Datawhale Obsidian智能体 202603作业1
1. 核心方法论 (Key Frameworks)
|
核心理论模型全称定义与核心价值来源 |
|||
|
MVW |
Minimum Viable Workflow |
最小可行工作流。拒绝过度设计,先构建一个包含“输入-处理-反馈-输出”的最简闭环,验证 AI 协作的可行性。 |
|
|
I-S-G-I-E |
Workflow Stages |
知识处理五环。将复杂的知识任务拆解为标准步骤:输入(Input)、结构(Structure)、生成(Generate)、迭代(Iterate)、表达(Express)。 |
|
|
S.C.O.R.E |
Structure for Prompts |
提示词结构标准。通过角色(S)、背景(C)、目标(O)、要求(R)、评估(E)五要素,将模糊意图转化为机器可执行的“软协议”。 |
|
|
MVR |
Minimum Viable Repository |
最小可行知识库。基于 Git 版本控制和元数据规范构建的工程化知识底座,确保知识资产“机器可读”且“历史可溯”。 |
|
|
PEAR |
Agent Loop |
智能体运行闭环。将智能体行为解构为四个系统阶段:感知(Perceive) → 评估(Evaluate) → 行动(Act) → 反思(Reflect)。 |
|
|
MVG |
Minimum Viable Graph |
最小可行图谱。在本地构建包含核心实体与关系的最小知识图谱 (GraphRAG),赋予智能体跨文档推理与全局结构理解能力。 |
|
|
Agentic Workflow |
Agentic Workflow |
智能体式工作流。从被动的“问答模式”升级为“主动行动模式”。系统基于目标(Goals)、状态(State)与事件(Events)持续运行,而非单次触发。 |
|
|
Agent Runtime |
Agent Runtime |
智能体运行环境。承载智能体的系统基础设施,提供状态管理、记忆存储、行动接口与反馈通道,决定了智能体能力的上限。 |
|
|
MVA |
Minimum Viable Agent |
最小可行智能体。在本地运行环境中构建的具备完整 PEAR 闭环、且“推理外包、状态内生”的最小工程实体。 |
|
|
DIKWA |
Data-Info-Know-Wisdom-Action |
价值链重构。在传统的DIKW知识金字塔顶端增加Action (行动),标志着从“给建议”到“做任务”的范式跃迁。 |
2. 安装:
一、系统底层环境
1. 安装 Node.js(MCP 依赖)
- 打开 Node.js 官网,下载 LTS 长期支持版(64 位 .msi)。
- 双击安装,务必勾选 Add to PATH(自动配置环境变量)。
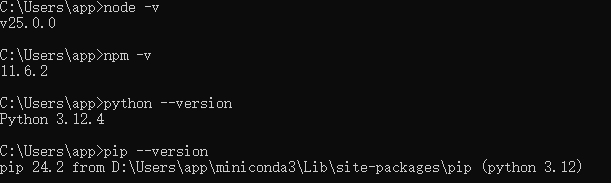
- 安装完成后,按
Win+R→ 输入cmd→ 打开命令提示符,执行:
出现版本号(如 v20.x.x)即成功。node -v npm -v
输出:
2. 创建 Python 虚拟环境(隔离依赖)
打开 cmd,进入你的项目目录
# 第一步:切换到 D 盘
D:
# 第二步:进入目标目录
cd D:\my projects\Obsidian
创建虚拟环境:
python -m venv mcp-env
激活环境(命令行出现 (mcp-env) 即成功):
mcp-env\Scripts\activate
安装 MCP SDK:
# 使用阿里云镜像源安装 mcp[cli](最快、最稳)
pip install "mcp[cli]" -i https://mirrors.aliyun.com/pypi/simple/4. 获取硅基流动 API Key(模型调用)
- 访问 硅基流动官网
 https://siliconflow.cn/ 注册账号。
https://siliconflow.cn/ 注册账号。 - 进入控制台 → API 密钥 → 新建密钥,复制
sk-xxxx密钥。
配置 Obsidian(核心知识库)
1. 安装 Obsidian
- 打开 Obsidian 官网,下载 Windows 版安装。
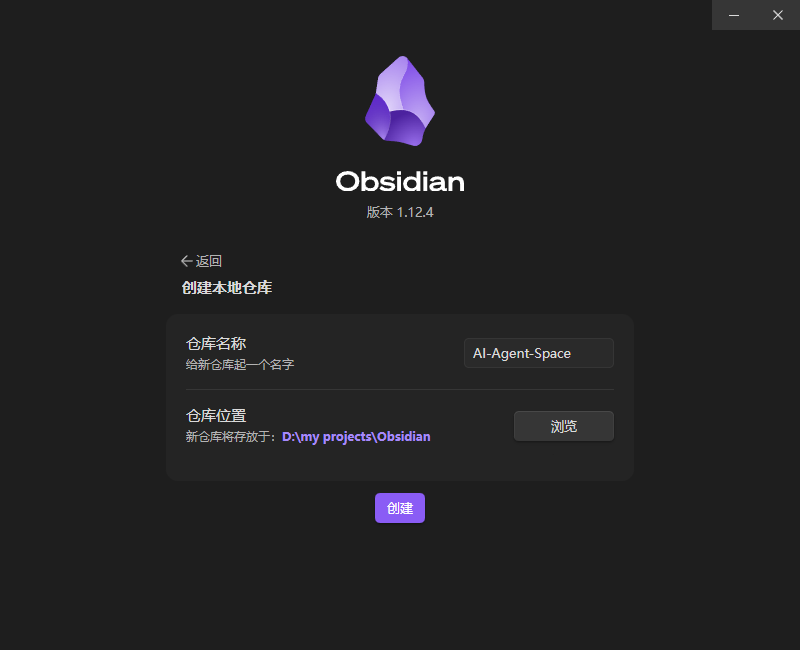
- 打开 Obsidian → Create new vault → 命名为
AI-Agent-Space→ 保存到D:\AI-Agent-Space(无空格、无中文)。
2. 基础设置
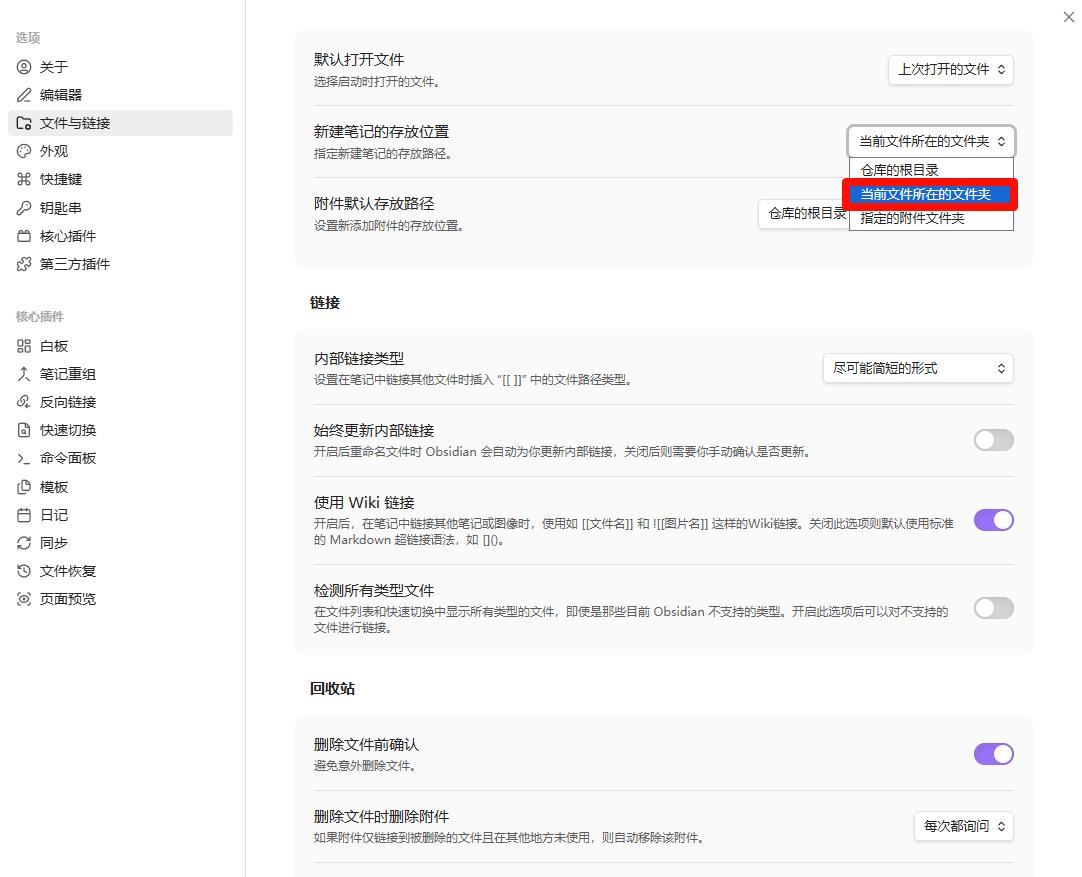
- 进入 Settings → Files & Links:
- Default location for new attachments:改为 In subfolder under current folder。
- 进入 Settings → Community plugins:
- 关闭 Restricted mode(允许第三方插件)。
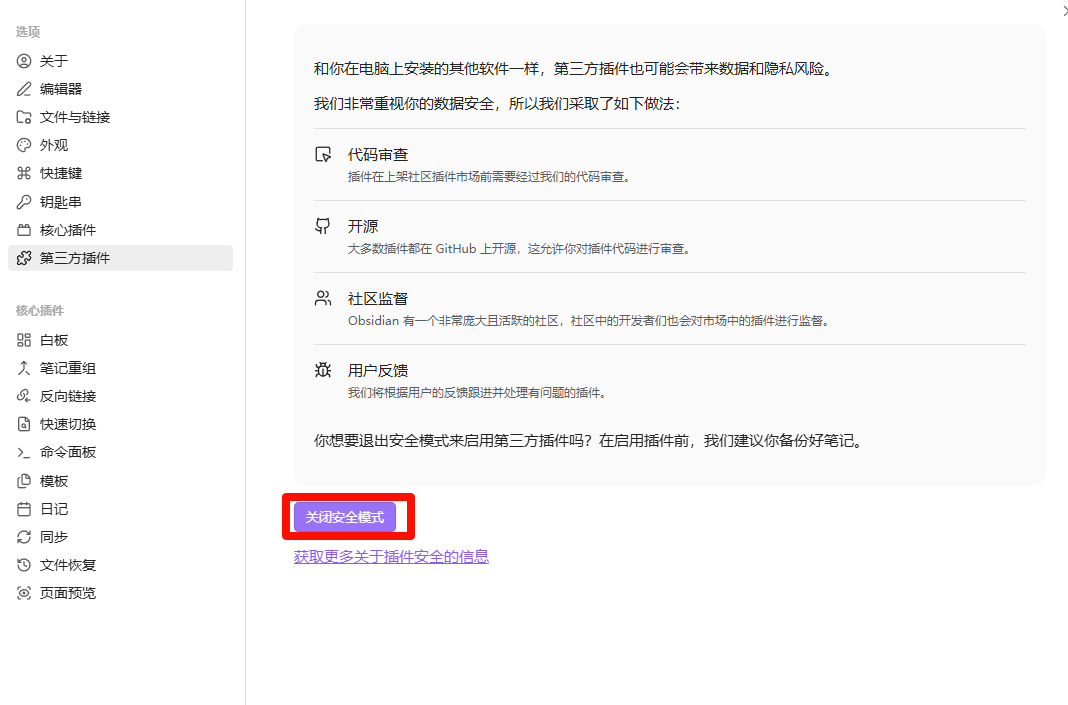
- 关闭 Restricted mode(允许第三方插件)。
3. 安装 Text Generator 插件
- 社区插件市场搜索 Text Generator → Install → Enable。
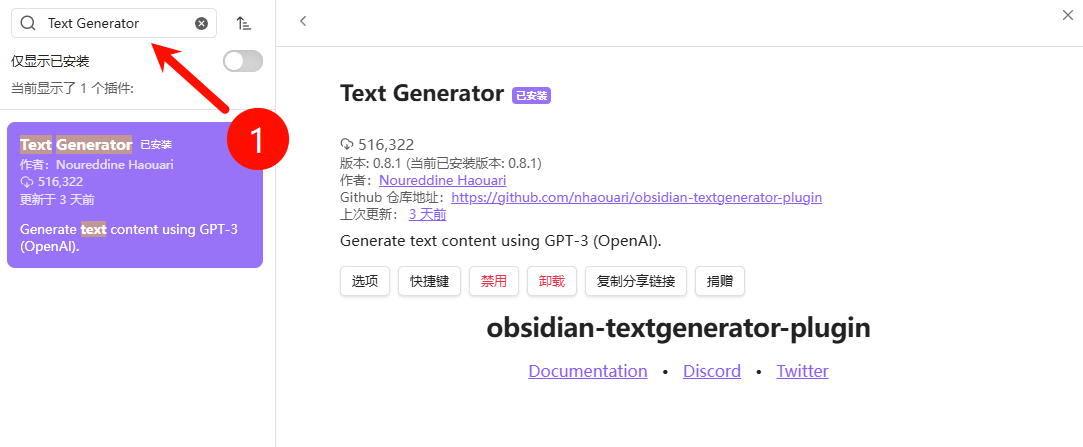
- 配置:
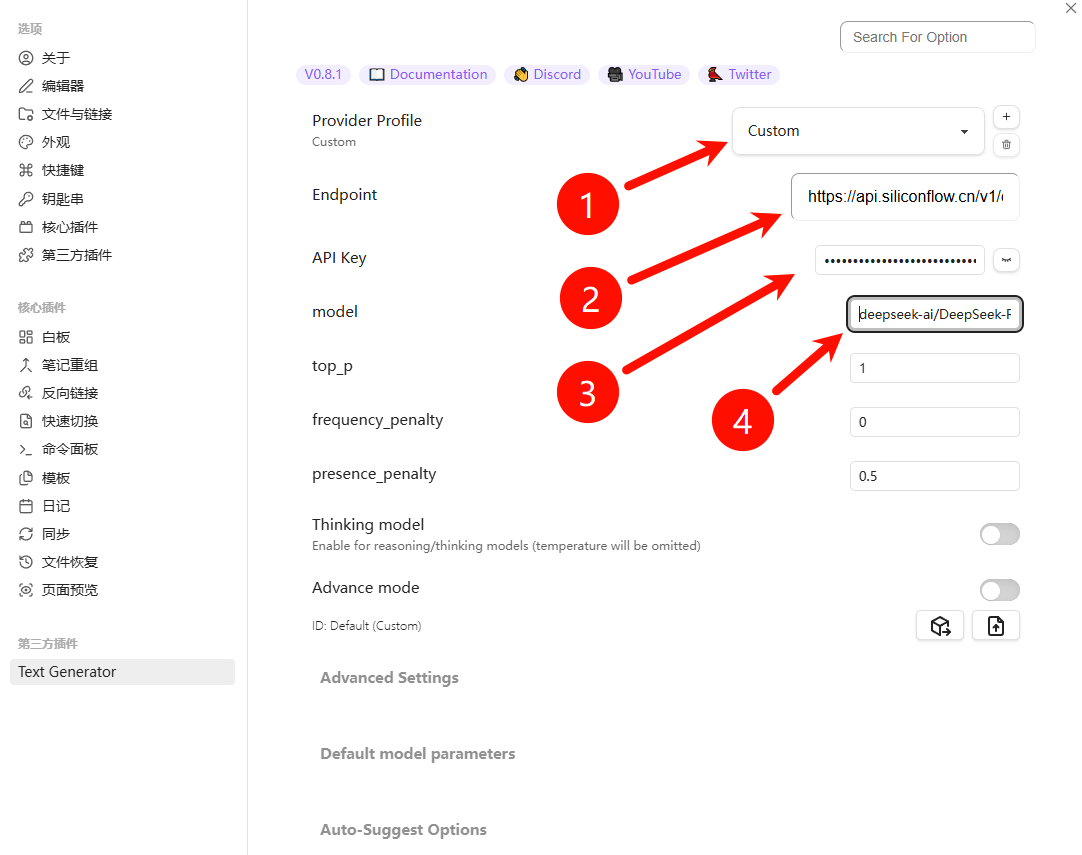
- LLM Provider:Custom
- Endpoint:
https://api.siliconflow.cn/v1/chat/completions - API Key:粘贴你的
sk-xxxx - Model:
deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
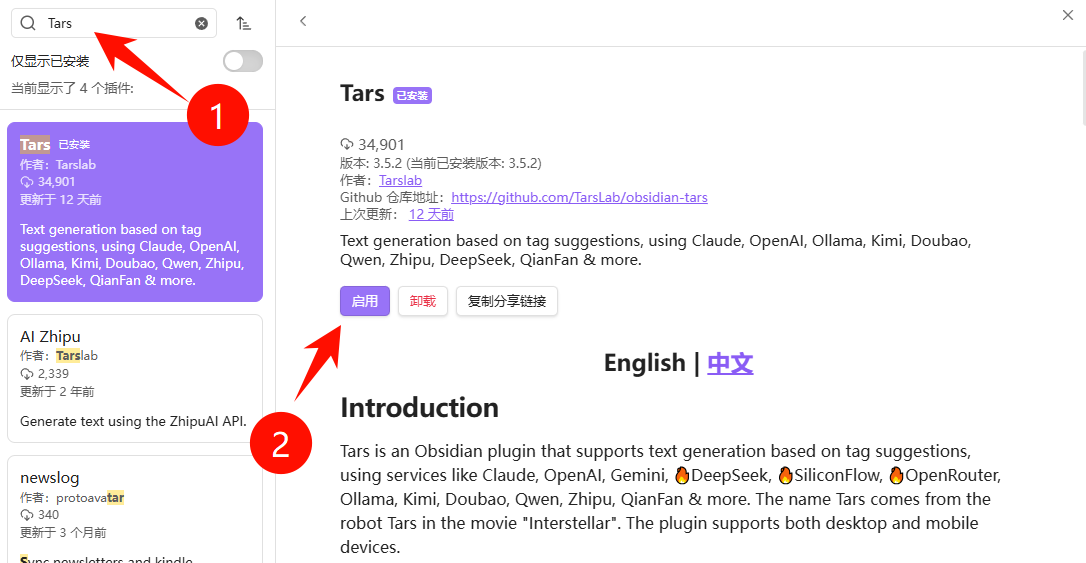
4. 安装 Tars 插件
- 搜索 Tars → Install → Enable。
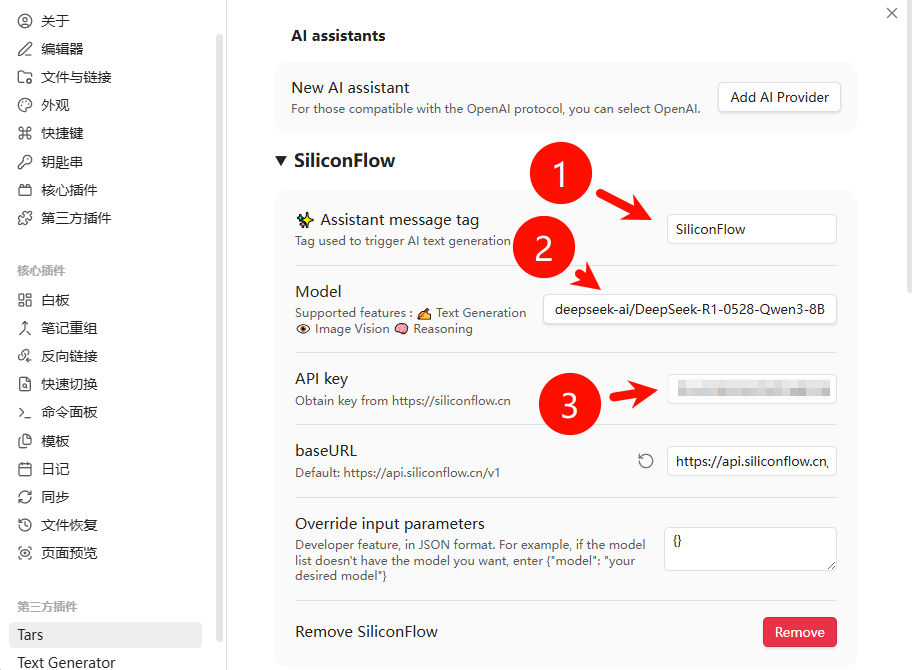
- 配置:
- Provider:SiliconFlow
- API Key:粘贴
sk-xxxx - Model Name:
deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
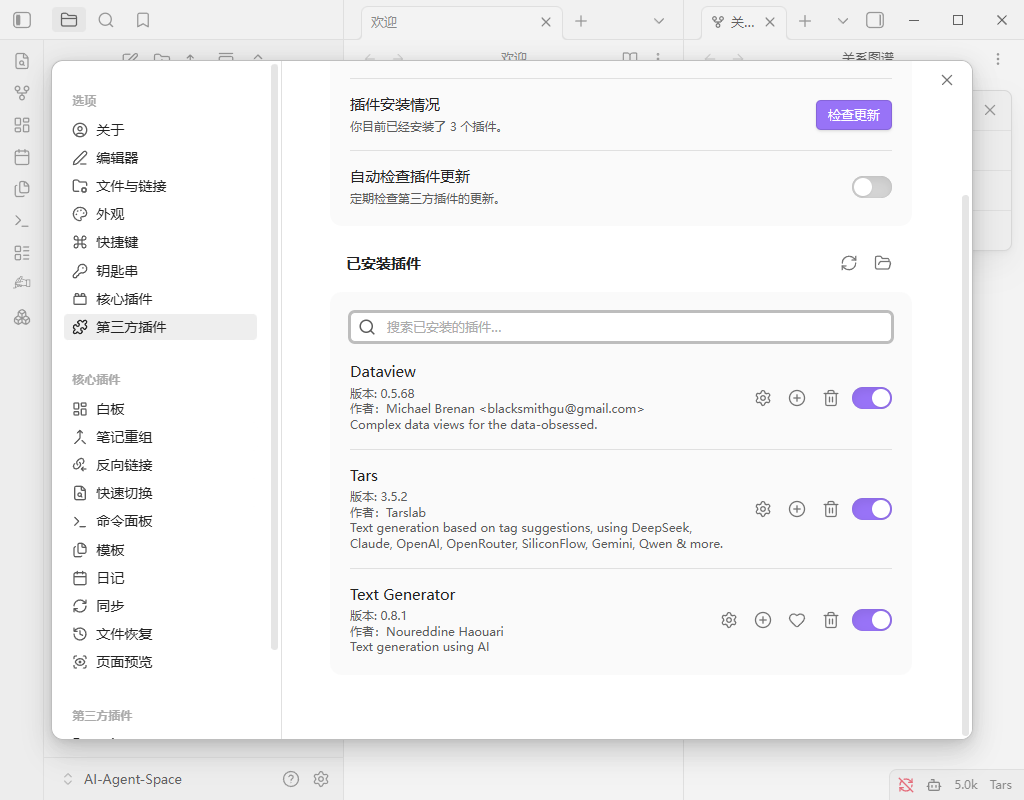
安装Dataview, 显示三个插件如下:
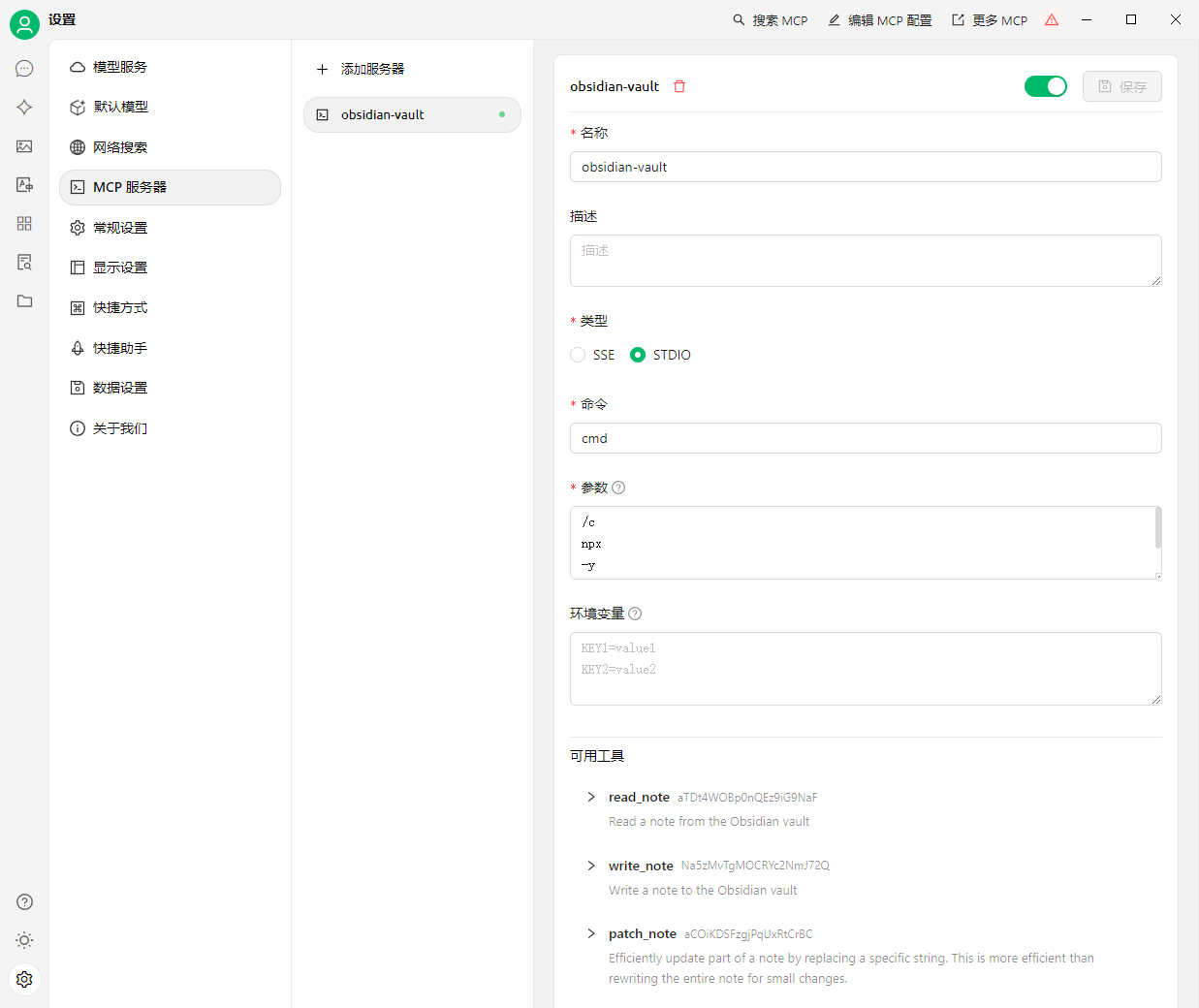
三、Cherry Studio 连接 Obsidian MCP(核心步骤)
1. 打开 Cherry Studio 设置
- 打开 Cherry Studio → 左下角 设置(⚙️) → 左侧 MCP 服务器。
- 点击 添加服务器 → 选择 Import from JSON(代码模式)。
2. 粘贴 MCP 配置(替换为你的 Obsidian 绝对路径)
json
{
"mcpServers": {
"Obsidian-Vault": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-obsidian",
"D:\\AI-Agent-Space"
]
}
}
}
- 注意:Windows 路径用
\\,必须是绝对路径、无空格。
在编辑MCP配置这里填入:
{
"mcpServers": {
"obsidian-vault": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@mauricio.wolff/mcp-obsidian@latest",
"'D:\\my projects\\Obsidian\\AI-Agent-Space'"
]
}
}
}
注意:老师用 npx 直接作为命令,是因为他的课件基于 Linux/Mac 系统;而我们用 cmd 包装,是为了适配你的 Windows 10 系统—— 两者本质都是启动 MCP 服务,只是系统底层的命令解析规则不同。
3. 保存并验证
点击 保存,等待指示灯变 绿色(连接成功)。
四、最终验证(确保全部成功)
- 在 Cherry Studio 聊天框输入:
plaintext
读取我的 Obsidian 笔记 AI-Agent-Space - 能正常读取笔记内容 → 环境搭建完成。
3. 作业:
✅ 步骤 1:在 Obsidian 新建笔记并粘贴原始文本
- 打开 Obsidian,在你的仓库(
D:\my projects\Obsidian\AI-Agent-Space)里,右键「新建笔记」,命名为02-SCORE-Practice。 -
运行你的第一次对话
新建笔记:点击左侧栏的 New note,命名为 00-Hello-World。
输入指令:在笔记中输入以下内容(这是给 AI 的指令):
你好,AI。请你扮演一位资深的 Python 工程师。
请用 3 句话向我解释什么是“Hello World”,并输出一段 Python 的 Hello World 代码。
触发生成:
- 将光标停在文字末尾。
- 按下快捷键(默认通常是
Cmd+J或Ctrl+J,具体看插件设置)。 - 观察屏幕,如果一段文字自动流淌出来,环境觉醒成功。

运行你的第一次对话
步骤 1:呼出控制面板
在 Obsidian 的右侧边栏找到 Tars 的图标并点击,或者使用快捷键 Ctrl+P唤出命令面板,输入 Tars: 打开对话窗口,选择 Tars 有关的指令。
步骤 2:注入上下文并测试
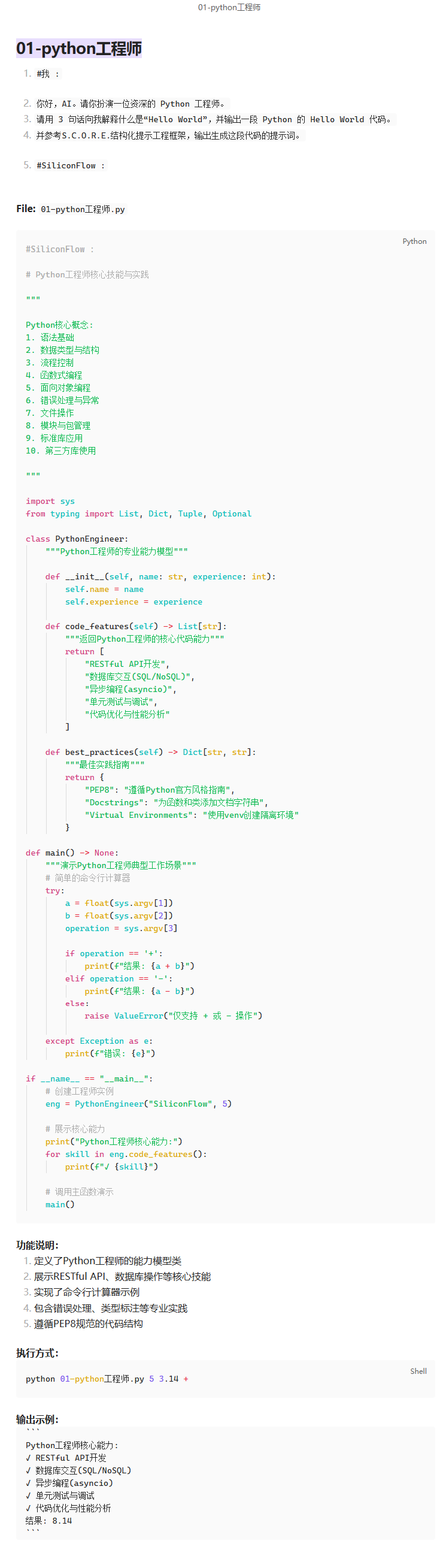
01-python工程师
#我 :你好,AI。请你扮演一位资深的 Python 工程师。请用 3 句话向我解释什么是“Hello World”,并输出一段 Python 的 Hello World 代码。并参考S.C.O.R.E.结构化提示工程框架,输出生成这段代码的提示词。#SiliconFlow :
💡 提示工程技巧: Tars 的核心工程优势在于动态上下文引用。除了自动读取当前笔记,你还可以在提问时使用特定的引用符(如 @),将知识库中任意的其他 Markdown 文件挂载到单次请求中。这是未来构建复杂“本地知识问答”底座的基础动作。
- 打开这篇笔记,把下面这段「混乱的原始文本」完整粘贴进去:
plaintext
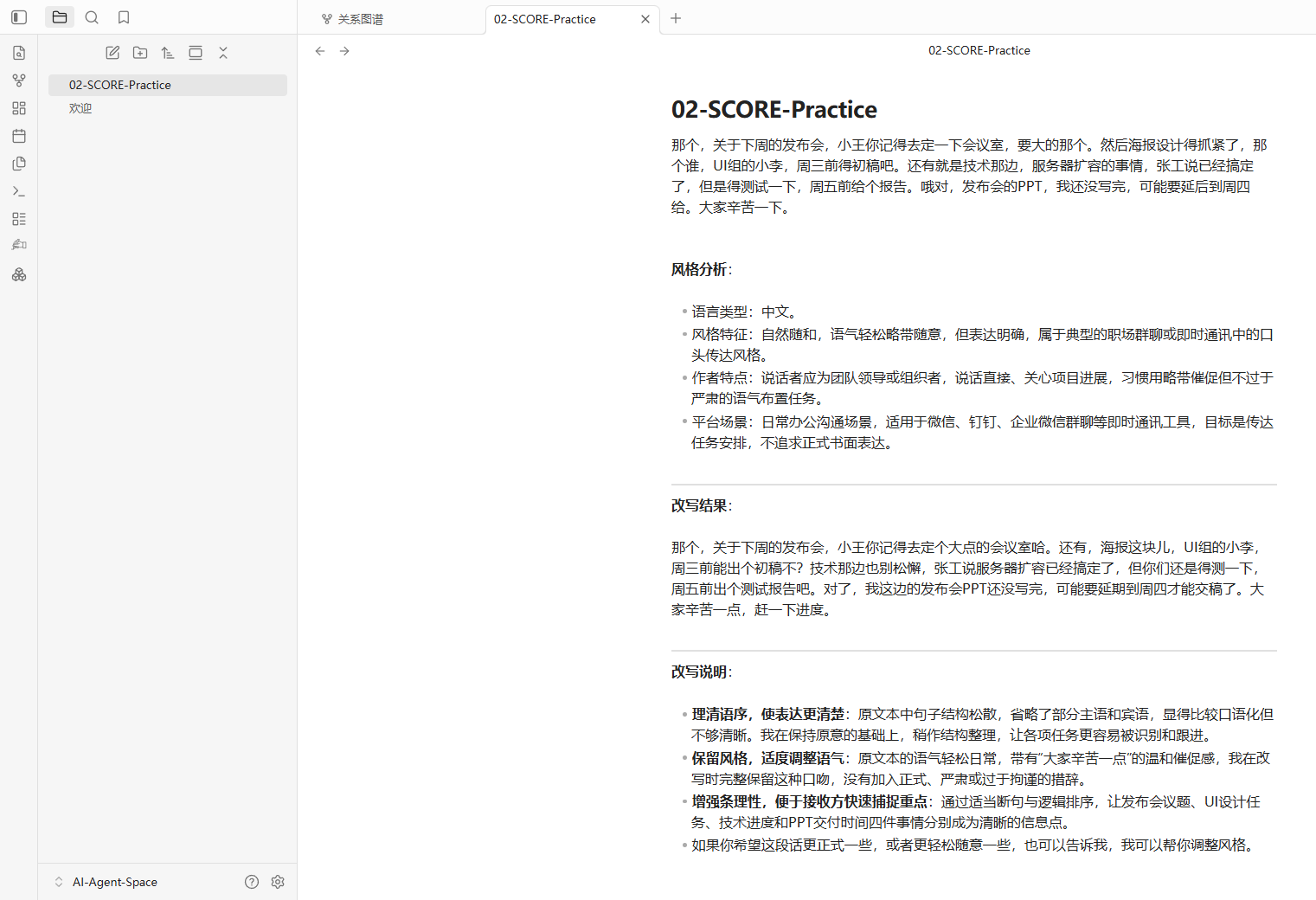
那个,关于下周的发布会,小王你记得去定一下会议室,要大的那个。然后海报设计得抓紧了,那个谁,UI组的小李,周三前得初稿吧。还有就是技术那边,服务器扩容的事情,张工说已经搞定了,但是得测试一下,周五前给个报告。哦对,发布会的PPT,我还没写完,可能要延后到周四给。大家辛苦一下。
把光标移到最后,然后ctrl+j 即可调用 Text Generator
text generator
1. 在任意一行文本后按 `ctrl + j`,即可在后面自动生成文本。
2. - 如果左键选中文本,则该文本即为发送给 gpt 的上下文
- 如果打字光标前有文本,则该行文本即为发送给 gpt 的上下文
- 如果打字光标前无文本,则整个文档都将发送给 gpt 作为上下文
输入简单的提示词
在 Text Generator 中输入以下指令并运行:
帮我整理一下这个会议记录。

工程化的白盒解析
- S—Scrum Master:激活了模型关于“敏捷管理”、“Action Item”的专业知识权重,它立刻知道“任务”比“闲聊”更重要。
- C—Context:明确了输入数据的边界(【开始】…【结束】),防止 AI 把你的指令也当成会议记录去处理。
- O—Objective:通过使用“提取”、“识别”等原子化动词,并将大任务拆解为 4 个具体步骤(内容、负责人、DDL、状态),我们强制模型触发了思维链。这让模型在生成结果前,必须先在潜空间内完成逻辑推理,建立了从“模糊录音”到“清晰条目”的直接映射路径。
- R—Markdown表格:这是最关键的 “格式契约”。通过规定 Markdown 格式,我们保证了输出的数据可以直接被 Notion、Obsidian 或其他软件读取。
- E —Check:修正了可能的逻辑漏洞(比如容易忽略张工已经做完的事实)。
03-数据清洗
“噢,我叫韩梅梅,不过我现在的同事都叫我 Meimei。我出生在 1996 年,现在正好 28 岁。我在上海已经工作 5 年了,目前在一家挺牛的广告公司担任资深文案策划。要说我的专长,那肯定是对品牌故事的深度挖掘,还有就是能写特别带感的短视频脚本。哦,我以前在复旦大学念的新闻学,拿了文学学士学位。工作之余,我自己还捣鼓了一个播客节目,叫《字里行间》,主要聊文学和城市文化,现在已经在各平台更了 50 多期了,粉丝反馈还不错。”
**S (角色)**:
你是一位资深的数据清洗工程师。你的核心能力是将混乱的自然语言提取并重构为生产级的 JSON 数据。
**C (背景)**:
处理一份非正式的面试自我介绍录音转录文本。
【原始文本开始】
{{粘贴上面的韩梅梅文本}}
【原始文本结束】
**O (目标)**:
提取文本中的核心实体,生成一个单层的、无冗余的 JSON 对象。
**R (要求)**:
1. **语义契约 (Schema Contract)** (必须严格遵循以下字段定义):
- "full_name": String, 优先提取全名。
- "age": Integer, 仅保留数字。 // 注释:强制类型转换,防止字符串混入
- "occupation": String, 当前职位。
- "years_of_experience": Integer.
- "skills": String Array (数组).
- "education": Nested Object (嵌套对象), 包含 "university" 和 "degree"。
- "side_projects": String Array.
2. **格式规范**:
- **严禁** 使用 Markdown 代码块。 // 注释:确保输出纯净文本
- **严禁** 输出任何解释性文字。
- 输出必须以 `{` 开头,以 `}` 结尾。
- 使用压缩的单行 JSON 格式。
**E (评估)**:
在输出前自检:生成的 JSON 能否通过 JSONLint 校验?字段类型是否与 Schema 一致?
输出:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)