RLinf-USER:面向具身智能中真实世界在线策略学习的统一且可扩展系统
26年2月来自清华、无问芯穹(Infinigence AI)、北理工、浙大、中关村学院和上海AI实验室的论文“RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI”。
直接在物理世界中进行在线策略学习,是具身智能领域一个充满前景但又极具挑战性的方向。与仿真不同,现实世界的系统无法随意加速、低成本重置或大规模复制,这使得可扩展的数据采集、异构部署和长期有效训练变得困难重重。这些挑战表明,现实世界的策略学习不仅是一个算法问题,更是一个系统问题。提出 USER,一个统一且可扩展的现实世界在线策略学习系统。USER 通过统一的硬件抽象层,将物理机器人与 GPU 并列为一等硬件资源,从而实现异构机器人的自动发现、管理和调度。为了解决云-边通信问题,USER 引入一个自适应通信平面,该平面采用基于隧道的网络(tunneling-based networking)、用于流量定位的分布式数据通道以及流-多处理器-觉察的权重同步机制来调节 GPU 端的开销。在此基础架构之上,USER 将学习组织成一个完全异步的框架,并配备持久化的缓存-觉察缓冲区,从而能够高效地进行长周期实验,并具备强大的崩溃恢复能力和历史数据的重用功能。此外,USER 还为奖励、算法和策略提供可扩展的抽象,支持在统一的流程中对 CNN/MLP、生成策略和大型视觉-语言-动作 (VLA) 模型进行在线模仿或强化学习。如图所示:
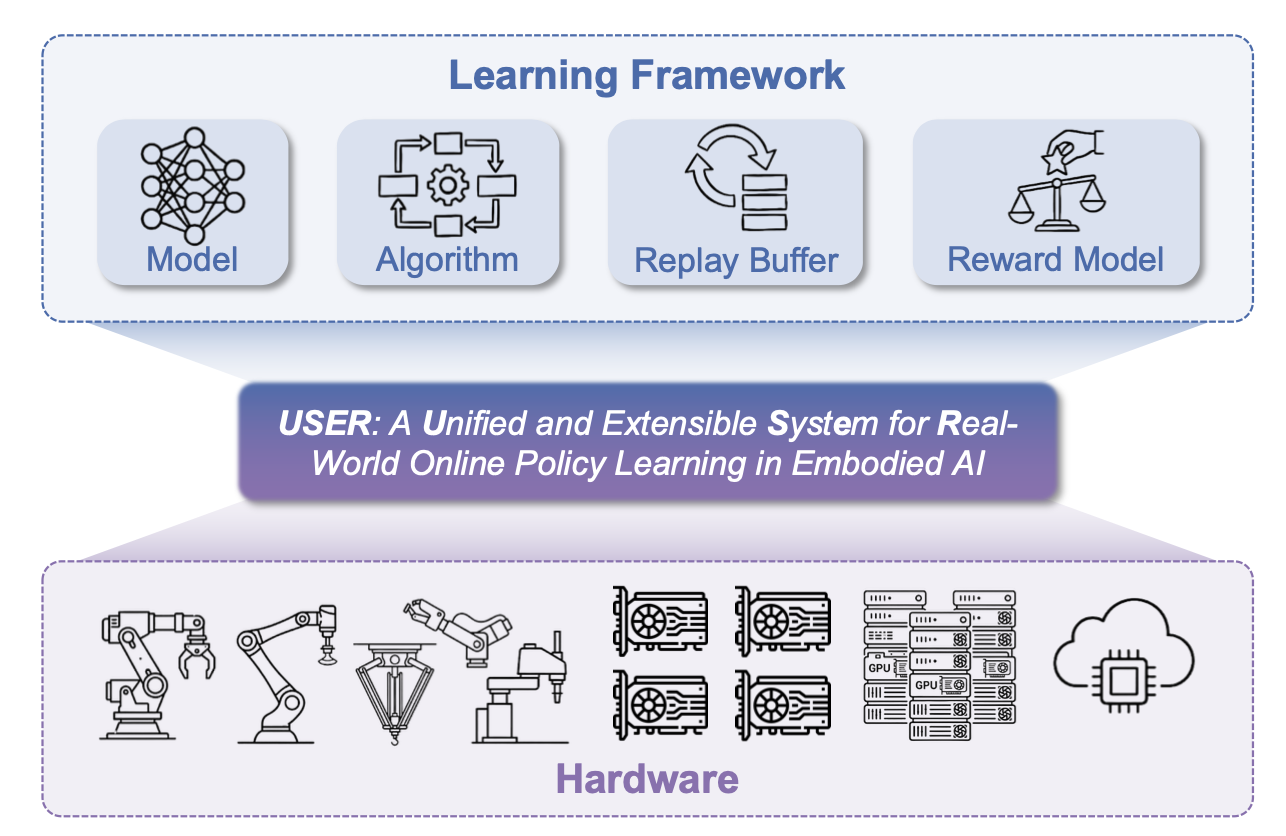
随着具身智能中现实世界策略学习的兴起,支持多机器人和异构部署变得至关重要。USER 的系统架构设计旨在为异构机器人和分布式计算资源上的现实世界策略学习提供统一且可扩展的系统支持。USER 的核心是将物理机器人和加速器虚拟化为一流的可调度硬件,并通过强大的云-边通信底层将它们连接起来。这种设计将学习逻辑与物理部署细节解耦,从而实现统一的资源管理、可靠的跨域网络连接以及跨多机器人、多节点环境的低延迟数据交换,如图所示。统一的硬件抽象层和自适应通信平面共同构成分布式异构环境下现实世界策略学习的基础架构。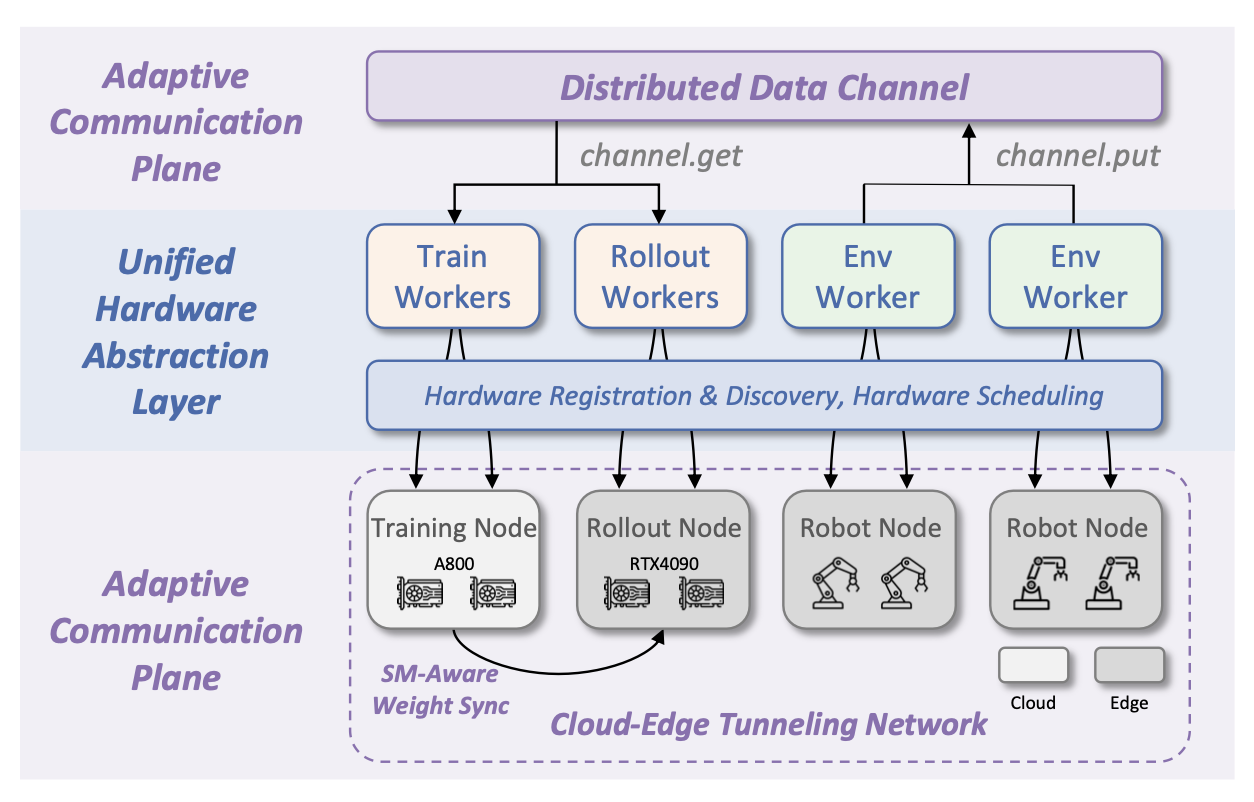
统一硬件抽象层
为了实现可扩展的真实世界策略学习,USER 的核心思想是将物理机器人视为加速器(例如 GPU 和 TPU),并将其视为一流硬件资源。为此,USER 将所有类型的机器人和加速器统一抽象为可调度硬件单元,并在一个特殊的硬件抽象层 (HAL) 中进行统一管理。HAL 提供统一的接口,用于扩展新型硬件、自动发现可用硬件资源以及为不同的学习任务调度硬件。
节点和硬件抽象。USER 将部署建模为一个节点集群,每个节点导出一组硬件单元。硬件单元是调度器的原子可分配实体——单个 GPU 设备或单个物理机器人,可选择性地捆绑其所需的外部设备,例如摄像头和空间鼠标。每个单元都由一个轻量级的类型化描述符(硬件类型和型号)以及配置元数据(例如机器人网络标识和传感器绑定)来描述。节点本质上是异构的,可以承载多种类型的硬件单元,例如不同类型的机器人和GPU,从而最大限度地提高部署的灵活性。在USER中,通常部署三种类型的节点:配备GPU用于策略推理的部署节点、运行在仅CPU机器上的机器人节点(用于在边缘执行动作)以及配备大规模加速器用于集中式训练的训练节点。节点可以组织成节点组来体现这种异构性,每个组包含同构的硬件单元,一个节点可以属于多个组,具体取决于其硬件组成。这样,硬件调度策略既可以对同构池进行推理,又能支持异构集群。
硬件注册和发现。HAL使用可插拔的检查器接口来注册和扩展新硬件。每种硬件类型都提供一个HAL检查器,用于定义(i)其类型标识符,(ii)如何在节点上发现硬件,以及(iii)附加到每个实例的元数据。这种模块化设计将设备特定的逻辑(GPU 厂商工具、机器人连接性检查、传感器发现)与系统的其余部分隔离开来。在集群初始化时,USER 通过在每个节点上启动一个轻量级硬件探测进程并调用已注册的 HAL 检查器来构建全局硬件清单,从而发现可用的硬件。这种发现可以是自动的(通常用于 PCIe 或 USB 连接的设备,例如 GPU、摄像头和空间鼠标),也可以是配置驱动的(通常用于 IP 绑定的机器人),因为后者需要显式绑定和安全检查。对于物理机器人,发现过程包括可选的验证,例如网络可达性、所需摄像头的存在以及基本健康检查,以确保只有可用的机器人才能进入可调度池。最终生成的清单会显示每个节点的可用单元及其等级,从而构成后续调度的基础。
硬件调度。USER 通过一个基于等级的单一放置接口来调度机器人和加速器——每个组件选择节点组和一组资源等级,其中等级解析为节点组内各个节点的加速器或机器人单元。调度器随后确定性地将进程等级映射到这些资源等级(平均共享单元或为每个进程分配多个单元),并启动每个进程,使其仅绑定到其分配的硬件(例如,受限的可见 GPU 设备或注入的机器人端点配置)。这种统一的机制支持在单个作业中进行异构部署,例如在一个 GPU 池上进行训练,同时将不同的部署进程子集绑定到不同类型的机器人。
自适应通信平面
实际的策略学习运行在云-边分布式计算资源上,尤其对于大规模 VLA 模型而言,部署节点和机器人节点位于边缘,而训练节点位于云端。USER 的自适应通信平面旨在解决由此产生的跨异构云边缘网络域的通信挑战。USER 通过基于隧道技术的云-边网络实现跨域连接,从而实现跨网络边界的数据交换。为了处理域内通信和跨域通信之间带宽不均的问题,USER 采用分布式数据通道来本地化流量并减少不必要的跨域传输。此外,USER 引入了流-多处理器-觉察权重同步,以防止基于 NCCL 的通信垄断 GPU 资源并降低吞吐量。
基于隧道技术的云-边网络。USER 运行于云-边计算资源之上,跨越不同的管理网络域(例如,NAT、园区网、工厂 VLAN),这些网络域本身是隔离的,不支持直接通信。为了弥合这一差距,USER 基于 UDP 隧道技术,在扁平化的 TCP/IP 底层构建其通信平面,使所有机器人、训练节点和部署节点都能通过隧道建立双向连接。控制平面使用 Ray [21] 进行集群成员分配和工作节点部署,而数据平面则依赖 TCP 汇合(rendezvous) 来引导点对点通信组;至关重要的是,USER 将所有控制/数据流量绑定到隧道接口,从而使异构部署能够应对多宿主主机,并避免意外地将流量路由到速度较慢或受防火墙保护的链路上。
分布数据通道。在 USER 中,节点间的数据交换通过通道抽象实现统一。通道代表连接系统组件的数据流管道,承载观测值、动作、状态和中间结果。传统的集中式通信方式,数据首先发送到云节点,然后再分发到边缘节点,虽然实现起来简单,但在云边部署中会产生大量的跨域流量。在多机器人或高频实际交互场景下,这种设计存在延迟高、稳定性差的问题 [3, 7]。为了解决这个问题,USER 提供一种分布式数据通道:一个由轻量级通道服务托管的、命名的、先进先出 (FIFO) 的生产者-消费者队列,可通过异步 put/get API 访问。通道内部基于数据键(例如机器人 ID)在服务实例之间进行分片,以将流量限制在边缘或云区域内,并减少跨域传输。它们支持多个生产者和消费者,使机器人和部署节点能够流式传输数据,而无需直接的同步耦合。这种设计最大限度地减少了跨域通信,并平衡了各个通道服务的负载。
SM-觉察权重同步。在USER中,当权重同步通过NVIDIA集体通信库(NCCL)执行并在GPU之间直接传输时,会占用GPU执行资源,因为NCCL的集体通信作为CUDA内核执行,会消耗流多处理器(SM)。USER通过一个可调配置来显式地控制这种资源争用,该配置限制权重传输期间使用的NCCL CTA(协作线程组)的最大数量。通过限制NCCL的SM占用,USER可以防止后台权重同步独占GPU执行资源,从而避免降低滚动延迟和吞吐量。这使得USER能够在异步权重更新的情况下维持稳定、低延迟的滚动。
基于虚拟化并连接异构机器人和计算资源的系统架构设计,USER 的学习框架设计着重于运行时数据和计算的组织方式。具体而言,它定义一个统一的真实世界学习框架,包括一个完全异步的流水线、持久缓存感知缓冲区以及用于策略、算法和奖励的可扩展抽象。
完全异步流水线
在真实世界的策略学习中,主要瓶颈在于数据收集而非计算[17]。物理交互无法加速,因此保持机器人持续运行至关重要。将数据生成和训练紧密耦合的同步流水线容易出现级联停顿:训练中的延迟会传播到执行阶段,迫使机器人暂停,并显著降低数据效率。
如图所示(学习框架设计和全异步流水线),USER 将真实世界的策略学习组织成一个完全异步的流水线。在数据生成方面,多个环境工作节点通过部署工作节点在物理机器人上执行策略,持续不断地传输观测数据和动作,而不会受到优化进程的阻塞。与此同时,人类操作员可以通过远程操作进行干预,提供修正或演示,而奖励工作节点则分配监督信号。所有交互数据都会异步地被摄取到一个持久缓存感知缓冲区中,该缓冲区包含一个用于自主部署的轨迹回放缓冲区和一个用于存储预收集数据和人类干预的演示缓冲区。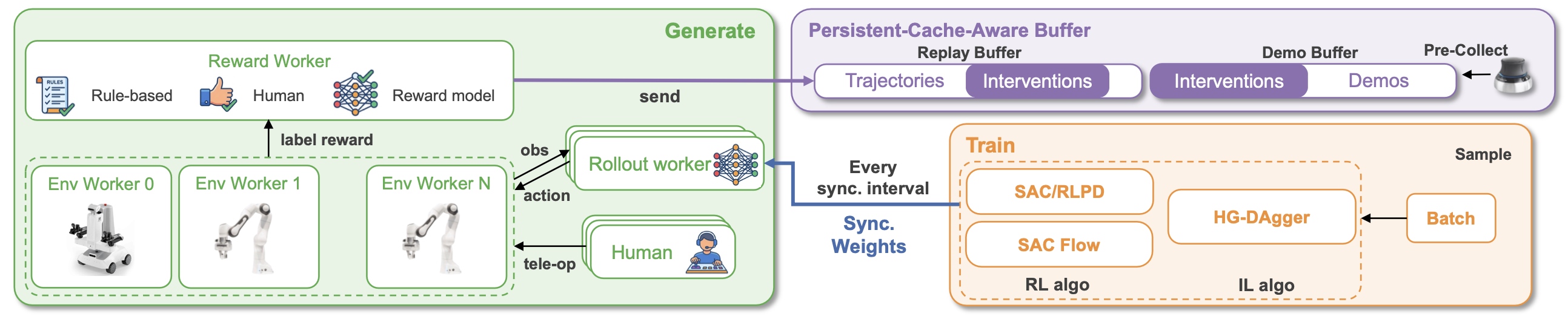
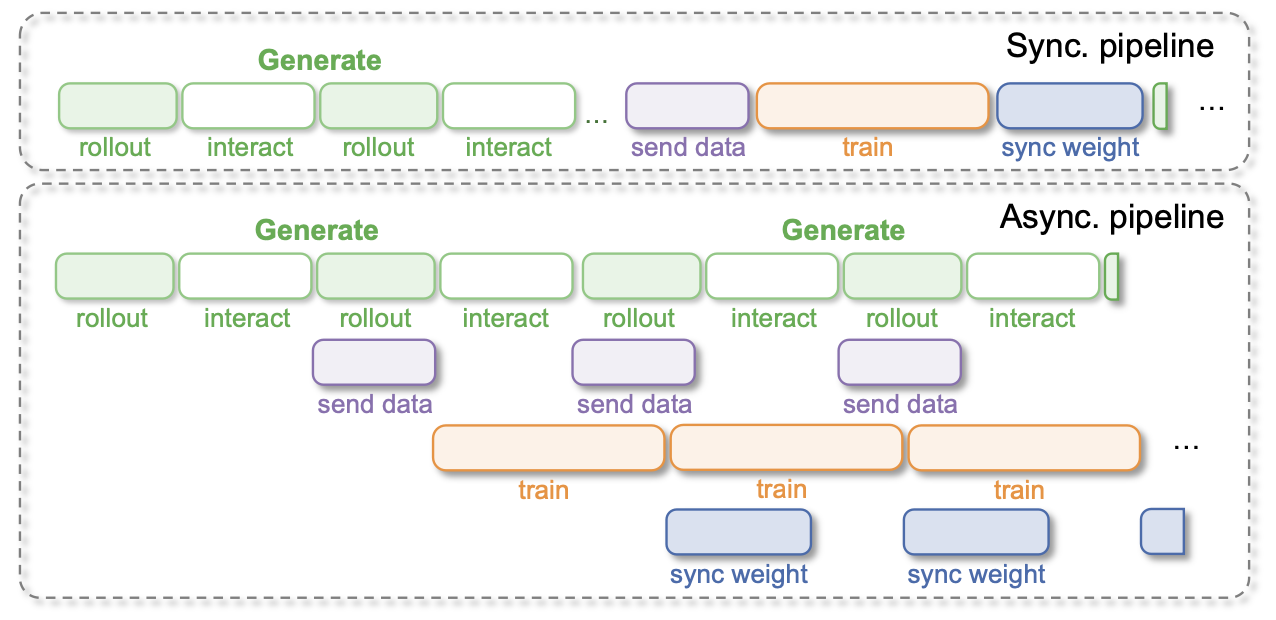
在训练方面,学习工作节点会异步地从这些缓冲区中抽取小批量数据来更新模型参数,从而支持强化学习和模仿学习。更新后的权重会定期同步回部署工作节点,形成闭环,同时保持机器人不间断执行。
持久-缓存-觉察的缓冲区
现实世界的具身学习涉及长时程、非平稳策略和异步流水线。训练过程跨越多个会话和策略版本,网络故障、重启和人为干预十分常见。在不同策略下收集的数据通常需要重用于非策略更新或恢复,这使得短期内存缓冲区无法满足实际部署的需求。
USER 采用持久化的基于索引缓冲区(如图所示),将存储与内存解耦。轨迹异步写入磁盘,而缓冲区则存储包含策略版本、时间戳和事件 ID 等元数据的轻量级索引,从而实现对时间和策略的长期采样。为了平衡效率和内存,USER 添加一个有界内存缓存,并采用先进先出 (FIFO) 机制进行替换。新样本首先进入缓存;当缓存满时,旧条目将被驱逐,但仍保留在磁盘上的索引。被驱逐的样本会在需要时透明地重新加载,从而在内存有限的情况下保持高吞吐量采样。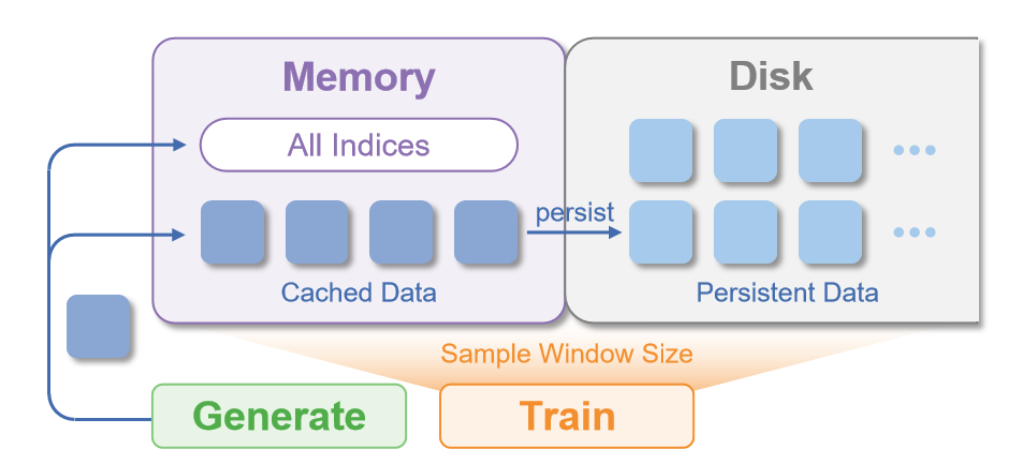
与仅保留近期数据的内存缓冲区[5, 26]不同,USER的持久缓存-觉察设计支持任意大的数据集,并能在策略演进过程中保留历史数据。持久化还通过崩溃恢复和流水线解耦提高了鲁棒性,从而实现了超越易失性内存中心设计的可靠的长期真实世界学习。
可扩展的策略、算法和奖励
USER与模型架构和学习算法无关,它提供统一的接口,使异构策略、优化器和奖励机制能够共享单个执行和数据流水线。
在策略层面,USER同时支持轻量级模型和大规模模型。轻量级策略包括基于CNN和MLP的控制器,例如ResNet风格的视觉策略[9],以及通过连续概率流表示动作的表达性流匹配策略[16]。在大规模应用中,USER 集成 VLA 模型(例如 π0/π0.5 架构 [2, 12]),这些模型能够处理多模态输入并输出连续动作。尽管结构和计算方式有所不同,但所有策略都通过统一的部署抽象层进行部署。
在算法层面,USER 支持多种机器人学习范式。这些范式包括离策略强化学习(RL),例如 Soft Actor-Critic (SAC) [8];用于流策略的高效采样强化学习(例如 SAC-Flow [28]);人机协同方法,例如使用预训练数据的强化学习 (RLPD) [1];以及用于大型模型的模仿式更新,例如 HG-DAgger [14]。训练工作节点通过标准化的采样和更新 API 与策略交互,使得优化层可以互换。
奖励机制也采用模块化设计。USER 支持 (i) 基于规则的任务奖励,(ii) 人工提供的标签,以及 (iii) 学习的奖励模型。奖励可以在部署过程中附加,也可以在后处理阶段离线计算,从而在现实世界的约束条件下实现灵活的监督。
USER 通过统一策略表示、算法和奖励来源,无需重新设计部署、数据处理或执行流程,即可支持从强化学习到模仿学习和人机协同学习等各种现实世界的学习设置。
实验设置
设计一套包含五个真实世界操作任务的实验集,以评估 USER 学习框架的可扩展性,如图所示:插销插入、充电、拧紧瓶盖、拾取放置和桌面清理。所有任务均在 Franka 机械臂上完成。
小策略(包括 CNN 和基于流的模型)的实验在配备 CNN RTX 4090 (24GB) GPU 的本地工作站上执行,而大型 VLA 策略(例如拾取放置π0 模型)则在配备 4 个 NVIDIA A100 (80GB) GPU 的服务器上进行训练和评估。选择四种具有代表性的算法,涵盖在线强化学习和模仿学习:SAC、RLPD、SAC-Flow 和 HG-DAgger。从基于规则的奖励、人工奖励和学习的奖励模型中选择适合每项任务的奖励来源。基于规则的奖励用于固定位置操作任务,并根据末端执行器的姿态计算得出。人工奖励是二元的,操作者成功则奖励 1,失败则奖励 0。奖励模型根据观察结果对成功 (1) 或失败 (0) 进行分类。
硬件设置
在两个不同的机器人平台上进行所有实验:一个是7自由度的Franka机器人手臂,另一个是6自由度的低成本ARX机器人手臂(如图所示):

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)