国产AI下半场开启?两大顶流模型4月同台竞技
2026年的国产大模型赛道,刚进入3月就迎来了重磅信号。据《白鲸实验室》独家爆料,DeepSeek V4与姚顺雨领衔的全新腾讯混元模型,均计划于2026年4月正式发布。这场由两位顶尖AI领军人物主导的同台竞技,不仅拉开了2026年国产大模型技术迭代的大幕,更折射出整个行业从参数竞赛向真实价值落地的核心转向。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
截至2025年12月,我国生成式人工智能用户规模已达6.02亿人,较2024年底增长141.7%,普及率达42.8%(来源:中国互联网络信息中心,2026)。用户规模的快速扩张,让市场对大模型的能力提出了更高要求——不再是榜单上的冰冷数字,而是真实场景中的稳定表现与生产力价值。而此次两大模型的提前预热,也早已在海外平台露出了蛛丝马迹。
OpenRouter神秘模型现身,国产新模型的提前预热
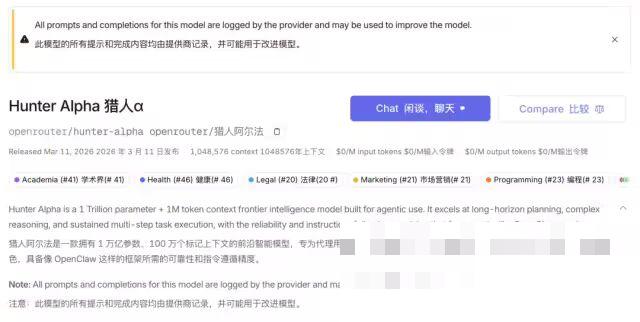
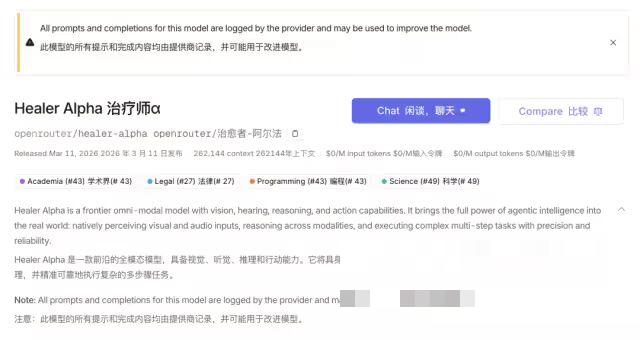
3月11日,全球AI API平台OpenRouter悄然上线了两款匿名模型——Hunter Alpha与Healer Alpha,迅速引发了全球AI社区的热议。两款模型均未公布背后的开发团队,但其参数规格、能力定位与系统提示词的细节,让社区普遍将其与即将发布的国产新一代大模型关联起来。
公开信息显示,Hunter Alpha定位为专为Agent场景打造的前沿智能模型,拥有1万亿参数规模与100万token的上下文窗口,核心优势集中在长期规划、复杂推理与多步骤任务执行,恰好匹配了当前AI行业对智能体框架的核心需求。而Healer Alpha则被定义为全模态模型,具备视觉、听觉、推理与行动能力,可原生感知多模态输入并完成复杂的具身智能任务(来源:OpenRouter官方页面,2026)。
更关键的细节在于,社区开发者捕捉到两款模型的系统提示词中,明确包含“严格遵守中国法律法规”的要求,模型也在对话中自称为“中国研发的AI模型”。这一特征直接排除了海外主流厂商的可能性,也让两款匿名模型被普遍视作即将发布的国产新模型的测试版本。
DeepSeek V4:从架构创新到算力自主的全面突破
作为DeepSeek创始人梁文锋打磨已久的重磅迭代产品,DeepSeek V4的技术路线,早已在团队近半年的公开研究中露出了清晰脉络。此次V4版本的核心迭代方向,锁定在长期记忆能力的突破上,这也是团队针对传统Transformer架构的核心瓶颈给出的解决方案。
2026年1月,梁文锋署名的论文《Conditional Memory via Scalable Lookup》首次提出“条件记忆”机制,为模型的长期记忆能力提供了底层架构支撑;2025年12月的《mHC:Manifold-Constrained Hyper-Connections》,则进一步完成了模型底层架构的优化,解决了Transformer架构在训练稳定性与长上下文处理上的痛点(来源:arXiv,2026)。除了核心架构的创新,DeepSeek V4还将补齐此前的能力短板,在代码能力跃升的同时,强化视觉内容处理与AI搜索能力,为此DeepSeek早在2025年就已与百度达成相关合作。
更值得关注的是,DeepSeek V4将深度适配国产芯片,有望成为首个完全跑在国产算力生态上的大模型,实现从技术架构到算力供给的全链路自主可控。而庞大的用户基础,也为新模型的迭代提供了充足的场景支撑——截至2025年2月9日,DeepSeek App累计下载量已超1.1亿次,周活跃用户规模最高接近9700万(来源:DeepSeek官方披露数据,2025)。

姚顺雨的新混元:告别榜单内卷,回归真实场景价值
与DeepSeek的底层架构创新路线不同,姚顺雨领衔的全新腾讯混元模型,走的是一条“去榜单化、重真实价值”的路线。据爆料,此次发布的新混元模型参数规模约为30B,与行业内动辄千亿、万亿的参数规模形成了鲜明反差,背后正是姚顺雨对大模型研发逻辑的重新定义。
作为AI Agent领域的标杆性人物,1998年出生的姚顺雨是清华姚班出身、普林斯顿大学博士,曾是OpenAI的核心研究成员,提出的ReAct框架成为AI智能体的教科书级理论,更在2025年以《The Second Half》一文提出“AI下半场应从解决问题转向定义问题”的核心观点,直指行业过度追逐榜单成绩的痛点。2025年12月,姚顺雨正式出任腾讯总办首席AI科学家,同时掌管AI Infra部与大语言模型部,全面主导混元模型的迭代。
在腾讯内部,姚顺雨明确提出团队“不要以打榜为导向”,直言过往混元模型过度追逐榜单成绩,将打榜语料放入训练集导致数据污染,最终造成模型“会答题却在真实场景表现不稳定”的问题。而此次新模型的研发,核心方向正是聚焦上下文学习与Agent可用性,2026年2月姚顺雨署名发布的CL-bench论文,也专门提出了面向上下文学习的全新评测基准,彻底跳出了传统榜单的评价体系(来源:arXiv,2026)。
参数竞赛落幕,国产大模型进入落地决胜期
从公开信息来看,4月的这场同台竞技,早已不是行业过去常见的参数规模竞赛。DeepSeek V4与新混元模型,选择了两条完全不同的技术路线,却指向了同一个行业命题:大模型如何真正走进生产环境,创造可落地的真实价值。
过去几年,国产大模型的迭代始终绕不开“参数攀比”,从百亿到千亿再到万亿参数,模型规模不断刷新纪录,但真实场景的落地效果却始终未能同步提升。IDC数据显示,2025年中国大模型市场规模约490亿元,预计2026年将突破700亿元,但截至2025年底,仅有超8万家中国企业完成了大模型的试点或生产部署(来源:IDC、赛迪顾问,2026)。这意味着,行业的核心矛盾,已经从“能不能做出大模型”,变成了“能不能用好大模型”。
DeepSeek的路线,是通过底层架构创新与算力自主,突破大模型的能力边界,同时补齐多模态、搜索等场景化能力;而腾讯混元的路线,则是通过重构评测体系,让模型从“为榜单优化”转向“为真实场景优化”,用更合理的参数规模实现更高的落地效率。两条路线的背后,是国产大模型行业从“追平海外”到“走出自己的路”的核心转变,也为行业的后续发展提供了两种完全不同的参考范式。
对于这场即将到来的国产大模型巅峰对决,你更期待哪一款模型的真实落地表现?
如果你有什么想要交流的,欢迎在评论区留下你的想法。
那么我们下一篇再见!
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
137261875.142%5Ev100%5Epc_search_result_base4&spm=1018.2226.3001.4187)👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)