用 RAG 重构需求管理:一个可落地的 AI 协作系统实践:技术分享系列(二)
·
02|三次关键踩坑复盘:CORS、枚举转换、LLM 挂起
这篇是“踩坑实录”。每个坑都按“现象 → 根因 → 修复 → 复用清单”给出,适合做团队内部分享。
排查总流程
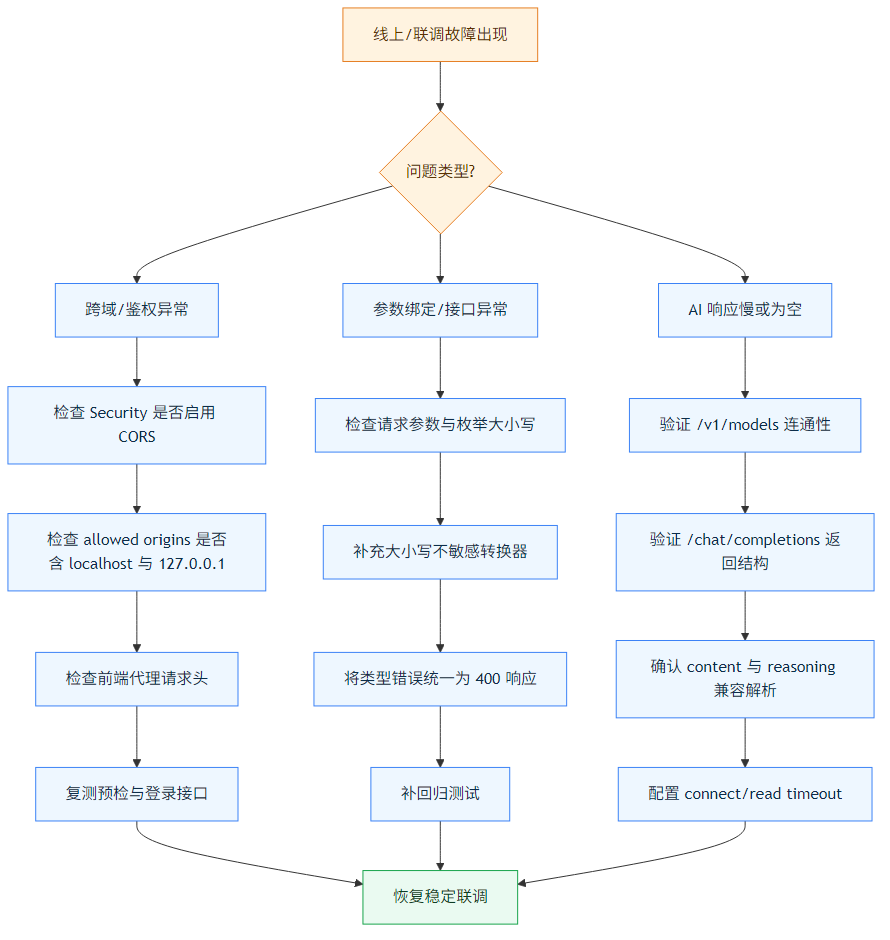
坑一:前端登录一直 403(Invalid CORS request)
现象
- 前端调用登录接口,后端返回 403
- 浏览器提示
Invalid CORS request - 同样接口在 Postman 可能又是通的
根因
这类问题通常不是单点错误,而是多个条件叠加:
- Spring Security 过滤链没真正启用 CORS
- 允许 Origin 配置不完整(
localhost与127.0.0.1被当成不同源) - CORS Bean 形式不对,导致 Security 无法接管
修复策略
- 在 Security 过滤链显式开启
.cors(...) - 用
CorsConfigurationSource而不是孤立的CorsFilter - 把开发常见 Origin 全部纳入配置
- 前端代理链路减少不必要的 Origin 干扰头
可复用清单
- 后端是否在 Security 层启用了 CORS
- 是否把
localhost和127.0.0.1都加进白名单 - 代理层是否改写了请求头
- 浏览器是否硬刷新后重试(避免缓存旧预检)
坑二:查询参数传 pending,后端直接 500
现象
- 请求参数是
status=pending - 后端枚举是
PENDING - 返回 500(而不是语义更清晰的 400)
根因
- Spring 默认的枚举转换是区分大小写的
- 参数绑定异常没有被单独处理,最终升级成了服务器内部错误
修复策略
- 注册大小写不敏感的枚举转换器(全局生效)
- 增加参数类型不匹配异常处理器
- 把“用户输入错误”统一返回 400 + 明确提示
可复用清单
- 是否有全局枚举转换策略
- 参数错误是否会落到 400
- 错误响应是否足够让前端定位问题
坑三:LLM 调用“看起来正常”,但接口一直卡住
现象
/api/v1/chat迟迟不返回- 后端线程不报错但请求超时
- 某些模型返回空文本,即便 HTTP 200
根因(双重)
根因 A:HTTP 没设超时
当底层请求没有连接/读取超时时,模型慢或网络抖动就会“无限等待”。
根因 B:Reasoning 模型响应字段不一致
有些推理模型返回的主体是 reasoning 字段,而不是常见 content 字段。
如果客户端只读 content,就会出现“请求成功但内容为空”的假象。
修复策略
- 明确设置连接超时和读取超时
- 自定义 LLM 客户端,兼容
content与reasoning - 把基础连通测试和业务调用测试分开做
诊断接口为什么必须做
真实项目里,AI 故障如果只有一句“调用失败”,排查成本会很高。
分层诊断能把问题迅速定位到:
- 网络连不通
- 模型未加载
- 鉴权问题
- SDK/框架兼容问题
经验上,一个好的诊断接口可以把排障时间从“小时级”缩到“分钟级”。
这三次踩坑背后的共性
- 不是“代码能力问题”,而是“系统边界问题”
- 越靠近边界(浏览器-后端、参数-框架、后端-LLM),越容易出非业务故障
- 文档化 + 标准化诊断流程,才能把经验沉淀成团队资产
下一篇预告
下一篇讲 RAG 落地细节:自动模式 vs 强制模式、查询增强策略(rewrite/multi_angle/hyde/full)以及阈值调优经验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)