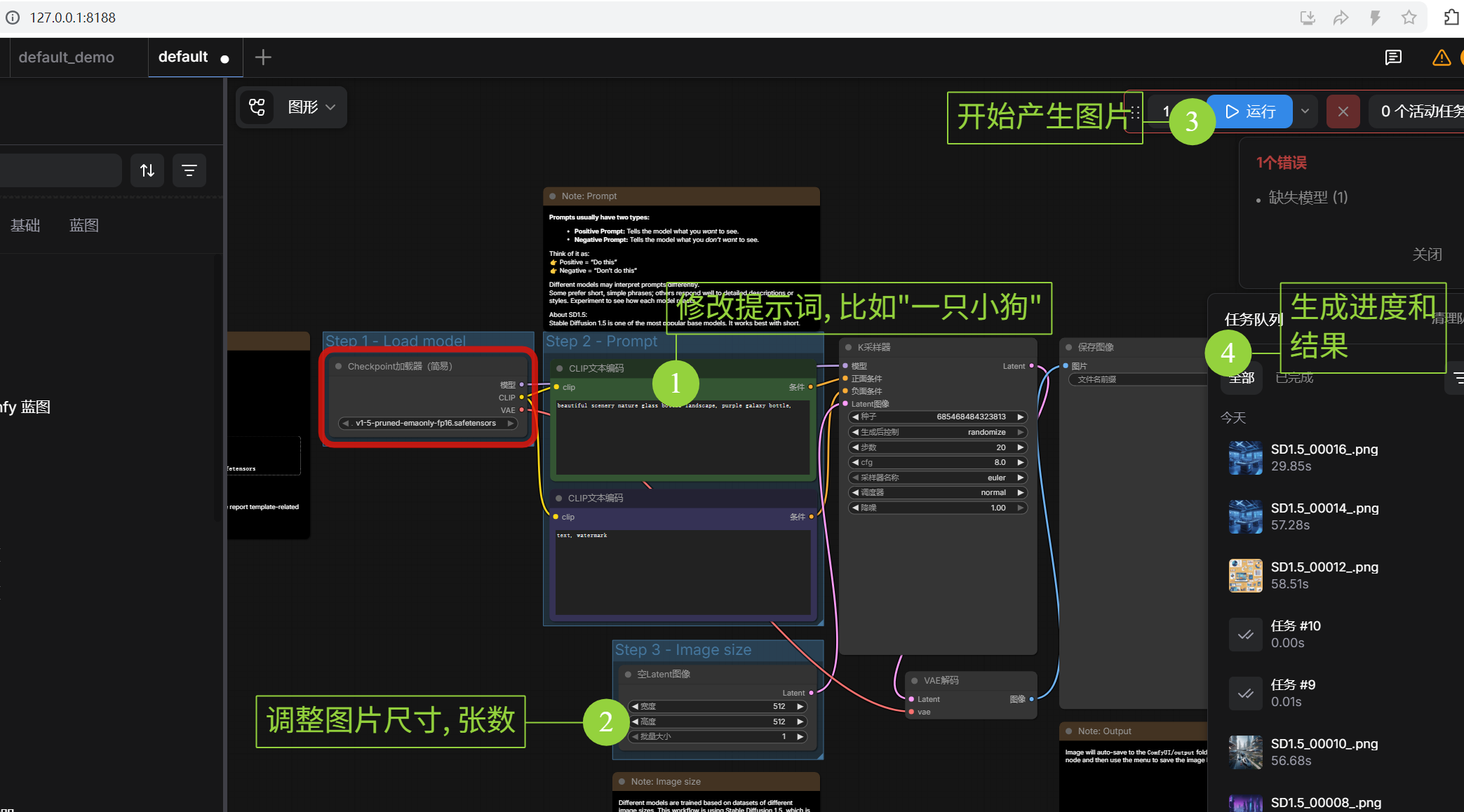
- 加载默认工作流:点击右侧菜单的
-
- 开启开发者选项:默认情况下,你是找不到“导出为 API”的按钮的。点击右侧面板的图标 ⚙️ (Settings),勾选
Enable Dev mode Options。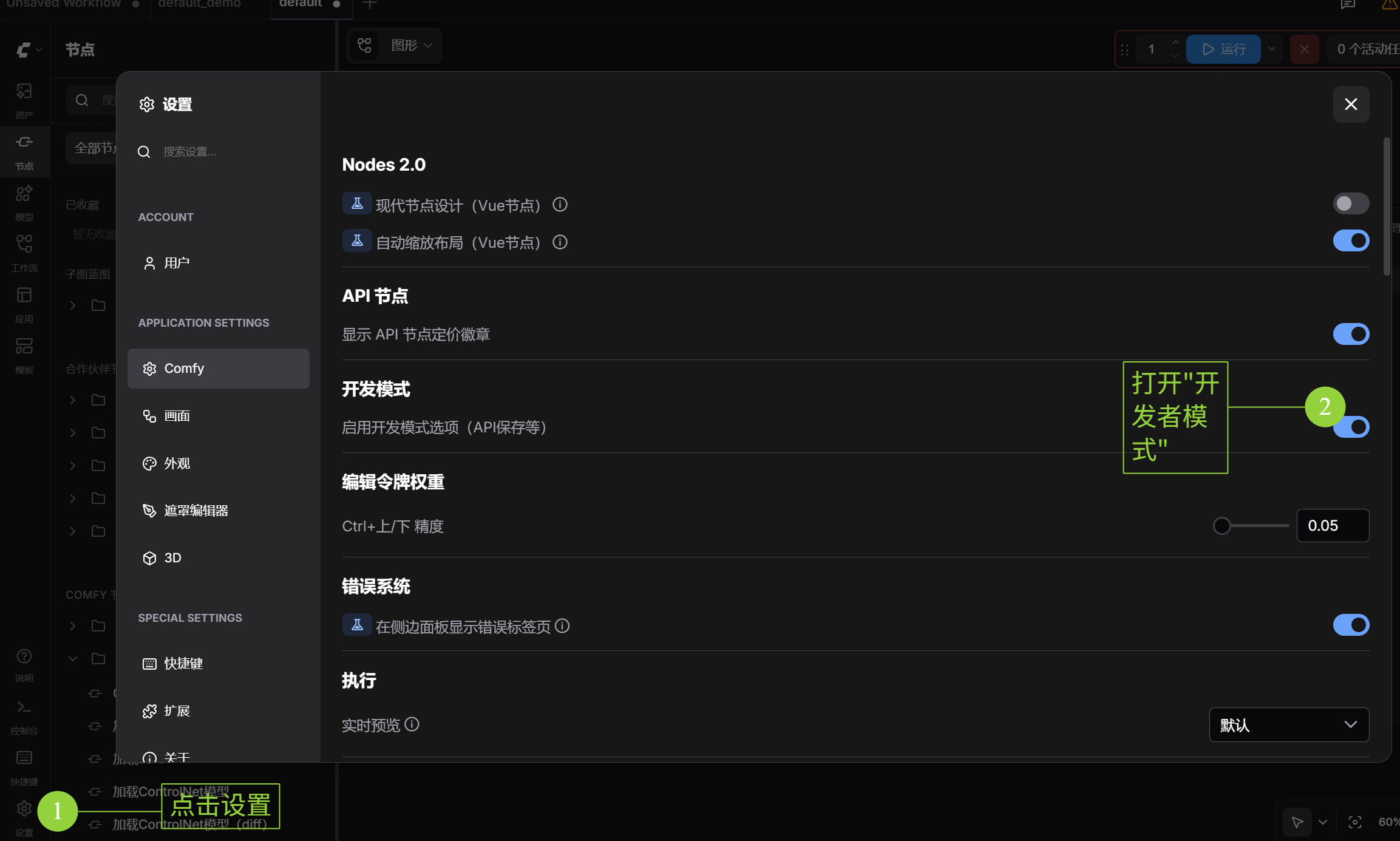
- 开启开发者选项:默认情况下,你是找不到“导出为 API”的按钮的。点击右侧面板的图标 ⚙️ (Settings),勾选
-
- 导出 JSON:回到主界面,点击右侧的
导出 (API),可以下载一个workflow_api.json文件。这个文件就是把工作流框中的节点信息转换成json格式,方便Python调用。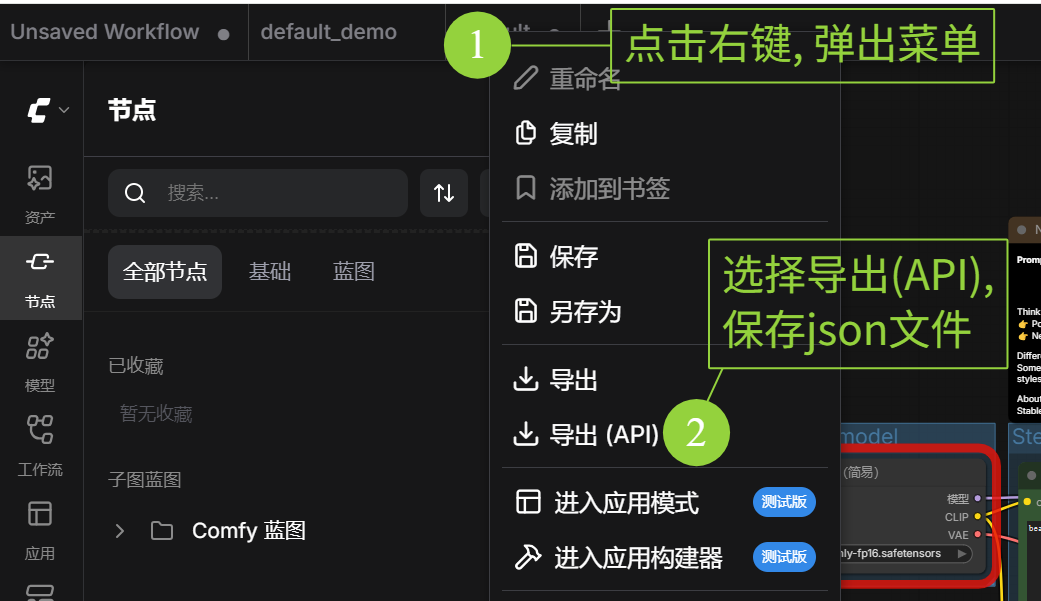
- 导出 JSON:回到主界面,点击右侧的
[!WARNING]
巨坑预警:务必使用 Save Image 节点!
在调试中我发现,如果你在界面里图方便,使用的是Preview Image(预览节点)而不是Save Image(保存节点),导出的 JSON 虽然能提交执行,但它是没有任何物理文件输出的,Python 后续的获取结果会得到一个空的列表[]!务必确保你的最后一棒连接的是标准的保存节点。
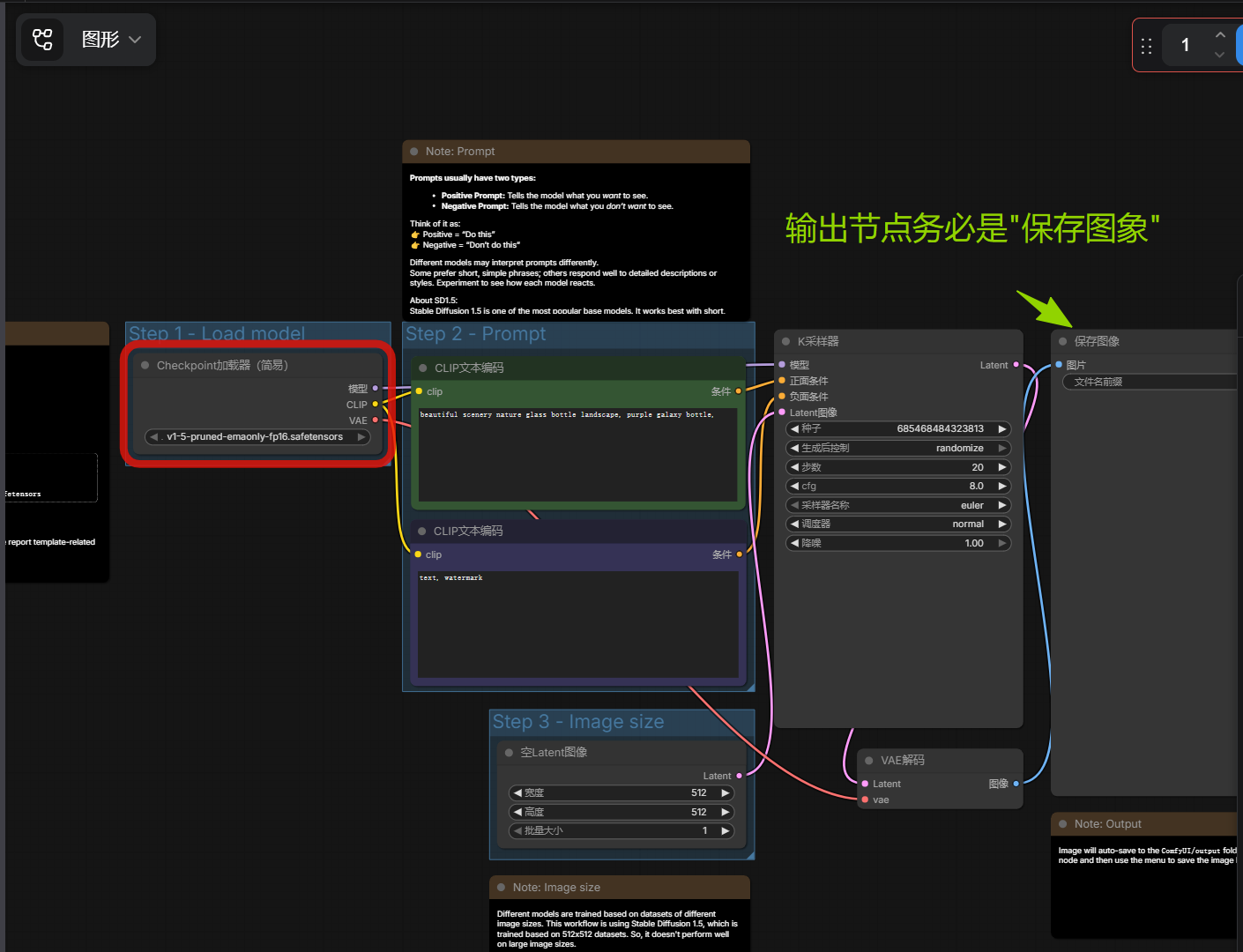
4. Python 代码实战:自动化调用的核心逻辑
在搞定了宿主机服务和 API JSON 后,我们要在 WSL 中写一段 Python 代码来自动化这个流程:
- 替换 Prompt:读取 JSON 并修改提示词。
- 提交任务:发送给 8188 端口。
- 轮询状态并下载:等待生图结束,下载并存储到 WSL 目录。
以下是我优化后能够完美处理单图及多图并发任务的 Python 测试脚本:
4.1 调用ComfyUI服务的代码
# -*- coding: utf-8 -*-
import json
import requests
import time
import subprocess
import os
# 1. 获取宿主机 IP (WSL -> Windows 穿透)
def get_host_ip():
return "127.0.0.1" # 此处务必要替换成你可以访问的宿主机IP !!!!!! 💀💀💀
COMFY_URL = f"http://{get_host_ip()}:8188"
# 2. 下载图片的协助函数
def download_image(filename):
print(f"📥 正在下载: {filename} ...")
url = f"{COMFY_URL}/view?filename={filename}"
try:
r = requests.get(url)
r.raise_for_status()
local_name = f"output_{int(time.time())}_{filename}"
with open(local_name, "wb") as f:
f.write(r.content)
print(f"✨ 保存成功: {local_name}")
except Exception as e:
print(f"❌ 下载失败 {filename}: {e}")
# 3. 主调度函数
def run_task(prompt_text):
print(f"🚀 初始化并加载 workflow_api.json ...")
with open("workflow_api.json", "r", encoding="utf-8") as f:
workflow = json.load(f)
# 这里的 "6" 对应导出 json 中 正向提示词(CLIPTextEncode) 节点的 ID
# 如果你的节点 ID 不同,请根据实际 JSON 结构修改
if "6" in workflow:
workflow["6"]["inputs"]["text"] = prompt_text
print(f"📡 发送生图任务到 ComfyUI ({COMFY_URL})...")
p = requests.post(f"{COMFY_URL}/prompt", json={"prompt": workflow}).json()
prompt_id = p['prompt_id']
print(f"✅ 任务已排队,ID: {prompt_id}")
# 轮询状态处理多图延迟
while True:
h = requests.get(f"{COMFY_URL}/history/{prompt_id}").json()
# history 只有在任务彻底完成后才会出现对应的 prompt_id 键
if prompt_id in h:
outputs = h[prompt_id].get("outputs", {})
if not outputs:
print("⚠️ 任务结束,但没有找到输出!请检查刚才的警告,是否使用了 SaveImage 节点。")
break
print(f"🎨 渲染完成!发现 {len(outputs)} 个输出节点。")
for node_id, node_data in outputs.items():
if "images" in node_data:
for img in node_data["images"]:
download_image(img['filename'])
break
print("⏳ 渲染中,由于可能包含多张图片,请耐心等待...")
time.sleep(2)
if __name__ == "__main__":
# 测试生成指令
run_task("a high-tech laboratory, futuristic, blue lighting, photorealistic, 8k")
4.2 核心调试复盘
在这段代码的编写中,我遇到了一个关于**“多张图片并发响应为空”的问题:
一开始跑脚本时,控制台直接抛出了找不到键值的错误。排查发现,生图是一个重资源操作。如果要生成 Batch Size > 1 或者是多图任务,渲染时间会从 5 秒激增到 15 秒以上。
之前因为没有做轮询(Polling)**等待,请求发出去后直接去拿结果,任务处于 Queued 或 Executing 状态,自然拿不到被保存的 outputs。
因此,加入一个 while True + time.sleep(2) 的设计是极其必要的。只有当 /history 接口的返回值里包含了当前任务的 ID,才说明执行生命周期彻底结束。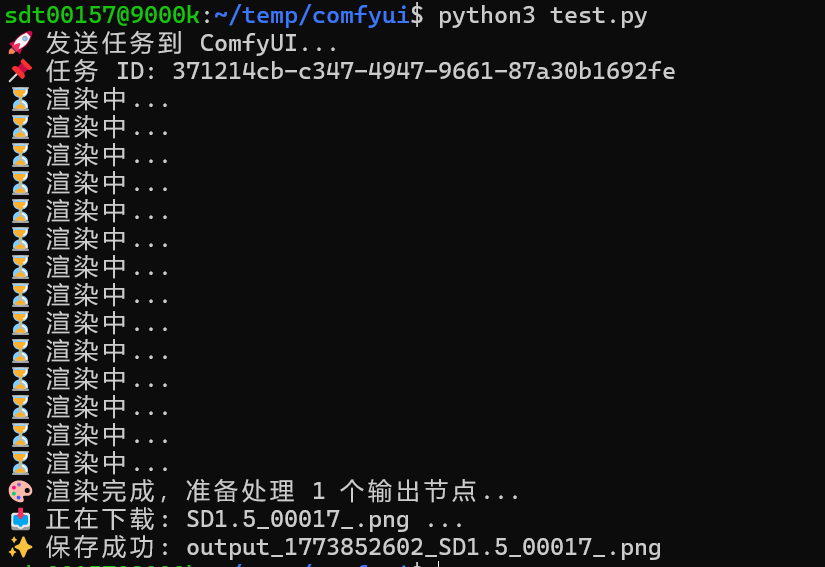
5. 效果与总结
在跑通这个自动化流水线之后,我一连生成了上百张不同领域的转场和背景图。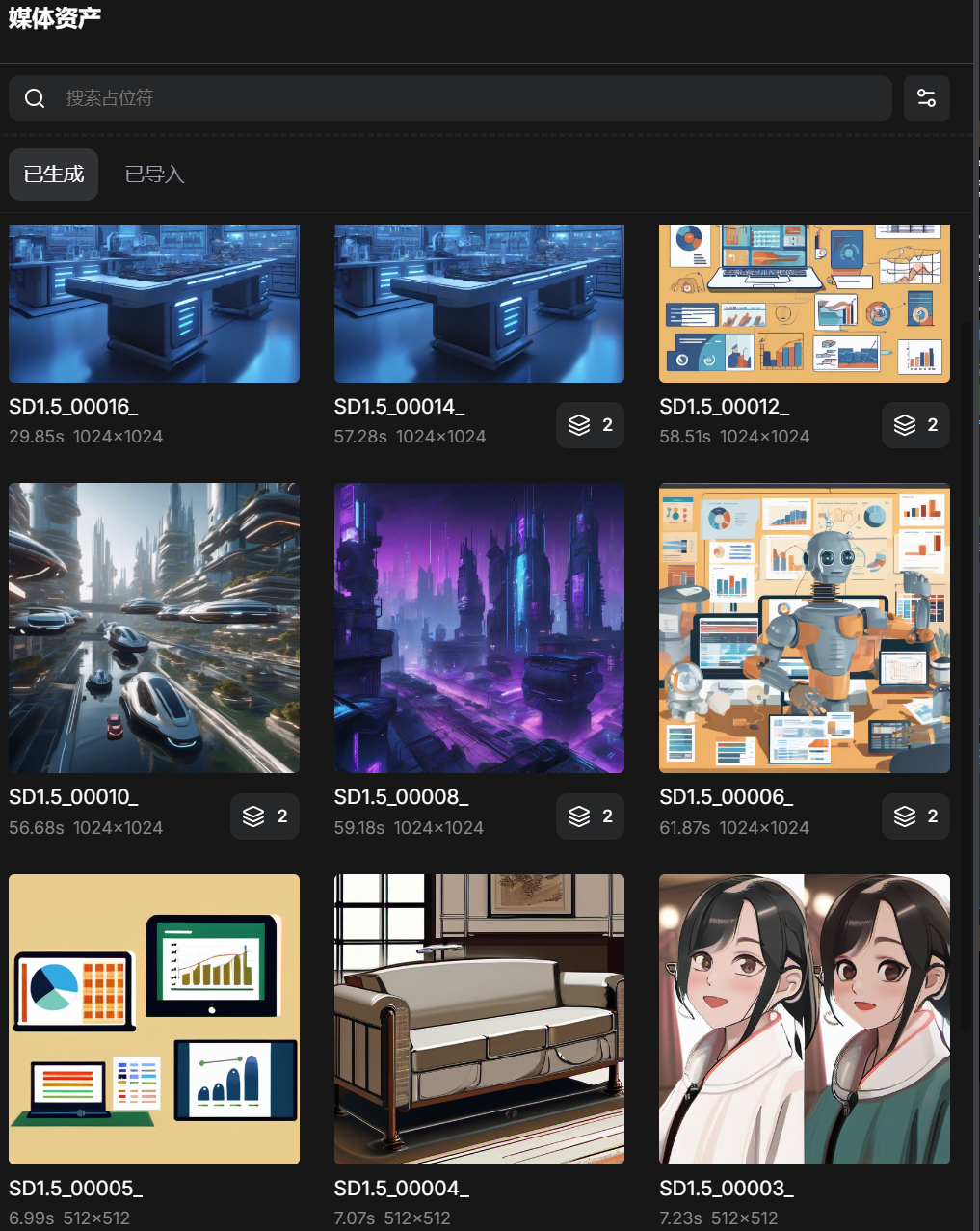
通过本次调试我们可以得出:
- 大规模应用的必备品:如果你要做自动化的视频流水线、小说推文或者批量插图,一定要放弃按量计费的生图 API,把本地 GPU 利用起来。 ComfyUI 这种 Server-Client 结构堪称完美。
- API 的门槛其实很低:无需复杂的编程框架,只需要把可视化连线导出为 JSON,再通过
requests.post发送字典即可,哪怕是编程新手也能在一天内完成改造。 - WSL环境的兼容性佳:事实证明,宿主机(Windows)扛算力、子系统(WSL)跑逻辑这种分层架构不仅不复杂,还能最大化两者的天然优势。
希望这篇博文能帮到由于业务需求被 文生图模型API 费用困扰的朋友们。如果大家感兴趣,下一期我还会讲讲如何在 ComfyUI 内部通过自动化脚本加载不同的 LoRA 模型以及高清放大(Upscale)算法。
欢迎在评论区探讨交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)