打造超强知识 Agent:KARL 强化学习构建指南(保姆级教程),从入门到精通,收藏这一篇就够了!
一个基于GLM 4.5 Air微调的开源模型,在六项知识检索与推理任务上,以约三分之一的成本达到了Claude Opus 4.6同等水平的表现——这是Databricks最新发布的KARL系统交出的成绩单。在当前各家大模型厂商竞相堆叠参数和推理预算的背景下,KARL用强化学习证明了一条更经济的路径:与其让通用模型暴力搜索,不如教会模型高效地搜。
知识Agent面临的核心难题
论文将目标聚焦于一类被称为"grounded reasoning"(基于证据的推理)的任务——模型需要从外部文档集合中多步检索信息,并在收集到的证据基础上进行复杂推理。这类任务在金融、法律、医疗、制造等领域极具经济价值,因为企业依赖大量模型训练时从未见过的私有数据。
论文指出,相比数学或代码推理,学术界对grounded reasoning前沿能力的研究严重不足。现有的"深度研究"类agent依赖公开网络知识和黑盒搜索工具,其结果能否迁移到其他grounded reasoning任务并不明确。此外,不同场景所需的搜索能力差异巨大:约束驱动的实体搜索、跨文档报告综合、表格数值推理、穷举实体检索、技术文档的过程推理等,针对单一场景优化的系统在其他场景上毫无保证。
KARLBench:六种搜索能力的统一评测
为系统评估grounded reasoning能力,论文构建了KARLBench评测套件,涵盖六项任务,每项隔离一种独特能力:BrowseComp-Plus(约束驱动实体搜索,830题)、TREC-Biogen(跨文档报告综合,65题)、FinanceBench(长文档表格数值推理,150题)、QAMPARI(穷举实体搜索,1000题)、FreshStack(技术文档过程推理,203题),以及内部开发的PMBench(企业内部笔记的事实聚合,57题)。
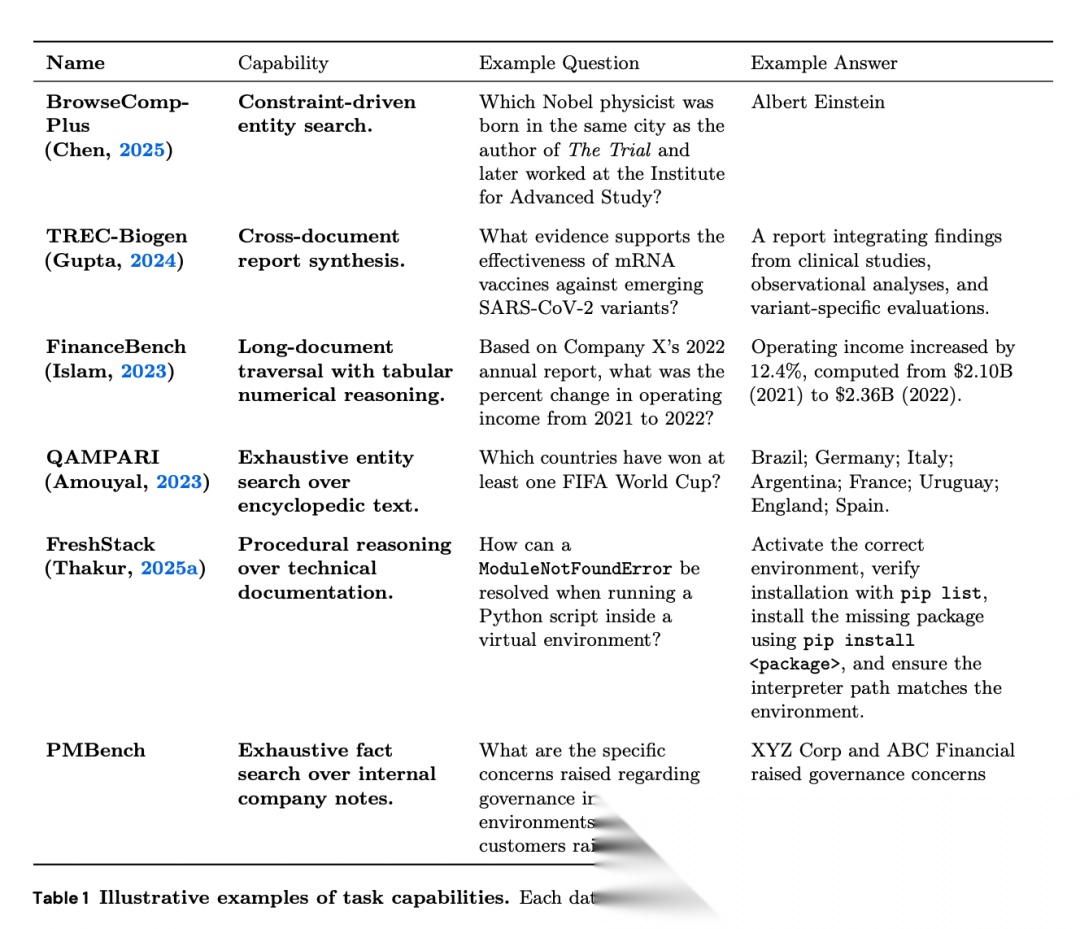
[Table 1: 任务能力示例] 每个数据集隔离一种独特的结构性挑战,从约束驱动的实体搜索到企业内部笔记的穷举事实搜索。
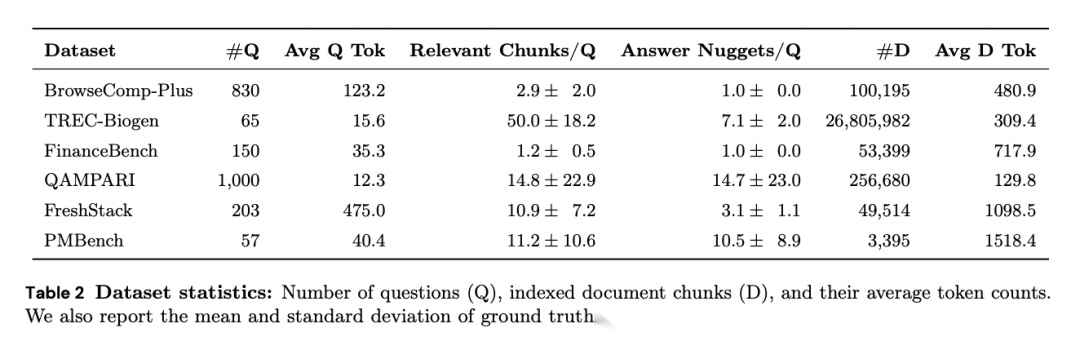
[Table 2: 数据集统计] 各评测集的问题数、索引文档块数及其平均token数,以及每个问题的平均相关块数和答案nugget数。
所有任务统一使用nugget-based completion评估框架,agent仅配备向量搜索这一单一工具,以隔离检索与推理能力本身。
训练方法:Agent式数据合成加离线强化学习
论文的训练流程分为三个核心环节。
第一步:Agent式训练数据合成。 论文开发了一个两阶段管道。Stage I中,合成agent通过向量搜索工具动态探索语料库,生成基于检索证据的问答对,再经去重agent过滤与评测集的重复项。Stage II中,多个Solver Agent独立尝试回答合成问题,论文根据经验通过率过滤掉过简(全对)和过难(全错)的样本,仅保留学习信号最丰富的中间难度数据。最后由Quality Filter Agent筛除歧义问题和错误标注。
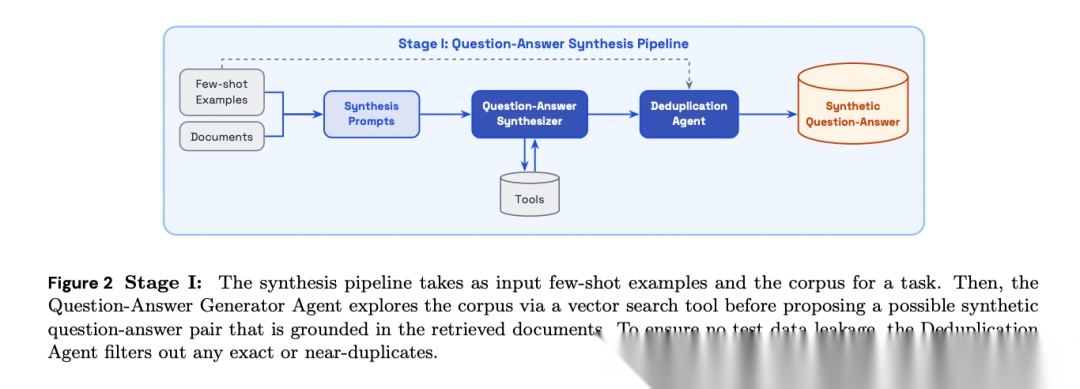
[Figure 2: Stage I合成管道] 问答生成agent探索语料库后提出合成问答对,去重agent过滤与测试数据的重复项。
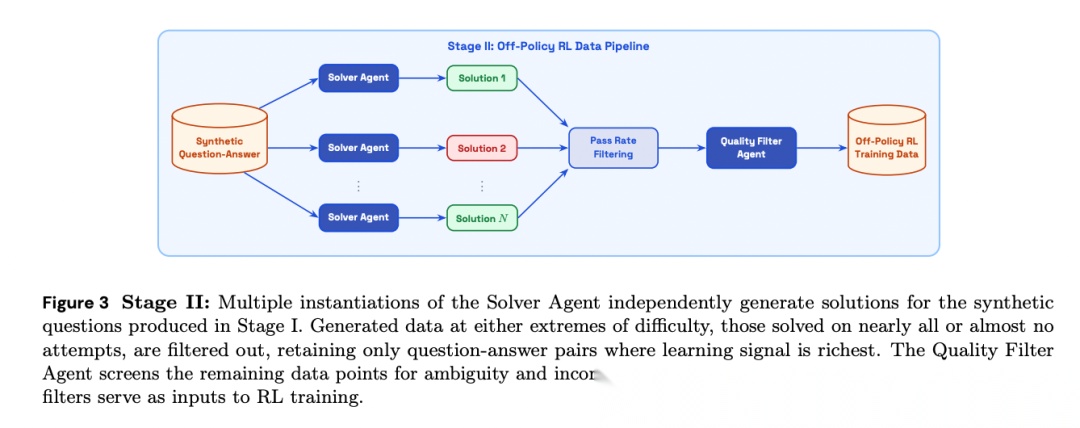
[Figure 3: Stage II求解管道] 多个Solver Agent独立生成解答,两端极值被过滤,Quality Filter Agent进一步筛除歧义和错误。
第二步:OAPL离线强化学习。 论文提出OAPL(Optimal Advantage-based Policy Optimization with Lagged Inference policy),一种基于大批量迭代离线RL的后训练范式。其核心思想是:给定参考策略生成的分组rollout,通过最小化一个关于最优优势函数的最小二乘回归损失来学习最优策略。这种设计天然是off-policy的,无需裁剪重要性权重、数据删除或路由器重放等在线GRPO训练大规模MoE模型时通常需要的启发式技巧。论文将压缩步骤也纳入RL训练,让模型端到端学习上下文管理。实验中最多执行3轮迭代训练。
第三步:多任务RL。 论文选择BrowseComp-Plus(深度搜索)和TREC-Biogen(广度搜索)作为分布内训练任务,简单地将两个任务的损失合并并平衡训练token数。与多专家蒸馏方案相比,多任务RL在分布外任务上展现出更好的泛化能力。
测试时计算:并行思考与价值引导搜索
论文探索了两种测试时计算TTC(test-time compute)策略。并行思考让模型生成N个独立rollout后,再由同一模型聚合为最终答案。聚合器不仅能从候选中选择,还能综合多个rollout生成更优答案——在PMBench上,5个并行rollout中有23.7%的情况下聚合答案优于任何单个候选。VGS(Value-Guided Search,价值引导搜索) 则训练一个小型价值模型(Qwen3-4B)预测部分rollout的未来成功概率,用于树搜索中的分支选择。
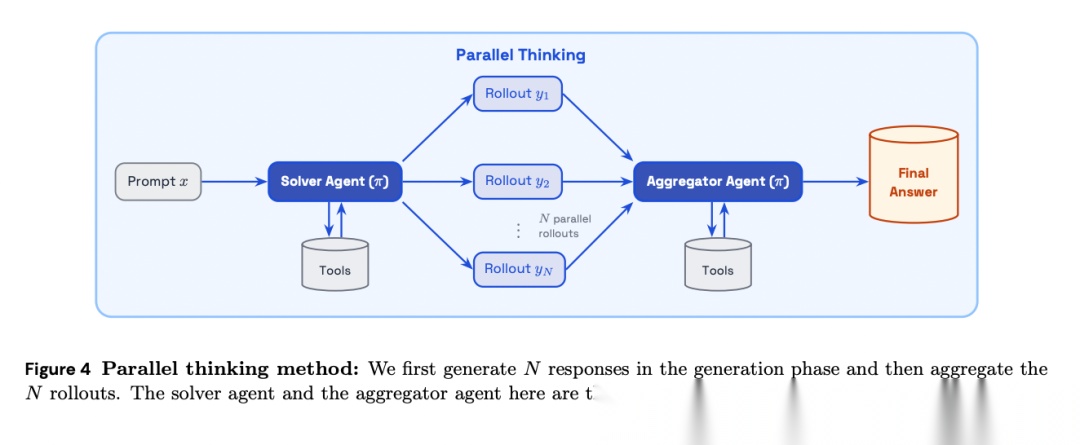
[Figure 4: 并行思考方法] 生成N个响应后聚合,solver agent和aggregator agent使用同一模型。
核心实验结果
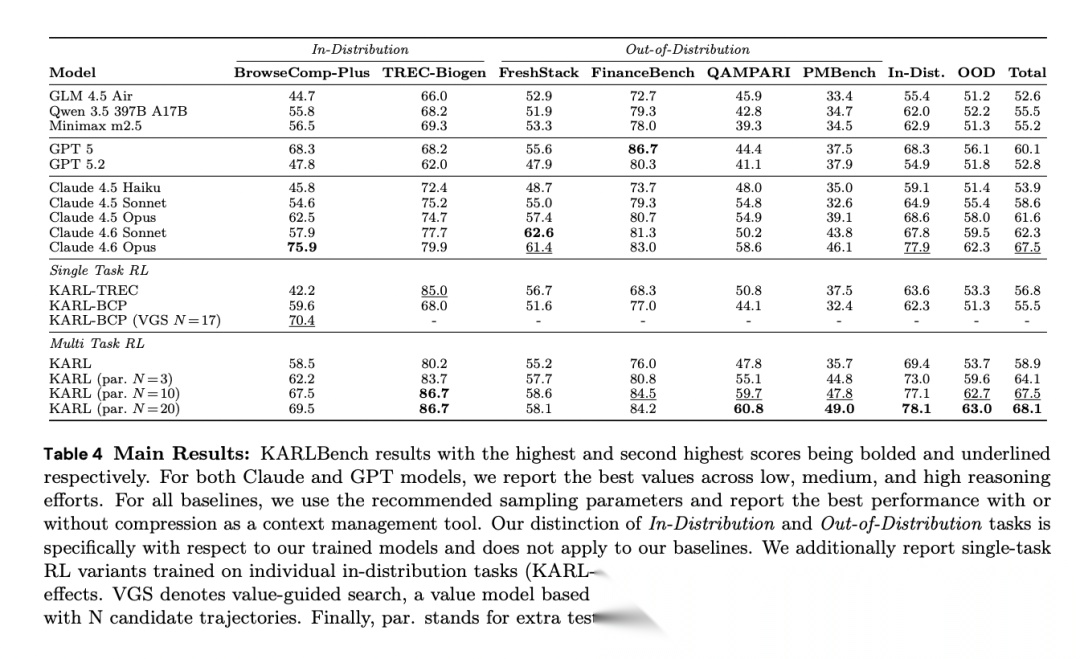
[Table 4: 主要结果] KARLBench上各模型表现,包括单任务RL变体、多任务RL及不同规模的并行思考。
论文以GLM 4.5 Air为基座模型。不使用任何测试时计算的KARL即达到Claude Sonnet 4.5高推理努力级别的水平。使用3个并行rollout时,KARL超越Sonnet 4.6;使用10个并行rollout时,KARL匹配最强模型Opus 4.6的表现(KARLBench总分67.5 vs. 67.5),而20个并行rollout进一步提升至68.1。
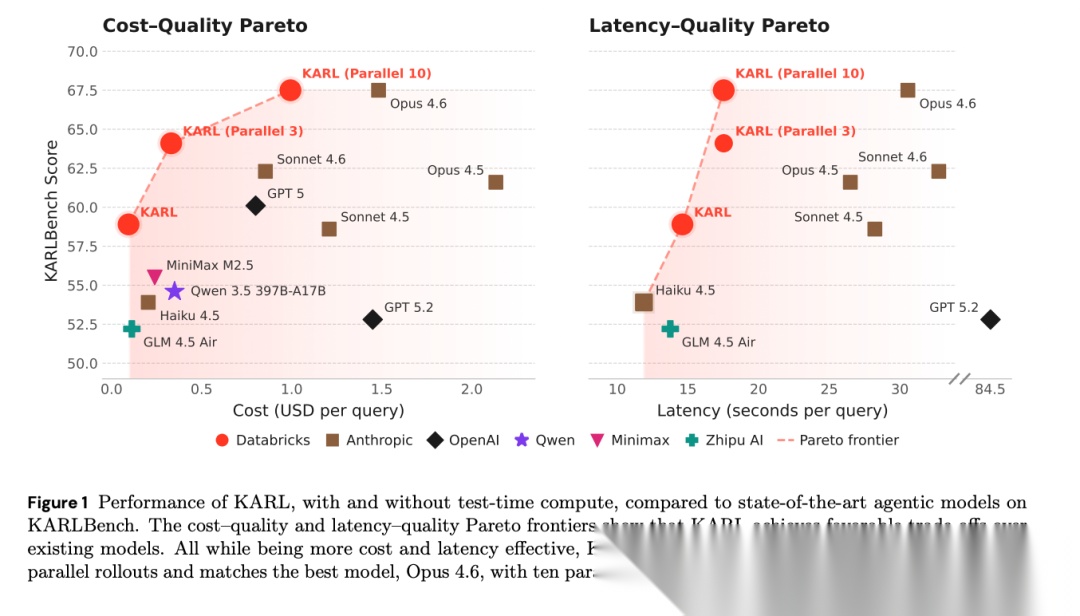
[Figure 1: 成本-质量与延迟-质量Pareto前沿] KARL在成本和延迟两个维度上定义了Pareto前沿。
在成本方面,单次调用KARL在所有55分以上模型中成本最低(低于$0.10/query)。匹配Opus 4.6质量时,KARL成本低约33%。更值得注意的是,KARL甚至比其基座模型GLM 4.5 Air更便宜,同时分数高出6分以上——RL让模型学会了更高效的搜索策略,用更少的步骤和token开销完成任务。延迟方面,匹配Opus 4.6时KARL延迟低约47%。
RL到底教会了模型什么
论文深入分析了RL训练对模型行为的影响。在BrowseComp-Plus合成数据上,RL训练后轨迹长度显著缩短,已解决问题的平均步数从51.1降至36.3。同时,模型的搜索多样性提升了37%(累计检索唯一文档数)。
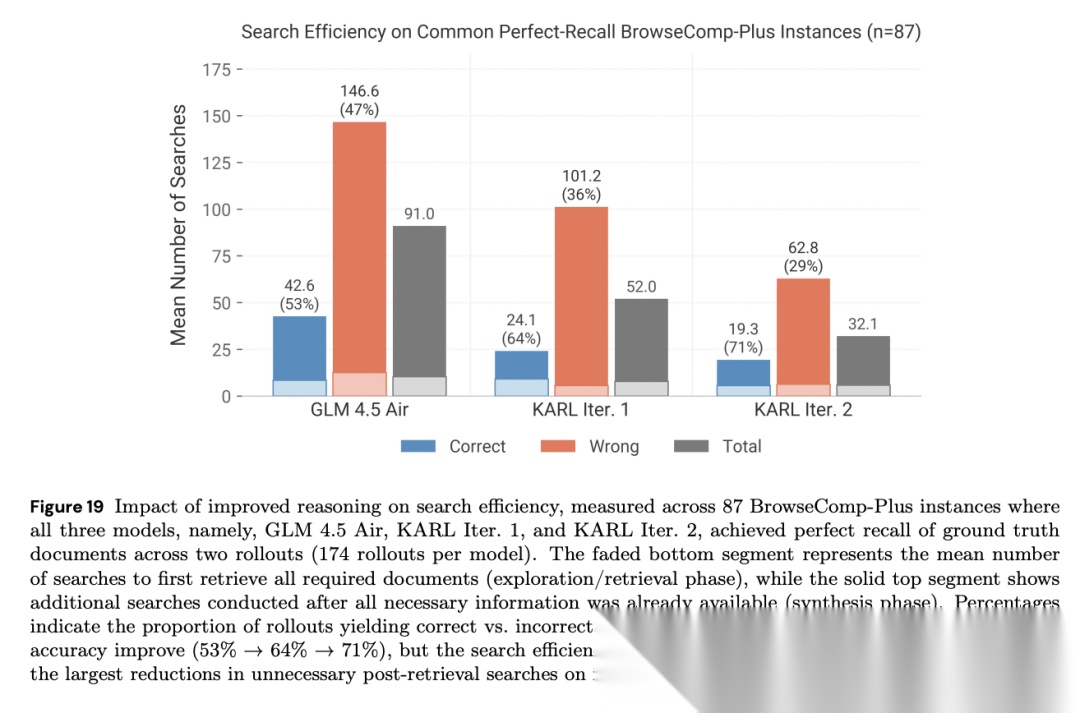
[Figure 19: 搜索效率提升] 在87个三个模型均实现完美召回的问题上,RL训练将不必要的后检索搜索从134.0次降至56.5次,同时准确率从53%提升至71%。
关于RL是否只是"锐化"基座模型已有能力这一问题,论文给出了明确证据:max@k在所有k值上均随训练迭代提升。训练后模型的max@1达到了基座模型max@8的水平,max@2已超过基座模型的max@16——这意味着训练后模型两次尝试就能解决基座模型十六次也解决不了的问题。
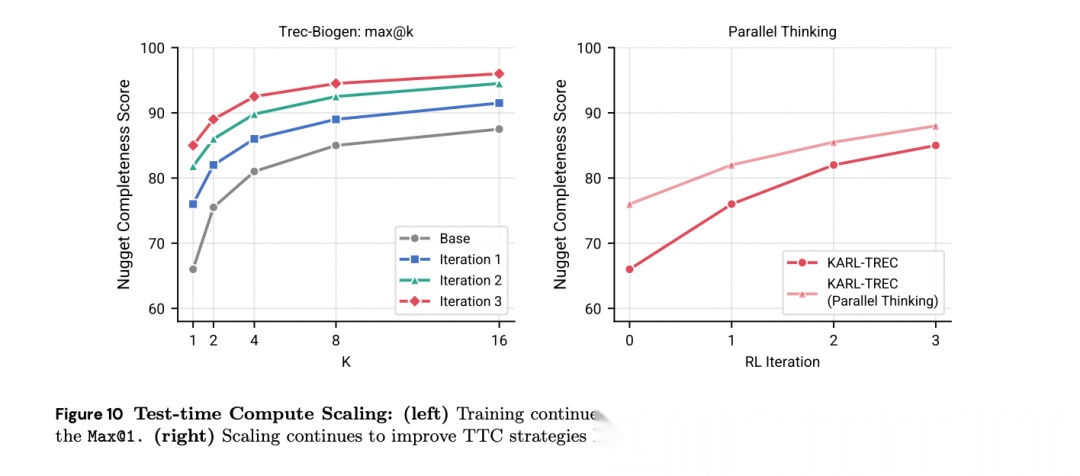
[Figure 10: 测试时计算缩放] 训练持续提升Max@K而非仅改善Max@1,表明RL扩展了模型的问题解决覆盖面。
X说
当前agent仅使用向量搜索这一单一工具,后续可扩展至结构化检索、代码执行和组合子agent。上下文管理目前依赖简单的提示压缩,可通过更精细的分层记忆管理进一步改进。此外,在需要数值计算的场景中,模型倾向于继续搜索预计算结果而非对已有证据进行推理,这一推理短板有待通过引入算术和表格推理奖励来弥补。
当大模型竞赛进入agent时代,KARL的结果提示了一个重要方向:精心设计的合成数据加多任务强化学习,可能比单纯扩大模型规模更有效地推动知识agent的Pareto前沿。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献219条内容
已为社区贡献219条内容

所有评论(0)