PPO算法原理
PPO(Proximal Policy Optimization,近端策略优化)是 OpenAI 在 2017 年提出的策略梯度类强化学习算法,核心目标是解决传统策略梯度(Policy Gradient, PG)算法 “更新幅度过大导致训练崩溃 / 不稳定” 的问题,同时保持简单、易实现、性能优异的特点 —— 这也是它成为强化学习(尤其是大模型 RLHF)中最主流算法的原因。
本文会从「核心背景→核心思想→数学原理→算法流程→RLHF 适配」逐步讲解,结合你之前的代码,让原理和实践对应。
一、先理解:策略梯度的核心(PPO 的基础)
强化学习的核心是让 “智能体(Agent)” 学习一个策略 πθ(a∣s)(以参数θ表示的函数,比如大模型),使得智能体在 “环境(Environment)” 中采取的动作a能最大化累计奖励(回报)。
1. 策略梯度的核心公式
传统策略梯度的目标是最大化策略的累计奖励,其梯度公式为:
2. 传统策略梯度的致命问题
- 更新幅度不可控:每次更新直接用新策略πθnew替换旧策略πθold,若学习率太大,新策略会和旧策略差异过大(比如模型突然生成无意义内容),导致训练崩溃;若学习率太小,训练效率极低。
- 数据利用率低:每轮更新仅用一次采样数据,浪费计算资源。
二、PPO 的核心思想:限制策略更新的 “步子”
PPO 的核心是“近端” —— 让新策略和旧策略的差异不超过一个可控范围(像给策略更新 “设护栏”),避免步子迈太大。
它有两种主流实现方式,其中PPO-Clip(裁剪版)是最常用的(也是你代码里的版本),另一种是 KL 惩罚版(通过 KL 散度限制策略差异)。
1. PPO-Clip 的核心目标函数(重中之重)
PPO 把传统策略梯度的目标函数修改为 “裁剪版”,强制限制策略更新的幅度:
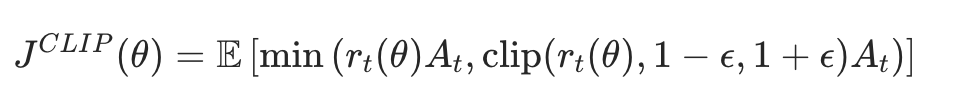
逐个符号解释(通俗化)
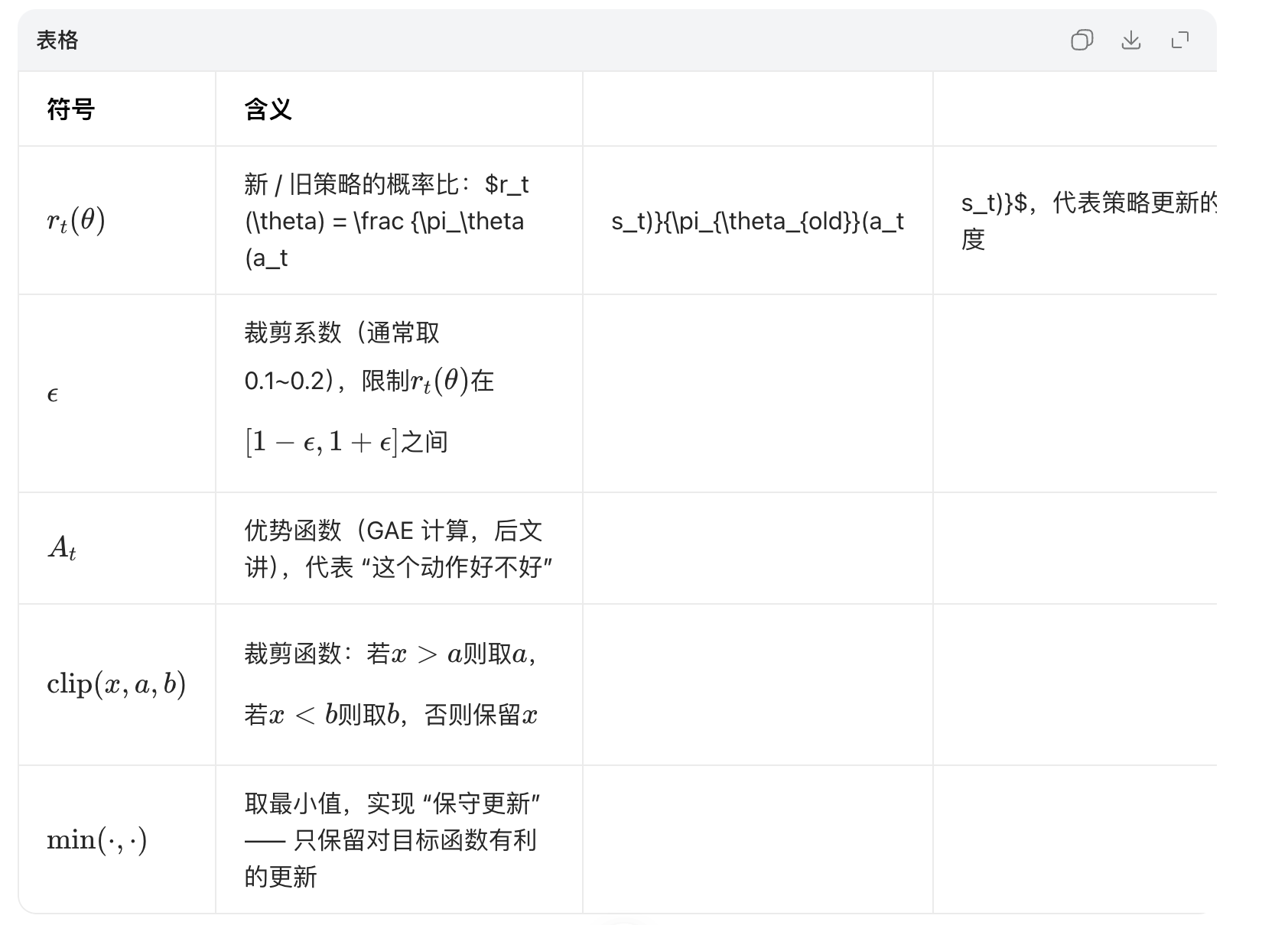
直观理解 Clip 操作(核心)

2. 辅助优化:值函数(Value Function)

3. 可选优化:熵奖励(鼓励探索)
为了避免策略收敛到 “局部最优”(比如模型只生成固定内容),PPO 会加入熵奖励(熵越大,策略越 “随机”,探索性越强):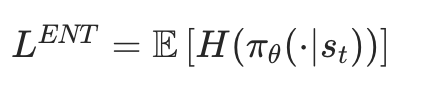
4. PPO 总损失函数

三、关键前置:优势函数的计算(GAE)
PPO 中优势函数At不是直接计算,而是用GAE(广义优势估计) 计算 —— 平衡 “方差” 和 “偏差”,让优势函数更稳定(这也是你代码里advantages = torch.stack(advantages_reversed[::-1], axis=1)的逻辑)。
GAE 的核心公式

直观理解
GAE 把 “即时优势(TD 误差)” 和 “长期优势” 结合,既避免只看即时奖励导致的方差大,又避免只看长期奖励导致的偏差大 —— 这是 PPO 训练稳定的关键。
四、PPO 完整算法流程(Clip 版本)
结合你之前的代码,梳理 PPO 的完整步骤(从采样到更新):
步骤 1:初始化

步骤 2:收集数据(Rollout,对应你代码里的batch_generation)

步骤 3:策略更新(多轮 Epoch,对应你代码里的for ppo_epoch_idx in range(args.num_ppo_epochs))

步骤 4:重复
回到步骤 2,直到策略收敛(比如奖励不再提升)。
五、PPO 在 RLHF 中的适配(对应你的代码)
你之前的代码是 PPO 在RLHF(基于人类反馈的强化学习) 中的应用,核心适配点:
总结(核心关键点)
- 核心目标:解决传统策略梯度 “更新幅度不可控” 的问题,通过 Clip 操作限制新 / 旧策略的差异;
- 稳定关键:用 GAE 计算优势函数,平衡方差和偏差,让训练更稳定;
- 效率关键:多轮 Epoch 训练同一批数据,提升数据利用率;
- 实现核心:Clip 操作(限制策略更新比例)+ 同时优化策略 / 值函数 + 熵奖励(鼓励探索);
- RLHF 适配:奖励由 “人类反馈(奖励模型)+ KL 惩罚” 组成,避免模型生成无意义内容。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)