多模态大模型学习笔记(二十)—— 基于 Qwen的 LoRA 意图分类微调实战
基于 Qwen2.5-1.5B-Instruct 的 LoRA 意图分类微调实战
1. LoRA 微调原理
1.1 什么是 LoRA?
LoRA(Low-Rank Adaptation) 是一种参数高效微调技术,由微软研究院于 2021 年提出。其核心思想是:冻结预训练模型的权重,只训练少量注入的低秩矩阵参数。
数学原理
对于预训练模型的权重矩阵 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,LoRA 引入低秩分解:
W = W 0 + Δ W = W 0 + B A W = W_0 + \Delta W = W_0 + BA W=W0+ΔW=W0+BA
其中:
- B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r 和 A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k 是可训练的低秩矩阵
- r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k) 是 LoRA 的秩(通常 r=4, 8, 16)
- 前向传播时: h = W 0 x + B A x = W 0 x + Δ W x h = W_0x + BAx = W_0x + \Delta Wx h=W0x+BAx=W0x+ΔWx
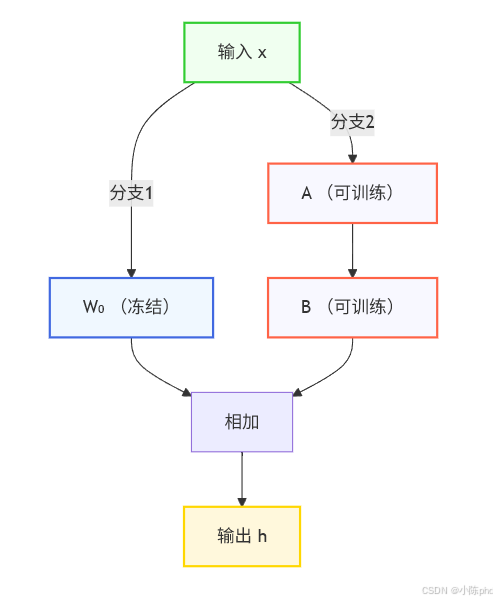
LoRA 架构示意图
颜色说明:
- 🟣 粉色:预训练权重(冻结,不更新)
- 🔵 蓝色:LoRA 低秩矩阵(可训练)
- 🟢 绿色:分类头(可训练,随机初始化)
为什么低秩有效?
根据 Aghajanyan et al. (2020) 的研究,预训练语言模型具有很低的"内在维度"(intrinsic dimension),即:
即使模型有数十亿参数,实际有效维度可能只有几百到几千。
因此,用低秩矩阵 B A BA BA 来近似权重更新 Δ W \Delta W ΔW 是合理且高效的。
1.2 LoRA 的优势
| 对比项 | 全参数微调 | LoRA 微调 |
|---|---|---|
| 可训练参数 | 100% | 0.01% - 1% |
| 显存需求 | 高(需存储梯度、优化器状态) | 低(仅 LoRA 参数) |
| 训练速度 | 慢 | 快 3-5 倍 |
| 存储空间 | 完整模型(数 GB) | LoRA 权重(数 MB) |
| 部署灵活性 | 差(每个任务一个完整模型) | 优(基础模型 + LoRA 适配器) |
| 灾难性遗忘 | 严重 | 轻微 |
1.3 适用场景
- 多任务学习:一个基础模型 + 多个 LoRA 适配器
- 消费级 GPU:显存有限(8GB-16GB)
- 快速原型:快速验证想法
- 隐私保护:少量参数可在本地训练
2. 项目概述
本文介绍如何使用 LoRA 技术对 Qwen2.5-1.5B-Instruct 模型进行微调,实现银行客服意图分类任务。通过本实战,你将掌握:
- LoRA 微调的基本原理和参数配置
- 使用 PEFT 库进行高效参数微调
- 完整的文本分类任务流程
- 微调效果评估与对比分析
2.1 任务背景
意图分类是智能客服系统的核心功能,需要将用户输入归类到预定义的意图类别。本实战使用银行客服场景,包含 5 类意图:
| 意图标签 | 说明 |
|---|---|
fraud_risk |
诈骗风险 |
refund |
退款 |
balance |
余额查询 |
card_lost |
卡片挂失 |
other |
其他 |
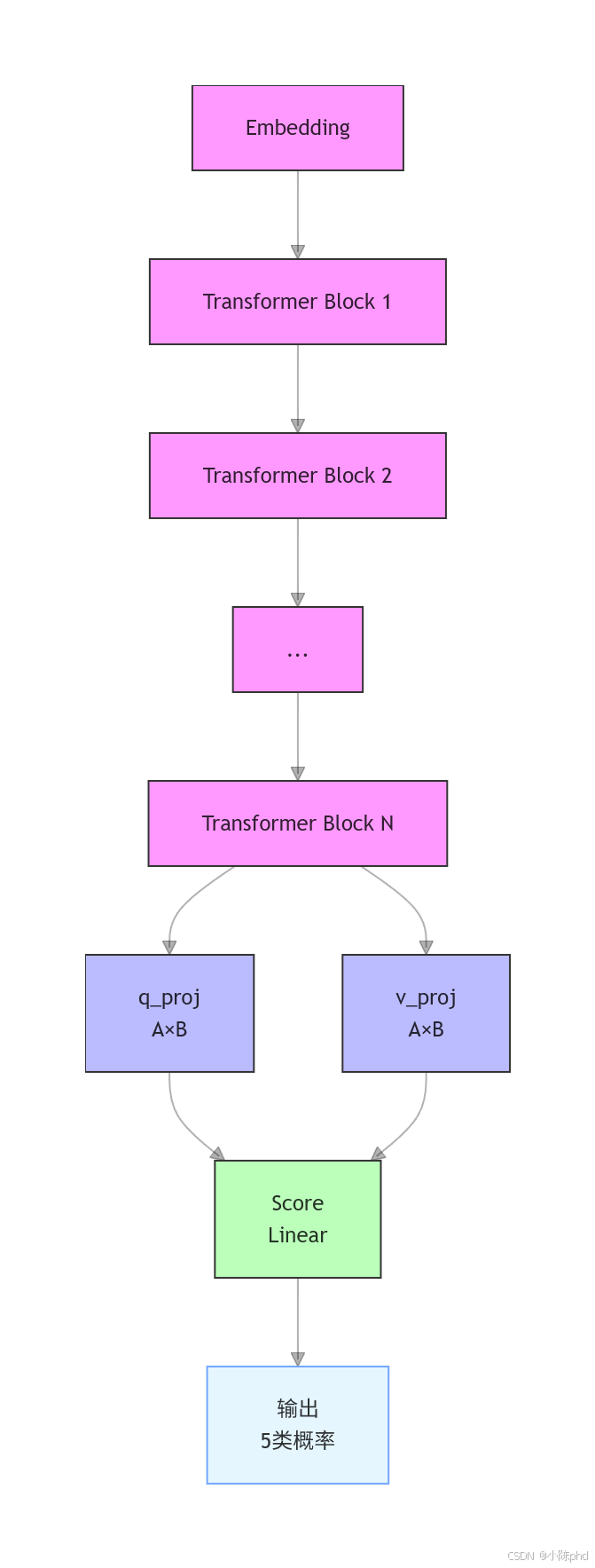
2.2 系统流程图

2.3 为什么选择 LoRA?
| 对比项 | 全参数微调 | LoRA 微调 |
|---|---|---|
| 可训练参数 | 15.4亿 (100%) | 109万 (0.071%) |
| 显存需求 | ~30GB | ~8GB |
| 训练时间 | 数小时 | 3分钟 |
| 存储空间 | 3GB+ | 4MB |
| 效果 | 优秀 | 接近全参数 |
3. 环境准备
3.1 依赖安装
pip install torch transformers datasets peft scikit-learn
3.2 模型与数据下载
from modelscope import snapshot_download
# 下载 Qwen2.5-1.5B-Instruct 模型
model_dir = snapshot_download(
'qwen/Qwen2.5-1.5B-Instruct',
cache_dir='/root/autodl-fs/class-2'
)
数据格式(JSONL):
{"text": "我的银行卡丢了怎么办", "label": "card_lost"}
{"text": "账户余额还有多少", "label": "balance"}
4. 核心代码实现
4.1 配置参数
CONFIG = {
"base_model_path": "/root/autodl-fs/class-2/qwen/Qwen2.5-1.5B-Instruct",
"train_data_path": "/root/autodl-fs/class-2/bank_intent_data/train.jsonl",
"test_data_path": "/root/autodl-fs/class-2/bank_intent_data/test.jsonl",
"lora_save_path": "/root/autodl-fs/class-2/bank_lora_model",
"labels": ["fraud_risk", "refund", "balance", "card_lost", "other"],
"max_seq_len": 64, # 最大序列长度
"batch_size": 1, # 批量大小
"epochs": 1, # 训练轮次
"lr": 2e-5 # 学习率
}
# 标签映射
label2id = {label: idx for idx, label in enumerate(CONFIG["labels"])}
id2label = {idx: label for idx, label in enumerate(CONFIG["labels"])}
4.2 数据预处理
def load_and_process_data():
# 加载数据集
train_ds = load_dataset("json", data_files=CONFIG["train_data_path"], split="train")
test_ds = load_dataset("json", data_files=CONFIG["test_data_path"], split="train")
# 数据清洗:过滤无效标签
def clean_data(examples):
valid_mask = [label in CONFIG["labels"] for label in examples["label"]]
return {
"text": [text for text, mask in zip(examples["text"], valid_mask) if mask],
"label": [label2id[label] for label, mask in zip(examples["label"], valid_mask) if mask]
}
train_ds = train_ds.map(clean_data, batched=True)
test_ds = test_ds.map(clean_data, batched=True)
# 初始化 Tokenizer
tokenizer = AutoTokenizer.from_pretrained(
CONFIG["base_model_path"],
trust_remote_code=True,
padding_side="right"
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 文本分词
def tokenize_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=CONFIG["max_seq_len"],
padding="max_length"
)
tokenized_train = train_ds.map(tokenize_function, batched=True)
tokenized_test = test_ds.map(tokenize_function, batched=True)
# 重命名标签列
tokenized_train = tokenized_train.rename_column("label", "labels")
tokenized_test = tokenized_test.rename_column("label", "labels")
return tokenized_train, tokenized_test, tokenizer
4.3 LoRA 配置与模型初始化
LoRA 参数结构图
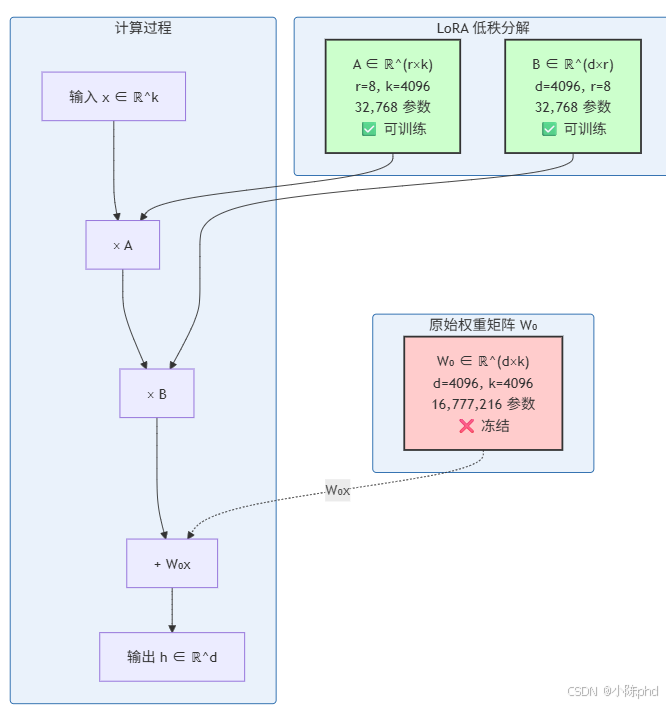
参数对比:
- 原始权重:16,777,216 参数(冻结)
- LoRA 参数:65,536 参数(可训练)
- 压缩比:256:1
from peft import LoraConfig, get_peft_model
# LoRA 配置
lora_config = LoraConfig(
r=8, # LoRA 秩:低秩矩阵维度
lora_alpha=16, # 缩放因子:通常设为 2*r
target_modules=["q_proj", "v_proj"], # 目标注意力层
lora_dropout=0.05, # Dropout 率
bias="none", # 不训练偏置
task_type="SEQ_CLS" # 序列分类任务
)
# 加载基础模型
model = AutoModelForSequenceClassification.from_pretrained(
CONFIG["base_model_path"],
trust_remote_code=True,
num_labels=len(CONFIG["labels"]),
id2label=id2label,
label2id=label2id,
device_map="auto",
dtype=torch.float32
)
# 初始化分类头权重
if hasattr(model, "score"):
torch.nn.init.normal_(model.score.weight, mean=0.0, std=0.02)
# 注入 LoRA
lora_model = get_peft_model(model, lora_config)
lora_model.print_trainable_parameters()
输出:
trainable params: 1,097,216 || all params: 1,544,819,200 || trainable%: 0.0710
4.4 训练配置
from transformers import TrainingArguments
from torch.optim import AdamW
training_args = TrainingArguments(
output_dir=f"{CONFIG['lora_save_path']}/lora_training",
per_device_train_batch_size=CONFIG["batch_size"],
per_device_eval_batch_size=CONFIG["batch_size"],
num_train_epochs=CONFIG["epochs"],
learning_rate=CONFIG["lr"],
logging_steps=50,
eval_strategy="epoch",
save_strategy="epoch",
save_total_limit=1,
load_best_model_at_end=True,
fp16=False,
report_to="none"
)
# 优化器
optimizer = AdamW(
lora_model.parameters(),
lr=CONFIG["lr"],
weight_decay=0.01
)
# Trainer
trainer = Trainer(
model=lora_model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
compute_metrics=compute_metrics,
optimizers=(optimizer, None)
)
# 开始训练
trainer.train()
4.5 评估指标
from sklearn.metrics import f1_score
import numpy as np
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
# 计算 Macro-F1
macro_f1 = f1_score(
y_true=labels,
y_pred=predictions,
average="macro",
labels=list(label2id.values())
)
return {"macro_f1": round(macro_f1, 4)}
5. 完整训练流程
5.1 训练流程详解

5.2 训练脚本
import os
import torch
from datasets import load_dataset
from transformers import (
AutoTokenizer, AutoModelForSequenceClassification,
Trainer, TrainingArguments
)
from peft import LoraConfig, get_peft_model, PeftModel
from torch.optim import AdamW
# 配置
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ["TOKENIZERS_PARALLELISM"] = "false"
def main():
# 1. 数据预处理
tokenized_train, tokenized_test, tokenizer = load_and_process_data()
# 2. 基础模型评估(Baseline)
base_model = AutoModelForSequenceClassification.from_pretrained(
CONFIG["base_model_path"],
trust_remote_code=True,
num_labels=len(CONFIG["labels"]),
id2label=id2label,
label2id=label2id,
device_map="auto",
dtype=torch.float32
)
base_trainer = Trainer(
model=base_model,
args=TrainingArguments(
output_dir=f"{CONFIG['lora_save_path']}/base_eval",
per_device_eval_batch_size=CONFIG["batch_size"],
do_train=False,
do_eval=True
),
eval_dataset=tokenized_test,
compute_metrics=compute_metrics
)
base_result = base_trainer.evaluate()
base_f1 = base_result["eval_macro_f1"]
# 释放显存
del base_model, base_trainer
torch.cuda.empty_cache()
# 3. LoRA 微调
lora_model = AutoModelForSequenceClassification.from_pretrained(
CONFIG["base_model_path"],
trust_remote_code=True,
num_labels=len(CONFIG["labels"]),
id2label=id2label,
label2id=label2id,
device_map="auto",
dtype=torch.float32
)
# 注入 LoRA
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="SEQ_CLS"
)
lora_model = get_peft_model(lora_model, lora_config)
# 训练
trainer = Trainer(
model=lora_model,
args=TrainingArguments(
output_dir=f"{CONFIG['lora_save_path']}/lora_training",
per_device_train_batch_size=CONFIG["batch_size"],
num_train_epochs=CONFIG["epochs"],
learning_rate=CONFIG["lr"],
logging_steps=50,
eval_strategy="epoch",
save_strategy="epoch",
save_total_limit=1,
load_best_model_at_end=True
),
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
compute_metrics=compute_metrics
)
trainer.train()
# 保存 LoRA 权重
lora_model.save_pretrained(CONFIG["lora_save_path"])
# 4. 微调后评估
final_model = AutoModelForSequenceClassification.from_pretrained(
CONFIG["base_model_path"],
trust_remote_code=True,
num_labels=len(CONFIG["labels"]),
device_map="auto"
)
final_model = PeftModel.from_pretrained(final_model, CONFIG["lora_save_path"])
final_model.merge_and_unload()
final_trainer = Trainer(
model=final_model,
args=TrainingArguments(
output_dir=f"{CONFIG['lora_save_path']}/final_eval",
per_device_eval_batch_size=CONFIG["batch_size"],
do_train=False,
do_eval=True
),
eval_dataset=tokenized_test,
compute_metrics=compute_metrics
)
final_result = final_trainer.evaluate()
final_f1 = final_result["eval_macro_f1"]
# 5. 结果对比
print("\n=== LoRA 微调前后效果对比 ===")
print(f"基础模型(无LoRA)Macro-F1: {base_f1}")
print(f"LoRA微调后模型Macro-F1: {final_f1}")
print(f"Macro-F1提升幅度: {round(final_f1 - base_f1, 4)}")
if __name__ == "__main__":
main()
6. 训练结果
6.1 训练效果可视化
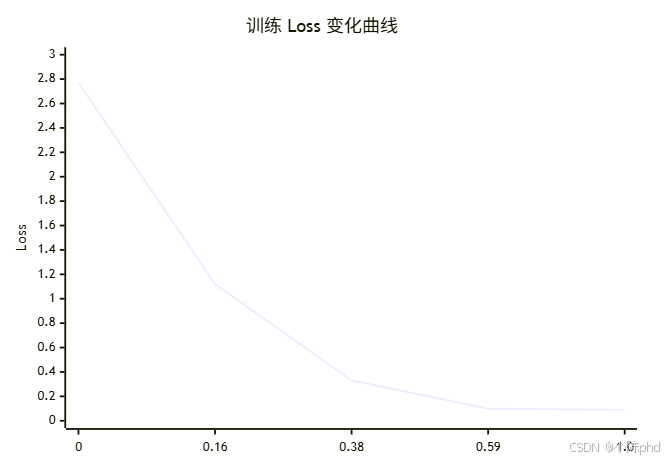
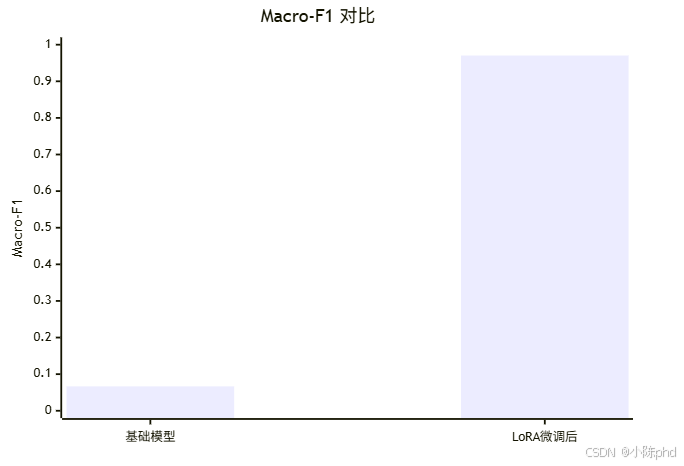
6.2 训练日志
数据预处理完成:训练集样本数=1600,测试集样本数=200
=== 基础模型(无LoRA)评估 ===
基础模型(无LoRA)Macro-F1: 0.0667
=== LoRA微调训练 ===
LoRA参数占比:
trainable params: 1,097,216 || all params: 1,544,819,200 || trainable%: 0.0710
{'loss': 2.7657, 'grad_norm': 169.17, 'learning_rate': 1.94e-05, 'epoch': 0.03}
{'loss': 1.1208, 'grad_norm': 84.52, 'learning_rate': 1.69e-05, 'epoch': 0.16}
{'loss': 0.3260, 'grad_norm': 0.35, 'learning_rate': 1.25e-05, 'epoch': 0.38}
{'loss': 0.0950, 'grad_norm': 163.27, 'learning_rate': 8.14e-06, 'epoch': 0.59}
{'loss': 0.0907, 'grad_norm': 0.02, 'learning_rate': 1.25e-08, 'epoch': 1.0}
{'eval_loss': 0.0799, 'eval_macro_f1': 0.9703, 'epoch': 1.0}
LoRA权重已保存至:/root/autodl-fs/class-2/bank_lora_model
=== LoRA微调后模型评估 ===
LoRA微调后模型Macro-F1: 0.9703
=== LoRA微调前后效果对比 ===
基础模型(无LoRA)Macro-F1: 0.0667
LoRA微调后模型Macro-F1: 0.9703
Macro-F1提升幅度: 0.9036
6.3 效果对比
| 模型 | Macro-F1 | 提升 |
|---|---|---|
| 基础模型(无LoRA) | 0.0667 | - |
| LoRA 微调后 | 0.9703 | +0.9036 |
6.4 关键指标
| 指标 | 数值 |
|---|---|
| 训练样本 | 1600 |
| 测试样本 | 200 |
| 训练轮次 | 1 |
| 训练时间 | 183 秒(约 3 分钟) |
| 可训练参数 | 1,097,216(0.071%) |
| 总参数 | 1,544,819,200 |
| 最终 Loss | 0.09 |
| 评估 Loss | 0.08 |
7. LoRA 参数详解
7.1 核心参数
| 参数 | 说明 | 推荐值 |
|---|---|---|
r |
LoRA 秩,低秩矩阵维度 | 4-16 |
lora_alpha |
缩放因子,控制更新幅度 | 2*r |
target_modules |
目标层,指定注入 LoRA 的模块 | [“q_proj”, “v_proj”] |
lora_dropout |
Dropout 率,防止过拟合 | 0.05-0.1 |
bias |
偏置训练策略 | “none” |
task_type |
任务类型 | “SEQ_CLS” |
7.2 参数选择建议
r(秩)的选择:
- 小模型(< 3B):r=8-16
- 大模型(> 7B):r=4-8
- 简单任务:r=4
- 复杂任务:r=16
target_modules 的选择:
- Transformer 模型:[“q_proj”, “v_proj”](推荐)
- 需要更强效果:[“q_proj”, “k_proj”, “v_proj”, “o_proj”]
- 显存充足:所有线性层
8. 常见问题
8.1 Qwen Tokenizer 警告
问题:Token indices sequence length is longer than the specified maximum sequence length
解决:手动设置 pad_token:
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
8.2 分类头未初始化
问题:Some weights were not initialized from the model checkpoint
解决:手动初始化分类头:
if hasattr(model, "score"):
torch.nn.init.normal_(model.score.weight, mean=0.0, std=0.02)
8.3 显存不足
解决:
- 减小
batch_size到 1 - 减小
max_seq_len到 32-64 - 使用
torch.float16或bfloat16 - 使用
load_in_4bit=True
9. 总结
本文完整介绍了使用 LoRA 微调 Qwen2.5-1.5B-Instruct 实现意图分类任务的流程:
- 数据准备:JSONL 格式,文本+标签
- 模型加载:使用 Transformers 加载预训练模型
- LoRA 配置:仅 0.071% 参数可训练
- 训练流程:3 分钟完成 1600 条样本训练
- 效果评估:Macro-F1 从 0.07 提升到 0.97
LoRA 技术的优势在于:用极少的可训练参数,达到接近全参数微调的效果,大幅降低训练成本和部署门槛。
10. 参考资源

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)