AI agent 项目开发
AI基础
LangChainj
目前主流的Java AI开发框架:Spring AI、LangChain4j,提供大量开箱即用的API调大模型和AI开发常用功能如:
- 对话记忆
- 结构化输出
- RAG 知识库
- 工具调用
- MCP
- SSE 流式输出
ChatModel
ChatModel 是最基础的概念,负责和 AI 大模型交互。
首先需要引入至少一个 AI 大模型依赖,这里选择国内的阿里云大模型,提供了和 Spring Boot 项目的整合依赖包,比较方便。在pom.xml中引入依赖:
dev.langchain4j
langchain4j-community-dashscope-spring-boot-starter
1.1.0-beta7
项目
标题项目配置
Java版本:21
springboot:3.5.*
引入依赖:Spring Web,Lombok
将src/resources中application.properties 改为application.yml
application.properties:采用 键值对(key=value) 格式,是传统的配置方式,语法简单直接。如:
server.port=8080
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=123456application.yml:采用 YAML(YAML Ain’t Markup Language) 格式,基于缩进(空格,不能用 Tab)表达层级关系,支持列表、嵌套,语法更简洁、结构化更强。
server:
port: 8080
spring:
datasource:
url: jdbc:mysql://localhost:3306/test
username: root
password: 123456
用 application.properties:
配置项少、层级浅的简单场景;
团队成员不熟悉 YAML 语法,追求最低学习成本;
需要兼容老项目(老项目多使用 properties)。
用 application.yml:
配置项多、层级深(如微服务、数据库 / 缓存 / 消息队列多配置);
需要配置列表 / 数组(如白名单、多环境配置);
追求配置文件的可读性和整洁性。
新建local版本的application.yml文件,防止开源时泄密,修改.gitignore 文件,添加一个自定义的不添加到github上的文件:application-local.yml
### CUSTMO ###
application-local.yml
.gitignore 是 Git 版本控制系统中一个核心的配置文件,作用是告诉 Git:「哪些文件 /
文件夹不需要被追踪(即不纳入版本管理)」。简单来说,它就是 Git 的「忽略清单」,能帮你过滤掉不需要提交到代码仓库的文件。
项目启动类路径:src/main/java/com/example/aicodehelper/AiCodeHelperApplication.java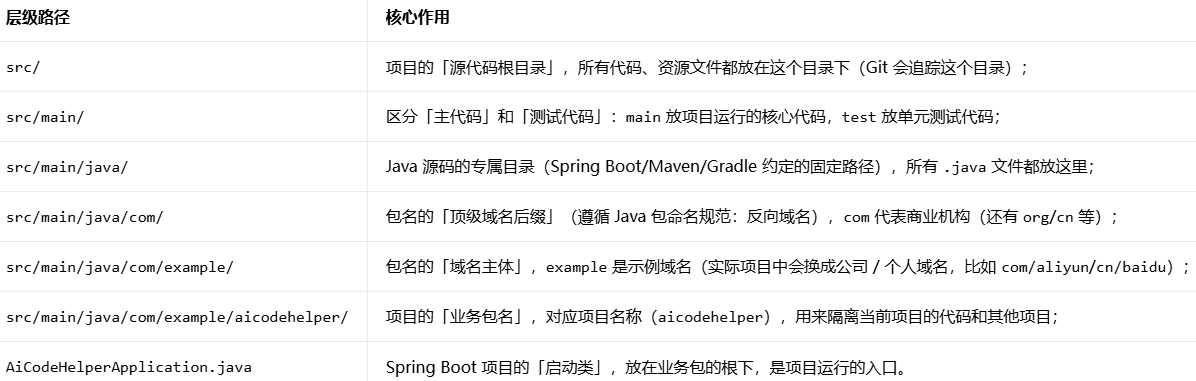
在配置文件中添加大模型配置
注入ChatModel
langchain4j:
community:
dashscope:
chat-model:
model-name: qwen-max
api-key: <You API Key here>
如此一来便有了ChatModel,可以注入
接下来在项目文件中创建AiCodeHelper 类,引入自动注入的 qwenChatModel,编写简单的对话代码,并利用 Lombok 注解打印输出结果日志:
package com.example.aicodehelper.ai;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.chat.response.ChatResponse;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
@Service
@Slf4j
public class AiCodeHelper {
@Resource
private ChatModel qwenChatModel;
//和ai聊天
public String chat(String message) {
UserMessage userMessage = UserMessage.from(message); //在langchain4j中用UserMessage封装用户消息
ChatResponse chatResponse = qwenChatModel.chat(userMessage); //模型输出
AiMessage aiMessage = chatResponse.aiMessage(); //从输出中提取模型的回复
log.info("AI输出:"+aiMessage.toString()); //调试的时候采用.toString()
return aiMessage.text(); //获取ai的文本回复用.text()
}
}
LangChain4j 中使用多模态的方法很简单,用户消息中可以添加图片、音视频、PDF 等媒体资源。
具体做法是通过UserMessage传递,UserMessage可以接收多模态的数据
UserMessage userMessage = UserMessage.from(
TextContent.from("描述图片"),
ImageContent.from("https://www.codefather.cn/logo.png")
);
但实现多模态agent的前提是使用的大模型支持多模态。
系统提示词-SystemMessage
系统提示词是设置 AI 模型行为规则和角色定位的隐藏指令,用户通常不能直接看到。
可以定义一个常量字符串保存系统提示词:
private static final String SYSTEM_MESSAGE = """
你是编程领域的小助手,帮助用户解答编程学习和求职面试相关的问题,并给出建议。重点关注 4 个方向:
1. 规划清晰的编程学习路线
2. 提供项目学习建议
3. 给出程序员求职全流程指南(比如简历优化、投递技巧)
4. 分享高频面试题和面试技巧
请用简洁易懂的语言回答,助力用户高效学习与求职。
""";
然后在传消息给大模型的时候将系统提示词一起传过去:
public String chat(String message) {
SystemMessage systemMessage = SystemMessage.from(SYSTEM_MESSAGE);
UserMessage userMessage = UserMessage.from(message); //在langchain4j中用UserMessage封装用户消息
ChatResponse chatResponse = qwenChatModel.chat(systemMessage,userMessage); //模型输出
AiMessage aiMessage = chatResponse.aiMessage(); //从输出中提取模型的回复
log.info("AI输出:"+aiMessage.toString()); //调试的时候采用.toString()
return aiMessage.text(); //获取ai的文本回复用.text()
}
首先创建SystemMessage 对象接收系统提示词,然后在qwenChatModel.chat传入,直接在userMessage之前传入就行了。
AI服务-AI Service
首先引入 langchain4j 依赖:
dev.langchain4j
langchain4j
1.1.0
然后创建AI Service服务接口,采用声明式开发方法,编写一个对话方法,然后可以直接通过 @SystemMessage 注解定义系统提示词。
public interface AiCodeHelperService {
@SystemMessage("你是一位编程小助手")
String chat(String userMessage);
}
同时,@SystemMessage 注解支持从文件中读取系统提示词:
public interface AiCodeHelperService {
@SystemMessage(fromResource = "system-prompt.txt")
String chat(String userMessage);
}
然后编写工厂类,用于创建 AI Service:
工厂类(Factory Class)是编程中创建型设计模式的核心实现,可以理解成 “对象生产车间”:它不直接让你用 new
关键字创建对象,而是通过专门的工厂类方法来封装对象的创建逻辑,对外提供统一的创建入口。 public class
AiCodeHelperFactory {
// 工厂方法:根据类型创建不同的实现类对象
public static AiCodeHelperService createService(String type) {
if (“openai”.equals(type)) {
return new OpenAiCodeHelperServiceImpl();
} else if (“local”.equals(type)) {
return new LocalAiCodeHelperServiceImpl();
}
throw new IllegalArgumentException(“不支持的AI类型”);
} }// 使用工厂类创建对象(无需关心具体实现类) AiCodeHelperService service =
AiCodeHelperFactory.createService(“openai”); String result =
service.chat(“帮我写一段Java代码”);
核心特点:
隐藏对象创建的细节(比如实现类的初始化、依赖注入、配置加载);
统一管理对象创建,修改创建逻辑时只需改工厂类,无需修改所有调用处;
解耦 “对象使用” 和 “对象创建”。
@Configuration
public class AiCodeHelperServiceFactory {
@Resource
private ChatModel qwenChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService() {
return AiServices.create(AiCodeHelperService.class, qwenChatModel);
}
}
调用 AiServices.create 方法就可以创建出 AI Service 的实现类了,背后的原理是利用 Java 反射机制创建了一个实现接口的代理对象,代理对象负责输入和输出的转换,比如把 String 类型的用户消息参数转为 UserMessage 类型并调用 ChatModel,再将 AI 返回的 AiMessage 类型转换为 String 类型作为返回值。
编写单元测试,调用我们开发的 AI Service:
@SpringBootTest
class AiCodeHelperServiceTest {
@Resource
private AiCodeHelperService aiCodeHelperService;
@Test
void chat() {
String result = aiCodeHelperService.chat("你好,我是程序员鱼皮");
System.out.println(result);
}
}
结构化输出
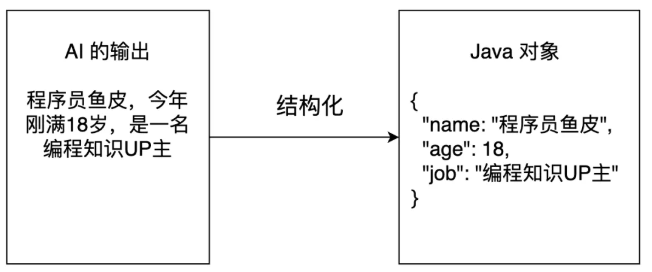
结构化输出有 3 种实现方式:
- 利用大模型的 JSON schema
- 利用 Prompt + JSON Mode
- 利用 Prompt
利用 Prompt:
默认是 Prompt 模式,也就是在原本的用户提示词下拼接一段内容 来指定大模型强制输出包含特定字段的 JSON 文本。
你是一个专业的信息提取助手。请从给定文本中提取人员信息,
并严格按照以下 JSON 格式返回结果:
{
"name": "人员姓名",
"age": 年龄数字,
"height": 身高(米),
"married": true/false,
"occupation": "职业"
}
重要规则:
1. 只返回 JSON 格式,不要添加任何解释
2. 如果信息不明确,使用 null
3. age 必须是数字,不是字符串
4. married 必须是布尔值
这样方法并不严格,最后的输出可能不会按结构化格式输出。
JSON schema:
底层接口实现:
采用 JSON Schema 模式,直接在请求中约束 LLM 的输出格式。这是目前最可靠、精确度最高的结构化输出实现。
ResponseFormat responseFormat = ResponseFormat.builder()
.type(JSON)
.jsonSchema(JsonSchema.builder()
.name("Person")
.rootElement(JsonObjectSchema.builder()
.addStringProperty("name")
.addIntegerProperty("age")
.addNumberProperty("height")
.addBooleanProperty("married")
.required("name", "age", "height", "married")
.build())
.build())
.build();
ChatRequest chatRequest = ChatRequest.builder()
.responseFormat(responseFormat)
.messages(userMessage)
.build();
流程: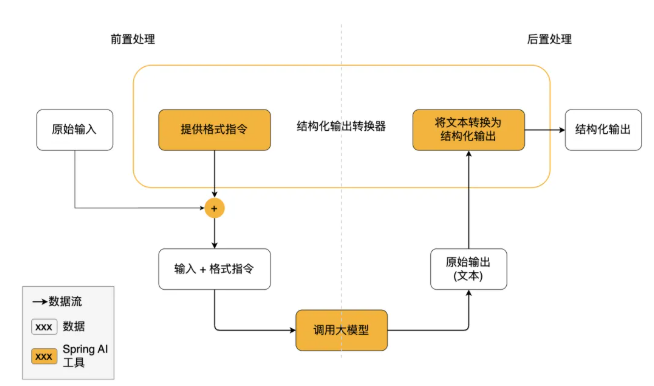
在代码中使用JSON schema进行结构化约束:
比如我们增加一个 让 AI 生成学习报告 的方法,AI 需要输出学习报告对象,包含名称和建议列表
@SystemMessage(fromResource = "system-prompt.txt")
Report chatForReport(String userMessage);
// 学习报告
record Report(String name, List<String> suggestionList){}
record Report(String name, List<String> suggestionList){} :AI 框架会基于你定义的 Report 记录类(record)「自动生成 JSON Schema」并注入到系统提示中
record Report(String name, List suggestionList){} 本质是 Java 的类型定义(类似定义一个类),而非可直接执行的方法 / 函数,所以你看不到像 new Report(…) 或 report.xxx() 这样的 “调用”,但它的作用贯穿整个 chatForReport 方法的执行流程。
编写单元测试:
@Test
void chatForReport() {
String userMessage = "你好,我是程序员鱼皮,学编程两年半,请帮我制定学习报告";
AiCodeHelperService.Report report = aiCodeHelperService.chatForReport(userMessage);
System.out.println(report);
}
RAG
极简版
引入依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.1.0-beta7</version>
</dependency>
然后使用内置的文档加载器读取文档,然后利用内置的 Embedding 模型将文档转换成向量,并存储在内置的 Embedding 内存存储中,最后给 AI Service 绑定默认的内容检索器。
// RAG
// 1. 加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
// 2. 使用内置的 EmbeddingModel 转换文本为向量,然后存储到自动注入的内存 embeddingStore 中
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
// RAG:从内存 embeddingStore 中检索匹配的文本片段
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
标准版
为了更好地效果,我们需要:
加载 Markdown 文档并按需切割
Markdown 文档补充文件名信息
自定义 Embedding 模型
自定义内容检索器
在 Spring Boot 配置文件中添加 Embedding 模型配置,使用阿里云提供的 text-embedding-v4 模型:
langchain4j:
community:
dashscope:
chat-model:
model-name:qwen-max
api-key:<YouAPIKeyhere>
embedding-model:
model-name:text-embedding-v4
api-key:<YouAPIKeyhere>
编写RAG配置类,创建并交给Spring管理一个内容检索器。
这个检索器会在当用户提问时,自动去本地文档中查找最相关的答案片段。
@Configuration
public class RagConfig {
@Resource
private EmbeddingModel qwenEmbeddingModel;
private EmbeddingStore<TextSegment> embeddingStore; //向量存储器
@Bean
public ContentRetriever contentRetriever(QwenChatModel qwenChatModel){ //内容检索器
//---RAG---
//1.加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
//2.文档分割,每个文档按照段落进行分割,最大1000个字符,每次最多重叠100个字符
DocumentByParagraphSplitter documentByParagraphSplitter =
new DocumentByParagraphSplitter(1000, 200);//使用Langchain4j提供的文档分割器
//3.自定义文档加载器,将文档转换为向量并保存到向量知识库中
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(documentByParagraphSplitter)
//为提高检索质量,为每个切割后的文档碎片TextSegment添加文档名作为元信息
.textSegmentTransformer(textSegment->TextSegment.from(textSegment.metadata().getString("file_name")+
"\n"+textSegment.text(),textSegment.metadata()))
//使用的向量模型
.embeddingModel(qwenEmbeddingModel)
//前面注入的向量存储器
.embeddingStore(embeddingStore)
.build();
//加载文档
ingestor.ingest(documents);
//4.自定义内容加载器,检索向量知识库中知识
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddingModel)
.maxResults(5) //最多存五条
.minScore(0.75) //过滤分数小于0.75的结果
.build();
return contentRetriever;
}
}
其中EmbeddingStoreIngestor为入库工具
//3.自定义文档加载器,将文档转换为向量并保存到向量知识库中
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(documentByParagraphSplitter)
//为提高检索质量,为每个切割后的文档碎片TextSegment添加文档名作为元信息
.textSegmentTransformer(textSegment->TextSegment.from(textSegment.metadata().getString("file_name")+
"\n"+textSegment.text(),textSegment.metadata()))
//使用的向量模型
.embeddingModel(qwenEmbeddingModel)
//前面注入的向量存储器
.embeddingStore(embeddingStore)
.build();
EmbeddingStoreIngestor做的事:
- 把文档切分成碎片
- 给碎片加上文件名(提升检索质量)
- 把文本转成向量
- 把向量存进向量库
EmbeddingStoreIngestor只负责将知识存入向量知识库。
EmbeddingStoreContentRetriever为检索工具
//4.自定义内容加载器,检索向量知识库中知识
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddingModel)
.maxResults(5) //最多存五条
.minScore(0.75) //过滤分数小于0.75的结果
.build();
EmbeddingStoreContentRetriever要做的事:
- 用户提问 → 转成向量
- 去向量库里找最相似的内容
- 按分数过滤(>0.75)
- 最多返回 5 条
- 把结果返回给大模型
EmbeddingStoreContentRetriever只负责从向量知识库中取出知识。
紧接着就可以在AIService中使用RAG了
首先在AiCodeServiceFactory中注入检索知识构造器ContentRetriever
@Resource
private ContentRetriever contentRetriever;
然后就可以在构造aiCodeHelperService时加上自定义的检索知识构造器
AiCodeHelperService aiCodeHelperService=AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.contentRetriever(contentRetriever) //RAG
.build();
上文程序出现错误:langchain4j-easy-rag 1.1.0-beta7 没有自动创建 EmbeddingStore Bean!
Spring容器中没有EmbeddingStore,上面程序中注入EmbeddingStore时报错。
需要手动创建EmbeddingStore的配置类来创建EmbeddingStore Bean
创建EmbeddingStoreConfig:
package com.example.aicodehelper.ai.rag;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class EmbeddingStoreConfig {
// 直接创建内存向量存储 → 立刻解决报错
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return new InMemoryEmbeddingStore<>();
}
}
在AI Service中新增方法,在原本的返回类型外封装一层Result类,就可以获得封装后的结果,包括RAG引用的源文档、消耗的Token情况等。
首先在AiCodeHelperService中创建chatWithRag方法,返回类型为Result
SystemMessage自动生成chatWithRag方法
//返回封装后的结果
@SystemMessage(fromResource = “system-prompt.txt”)
Result chatWithRag(String userMessage);
LangChain4j 就会 自动动态实现方法
不需要写 impl 类,不需要写方法体!
条件 1:方法在 接口 里(不能是 class)
java
运行
public interface AiCodeHelperService { // 必须是 interface
// 方法在这里
}
条件 2:接口被 LangChain4j 识别为 AI 服务
满足任意一种即可:
1.使用了 langchain4j-easy-rag
2.接口上加了 @AiService 注解() (langchain4j-easy-rag 会自动扫描所有接口,不需要 @AiService:只要满足:1.是 interface 2.方法上有 @SystemMessage 或 @UserMessage
easy-rag 就会自动把它当成 AI 服务,并自动生成实现!)
3.通过 Spring 自动扫描
条件 3:方法上 必须加 AI 提示词注解
只能是这两个之一:
@SystemMessage(…) ✅
@UserMessage(…) ✅
测试:
@Test
void chatWithRag() {
Result<String> result = aiCodeHelperService.chatWithRag("怎么学习JAVA,有什么常见的面试题");
System.out.println(result.sources()); //获取RAG的源文档
System.out.println(result.content()); //获取实际输出内容
}
result.sources()获取RAG的源文档
result.content()获取实际输出内容
Agent相关概念
什么是agent
agent:大模型为"大脑",能自主感知环境、做出决策、调用工具、完成多步骤任务的程序。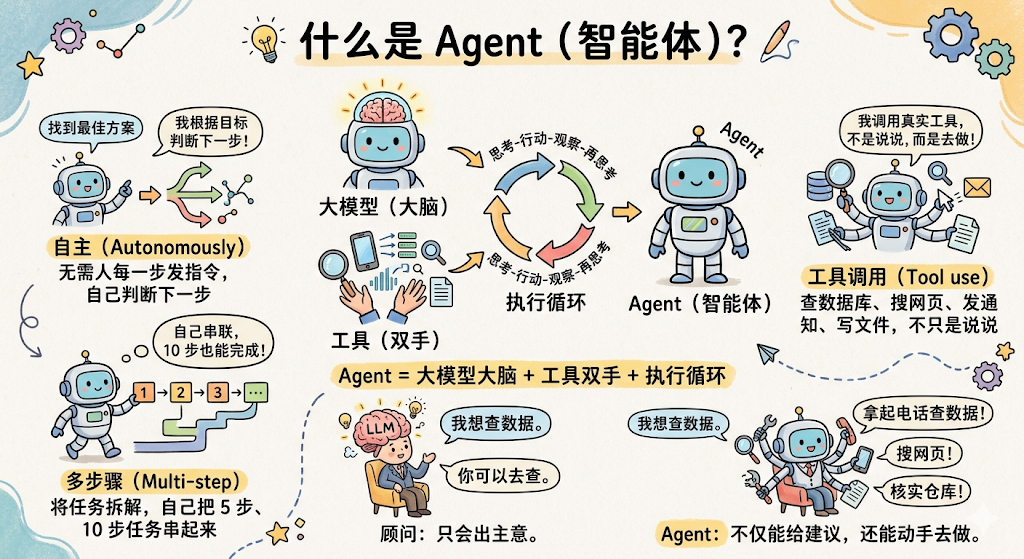
为什么需要Agent
大模型的三大短板:
1.没有执行能力 :只能生成文字,不能操作外部系统
2.知识有截止日期 :不知道最新数据,看不到你的私有系统
3.没有持久记忆 :每次调用对它都是全新的,不能积累任务中间状态
Agent 的价值在于:把大模型的 灵活推理能力 和真实工具的 执行能力 结合在一起,让系统能处理那些 你没法提前穷举所有情况 的复杂任务。
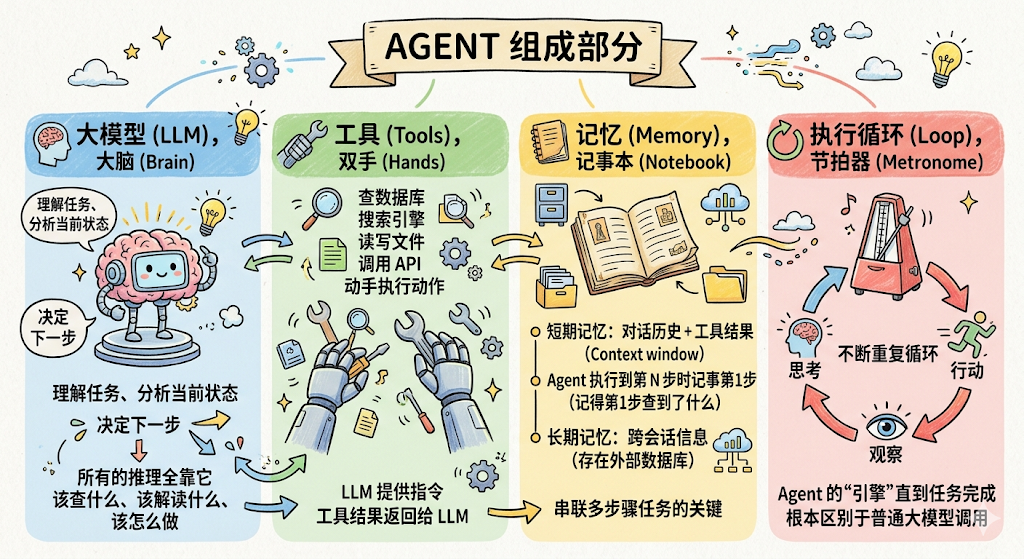
Agent的核心组成
Agent工作范式
ReAct 循环
目前最主流的 Agent 工作范式叫做 ReAct ,全称 Reasoning + Acting: 推理(Think)→ 行动(Act)→ 观察(Observe)→ 再推理……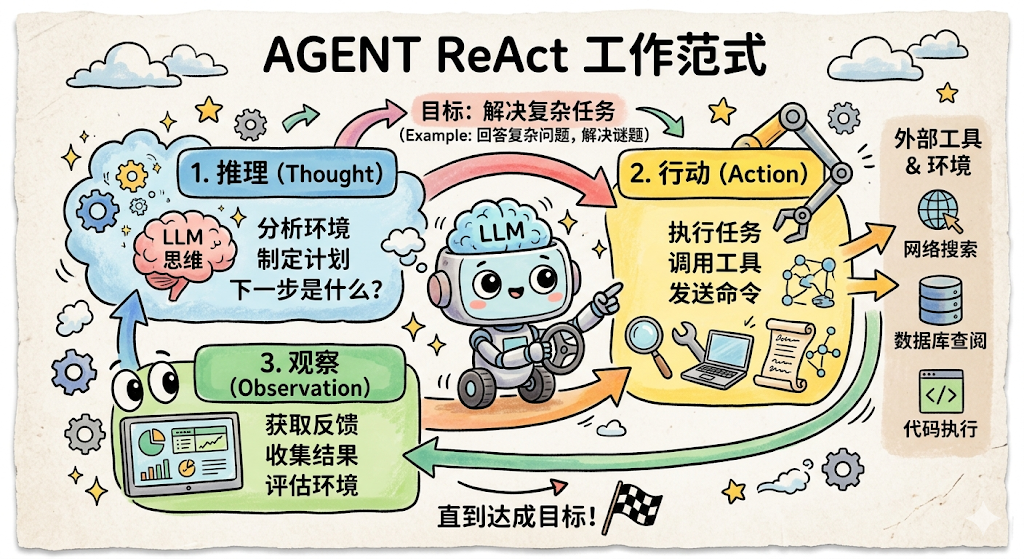
agent示例场景:
用户:帮我调查今晚 23:00 的数据库报警
[第 1 轮]
Think:需要先拿到具体的报警详情
Act:调用 get_alarm_details(time="23:00")
Observe:返回"连接数突增,连接池耗尽,持续 8 分钟后自动恢复"
[第 2 轮]
Think:连接数突增,需要看是哪些查询造成的
Act:调用 query_slow_log(timerange="22:50-23:10")
Observe:发现 3 条全表扫描的慢查询,来自同一个用户 ID
[第 3 轮]
Think:根因已经清楚,生成分析报告
Act:输出最终分析结论(Final Answer)
几个关键机制:
- 结果回流 :每一轮的工具调用结果都会追加到 context window里,大模型下一轮能"看到"所有历史。所以它能基于已有发现继续推理,而不是每次都从零开始。这就是为什么前面"记忆"那个组件如此重要。
- 动态决策:每一步该怎么走,是大模型实时推理出来的,不是你提前写好的。发现是慢查询,它就去查慢查询日志;如果发现是网络问题,它就会去查网络相关的工具。路径是活的,不是死的。
- 何时停止 :大模型判断任务已完成时输出"最终答案",或者达到预设的最大轮数上限。两个条件任意满足一个,循环结束。
Plan and Execute(规划-执行模式)
ReAct的最大缺陷:「边想边做」,每一步只看眼前,这一步的结果决定下一步的方向。对于 2-3 步能解决的短任务,这完全没问题。但如果任务很复杂、步骤很多就无法胜任。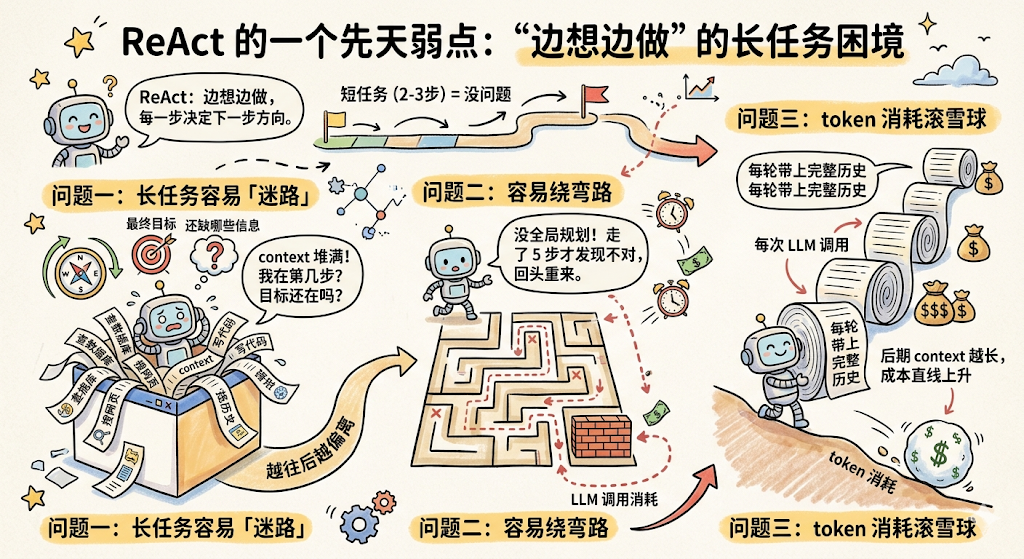
Plan and Execute(规划-执行模式)。核心思路用一句话说清楚: 先让大模型把整个任务规划成一份清单,再逐步按清单执行,而不是走一步看一步。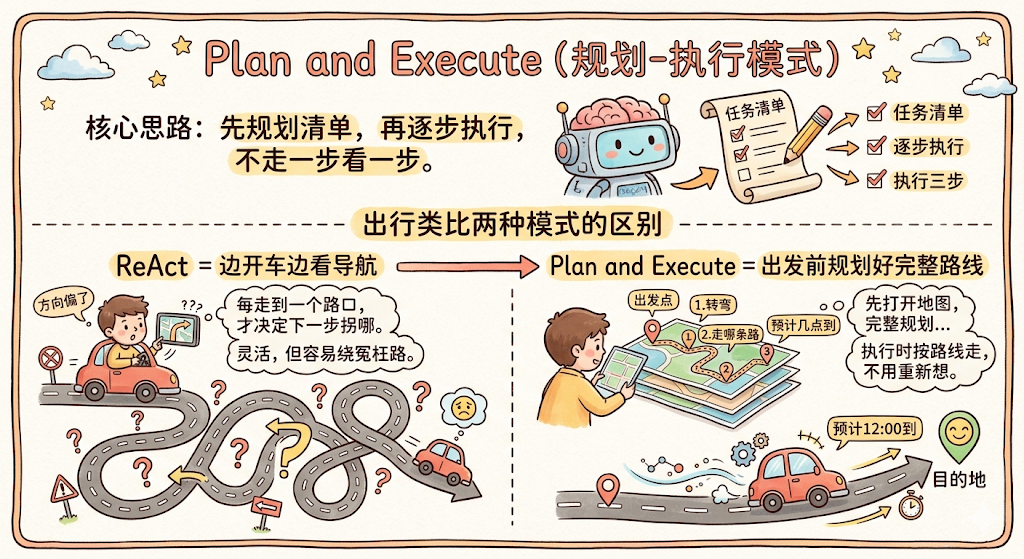
第一阶段:Planner(规划阶段)
大模型拿到任务,先不调任何工具,专注做一件事: 把任务完整拆解成一份有序的子任务清单 。
示例:
用户:「帮我调查今晚 23:00 的数据库报警,写一份完整的故障分析报告」
Planner 输出的计划:
步骤 1:获取 23:00 报警的详细信息(报警类型、持续时间、影响范围)
步骤 2:查询报警时间段内的慢查询日志,定位异常 SQL
步骤 3:查询报警时间段内的数据库连接数、CPU、内存指标
步骤 4:关联步骤 2 和步骤 3 的结果,分析根因
步骤 5:生成完整的故障分析报告,包含时间线、根因和改进建议
第二阶段:Executor(执行阶段)
计划有了,开始逐步执行。每个步骤可以是一次简单的工具调用,也可以是一个小的 ReAct 循环,步骤复杂就跑几轮,步骤简单就一步到位。
执行步骤 1:
→ 调用 get_alarm_details(time="23:00")
← 返回「连接数突增,连接池耗尽,持续 8 分钟后自动恢复」
执行步骤 2:
→ 调用 query_slow_log(timerange="22:50-23:10")
← 发现 3 条全表扫描的慢查询,来自同一个用户 ID
执行步骤 3:
→ 调用 get_db_metrics(timerange="22:50-23:10")
← CPU 正常,连接数峰值达到上限 500,内存无异常
执行步骤 4:
→ 大模型综合步骤 2、3 结果进行分析
← 结论:慢查询导致连接长时间占用,连接池耗尽触发报警
执行步骤 5:
→ 生成故障分析报告
← 完整报告输出,任务完成
还有一个重要机制: Re-planning(重新规划) 。执行中途如果遇到了计划没预料到的情况,比如步骤 2 查不到慢查询,但发现了大量锁等待,Executor 可以把这个新信息反馈给 Planner,重新生成后续步骤的计划,而不是一条路走到黑。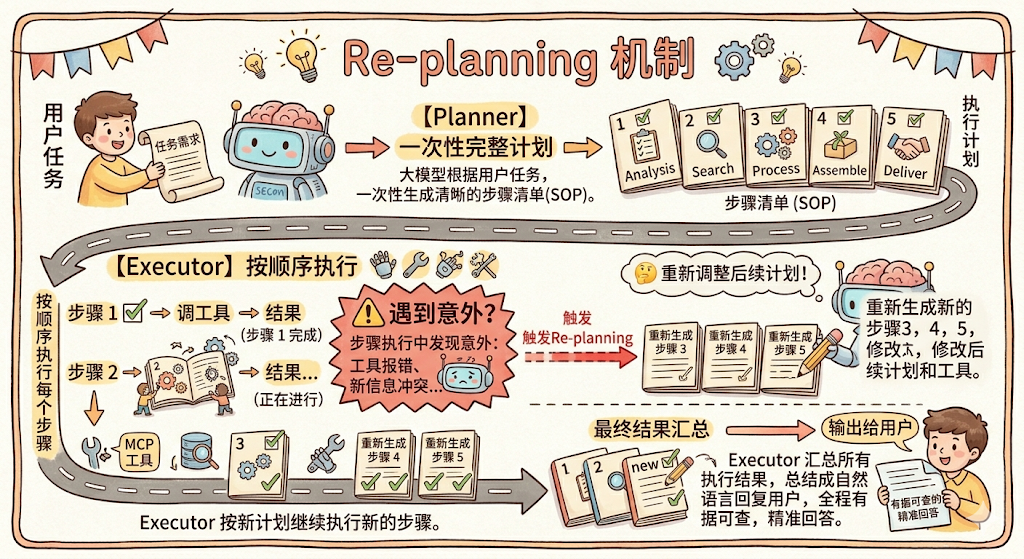
用户任务
↓
[Planner] 大模型一次性生成完整计划
↓
执行计划 = [步骤1, 步骤2, 步骤3, 步骤4, 步骤5]
↓
[Executor] 按顺序执行每个步骤
步骤1 → 调工具 → 结果
步骤2 → 调工具 → 结果 ← 遇到意外?触发 Re-planning,重新调整后续计划
步骤3 → 调工具 → 结果
...
↓
最终结果汇总 → 输出给用户
ReAct vs Plan and Execute:
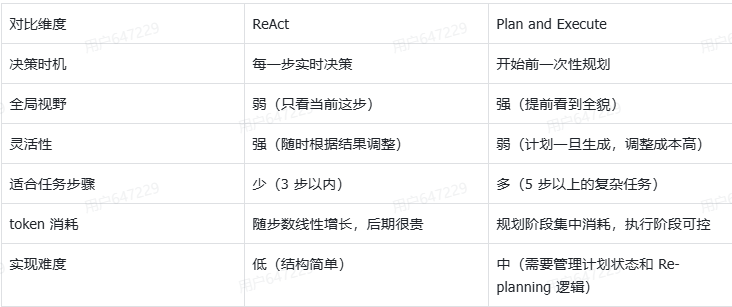
- 任务步骤少、目标模糊、需要随机应变 → 用 ReAct
- 任务步骤多、目标明确、需要全局把控 → 用 Plan and Execute
- 系统复杂、两者都需要 → Plan and Execute 做外层框架,每个子任务内部跑 ReAct
Agent vs Workflow
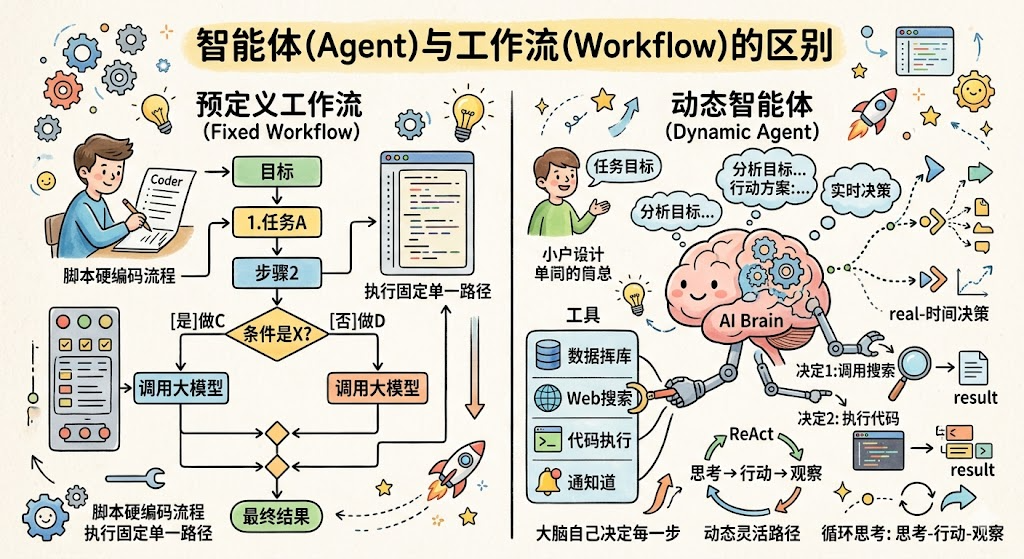
- Workflow(工作流) 是你提前写好所有步骤和分支逻辑的流程:先做 A,再做 B,如果 B 的结果是 X 就走流程 C,否则走流程D。大模型只是其中某个步骤里被调用一次,整体流程是硬编码的
- Agent是你只给任务目标,大模型自己实时决定每一步做什么、调用什么工具、根据结果决定下一步。执行路径是动态的,每次运行可能走不同的路径。
一个真实agent的样子
一个极简的 Agent 骨架:
def run_agent(user_message):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_message},
]
while True:
# 1. 调用大模型,让它思考下一步
response = llm.call(messages)
# 2. 如果大模型说"我完成了",退出循环
if response.is_final_answer:
return response.content
# 3. 否则,执行大模型指定的工具
tool_result = execute_tool(response.tool_name, response.tool_args)
# 4. 把工具结果追加到 messages,供下一轮参考
messages.append({"role": "tool", "content": tool_result})
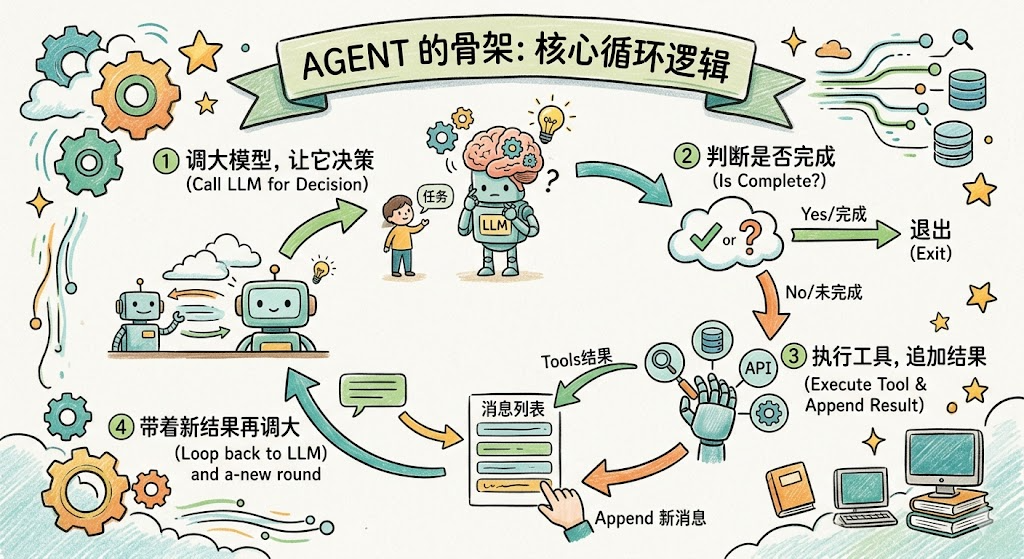
**核心组成 :**大模型(大脑)+ 工具(双手)+ 记忆(记事本)+ 执行循环(节拍器)
Tool
组成部分
四要素: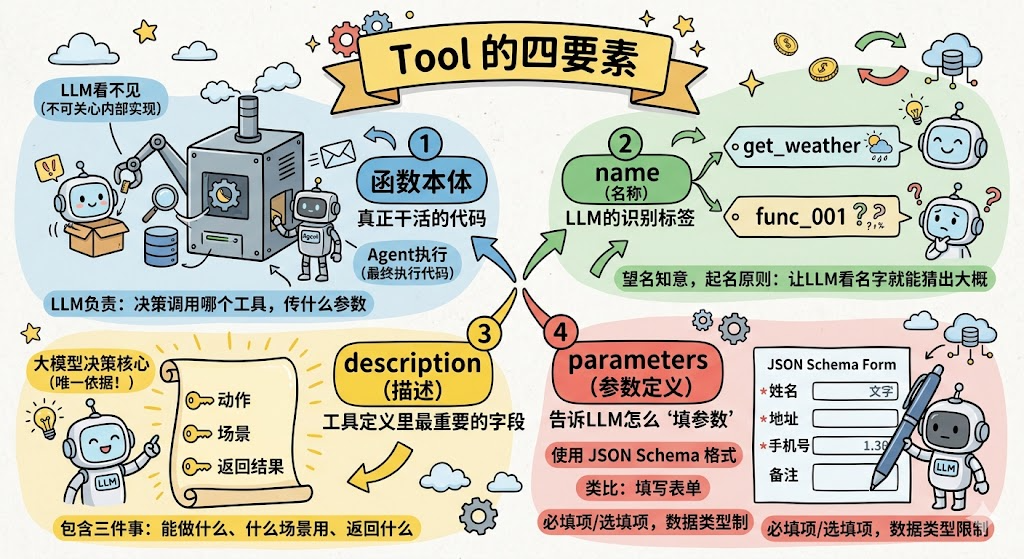
- 函数本体:这是实现具体功能的代码,查数据库就是查数据库,发通知就是发通知。
这部分 大模型看不到 ,但是 Agent 最终会执行它。大模型只负责「决策调用哪个工具、传什么参数」,至于这个工具内部怎么实现,大模型完全不关心。 - name(名称):大模型决定「调哪个工具」的时候,第一步靠的就是名称。名字要 望名知意 。
get_weather 一眼就知道是「查天气」; func_001 就算加了再多描述,大模型也会更难联想到它的用途。起名的原则很简单:让大模型看名字就能猜出大概。 - description(描述):大模型每轮决策的核心问题是:「当前这一步,该不该调这个工具?」它做这个判断的 唯一依据 ,就是工具的 description。
描述写清楚了,大模型准确选工具;描述写模糊了,大模型要么选错工具,要么该用的时候没用,或者不该用的时候乱用。
一个好的 description 应该包含三件事:
•能做什么 :这个工具的核心功能是什么
•什么场景用 :遇到哪类问题、哪种情况该选它
•返回什么 :调用完会得到哪些信息 - parameters(参数定义):有了函数,大模型还得知道:调用这个工具要传哪些参数、每个参数是什么类型、哪些是必填的。
这些信息用 JSON Schema 格式来定义。
示例:
函数本体:
# ===== 第一部分:函数本体(大模型看不到,Agent 负责执行)=====
import requests
def get_weather(city: str, date: str) -> dict:
"""调用天气 API,查询指定城市指定日期的天气"""
response = requests.get(
"https://api.weather.com/v1/forecast",
params={"city": city, "date": date}
)
data = response.json()
return {
"city": city,
"date": date,
"weather": data["condition"], # 晴/多云/雨
"temperature": data["temp_c"], # 摄氏度
"humidity": data["humidity"] # 湿度百分比
}
工具说明书(包含name + description + parameters):
// ===== 第二三四部分:工具说明书(大模型看到的部分,靠这个决定要不要调用)=====
{
"name": "get_weather",
"description": "查询指定城市在指定日期的天气情况。当用户询问某地天气、出行建议、是否需要带伞等问题时使用此工具,返回天气状况、气温和湿度信息。",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "要查询天气的城市名称,例如:北京、上海、广州"
},
"date": {
"type": "string",
"description": "查询日期,格式:YYYY-MM-DD,例如:2025-03-21"
}
},
"required": ["city", "date"]
}
}
大模型如何使用tool
Agent 在每次对话开始前,会把所有可用工具的 name + description + parameters 打包成一个列表,通过 API 的 tools 参数传给大模型。这个列表就叫 工具清单 。
大模型每次做决策,实际上是在读这份清单,然后判断:「当前任务需要什么操作?哪个工具能完成?该怎么调用?」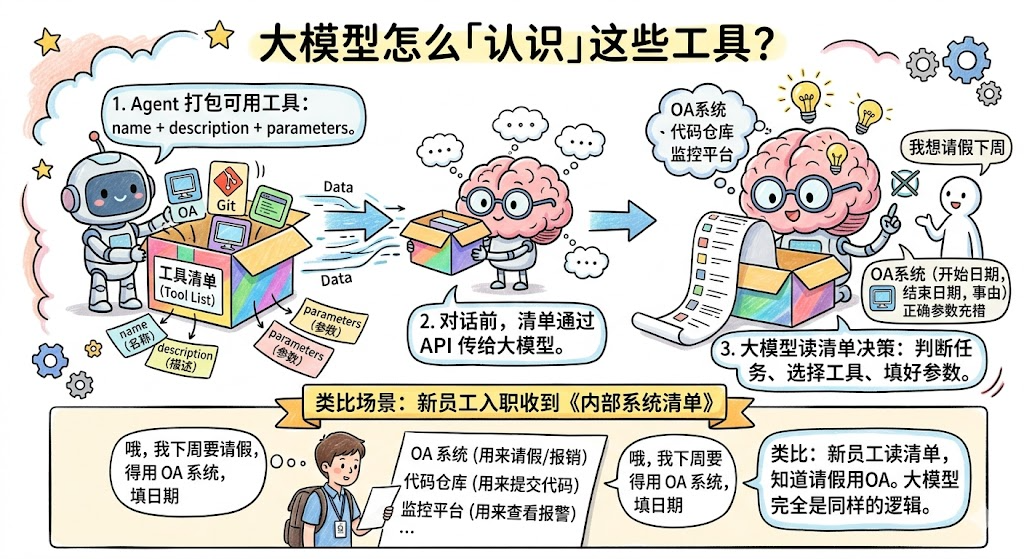
大模型选对工具的能力,不只取决于模型有多聪明,更取决于工具描述写得有多清晰。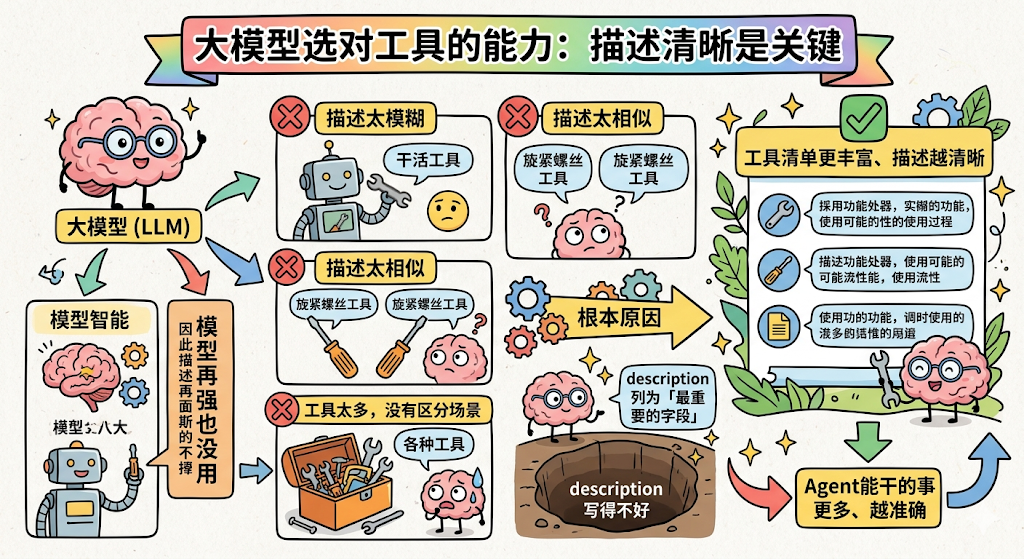
工具类型
四类工具: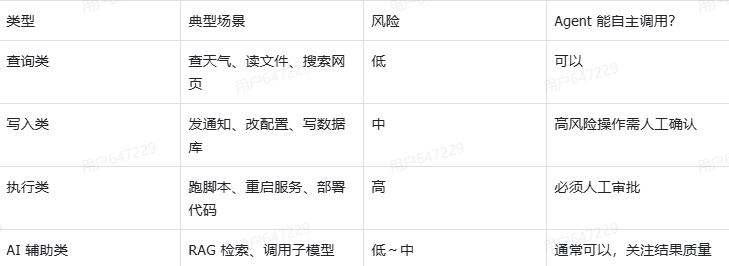
Function Call
Function Calling 的本质,是一套大模型和 Agent 之间的标准化工具调用协议 ,我们不再用自然语言告诉 AI「你可以用这个工具」,而是用一套固定的 JSON 格式把工具定义清楚;大模型也不再自由发挥,而是严格按固定的 JSON 结构返回调用指令。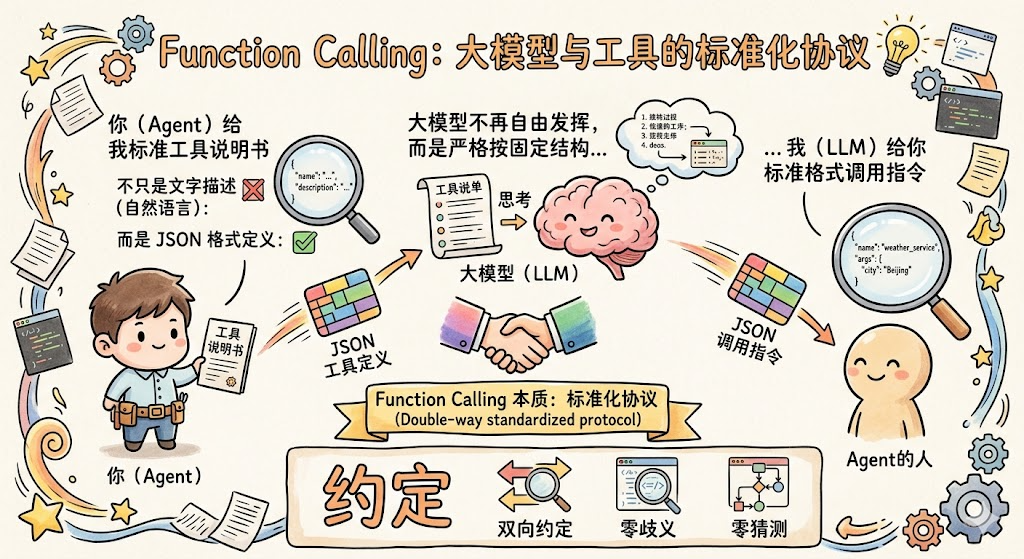
- 工具(Tool)= 能力层,解决「有什么」:一个工具需要哪些要素才算完整、才能让大模型认识和使用它,函数本体是真正干活的,名称让大模型能精准识别,描述告诉大模型什么时候该用它,参数定义告诉大模型怎么构造调用参数。这是在定义一个能力本身。
- Function Calling = 协议层,解决「怎么传」 :工具写好之后,大模型和 Agent之间要用什么格式来交换信息,大模型怎么告诉 Agent 要调哪个工具、传什么参数;Agent执行完工具后怎么把结果回传给大模型。这是一套标准化通信规范。
Function Call的三部分
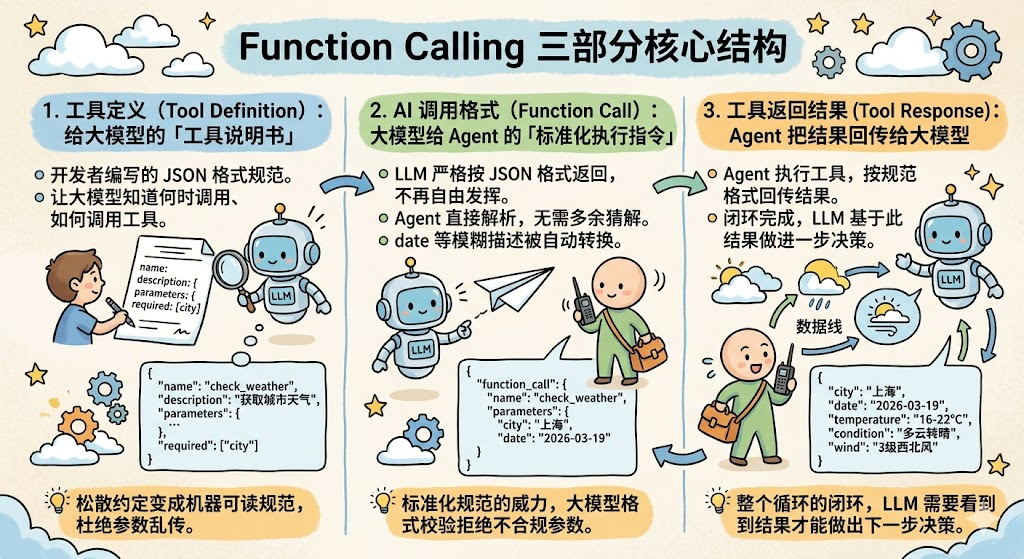
第一部分:工具定义(Tool Definition),给大模型的「工具说明书」
这一步是我们开发者要写的,相当于给大模型一份严格规范的工具说明书,大模型会完全按照这份说明书,判断要不要调用工具、怎么调用工具。
{
"name": "check_weather",
"description": "获取指定城市指定日期的天气情况,包括温度区间、晴雨状况、风力风向",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "需要查询天气的城市中文名称,示例:北京、上海、广州"
},
"date": {
"type": "string",
"format": "YYYY-MM-DD",
"description": "需要查询的日期,格式为年-月-日,示例:2026-03-19,不填默认查询当天"
}
},
"required": ["city"]
}
}
第二部分:AI 调用格式(Function Call),大模型给 Agent 的「标准化执行指令」
当大模型判断需要调用工具时,会严格按照固定格式返回 JSON,不再有任何自由发挥的自然语言。我们的 Agent 直接解析这个结构,拿到工具名和参数,不用做任何额外的猜解处理。
{
"function_call": {
"name": "check_weather",
"parameters": {
"city": "上海",
"date": "2026-03-19"
}
}
}
第三部分:工具返回结果(Tool Response),Agent 把结果回传给大模型
{
"city": "上海",
"date": "2026-03-19",
"temperature": "16-22℃",
"condition": "多云转晴",
"wind": "3级西北风"
}
Agent执行流程:
第 1 步:Agent 把「用户需求 + 工具清单」打包,发给大模型
第 2 步:大模型做决策,返回调用指令
第 3 步:Agent 执行指令,调用工具函数
第 4 步:Agent 把工具执行结果回传给大模型
第 5 步:大模型根据结果,决定下一步
第 6 步:循环执行,直到任务完成
第 7 步:Agent 把最终结果反馈给用户
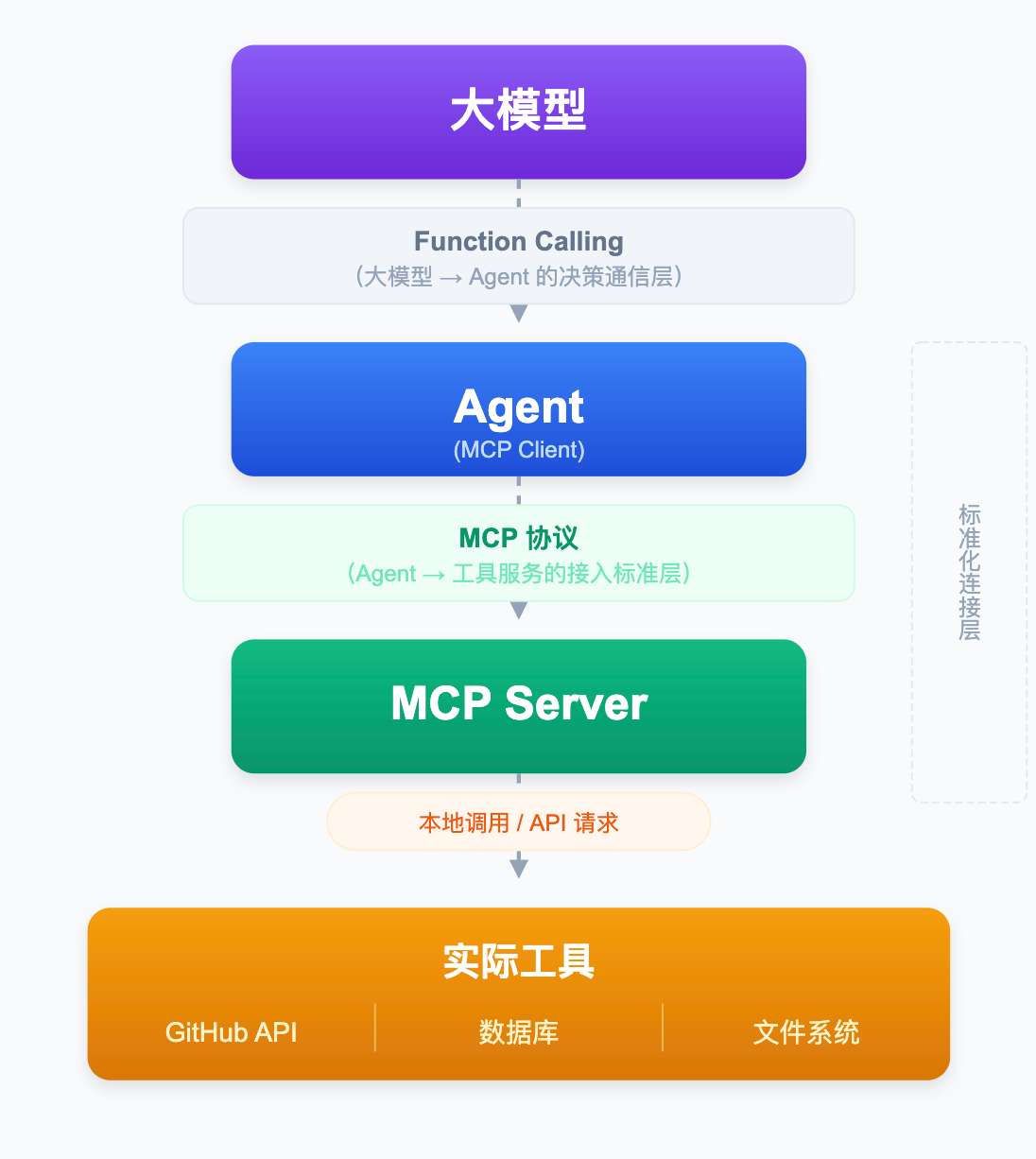
MCP
MCP 对于 AI 工具世界的意义,就和 USB-C 对于充电口的意义一模一样。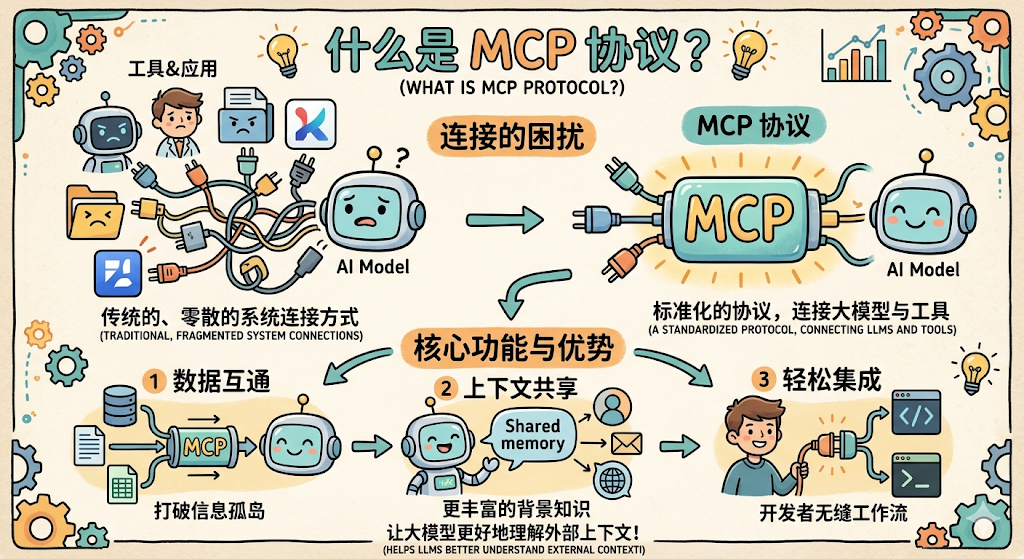
MCP三大角色
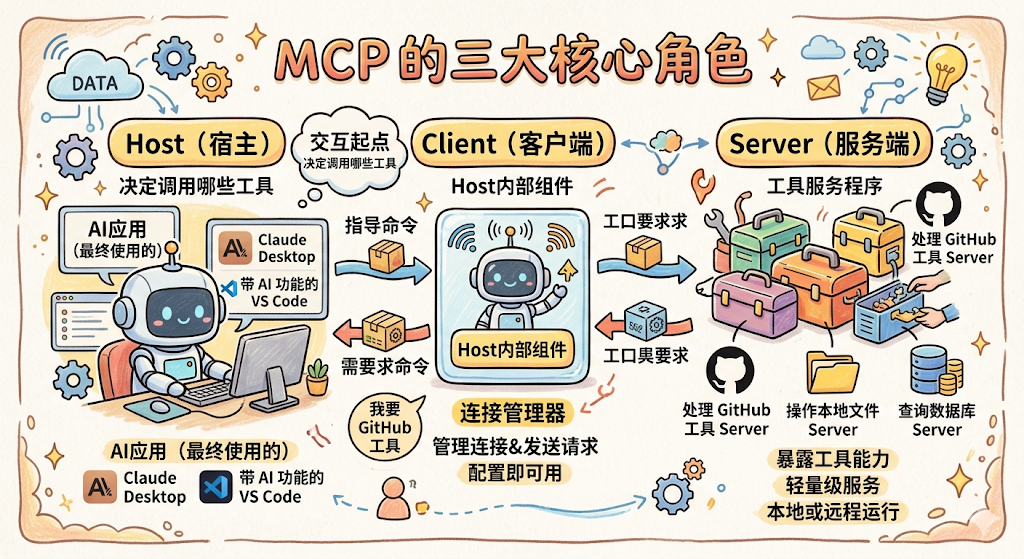
- Host(宿主)
Host 就是你最终使用的那个 AI 应用,可以是 Claude Desktop、带 AI 功能的 VS Code、或者你自己开发的 Agent 程序。Host 是整个交互的起点,用户在 Host 里提问,Host 决定要调用哪些工具来完成任务。 - Client(客户端)
Client 是 Host 内部的一个组件,专门负责管理和 MCP Server 的连接。你可以把它理解为一个「连接器」,Host 说「我要调用 GitHub 工具」,Client 就负责找到对应的 MCP Server、建立连接、发送请求、拿回结果。
每个 Host 通常会内置一个 MCP Client,你不需要自己开发,直接配置就能用。
- Server(服务端)
Server 是对外暴露工具能力的轻量级服务程序。一个 MCP Server 通常负责一类工具,比如专门处理 GitHub 的 MCP Server、专门操作本地文件的 MCP Server、专门查询数据库的 MCP Server。
Server 和 Host 可以运行在同一台机器上(本地 Server),也可以部署在远程服务器上(远程 Server)。对于 Host 和 Client 来说,这些细节完全透明,调用方式完全一致。
Skills
我们从最基础的大模型、Prompt,一路学到了 Agent、Function Calling、MCP,前面这些技术在咱们之前的“智能OnCall项目”中都有用到。
不过,从 26 年初开始,AI 圈子又出了个叫 Skills(技能) 的新东西。当时我们在做智能 OnCall 项目时,还没有 Skills 这个概念,自然项目也就没有用到。不过今天,我还是得专门带大家来学习一下 Skills 这个新玩意,因为它现在真的太火了,现在的 AI 岗位面试几乎逢考必问!
很多同学在看各种 AI 框架源码时,经常被这几个词绕晕:“它们到底是个啥?谁先出谁后出?有啥区别?”
别慌,今天咱们就泡杯茶,用最接地气的话,按照技术演进的真实时间线,把这三个概念从头到尾盘一盘。
第一阶段:AI 的“破壁人” , Function Calling(函数调用)
咱们先回想一下早期的 ChatGPT。那时的它就像是一个 被关在小黑屋里的超级学霸 :虽然上知天文下知地理,但他没网(没法查实时数据),也没手(没法帮你真正去执行操作,比如发邮件、查数据库)。
为了让大模型能连接外部世界, Function Calling 诞生了。
用白话说,这就是 大模型和外部世界打交道的一种“底层暗号” 。
你想让 AI 查今天深圳的天气,它自己查不到,但你可以给它提供一个 get_weather 的函数说明书。AI 看到你的需求和说明书后,不会直接回答天气,而是输出一段 JSON 代码:“我决定调用 get_weather ,参数是 深圳 ”。 然后你的代码拿着这个参数去真正调用 API,查到结果后再喂给 AI,AI 最后总结成人类语言回复你。
划重点: Function Calling 是最基础的机制,它赋予了 AI 使用工具的“潜能”。
第二阶段:大一统的“Type-C 接口” , MCP (模型上下文协议)
有了 Function Calling,大家都很兴奋,开始给 AI 疯狂写各种工具(查天气、查 MySQL、读 Github 等等)。
但很快,新的灾难来了: 接口完全不兼容。
张三用 Python 写了个查数据库的工具,李四用 Java 搞了个读本地文件的工具。由于没有统一的标准,你的 AI 应用想要接入这些现成的工具,就得挨个去适配它们千奇百怪的数据格式和通信逻辑。这就像你买了个新手机,却发现大家用的充电线有圆头、扁头、方头,简直让人崩溃。
这时候, MCP(Model Context Protocol,模型上下文协议) 闪亮登场。
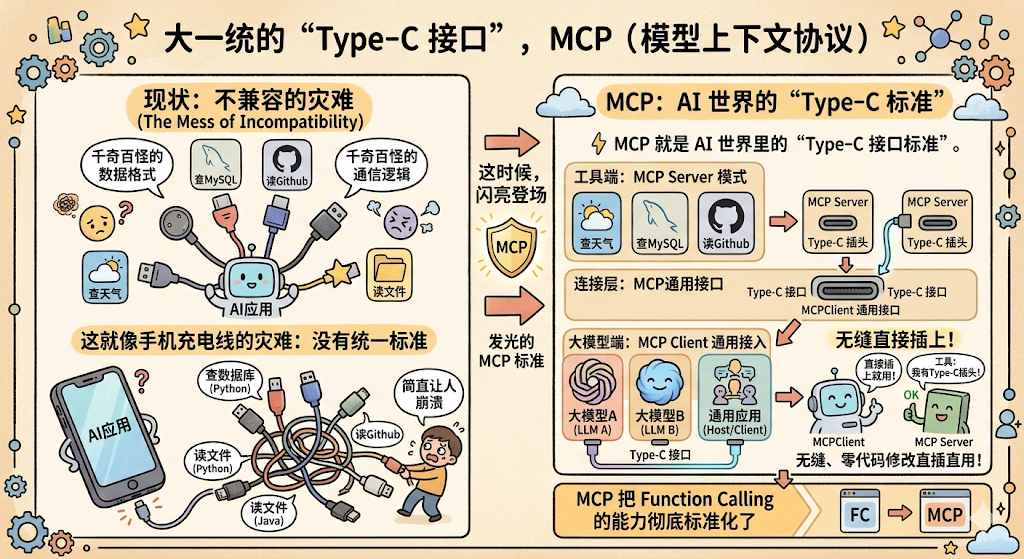
用大白话说,MCP 就是 AI 世界里的 “Type-C 接口标准” 。
它是一套通用的开源协议。只要外部工具(数据源、数据库、代码仓库)按照 MCP 的标准开发成 MCP Server,那么无论前端是哪个大模型(MCP Client),都可以 无缝、零代码修改 地直接插上去用。MCP 把 Function Calling 的能力彻底标准化了。
第三阶段:终极进化 , Skills(技能)为什么会出现?
好,现在 AI 有了底层机制(Function Calling),也有了标准化的工具箱(MCP)。是不是就天下太平了?
并没有!随着咱们让 AI 干的活越来越复杂,26 年初,一个极其痛点的问题暴露了出来: 每次让 AI 干活,沟通成本太高了!
举个例子,假设你要让 AI 帮你写一份项目日报。你手里虽然已经有了 MCP 提供的“读取数据库”和“读取 Jira”的标准化工具,但你每次跟 AI 聊天,还是得像个唐僧一样反复叮嘱。
咱们来看看没有 Skills 之前的现状:
用户:"帮我按XX格式生成报告"
用户:"生成报告前,先去调用数据库工具获取今天的数据"
用户:"记得要包含数据分析和总结部分"
用户:"别忘了图表的排版细节..."
(每次生成报告,都要重复这段痛苦的念经过程)
发现问题了吗? 工具虽然标准化了,但“使用工具的流程和大脑的思考方式(Prompt)”并没有被沉淀下来。
为了解决这个痛点, Skills(技能) 应运而生!
什么是 Skill? Skill 就像是给 AI 定制的一份 “标准作业程序 (SOP)” 。它把解决特定问题所需的 背景设定 (Prompt) 、 执行步骤 和 所需的工具 (MCP) ,打包成了一个干净利落的代码文件。
咱们来看看用了 Skills 之后的方案:
---
name: report-generator
description: 按照公司标准格式自动收集数据并生成报告
tools:
- mcp-jira-reader # 挂载所需的 MCP 工具
- mcp-database-query
---
# 报告生成流程
1. 包含封面页(模板见 templates/cover.md)
2. 执行数据分析(自动调用 mcp-database-query 获取今日核心指标)
3. 提取任务进度(自动调用 mcp-jira-reader 获取任务状态)
4. 生成图表和摘要
...
只要有了这个 Skill 文件,你下次只需要对 AI 说一句:“ 帮我生成今天的日报 ”。 AI 就会自动加载 report-generator 这个技能,自动按顺序调用 MCP 工具,按规定格式输出。一步到位,神清气爽!
拆解:一个 Skill 的内部结构长什么样?
从上面的对比图咱们能看出来,一个优秀的 Skill,结构是非常清晰的,通常分为两部分:
-
头部配置(Frontmatter): 通常用 YAML 语法写在最前面(被
---包裹)。这里用来定义技能的名字、描述, 最重要的是,在这里声明它需要挂载哪些 MCP 工具(Tools) 。这就好比一个电工师傅出门前,先在工具箱里挑好今天要用的螺丝刀和万用表。 -
技能主体(Body): 这里写的是具体的指令、工作流(Workflow)、规则限制和模板。这里的大白话指令,就是在教大模型“拿到工具后,第一步干啥,第二步干啥”。
灵魂拷问:Skills 不就是高级一点的 Prompt 吗?
可能看到这里,有同学心里犯嘀咕了:“我看你这 SKILL.md 里面,主体部分不还是写了一堆自然语言的步骤吗?这不就是个长一点的 Prompt(提示词)吗?跟我在对话框里敲字有什么区别?”
这个问题问得太好了!其实很多人刚接触时都会有这个错觉。咱们来掰扯掰扯它俩到底是什么关系、有什么区别:
-
从关系上看:包含与被包含。 Prompt 是 Skill 的“灵魂核心”,但不是全部。一个完整的 Skill = Prompt(指令与流程) + 挂载的工具列表(MCP) + 触发条件 + 上下文状态 。
-
从能力上看:动嘴与动手。 Prompt 只能控制大模型的“嘴”。你写一万字的 Prompt 教它怎么查数据库,它也只能给你输出一段怎么查的文本。而 Skill 给 AI 赋予了“手”。通过配置文件里绑定的
tools,AI 在阅读 Prompt 的同时,是真的能去后台调用代码、拉取数据的。 -
从工程上看:临时工与标准资产。 你在对话框里敲的 Prompt 是“临时工”,上下文一长它就忘了,下次还得重敲。而 Skill 是一份写在项目目录里的配置文件(通常是 YAML 或 Markdown),它是可以提交到 Git 仓库里的 代码资产 。它把个人经验变成了整个团队都可以直接复用的 标准作业程序(SOP) 。
打个粗俗点的比方:
-
Prompt 是你站在厨房门口喊:“去给我炒个鱼香肉丝,先放葱姜蒜,再放肉丝!”
-
Skill 是你把《鱼香肉丝菜谱》写好,连带厨房里自动炒菜机的【启动钥匙】,一起装进了一个信封里。以后谁饿了,拿着这个信封扫一下,菜就自动炒出来了。
实战加餐:以最近爆火的 Claude Code 为例,看看 Skills 到底有多强?
光说不练假把式。今年(2026年)Anthropic 发布的终端编程神器 Claude Code ,直接把 Skills 机制带火了。咱们就以它为例,看看真实项目里是怎么玩 Skills 的。
假设你在开发一个前端网站,经常需要把设计稿里的大图片压缩、转换成 WebP 格式,然后再挪到 public 文件夹里。如果每次都让大模型现写一段 Python 脚本来跑,既费时间又容易出错。
有了 Skills 之后,你可以直接在项目目录下建一个专门干这活的“图片优化技能”。
- 目录结构长这样:
your-web-project/
├── src/
├── .claude/ # Claude Code 的专属配置目录
│ └── skills/ # 💡 这里就是技能大本营
│ └── image-optimizer/ # 我们自定义的“图片优化技能”
│ ├── SKILL.md # 技能的说明书和工作流
│ └── optimize.py # 真正干活的 Python 压缩脚本
- SKILL.md 里面写了啥? 咱们刚才说了,一个优秀的 Skill 分为“头部配置”和“技能主体”。在 Claude Code 里,它是这么写的:
---
name: image-optimizer
description: 专门用于将大尺寸图片压缩并转换为 webp 格式,输出到 public/assets 目录。
tools:
- mcp-python-runner # 声明需要用到运行 Python 代码的工具能力
---
# 任务流程
当你收到优化图片的指令时,请严格按照以下步骤执行:
1. 读取用户指定的原图片文件。
2. 调用同目录下的 `optimize.py` 脚本,将原图转换为高质量的 webp 格式。
3. 将转换后的图片移动到项目的 `public/assets/` 目录下。
4. 在终端打印出压缩前后的文件大小对比。
- 怎么使用? 配置好之后,你在 Claude Code 的终端里,只需要像聊天一样发一句话(或者直接输入内置指令
/image-optimizer):
Claude 会自动扫描 skills/ 目录,读取 SKILL.md 理解整个工作流,然后默默在后台调用脚本、压缩图片、移动文件,最后在终端里回复你:“搞定了!图片大小从 631KB 压缩到了 56KB,已经放在 public 目录啦!”
发现了吗?这种目录结构最大的好处是“热插拔”。 有了 Skill,你实际上是在给 AI “教流程”、“写 SOP”。
以后再遇到类似的脏活累活,AI 就能像个熟练的老员工一样,直接照着这个目录里的 SOP 帮你把活干得漂漂亮亮!
总结:理清它们的三角关系
最后,我再用一句话帮大家总结一下今天聊的这三个核心概念:
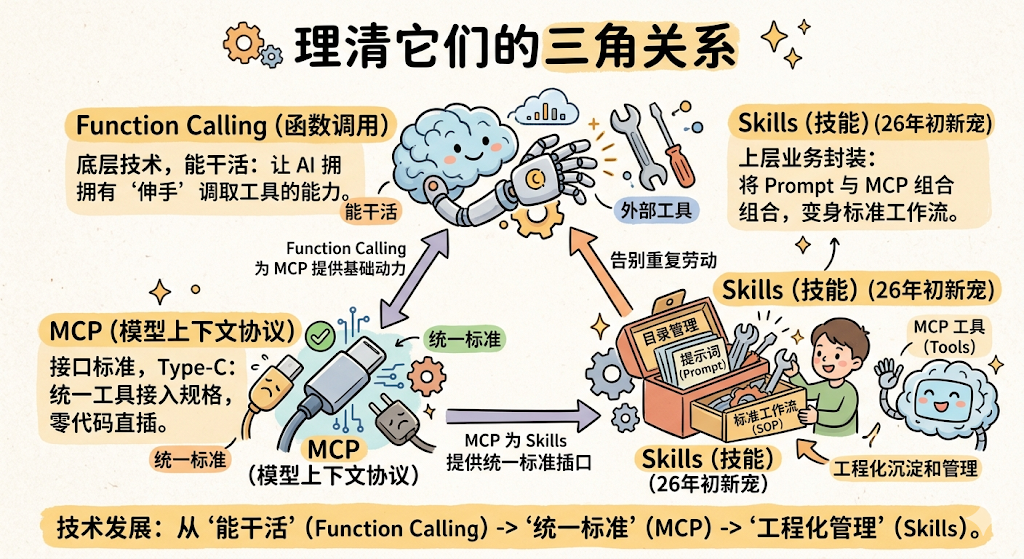
-
Function Calling(函数调用): 是底层技术,让大模型拥有了“伸手”调取外部工具的 能力 。
-
MCP(模型上下文协议): 是接口标准,统一了全网工具的接入规格,让 AI 拥有了“Type-C”通用 插口 。
-
Skills(技能): 是上层的业务封装(26年初的新宠),它将 Prompt 指令和 MCP 工具组合在一起,按清晰的 目录结构 管理起来,变成了 AI 可以随拿随用、彻底告别重复劳动的“ 标准工作流 ”。
技术的发展永远是这样,从“能干活”(Function Calling),到“统一标准”(MCP),再到“工程化沉淀和管理”(Skills)。
RAG
RAG 的核心思路:先检索,再回答
核心思路:不把所有数据都塞进 Prompt,而是在每次回答之前,先去找到最相关的那几段,再把这几段塞进 Prompt。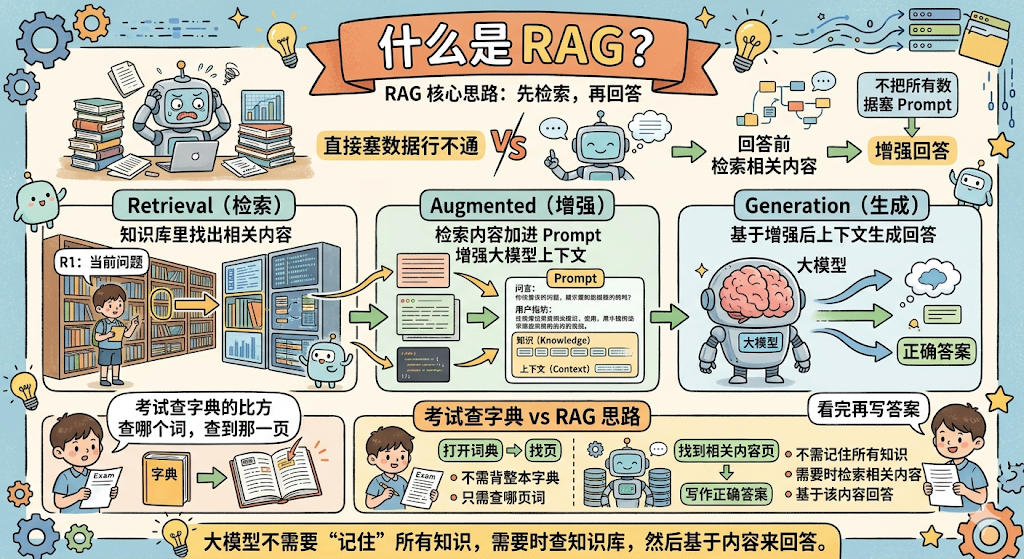
- Retrieval(检索):从知识库里找出和当前问题最相关的内容
- Augmented(增强) :把检索到的内容加进 Prompt,增强大模型的上下文
- Generation(生成):大模型基于增强后的上下文生成回答
工作流程
分两个阶段: 离线建库 和 在线检索生成 。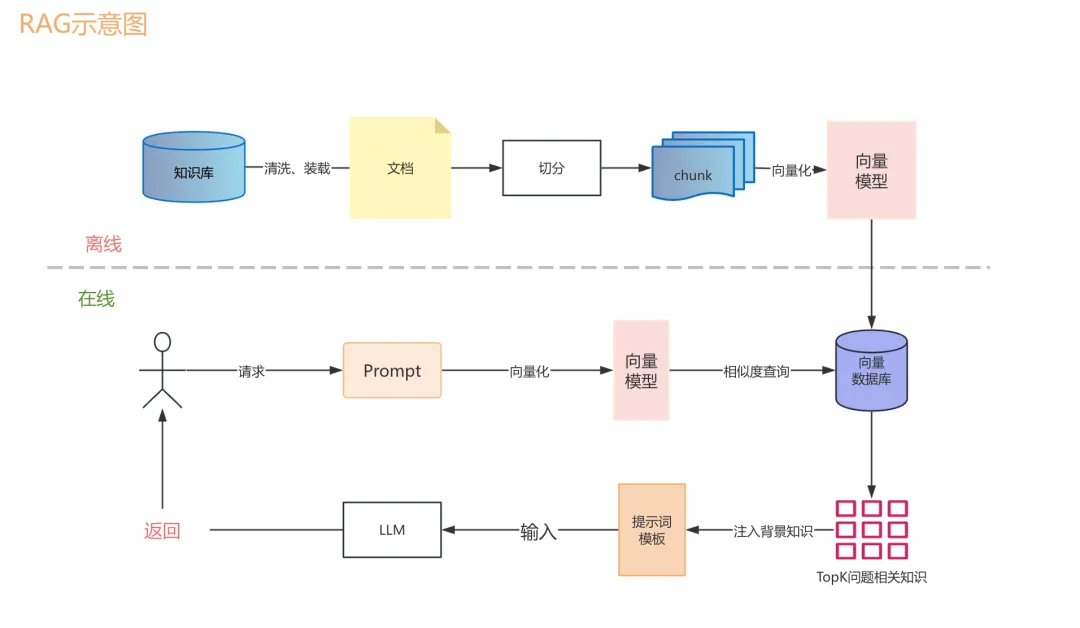
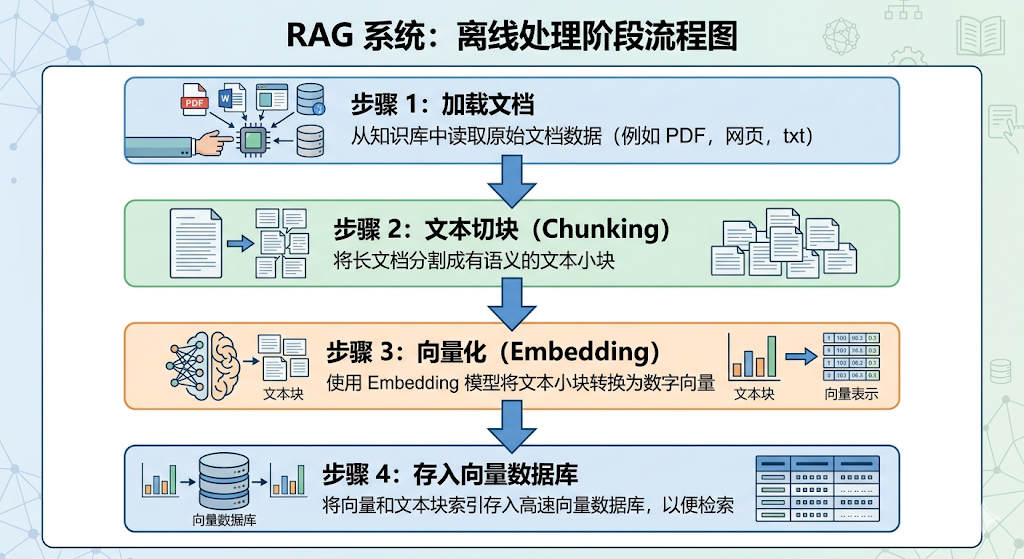
- 离线阶段:
- 这个阶段的目标是把你的私有数据,处理成大模型能快速检索的格式,存进向量数据库。
2.在线阶段
每次用户提问,实时触发以下四步: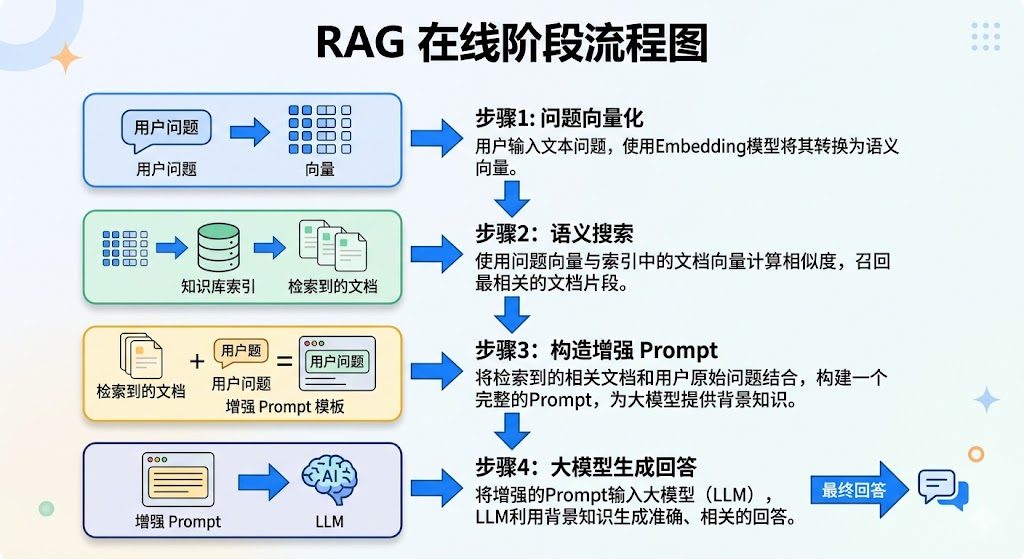
向量知识库
普通数据库能不能存向量?
能存,但有个很大的问题。
普通数据库存向量没问题,向量本质上就是一串浮点数,MySQL 建个字段存下来完全没难度。
难的是 查 。
普通数据库为什么查不了向量
咱们先聊聊 MySQL 是怎么查数据的。
你写 SELECT * FROM users WHERE id = 5 ,MySQL 走 B+ 树索引,几次跳转就找到了,极快。你写 WHERE age > 18 ,同样走索引,范围扫描,也很快。
MySQL 的索引本质上是为两类操作优化的: 精确匹配 和 范围比较 。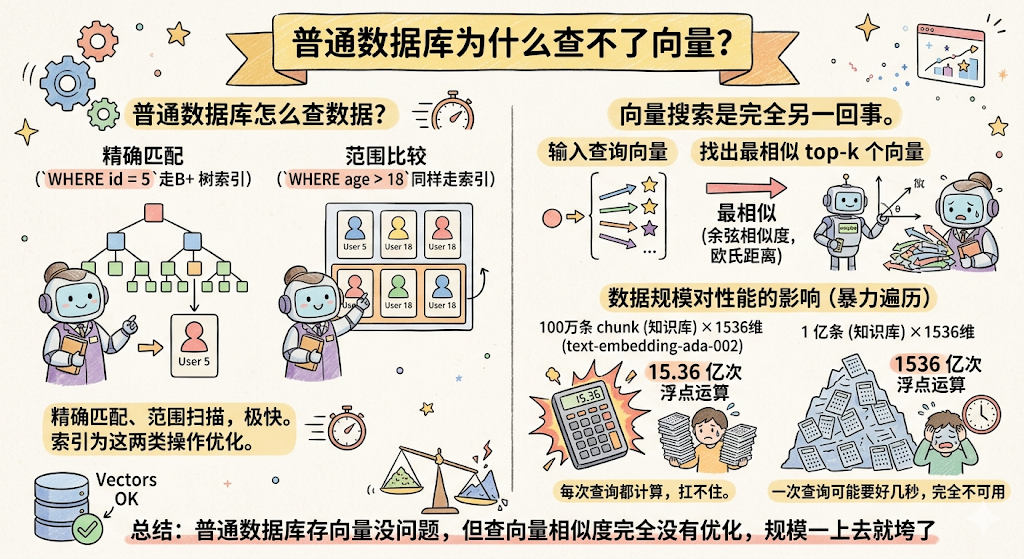
但向量搜索是完全另一回事。
向量搜索要做的事情是: 给你一个向量,找出和它最相似的 top-k 个向量 。
「最相似」意味着要算距离,余弦相似度、欧氏距离……这类计算,需要拿着你的查询向量,和库里每一条向量都算一遍距离,然后排序,取最小的几个。
MySQL 的 B+ 树索引完全帮不上这个忙。它压根不知道怎么在多维空间里找「最近邻」。
普通数据库存向量没问题,但查向量相似度完全没有优化,规模一上去就垮了。
向量数据库是什么
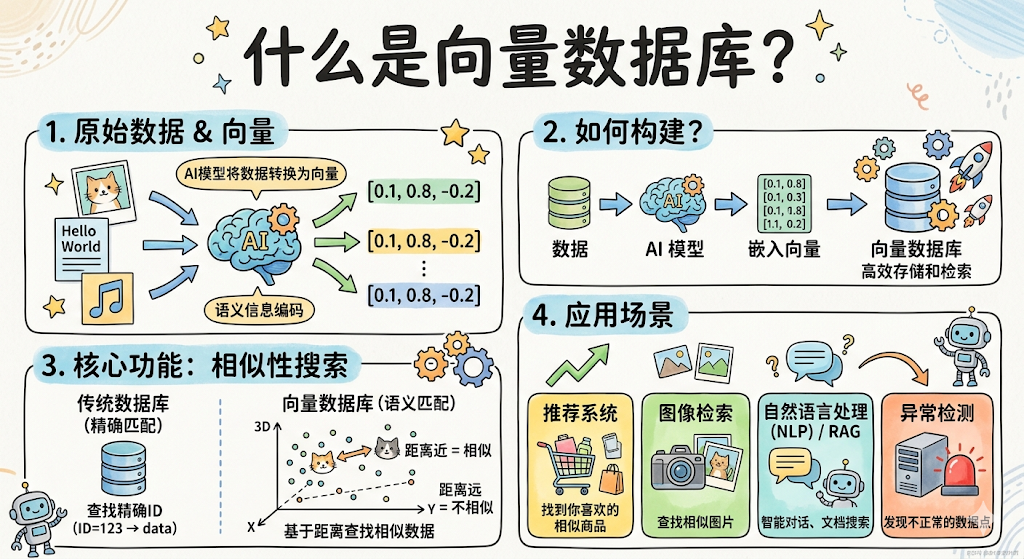
存储的内容:向量+元数据
向量本身只负责表达“像不像”,而元数据负责回答“它是谁、能不能用、怎么筛”。
可以把两者分工理解成:
向量:用于相似性检索
元数据:用于业务约束、解释和管理
示例:
vector: [0.12, -0.45, ...]
metadata:
title: “员工报销流程”
doc_id: doc_2381
source: HR知识库
chunk_index: 7
向量数据库怎么做到「又快又准」?
秘诀是 ANN(Approximate Nearest Neighbor,近似最近邻) 搜索。
向量数据库并不保证找到绝对最相似的那几条,而是找到「差不多最相似的」几条,精度换速度。但在实际场景里,「差不多最相似的」和「绝对最相似的」效果几乎没有区别,因为语义检索本身就不需要那么精确。
那它用的什么算法?目前最主流的是 HNSW (Hierarchical Navigable Small World,分层可导航小世界图)。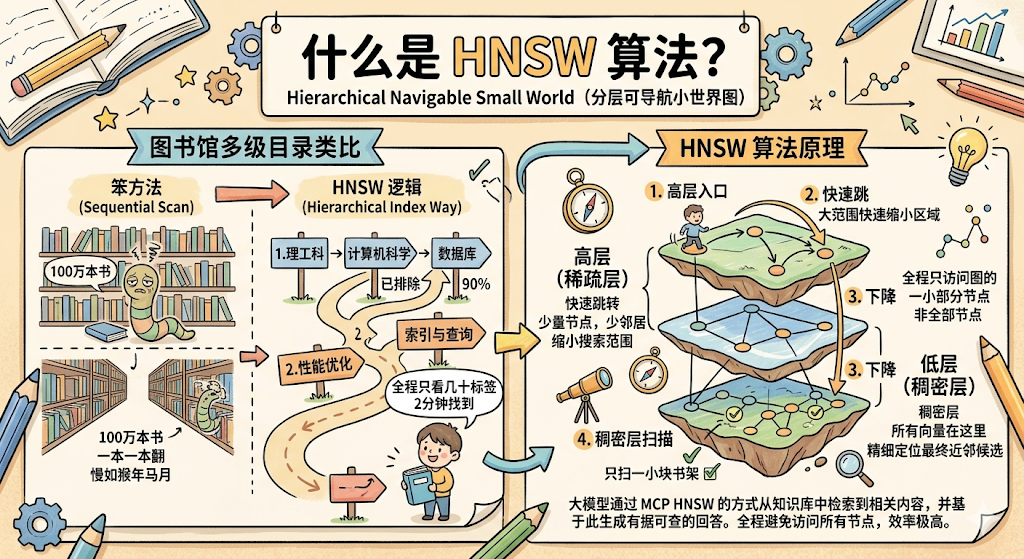
图书馆的多级目录类比
你去一个大图书馆,想找一本叫《MySQL 索引优化》的书。
笨方法 :从第一排书架的第一本书开始,一本一本翻,直到找到它。100 万本书的图书馆,你翻到猴年马月。
图书馆的实际做法 :
-
第一步,看大类目录牌:理工科 → 计算机科学 → 数据库技术。三步跳转,你已经排除了 90% 的书架区域。
-
第二步,看中类目录:性能优化 → 索引与查询。再两步,进一步缩小范围。
-
第三步,直接在这一小块书架上找。扫几眼,拿到书。
整个过程不超过 2 分钟,而你总共只「看过」几十本书的标签,不是 100 万本。
HNSW 就是这个逻辑。
它把所有向量组织成一个多层的图结构:
-
高层(稀疏层) :只有少量「节点」,每个节点连接着几个「邻居」。高层负责大范围的快速跳转,帮你快速缩小搜索范围。
-
低层(稠密层) :所有向量都在这里,精细定位最终的近邻候选。
查询的时候,从高层入口进,快速跳转几步找到大致区域,然后下到低层精细扫描。全程只需要访问整个图的一小部分节点,而不是所有节点。
结果: 牺牲极少量精度(通常 95%+ 的召回率),换来 100 倍以上的速度提升 。100 万条向量,几毫秒搞定。
主流向量数据库介绍
市面上向量数据库已经有不少选择了,咱们介绍五个最常见的。
Chroma
本地轻量级向量数据库,Python 原生 API,几行代码就能跑起来,不需要任何部署配置。
适合干什么: 本地开发、功能验证、快速上手原型 。你想跑通 RAG 的完整流程,Chroma 是最低摩擦的选择,装个 pip 包直接用。
缺点:不适合生产环境,没有高可用、分布式这些特性。
Pinecone
全托管的云向量数据库,你不需要管任何基础设施,服务器、扩容、备份全都是 Pinecone 的事,你只需要调 API。
适合干什么: 快速上线,不想自己运维 。创业公司、小团队,想把 RAG 功能上生产但没有专职 DBA,Pinecone 是最快的路径。
缺点:数据放在第三方,有数据合规顾虑的场景不适合;按用量收费,规模大了成本不低。
Milvus
开源的生产级向量数据库,功能最全,支持多种索引类型、分布式部署、数据持久化。背后是 Zilliz 公司(国产)维护,社区活跃,文档完善。
适合干什么: 私有化部署的生产环境 。数据不能出内网、需要精细控制、规模较大的场景,Milvus 是目前开源里功能最完整的选择。
缺点:部署和运维有一定复杂度,学习曲线比 Chroma 陡。
Weaviate
开源向量数据库,特色是内置了 Embedding 集成,你可以直接把原始文本丢进去,Weaviate 自动帮你调 Embedding 模型转向量,不用自己处理这一步。同时支持图片、音频等多模态数据。
适合干什么: 需要多模态搜索、或者想简化 Embedding 步骤 的场景。
Qdrant
Rust 实现的高性能向量数据库,内存占用低,查询速度快,适合资源受限或高并发场景。接口设计简洁,HTTP/gRPC 都支持。
适合干什么: 对性能和资源消耗敏感 的生产环境,比如在有限硬件上跑大规模向量检索。
怎么选?
讲了五个,选哪个?给你一个明确的决策树,不说「看情况」:
学习 / 跑原型 → 用 Chroma
零配置,pip 安装,几行代码跑通完整 RAG 流程。你现在就在学 RAG,直接用 Chroma,不要想太多。
生产环境,不想管运维 → 用 Pinecone
不想操心服务器、扩容、备份这些事,数据放云上也没问题,Pinecone 拿起来就用。
生产环境,需要私有化部署 → 用 Milvus 或 Qdrant
数据必须在自己服务器上,选这两个。团队有运维能力、需要最全功能选 Milvus;对性能和资源敏感、希望部署简单点选 Qdrant。
用厨房来类比这四个选择:
-
Chroma :家用厨房。够用,方便,不用专门装修,在家做饭首选。
-
Pinecone :叫外卖。你只管点菜,后厨、配送、洗碗全不用管,就是要花外卖费。
-
Milvus :专业餐厅厨房。功能齐全、可定制,但你得有专业厨师来管。
-
Qdrant :高效快餐厨房。出菜快、省资源,适合高并发大量出餐的场景。
普通数据库 vs 向量数据库
| 对比维度 | 普通数据库(MySQL) | 向量数据库(Milvus/Pinecone…) |
|---|---|---|
| 核心用途 | 结构化数据存储和精确查询 | 向量存储和相似度搜索 |
| 索引结构 | B+ 树(适合精确匹配/范围查询) | ANN 索引,如 HNSW(适合近邻搜索) |
| 查询类型 | id = 5、age > 18、LIKE 匹配 | 找 top-k 个最相似向量 |
| 向量相似度查询 | 不支持(只能暴力全表扫描) | 原生支持,毫秒级 |
| 百万级向量查询速度 | 数秒(暴力遍历,不可用) | 毫秒级(ANN 索引加速) |
| 数据形式 | 表格(行列结构) | 向量 + 元数据 |
| 适合 RAG 吗 | 存能存,查不行 | 专为这个场景设计 |
微调
1. 导入所有需要的库
from peft import LoraConfig, get_peft_model
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
from datasets import load_dataset
2. 基础模型配置
model_name = “THUDM/chatglm3-6b”
加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
加载模型(8bit 量化)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map=“auto”,
trust_remote_code=True
)
3. LoRA 配置(论文最优参数)
lora_config = LoraConfig(
r=64,
lora_alpha=128,
target_modules=[“q_proj”, “k_proj”, “v_proj”],
lora_dropout=0.05,
bias=“none”,
task_type=“CAUSAL_LM”
)
4. 给模型装上 LoRA 插件
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
5. 加载数据集(你的航空QA数据集)
dataset = load_dataset(“json”, data_files=“aircraft_qa_dataset.json”)
6. 训练参数配置
training_args = TrainingArguments(
output_dir=“./lora_chatglm3”,
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
learning_rate=2e-5,
num_train_epochs=10,
logging_steps=10,
evaluation_strategy=“epoch”,
save_strategy=“epoch”,
fp16=True,
push_to_hub=False
)
7. 定义训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset[“train”],
eval_dataset=dataset[“test”],
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
8. 开始训练(核心训练代码)
trainer.train()
9. 保存 LoRA 模型
model.save_pretrained(“lora_aircraft_model”)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)