6自然语言处理-NLP
NLP 是用深度神经网络让机器理解、生成、处理人类语言的技术,核心是词嵌入 + 注意力机制(其成熟实现就是 Transformer) + 预训练大模型。
在 Transformer 出现之前,NLP 很笨,有了 Transformer,NLP 直接起飞。Transformer 是现在所有顶尖 NLP 模型的 “底层骨架”。
以前的 NLP:RNN、LSTM 这类模型
- 只能按顺序读句子
- 长文本容易忘前面的内容
- 并行计算差,训练慢
现在的 NLP:几乎全都基于 Transformer
- BERT(理解类)
- GPT(生成类)
- T5、LLaMA、文心一言、豆包……全都是 Transformer 变种。
什么是 Transformer?
Transformer 是一种基于「自注意力机制(Self-Attention)」的深度学习模型结构。
它的核心特点:
- 不靠循环(RNN/LSTM),也不靠卷积
- 能同时看到一整段文本,而不是一个词一个词往后看
- 擅长计算每个词和其他所有词的关系强弱
- 并行计算能力极强,训练速度远快于传统模型
一、怎么用数据表示文字:

以上为常见的输入
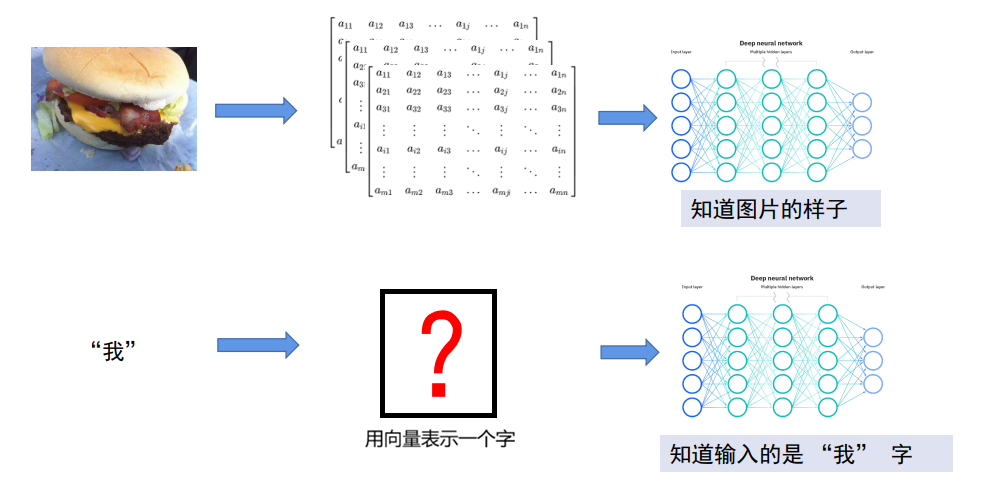
1. 最原始:one-hot 编码(字典法)
将文字编码为向量,假设有词典:[我,爱,学,深度,学习],每个词对应一个只有一个 1,其余全 0的向量。
缺点:1如果要想表示每一个字,则维度太长了;2每个字之间体现体现不出关系。

2. 现代方法:词嵌入(Word Embedding)
把每个词变成一个短的、有意义的小数数组(向量),让机器能看懂、能计算语言。机器看文字只能看懂 0 和 1,完全不懂文字。所以我们需要把每个词,映射成一个固定长度的数字向量,这就叫 词嵌入。
例子(5 维向量):
我 → [0.12, 0.45, -0.23, 0.66, 0.02],
学习 → [0.88, 0.11, -0.73, 0.21, 0.55]
关键特点:
- 意思相近的词,向量挨得近
- 国王 - 男人 + 女人 ≈ 女王
- 这就是 Word2Vec、GloVe 做的事
3. 现在最强:上下文词向量(BERT/GPT 用)
根据语境动态变化。同一个词,不同语境,向量不一样。例:
- 我今天学
深度学习 - 这本书很有
深度
两个 “深度” 向量不同,因为语境不同。这叫 动态词嵌入。
二、常见的输入:每个词对应一个编码。

三、常见的输出
1、每个词都有输出一个值
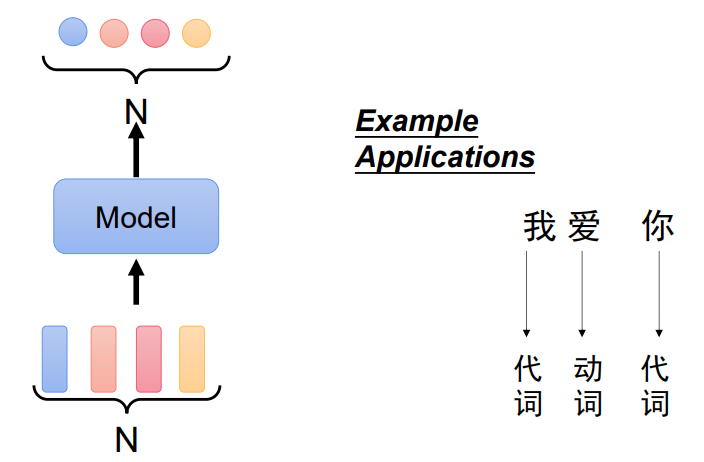
假如有个词性识别任务:
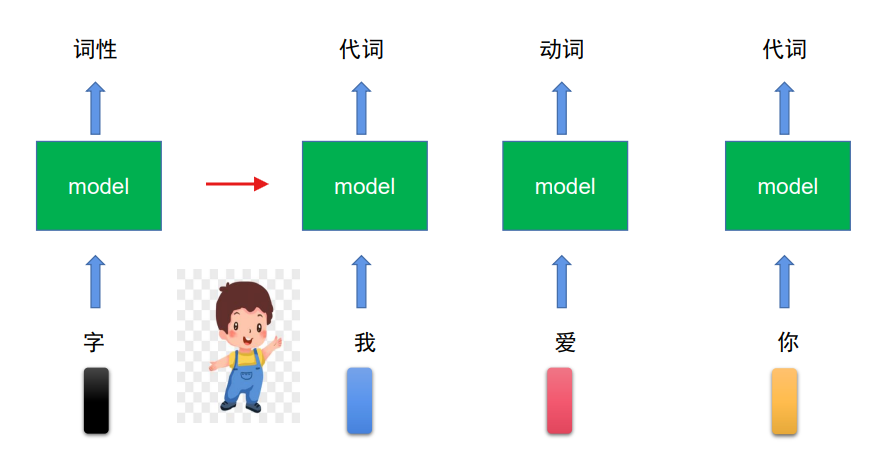
但问题是,无法判断“爱”是动词还是名词
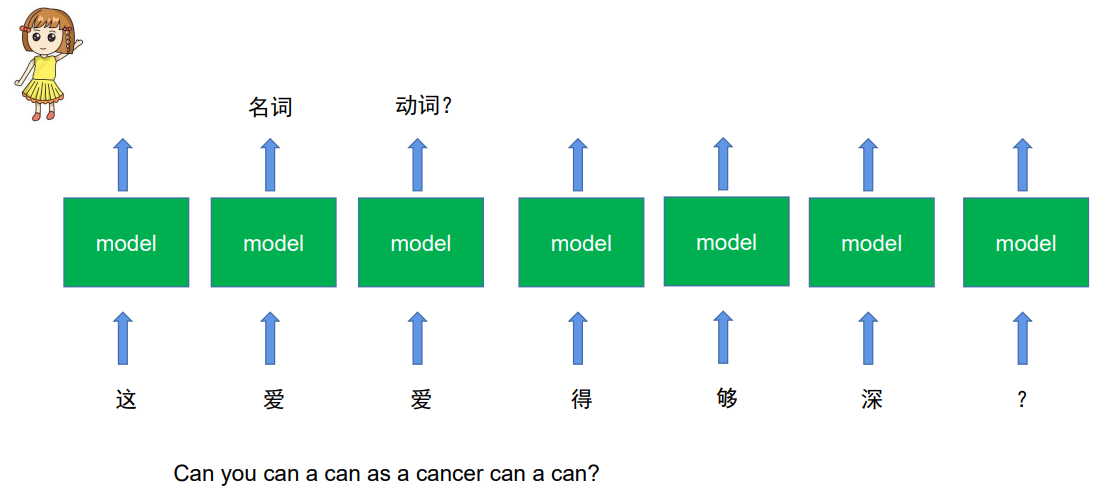
所以要考虑序列的前后关系。这就引出了RNN:循环神经网络
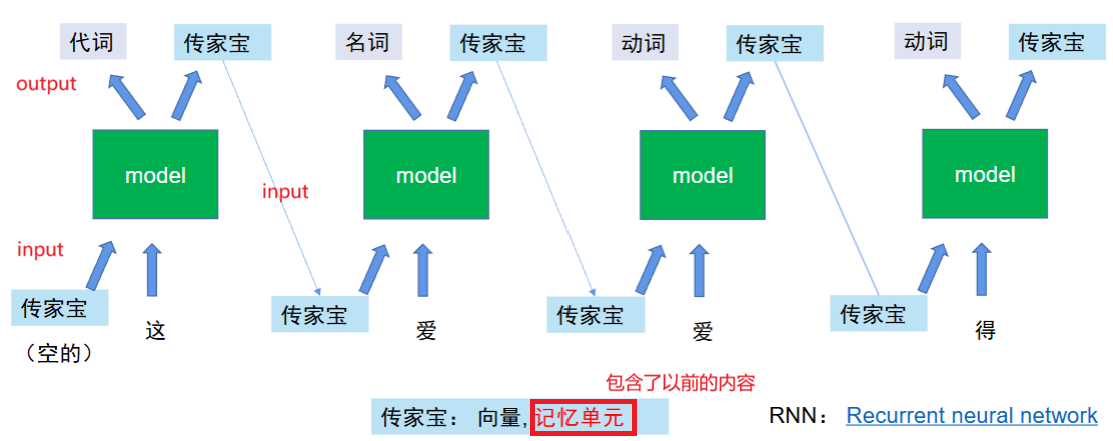
RNN(Recurrent Neural Network)就是一种专门处理序列数据的神经网络,它的核心设计是通过 “记忆” 前一步的信息,来处理当前步的输入,从而自然地捕捉序列的前后关系。RNN 的核心原理:循环 + 状态记忆。
RNN 有一个记忆单元,可以理解成模型的 “短期记忆”,或者“传家宝”:
- 每处理一个字(序列中的一个元素),都会用「当前字的输入 + 上一步的记忆」更新「新的记忆」
- 这个 “记忆” 会沿着序列一步步传递,自然捕捉前后关系
RNN 的问题:长序列记不住(梯度消失或爆炸)。如果序列很长(比如 100 个字的句子),前面的信息会慢慢 “丢失”,比如处理第 100 个字时,几乎记不住第 1 个字的内容。
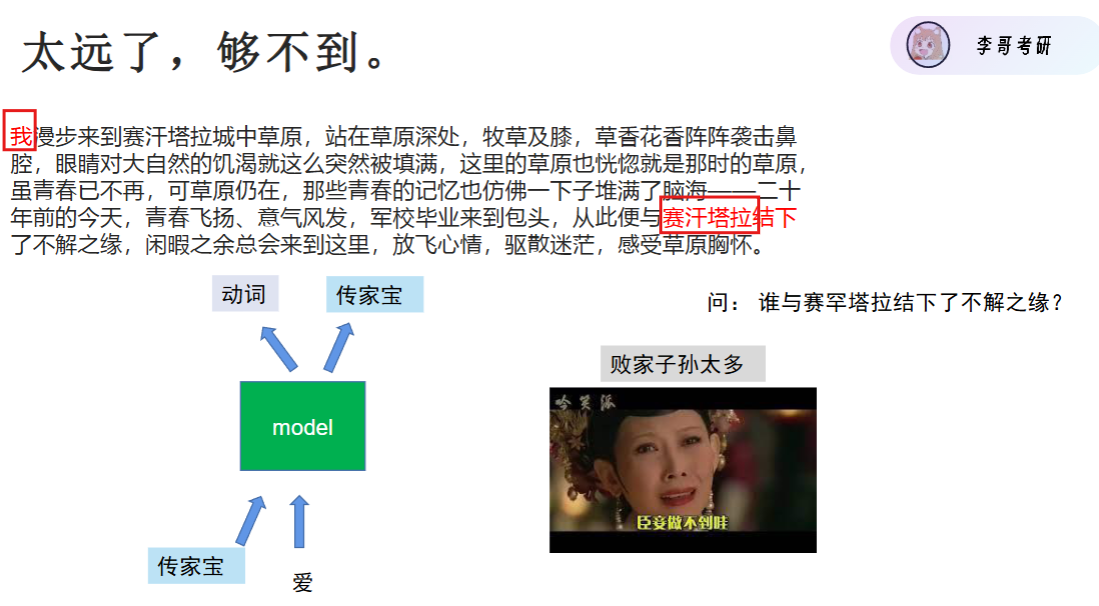
为了解决这个问题,衍生出了升级版 RNN:LSTM(长短期记忆网络)
- 新增 “门控机制”(输入门、遗忘门、输出门),可以主动 “记住重要信息”“忘记无关信息”
- 比如处理 “我昨天买了苹果,今天吃了它”,LSTM 能记住 “它” 指代的是 “苹果”
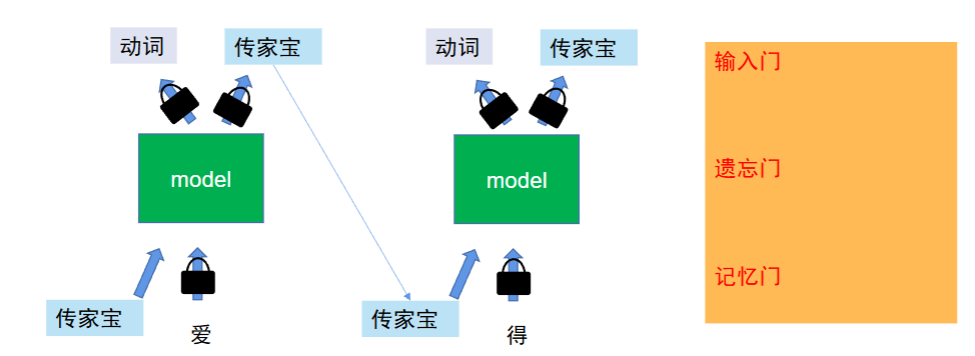
但是 RNN 和 LSTM 太慢了,只可串行
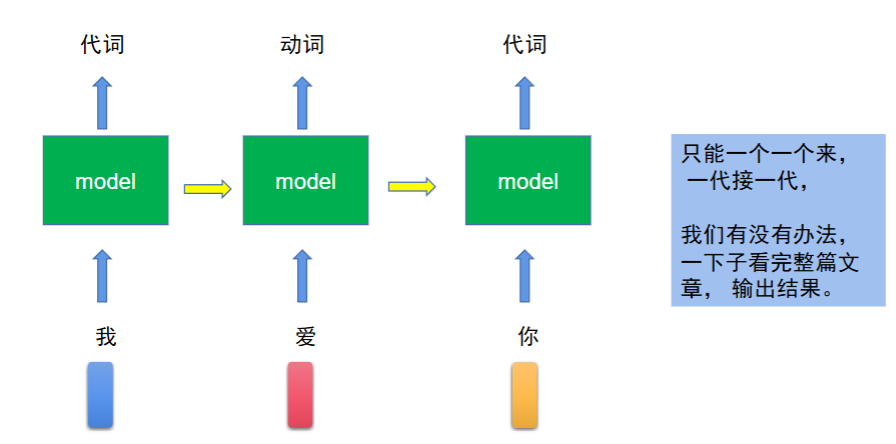
“串行”,指的是必须等前一个字处理完,才能处理下一个字,一步接一步算,没法同时算多个字;而 Transformer 能 “并行”,把一整句话的所有字同时算完,速度差几十上百倍。
这就引出了
自注意力机制(Self-attention)
- RNN:一个字一个字看,只能记住前面的,而且必须串行。
- 自注意力:一句话所有字同时看,每个字都能直接和任何一个字产生关系。
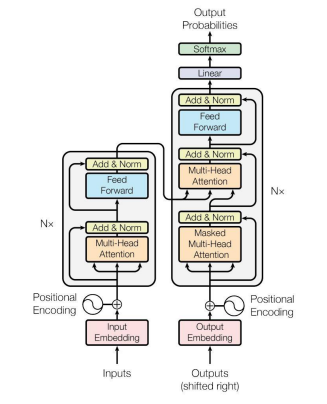
自注意力 = 一句话里,每个字都看一遍所有字(包括自己),自动决定重点看谁。是 Transformer、BERT、GPT 的灵魂。
即:一句话里,每个字都给其他所有字打个 “相关性分数”,分数高 = 关系近,重点看;分数低 = 关系远,少看。
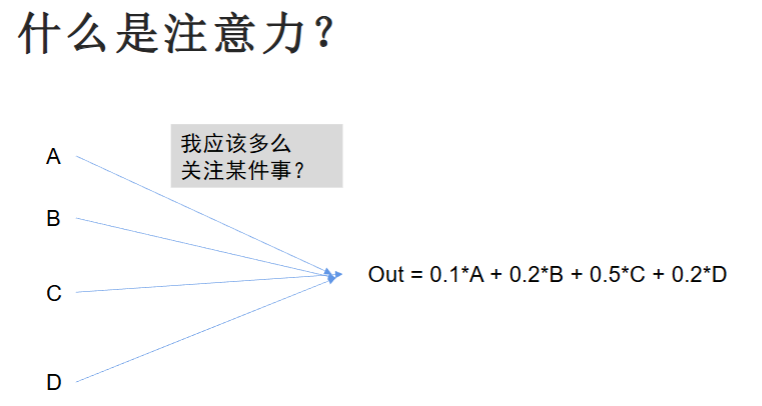
例:句子:“我 昨天 买了 苹果,今天 吃了 它”
模型要知道 “它” 指的是谁。
自注意力怎么做?
让 “它” 这个字,去看句子里所有字:
- 它 ↔ 我 → 分数低
- 它 ↔ 昨天 → 分数低
- 它 ↔ 买了 → 分数低
- 它 ↔ 苹果 → 分数极高
- 它 ↔ 今天 → 分数低
- 它 ↔ 吃了 → 分数低
结果:它 = 苹果
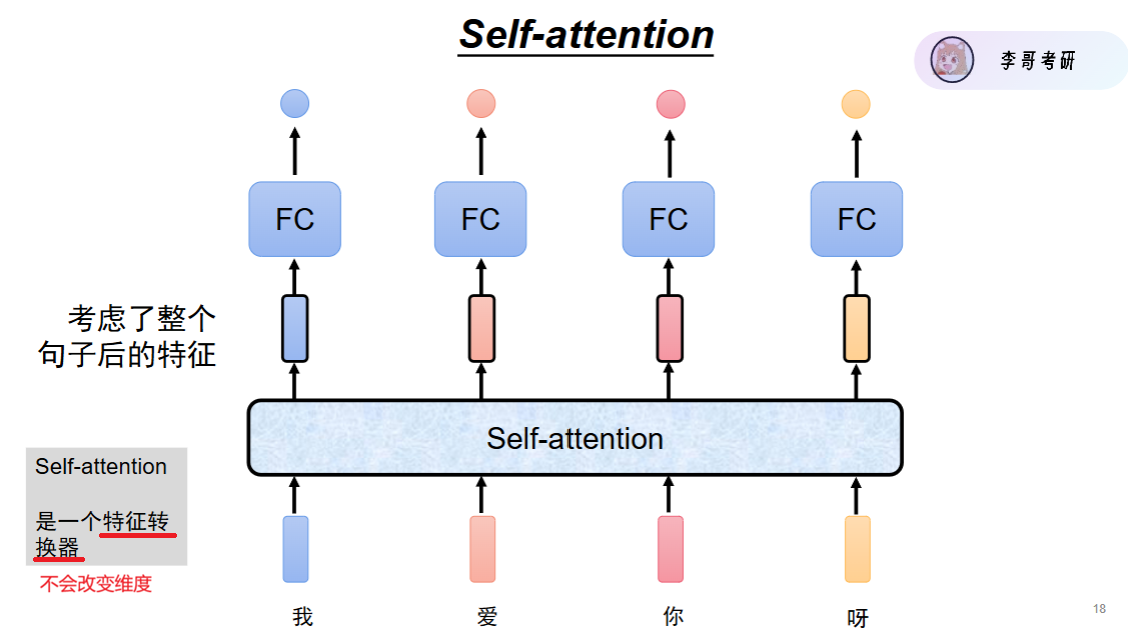
如何计算注意力
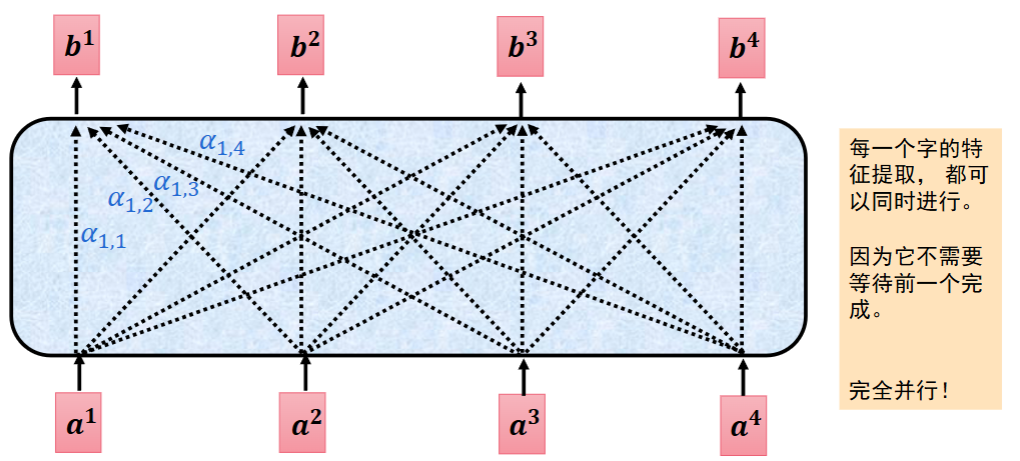

计算公式
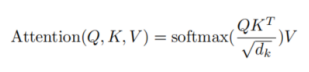
简单来说:注意力 = 先算相似度 → 再算权重 → 再加权求和
step0. 先准备三个向量(每个词都有)

这3个矩阵是随机初始化、会被训练的矩阵
全连接层的本质,就是矩阵相乘,所以也可以说是全连接
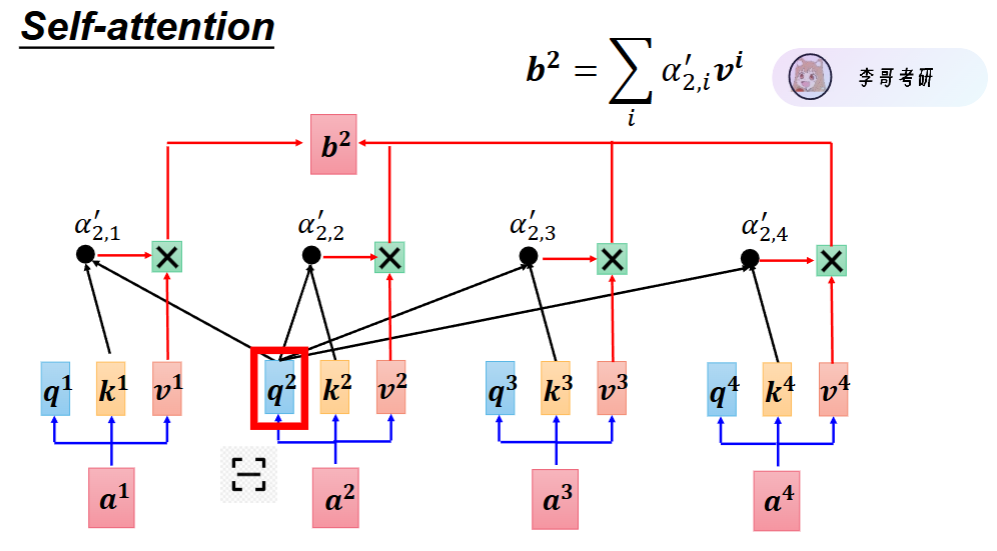
每个词 embedding 后,会通过矩阵得到 3 个向量:
- Q (Query):我要找什么
- K (Key):我这里有什么
- V (Value):我真正的信息内容
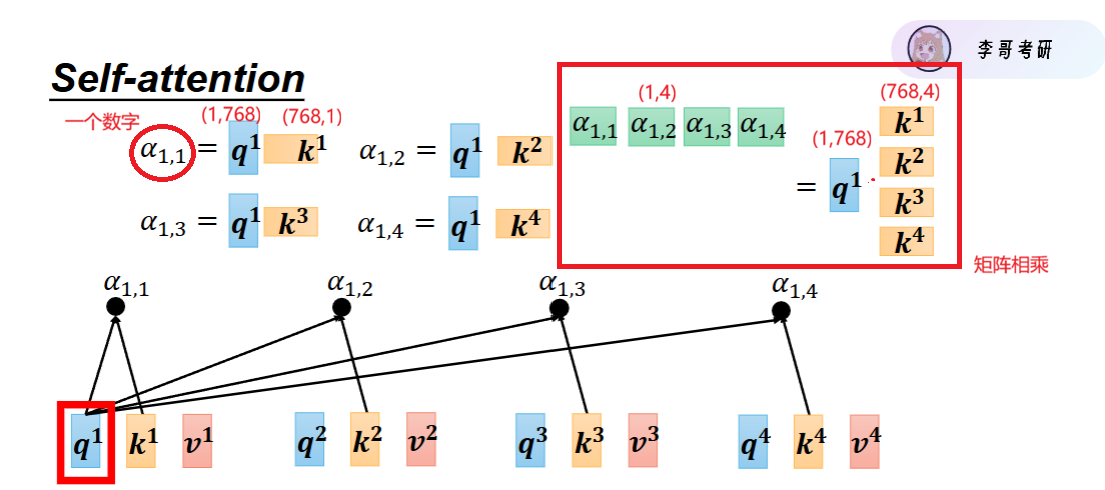
step1. 第一步:算相似度(Q・K)
相似度 = 这个词和句子里所有词的关系有多近
计算方式:当前词的 Q・所有词的 K。(点积越大 → 向量方向越接近 → 语义越相关,点积本质就是:相似度)


例子:句子:我 吃 苹果。我们算 “苹果” 的注意力:
- 苹果.Q・我.K → 分数 1
- 苹果.Q・吃.K → 分数 2
- 苹果.Q・苹果.K → 分数 3
得到一组原始分数。
step2. 第二步:除以根号 d_k(防数值太大,让Softmax 失效)
就是把分数缩小一点,防止 Q・K 点积太大,导致 Softmax 变成 “硬打分”,梯度消失。不用理解为什么,知道是缩放就行。

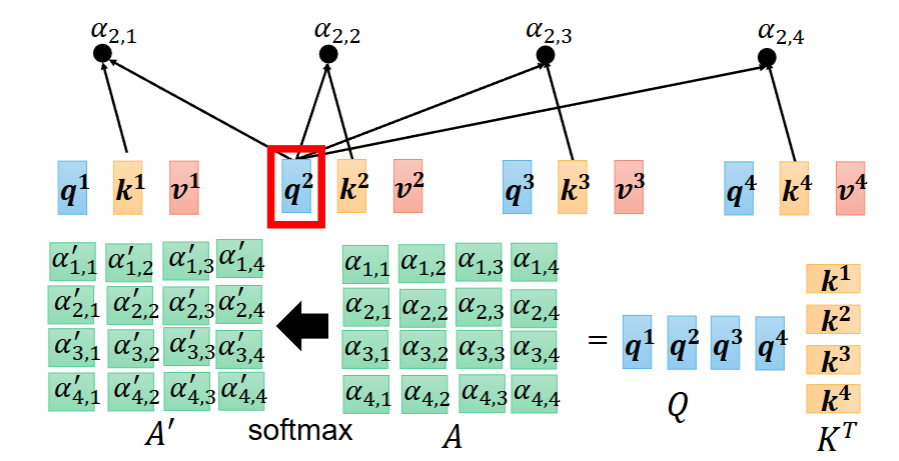
step3. 第三步:softmax 变成权重(0~1 之和 = 1)
把分数变成概率一样的权重:
- 权重越高 = 越关注
- 权重越低 = 越不关注
比如:
- 我:0.1
- 吃:0.2
- 苹果:0.7
这就是注意力权重。注意力权重 = 每个词该信多少、看多少
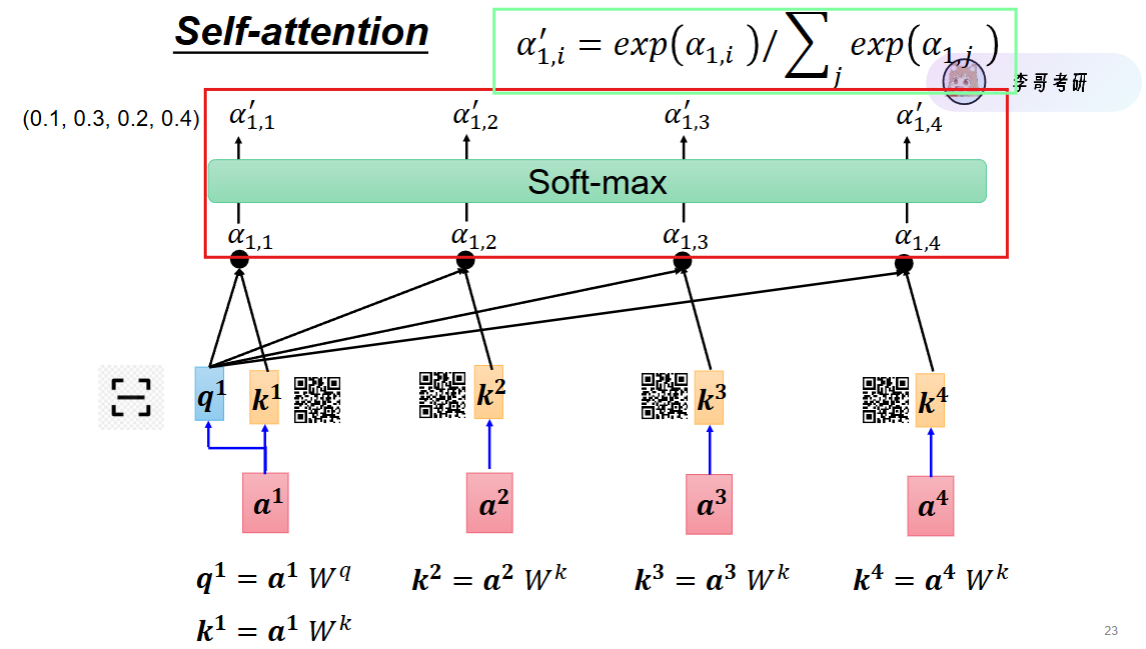
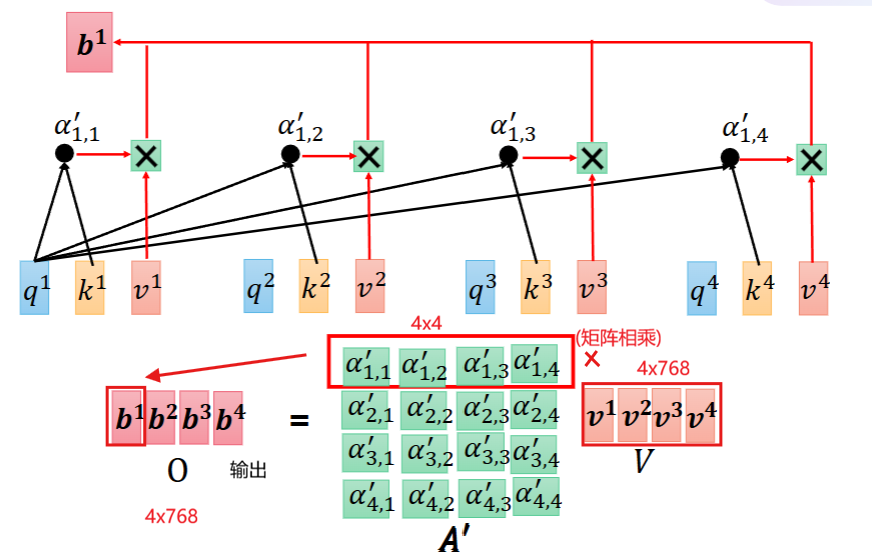
step4. 第四步:权重 × V 加权求和(最终结果)
用权重去乘每个词的 V,再加起来:最终向量 = 0.1 × 我.V + 0.2 × 吃.V + 0.7 × 苹果.V,这个结果,就是带上下文信息的词向量。

综上,总结:
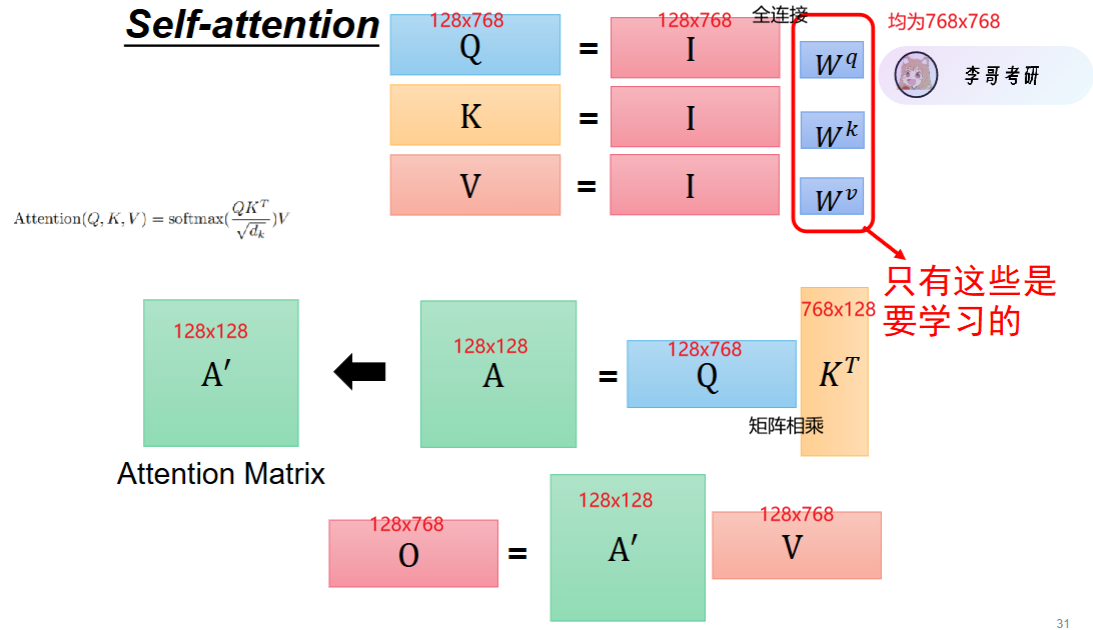
一般一个self - attention 模型 ,一个字的编码维度是768, 字的个数可以按照128,或者512计算。这里的数字的含义是什么?
- 768 维:指每个字的向量长度(特征维度),是模型对一个字的 “描述维度”;
- 128/512:指序列长度(token 数量),是模型能处理的 “最多字数”,本质是序列维度。
对应到模型里,描述一个字(比如 “苹果”),用的是:[0.12, -0.45, 0.67, ..., 0.89] → 768 维特征(768 个小数)
1、如何得到Q、K、V?
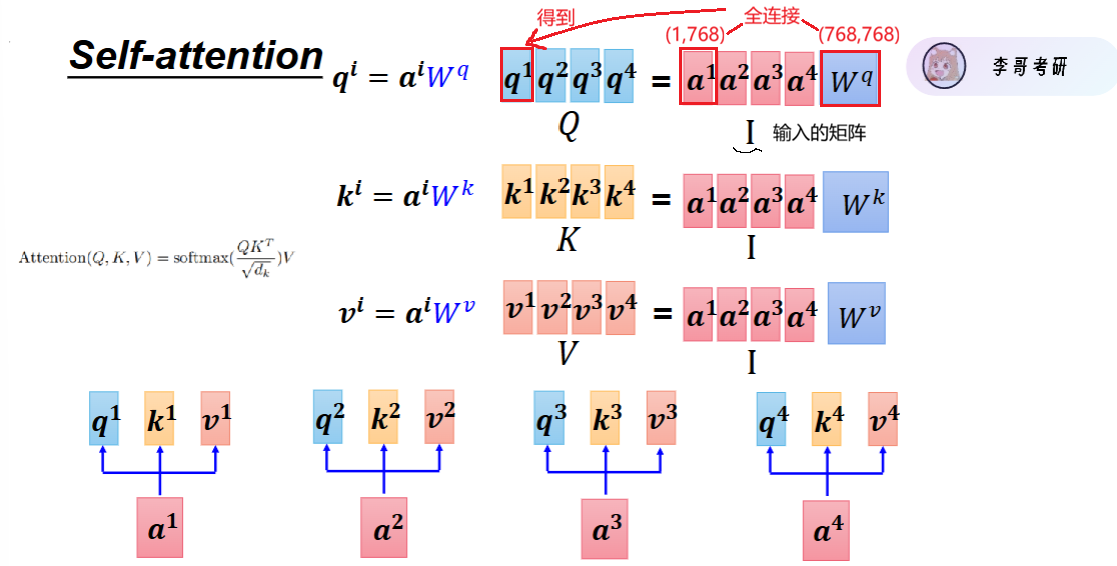
2、算相似度 + softmax:
类似的:
3、权重 × V 加权求和(最终结果)
我们可以简化为:(可以看到,维度并未改变,仍为128x768)
2、所有词输出一个值
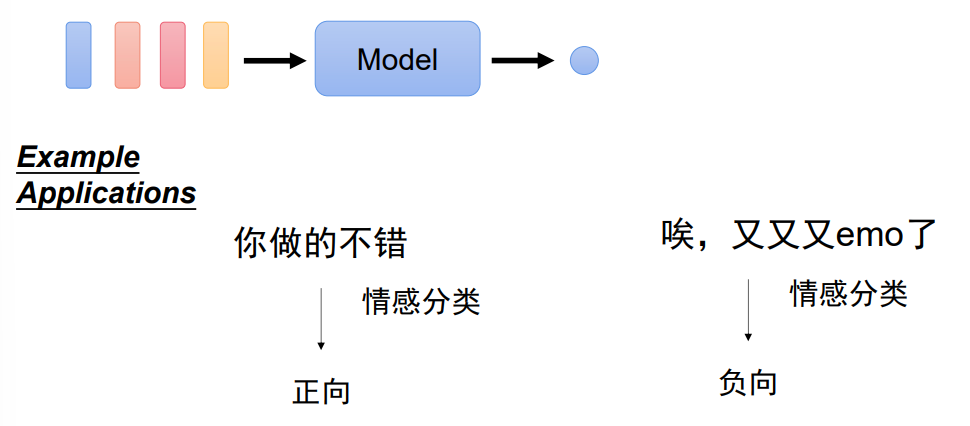
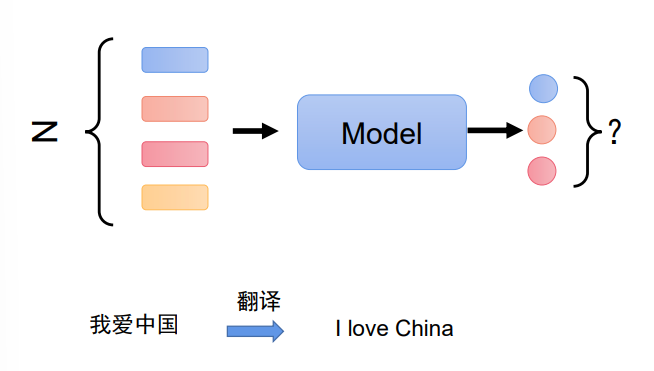
3、输入输出长度不对应
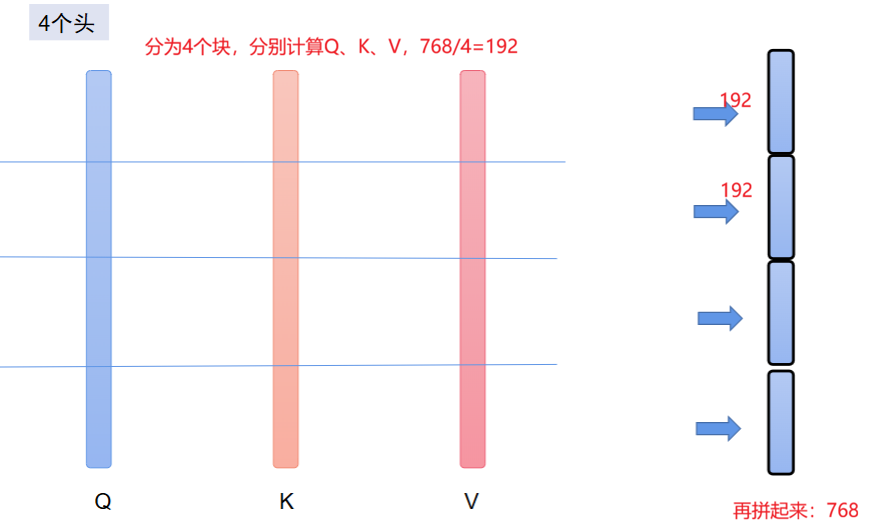
四、多头、多层、分层自注意力机制
在单个自注意力层内部,把 Q、K、V 分成多个 “头”(head),每个头独立计算注意力,最后再把结果拼接起来。让模型在同一层里,同时从多个不同角度(比如语法、语义、指代关系)去关注句子里的信息,而不是只看一个角度。(拓宽模型视野)
BERT-base 模型正是由 12 层 Transformer 编码器堆叠而成,每一层都包含一个 12 头的自注意力机制

也可以实现多层自注意力结构,它是 Transformer / BERT 等模型的核心堆叠方式,指把自注意力层 + 全连接层重复堆叠多次,形成一个深层网络。让模型一层一层地从词级、句级,再到篇章级,逐步理解更深层的语义。(加深模型深度)
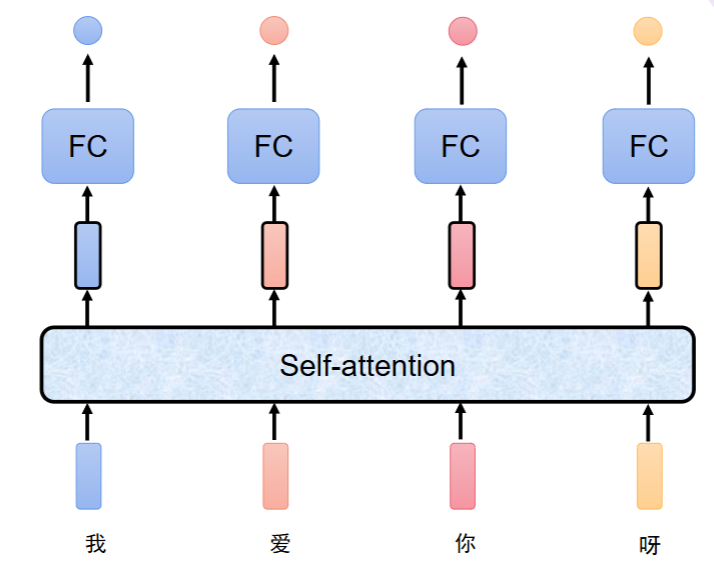
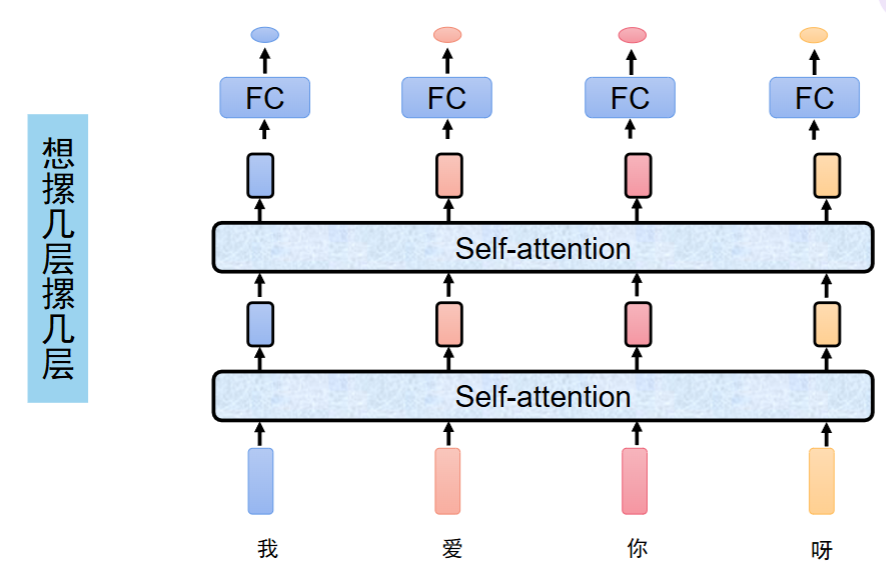
在 BERT-base 中,就堆叠了 12 层 这样的自注意力 + 全连接结构
分层注意力机制(Hierarchical Attention)
是针对任务定制的注意力—— 核心是 “按信息类型分层加权”,比如先给 “词”(情感词 / 中性词)分层,再给 “句子片段”(核心情感段 / 铺垫段)分层,是 “按信息维度拆分” 的注意力,目的是让模型精准聚焦核心情感信息。
五、位置信息(编码)
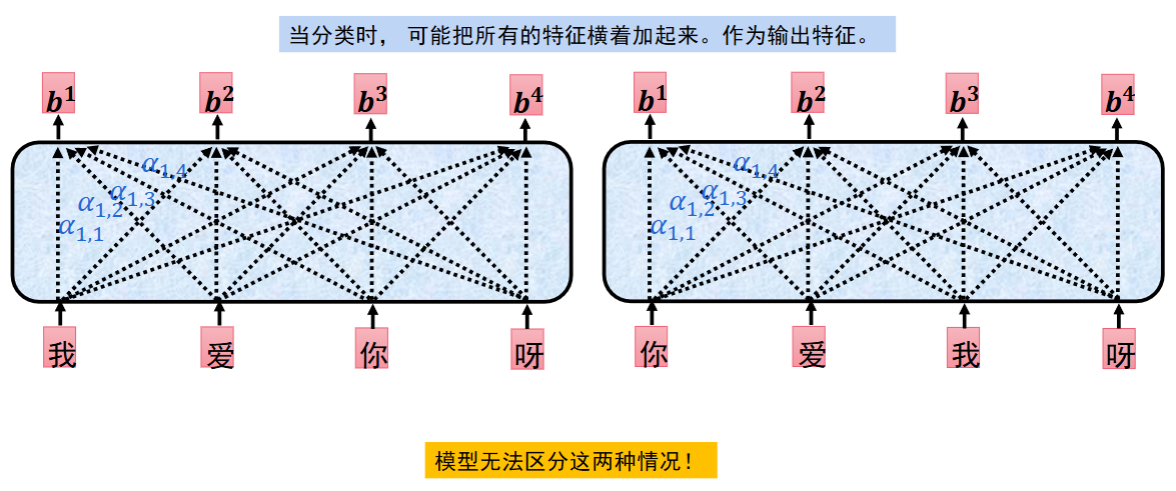
Transformer 的自注意力机制有一个天生的 “缺陷”:
- 它是无序的,对输入序列的顺序不敏感。
- 不管你把 “我爱你” 排成 “我爱你” 还是 “你爱我”,自注意力计算出来的结果是一样的。
但语言是有序的,语序变了,意思就完全变了。
它的核心作用有三点:
-
恢复语序信息让模型知道词与词之间的先后顺序,比如 “我” 在 “爱” 前面,“你” 在 “爱” 后面。
-
帮助理解依赖关系很多语言现象(比如指代、时态、逻辑关系)都和位置有关。例如:“我昨天看到了它”,模型需要知道 “昨天” 在 “看到” 之前,“它” 指代的是前面提到的事物。
-
让自注意力 “有序化”位置编码和词嵌入相加后,作为模型的输入,这样自注意力在计算时,就会把位置信息也考虑进去,从而理解有序的语言结构。
因此可以加上位置信息(编码),输入=词嵌入+位置编码(二者直接相加),让 Transformer 从 “无序的注意力机器” 变成 “能理解语序的语言模型”。
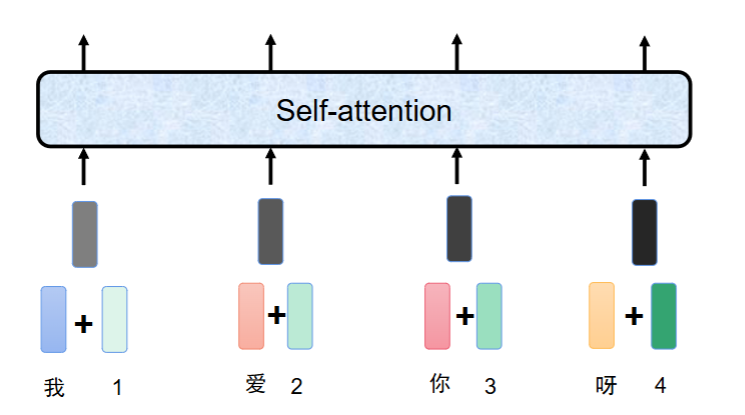
这就是self-attention
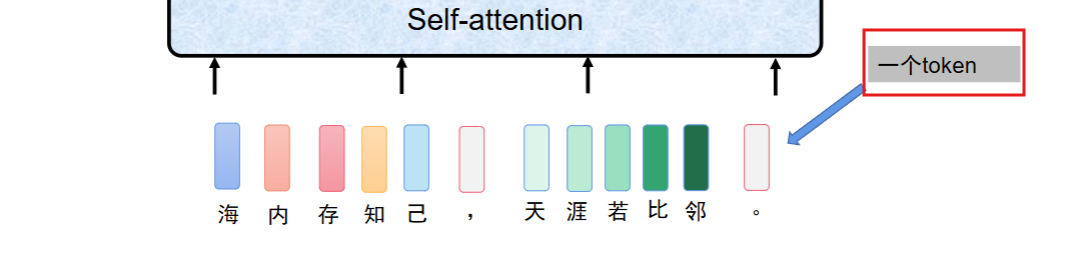
Token 是什么?
Token 就是 “最小处理单元”,可以理解成模型眼里的 “字 / 词 / 子词”,是它能直接处理的最小单位。Token = 模型能直接 “读” 的最小语言单位。
- 词嵌入 → 给每个 Token 一个向量
- 位置编码 → 给每个 Token 一个位置标签
- 自注意力 → 让每个 Token 关注其他 Token
不同语言、不同分词方式,Token 会不一样:
- 英文:常切成子词(subword),比如
unhappiness→un,happiness - 中文:可以是单字、词或子词,比如 BERT 中文模型常把每个汉字当作一个 Token
1、为什么要切 Token?
-
控制词汇表大小如果把每个词都当一个独立 Token,词汇表会爆炸(上百万词),模型太大。用子词(subword)可以把词汇表控制在几万以内,同时又能覆盖所有词。
-
处理未登录词(OOV)遇到训练时没见过的词,也能拆成已知子词,比如
ChatGPT→Chat,G,PT,模型照样能处理。 -
统一输入长度模型需要固定长度的输入,所以句子会被切成固定数量的 Token,不足就补
[PAD],太长就截断。
2、常见特殊 Token
在 BERT 里,你会经常看到这些特殊 Token:
[CLS]:放在句首,用来做分类任务的输出[SEP]:分隔两个句子[MASK]:做预训练时用来 “盖住” 词,让模型预测[UNK]:未知词(没见过的词)[PAD]:填充,用来对齐长度
六、预训练模型:Bert
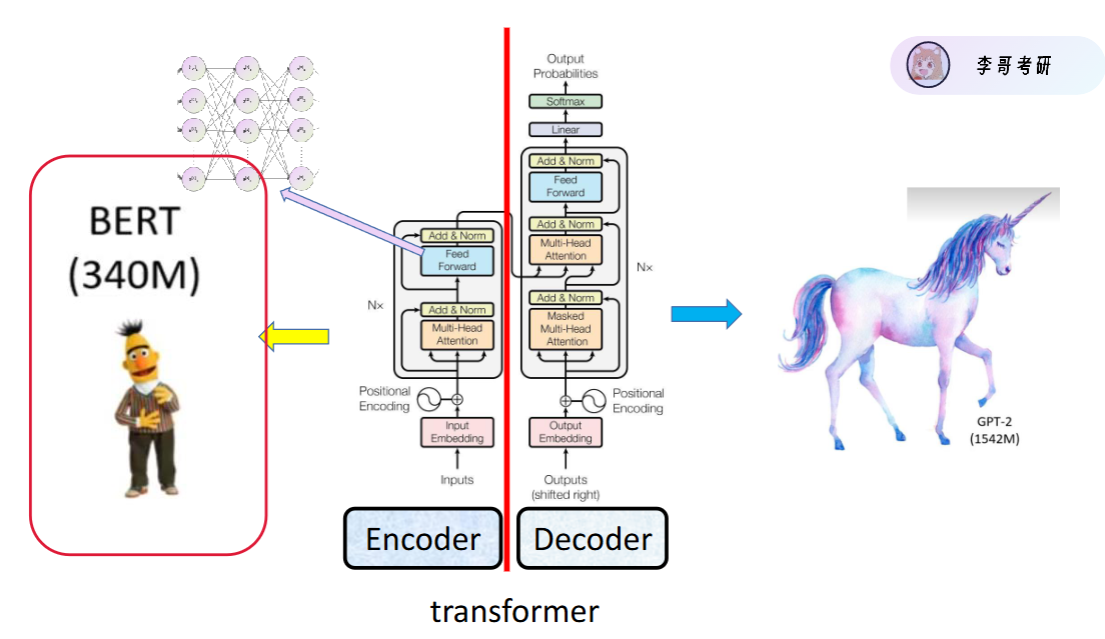
Bert 就是用 Transformer 的 Encoder 部分做出来的预训练模型,专门做理解类任务:分类、匹配、抽取、问答等。
它是一个 “超级会理解中文 / 英文” 的预训练模型,它的核心:一句话里,每个字都能看懂左右两边的上下文。
1、BERT 能干嘛?(全是理解类任务)
- 文本分类(情感分析、垃圾邮件识别)
- 命名实体识别 NER(找人名、地名、机构)
- 语义相似度
- 问答系统(阅读理解)
- 文本匹配
BERT 是 “理解型” 模型,不擅长生成(写诗、写文章靠 GPT)。
#补充:什么是「上游任务」、「下游任务」?
(1)上游(预训练):BERT 先在超大文本数据上学语言 → 变成一个语言大神
(2)下游(微调 Fine-tune):用预训练好的 BERT,去做你真正想干的具体任务。你把 BERT 拿来,在你的小数据集上再训练一点点,让它变成:
- 情感分析机器人
- 客服意图识别
- 试卷批改模型
- 信息抽取工具
2、三个关键点
- BERT = 基于 Transformer 编码器(Encoder)的预训练模型(双向 Transformer 编码器)
- 它是 “双向” 理解:看一个字时,左边 + 右边一起看
- 先预训练,再微调:学会通用语言能力,再拿去做具体任务(下游任务)。
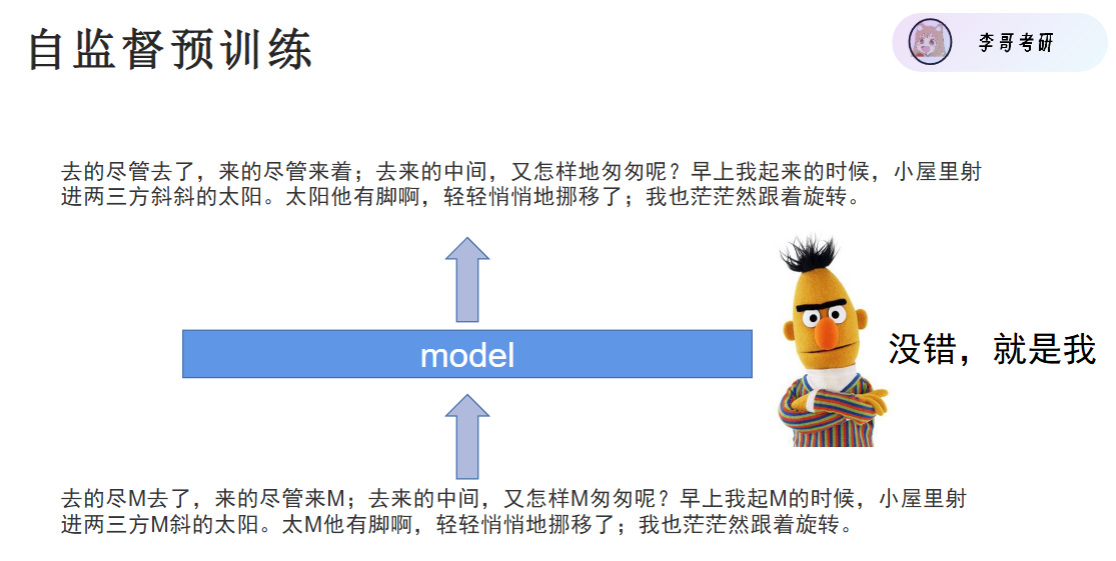
BERT 采用自监督预训练,通过两个任务同时学习语言表示:(数据是普通文本,没人给标注)
-
MLM(Masked Language Model,掩码语言模型)随机将句子中 15% 的 token 替换为
[MASK],让模型根据上下文预测被遮住的词。目的:学习双向上下文语义,使每个词都能同时利用左右语境信息。 -
NSP(Next Sentence Prediction,下一句预测)输入一对句子 A、B,让模型预测 B 是否是 A 的真实下一句。目的:学习句子间的逻辑关系与篇章连贯性。
通过 MLM + NSP 联合训练,BERT 获得了强大的通用语言理解能力,可直接在下游任务(文本分类、NER、语义匹配、问答等)上微调使用。
它用文本本身当监督信号,所以叫:自监督学习
3、Bert 结构
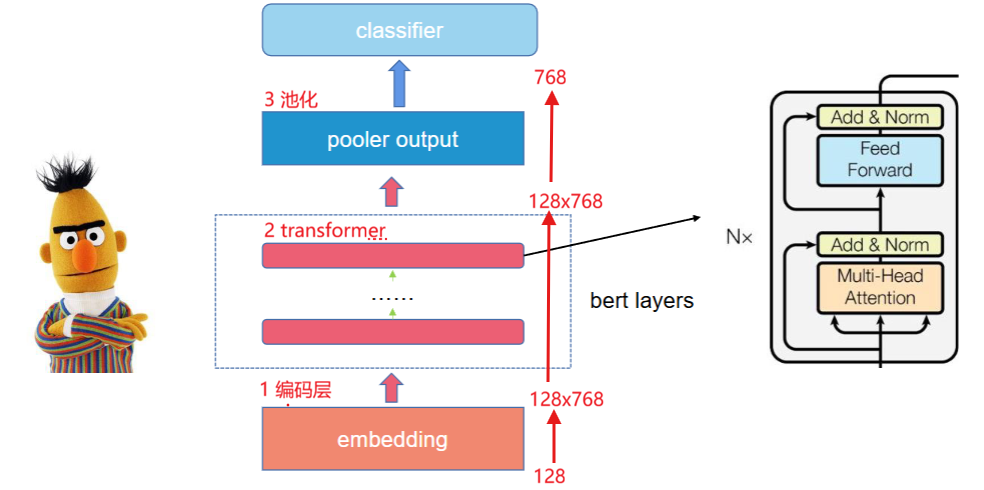
BERT 的结构可以理解为:多层堆叠的 Transformer Encoder的双向预训练语言模型,核心是 “自注意力 + 全连接” 的重复。
(1)整体结构
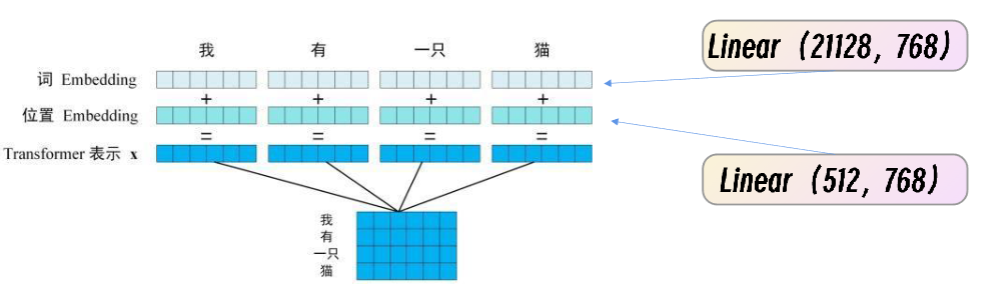
1、输入层(Input Embedding)
- 把句子切成 Token(如 “我”“爱”“你”)。
- 每个 Token 得到 3 种嵌入:
- Token Embedding:词的语义信息。
- Segment Embedding:区分两个句子(用于句子对任务)。
- Position Embedding:位置信息,解决 Transformer 无序的问题。
- 三者相加,得到最终输入向量。
最终输入:Token + Segment + Position 三者相加
2、Transformer Encoder 层(核心堆叠)
- BERT-base:12 层 Encoder;BERT-large:24 层。
- 每一层 Encoder 都包含:
a. 多头自注意力(Multi-head Self-Attention):让每个 Token 关注句子中其他 Token 的信息。Attention 是线性、全局的,
b. 残差连接 + 层归一化(Residual Connection + LayerNorm):防止梯度消失,稳定训练。
c. 全连接前馈网络(Feed Forward Network, FFN):对注意力结果做非线性变换,提取更复杂的特征。FFN 是非线性、每个 token 独立的。
d. 再次残差连接 + 层归一化。
3、输出层(Pooler)
BERT 最后要输出一整个句子的向量,用来做分类任务(情感分析、语义匹配等)。它规定:用句子第一个 token [CLS] 的输出,代表整个句子。但 [CLS] 输出是 768 维,内容全但杂乱,有重复、有冗余、重点不突出,作者想再做一次变换 + 激活,让句子表示更规整,核心目的是突出句子核心语义、消除冗余干扰、规整数值范围;最终效果是让这个向量能更精准、稳定地支撑所有句子级任务(分类、匹配、推理等)。从模型层面,还能加速训练收敛、提升泛化能力,让 BERT 在下游任务中表现更好。所以加了一层:Pooler = 全连接层 + Tanh。
Pooler层的核心是「整理信息而非改变维度」:输入输出都是 768 维,只优化向量内的信息分布;
它的输入输出维度:输入:[CLS] 的向量 = 768 维;输出:还是 768 维(保持维度统一)。
- 取句首特殊 Token
[CLS]的输出,经过一个全连接层和 Tanh 激活(双曲正切函数,把任意数字,压缩到 [-1, 1] 之间),用于句子级任务(如分类、匹配)。 - 对于 Token 级任务(如命名实体识别、问答),则直接使用每个 Token 的输出向量。
BERT 是由 12 层 Transformer 编码器堆叠而成的双向语言模型,输入由字向量、句子向量、位置向量三者相加,通过 MLM 与 NSP 自监督预训练,得到强大的语言理解能力。
BERT 预训练 = 用「填空题(MLM)+ 上下文题(NSP)」当作业,让模型在海量文本里反复刷题,学会语言的双向上下文和篇章逻辑。
我用一个生活化的比喻 + 一步一步的流程,帮你把 BERT 预训练的完整流程讲清楚👇
🎭 先打个比方:BERT 预训练就像「语文老师教学生」
- 输入层 = 老师给学生出「填空题 + 上下文判断题」
- Encoder 层 = 学生读题、理解整段话的意思
- 输出层 = 学生写出答案,老师批改打分(算损失、教学生改)
🚶 完整流程拆解(按顺序走一遍)
1. 【准备阶段:出题】—— 对应图里的 输入层
老师(数据处理)先准备两道题:
- 题目 1(MLM:填空题)原句:我 爱 吃 苹果随机遮掉 15% 的词 → 我 [MASK] 吃 苹果目标:让模型根据「我、吃、苹果」猜出被遮住的「爱」
- 题目 2(NSP:上下文题)句子 A:我爱吃苹果句子 B:它很脆甜(真实下一句)/ 今天下雨了(随机句子)目标:让模型判断句子 B 是不是句子 A 的真实下文
然后把题目变成模型能懂的向量:
- 每个字 → Token Embedding(字的意思)
- 句子 A/B → Segment Embedding(区分哪句是 A、哪句是 B)
- 字的顺序 → Position Embedding(告诉模型「我」在第 1 位、「爱」在第 2 位)
- 三者相加 → 最终输入向量,喂给模型
2. 【思考阶段:读题理解】—— 对应图里的 Transformer Encoder 层
模型(学生)开始读题,用 12/24 层 Encoder 反复理解上下文:
- 多头自注意力:让每个字都看看左右邻居
- 比如
[MASK]会去看「我、吃、苹果」,知道这里应该填一个表达喜好的字 [CLS]会看整段话,总结句子 A 和 B 的关系
- 比如
- 残差连接 + 层归一化:保证模型不会越学越乱,稳定理解
- FFN 前馈网络:对每个字做更复杂的语义加工
- 重复上面步骤 12/24 次 → 每个字都得到一个「懂了整段话」的向量
3. 【答题阶段:写答案 + 批改】—— 对应图里的 输出层
模型读完题,开始分别做两道题:
✅ 做 NSP 题(上下文判断)
- 用
[CLS]的向量(代表整段话的意思) - 经过 Pooler(全连接 + Tanh)→ 把向量整理得更规整
- 再经过一个小分类层 → 输出两个概率:「是真实下文」/「不是真实下文」
- 老师批改:和真实标签对比,算损失,告诉模型哪里错了
✅ 做 MLM 题(填空)
- 只看被
[MASK]遮住的字的向量 - 经过一个线性层 → 把向量映射到词表大小(比如 3 万个词)
- 经过 Softmax → 输出每个词的概率,挑概率最高的作为答案
- 老师批改:和真实被遮住的字对比,算损失,告诉模型哪里错了
4. 【学习阶段:改错题】
模型根据两道题的损失总和,调整自己的参数(Encoder、输出层的权重)
- 下次再做类似题,就会更准
- 反复做几百万、几千万道题 → 模型就学会了「语言的规律」
(2)计算Bert参数(忽略偏置值b)
BERT-base:12 层,hidden size=768,feed forward=3072
先记这 4 个关键数
- 词表大小:30522(BERT 官方词表)
- 隐层维度:d = 768
- 层数:L = 12
- FFN 中间层(负责 “把信息加工得更复杂”):4*d = 3072(没有公式规定必须 4d,只是 Transformer、BERT 作者们实验出来的最优配置。太窄:学不动;太宽:参数爆炸、变慢;4d:刚好又强又快)
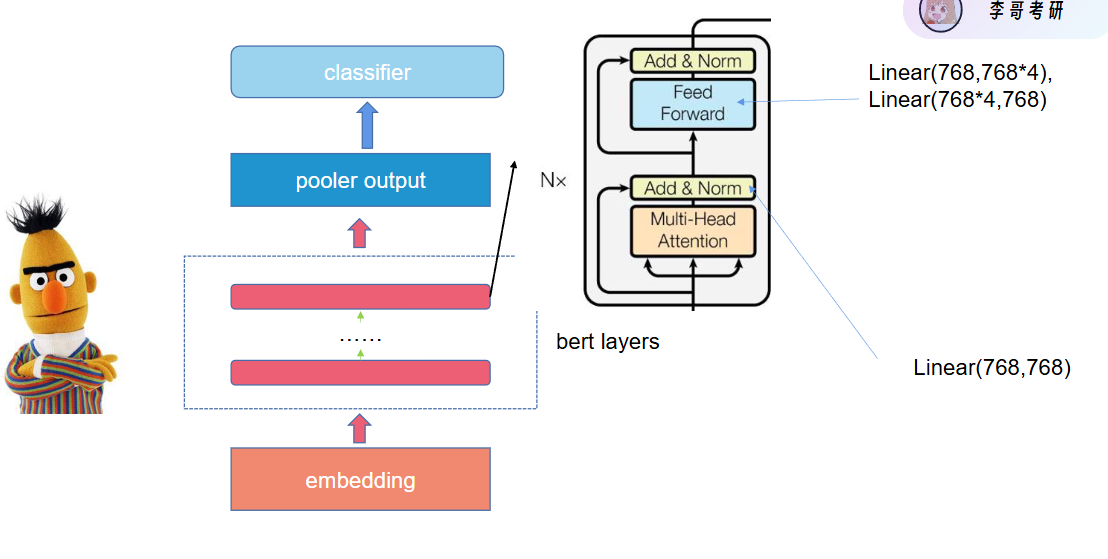
1. 嵌入层参数
BERT 有 30522 个不同的 token(字、词、符号),给每一个 token 分配一个 768 维的向量。 Segment 是用来区分第一句、第二句的。只有两种:0 = 第一句;1 = 第二句。所以只有 2 个向量,每个也是 768 维。而BERT 最多支持 512 个 token 长度。它给:
- 第 1 个位置 → 一个向量
- 第 2 个位置 → 一个向量
- …
- 第 512 个位置 → 一个向量
一共 512 个位置向量,每个 768 维。
Token Embedding + Segment Embedding + Position Embedding都是 d=768 维,所以:
- Token Embedding:
30522 × 768≈ 2344 万 - Segment Embedding:
2 × 768≈ 1536 - Position Embedding:
512 × 768≈ 39 万
嵌入层总参数量 ≈ 2383 万,这三本 “小字典”都是独立学习的,所以参数要加在一起。
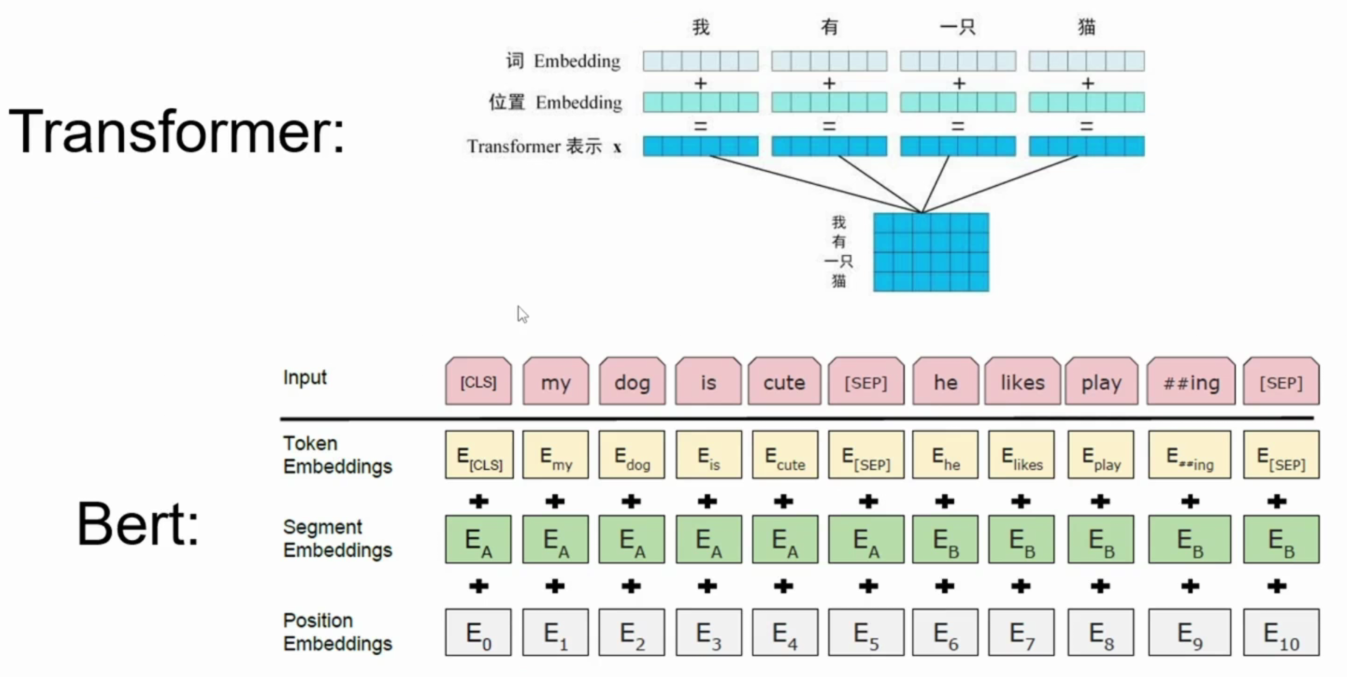
图示:Bert输入embedding
2. 一层 Transformer Encoder 有多少参数?
每层 = Multi-Head Attention + FFN
(1)Multi-Head Attention 内部:Q、K、V 三个线性层 + 输出投影:
- Q:
768×768 - K:
768×768 - V:
768×768 - Out:
768×768
共:4 × 768×768 = 4×589,824 = 2,359,296
(2)FFN 是两层全连接:
- 第一层:
768 → 3072→768×3072 - 第二层:
3072 → 768→3072×768
合计:768×3072 × 2 = 4,718,592
(3)LayerNorm 很小,忽略不计。
⇒ 一层 Encoder 总参数:2,359,296 + 4,718,592= 7,077,888
3. 有12 层 Encoder
12 × 7,077,888= 84,934,656
4. 最后 还有一个Pooler 层
768×768≈ 589,824
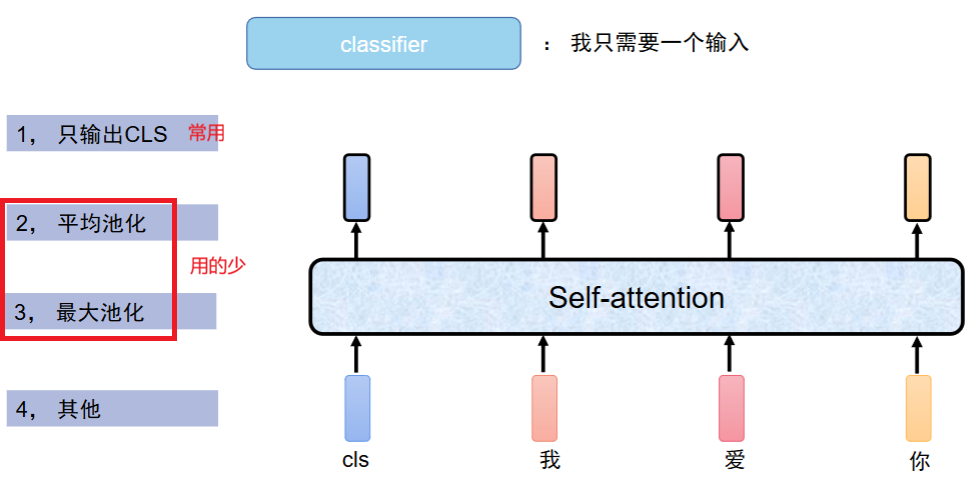
图示:Bert输出pooler
5. BERT-base 总参数量
- 嵌入:23,834,688
- 12 层:84,934,656
- Pooler:589,824
合计:≈ 109,359,168
七、BERT vs GPT 核心区别
BERT
- 结构:Transformer Encoder
- 模式:双向(同时看左右)
- 任务:MLM + NSP
- 擅长:理解类任务(分类、匹配、NER、QA)
- 定位:语言理解模型
GPT
- 结构:Transformer Decoder
- 模式:单向自回归(从左到右,只能看左边)
- 任务:Next Token Prediction(预测下一个词)
- 擅长:生成类任务(写作、对话、续写、代码)
- 定位:语言生成模型
一句话区分
- BERT:读懂上下文 → 做理解
- GPT:顺着往下写 → 做生成

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)