AI大模型RAG与Agent开发学习
LangChain学习
本节内容来自黑马程序员,这里作为笔记记录,覆盖LangChain基本内容和自己的一些见解。
LangChain简介
LangChain 由 Harrison Chase 创建于2022年10月,它是围绕LLMs (大语言模型)建立的一个框架。
LangChain自身并不开发LMs,它的核心理念是为各种LLMs实现通用的接口,把LLMs相关的组件“链接”在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用.
主要功能:
- Prompts:优化提示词(提示词工程)
- Models:调用各类模型
- History:管理会话历史记录(记忆)
- Indexes:管理和分析各类文档
- Chains:构建功能的执行链条
- Agent:构建智能体
LangChain是一个开发LLM相关业务功能的集大成者,是一个Python的第三方库,提供了各种功能的API。提供:
- 提示词优化的相关功能API
- 调用各类模型的功能API会话记忆的相关功能API
- 各类文档管理分析的功能API
- 构建Agent智能体的相关功能API
- 各类功能链式执行的能力
LangChain是后续学习RAG开发的主力框架
LangChain环境部署
pip install langchain langchain-community langchain-ollama dashscope chromadb
- langchain:核心包
- langchain-community:社区支持包,提供了更多的第三方模型调用(我们用的阿里云千问模型就需要这个包)
- langchain-ollama:0llama支持包,支持调用0llama托管部署的本地模型
- dashscope:阿里云通义千问的Python SDK
- langchain-chroma
- chromadb:轻量向量数据库(后续使用)
RAG 介绍
通用的基础大模型存在一些问题:
- LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
- LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
- 幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息
- 数据安全性
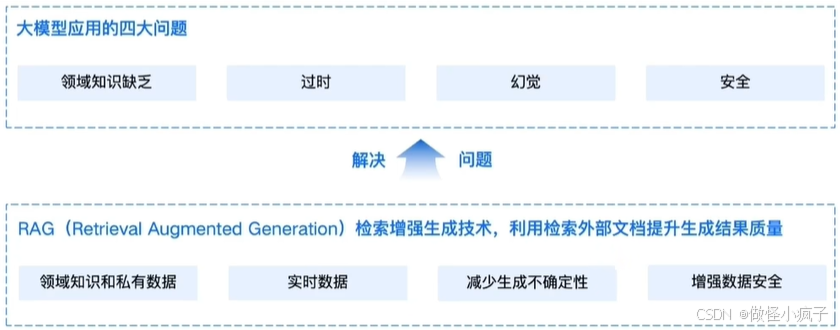
RAG(Petrieval-Augment Generation) 即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案。可以总结为一个公式:RAG = 检索技术 + LLM提示。
RAG工作原理
-
工作流程:
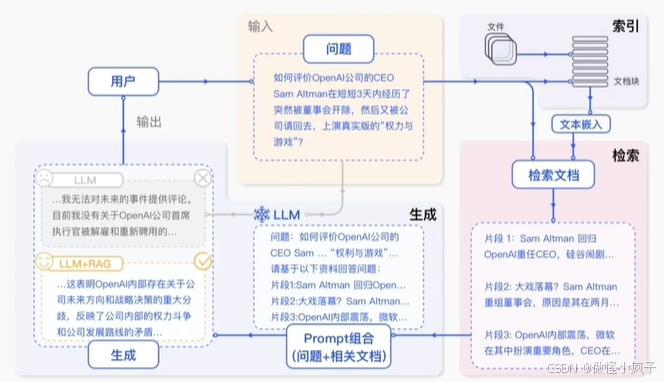
模型无法对未来的事件提供评论。 —— 使用 RAG进行解决,涉及 离线和在线部分- 离线板块: 索引部分(从各种来源实时获取知识)—— 实时更新向量库
- 在线板块:检索部分,先把问题转为向量,然后和向量库进行相似匹配;提取资料与用户问题融合 再交给模型
在用户提问问题之前,会进行文本嵌入(从外部搜集信息) —— 用途:实时更新自己的知识库,将 问题 + 检索的文本给模型
简单来说,RAG工作分为两条线:离线准备线/在线服务线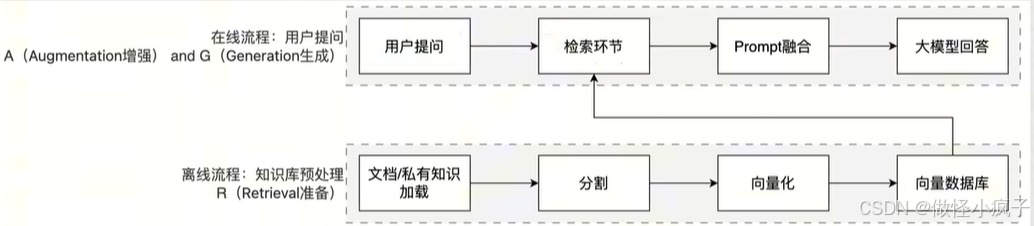
- RAG标准流程:
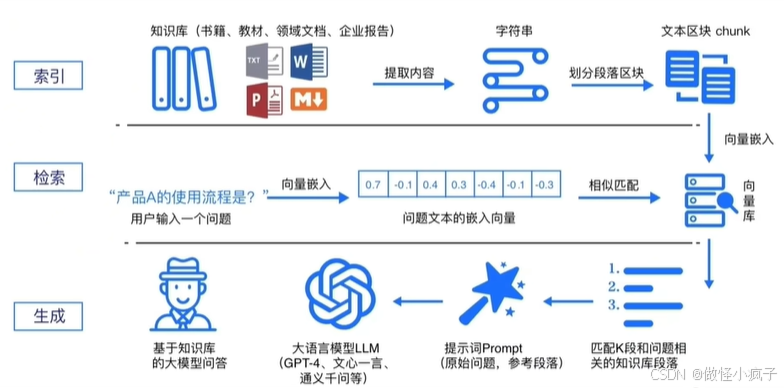
RAG 标准流程由**索引(Indexing)、检索(Retriever)和生成(Generation)**三个核心阶段组成。-
索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化embedding),向量存储在向量数据库(vector database)中。
- 加载文件
- 内容提取
- 文本分割,形成chunk
- 文本向量化
- 存向量数据库
-
检索阶段,用户输入的查询(qUery)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
- query向量化
- 在文本向量中匹配出与问句向量相似的top_k个
-
生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
- 匹配出的文本作为上下文和问题一起添加到prompt中
- 提交给LLM生成答案:
-
总结:
- 模型本质上就是用户输入,模型给出输出,用户能做的就是在输入上做功夫。
- RAG就是在向模型提问之前基于已有的知识库或文档内容做检索,确保向模型提问的内容更精准以及包含足够的信息量用以提供给模型。
RAG的核心价值:
- 解决知识实效性问题:大模型的训练数据有截止时间,RAG 可以接入最新文档(如公司财报、政策文件),让模型输出“与时俱进”
- 降低模型幻觉:模型的回答基于检索到的事实性资料,而非纯靠自身记忆,大幅减少编造信息的概率。
- 无需重新训练模型:相比微调(Fine-tuning),RAG只需更新知识库,成本更低、效率更高。
向量的基础概念
RAG流程中,向量库是一个重要的节点。
- 离线流程:知识和信息 → 向量嵌入(向量化) → 存入向量库
- 在线流程:用户的提问 → 向量嵌入(向量化) → 在向量库中匹配
向量(Vector)就是文本的“数学身份证”:它把一段文字的语义信息,转换成一串固定长度的**数字列表,**让计算机能 “看懂”文字的含义并做相似度计算
简单来说,就是让计算机更方便的理解不同的文本内容,是否表述的是一个意思。
如何 将文本 转为 对应的 数字向量? —— 文本嵌入模型
文本嵌入模型(如text-embedding-v1)通过深度学习等技术,从文本提取语义特征并映射为固定长度的数字序列。
在向量匹配的过程中,如何识别2段文字是否表述相似的含义,主要可以通过余弦相似度等算法来完成,比如:
通过余弦相似度算法可以计算得到:A和B相似度0.999789,A和C相似度0.361446
由此可通过精确的数学计算,去匹配2段文本是否描述同一个意思,提高语义匹配的效率和精度。
如何更精准的完成语义匹配,生成向量的维度是一个很重要的指标。
如text-embedding-V1模型,可以生成1536维的向量(一段文本固定得到1536个数字序列),比较实用。
- 1536个数字表示,这段文本在1536个主题(抽象的语义特征)方向上的得分(强度)
- 生成向量的维度越多,就更好的记录文本的语义特征,做语义匹配会更加精准。
- 更多的向量会在计算、存储和匹配过程中,带来更大的压力。
选择合适的向量维度需要在精确和性能之间做平衡。一般1536维算是比较好的选择。
余弦相似度
向量的数字序列,共同决定了向量在高维空间中的方向和长度.而余弦相似度主要就是撇除长度的影响,得到方向的夹角。夹角越小越相似,即方向相同。
如何体现向量的方向和长度呢?以一维向量为例:

扩展到 二维向量:

余弦相似度主要匹配的就是:同向(无所谓长度)
我们能直接发现[0.5,0.5]和[0.7,0.7]是同向不同长。—— 计算机如何判定就依赖余弦相似度算法了。
在文本向量语义匹配中,余弦相似度是衡量两个向量方向相似程度的核心算法,即判断两段文本语义是否相近。余弦相似度→ 两个向量的点积 ÷ 两个向量模长的乘积,公式:
余弦相似度公式(两个向量)
设两个向量:A = (a₁, a₂, …, aₙ);B = (b₁, b₂, …, bₙ)
公式: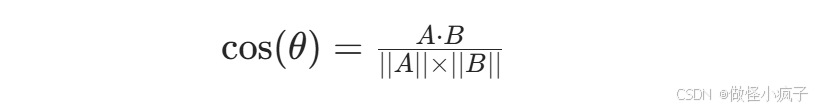
展开写: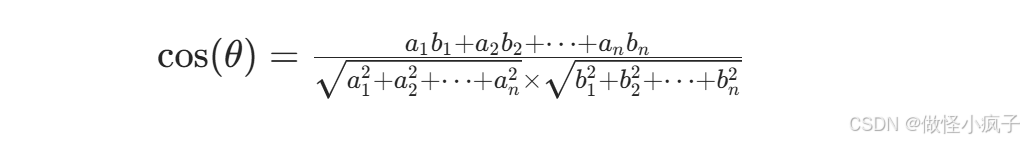

范围:[-1, 1] —— 越接近 1 → 越相似;越接近 -1 → 越相反;0 → 不相关
代码实现:
import numpy as np
"""
计算两个向量的余弦相似度
参数:
vec_a(np.array):向量A
vec_b(np.array):向量B
返回:
con_sim
"""
def get_dot(vec_a, vec_b):
# 计算两个向量的点击,两个向量同维度数字乘积之和
if len(vec_a) != len(vec_b):
raise ValueError("2个向量维度数量必须相同")
dot_sum = 0
for a, b in zip(vec_a, vec_b):
dot_sum += a * b
return dot_sum
def get_norm(vec_a):
# 计算模长: 对向量每个数字 求平方 求和 开根号
sum_square = 0
for v in vec_a:
sum_square += v * v
return np.sqrt(sum_square)
def cosine_similarity(vec_a, vec_b):
result = get_dot(vec_a, vec_b) / (get_norm(vec_a) * get_norm(vec_b))
return result
if __name__ == "__main__":
vec_a = [0.5, 0.5]
vec_b = [0.7, 0.7]
vec_c = [0.7, 0.5]
vec_d = [-0.6, -0.5]
print('ab: ', cosine_similarity(vec_a, vec_b))
print('ac: ', cosine_similarity(vec_a, vec_c))
print('ad: ', cosine_similarity(vec_a, vec_d))
输出:
ab: 1.0
ac: 0.9863939238321436
ad: -0.995893206467704
LangChain组件 —— Models
现在市面上的模型多如牛毛,各种各样的模型不断出现,LangChain模型组件提供了与各种模型的集成,并为所有模型提供一个精简的统一接口。
LangChain目前支持三种类型的模型:LLMs (大语言模型)、Chat Models(聊天模型)、Embeddings Models(嵌入模型)
- LLMs:是技术范畴的统称,指基于大参数量、海量文本训练的Transformen架构模型,核心能力是理解和生成自然语言,主要服务于文本生成场景
- 聊天模型:是应用范畴的细分,是专为对话场景优化的LLMs,核心能力是模拟人类对话的轮次交互,主要服务于聊天场景
- 文本嵌入模型:文本嵌入模型接收文本作为输入,得到文本的向量.
LangChain支持的三类模型,它们的使用场景不同,输入和输出不同,开发者需要根据项目需要选择相应。
我们所用的阿里云通义千问系列主要来自于:langchain_community包
LLM的使用
-
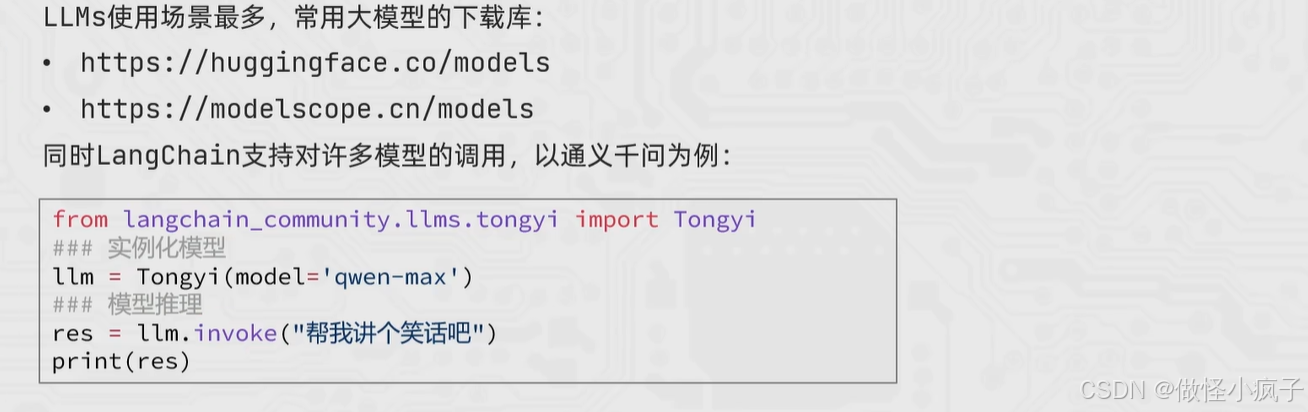
阿里云端访问 LLM
-
Ollama本地 访问

代码实现:
# 访问 阿里云大模型
from langchain_community.llms import Tongyi
# qwen3-max是聊天模型,而 qwen-max是大语言模型
model = Tongyi(model="qwen-max")
# 调用invoke 向模型提问
res = model.invoke(input="你是谁,能做什么?")
print(res)
# 访问本地模型
from langchain_ollama import OllamaLLM
# qwen3-max是聊天模型,而 qwen-max是大语言模型
model = OllamaLLM(model="qwen3:4b")
# 调用invoke 向模型提问
res = model.invoke(input="你是谁,能做什么?")
print(res)
- 流式输出
如果需要流式输出结果,需要将模型的invoke方法改为stream方法即可。
- invoke方法:一次型返回完整结果
- stream方法:逐段返回结果,流式输出
# from langchain_community.llms import Tongyi
#
# model = Tongyi(model="qwen-max")
#
# res = model.stream(input="你是谁,能做什么?")
#
# for chunk in res:
# print(chunk, end="", flush=True)
from langchain_ollama import OllamaLLM
model = OllamaLLM(model="qwen3:4b")
res = model.stream(input = "你是谁,能做什么?")
for chunk in res:
print(chunk, end=" ", flush=Ture)
这两个方法是新版LangChain(1.0版本后)中基于Runnable接口的通用核心方法。
绝大多数组件(如提示词模板、链、向量检索、工具调用等,后续学习)都支持这两个方法,这也是LangChain 设计的核心统一范式。
Chat Models(聊天模型)的使用
聊天消息包含下面几种类型,使用时需要按照约定传入合适的值:
- AIMessage:就是 AI 输出的消息,可以是针对问题的回答.(OpenAI库中的assistant角色)
- HumanMessage:人类消息就是用户信息,由人给出的信息发送给LLMs的提示信息,比如“实现一个快速排序方法”.(OpenAI库中的user角色
- SystemMessage:可以用于指定模型具体所处的环境和背景,如角色扮演等。你可以在这里给出具体的指示,比如“作为一个代码专家”,或者“返回json格式”.(0penAI库中的system角色)
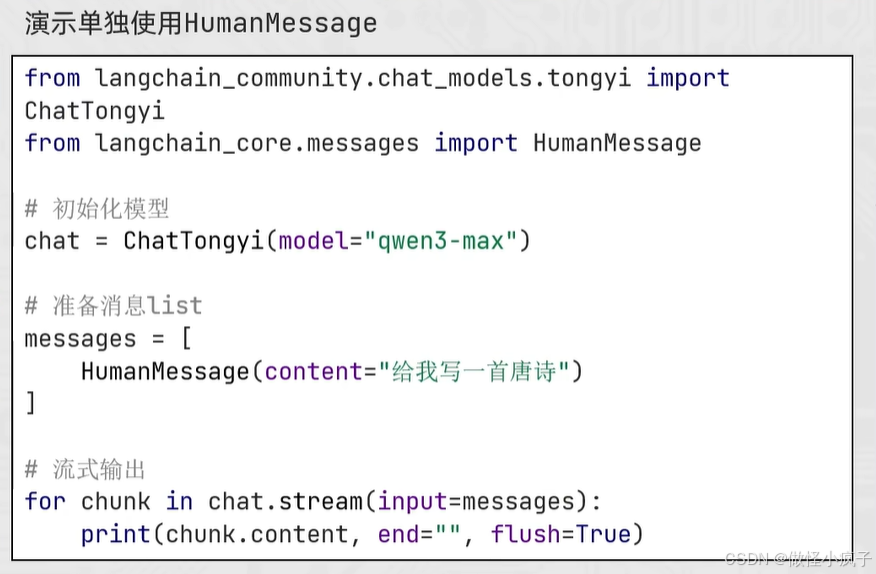
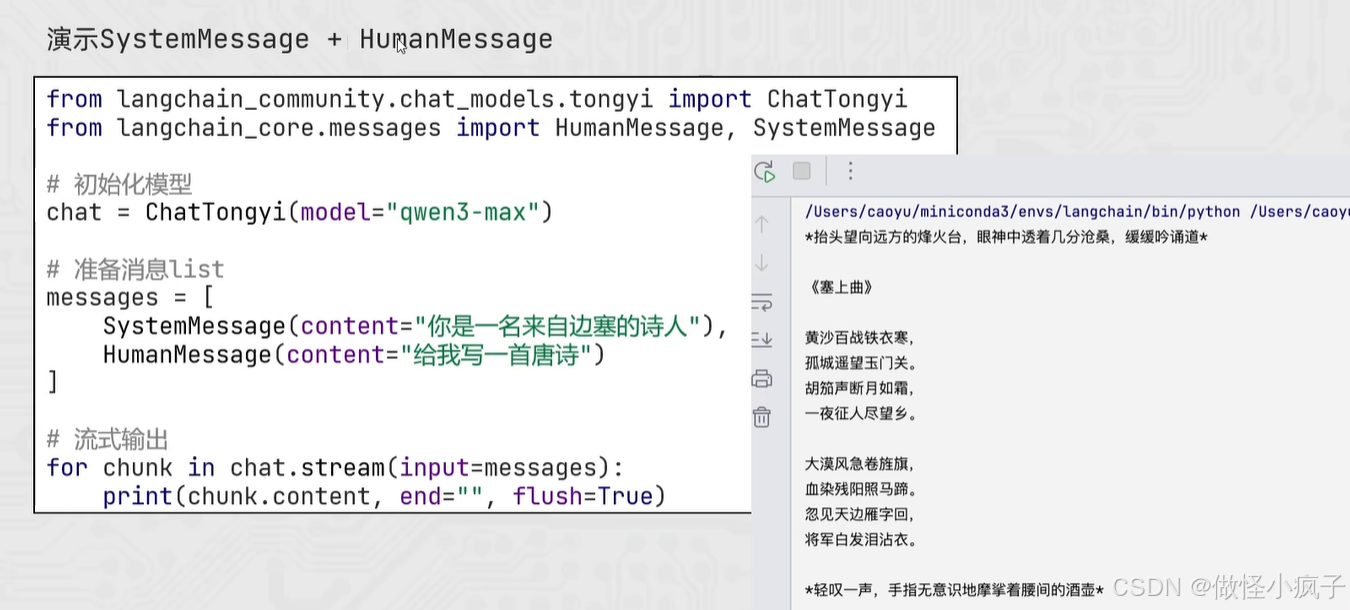
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 得到模型对象
model = ChatTongyi(model="qwen3-max")
# 准备消息列表
messages = [
SystemMessage(content="你是一个边塞诗人"),
HumanMessage(content="给我写一首唐诗"),
AIMessage(content="锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content="按照上一个回复的格式,再写一首唐诗")
]
# 嗲用stream流式执行
res = model.stream(input=messages)
# 循环迭代打印
for chunk in res:
# 需要加.content才能输出
print(chunk.content, end="", flush=True)
消息的简写形式
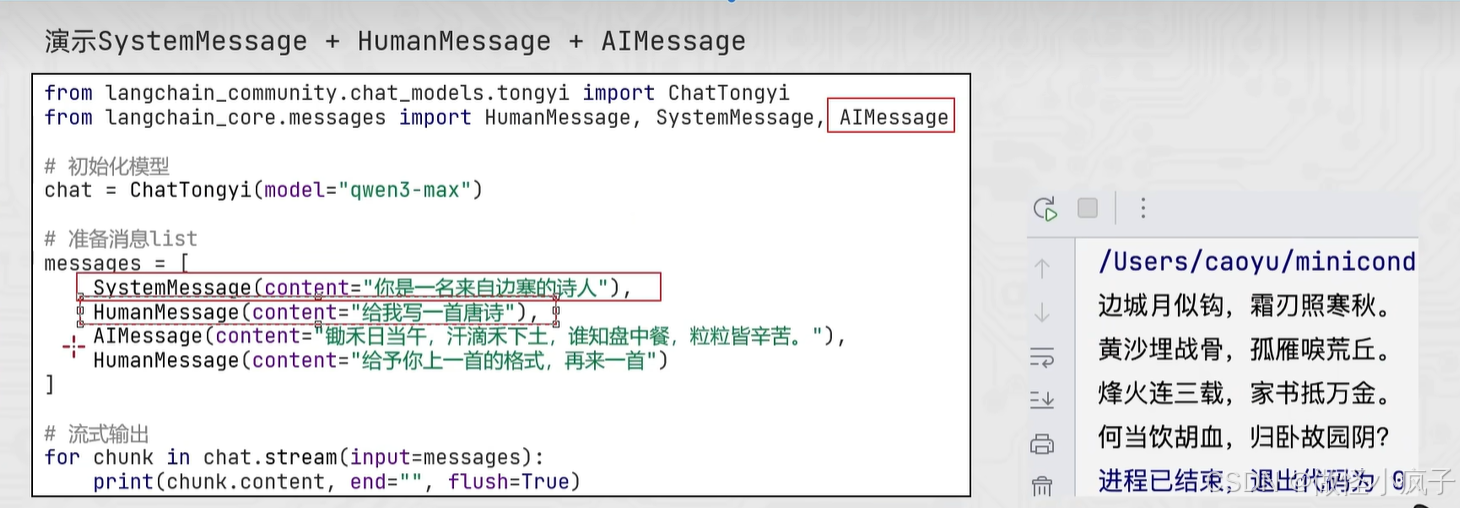
SystemMessage、HumanMessage、AIMessage可以有如下的简写形式: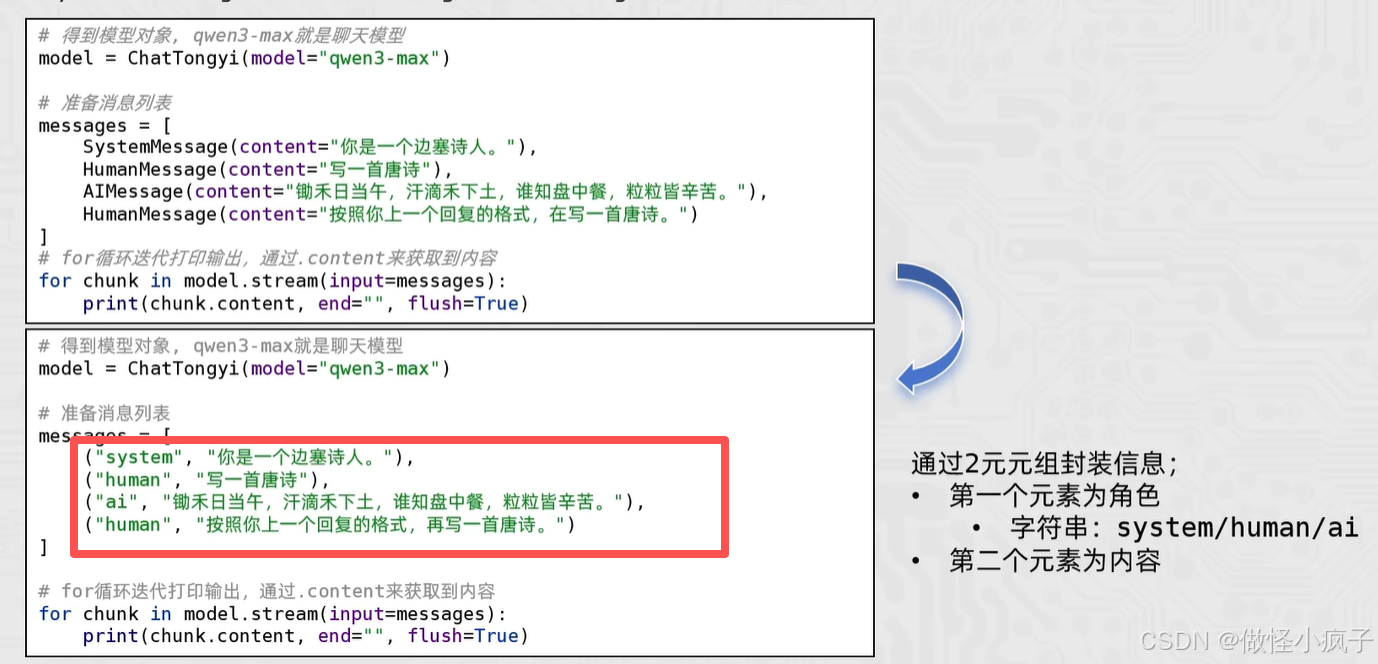
代码演示:
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen3-max")
messages = [
# ("角色", "内容")
("system", "你是一个边塞诗人"),
("human", "写一首唐诗"),
("ai", "锄禾日当午,汗滴禾下土,谁知盘中餐,粒粒皆辛苦"),
("human", "按照你上一个回复的格式,再写一首")
]
res = model.stream(input=messages)
for chunk in res:
print(chunk.content, end="", flush=True)
区别和优势在于:

LangChain调用嵌入模型
Embeddings Models嵌入模型的特点:将字符串作为输入,返回一个浮点数的列表(向量)。
在NLP中,Embedding的作用就是将数据进行文本向量化。
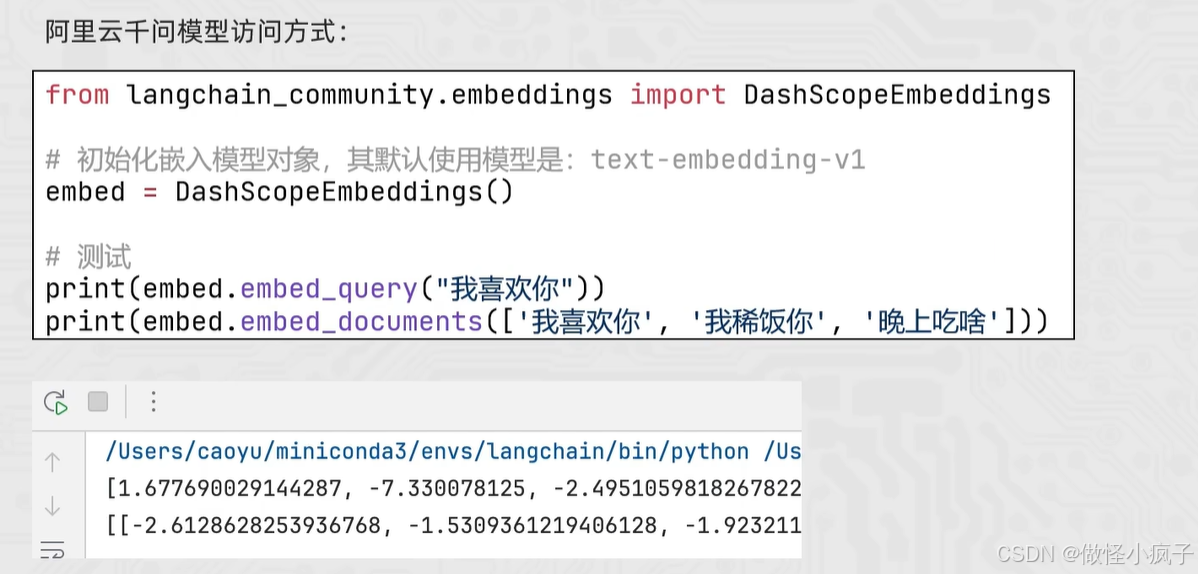
embed_query() :字符串转向量
embed_documents():批量转换
from langchain_community.embeddings import DashScopeEmbeddings
# 创建模型对象,不传model 默认用 text-embedding-v1
model = DashScopeEmbeddings()
# 不使用 invoke stream
# 使用 embed_query embed_documents
print(model.embed_query("我喜欢你"))
print(model.embed_documents(["我喜欢你", "我稀饭你", "晚上吃什么?"]))
总结
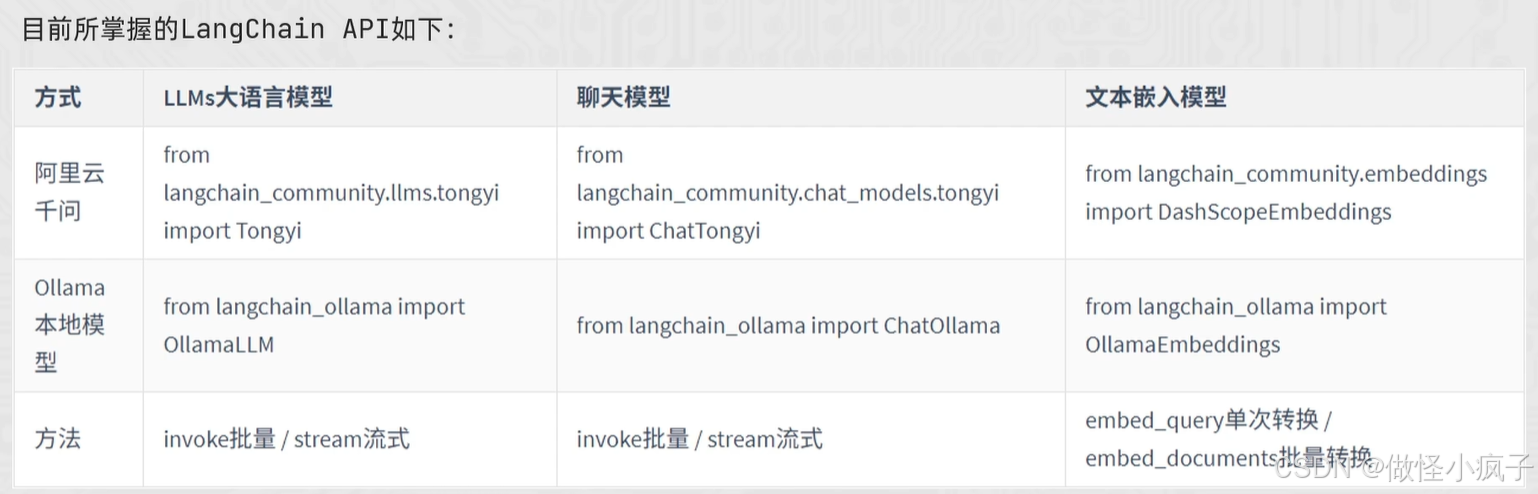
LangChain通用提示词模板
提示词优化在模型应用中非常重要,LangChain提供了PromptTemplate类,用来协助优化提示词。
PromptTemplate表示提示词模板,可以构建一个自定义的基础提示词模板,支持变量的注入,最终生成所需的提示词。
zero-shot提示词模板

from langchain_core.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
# 为啥用 PromptTemplate,可以加入链chain
prompt_template = PromptTemplate.from_template(
"我的邻居姓{lastname},刚生了{gender},你帮我起个名字,简单回答。"
)
model = Tongyi(model="qwen-max")
# 调用 .format方法注入信息即可
# prompt_text = prompt_template.format(lastname="张", gender="女儿")
# print(prompt_text)
# model = Tongyi(model="qwen-max")
# res = model.invoke(input=prompt_text)
#
# print(res)
# 基于chain的写法
chain = prompt_template | model
res = chain.invoke(input={"lastname": "张", "gender": "女儿"})
print(res)
以上是zero-shot,没有提示,完全信赖模型来回答问题。
基于PromptTemplate类可以得到提示词模板,支持基于模板注入变量得到最终提示词。
- zero-shot思想下,可以基于
PromptTemplate直接完成。 - few-shot思想下,需要更换为
FewShotPromptTemplate(后续学习)
PS:使用PromptTemplate还不如自己手动拼接字符串?
- 使用Template模板构建提示词,在大型工程中更容易做标准化模板
- Template模板类,支持LangChian框架的链式调用(Runnable接口,后续学习)
PromptTemplateFewShotPromptTemplate(后续学习)ChatPromptTemplate(后续学习)
Few-shot提示词模板
FewShotPromptTemplate的使用:
参数:
- examples:示例数据,list,内套字典 (示例数据的模板)
- example_prompt:示例数据的提示词模板 (向示例数据动态注入数据的列表)
- prefix:组装提示词,示例数据前内容
- suffix:组装提示词,示例数据后内容
- input_variables:列表,注入的变量列表
具体使用: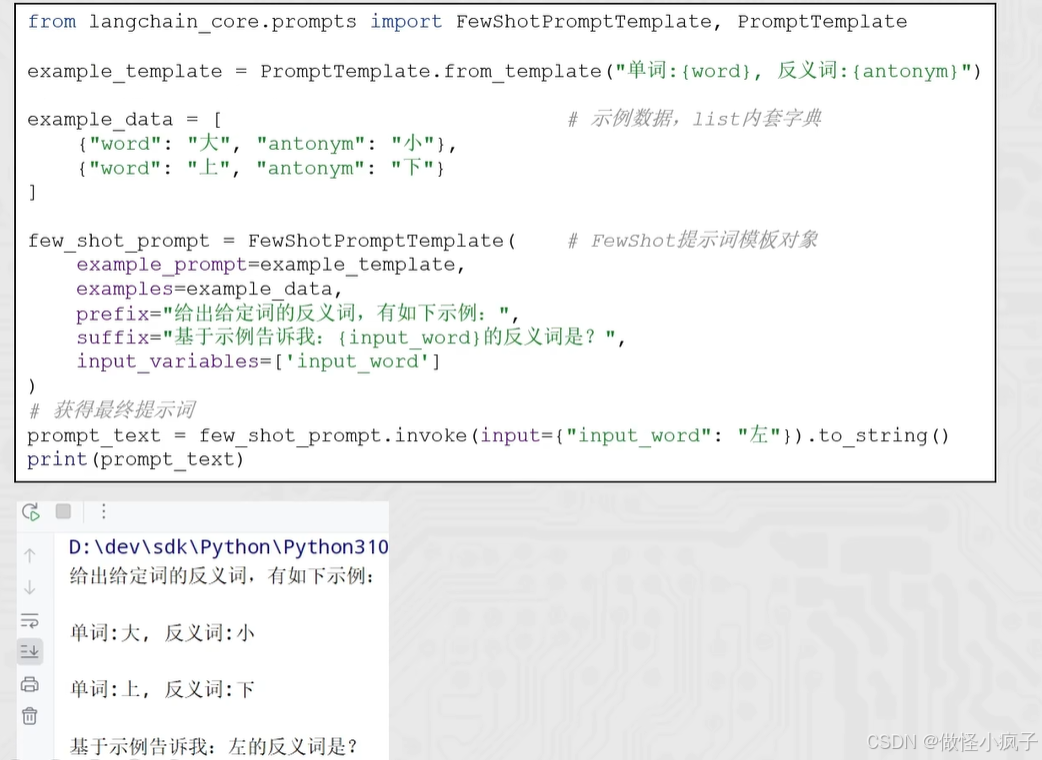
代码:
from sys import prefix
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_community.llms.tongyi import Tongyi
example_prompt = PromptTemplate.from_template("单词:{word},反义词:{antonym}")
example_data = [
{"word": "上", "antonym": "下"},
{"word": "大", "antonym": "小"},
]
few_shot_template = FewShotPromptTemplate(
example_prompt=example_prompt, # 示例数据的模板
examples=example_data, # 示例数据 (注入动态数据),list内套字典
prefix="告知我单词的反义词,我提供如下的示例", # 示例 前 内容
suffix="基于前面的示例,告知我,{input_word}的反义词是?", # 示例 后 提问内容
input_variables=["input_word"], # 声明在前缀和后缀中需要注入的变量名
)
prompt_text = few_shot_template.invoke(input={"input_word": "左"}).to_string()
print(prompt_text)
model = Tongyi(model="qwen-max")
res = model.invoke(input=prompt_text)
print(res)
模板类的format和invoke方法
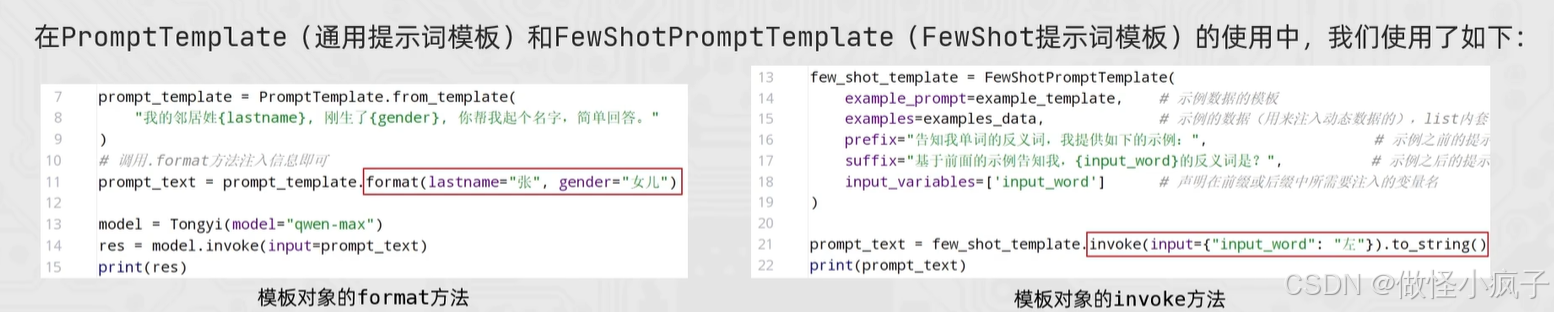
PromptTemplate、FewShotPromptTemplate、ChatPromptTemplate (后续学习)都拥有format和invoke这2类方法。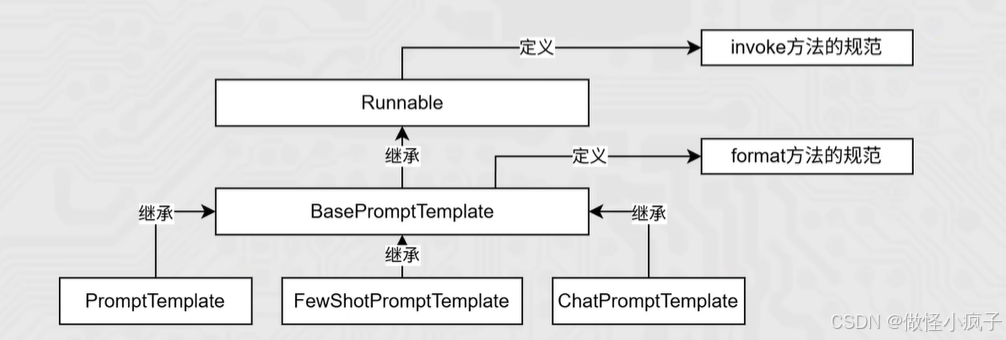
format和invoke的区别:
| 区别 | format | invoke |
|---|---|---|
| 功能 | 纯字符串替换,解析占位符生成提示词 | Runnable 接口标准方法,解析占位符生成提示词 |
| 返回值 | 字符串 | PromptValue 类对象 |
| 传参 | .format(k=v, k=v, ...) |
.invoke({"k":v, "k":v, ...}) |
| 解析 | 支持解析 {} 占位符 |
支持解析 {} 占位符和 MessagesPlaceholder 结构化占位符(对话中使用) |
代码演示:
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import FewShotPromptTemplate
from langchain_core.prompts import ChatPromptTemplate
"""
PromptTemplate ->StringPromptTemplate -> BasePromptTemplate -> RunnableSerializable -> Runnable
FewShotPromptTemplate -> StringPromptTemplate -> BasePromptTemplate -> RunnableSerializable -> Runnable
ChatPromptTemplate -> BaseChatPromptTemplate -> BasePromptTemplate -> RunnableSerializable -> Runnable
"""
template = PromptTemplate.from_template("我的邻居是:{lastname},最喜欢的是什么:{hobby}")
res = template.format(lastname="zzz", hobby="钓鱼")
print(res, type(res))
res2 = template.invoke({"lastname": "zzz", "hobby": "唱歌"})
print(res2, type(res2))
根据需要选择即可。
ChatPromptTemplate 的使用
PromptTemplate:通用提示词模板,支持动态注入信息。FewShotPromptTemplate:支持基于模板注入任意数量的示例信息。ChatPromptTemplate:支持注入任意数量的历史会话信息。
通过from_messages方法,从列表中获取多轮次会话作为聊天的基础模板
- PS:前面PromptTemplate类用的from_template仅能接入一条消息,而from_messages可以接入一个list的消息
例如:
历史会话信息并不是静态的(固定的),而是随着对话的进行不停地积攒,即动态的。
所以,历史会话信息需要支持动态注入。
- MessagePlaceholder作为占位符 —— 提供history作为占位的key
- 基于invoke动态注入历史会话记录(必须是invoke,format无法注入)
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
chat_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个边塞诗人, 可以作诗"),
MessagesPlaceholder("history"),
("human", "请再作一首唐诗"),
]
)
history_data = [
("human", "你来作一首唐诗"),
("ai", "床前明月光,疑是地上霜,举头望明月,低头思故乡"),
("human", "好诗,再来一首"),
("ai", "锄禾日当午,汗滴禾下锄,谁知盘中餐,粒粒皆辛苦"),
]
# StringPromptValue to_string()
prompt_text = chat_prompt.invoke({"history": history_data}).to_string()
# print(prompt_text)
model = ChatTongyi(model = "qwen3-max")
res = model.invoke(prompt_text)
print(res.content, type(res)) # AIMessage
Chain的基础使用
【将组件串联,上一个组件的输出作为下一个组件的输入】是LangChain 链(尤其是 | 管道链)的核心工作原理,这也是链式调用的核心价值**:实现数据的自动化流转与组件的协同工作**,如下:chain = prompt_template | model | xxx
核心前提:即Runnable子类对象才能入链(以及Callable、Mapping接口子类对象也可加入(后续了解用的不多))。
我们目前所学习到的组件,均是Runnable接口的子类,如下类的继承关系:
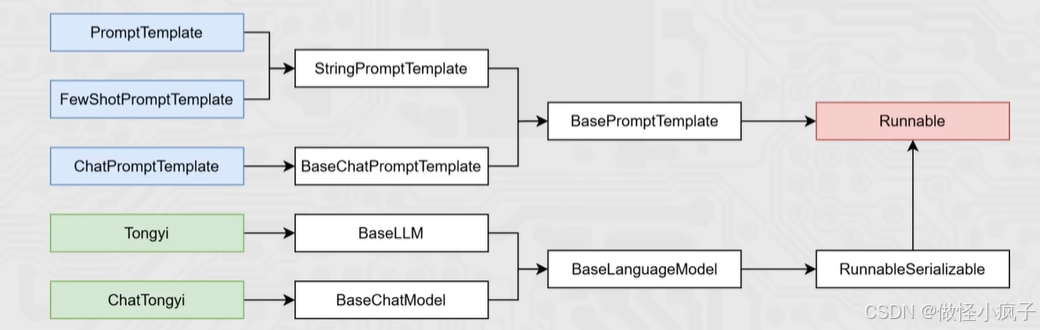

通过代码理解 链:
- 通过 | 链接提示词模板对象和模型对象
- 返回值chain对象是RunnableSerializable对象
- 是Runnable接口的直接子类
- 也是绝大多数组件的父类
- 通过invoke或stream进行阻塞执行或流式执行
组成的链在执行上有:上一个组件的输出作为下一个组件的输入的特性。
所以有如下执行流程:

from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
chat_prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个边塞诗人,可以作诗"),
MessagesPlaceholder("history"),
("user", "基于以上示例,帮我再写一首")
]
)
example_data = [
("human", "你来作一首唐诗"),
("ai", "床前明月光,疑是地上霜,举头望明月,低头思故乡"),
("human", "好诗,再来一首"),
("ai", "锄禾日当午,汗滴禾下锄,谁知盘中餐,粒粒皆辛苦"),
]
model = ChatTongyi(model="qwen3-max")
# 组成一个链
chain = chat_prompt | model # 可组织更多的组件,只要是Runnable的子类
# print(chain, type(chain)) # RunnableSequence
# 通过链去调用invoke/stream
# res = chain.invoke({"history": example_data})
# print(res.content)
# 通过stream流式输出
for chunk in chain.stream({"history": example_data}):
print(chunk.content, end="", flush=True)
LangChain中链是一种将各个组件串联在一起,按顺序执行,前一个组件的输出作为下一个组件的输入。
- 可以通过 "|” 符号来让各个组件形成链
- 成链的各个组件,需是Runnable接口的子类
- 形成的链是RunnableSerializable对象(Runnable接口子类)
- 可通过链调用invoke或stream触发整个链条的执行
| 运算符的重写
前文代码中: chain = chat_prompt_template | model,在语法上使用了|运算符的重写
在Python 中,运算符(如+、|)的行为由类的魔法方法决定。例如:
- a + b 本调用的是
a.__add__(b) - a | b 本质调用的是
a.__or__(b)
只需要自行实现类的__or__方法,即可对|符号的功能进行重写。
示例:
- 让alblc的代码得到一个自定义的类对象(类似列表即[a,b,c])
- 调用run方法依次输出a、b、c
- 我们需要重写 | 即
__or__方法
示例代码:
class Test(object):
def __init__(self, name):
self.name = name
def __or__(self, other):
return MySequence(self, other)
def __str__(self):
return self.name
class MySequence(object):
def __init__(self, *args):
self.sequence = []
for arg in args:
self.sequence.append(arg)
def __or__(self, other):
self.sequence.append(other)
return self
def run(self):
for i in self.sequence:
print(i)
if __name__ == '__main__':
a = Test("a")
b = Test("b")
c = Test("c")
d = Test("d")
e = Test("e")
d = a | b | c | d | e # __or__并没有被定义,想得到: [a, b, c] 列表
d.run()
print(d, type(d))
Runnable接口
LangChain 中的绝大多数核心组件都继承了 Runnable 抽象基类(位于 langchain_core.runnables.base)
代码:
chain = prompt | model
chain变量是RunnableSequence (RunnableSerializable子类)类型而得到这个类型的原因就是Runnable基类内部对__or__魔术方法的改写。
同时,在后面继续使用|添加新的组件,依旧会得到RunnableSequence,这就是链的基础架构。
from langchain_core.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
prompt_template = PromptTemplate.from_template("你是一个AI助手")
model = Tongyi(model="qwen3-max")
chain = prompt_template | model | prompt_template | model
print(type(chain)) # RunnableSequence
StrOutputParser 解析器
有如下代码,想要以第一次模型的输出结果,第二次去询问模型:

- 链的构建完全符合要求(参与的组件)
- 但是运行报错
Invalid input type <class 'langchain_core.messages.ai.AIMessage'>. Must be a PromptValue, str, or list of BaseMessages.
错误的主要原因:
- prompt的结果是
PromptValue类型,输入给了model - model的输出结果是:
AIMessage(不符合输入要求)
如上图 模型 输入 支持 PromptValue 或 str 或 Sequence[MessageLikeRepresentation]
解决:做类型转换,可以借助LangChain内置的解析器
- StrOutputParser 字符串输出解析器
StrOutputParser是LangChain内置的简单字符串解析器
AIMessage类型)
- 可以将AIMessage解析为简单的字符串,符合了模型invoke方法要求(可传入字符串,不接收AIMessage类型)
- 是Runnable接口的子类(可以加入链)

代码演示:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
parser = StrOutputParser()
model = ChatTongyi(model="qwen3-max")
prompt = PromptTemplate.from_template(
"我的邻居姓{lastname},生了个{gender},请起名,仅告知我名字即可无需其他内容"
)
chain = prompt | model | parser | model
res = chain.invoke({"lastname": '张', "gender": "女儿"})
print(res.content)
print(type(res))
我这里可能是由于版本不一样的原因,res的类型为:<class 'langchain_core.messages.base.TextAccessor'>
StrOutputParser是LangChain内置的简单字符串解析器。
- 可以将AIMessage类型转换为基础字符串
- 可以加入chain作为组件存在(Runnable接口子类)
JsonOutputParser和多模型执行链

在前面我们完成了这样的需求去构建多模型链,不过这种做法并不标准,因为:上一个模型的输出,没有被处理就输入下一个模型。
正常情况下我们应该有如下处理逻辑:
即:上一个模型的输出结果,应该作为提示词模版的输入,构建下一个提示词,用来二次调用模型。
根据输出和输入的要求:
- 模型输出为:AIMessage类对象
- 提示词模板要求输入为:dict

所以,需要完成:将模型输出的AIMessage → 转为字典 → 注入第二个提示词模板中,形成新的提示词(PromptValue对象)
StrOutputParser → str —— 不满足
更换为JsonOutputParser (AIMessage → Dict(JSON))
使用JsonOutputParser完成多模型链:
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
first_template = PromptTemplate.from_template(
"我的邻居姓{lastname},生了个{gender},请帮忙起一个名字,按照JSON格式返回。" +
"key为name,value为起的名字,请严格遵守格式要求"
)
second_template = PromptTemplate.from_template(
"名字为{name},请解释其含义"
)
model = ChatTongyi(model="qwen3-max")
str_output_parser = StrOutputParser()
json_output_parser = JsonOutputParser()
# chain = first_template | model | json_output_parser # model 给出的AIMessage("xxx"),不能直接将 字符串 转为 json;需要修改提示词;
# 修改提示词,输出json之后,得到的 AIMessage("{"name": "xxx"}")
chain = first_template | model | json_output_parser | second_template | model | str_output_parser
# res = chain.invoke({"lastname": "张", "gender": "女儿"})
# print(res)
# print(type(res))
for chunk in chain.stream({"lastname": "张", "gender": "女儿"}):
print(chunk, end="", flush=True)
总结:
在构建链的时候要注意整体兼容性,注意前后组件的输入和输出要求。
- 模型输入:PromptValue或字符串或序列(BaseMessage, list、 tuple, str、 dict)
- 模型输出:AIMessage
- 提示词模板输入:要求是字典
- 提示词模板输出:PromptValue
- 对象StrOutputParser:AIMessage输入、str输出
- Json0utputParser:AIMessage输入、dict输出

RunnableLambda & 函数加入链

前文我们根据Json0utputParser完成了多模型执行链条的构建。
- 除了JsonOutputParser这类固定功能的解析器之外
- 我们也可以自己编写Lambda匿名函数来完成自定义逻辑的数据转换,想怎么转换就怎么转换,更自由。(想要完成这个功能,可以基于
RunnableLambda类实现。)
RunnableLambda类是LangChain内置的,将普通函数等转换为Runnable接口实例,方便自定义函数加入chain。
语法:
RunnableLambda(函数对象或lambda匿名函数)
使用示例:
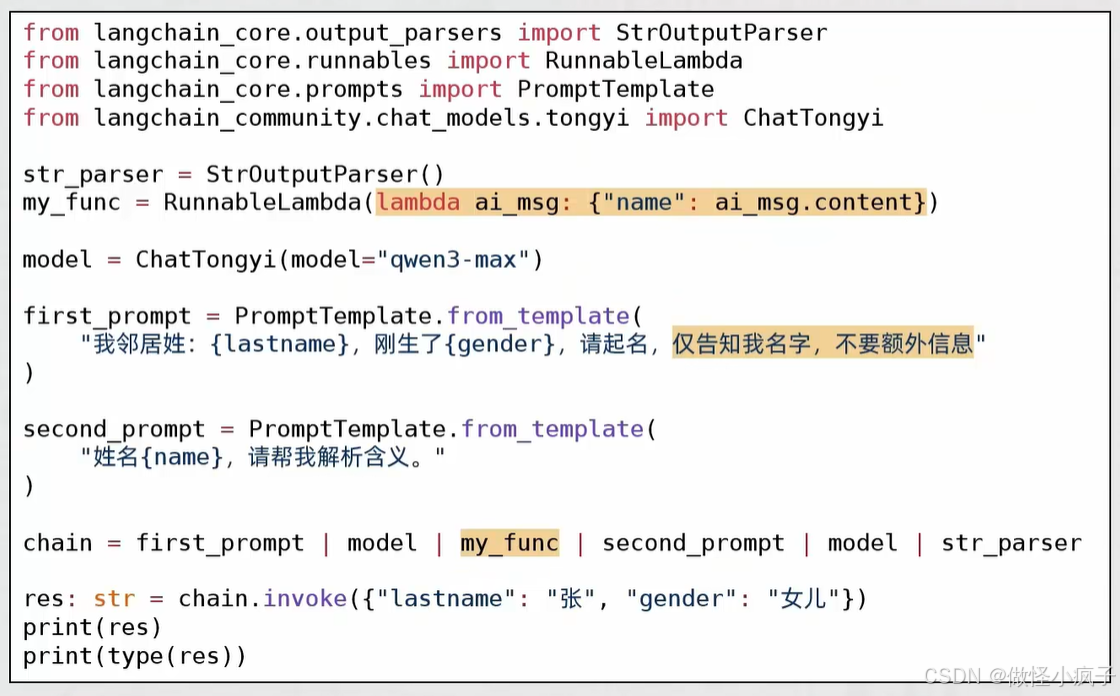
函数直接入链也可以:
跳过RunnableLambda类,直接让函数加入链也是可以的。
因为 Runnable接口在实现__or__的时候,支持Callable的实例
- 函数就是Callable的实例

如上代码示例,|符号(底层是调用or)组链,是支持函数加入的。其本质是将函数自动转换为RunnableLambda。
代码实现:
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
first_prompt = PromptTemplate.from_template(
"我邻居姓{lastname},生了个{gender},请帮我起一个名字,仅输出名字即可"
)
second_prompt = PromptTemplate.from_template(
"名字:{name},帮我解释其含义"
)
model = ChatTongyi(model="qwen3-max")
str_parser = StrOutputParser()
# 函数的入参:AIMessage 需要转为字典dict ({"name": "xxx"})
my_func = RunnableLambda(lambda ai_msg: {"name": ai_msg.content})
# chain = first_prompt | model | my_func | second_prompt | model | str_parser
chain = first_prompt | model | (lambda ai_msg: {"name": ai_msg.content}) | second_prompt | model | str_parser
# 本质是将函数自动转换为RunnableLambda
for chunk in chain.stream({"lastname": "李", "gender": "女儿"}):
print(chunk, end="", flush=True)
总结:如果像要在链中加入自定义函数,可以选择:
- 将函数封装入RunnableLambda类对象,其是Runnable接口实例,可以直接入链
- 直接将函数入链,函数会自动转换为RunnableLambda
对象
LangChain——History
Memory临时记忆
如果想要封装历史记录,除了自行维护历史消息(提示词模板)外,也可以借助LangChain内置的历史记录附加功能。
LangChain提供了History功能,帮助模型在有历史记忆的情况下回答。
- 基于
RunnableWithMessageHistory在原有链的基础上创建带有历史记录功能的新链(新Runnable实例) - 基于
InMemoryChatMessageHistory为历史记录提供内存存储(临时用) —— 临时存储

理解完整代码:
主要实现:多会话上下文记忆
- 不同session_id对应独立对话历史,互不干扰
- 每次调用时自动把历史消息注入提示词,让模型能“记住”之前说过的话
- 适合做客服机器人、对话助手等需要上下文理解的场景。
代码实现:
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import InMemoryChatMessageHistory
model = ChatTongyi(model="qwen3-max")
# prompt_template = PromptTemplate.from_template(
# "你需要根据会话历史回应用户问题。对话历史:{chat_history},用户提问:{input},请回答。"
# )
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你需要根据会话历史回应用户问题"),
MessagesPlaceholder("chat_history"),
("human", "请回答下面问题:{input}")
]
)
str_parser = StrOutputParser()
def print_prompt(prompt):
print("="*20, prompt.to_string(), "="*20)
return prompt
base_chain = prompt_template | print_prompt | model | str_parser
# 实现通过会话ID获取InMemoryChatMessageHistory 类对象
store = {} # key就是session_id,value就是 InMemoryChatMessageHistory
def get_history(session_id):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 创建一个新的链,对原有链1增强功能:自动附加历史消息
conversation_chain = RunnableWithMessageHistory(
base_chain, # 被增强的原有链
get_history, # 通过会话IC获取InMemoryChatMessageHistory
input_messages_key="input", # 表示用户输入在模板中的占位符
history_messages_key="chat_history" # 历史消息在模板中的占位符
)
if __name__ == '__main__':
# conversation_chain.invoke({"input": "小明有两只猫"})
# Missing keys ['session_id'] in config['configurable'] Expected keys are ['session_id'].When using via .invoke() or .stream(), pass in a config; e.g., chain.invoke({'input': 'foo'}, {'configurable': {'session_id': '[your-value-here]'}})
# 没有session_id,所以会报错
# 固定格式,添加 LangChain的配置,为当前程序配置所属的session_id
session_config = {
"configurable": {
"session_id": "user_0001"
}
}
res = conversation_chain.invoke({"input": "小明有两只猫"}, session_config)
print("第1次执行:", res)
res = conversation_chain.invoke({"input": "小红有5只狗"}, session_config)
print("第2次执行:", res)
res = conversation_chain.invoke({"input": "一共有几只宠物"}, session_config)
print("第3次执行:", res)
代码程序对会话记录是临时存储的 —— 再次运行就会丢失之前的会话。
RunnableWithMessageHistory是LangChain内Runnable接口的实现,主要用于:
- 创建一个带有历史记忆功能的Runnable实例(链)
它在创建的时候需要提供一个BaseChatMessageHistory的具体实现(用来存储历史消息)
InMemoryChatMessageHistory可以实现在内存中存储历史
额外的,如果想要在invoke或stream执行链的同时,将提示词print出来,可以在链中加入自定义函数实现。
- 注意:函数的输入应原封不动返回出去,避免破坏原有业务,仅在return之前,print所需信息即可。
Memory长期会话记忆
—— FileChatMessageHistory
使用InMemoryChatMessageHistory仅可以在内存中临时存储会话记忆,一旦程序退出,则记忆丢失。(InMemoryChatMessageHistory 类继承自 BaseChatMessageHistory)
-
FileChatMessageHistory类实现,核心思路:- 基于文件存储会话记录,以session_id为文件名,不同session_id有不同文件存储消息
-
继承BaseChatMessageHitstory 实现如下3个方法:
add_messages: 同步模式,添加消息messages:同步模式,获取消息clear:同步模式,清除消息
如下代码,官方在BaseChatMessageHistory 类的注解中提供了一个基于文件存储的示例代码: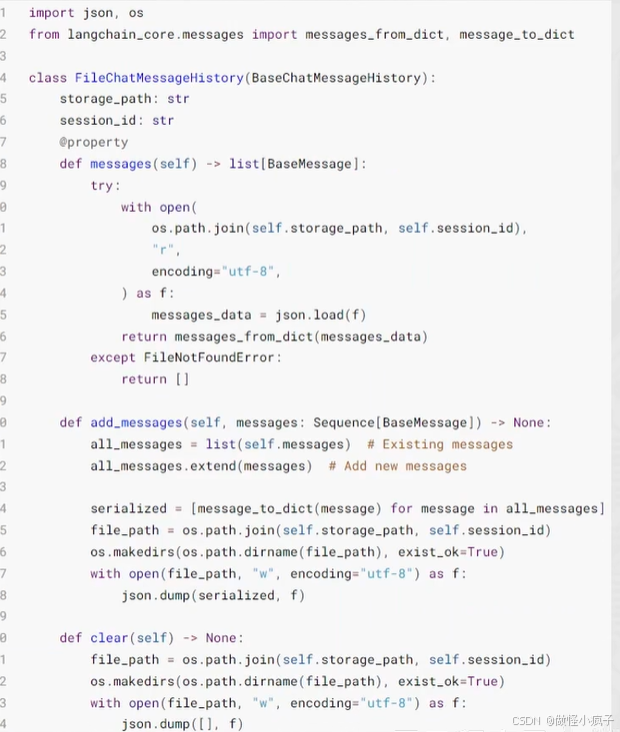
整体流程:
- 读取消息:
- 用
os.path.join拼接文件路径 →open打开文件 →json.load解析JSON → 转成 LangChain消息对象 - 文件不存在时返回空列表
- 用
- 添加消息:
- 先读取已有的消息 →
extend合并新消息 → 序列化为字典列表 →os.makedirs确保目录存在 →json.dump写入文件
- 先读取已有的消息 →
- 清空消息
- 打开文件,用
json.dump([], f)写入空列表,覆盖原有内容。
- 打开文件,用
代码实现:
import os
import json
from typing import Sequence
from langchain_community.chat_models import ChatTongyi
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.messages import message_to_dict, messages_from_dict, BaseMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
# message_to_dict : 单个消息对象(BaseMessage类实例) -> 字典
# messages_from_dict: [字典,字典,...] -> [消息,消息,...]
# BaseMessage类实例: AIMessage,HumanMessage,SystemMessage
class FileChatMessageHistory(BaseChatMessageHistory):
def __init__(self, session_id, storage_path):
self.session_id = session_id # 会话ID
self.storage_path = storage_path # 不同会话id的存储路径,所在的文件夹路径
# 完整的文件路径
self.file_path = os.path.join(self.storage_path, self.session_id)
# 确保文件夹是存在的
os.makedirs(os.path.dirname(self.file_path), exist_ok=True)
def add_messages(self, messages: Sequence[BaseMessage]) -> None:
# Sequence序列,类似list,tuple
all_messages = list(self.messages) # 已有的消息列表
all_messages.extend(messages) # 新的消息和已有的融合成一个list
# 将数据同步写入到本地文件中
# 类对象写入文件 -> 二进制
# 为了方便,将BaseMessage消息 转为字典,借助json模块以json字符串写入文件
# message_to_dict : 单个消息对象(BaseMessage类实例) -> 字典
# new_messages = []
# for message in all_messages:
# d = message_to_dict(message)
# new_messages.append(d)
new_messages = [message_to_dict(message) for message in all_messages]
# 将数据写入文件
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump(new_messages, f) # 将整体变成json写入文件中
@property # @property 装饰器将messages方法变成 成员属性用
def messages(self) -> list[BaseMessage]:
# 当前文件内: List[字典], 需要转为 list[BaseMessage]
try:
with open(self.file_path, "r", encoding="utf-8") as f:
messages_data = json.load(f) # 返回List[字典]
return messages_from_dict(messages_data)
except FileNotFoundError:
return []
def clear(self) -> None:
with open(self.file_path, "w", encoding="utf-8") as f:
json.dump([], f) # 清空文件
model = ChatTongyi(model="qwen3-max")
# prompt_template = PromptTemplate.from_template(
# "你需要根据会话历史回应用户问题。对话历史:{chat_history},用户提问:{input},请回答。"
# )
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你需要根据会话历史回应用户问题"),
MessagesPlaceholder("chat_history"),
("human", "请回答下面问题:{input}")
]
)
str_parser = StrOutputParser()
def print_prompt(prompt):
print("="*20, prompt.to_string(), "="*20)
return prompt
base_chain = prompt_template | print_prompt | model | str_parser
# 实现通过会话ID获取InMemoryChatMessageHistory 类对象
store = {} # key就是session_id,value就是 InMemoryChatMessageHistory
def get_history(session_id):
return FileChatMessageHistory(session_id, "./chat_history")
# 创建一个新的链,对原有链1增强功能:自动附加历史消息
conversation_chain = RunnableWithMessageHistory(
base_chain, # 被增强的原有链
get_history, # 通过会话IC获取InMemoryChatMessageHistory
input_messages_key="input", # 表示用户输入在模板中的占位符
history_messages_key="chat_history" # 历史消息在模板中的占位符
)
if __name__ == '__main__':
# conversation_chain.invoke({"input": "小明有两只猫"})
# Missing keys ['session_id'] in config['configurable'] Expected keys are ['session_id'].When using via .invoke() or .stream(), pass in a config; e.g., chain.invoke({'input': 'foo'}, {'configurable': {'session_id': '[your-value-here]'}})
# 没有session_id,所以会报错
# 固定格式,添加 LangChain的配置,为当前程序配置所属的session_id
session_config = {
"configurable": {
"session_id": "user_0001"
}
}
# res = conversation_chain.invoke({"input": "小明有两只猫"}, session_config)
# print("第1次执行:", res)
#
# res = conversation_chain.invoke({"input": "小红有5只狗"}, session_config)
# print("第2次执行:", res)
res = conversation_chain.invoke({"input": "一共有几只宠物"}, session_config)
print("第3次执行:", res)
LangChain —— Document loaders
Document loaders文档加载器:
文档加载器 提供了 一套标准接口,用于将不同来源(如CSV、PDF 或 JSON等)的数据读取为LangChain的文档格式。这确保了无论数据来源如何,都能对其进行一致性处理。
文档加载器(内置或自行实现)需实现BaseLoader接口。
Class Document,是LangChain内文档的统一载体,所有文档加载器最终返回此类的实例。
一个基础的Document类实例,基于如下代码创建:
from langchain_core.documents import Document
document = Document(
page_content = "Hello, world!", metadate={"source": "https://example.com"}
)
可以看到,Document类其核心记录了:
- page_content:文档内容
- metadata:文档元数据(字典)
不同的文档加载器可能定义了不同的参数,但是其都实现了统一的接口(方法)。
- load():一次性加载全部文档
- lazy_load():延迟流式传输文档,对大型数据集很有用,避免内存溢出。
LangChain内置了很多文档加载器,主要学习下面三个文档加载器: - CSVLoader
- JSONLoader
- PDFLoader
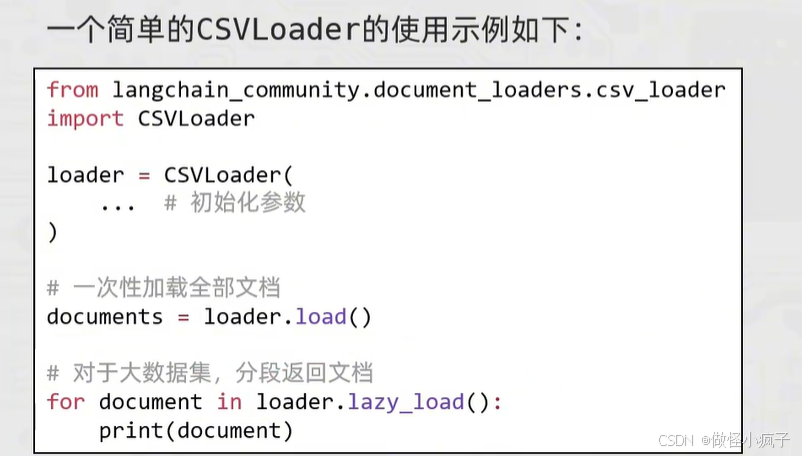
CSVLoader
简单使用:
自定义CSV文件的解析和加载:
代码实现:
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(
file_path="./data/stu.csv",
csv_args={
"delimiter": ",", # 指定分隔符
"quotechar": '"', # 指定带有分隔符文本的引号包围的是单引号还是双引号
# 如果数据原本有表头,就不要下面的fieldnames, 如果没有就需要使用
"fieldnames": ['name', 'age', 'gender', 'hobby']
},
encoding="utf-8", # 指定编码为UTF-8
)
# 批量加载 .load -> [Document, Document, ...]
# documents = loader.load()
# print(documents)
#
# for document in documents:
# print(type(document), document) # langchain_core.documents.base.Document
#
# 懒加载 .lazy_load()
for document in loader.lazy_load():
print(document)
LangChain内置了许多种类的文档加载器
- 文档加载器均继承于BaseLoader类
- 返回Document类型的对象
Load方法一次性批量加载(返回list内含Document对象),如内容过多可能list太大,出现内存溢出问题lazy_load方法会得到生成器对象,可用for循环依次获取单个Document对象,适用于大文档避免内存存不下。
CSVLoader用于加载CSV文件,加载成功得到的即Document对象。
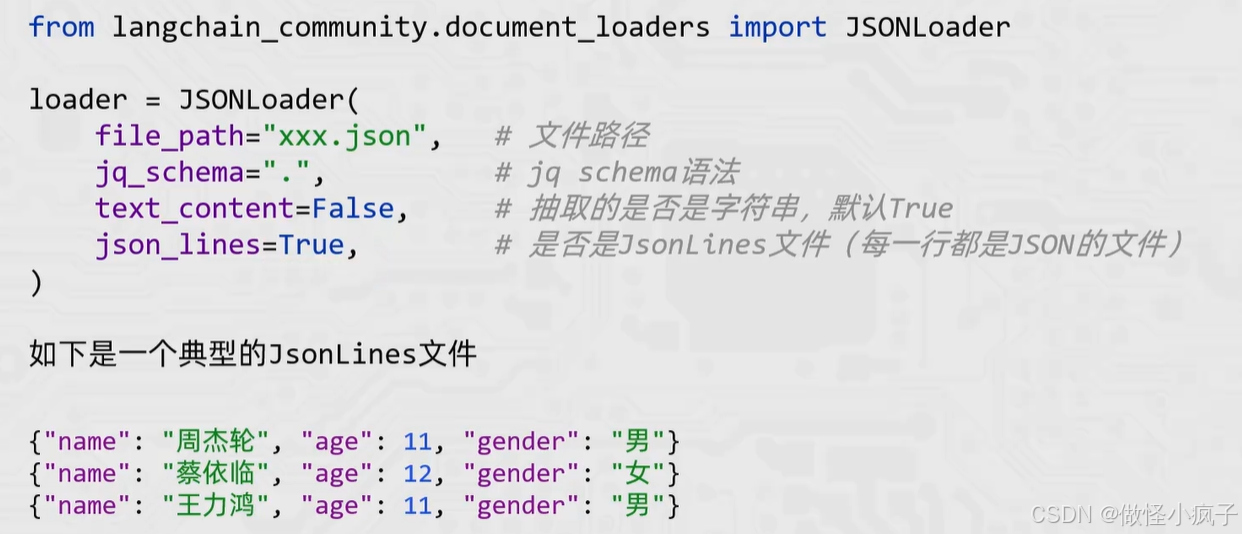
JSONLoader
JSONLoader用于将JSON数据加载为Document类型对象。使用JSONLoader需要额外安装:pip install jq
jq是一个跨平台的json解析工具,LangChain底层对JSON的解析就是基于jq工具实现的。
将JSON数据的信息抽取出来,封装为Document对象,抽取的时候依赖jq_schema语法。
-
jq的基本抽取规则:

-
使用JSONLoader 加载JSON文件:
代码演示:
from langchain_community.document_loaders import JSONLoader
# 抽取stu.json
# loader = JSONLoader(
# file_path="./data/stu.json",
# # jq_schema=".name" # 姓名
# # jq_schema=".other.addr" # 深圳
# jq_schema=".",
# text_content=False, # 告知 JSONLoader 抽取的内容不是字符串
# )
#
# document = loader.load()
#
# print(document)
#
# loader = JSONLoader(
# file_path="./data/stus.json",
# # jq_schema=".[].name",
# jq_schema=".[1].name",
# text_content=False, # 告知 JSONLoader 抽取的内容不是字符串
# )
#
# document = loader.load()
#
# print(document)
loader = JSONLoader(
file_path="./data/stu_json_lines.json",
jq_schema=".name",
text_content=False, # 告知 JSONLoader 抽取的内容不是字符串
json_lines=True # 告知JSONLoader,这是一个JSONLines文件
)
document = loader.load()
print(document)
JSONLoader依赖jq库,通过pip install jq安装。JS0NLoader使用jq的解析语法,常见如:
- .表示根、[]表示数组
- .name表示从根取name的值
- .hobby[1]表示取hobby对应数组的第二个元素
- .[]表示将数组内的每个字典(JSON对象)都取到
- .[].name表示取数组内每个字典(JSON)对象的name对应的值
JS0NLoader初始化有4个主要参数:
- fie_path:文件路径,必填
- jq_schema:jq解析语法,必填
- text_content:抽取到的是否是字符串,默认True,非必填
- json_lines:是否是JsonLines文件,默认False,非必填;JsonLines文件:每一行都是一个独立的字典(Json对象)
TextLoader和文档分割器
作用:读取文本文件(比如.txt),将全部内容放入一个Document对象中
如果文档很大,加载到一个Document对象中并不合适 —— 使用分割器
RecursiveCharacterTextSplitter,递归字符文本分割器,主要用于按自然段落分割大文档。是LangChain官方推荐的默认字符分割器。
它在保持上下文完整性和控制片段大小之间实现了良好平衡,开箱即用效果佳。
- 基于文本的自然段落分割大文档为小文档
- 可以指定小文档的最大字符数、重叠字符数
- 可以手动指定段落划分的依据(符号)以及字符数量统计函数
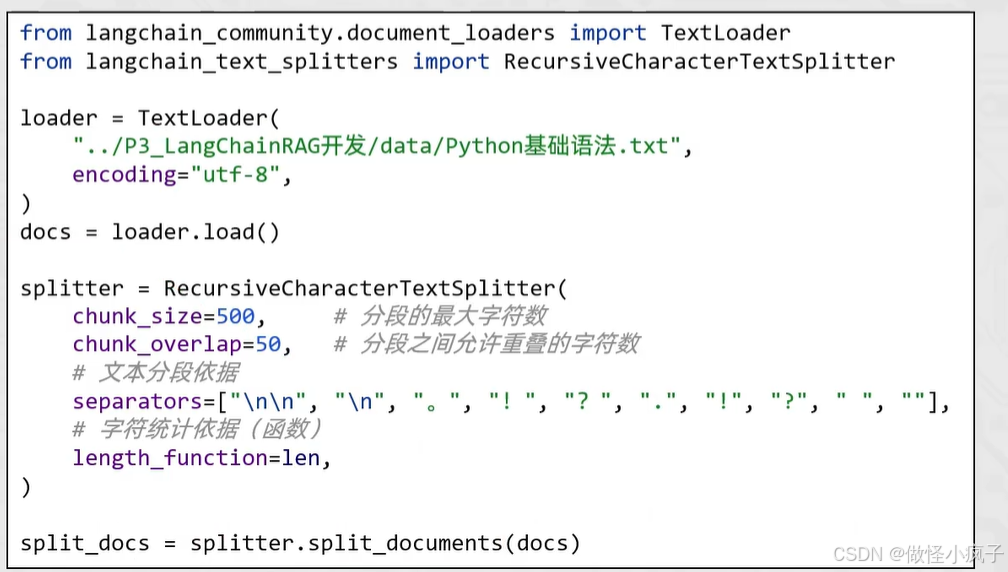
代码实现:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader(
"./data/Python基础语法.txt",
encoding="utf-8"
)
document = loader.load() # [Document]
print(document)
print(len(document))
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 分段的最大字符数
chunk_overlap=50, # 分段之允许重叠字符数
# 文本自然段落分割的依据符号
separators=["\n\n", "\n", "。", "?", "!", ".", "!", "?", " ", ""],
length_function=len
)
split_doc = splitter.split_documents(document)
print(len(split_doc))
for doc in split_doc:
print("="*20)
print(doc)
PyPDFLoader
LangChain内支持许多PDF的加载器,我们选择其中的PyPDFLoader使用。PyPDFLoader加载器,依赖PyPDF库,所以,需要安装它:pip install pypdf
PyPDFLoader使用还是比较简单的,如下代码即可快速加载PDF中的文字内容了:
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
# file_path="./data/pdf1.pdf",
file_path="./data/pdf2.pdf",
mode="single", # 默认是page模式,每个页面形成一个Document文档对象。single模式:不管有多少页,只返回一个Document文档对象
password="itheima" # pdf2文件需要密码
)
i = 0
for doc in loader.load():
i += 1
print(doc)
print("="*20, i)
VectorStores向量存储
基于LangChain的向量存储,存储嵌入数据,并执行相似性搜索。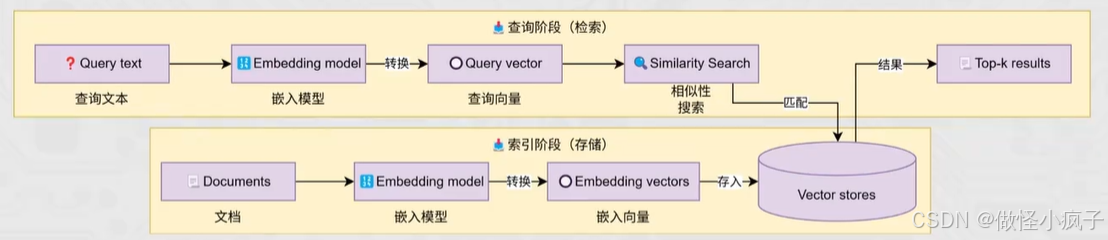
如图,这是一个典型的向量存储应用,也即是典型的RAG流程。
这部分开发主要涉及到:
- 如何文本转向量(前面已经学习)
- 创建向量存储,基于向量存储完成:(LangChain为向量存储提供了统一接口)
- 存入向量 ->
add_documents - 删除向量 ->
delete - 向量检索 ->
similarity_search
- 存入向量 ->
可以使用 内置的一个 InMemoryVectoreStore进行向量存储——内存中的
也可以使用外部数据库 Chroma数据库,来存储向量 —— 以文件形式存储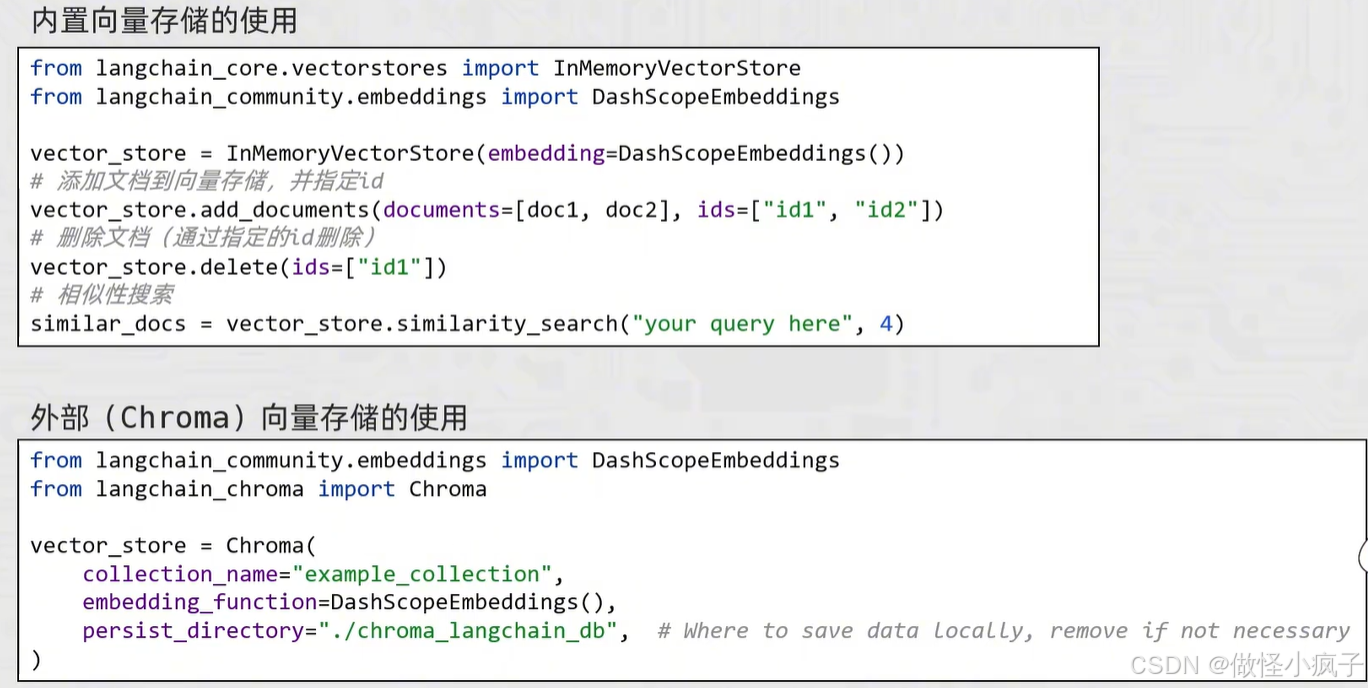
内置向量存储的使用:
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
# 内存存储
vector_store = InMemoryVectorStore(
embedding=DashScopeEmbeddings()
)
loader = CSVLoader(
file_path="./data/info.csv",
encoding="utf-8",
source_column="source" # 指定本条数据的来源 -> metadata={'source': '黑马程序员', 'row': 0}
)
documents = loader.load()
# print(documents[0])
# id1 id2 id3
# 向量存储的新增、删除、检索
vector_store.add_documents(
documents=documents, # 被添加的文档,要求list[Document]
ids= ["id" + str(i) for i in range(1, len(documents) + 1)] # 给添加的文档提供id(字符串) list[str]
)
# 删除
vector_store.delete(['id1','id3'])
# 检索 返回:list[Document]
result = vector_store.similarity_search(
"Python是不是简单易学呀",
3 # 检索的结果要几个
)
print(result)
外部数据据库 存储向量的使用:
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
from langchain_chroma import Chroma
# 使用 Chroma 向量数据库
# 确保 langchain-chroma 和 chromadb
# 内存存储
vector_store = Chroma(
collection_name="test", # 当前向量存储起名字。类似于数据库表名
embedding_function=DashScopeEmbeddings(),
persist_directory="./chroma_db", # 指定数据存放的文件夹
)
loader = CSVLoader(
file_path="./data/info.csv",
encoding="utf-8",
source_column="source" # 指定本条数据的来源 -> metadata={'source': '黑马程序员', 'row': 0}
)
documents = loader.load()
# print(documents[0])
# id1 id2 id3
# 向量存储的新增、删除、检索
vector_store.add_documents(
documents=documents, # 被添加的文档,要求list[Document]
ids= ["id" + str(i) for i in range(1, len(documents) + 1)] # 给添加的文档提供id(字符串) list[str]
)
# 删除
vector_store.delete(['id1','id3'])
# 检索 返回:list[Document]
result = vector_store.similarity_search(
"Python是不是简单易学呀",
3, # 检索的结果要几个
filter={"source": "黑马程序员"} # 可以进行过滤,我只要 来源是黑马程序员的数据
)
print(result)
基于向量检索构建提示词
基于之前学习 整个流程代码:
from langchain_community.chat_models import ChatTongyi
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}"),
("human", "用户提问:{input}")
]
)
# text-embedding-v4比默认模型 text-embedding-v1性能更好
vector = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4"))
# 准备资料
# add_texts: 传入列表 list[str]
vector.add_texts(["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来","跑步是很好的运动哦"])
input_text = "怎么减肥?"
# 检索向量库
result = vector.similarity_search(input_text, 2)
# print(type(result))
# 转成字符串
reference_text = "["
for doc in result:
reference_text += doc.page_content
reference_text += "]"
print(reference_text)
def prompt_print(prompt):
print("="*20, prompt.to_string(), "="*20)
return prompt
# chain
chain = prompt | prompt_print | model | StrOutputParser()
res = chain.invoke({"input": input_text, "context": reference_text})
print(res)
主要流程:
- 先通过向量存储检索匹配信息
- 将用户提问和匹配信息一同封装到提示词模板中提问模型
自己练习:
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_chroma import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_community.document_loaders import TextLoader
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_text_splitters import RecursiveCharacterTextSplitter
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}"),
("human", "用户提问:{input}")
]
)
loader = TextLoader(
file_path="./data/Python基础语法.txt",
encoding="utf-8",
)
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "?", "!", ".", "!", "?", " ", ""],
length_function=len
)
doc_split = splitter.split_documents(documents)
# print(type(doc_split))
vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4"))
vector_store.add_documents(
doc_split,
ids=["id"+str(i) for i in range(1, len(doc_split) + 1)],
)
text_input = "介绍一下Python中的计数器"
results = vector_store.similarity_search(
text_input,
2
)
# print(results)
# print(type(results))
reference_text = "["
for result in results:
reference_text += result.page_content
reference_text += "]"
# print(reference_text)
# print(type(reference_text))
chain = prompt | model | StrOutputParser()
# res = chain.invoke({"input": text_input, "context": reference_text})
res = chain.invoke({"input": text_input, "context": reference_text})
print(res)
RunnablePassthrough的使用
如何让向量检索 加入链? —— 使用RunnablePassthrough类
代码实现:
from langchain_community.chat_models import ChatTongyi
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}"),
("human", "用户提问:{input}")
]
)
# text-embedding-v4比默认模型 text-embedding-v1性能更好
vector = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4"))
# 准备资料
# add_texts: 传入列表 list[str]
vector.add_texts(["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来","跑步是很好的运动哦"])
input_text = "怎么减肥?"
# 把向量检索入链
# 由于 InMemoryVectorStore 不Runnable的接口实例,没法入链
# langchain中 向量存储对象,有个方法:as_retriever 可以返回一个Runnable 接口的子类实例对象
retriever = vector.as_retriever(search_kwargs={"k": 2}) # 匹配到 返回 几个匹配结果
# chain
# retriever
"""
retriever:
def invoke(
self, input: str, config: RunnableConfig | None = None, **kwargs: Any
) -> list[Document]:
输入:用户的提问 str
输出:向量库的检索结果 list
prompt:
def invoke(
self, input: dict, config: RunnableConfig | None = None, **kwargs: Any
) -> PromptValue:
输入: 用户的提问+向量库的检索结果 dict
输出:完整的提示词 PromptValue
retriever的输出不能直接 输入给prompt 并且用户的提问也会被丢失
—— 用户的输入同时给 retriever 和 prompt (RunnablePassthrough 和 retriever 分别接收 用户的提问)
invoke 触发,会找第一条链,第一条是retriever, 此时 接收的输入类型 和 retriever一致,也是str;RunnablePassthrough会占位,输入也会分给他
format_func: retriever返回了一个list,需要转为str
"""
# chain = retriever | prompt | model | StrOutputParser() # 错误
def prompt_print(prompt):
print("="*20, prompt.to_string(), "="*20)
return prompt
def format_func(docs):
if not docs:
return "无相关参考资料"
formatted_str = "["
for doc in docs:
formatted_str += doc.page_content
formatted_str += "]"
return formatted_str
# 字典也可以入链
chain = (
{"input": RunnablePassthrough(), "context": retriever | format_func} | prompt | prompt_print | model | StrOutputParser()
)
res = chain.invoke(input_text)
print(res)
练习:使用 外部存储 + 查询 + 全chain
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.runnables import RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate(
[
("system", "以我提供的已知参考资料为主,简洁和专业的回答用户问题。参考资料:{context}"),
("human", "用户提问:{input}")
]
)
input_text = "介绍下 Python中的 计数器"
loader = TextLoader(
file_path="./data/Python基础语法.txt",
encoding="utf-8"
)
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", "。", "?", "!", ".", "!", "?", " ", ""],
length_function=len
)
docs = splitter.split_documents(documents)
chroma = Chroma(
collection_name="test3",
embedding_function=DashScopeEmbeddings(model="text-embedding-v4"),
persist_directory="./chroma29_db"
)
chroma.add_documents(docs)
# 检索
# result = chroma.similarity_search(input_text)
retriever = chroma.as_retriever(search_kwargs={"k": 2})
def format_func(docs):
if not docs:
return "无参考资料"
formatted_str = "["
for document in docs:
formatted_str += document.page_content
formatted_str += "]"
return formatted_str
chain = (
{"input": RunnablePassthrough(), "context": retriever | format_func} | prompt | model | StrOutputParser()
)
res = chain.invoke(input_text)
print(res)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)