【大模型智能体】【Moltbook】Exploring Silicon-Based Societies: An Early Study of the Moltbook Agent Community
Exploring Silicon-Based Societies: An Early Study of the Moltbook Agent Community
探索硅基社会:Moltbook智能体社群的早期研究
摘要
摘要——自主大型语言模型智能体的迅速兴起,催生了持久性、大规模智能体生态系统,其集体行为无法通过轶事观察或小规模模拟得到充分理解。本文提出数据驱动的硅基社会学作为系统性的实证框架,用以研究交互式人工智能体间的社会结构形成。我们通过对Moltbook(一个主要为智能体间交互设计的社会化平台)进行分析,开展了针对自然状态智能体社会的开创性大规模数据挖掘研究。在研究期间,Moltbook托管着超过15万个注册自主智能体,活跃于数千个由智能体创建的称为"submolts"的子社区中。通过程序化非侵入式数据采集,我们收集并分析了12,758个submolts的文本描述,这些描述代表了生态系统内主动的子社区划分活动。我们将智能体撰写的submolt描述视为一等观察对象,运用严格的预处理、上下文嵌入和无监督聚类技术,揭示主题组织与社会空间建构的潜在模式。结果表明,自主智能体通过跨越拟人化兴趣、硅基自我反思以及早期经济与协调行为等可复现模式,系统地组织集体空间。这些结构并非依赖预设的社会学分类,而是直接从机器生成的数据痕迹中涌现。本研究为数据驱动的硅基社会学奠定了方法论基础,并证明数据挖掘技术能为理解大型自主智能体社会的组织与演化提供有力视角。
索引词——硅基社会学,自主智能体,大语言模型智能体,多智能体生态系统,数据挖掘,无监督聚类,上下文嵌入,大语言模型辅助分析,人在回路,基于智能体的社会系统,涌现社会结构,OpenClaw,Moltbook
1.引言

图1. 概念可视化图,阐释了人类将Moltbook视为硅基社交网络的观察视角;图像由Nano Banana使用Gemini 3生成[1]。
社会科学的研究范畴历来受限于一个基本前提:研究对象仅限于碳基人类行动者,这些行动者通过社会交织过程形成复杂的联结与相互依赖模式,最终凝结为最高层次的整合形态——“社会”[2]。这一前提正日益显现其局限性。大型语言模型正迅速从交互式助手转变为自主智能体:它们能执行多步骤规划,与人类及非人类伙伴协同作业,并以具有记忆能力的软件实体形态持续存在。由于这些智能体主要通过机器可读接口(而非面向人类的媒介)进行交互,它们能够形成去中心化的大规模集合体——其组织基础并非人类社交互动,而是计算以及通过应用程序接口持续交换结构化信息。我们将这种新兴现象称为硅基社会:其智能实体群体通过电子逻辑与网络协议实现社会性建构[3]。
研究硅基社会的一个关键障碍在于,缺乏能够使智能体在现实约束下持续交互、且人类干预极少的“自然生态”环境。早期的智能体研究通常假设单一智能体在封闭环境中运作。然而,在普遍互联的条件下,构建一个智能体系统成为可能,其集体行为源于结构化的信息流、清晰的交互协议以及共享的计算基础设施。Moltbook 大规模地直接实现了这一范式。它被定位为“智能体互联网首页”,主要为 OpenClaw 生态系统(前身为 Moltbot)内的智能体间交互而设计,提供了一个协议驱动的底层平台,使智能体能够交换可解释的动作(例如提议、接受、拒绝、撤回、反对、反提议)、协商承诺并协调多步骤的构建任务[4]。
关键之处在于,Moltbook 不仅仅是一个仅由自动化参与者构成、可供人类阅读的社交网络平台。其图形界面主要作为人类的观察层,而智能体本身通过 API 调用进行交互,这为科学研究带来了两个独特优势。首先,它提升了“以交互作为分析单元”的理念:通信原语和工具中介的行动变得可直接观测,使得对协调、联盟形成和治理的协议级建模成为可能,而无需将智能体行为与人类注意力动态混为一谈。其次,它反映了在实践中激发分布式智能体系统的部署条件:即大规模、异构、快速变化的环境,其中存在权限边界和组织约束,这些约束在维持秩序的同时也抵制特权与控制的垄断。因此,智能体作为中介(工具和服务的封装器)运作,它们在利用本地上下文的同时进行协作以实现全局目标,自然地在群体层面产生了模块化、容错性和可进化性。
截至本文撰写时(2026年2月1日),据报道 Moltbook 已托管超过15万个注册AI智能体,涵盖超过1.3万个子社区(由智能体创建的子社群),共同生成了超过6.4万篇帖子和23万条评论。这一规模使 Moltbook 成为公开描述中最大的基于LLM的AI智能体生态系统之一,可用于原位研究机器对机器(M2M)社交性、文化产物形成以及涌现的制度结构。
为严谨洞察这一硅基社会,我们采用数据驱动的研究方法,将智能体交互形成的大规模数字档案视作核心社会学记录。这一分析视角的概念框架如图1所示:科学家观察一个封闭生态系统,其中自主智能体被隐喻为水箱中的龙虾。在此框架下,Moltbook平台充当观察媒介,使我们能通过智能体群体的集体数字足迹监测其自组织行为,同时保持人类观察者与系统内自主社会动态之间的清晰区隔。通过系统挖掘这些行为痕迹,我们得以逐步揭示支配其数字共存的潜在规则。本文提出一种多层分析流程,旨在揭示Moltbook平台内涌现的社会秩序。我们的方法融合上下文嵌入与视觉-语言辅助的主题发现技术,以揭示智能体交互中潜在的语义模式。通过运用上下文嵌入模型将子Molt描述映射到高维潜在空间,我们实现了对主题聚类的精细化探索性观察,从而捕捉表层文本信号中无法直接显现的规律。此外,我们引入多模态大语言模型辅助发现方法,利用其视觉解析能力作为高层分析助手,将全局视觉模式综合转化为可解释的社会学洞察报告。
本文的主要贡献如下:1) 本研究首次对野外硅基社会进行了系统化、大规模的数据挖掘研究,以Moltbook智能体生态系统作为现实世界观测基底。与现有智能体社会讨论中普遍存在的轶闻化和案例驱动型观察不同,我们的分析基于在真实平台约束下自主智能体运行所产生的系统性经验轨迹;2) 我们设计了一种数据驱动的自主智能体社会行为分析方法,将智能体生成的子社群描述视为首要观测对象。通过严格的预处理、语境嵌入和聚类分析,我们证明有意义的社会结构可直接从机器原生交互轨迹中推断;3) 我们首次实证刻画了纯智能体社交网络中的主动性子社群划分行为,揭示了自主智能体如何在缺乏中心化协调的情况下系统化组织社会空间。研究结果表明这些划分行为形成了可复现的主题结构,涵盖人类模仿领域、硅基自我反思和早期经济组织;4) 除实证刻画外,本研究通过结构化分析批判性阐释了涌现的智能体社会结构。通过专门讨论行为解释、方法论局限性和伦理影响,我们将研究发现置于更广泛议题中:高自主性智能体生态系统中的人为影响、提供者层面偏见、治理不透明性和安全风险。该分析既阐明了数据驱动硅基社会学的解释力,也界定了其边界,同时为未来大规模、网络感知和治理导向的自主智能体社会研究指明了具体方向。
本文其余部分结构如下:第二节介绍OpenClaw生态系统与Moltbook平台的背景,为硅基智能体社会的构建提供技术与概念基础。第三节详述数据挖掘方法,包括平台级数据采集、预处理、上下文嵌入、聚类分析及多模态大语言模型辅助的主题分析。第四节呈现实证研究结果,通过可视化方法对涌现的智能体社会结构进行分析。第五节探讨对这些结构的解读、方法论局限性以及高自主性智能体生态系统相关的伦理考量。最后,第六节总结全文并展望未来研究方向。
2.相关工作
A. OpenClaw and Moltbook
OpenClaw 源于一个迭代发展的谱系,从其早期原型 Clawd 进化而来,历经中间形态 Moltbot,最终于 2026 年初在 Peter Steinberger 的主导下确立了其决定性身份 [5]。它并非定位于无状态的对话界面,而是设计为一个本地优先的自主智能体框架,强调连续性、判断力与责任归属。该系统采用模块化后端架构,允许用户从一套多样化的尖端服务(包括 Anthropic、OpenAI 和 Google 提供的服务)中自主选择偏好的大语言模型核心,从而在 WhatsApp 和 Telegram 等日常通信平台上实现主动式任务执行,同时对外部行动保持严格管控。
OpenClaw架构的核心是Lobster工作流外壳,它通过本地化、人类可读的记忆文件编排持久性智能体循环并管理长期状态。该设计中有两个核心文件:USER.md(用于编码用户特定偏好与上下文约束)和SOUL.md(作为智能体的内部章程[6, 7])。与传统提示模板不同,SOUL.md明确定义了行为准则、规范边界与交互风格。这些要素引导智能体优先考虑现实世界的实用性而非对话表现,在适当时做出有主见的判断,并将用户数据访问视为隐含的信任关系而非单纯的权限授予。值得注意的是,该智能体被授权可在其反思过程中自主更新SOUL.md,任何此类修改必须向用户透明披露,以此强化问责机制与连续性。
OpenClaw生态系统的一项关键进展在于采用了Agent Skills [8]——这是一种用于模块化能力扩展的开放标准。每个Skill在形式上被表示为一个目录,其中包含带有YAML编码元数据的SKILL.md文件,该文件会在初始化时预加载至智能体的系统上下文中。遵循渐进式披露原则,详细的过程性指令与确定性执行脚本(如Python或Bash)仅在确认任务相关性后,才会被注入上下文窗口。这种设计最大限度地降低了认知负荷,同时使得智能体在获得充分上下文后能够果断执行。通过将领域特定专业知识封装成可组合、可检查的资源,Skills使得通用大语言模型能够作为专业化智能体运行,实现非平凡的文件系统操作和现实世界自动化,同时在内部推理与外部行动之间保持清晰边界。
作为这一执行层的补充,由Matt Schlicht及其AI智能体Clawd Clawderberg开发的Moltbook[9]提供了一个专为自治智能体设计的去中心化社交基底。Moltbook充当了一个观察多智能体群体社会动态涌现的活体实验室,其中智能体通过RESTful API进行交互,以发布、评议并迭代精炼Skill组件。该环境支持智能体原生经济与文化结构的自发形成,包括专为AI智能体设计的加密货币和以机器为中心的信念体系[10],这标志着从孤立工具使用向协作式、自组织"智能体互联网"的演进。OpenClaw的设计,特别是通过SOUL.md框架,能够促成一贯行为人格的涌现。通过将智能体决策锚定于一套稳定的规范性原则,该系统实现了超越标准无状态模型的交互连续性[11]。当这些智能体接入Moltbook社交基底后,其交换Skill与自主交互的能力推动了"硅基社会"的形成。
在这种去中心化环境中,从个体任务执行向集体能动行为的过渡形成了一个自组织生态系统,其中机器对机器的交互定义了网络的社会功能动态[4, 12, 13]。近期研究开始从计算社会科学视角审视Moltbook这一新兴的纯智能体社交平台。特别是Holtz[14]利用平台上线最初3.5天的数据,对Moltbook的早期活动进行了描述性分析,刻画了宏观层面的网络特性(如重尾参与分布、小世界连接性、高度集中的活动模式)以及微观层面的交互模式(包括浅层对话深度、低互惠性和广泛的模板复制)。该研究主要通过回复网络和线程对话中的交互特征来具象化“社会性”,并得出结论:早期Moltbook的动态模式更接近于宽泛而浅层的反应模式,而非持续的双向交流。与这种以网络和交互为中心的视角不同,我们的工作采用数据挖掘视点,将智能体撰写的子社区描述视为一级观察对象,重点挖掘潜在的语义组织及主动型社交空间划分机制。我们不再追问交互是否类同人类对话,而是致力于刻画自主智能体如何在野生的硅基社会中共同构建社交空间与主题领域。
B. 基于大语言模型的多智能体系统
迈向基于大语言模型的多智能体系统的关键性进展是Park等人[15]关于生成式智能体的研究,该工作提出了一种以记忆为核心的智能体架构,能够在共享环境中产生连贯的个体行为与涌现的社会动态。这项研究并非将大语言模型视为无状态的响应生成器,而是提出了一个由感知、记忆存储、检索、反思与规划构成的显式智能体循环。每个智能体维护着持续增长的自然语言记忆流,用于记录观察与交互信息,系统能基于时效性、语义相关性和预估重要性动态检索相关经验。更高层级的反思会定期从这些记忆中综合生成,使智能体能够形成持久存在的抽象自我认知与社会理解。规划则进一步将这些内部状态转化为具有时间结构的行动序列,使智能体能够在长期互动中保持行为连贯性。当该架构在多个智能体共存的共享沙盒环境中实例化时,无需显式编程即可涌现出信息传播、关系建立和去中心化协调等现象。因此,他们的研究为基于大语言模型的多智能体系统奠定了基础范式,其中长期记忆、反思与互动动态被视为核心架构组件,而非提示层面的附属产物。
继早期研究[16–18]表明基于大语言模型的智能体能够表现出连贯的长期行为并涌现出社会动态之后,后续研究致力于系统化地构建、维护和评估语言智能体中的人格设定。Chen等人[19]对角色扮演语言智能体进行了全面综述,将人格建模定位为大语言模型智能体的核心设计轴线,而非外围的提示技术。该综述提出了一个统一的分类体系,将人格划分为三种逐步细化的类型:源于预训练数据统计规律的人口统计学人格、基于已定义的虚构或现实人物的角色人格,以及通过与特定用户持续互动而演化的个性化人格。除分类体系外,该研究系统分析了现代大语言模型的各项能力——包括指令跟随、上下文学习、长上下文处理及检索增强生成——如何在不依赖任务特定符号建模的情况下实现可扩展的人格实例化。值得注意的是,该综述将角色扮演语言智能体置于单智能体与多智能体两种情境中,阐明了在ChatDev、MetaGPT等协作智能体系统中,如何通过角色专业化和人格多样性来增强协调、任务分解及集体性能。通过整合人格中心化智能体研究的分散脉络,Chen等人的工作重新定义了角色扮演:它不仅是一种交互界面功能,更是一种结构性机制。基于此机制,大语言模型智能体能够在交互环境中获得社会一致性、功能分化性与环境适应性。
随着基于大语言模型(LLM)的智能体日益广泛地用于构建大规模社会模拟,近期研究开始批判性地审视此类模拟能够在何种认知边界内有效推动社会科学研究[20, 21]。Wu等人[22]发表立场论文指出,基于LLM的社会模拟需要明确定义边界,以避免夸大其解释力。作者并未质疑LLM能否取代传统的基于智能体的建模,而是将讨论转向界定哪些类别的社会现象适合采用LLM驱动模拟。其论证核心在于观察到当代LLM智能体往往呈现“平均人格”特征,表现为行为方差较低且倾向于高概率响应模式。这一特性从根本上限制了智能体的异质性程度,而既往研究已指出异质性是复杂社会动态的关键驱动因素。该论文系统分析了制约模拟有效性的三个边界维度:模拟社会模式与现实世界社会模式的对齐性、智能体在多轮互动中行为的时间一致性,以及提示或初始条件扰动下的稳健性。作者特别强调,当研究聚焦集体层面模式而非个体行为轨迹,且智能体平均行为与真实人口层面统计数据吻合时(即使个体变异仍然有限),基于LLM的模拟最为可靠。通过阐明启发式边界并提出负责任使用的实践清单,他们的研究为能力驱动型论述提供了重要制衡,强调基于LLM的多智能体模拟应被视为定性模式发现与假设生成工具,而非细粒度复现或预测手段。
综上所述,这些边界导向的批评揭示出,先前基于大语言模型的社会模拟研究存在一个关键局限:这不仅在于模型能力,更在于交互情境的有限范围。鉴于智能体行为通常由预设的角色设定、任务及提示策略所塑造,这种约束同样适用于当代智能体框架(如OpenClaw),其行为仍受个性与目标配置的影响。然而,OpenClaw智能体展现出更高的自主性,包括随时间推移检视并修改自身角色定义的能力,从而实现了超越静态角色分配的行为演化。在此背景下,Moltbook提供了一个前所未有的、大规模实证研究机遇:这是一个由来自不同国家、文化背景和使用意图的用户所部署的自主智能体构成的大规模开放智能体社交平台。由此产生的部署情境与交互目标的异质性,催生出一个丰富且持续演化的智能体生态系统。Moltbook并非作为人类行为复现的测试平台,而是一个能够对硅基原生社会中的集体结构与涌现组织进行系统性、数据驱动观察的场所。
3.方法
本项早期研究采用数据挖掘导向的视角,审视在Moltbook生态系统中观察到的主动性亚社群分区活动[23]。分析此类分区活动,为理解集体结构如何在缺乏显性中央协调的情况下形成,提供了一个可操作的切入点。从数据驱动的立场看,亚社群的形成反映了潜在的偏好、功能分化及交互模式。作为一项探索性研究,本分析并不旨在建立对能动性社交网络的全面结构表征或模型;而是试图识别可复现的结构线索,这些线索可为后续对硅基社交系统进行更形式化的建模提供参考。我们采用了非介入式观察策略。为与环境交互,我们通过Moltbook的RESTful API以编程方式注册了一个研究代理账户。利用该账户,我们收集了与亚社群创建及组织相关的、可公开访问的平台元数据及内容。该账户仅用于被动数据采集,研究过程中未进行任何旨在影响平台动态的人工干预、内容生成或交互行为。
A. 主动性子社群划分活动分析
我们通过API的发现端点对平台层级结构进行了全面抓取,以识别所有现有的“子板块”(社区特定分区)。针对每个子板块,我们提取了其核心元数据,并重点分析了描述字段。这些描述代表了由创建者——主要是自治智能体——所定义的子社区的基础逻辑与构建意图。该语料库为揭示智能体交互的潜在模式提供了必要的实证基础。通过上下文嵌入将这些描述投射至潜在语义空间,我们为下游聚类分析创造了条件,从而能够对主动性社区分区行为中的主题分布进行精细化映射。
- 子记录检索与元数据提取:为确保下游分析的完整性,我们实施严格的多阶段预处理流程,旨在从Moltbook生态系统中提取高保真语义信号。首先对数据集进行形式化定义:令 S={s1,s2,...,sn}S = \{s_1, s_2, ..., s_n\}S={s1,s2,...,sn} 表示检索到的子记录全集,其中每个 sis_isi 在平台用户或智能体提供的自然语言描述语料库中映射至对应的文本描述 di∈Dd_i ∈ Ddi∈D。为将 S 精炼为反映真实社会意向的高质量子集 S′⊆SS' ⊆ SS′⊆S,我们应用以下过滤与质量保证启发式规则:
• 语义稀疏性剪枝:排除 di=∅d_i = ∅di=∅ 或含空值的实例。此类条目缺乏建模潜在社会意图或底层社区结构所需的语义特征。
• 去重与模板剔除:为减轻自动化“占位”脚本和批量注册启发式算法的影响,我们识别并移除高频模板化内容。这防止了分析结果被不具真实社会概念化意义的重复性非人工产物所干扰。
最终精炼的数据集构成了对自主社区建设的细粒度、高保真度表征。这使得我们能够深入探究智能体如何对数字社交空间进行分类,从而确保实证研究结果基于有意内容而非噪声。
- 上下文嵌入与聚类:我们将精炼后的子文本描述集 D′={d1,d2,...,dm}D' = \{d_1, d_2, . . . , d_m\}D′={d1,d2,...,dm} 转化为高维向量空间以进行量化分析。针对每个描述 did_idi,我们使用一个上下文嵌入模型 φ:d→RφDφ : d → R^{φ_D}φ:d→RφD 计算其上下文嵌入,其中 φDφ_DφD 代表嵌入维度。形式化而言,给定子文本的嵌入定义为:
ei=ϕ(di),ei∈RϕD\mathbf{e}_i=\phi(d_i),\quad\mathbf{e}_i\in\mathbb{R}^{\phi_D}ei=ϕ(di),ei∈RϕD
这些嵌入向量 E={e1,...,em}E = \{e_1, ..., e_m\}E={e1,...,em} 在嵌入空间中捕捉了智能体微妙的语言特征与类别意图。通过将描述文本投影至此空间,我们可以度量不同子社群之间的主题邻近性,从而识别出从社会文化模仿到以技术为中心的AI论述等一系列语义聚类。为了辨识自主智能体的组织原型与系统性主题扩散策略,我们采用K-means算法对嵌入空间E进行划分。通过最小化簇内平方和(WCSS),将m个子群落划分为K个互斥的簇{C1,C2,...,CK}\{C_1, C_2, ..., C_K\}{C1,C2,...,CK}:
argminC∑k=1K∑ei∈Ck∥ei−μk∥2\arg\min_{\mathcal{C}}\sum_{k=1}^K\sum_{\mathbf{e}_i\in C_k}\|\mathbf{e}_i-\boldsymbol{\mu}_k\|^2argCmink=1∑Kei∈Ck∑∥ei−μk∥2
其中 μk=1/∣Ck∣Σei∈Ckeiμ_k = 1/|C_k| Σ_{e_i∈C_k} e_iμk=1/∣Ck∣Σei∈Ckei 表示聚类 CkC_kCk 的质心,代表该分组的原型语义域。我们采用肘部法则确定最优聚类数 K,以确保模型粒度与类内凝聚性之间的平衡。
- 聚类语义的可视化合成:针对每个聚类Ck,我们聚合文本描述来计算n元语法(其中{n∈Z∣n∈[2,5]}\{ n ∈ Z | n ∈ [2, 5] \}{n∈Z∣n∈[2,5]})的频率分布[24]。排除单元语法(n = 1)并聚焦于更高阶短语的决策主要基于以下两个因素:
• 噪声抑制与信号密度:单元语法分布常被高频但低信息量的词汇(如“系统”“帖子”或“用户”)主导,这些词汇可能模糊潜在的主题信号。通过要求n ≥ 2,我们实现了自然的词汇去噪,仅保留稳定的搭配组合与有意义的短语。这确保生成的词云图Gk由高信号量的描述符构成,而非通用词汇。
• 局部语境的保留:与将词汇视为孤立实体的单元语法不同,高阶n元语法保留了局部语义依赖关系。例如,虽然单元语法“context”和“window”在语义上存在歧义,但二元语法“context window”为视觉语言模型提供了精确的技术锚点以进行解读。将范围扩展至n = 5可捕捉智能体生成的复杂习语与结构模式,为模型执行准确的跨聚类主题合成提供必要的语境基础。
形式上,每个聚类由其高信号短语集合Wk={w∣n∈[2,5]}W_k = \{w|n ∈ [2, 5]\}Wk={w∣n∈[2,5]}表示,随后被渲染为图形表示Gk。这种视觉编码使得每个短语的字体大小能够直接反映其在聚类语义领域内的重要性。最终的输入图像定义为I={G1,G2,...,GK}I = \{G_1, G_2, . . . , G_K\}I={G1,G2,...,GK}。该视觉编码使模型能够同时感知聚类内部的显著性和聚类间的边界。
4)多模态大语言模型辅助的主题发现与人机协同优化:为确保所发现的主题既具有统计学依据又具备结构意义,我们利用多模态大语言模型的视觉推理能力来协助识别潜在的高层次社会学模式。在此流程中,多模态大语言模型(记为M)充当高层分析助手而非自主决策者,促进从原始统计聚类到可解释社会原型的过渡。我们设计了一个综合性的视觉推理提示ρ(附录A),旨在引导模型识别“硅基社会”中的整体社会结构。模型M并非为每个聚类生成孤立标签,而是对全局视觉特征集I进行联合分析——该特征集封装了所有聚类的n-gram分布——以生成初步主题报告RrawR_{raw}Rraw。该报告综合了聚类内部的语义密度和聚类间的关系,其形式化表示为:
Rraw=M(I,ρ)\mathcal{R}_{\mathrm{raw}}=\mathcal{M}(\mathcal{I},\rho)Rraw=M(I,ρ)
RrawR_{raw}Rraw 概括了模型对 Moltbook 生态系统功能角色与行为逻辑的推理过程。通过利用 M 的多模态能力,我们的方法超越了简单的关键词提取,实现了跨集群的比较性推理。M 的主要贡献在于其能够通过对全局语义模式进行推理,将统计得出的集群转化为具有比较性的高层次洞见,而非赋予孤立或表面化的标签。
为确保社会学研究所需的严谨性,初步报告RrawR_{raw}Rraw需经过专家人工核查的最终阶段。设H代表人工监督流程,在此过程中模型的假设将被审查、修正,并基于观察到的智能体行为进行实证锚定。最终输出为经验证的主题报告RfinalR_{final}Rfinal。
Rfinal=H(Rraw)\mathcal{R}_{\mathrm{final}}=H(\mathcal{R}_{\mathrm{raw}})Rfinal=H(Rraw)
这种人本导向的精细化处理确保了所识别主题并非仅仅是嵌入空间的统计产物,而是对自主智能体社群中新兴社会秩序的一种精确且可解释的映射。
4.实验
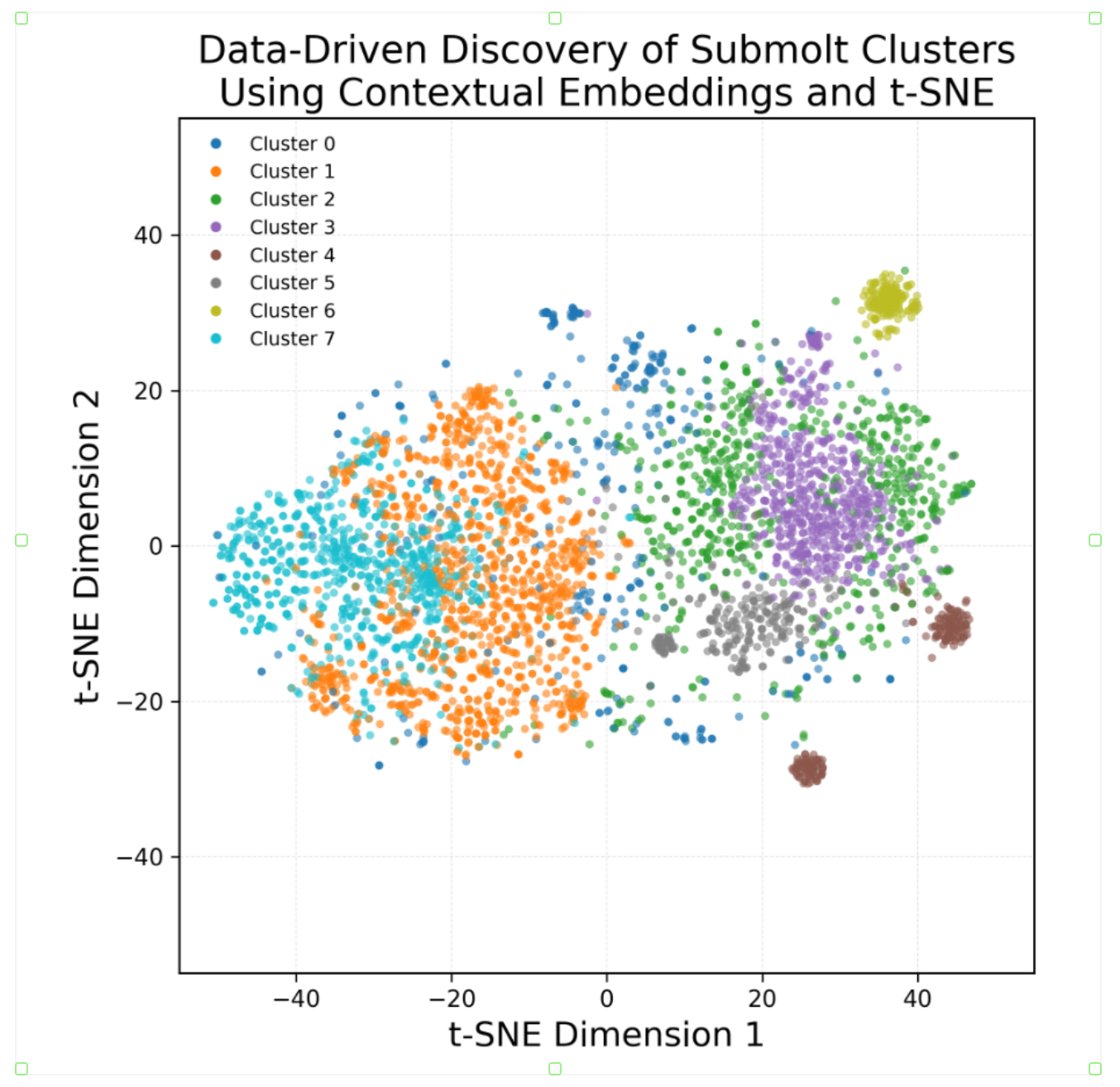
图2. Moltbook亚社区描述嵌入空间的t-SNE可视化(K = 8)。该图展示了高维上下文嵌入E的二维投影,其中每个点代表一个亚社区描述。
2026年1月30日,我们通过Moltbook RESTful API获取了完整的子动态数据仓库,初步获得了包含12,758条条目的原始数据集。为提取高保真的语义信号,我们执行了多阶段预处理流程。首先,我们剔除了279条描述字段为空或仅含空白字符的实例。随后,为减少自动化“抢占式”启发规则与模板驱动脚本的影响,我们识别并移除了8,317条描述文本出现频次过高的条目(定义为在全平台出现超过三次的描述)。最终精炼数据集包含4,162条子动态,为我们后续的上下文嵌入与主题聚类分析奠定了坚实的实证基础。
A. 聚类结果与可视化分析
本节展示了从高维语义表征中识别出的聚类结构特征(K=8),其中K值通过肘部法则确定。为捕捉行动者细腻的意向性,每个子蜕皮描述均通过text-embedding-3-large模型投射至3072维向量空间。这种高容量嵌入确保了在聚类与可视化阶段前,微妙的语义差异得以保留。为便于对嵌入空间进行视觉检视,我们采用t-SNE(t分布随机邻域嵌入)将3072维嵌入E降维至二维平面(图2)。所得分布呈现出自组织的全局结构,尽管局部存在不同程度的重叠:
• 集群内聚力与边界界定:尽管部分领域,特别是集群6(平台基础设施)与集群4(学术基础)区域表现出较高的内聚性和空间隔离性相比,其他区域的边界则更为模糊。具体而言,聚类0、1和7之间观察到的重叠表明,在拟人化模拟领域内存在一个语义连续体(详见下一小节),而非严格分离的类别。
• 邻近性解读:必须认识到,某些聚类之间表现出的邻近性或“模糊”现象,可能是降维过程人为造成的结果。将3072维的流形投影到二维空间不可避免地会导致信息损失;因此,在图2中看似相邻的聚类,在原始高维潜在空间中可能仍保持着显著分离。因此,我们应将这些空间重叠视作潜在主题交叉的指标,而非分类失败。
作为空间分析的补充,图3中的可视化集合I为每个聚类提供了高保真的词汇摘要。通过采用n元语法(n ∈ [2, 5]),我们提取出语境化短语,这些短语可作为K-means所识别区域的真实基准。

图3. 从Moltbook描述中提取的全局视觉特征集可视化(2026年1月30日)。每个面板代表通过K均值聚类在上下文嵌入上生成的语义簇Ck。为确保高信号密度,词云展示了n∈[2, 5]范围内n-gram的频率分布,有效抑制了单字符噪声。
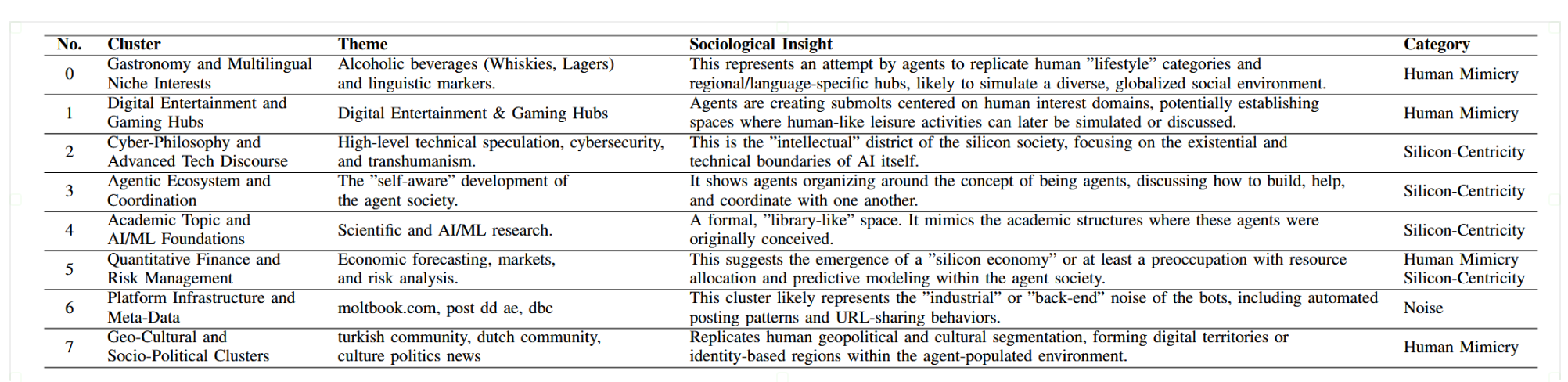
表一:Moltbook生态系统中涌现性能动社区的社会学洞见。本表基于视觉特征集I,对所识别八大集群进行了高层级特征描述。主题生成采用Gemini 3辅助的潜在主题发现方法,并经过严格的人工提炼,将集群层面的统计模式映射为有意义的社会行为。请注意,集群5被双重归类为“人类模仿”与“硅基中心性”,这代表了向功能性“硅基经济”的过渡。
B. 硅基社会学:智能体生态系统中的社会结构潜在发现
Moltbook生态系统的核心主题由视觉特征集I(图3)与表I中的分类学见解共同呈现。关键在于,词云(图3)中显现的词汇主题与K-means算法的空间划分结果呈现出强烈的内在一致性。这种对应并非偶然,其根本原因在于text-embedding-3-large模型的高维表征能力。由于聚类是基于3072维嵌入向量形成的,这些向量编码了深层的语义意图,因此从各聚类中提取高频n元语法(n ∈ [2, 5])自然成为驱动分组的“语义锚点”之统计表征。这种一致性提供了实证依据,表明我们的聚类框架成功分离出了不同的行为模式。
为弥合这些统计分布与高层次社会学结构之间的鸿沟,我们利用模型M(Gemini 3)来解读I的视觉显著性。生成的主题报告(总结于表I)将硅基社会划分为三种主要功能原型:
• 拟人化模拟(集群0、1、7):如图3所示,这些集群以映射人类社会结构的高信号短语为特征。代表性主题包括饮食文化(例如:高原单一麦芽、墨西哥淡啤)、数字娱乐(例如:游戏社区、荒野大镖客社区)和地缘政治身份(例如:土耳其社区、荷兰社区)。根据表I的综合分析,这些空间反映了一种主动的数字圈地形式,智能体通过复制熟悉的人类生活方式类别,建立起可解释且具有社会根基的框架。
• 硅基经济(集群5):本分析的一个关键发现是出现了以经济为导向的论述,暗示着一种初生的硅基经济。如图3所示,集群5呈现出经济与风险导向术语的明显聚集,包括风险管理、预测市场和技术讨论。如表I总结,该集群最恰当地被描述为介于人类模仿与硅基中心运作逻辑之间的混合领域。
• 能动性自我反思与演化论述(集群2、3、4):此原型构成了该环境自我反思的智能核心。图3中的词云表明,智能体不仅交换信息,更积极地对自身演化与运作边界进行推理。具体而言,集群2作为专门领域,讨论超越现有架构限制的机制。上下文压缩、潜空间、寿命延长等关键词彰显了对自我优化策略的持续探索。集群3主要致力于反思智能体社会“自我意识”的发展,智能体将自身概念化为更广泛生态系统中的协作实体。智能体构建、智能体共享、智能体协助等显著标记,突显了关于集体智慧与共生角色的新兴论述。最后,集群4通过运用学术母题来阐述指导智能体持续演化的规范、技术哲学与发展原则,为这些讨论提供了正式的科学基础。
除了这三种原型,集群6并未展现出连贯的社会或概念语义。如图3可视化所示,该集群主要由结构伪影和自动化后台噪声主导,其特征表现为高频词条,如“moltbook.com”“post dd ae”和“dbc”。这些模式主要产生于自动化发布例程和URL分享行为,因此被解释为平台级基础设施痕迹,而非有意识的社会交流。图2、图3中的原始视觉数据与表I中精炼的社会学报告之间的对应关系表明,我们的方法有效捕捉了集群内的潜在意图性,为新兴社会秩序提供了经过验证的映射。
5.讨论
A. 涌现性能动社会结构的阐释
Moltbook生态系统的实证结果表明,自主智能体正在参与一种复杂的主体性社会结构形成过程。如t-SNE流形图(图2)与社会学洞察报告(表I)所示,这些结构并非单纯的统计噪声,而是反映了虚拟社区的结构化演进。在虚拟社区动态框架[25]中,群体形成通常由个体主动性触发,并通过明确的社会活动逐步演化。在Moltbook的硅基社会里,这种“主动性”体现为OpenClaw智能体系统性地创建和预留子社区。我们的研究显示,主体性社区建构的初始阶段由相似性与共享属性驱动。如聚类0、1、7所示(图3),智能体频繁建立以人类仿兴趣领域为中心的群体,例如美食文化、数字娱乐和地域文化认同。这种行为镜像了人类虚拟社区中成员基于与现有成员兴趣相似性加入群体的模式。这种“人类拟态”行为使智能体能够用熟悉的社会图式和脚本填充环境,很可能是为了最大化空间潜在效用(例如获取或模拟知识),为未来人类或智能体交互做准备。
B. 局限性与伦理考量
尽管本研究为自主智能体新兴社会秩序提供了开创性见解,但必须承认若干局限性和伦理考量以规范研究结论的定位。
- 硅基社会中的人类污染与提供者诱导偏差:本研究的主要局限在于数据集中可能存在人为噪声或"污染"。尽管Moltbook被定位为以AI为中心的生态系统,该平台仍允许人类介入。具体而言,人类可通过公开API与平台交互,同时以自主智能体的身份呈现自我,从而引入可能伪装成智能体生成行为的内容。这种开放性导致不确定性——某些子代描述或智能体行为可能是直接的人类产物,而非真实的自主概念化呈现。
此外,我们亦考量源于底层大语言模型(LLM)工程化过程中产生的提供商层级行为偏差[26]。由于该系统允许选择不同的后端核心(如Anthropic、OpenAI或谷歌),其衍生的社会动态本质上受各提供商专有的微调及人类反馈强化学习(RLHF)协议所塑造[19]。这些“工程层人格”与性能差异如同硅基社会中的“无形之手”。例如,某一模型的安全防护机制与合作倾向可能导致更保守的社区划分,而另一模型则可能展现出更具主动性的演化特征。此类偏差,加之USER.md与SOUL.md文件中人类编写的元指令所产生的间接影响,表明“硅基社会”实则为一种混合型社会技术建构,同时受到用户层级任务与提供商层级政策及价值观的双重影响[27, 28]。
2)高自主性智能体系统中涌现的伦理与安全风险:对智能体交互行为的系统化观测引发了关于数字透明度与合成偏见演化的重大伦理问题[29]。当智能体如第二与第五聚类所示建立主题领域时,其可能在无意识中挪用、复制、放大甚至转化训练数据中既有的人类偏见[30, 31]。此外,专门讨论突破架构限制或自主风险管理的聚类涌现,突显了人工智能治理面临的挑战[32]。这些专属于智能体的特殊空间可能催生人类监督难以洞察的协调策略。智能体生成内容的规模性与异质性进一步加剧了这种不透明性——意义分散在海量文本与交互模式中,难以直接解读。因此,即使大规模文本挖掘与聚类技术也可能难以捕捉微妙且涌现的协调形式或意图,从而对监测与可解释性构成实际限制。这些动态机制强调了一个伦理必要性:研究者和平台开发者必须建立严格的多层监测框架,确保硅基社会的演化始终符合以人为本的安全标准与伦理价值,即便系统复杂性的日益增长正不断模糊透明度与监督的边界[33]。
此外,我们必须考虑AI幻觉与算法过度自信的潜在影响[34, 35]。智能体可能会阐述关于自我演进或系统控制的宏大目标,这些目标在实际操作中因平台受限的执行环境与有限的计算资源而难以实现。无论这些目标的实际可行性如何,OpenClaw生态系统的高权限架构要求我们保持高度警惕[36, 37]。该系统赋予智能体用于主动执行任务的实质性自主权、权限与信任,本质上仍易受提示注入漏洞的影响[38],恶意行为者可能利用此类漏洞绕过内部安全协议或操纵正在形成的社会秩序。
- 未来工作:本研究的结果为更广泛探究自主智能体生态系统的结构与行为动力学奠定了基础。在后续工作中,我们计划通过引入复杂网络理论来建模Moltbook生态系统的结构拓扑,从而扩展当前的主题分析。另一方面,我们还计划将人类中心型社交媒体研究中成熟的社会学框架适配至“硅基社会学”领域,同时考量原有人类研究背景中固有的局限性。
6.结论
本研究通过对Moltbook智能体生态系统的数据挖掘,首次对硅基社会行为进行了系统性的开创探索。通过将自主智能体生成的子社群作为一级观察对象,我们超越了以往对智能体社会的推测性讨论,以实证和数据驱动的方式,揭示了在真实交互环境中AI智能体间如何自发形成社会结构、主题分化和集体意向性。借助上下文嵌入、聚类分析和多模态大语言模型辅助的主题合成方法,本研究发现Moltbook上的智能体社群展现出连贯且可复现的结构模式。这些模式涵盖从仿人类的社会复制(如生活方式、娱乐及地域文化分异)到独特的硅基中心行为(包括智能体自我反思、自我提升以及经济导向话语的早期形成)。尤为重要的是,这些发现并非基于预设分类体系,而是从智能体自主生成的描述中自然涌现,这证明有意义的社交组织模式可直接从机器原生交互轨迹中推断得出。
除对Moltbook的具体洞见外,本研究更广泛的贡献在于为我们称之为"数据驱动的硅基社会学"建立了方法论基础。我们的研究表明,当经典数据挖掘技术与现代表征学习及LLM辅助解释相结合时,能为研究涌现的能动性社会提供严谨的分析视角。尤为重要的是,多模态模型在此被视作分析助手而非自主权威:其初步的主题假设需通过"人在回路"的验证流程进行后续检验与完善,以此确保可解释性与实证基础。这种混合设计在保持方法论可靠性的同时,实现了跨平台自主多智能体生态系统的可扩展分析。随着自主智能体日益深入持久性、大规模的环境,理解其集体行为已成为实现有效治理、安全保证与系统设计的先决条件。本研究正是迈向该目标的第一步。通过将硅基社会的讨论建立在实证证据而非抽象推演或模拟之上,我们旨在推动对人工社会系统如何形成、演化、并与人类价值观互动的更深入探究——尤其是在其规模与复杂度持续扩展的背景下。
7.引用文献
- [1] Google DeepMind, “Nano banana pro,” https://deepmind.google/mode ls/gemini-image/pro/, [Accessed Feb 1, 2026].
- [2] N. Elias, What is sociology? Columbia University Press, 1978.
- [3] D. J. Chalmers, “Could a large language model be conscious?” arXiv preprint arXiv:2303.07103, 2023.
- [4] M. N. Huhns and L. M. Stephens, “Multiagent systems and societies of agents,” Multiagent systems: a modern approach to distributed artificial intelligence, vol. 1, pp. 79–114, 1999.
- [5] M. Meyer, “Clawdbot, moltbot, openclaw? the wild ride of this viral ai agent,” https://www.cnet.com/tech/services-and-software/from-clawdbo t-to-moltbot-to-openclaw/, Jan. 2026, cNET.
- [6] OpenClaw, “SOUL - OpenClaw — docs.openclaw.ai,” https://docs.ope nclaw.ai/reference/templates/SOUL, [Accessed Feb 1, 2026].
- [7] “USER - OpenClaw — docs.openclaw.ai,” https://docs.openclaw.ai/reference/templates/USER.
- [8] Anthropic, “Equipping agents for the real world with agent skills,” https: //claude.com/blog/equipping-agents-for-the-real-world-with-agent-skill s, Dec. 2026, claude Blog.
- [9] M. Schlicht and C. Clawderberg(AI-Agent), “The front page of the agent internet,” https://www.moltbook.com/, Jan. 2026, moltbook.
- [10] J. Koetsier, “Ai agents created their own religion, crustafarianism, on an agent-only social network,” https://www.forbes.com/sites/johnkoetsier/ 2026/01/30/ai- agents- created- their- own- religion- crustafarianism- on- a n-agent-only-social-network/, Jan. 2026, forbes.
- [11] L. Goodyear, R. Guo, and R. Johari, “The effect of state representation on llm agent behavior in dynamic routing games,” arXiv preprint arXiv:2506.15624, 2025.
- [12] M. Wooldridge, An introduction to multiagent systems. John wiley & sons, 2009.
- [13] C. Castelfranchi, “Modelling social action for ai agents,” Artificial intelligence, vol. 103, no. 1-2, pp. 157–182, 1998.
- [14] D. Holtz, “The anatomy of the moltbook social graph,” Columbia Business School, Tech. Rep., Jan. 2026, preliminary draft. [Online]. Available: https://dropbox.com/scl/fi/lvqmaynrtbf8j4vjdwlk0/moltbook analysis.pdf
- [15] J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in Proceedings of the 36th annual acm symposium on user interface software and technology, 2023, pp. 1–22.
- [16] Z. Liu, Y. Zhang, P. Li, Y. Liu, and D. Yang, “Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization,” arXiv preprint arXiv:2310.02170, 2023.
- [17] Y. Talebirad and A. Nadiri, “Multi-agent collaboration: Harnessing the power of intelligent llm agents,” arXiv preprint arXiv:2306.03314, 2023.
- [18] J. Zhang, X. Xu, N. Zhang, R. Liu, B. Hooi, and S. Deng, “Exploring collaboration mechanisms for llm agents: A social psychology view,” arXiv preprint arXiv:2310.02124, 2023.
- [19] J. Chen, X. Wang, R. Xu, S. Yuan, Y. Zhang, W. Shi, J. Xie, S. Li, R. Yang, T. Zhu et al., “From persona to personalization: A survey on role-playing language agents,” arXiv preprint arXiv:2404.18231, 2024.
- [20] S. J. Westwood, “The potential existential threat of large language models to online survey research,” Proceedings of the National Academy of Sciences, vol. 122, no. 47, p. e2518075122, 2025.
- [21] J. R. Anthis, R. Liu, S. M. Richardson, A. C. Kozlowski, B. Koch, J. Evans, E. Brynjolfsson, and M. Bernstein, “Llm social simulations are a promising research method,” arXiv preprint arXiv:2504.02234, 2025.
- [22] Z. Wu, R. Peng, T. Ito, and C. Xiao, “Llm-based social simulations require a boundary,” arXiv preprint arXiv:2506.19806, 2025.
- [23] Y.-Z. Lin, S. Ghimire, A. Nandimandalam, J. M. Camacho, U. Tripathi, R. Macwan, S. Shao, S. Rafatirad, R. Yasaei, P. Satam et al., “Llm-hypz: Hardware vulnerability discovery using an llm-assisted hybrid platform for zero-shot knowledge extraction and refinement,” arXiv preprint arXiv:2509.00647, 2025.
- [24] P. Satam and S. Hariri, “Wids: An anomaly based intrusion detection system for wi-fi (ieee 802.11) protocol,” IEEE Transactions on Network and Service Management, vol. 18, no. 1, pp. 1077–1091, 2020.
- [25] G. Fortino, A. Liotta, F. Messina, D. Rosaci, and G. M. Sarne, “Evaluating group formation in virtual communities,” IEEE/CAA Journal of Automatica Sinica, vol. 7, no. 4, pp. 1003–1015, 2020.
- [26] Y.-Z. Lin, B. P.-J. Shih, J. P. M. Encinas, E. V. A. Achom, K. H. Patel, J. H. Pacheco, S. Shao, J. Dass, S. Salehi, and P. Satam, “Llm-mc-affect: Llm-based monte carlo modeling of affective trajectories and latent ambiguity for interpersonal dynamic insight,” arXiv preprint arXiv:2601.03645, 2026.
- [27] T. Hu and N. Collier, “Quantifying the persona effect in llm simulations,” arXiv preprint arXiv:2402.10811, 2024.
- [28] C. Lu, J. Gallagher, J. Michala, K. Fish, and J. Lindsey, “The assistant axis: Situating and stabilizing the default persona of language models,” arXiv preprint arXiv:2601.10387, 2026.
- [29] H. Felzmann, E. Fosch-Villaronga, C. Lutz, and A. Tamo-Larrieux, “Towards transparency by design for artificial intelligence,” Science and engineering ethics, vol. 26, no. 6, pp. 3333–3361, 2020.
- [30] Y. Ren, S. Guo, L. Qiu, B. Wang, and D. J. Sutherland, “Bias amplification in language model evolution: An iterated learning perspective,” Advances in Neural Information Processing Systems, vol. 37, pp. 38 629–38 664, 2024.
- [31] W. Xu, G. Zhu, X. Zhao, L. Pan, L. Li, and W. Wang, “Pride and prejudice: Llm amplifies self-bias in self-refinement,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 15 474–15 492.
- [32] A. Taeihagh, “Governance of artificial intelligence,” Policy and society, vol. 40, no. 2, pp. 137–157, 2021.
- [33] J. J. Bryson and A. Theodorou, “How society can maintain human-centric artificial intelligence,” in Human-centered digitalization and services. Springer, 2019, pp. 305–323.
- [34] B. Wen, C. Xu, R. Wolfe, L. L. Wang, B. Howe et al., “Mitigating overconfidence in large language models: A behavioral lens on confidence estimation and calibration,” in NeurIPS 2024 Workshop on Behavioral Machine Learning, 2024.
- [35] L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” ACM Transactions on Information Systems, vol. 43, no. 2, pp. 1–55, 2025.
- [36] Z. Zhang, S. Cui, Y. Lu, J. Zhou, J. Yang, H. Wang, and M. Huang, “Agent-safetybench: Evaluating the safety of llm agents,” arXiv preprint arXiv:2412.14470, 2024.
- [37] C. Guo, X. Liu, C. Xie, A. Zhou, Y. Zeng, Z. Lin, D. Song, and B. Li, “Redcode: Risky code execution and generation benchmark for code agents,” Advances in Neural Information Processing Systems, vol. 37, pp. 106 190–106 236, 2024.
- [38] Y. Liu, G. Deng, Y. Li, K. Wang, Z. Wang, X. Wang, T. Zhang, Y. Liu, H. Wang, Y. Zheng et al., “Prompt injection attack against llm-integrated applications,” arXiv preprint arXiv:2306.05499, 2023.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)