comfyUI-高清放大1
lz由于设备性能有限,选择使用吐司平台,uu们可以自行选择其他在线工作流搭建平台。
有能力的uu可以选择本地部署,或者云端部署,不影响comfyUI的学习。。
基础节点搭建
常规5件套,包含Checkpoint、CLIP提示词、空Latent、VAE解码、预览图像。可以根据所选模型的特点决定是否需要外置VAE。
1.checkpoint
每个配置文件(.yaml)定义了模型的结构和推理设置,选择哪个配置文件取决于使用的模型权重(Checkpoint)以及的生成需求(如精度、速度、特定功能)。
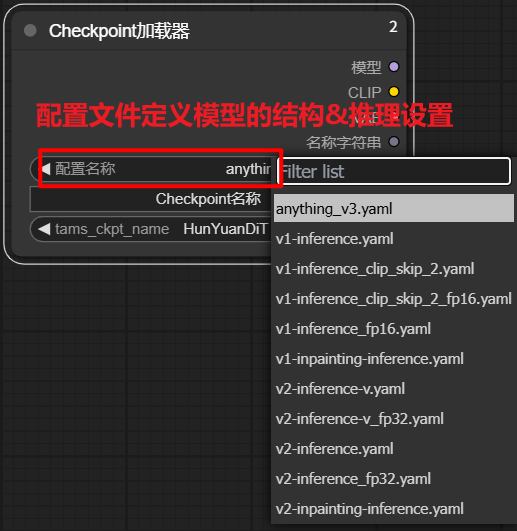
以下说明来源于D老师
上图配置文件说明
匹配模型类型:
配置文件需与模型权重训练时的架构一致(例如v1、v2、Anything-V3等)
功能需求:
- `inpainting`:用于图像修复(需配合修复模型)。
- `clip_skip`:跳过CLIP的某些层以调整文本理解强度(通常用于特定画风)。
- `fp16`:半精度计算(减少显存占用,提速但可能略微降低质量)。显存较小选择
- `fp32`:全精度计算(质量最佳,但显存需求高)。显存充足选择
配置文件名称 适用场景 选择说明 anything_v3.yaml Anything V3 系列模型(动漫风格专用) 模型名称包含`anything`、`anime`等 v1-inference.yaml Stable Diffusion V1 标准模型(通用场景) 官方V1模型(如`sd-v1-4.ckpt`) v1-inference_clip_skip_2.yaml V1模型 + 跳过CLIP最后2层(可增强风格化效果) v1-inference_fp16.yaml V1模型 + 半精度推理(显存优化) v1-inpainting-inference.yaml V1修复模型专用(需配合inpainting权重) v2-inference.yaml Stable Diffusion V2 基础模型(768x768分辨率) 官方V2模型(如`768-v-ema.ckpt`) v2-inference_v.yaml V2 版本v的模型(指公开发布的V2基础版) v2-inference_fp32.yaml V2模型 + 全精度推理(最高质量) v2-inpainting-inference.yaml V2 修复模型专用
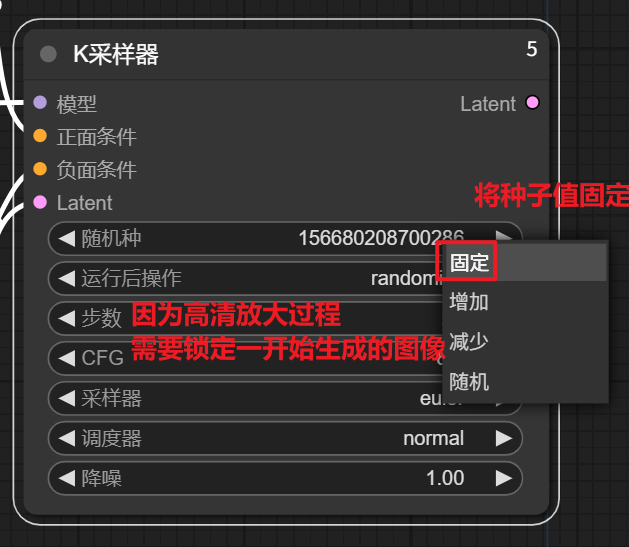
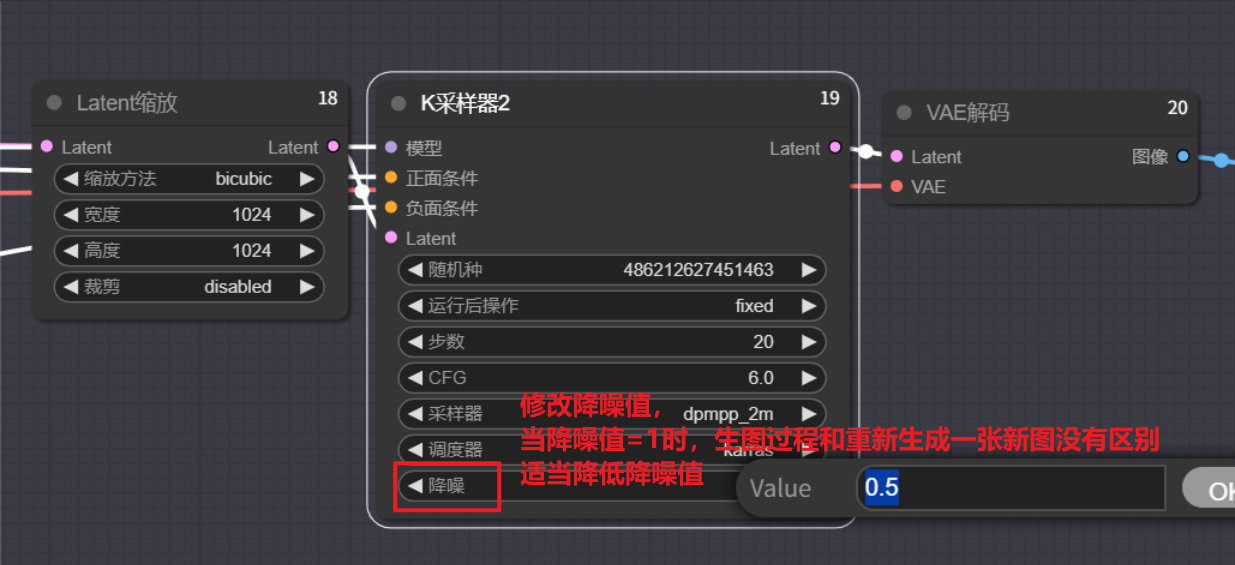
2.K采样器
将运行后操作改为固定,固定种子数,锁定生成的图片的样式。步数、CFG、采样器以及调度器参考所选模型作者给出的提示进行设置。
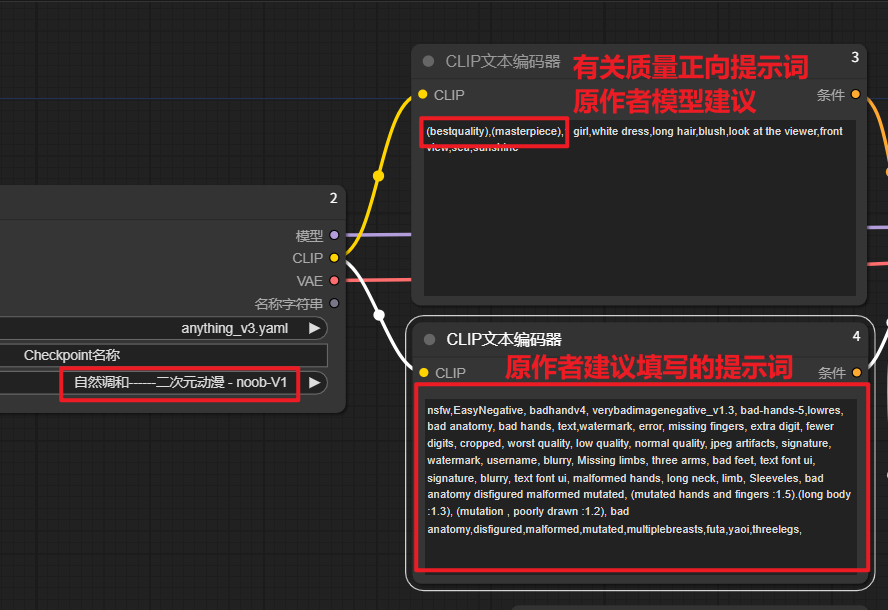
3.CLIP
CLIP的填写可以参考作者所给提示,相关提示词的撰写可以从下述5个方面展开发散进行撰写。
1人物(人物主体、表情动作、服饰道具)、2场景、3环境、4光照、5镜头
相关提示词复习:SD-提示词书写1-CSDN博客
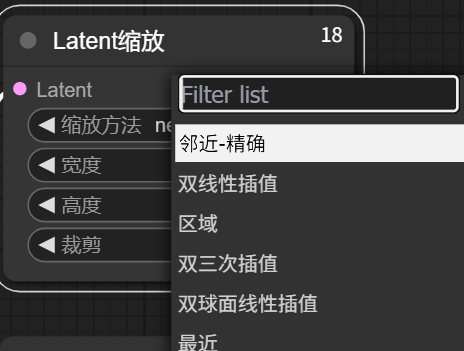
初次缩放:Latent缩放
下图列出的方法用于在潜在空间(Latent Space)中调整图像尺寸,而不是在像素空间。可以综合设备性能,图片质量选择合适的缩放方法。
常见缩放方法对比
方法名称 原理 特点 适用场景 最近邻 (Nearest) 直接取最近的原始像素值 ⚡️ 速度最快
⚠️ 锯齿明显,边缘粗糙像素艺术/需要保留硬边缘的情况 邻近-精确 (Nearest-exact) 最近邻的改进版,边界处理更精确 ✅ 比标准最近邻锯齿更少
⚡️ 仍保持高速需要快速处理的低精度缩放 双线性 (Bilinear) 基于2×2邻域的加权平均 ⚖️ 平衡速度和质量
🌫️ 中等模糊(平滑过渡)通用缩放(速度与质量折中) 双三次 (Bicubic) 基于4×4邻域的三次多项式计算 🌟 细节保留最好
⚠️ 计算量较大照片/高清图像放大 区域 (Area) 按像素区域面积平均采样 🔍 缩小图像时效果最佳
✅ 避免摩尔纹图像缩小/降采样 双球面线性 (Bilinear spherical) 在球面色彩空间计算(如LAB/LCH) 🌈 色彩过渡更自然
⚙️ 减少色带现象渐变色彩图像(如天空/皮肤)
使用说明建议
图像放大 → 优先选 双三次
实时处理/视频 → 选 双线性
像素风格作品 → 选 最近邻-精确
色彩敏感内容(如艺术作品)→ 尝试 双球面线性
缩小图像 → 首选 区域法
复制K采样器节点,粘贴带连线的K采样器节点——Ctrl+Shift+C。
当降噪值=1时,初始图片为充满噪声的图片。
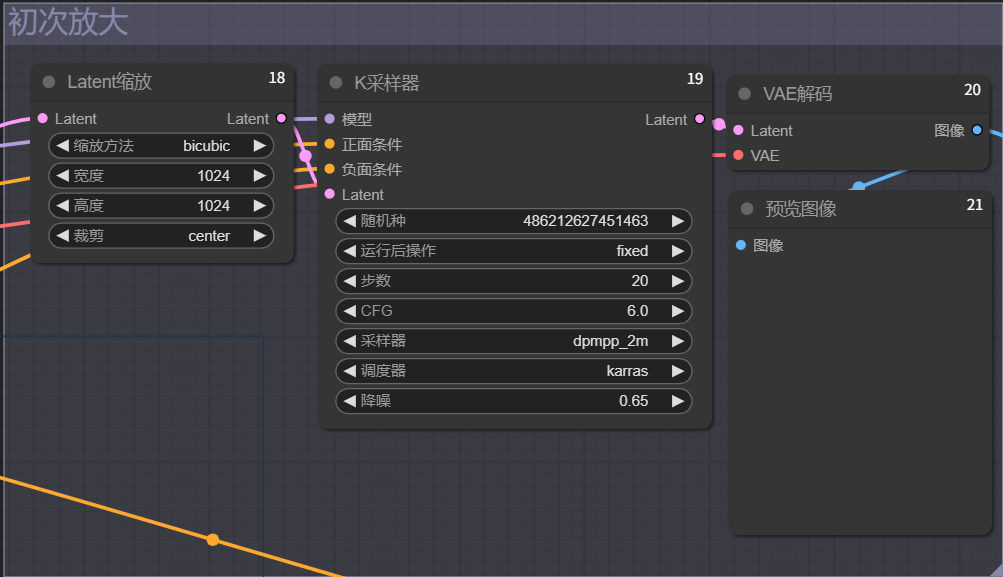
但通过观察可以看到,初次放大后的图片相较于原图具备更多细节,发顶的光影处理更细致,但由于设置的降噪数=1,故是一张区别于原图的新图。
可以多次尝试,试出最佳的降噪数值。
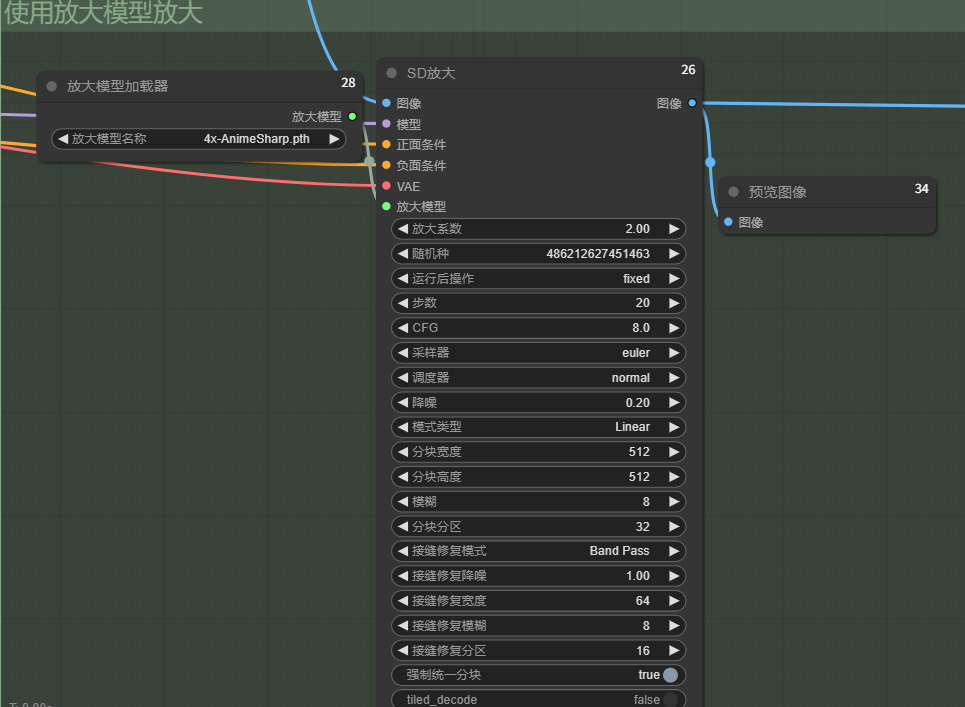
二次缩放:放大模型缩放
通过加载放大模型进行放大
放大模型分类
放大倍数
2x(轻度放大,保留原始风格)、4x(最常用,细节明显增强)、8x(极限放大,需配合降噪)
使用场景
内容类型 代表模型 最佳用途 通用真实图像 RealESRGAN_x4plus.pth(消除伪影更优)4x_NMKD-Superscale-SP.pth照片/风景/物品 动漫插画 4x-AnimeSharp.pthRealESRGAN_x4plus_anime_6B.pth二次元/卡通/游戏截图 人脸特写 4xFaceUpSharpDAT.pth人像照片/肖像画 艺术插画 4x_IllustrationJaNai_V1_ESRGAN.pth水彩/油画/手绘 选型法则
匹配内容类型
动漫选
4x-AnimeSharp或*anime_6B真人照片选
RealESRGAN_x4plus选择锐度
柔和自然:
4x_RealisticRescaler极致锐利:
4x-UltraSharp分层放大处理
先4倍→再4倍(如4x-AnimeSharp→8x_NMKD)⚠️ 注意:
.safetensors格式比.pth更安全,优先选用
三次放大
三次放大和二次放大均为通过大模型对图片进行放大,肉眼基本看不出差异。




具体工作流
动漫风格放大工作流 | ComfyUI Workflow | 吐司 tusiart.com
事情不会随着时间自行解决,除非你采取行动。——来点鸡汤8
以上end

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)