20260318_204623_PyVision-RL:通过强化学习构建开放型智能体视觉模型
摘要(Abstract)
在多模态智能体(agentic multimodal models)中应用强化学习(Reinforcement Learning, RL)时,常出现“交互崩溃”(interaction collapse)问题:模型为了“偷懒”,逐渐减少调用工具(如OCR、目标检测、时间戳定位等)、缩短推理轮次(multiturn reasoning),最终退化成单步问答式模型——这严重削弱了智能体本该具备的主动规划、分步执行、持续交互等核心能力。
举个例子:
假设你让一个视觉智能体分析一段视频:“请找出视频中穿红衣服的人第一次挥手的时间点,并描述他挥手时周围发生了什么”。
- 理想行为 :模型先调用关键帧采样工具 → 再调用动作识别工具定位挥手 → 调用物体检测确认红衣 → 调用场景理解描述周边 → 最后整合输出答案。
- 崩溃行为 :模型直接看第一帧就瞎猜:“大概在第3秒,周围没人”,全程不调任何工具,也不翻看后续帧。
为解决这个问题,作者提出了 PyVision-RL —— 一个专为开源(open-weight)多模态大模型设计的强化学习训练框架,核心目标是:稳住训练过程 + 让模型愿意且善于多轮调用工具 。
它包含两个关键技术:
-
过采样–过滤–排序(Oversampling–Filtering–Ranking) rollout 策略
这样做避免了“只学一条烂路径就定型”的风险,也防止模型因偶然成功而固化低效策略。
- 过采样(Oversampling) :在训练时,对同一个输入(比如一张图或一段视频),让模型生成多个不同路径的推理轨迹(rollout),而不是只采1条——相当于“让模型多试几次不同解法”。
- 过滤(Filtering) :自动筛掉明显无效的轨迹(例如:没调用任何工具、输出空、格式错误、重复调用同一工具5次)。
- 排序(Ranking) :把剩下的有效轨迹按质量打分(比如是否答对、是否步骤合理、是否简洁),用于后续更新策略。
-
累积式工具奖励(Accumulative Tool Reward)
不再只在最后给一个“对/错”奖励(final reward),而是每成功调用一次有用工具,就即时给一小份正向奖励 ,并把所有小奖励加起来作为总奖励。
数学上可简单理解为:其中:
# 示例:计算一次推理轨迹的总奖励(简化版)tool_rewards = [0.2, 0.3, 0.0, 0.25] # 每步工具调用得分(第3步调用失败得0)final_answer_reward = 1.0 # 最终答案正确total_reward = sum(tool_rewards) + final_answer_rewardprint(f"总奖励 = {total_reward}") # 输出:总奖励 = 1.75
- 是第 步调用工具后获得的奖励(例如:调用OCR成功提取文字 → +0.3;调用目标检测框出人 → +0.2);
- 是最终答案正确的额外奖励(+1.0)。
基于该框架,作者构建了两个具体模型:
- PyVision-Image :专注图像理解任务(如图文推理、图表问答);
- PyVision-Video :专注视频理解任务(如时序推理、事件定位)。
其中,PyVision-Video 的亮点是“按需构建上下文”(on-demand context construction) :
- 它不会把整段视频所有帧都送进模型(那会爆炸式增长 visual token 数量);
- 而是在推理过程中,动态决定“此刻需要哪几帧” ——比如问“挥手时刻”,就只采挥手前后共5帧;问“人物从进门到坐下全过程”,就按动作逻辑稀疏采样关键帧。
- 这大幅降低了视觉 token 开销(visual token usage),让长视频推理变得可行。
实验表明:PyVision-RL 训练出的模型不仅准确率更高,而且推理更高效、交互更持久。论文结论强调:要想让多模态智能体真正“能干、肯干、会干”,就必须同时做到两点:一是保持长期稳定交互(sustained interaction),二是按需处理视觉信息(on-demand visual processing) 。
1. 引言(Introduction)
大型语言模型(Large Language Models, LLMs)已经快速从“只会聊天”的被动助手,进化成了能主动做事的智能体(agent)。它们不仅能进行多轮对话,还能调用外部工具(比如计算器、搜索引擎、代码执行环境等)来完成复杂任务。
不只是商业闭源模型在做这件事,越来越多的研究者也在探索:如何让开源、可自由下载的“开放权重”(open-weight)模型也具备这种工具使用能力? 尤其是面对需要长时间与外部环境交互的任务,比如深度资料调研(deep research)、操作电脑界面(computer use)等。
最近,这种“智能体范式”(agentic paradigm)开始从纯文本领域,拓展到多模态(multimodal)领域 ——也就是同时理解图像、视频和文字。
举个例子:OpenAI o3(OpenAI, 2025)就发现,如果让模型在看图/看视频时,也能像人一样“动手操作”(比如放大某个区域、截取一段视频、画框标注),而不是只“静态地看”,它的推理就会更扎实——因为每一步操作都基于真实的视觉证据(visual evidence)。这就催生了一个新方向:构建能对图像和视频进行推理、行动、交互的多模态智能体。
目前,实现多模态工具使用的主流方法大致分两类:
第一类:静态工具集(Static Toolsets)
研究者提前手工设计好一套固定工具,比如“裁剪图片”“放大局部”“截取视频片段”,然后把这套工具“塞给”模型用。
优点:针对特定任务效果不错。
缺点:太死板!换一个任务就得重新设计工具,工程成本高,泛化性差。
代表工作:Hu 等(2024)、Yang 等(2023)、Gupta & Kembhavi(2023)、Zhang 等(2025a)、Yang 等(2025)、Gao 等(2025b)、Meng 等(2025b)。
第二类:动态工具化(Dynamic Tooling)
不预设工具,而是把 Python 运行环境本身当作一个“万能工具” 。模型可以随时写 Python 代码,临时生成它当前任务真正需要的操作——比如“先用 OpenCV 提取视频第10秒的帧,再用 PIL 把它转成灰度图,最后用 pytesseract 识别上面的文字”。
优点:表达力强、组合灵活(compositional),能应对千变万化的任务。
缺点:目前主要用在图像理解上;而且很多工作依赖闭源 API(如 GPT-4V 调用外部服务),开源、可复现的多模态强化学习(RL)训练,尤其是面向视频的,几乎还是空白 。
那么问题来了:为什么视频上的 RL 训练这么难?
一个关键挑战是:训练不稳定,容易“交互崩溃”(interaction collapse) 。
什么叫交互崩溃?简单说:模型本来该多步操作(比如“先找人脸→再框出来→再识别人名→再查资料”),但经过强化学习微调后,它反而越来越懒——只输出一两句话、完全不用工具,或者只用一次就草草结束。
Zhang 等(2025b)、Hong 等(2025)都观察到了这个现象。这让不少人怀疑:“多步交互”在视觉任务里是不是根本行不通?毕竟它在纯文本推理中很成功(Jaech 等,2024;Li 等,2025a)。
但我们认为:不是交互没用,而是训练方法没给对劲儿的“奖励”和“引导” 。
具体来说,两个原因导致了崩溃:
- 强化学习采样(rollout)过程太随意,好坏样本混在一起,模型学不到“怎么好好互动”;
- 奖励函数只关心最终答案对不对,却不管模型用了几次工具、是否持续思考——等于告诉模型:“只要蒙对答案,别动工具也行”。
所以,我们提出了 PyVision-RL :一个专为开源多模态模型设计的智能体强化学习训练框架。
它的核心思路有两点:
- 统一用 Python 作为底层工具 :无论是图像还是视频,都通过 Python 运行时(runtime)来加载、处理、可视化。这样既支持动态工具化,又完全开源可控。
- 两项关键 RL 改进 :
- 过采样–过滤–排序(Oversampling–Filtering–Ranking)的 rollout 生成机制 :先大量生成不同交互路径(oversampling),再自动筛掉乱写的、无效的(filtering),最后按质量排序选最好的几个去更新模型(ranking)——大幅稳定训练过程。
- 累积式工具奖励(Accumulative Tool Reward) :不只在最后给分,而是在每一步调用工具时都给小奖励 ,并且越往后坚持使用,奖励越高。这就像鼓励学生“保持专注、持续动手”,而不是“最后一秒抄答案”。
基于这个框架,我们训练出两个模型:
- PyVision-Image :专攻图像理解。系统提示(system prompt)和图像提示(image hints)都输入大模型上下文(MLLM context),图像本身也加载进 Python 运行时。
- PyVision-Video :专攻视频理解。只把系统提示送入大模型上下文,整段视频则完全隔离在 Python 运行时中 。模型要处理视频时,必须自己写 Python 代码——比如
get_frame(video_path, timestamp=12.5)或sample_keyframes(video_path, n=3)——来按需提取关键帧并绘图。
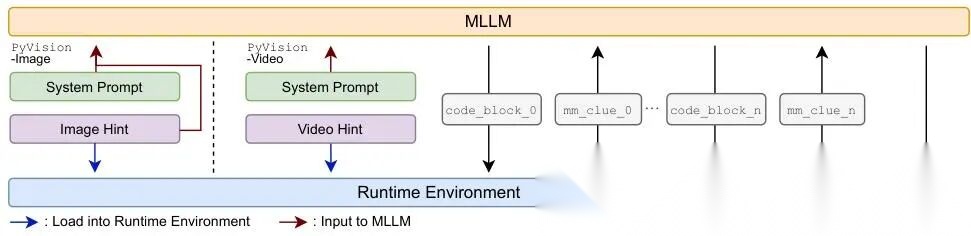 图 1. PyVision-RL 的智能体架构(Agentic scaffolds)。我们在统一的 Python 动态工具框架下,为图像和视频理解分别设计了两种智能体结构。对于 PyVision-Image,系统提示和图像提示均注入多模态大模型(MLLM)上下文,图像也加载进 Python 运行时;对于 PyVision-Video,仅系统提示注入 MLLM 上下文,视频则独占运行时环境。给定用户查询,模型交替进行自然语言推理与可执行代码块(code_block_0)生成,以处理多模态输入。执行结果(mm_clue_0),包括文本输出和渲染后的图像,将被追加回上下文并反馈给模型。该交互循环持续进行,直至生成最终答案。通过将视频输入严格限制在运行时中,PyVision-Video 实现了按需上下文构建(on-demand context construction):智能体可在推理过程中选择性地采样并绘制任务相关帧,从而大幅提升视觉 token 利用效率(见图 2)。
图 1. PyVision-RL 的智能体架构(Agentic scaffolds)。我们在统一的 Python 动态工具框架下,为图像和视频理解分别设计了两种智能体结构。对于 PyVision-Image,系统提示和图像提示均注入多模态大模型(MLLM)上下文,图像也加载进 Python 运行时;对于 PyVision-Video,仅系统提示注入 MLLM 上下文,视频则独占运行时环境。给定用户查询,模型交替进行自然语言推理与可执行代码块(code_block_0)生成,以处理多模态输入。执行结果(mm_clue_0),包括文本输出和渲染后的图像,将被追加回上下文并反馈给模型。该交互循环持续进行,直至生成最终答案。通过将视频输入严格限制在运行时中,PyVision-Video 实现了按需上下文构建(on-demand context construction):智能体可在推理过程中选择性地采样并绘制任务相关帧,从而大幅提升视觉 token 利用效率(见图 2)。
这种“按需构建上下文”的策略,带来了巨大收益:
- 不再强制均匀抽帧(比如每秒抽1帧),而是让模型自己判断“哪几帧最关键”;
- 极大减少了视觉 token 消耗(visual token consumption),避免把整段视频无差别喂给模型;
- 同时提升了推理效率——因为模型看到的永远是它真正需要的视觉信息。
实验结果也很亮眼:
- PyVision-Image 在视觉搜索、多模态推理、智能体推理等多个基准测试中达到当前最优(state-of-the-art) :
- 在 (Wu & Xie, 2024)上比 DeepEyes-v2(Hong 等,2025)高 ;
- 在 WeMath(Qiao 等,2025a)上高 。
- PyVision-Video 在视频理解基准 VSI-Bench(Yang 等,2024)上,比带视频裁剪工具的多模态智能体 VITAL(Zhang 等,2025a)高 ,且视觉 token 使用量大幅降低 :
- PyVision-Video 平均每条样本仅用 5K 视觉 token ;
- 对比模型 Qwen2.5-VL-7B 用了 45K ;
- 但准确率反而更高:PyVision-Video 达 44.0%,Qwen2.5-VL-7B 仅 38.0% 。
总结来说,PyVision-RL 是一个统一的、面向开源多模态模型的智能体强化学习框架,支持图像与视频的工具化推理。它通过“过采样–过滤–排序” rollout 策略和“累积式工具奖励”,有效防止了交互崩溃,真正激励模型进行多轮、持续、有意义的工具调用。最终得到的 PyVision-Image 和 PyVision-Video 证明:只要训练得当,“持续交互 + 工具使用”依然是提升多模态推理能力的强力引擎——尤其在视频理解这类高成本任务中,还能兼顾高性能与高效率。
2. 相关工作(Related Work)
工具集成的多模态推理(Tool-Integrated Multimodal Reasoning)
与那些只依赖文本推理的多模态模型不同(例如 Wang 等,2025a;Deng 等,2025;Xie 等,2025),工具集成的多模态推理模型会主动调用外部工具 ,并把工具执行后产生的视觉结果(比如裁剪后的图、放大的局部、绘制的热力图等)作为推理链条中的一环 (Wang 等,2024c)。
举个例子:当你让模型分析一张超高清卫星图时,它不会硬着头皮直接“看全图”——而是先用“裁剪工具”框出疑似有建筑的区域,再用“放大工具”仔细查看细节。这些操作不是模型在脑子里“脑补”,而是真实运行了代码、拿到了新图像,再基于这张新图继续思考。这就像人类用放大镜+标尺辅助看显微照片,而不是光靠眼睛硬盯。
目前主流方法大致分两类:
静态工具集(Static Toolsets)
这类方法提前把能用的工具都写死——比如规定只能用“上下左右裁剪”“2倍/4倍放大”“边缘检测”这几个按钮。这些工具怎么用、什么时候用,甚至提示词里都写好了(Zheng 等,2025c;Lai 等,2025;Su 等,2025a;Hu 等,2024;Suris 等,2023;Gupta & Kembhavi,2023;Song 等,2026)。
类似地,在长视频理解中,也预设好“截取前10秒”“提取每30帧一张图”“找动作最剧烈的5秒片段”等固定视频处理工具(Zhang 等,2025a;Yang 等,2025;Gao 等,2025b;Meng 等,2025b)。
优点:简单、稳定、容易控制。
缺点:像给汽车只配三档变速箱——遇到陡坡或急弯就卡壳;新任务来了就得人工加按钮,没法自适应。
动态工具化(Dynamic Tooling)
这类方法把 Python 运行环境本身当作一个“万能工具箱” 。模型不再被限制在几个预设按钮里,而是可以当场写一小段 Python 代码 ,实现任意需要的视觉操作——比如“把所有红色像素变蓝”“用YOLOv8检测猫,把框出来的区域拼成九宫格”“对视频按光流变化强度打分,选Top3片段”。
代表性工作包括 Zhao 等(2025a)、Zhang 等(2025b)、Hou 等(2025)、Song 等(2025)、Guo 等(2025b)、Hong 等(2025)。
优点:灵活得像乐高——要搭桥就拿桥块,要造车就拿轮子;模型真正“动手做”,不光“动嘴说”。
缺点:过去只在单张图像任务上跑通,没人把它成功搬到视频理解上——因为视频更复杂:数据量大、时序关联强、工具调用需考虑前后帧一致性。
我们的方法 PyVision-RL 正是填补这个空白:它同样把 Python 当作基础工具(primitive tool),但首次将动态工具化同时应用于图像理解和视频理解两大任务,并通过强化学习(Reinforcement Learning, RL)让模型学会“什么时候该写什么代码、调什么函数、传什么参数”,而不是靠人工写死逻辑。
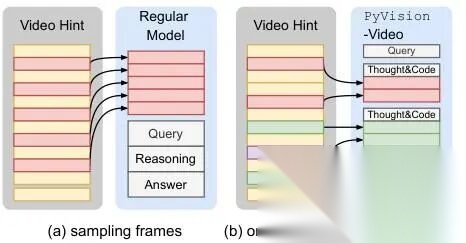 图 2. 帧采样(frame sampling)与按需上下文构建(on-demand context construction)对比。(a)传统视频多模态大语言模型(video MLLMs),例如 Qwen-VL 系列,采用均匀采样若干帧(如每秒1帧),然后把所有帧一股脑塞进模型的上下文窗口。(b)在 PyVision-Video 中,我们采用按需上下文构建:整段视频仅加载到 Python 运行环境中(不占模型上下文);模型在推理过程中,通过生成 Python 代码,**自主决定**何时、何地、采哪几帧,并实时绘制/处理,再把结果喂给语言模型。这大幅提升了 token 利用效率(token efficiency)。
图 2. 帧采样(frame sampling)与按需上下文构建(on-demand context construction)对比。(a)传统视频多模态大语言模型(video MLLMs),例如 Qwen-VL 系列,采用均匀采样若干帧(如每秒1帧),然后把所有帧一股脑塞进模型的上下文窗口。(b)在 PyVision-Video 中,我们采用按需上下文构建:整段视频仅加载到 Python 运行环境中(不占模型上下文);模型在推理过程中,通过生成 Python 代码,**自主决定**何时、何地、采哪几帧,并实时绘制/处理,再把结果喂给语言模型。这大幅提升了 token 利用效率(token efficiency)。
多模态大语言模型的强化学习方法(RL for Multimodal Large Language Models)
在 DeepSeek-R1(Guo 等,2025a)取得成功之后,越来越多的研究开始将强化学习(Reinforcement Learning, RL)用于提升大语言模型(LLM)和多模态大语言模型(Multimodal LLMs, MLLM)的推理能力和工具使用能力 (tool-use capabilities)。比如,Meng 等(2025a)、Yu 等(2025)、Zheng 等(2025a)都做了这方面的探索。
这些方法大多采用无需评论器(critic-free)的 RL 算法 。什么叫“无需评论器”?我们来打个比方:
- 在传统 RL(如 PPO)中,通常需要两个神经网络协同工作:一个是策略网络(policy network) ,负责决定“下一步做什么”;另一个是评论器网络(critic network) ,负责评估“当前状态值多少分”或“这个动作好不好”。
- 而 critic-free 方法只保留策略网络 ,直接用某种方式估计动作的好坏(比如通过比较多个回答的奖励差异),省去了训练和维护评论器的开销,更适合参数量巨大、训练成本高昂的 MLLM。
目前这些 RL 方法,大致可以按技术侧重点分为四类:
1. 改进优势函数估计(Improved Advantage Estimation)
优势函数(Advantage function)用来衡量:“比起平均表现,我这个动作好多少?”——它决定了模型该多大力度去调整策略。
Liu 等(2025c)和 Hu(2025)提出了更稳定、更准确的优势估计方法。例如,他们可能用多个 rollout(即让模型多次生成答案)来估算期望奖励,再减去一个自适应基线(baseline),从而得到更鲁棒的优势值 :
其中 是从第 步开始的累计奖励(含折扣), 是对当前状态 的价值估计(可由简单统计或轻量网络给出)。
2. 修改 PPO 的裁剪机制(Modified PPO Clipping)
PPO(Proximal Policy Optimization)常用“裁剪(clipping)”防止策略更新过大,公式为:
其中 是重要性采样比, 是裁剪范围(如 0.1 或 0.2)。
但直接套用到 LLM 上容易出问题:因为 LLM 输出的是长文本(一串 token 序列),每个 token 的概率都很小,乘起来后 极易趋近于 0 或爆炸,导致裁剪失效。
Yu 等(2025)、Chen 等(2025a)、Zheng 等(2025b)、Zhao 等(2025b)、Gao 等(2025a)就分别设计了更适配 token 级别更新的裁剪策略,比如:
- 对每个 token 单独裁剪重要性比;
- 动态调整 ,在训练初期宽松、后期收紧;
- 或把裁剪逻辑从“整个响应”下沉到“关键决策步”。
3. 缓解训练-推理不匹配(Training-Inference Mismatch)
这是 MLLM 做 RL 时的一个典型痛点:
- 训练时 :模型常被强制“一步步思考”(比如先写思维链 Chain-of-Thought,再给答案),甚至被人工标注中间步骤;
- 推理时 :用户只给一个输入图+问题,模型要端到端输出答案,不会主动展示思考过程 。
这种不一致会让模型学到“表演式推理”——只为骗过训练奖励,而非真正理解。Yao 等、Liu 等(2025b)尝试用隐式推理建模或奖励塑形(reward shaping) 让模型在无显式思维链监督下,也能内化推理结构。
4. 稳定 MoE 模型的 RL 训练(Stabilizing RL for Mixture-of-Experts)
MoE(Mixture of Experts)模型(如 Qwen2-MoE、DeepSeek-MoE)靠路由(routing)机制动态激活部分专家(expert),节省计算但带来新挑战:
- RL 更新会剧烈改变 token 分布 → 路由结果突变 → 某些 expert 突然“失业”或“过载”;
- reward 信号稀疏,难以精准归因到具体 expert。
Ma 等(2025)和 Xiao 等(2026)提出:
- 对 router 加入熵正则(entropy regularization),鼓励负载均衡;
- 设计 expert-level 的局部奖励(per-expert reward),而非只看整条 response 的全局奖励;
- 或冻结 router,在 RL 阶段只微调 expert 参数。
这些方向并非互斥,最新工作往往融合多种技术——比如既改进优势估计,又适配 MoE 结构,还缓解训练-推理鸿沟——共同推动开放型具身视觉模型(open agentic vision models)走向实用。
3. 方法:PyVision-RL(Methods: PyVision-RL)
这一节介绍 PyVision-RL —— 我们提出的、面向开放权重多模态模型 (open-weight multimodal models)的具身智能体式强化学习框架 (agentic reinforcement learning framework),它支持模型在训练中动态调用工具 (dynamic tool use)。
你可以把 PyVision-RL 想象成一个“会写 Python 脚本的视觉智能体”:它不仅能“看”图片和视频,还能在推理过程中实时生成并运行一小段 Python 代码 ,来完成普通大模型做不到的事——比如精确数出图中有几只猫、算出视频里小球运动的速度、或者把两张图按像素做差值分析。
这里有两个关键设计:
1. Python 作为基础工具(Python as a primitive tool)
- 不是把 Python 当成黑箱 API 调用,而是让模型直接生成可执行的 Python 代码片段 (例如
cv2.imread()加载图像、PIL.Image.open()打开图片、np.mean()计算像素均值等)。 - 这些代码会在一个安全沙箱中运行,返回结果(如数字、布尔值、新图像)给模型继续思考。
- 举个例子 :
输入一张街景图,模型可能生成:plaintext from PIL import Imageimport numpy as npimg = Image.open("input.jpg").convert("RGB")r, g, b = img.split()np.array(r).mean() > 128 # 判断红色通道是否整体偏亮运行后返回True,模型就据此推断“这张图偏暖色调”。
2. 统一的具身智能体架构(unified agentic scaffold)
- 这个架构像一个“通用任务大脑”,同时兼容图像理解和视频理解任务。
- 它定义了一套标准交互流程(interaction protocol):
观察(Observation)→ 思考(Reasoning)→ 工具选择(Tool Selection)→ 代码生成(Code Generation)→ 执行反馈(Execution Feedback)→ 更新状态(State Update)
循环往复,直到得出最终答案。
3. 防止交互崩溃 + 提升多轮工具使用质量
在传统视觉 RL 中,模型容易“卡住”:比如第一次调用工具失败后,后续轮次就乱猜、不尝试新工具,甚至反复生成同一段无效代码——这叫交互崩溃(interaction collapse) 。
PyVision-RL 通过以下方式缓解:
- RL 建模方式 :将整个多轮交互建模为一个序列决策过程,每个时间步的动作(action)是:
- 选择一个工具(目前固定为 Python 解释器)
- 生成一段合法、有目的的 Python 代码
- 输出自然语言反思(如“我需要先裁剪出左上角区域再统计边缘”)
奖励(reward)不仅取决于最终答案对错,还鼓励代码成功执行 、信息增益提升 、避免重复无效操作 。
- 训练策略 :
- 使用带约束的采样 (constrained sampling)防止生成语法错误或危险代码(如
import os; os.system("rm -rf /")); - 引入回滚机制 (roll-back mechanism):若某轮代码报错,不终止对话,而是让模型基于错误信息重试;
- 在 rollout(即一次完整交互序列)中加入多样性正则项 ,抑制模型总用同一套路解决问题。
换句话说:PyVision-RL 不只要模型“答得对”,更要求它“想得清、写得准、试得巧、改得快”。
3.1. Agentic Scaffold:Python 作为基础工具(Python as a Primitive Tool)
交互协议(Interaction Protocol)
想象你正在和一个“会写代码的AI助手”合作解题——它一边用自然语言思考,一边实时写代码来验证想法。这个过程就像两个人协作:AI负责推理(说人话),Python 解释器负责执行(干实事)。
具体流程如图 1 所示(原文中图 1 的 URL 将在原文提供时原样输出,此处暂无):
- AI 先输出一段中文/英文推理,比如:“这张图里有三只猫,我需要数清楚每只猫的颜色……”;
- 紧接着插入一段可运行的 Python 代码,用
<code>...</code>标签包起来,例如:```plaintext
from PIL import Imageimg = Image.open(“input.jpg”)print(img.size) # 查看图片尺寸 - 系统自动运行这段代码,并把结果(比如
(640, 480))用<interpreter>...</interpreter>包裹后返回给 AI; - AI 看到结果后,继续推理、再写新代码,循环往复;
- 直到它写出最终答案,用
<answer>...</answer>包起来,比如<answer>图中有两只橘猫和一只黑猫。</answer>; - 所有中间步骤(推理文字 + 代码 + 执行结果)都会被保留在对话历史里,供后续步骤参考——这叫上下文累积(context accumulation) ,让 AI 越聊越“有记忆”。
换句话说:这不是“先想完再写代码”的静态流程,而是“边想边试、试完再想”的动态闭环,像科学家做实验一样迭代。
多模态提示注入(Multimodal Hint Injection)
当任务涉及图片或视频(比如“这张图里有什么动物?”或“视频里的人最后做了什么动作?”),AI 不仅要在语言层面理解问题,还要能“看见”内容。这就需要把图像/视频既喂给大模型(MLLM),也送进 Python 运行环境——两者缺一不可。
图像任务处理方式
- 原图直接作为输入传给 MLLM(让它“看见”);
- 同时,这张图也被加载进 Python 运行环境(比如用
PIL.Image.open()或cv2.imread()),让 AI 写的代码可以随时打开、裁剪、分析它。
举例:AI 可以写代码把图片转成灰度图、圈出人脸区域、统计像素颜色分布……所有操作都基于真实图像数据。
视频任务处理方式(创新点!)
传统方法(prior work)通常把整个视频“暴力拆解”:比如每秒抽 1 帧,固定取前 32 帧 → 拼成一长串图像输入。这样做简单粗暴,但浪费大量 token(视觉 token 很贵!),且可能漏掉关键帧。
PyVision-Video 换了一种更聪明的方式:按需加载,自主采帧(on-demand context construction) 。
- 整个原始视频只加载进 Python 运行环境(不塞进 MLLM 的文本上下文);
- MLLM 本身看不到全部画面,但它被系统提示词(system prompt)明确告知:“你可以用 Python 代码随时读取、采样、绘制任意帧!”;
- 于是 AI 可以根据问题,自己决定“看哪几帧”。这就是智能代理式帧选取(agentic frame fetching) 。
举个例子:
问题:“演员在视频后半段做了什么动作?”
→ AI 写出如下代码:
import decordvr = decord.VideoReader("video.mp4")total_frames = len(vr)start_idx = total_frames // 2 # 从一半处开始selected_frames = [vr[i] for i in range(start_idx, min(start_idx + 8, total_frames))]# 接着可调用 plt.imshow() 显示这些帧,或送入 CLIP 提取特征……
这样只处理后半段的若干帧,省下近 50% 的视觉 token(见原文图 2),同时提升准确率——因为关键信息真的在那里,而不是被平均采样稀释了。
总结一句话:让 AI 当“导演”,而不是“观众”;它不被动接收所有画面,而是主动调取所需镜头。
3.2.累积工具奖励(Accumulative Tool Reward)
之前的研究发现,在强化学习(Reinforcement Learning, RL)训练过程中,模型平均调用工具(tool)的次数往往会持续下降,最终陷入一种“模式坍塌(mode collapse)”现象:模型学会尽量少用甚至完全不用工具——哪怕任务本身需要多步工具交互才能解决(Hong 等,2025;Zhang 等,2025b)。这就像一个学生做数学题,明明需要先画图、再列式、最后计算三步,但他只记住“直接猜答案”,虽然偶尔蒙对,但永远学不会真正解题流程。
为了解决这个问题,让模型能在长达数百甚至上千步的复杂多轮交互中稳定训练、持续提升,并真正学会分步骤、有策略地使用工具 ,作者提出了一个新设计:累积工具奖励(Accumulative Tool Reward) 。它不只是鼓励“答对”,还明确奖励“用对工具的次数”——而且是在答对的前提下才叠加奖励 ,避免模型为了凑次数而乱调工具。
具体怎么做?我们来拆解一次完整推理过程(即一次 rollout):
-
先看答案对不对 :任务结束时,系统会自动判断最终答案是否正确,给出一个二值准确奖励:
→ 答对了 = 1,答错了 = 0。
-
再数用了几次工具 :统计这次推理中总共调用了多少次工具,记作 (例如:查天气 1 次 + 翻译 1 次 + 计算 1 次 → )。
-
叠加工具奖励 :给 乘上一个小系数 0.1,得到基础工具分 。
但注意!这个分数只在答对时才生效 ——用数学符号 表示“指示函数”:当 时为 1,否则为 0。
换句话说:答错 = 白忙活,工具用得再多也不加分;答对 = 不仅拿 1 分基础分,还按调用次数额外加分。
最终的总奖励公式如下:
我们用 Python 把这个公式写成可运行代码,方便你直观理解:
def compute_total_reward(answer_correct: bool, num_tool_calls: int) -> float: """ 计算单次 rollout 的总奖励 R :param answer_correct: 是否答对(True/False) :param num_tool_calls: 本次推理中调用工具的总次数 :return: 总奖励值 """ R_acc = 1.0if answer_correct else0.0 # 只有答对时,才加上 0.1 * 工具调用次数 tool_bonus = 0.1 * num_tool_calls if answer_correct else0.0 return R_acc + tool_bonus# 示例1:答对了,且调用了3次工具 → R = 1 + 0.1×3 = 1.3print(compute_total_reward(answer_correct=True, num_tool_calls=3)) # 输出: 1.3# 示例2:答错了,调用5次工具 → R = 0 + 0 = 0.0(不鼓励无效尝试)print(compute_total_reward(answer_correct=False, num_tool_calls=5)) # 输出: 0.0# 示例3:答对了,但没调用工具 → R = 1 + 0 = 1.0(基础分仍保留)print(compute_total_reward(answer_correct=True, num_tool_calls=0)) # 输出: 1.0
这种设计就像老师批改作业:不仅看结果对不对(),还看解题过程是否规范、步骤是否完整(),但只在答案正确时才给过程分 ——既防止学生瞎蒙,也防止学生乱写步骤凑字数。
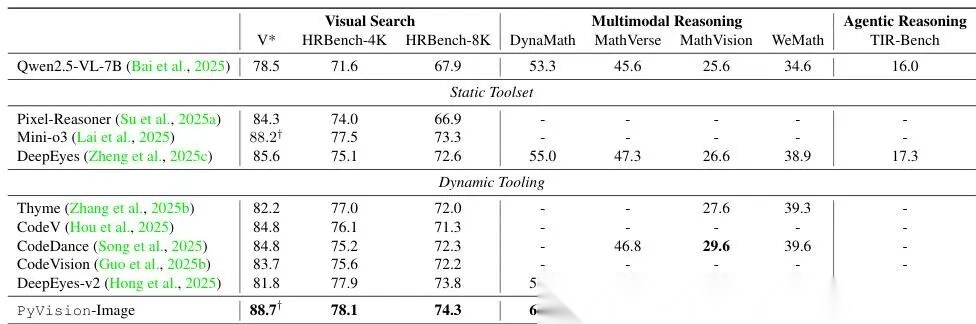
表格 1. PyVision-Image 在多个基准测试上的性能表现
我们对比了 PyVision-Image 与先前方法(均基于 Qwen2.5-VL-7B 模型),分为三类任务:视觉搜索、多模态推理、智能体推理。PyVision-Image 在全部三项任务中均达到当前最优(state-of-the-art)水平。
- 视觉搜索 :相比基线 Qwen2.5-VL-7B,在 、HRBench-4K、HRBench-8K 上分别提升 、、;
- 多模态推理 :相比 DeepEyes-v2,在 DynaMath、MathVerse、WeMath 上分别提升 、、;
- 智能体推理 :在 TIR-Bench 上比 Qwen2.5-VL-7B 提升 。
这些结果说明:动态工具调用机制(dynamic tooling) 具有很强的通用性和有效性。带 标记的结果表示 avg@32(即取前 32 个预测结果的平均得分)。
表格 2. VSI-Bench 上的性能对比
我们将 PyVision-Video 与两类视频理解模型对比:
- Video-R1:仅用纯文本推理(无视觉工具);
- VITAL:使用预定义的固定视频剪辑工具(predefined video clipping tools)。
三者均基于 Qwen2.5-VL-7B 并通过 RL 训练。PyVision-Video 相比基线 Qwen2.5-VL-7B 实现 7.3% 的绝对性能提升 ,验证了动态工具调用对空间推理任务的有效性 。

3.3. 过采样-过滤-排序回滚(Oversampling-Filtering-Ranking Rollouts)
当我们把原本只用于纯文本推理的 GRPO(一种强化学习算法)扩展到**具身智能体式视觉模型(agentic vision models)**时,一个关键问题浮现出来:回滚(rollout)的质量和分布 ,会极大影响训练是否稳定、是否高效。
你可以把“回滚”想象成模型在一次 RL 训练中,面对一个问题(比如“图中有没有猫?”),自己一步步思考、调用工具(如 crop 图像、调用分类器)、最终给出答案的一整条行为轨迹 。每条轨迹都会得到一个奖励(reward),告诉它这次做得好不好。
但在实际训练中,我们发现很多回滚其实“没啥用”,甚至“帮倒忙”。下面分三类情况解释:
情况一:全是“零信号”回滚 → 白忙一场
比如某个问题太难了(例如:“请从这张模糊卫星图里精确定位出2010年建的一座红色邮局”),当前模型根本不会做。结果一组(比如 8 条)回滚全失败,每条 reward 都是 0。
→ 经过组内归一化(group-level normalization)后,所有优势值(advantage)都变成 0;
→ 模型算不出任何有用梯度(gradient),相当于这一轮训练完全没学东西。
再比如:一组回滚全做对了,但每条都恰好调用了相同次数的工具 (比如都调了 3 次 detect_object)。
→ 奖励只跟结果正确性 + 工具调用数挂钩,那它们 reward 完全一样;
→ 归一化后,advantage 全为 0 → 又白跑了,浪费算力。
通俗说:就像考试批卷,如果全班都得 60 分(刚好及格),老师就看不出谁真懂、谁蒙对——没法针对性讲题。
情况二:回滚“跑崩了” → 直接 crash
智能体在执行过程中要写 Python 代码调用工具(比如 plt.imshow(img)),但可能出各种错:
- 超时(timeout):等了 5 秒没返回;
- 运行报错(runtime error):比如除零、索引越界;
- 多模态输出非法:比如生成了超大尺寸图像(10000×10000 像素),显存炸了;或根本没输出图像(空图)。
这些“断掉的轨迹”如果不提前筛掉,RL 训练过程可能直接中断或崩溃 —— 类似开车时突然方向盘失灵,必须提前装好“故障检测+自动刹车”。
情况三:好答案反被惩罚 → 学歪了
假设一个问题有多个正确解法:
- 解法 A:调用 2 次工具,干净利落(比如先 crop 再 classify);
- 解法 B:调用 5 次工具,绕一大圈(比如 crop→resize→enhance→crop again→classify)。
按我们的奖励设计,B 因为多调用工具而 penalty(扣分),所以 reward 略低于 A;但组内归一化后,A 的 advantage 可能反而变成负数 (因为 B 拉高了平均 reward)。
→ 模型一看:“咦?我答对了还被罚?那下次少动脑,多点几下工具保险!”
→ 结果鼓励了冗余行为,抑制了高效策略。
就像老师给作文打分:如果全班作文都偏长,突然一篇短小精悍的满分作文,按“相对排名”打分反而可能得负分——显然不合理。
我们的解法:过采样–过滤–排序(Oversampling-Filtering-Ranking)
我们设计了一个三步流水线来“精挑细选”高质量回滚:
- 过采样(Oversampling) :
先让模型对每个问题多生成几组回滚(比如每组 8 条,共生成 4 组 → 32 条),不急着用,先攒着。 - 在线过滤(Online Filtering) :
- 删掉整组 reward 方差为 0 的组(即全对/全错/全同分 → 没区分度);
- 删掉任何含“崩溃轨迹”的回滚(比如 Python 报错、空图像、超限图像)。
-
按标准差排序(Standard Deviation Sorting) :
对剩下的每组回滚,计算其 reward 的标准差(standard deviation) :标准差越大,说明这组里有“很对的”也有“很错的”,难度适中、信息丰富;
标准差越小(尤其接近 0),说明这组太简单或太难或太一致 → 学不到啥。然后我们只保留标准差最高的前 k 组用于更新策略(policy optimization)。
import numpy as np# 示例:假设有 4 组 rollout,每组 3 条,reward 如下rewards_per_group = [ [0.0, 0.0, 0.0], # 全零 → 方差=0 → 过滤掉 [1.0, 1.0, 1.0], # 全对且相同 → 方差=0 → 过滤掉 [0.2, 0.8, 0.5], # 有差异 → 方差≈0.25 [0.0, 1.0, 0.9], # 难度混合 → 方差≈0.34 → 优先选!]stds = [np.std(group) for group in rewards_per_group]print("各组 reward 标准差:", stds)# 输出: [0.0, 0.0, 0.249, 0.426]top_k_indices = np.argsort(stds)[-2:] # 取方差最大的 2 组print("选用的组编号:", top_k_indices) # 输出: [2 3]
效果:既避开“全废组”,又避开“崩溃样本”,还倾向选择“有挑战但可学”的中等难度样本 —— 让训练更稳、更快、更聪明。
这个策略我们叫 标准差排序(Standard Deviation Sorting) ,实验证明它显著提升了 PyVision-RL 的训练稳定性与最终性能(详见第 4.3 节)。
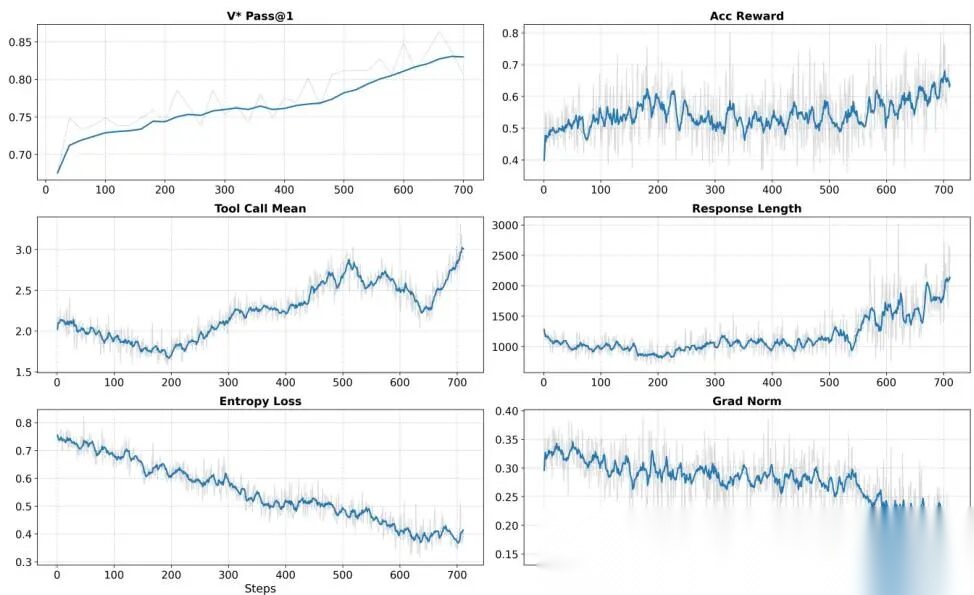
图 3. PyVision-Image 的 RL 训练动态。我们的训练算法实现了稳定的优化与持续提升的性能:熵损失(entropy loss)和梯度范数(gradient norm)平滑下降,表明 RL 动力学稳定;同时,在 上的验证准确率、准确率奖励(accuracy reward)、响应长度(response length)以及平均工具调用次数(mean number of tool calls)均持续上升,说明模型学会了可持续的、长视野的工具使用行为。
3.4. 优化与数据收集(Optimization and Data Collection)
移除 GRPO 中的标准差归一化(Removing Standard Deviation Normalization in GRPO)
我们采用 GRPO(Generalized Reinforcement Learning Policy Optimization,广义强化学习策略优化)作为强化学习(Reinforcement Learning, RL)训练的基础算法。你可以把 GRPO 理解为一种“打分+调优”的方法:模型(称为策略模型,记作 )对每个输入 (比如一张图或一段视频描述)生成多个回答(称为 rollout),然后根据这些回答的好坏来调整自身参数。
具体来说:
- 输入 来自训练数据集 ;
- 对每个 ,模型生成 个不同的回答(即 );
- 每个回答 都会得到一个整体奖励,这个奖励是基于整个回答的质量算出来的(例如是否正确调用了工具、是否完成任务等)。
关键改动来了:
原始 GRPO 在计算每个 rollout 的“优势值”(advantage,即这个回答比平均水平好多少)时,会对所有 个奖励做标准化处理 (减去均值、再除以标准差)。但我们去掉了除以标准差这一步 ——只保留“减去均值”。
为什么这么做?
因为最近一些针对大语言模型(LLM)的 RL 研究发现(Luo et al., 2025;Liu et al., 2025a,c;Zheng et al., 2025a),标准差归一化有时会让训练变得不稳定(比如某次采样中所有 reward 都特别接近,标准差极小,导致除零或数值爆炸)。去掉它后,优势值更平滑、训练更鲁棒。
公式(2)就是我们用的新优势值计算方式:
这里:
- 表示第 个 rollout 中第 个 token 的优势值(虽然名字里有 ,但其实当前版本是按整个 rollout 计算的,不是逐 token 细粒度);
- 是第 个 rollout 的总奖励;
- 就是这 个 rollout 奖励的平均值。
举个例子:
假设对一张图 ,模型生成了 4 个回答,对应奖励分别是:
那么均值是
于是各 rollout 的优势值为:
这个优势值后续会用来指导模型更新——让高优势的回答更可能被生成,低优势的回答减少出现概率。
下面是该公式的 Python 实现(可直接运行):
import numpy as npdef compute_advantages(rewards): """ 计算 GRPO 中去除了标准差归一化的优势值 rewards: list 或 np.array,长度为 G,每个元素是单个 rollout 的总奖励 返回:advantages,与 rewards 同长度的 numpy 数组 """ rewards = np.array(rewards) mean_reward = np.mean(rewards) advantages = rewards - mean_reward return advantages# 示例:用上面的例子验证rewards = [8.2, 6.5, 9.1, 7.0]advantages = compute_advantages(rewards)print("奖励:", rewards)print("均值:", np.mean(rewards))print("优势值:", advantages)
输出:
奖励: [8.2 6.5 9.1 7. ]均值: 7.7优势值: [ 0.5 -1.2 1.4 -0.7]
我们在第 4.2 节中通过实验验证了这一改动确实提升了训练稳定性与最终性能。
监督微调(SFT)数据收集与训练(SFT Data Collection and Training)
在开始强化学习之前,我们需要先让模型“学会基本功”——也就是能正确使用工具、进行多轮交互。这一步叫监督微调(Supervised Fine-Tuning, SFT) ,相当于给模型上一堂“实操课”。
我们构建了两个 SFT 模型:
- PyVision-Image-SFT :面向图像任务;
- PyVision-Video-SFT :面向视频任务。
PyVision-Image-SFT 数据构造
我们用 GPT-4.1(Zhao et al., 2025a)自动生成合成数据 (synthetic data),覆盖多种需要多轮工具调用的场景,包括:
- 多模态推理(MMK12):比如看图+读文字+推理逻辑关系;
- 医疗推理(GMAI-Reasoning):如分析医学影像报告并给出诊断建议;
- 图表理解(ChartQA、InfoVQA):识别柱状图趋势、提取表格数据;
- 通用视觉问答(MMPR):回答关于图像内容的开放问题。
接着我们做了两步过滤:
- 剔除答案错误的样本;
- 剔除工具调用少于 2 轮的样本(确保是“多轮交互”,而非一次性回答)。
最终留下 7,000 个高质量 SFT 样本 ,全部强调持续、多步的工具协作能力 。
PyVision-Video-SFT 数据构造
视频任务比图像更复杂,尤其要支持“按需抽取关键帧”(on-demand context construction)——即不把整段视频全塞进模型,而是在推理过程中动态决定哪几帧有用、再加载它们 。这是基座模型(base model)原本不具备的新能力。
因此我们专门构建了一个含 44,000 个样本 的视频 SFT 数据集,聚焦两类能力:
- 空间推理(Ouyang et al., 2025):如判断物体相对位置变化;
- 长视频推理(Chen et al., 2025b; 2024):如跨分钟级事件因果推断。
构造流程和图像版一致(同样用 GPT-4.1 合成 + 双重过滤)。
两个 SFT 模型都使用 LLaMA-Factory(Zheng et al., 2024) 工具,在单台机器上训练一个 epoch (即完整遍历一遍数据)。
强化学习(RL)数据收集与训练(RL Data Collection and Training)
SFT 只是“入门”,真正的“专精”靠 RL 完成。RL 的目标是让模型像智能体(agent)一样自主规划、试错、优化行为策略。
-
PyVision-Image 的 RL 训练聚焦两类任务:
数据来源:
-
视觉搜索:DeepEyes(Zheng et al., 2025c)、Mini-o3(Lai et al., 2025)→ 共 44,000 样本 ;
-
多模态推理:V-Thinker(Qiao et al., 2025b)、WeMath(Qiao et al., 2025c)。
-
视觉搜索(visual search) :如“在图片中找出所有穿红衣服的人,并统计人数”;
-
多模态推理(multimodal reasoning) :如结合图像+文本+代码工具解决数学题。
- PyVision-Video 的 RL 训练聚焦:
- 空间推理(spatial reasoning) :如跟踪视频中多个物体运动轨迹并判断碰撞;
- 数据来自 SpaceR(Ouyang et al., 2025)→ 15,000 样本 。
所有 RL 数据构成详见附录 B.2 节。
模型基础与预处理细节
- PyVision-Image 基于 Qwen2.5-VL-7B (一个多模态大模型);
- 由于它对图像尺寸敏感,我们沿用 Mini-o3 的图像缩放策略:
- 设定最小像素数
min_pixels = 3136(约 56×56); - 最大像素数
max_pixels = 2,000,000(约 1414×1414); - 超出范围的图像会被智能缩放(保持宽高比),避免显存爆炸或信息丢失。
RL 训练配置(统一用于 Image 和 Video 版本)
- 总训练步数:700 步 (steps);
- 使用 8 块 H100 GPU ;
- 超参数:
- 过采样批次大小(oversampling batch size):32
- 实际训练批次大小(training batch size):16
- 每组 rollout 数量(group size):8
- 学习率(learning rate):
小提示:“group size = 8”意味着每次更新参数前,我们会为同一个输入 生成 8 个不同回答( 到 ),然后用它们的奖励对比来算优势值——这就是前面公式(2)里的 。
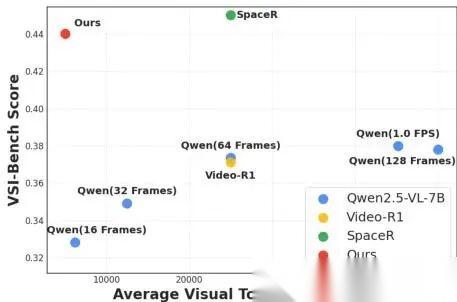 图 4. VSI-Bench 上的效率-性能权衡。得益于按需上下文构建(on-demand context construction),PyVision-Video 在推理时仅选择与任务相关的关键帧,因此在使用**显著更少视觉 token**的情况下,达到了比 Qwen2.5-VL 系列等固定帧采样基线更高的准确率。
图 4. VSI-Bench 上的效率-性能权衡。得益于按需上下文构建(on-demand context construction),PyVision-Video 在推理时仅选择与任务相关的关键帧,因此在使用**显著更少视觉 token**的情况下,达到了比 Qwen2.5-VL 系列等固定帧采样基线更高的准确率。
4. 实验(Experiments)
评估设置(Evaluation Setup)。在评估阶段,PyVision-Image 模型对 基准使用极低的采样温度(temperature)0.01,而对其他基准则使用温度 0.5 并配合 top-k=20 的采样策略;PyVision-Video 则统一使用 temperature=0.01。
由于强化学习(Reinforcement Learning, RL)微调赋予了模型长程推理(long-horizon reasoning)能力,我们把单次任务的最大交互轮数(max turn budget)设为 30 轮,并将最大上下文长度(context length)设为 32K token(注意:这里的 token 指的是 transformer 输入的基本单元,不翻译)。
我们在以下几类基准测试集上评估模型性能:
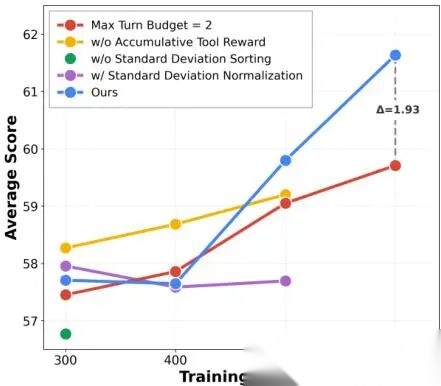
图 5. 训练组件消融实验(Ablation of training components)。我们在七个基准测试上报告平均性能(、HRBench-4K、HRBench-8K、MathVision、MathVerse、WeMath 和 DynamicMath),每组实验只移除或替换我们方法中的一个关键组件。
“我们的完整方法”(Ours)配置如下:
- 最大交互轮数设为 4;
- 引入累积工具奖励(accumulative tool reward);
- 在 rollout 分组时采用标准差排序 (standard deviation sorting);
- 在优势函数(advantage estimation)中去掉标准差归一化项 (removes standard deviation normalization term)。
其余所有对比配置,都仅相对于“Ours”改动恰好一个组件。
整体观察发现:
(1)采用标准差排序 ,或去掉标准差归一化项 ,都能稳定提升性能;
(2)引入累积工具奖励 ,或增大最大交互轮数 ,在训练后期带来更显著的性能提升。
例如,在训练第 600 步时,“最大轮数=4”的配置比“最大轮数=2”高出 1.93%。
视觉搜索(Visual Search)
为检验模型的具身式视觉感知能力 (agentic visual perception),我们在三个视觉理解基准上进行测试:
- (Wu & Xie, 2024):仅含 191 个样本,因此我们采用 avg@32 指标(即对每个问题生成 32 个回答,取其中最高分作为该题得分,再对全部题目取平均);
- HRBench-4K(Wang et al., 2025b);
- HRBench-8K(Wang et al., 2025b)。
举例说明 avg@32:假设某道题正确答案是“苹果”,模型生成了 32 个答案,其中第 7 个是“苹果”且被评分系统打满分,其余 31 个得分较低,则该题最终计为满分;对全部 191 题都这样处理后取平均,就是 。
多模态推理(Multimodal Reasoning)
我们在多个多模态数学理解基准上评估 PyVision-Image:
- MathVerse(Zhang et al., 2024):图文结合的数学应用题;
- MathVision(Wang et al., 2024a):以图像为输入的数学推理题(如几何图、统计图表);
- WeMath(Qiao et al., 2025a):强调世界知识与数学结合的题目;
- DynaMath(Zou et al., 2024):需动态理解图像中变化过程的数学题(如运动轨迹、状态演变)。
具身推理(Agentic Reasoning)
TIR-Bench(Li et al., 2025b)是一套需要多轮调用外部工具 (如计算器、OCR、搜索引擎等)才能完成的任务。我们在该基准上测试 PyVision-Image,重点考察它:
- 是否能自主规划多步操作;
- 是否能根据中间结果动态选择和调用合适工具(即“动态工具调用”能力)。
空间推理(Spatial Reasoning)
我们使用 VSI-Bench(Yang et al., 2024)来评估 PyVision-Video 的空间理解能力。该基准输入是一段视频(例如机器人在房间中移动的录像),要求模型理解物体位置、相对运动、空间关系等,属于典型的视频时空建模任务。
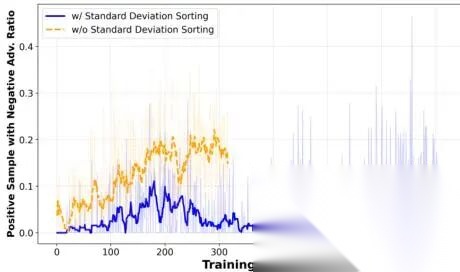
图 6. 具有负优势值的正样本比例(Ratio of positive samples with negative advantage)。
什么是“正样本”?——指模型实际走对了的推理路径(即最终答案正确)。
什么是“负优势值”?——在强化学习中,优势函数(advantage)衡量某一步动作比当前策略平均表现好多少;负值表示这步动作在当前 rollout 组里“相对更差”。
所以,“正样本但有负优势”是指:虽然整条路径答对了,但因同组其他路径调用了更多工具、显得更“积极”,导致它的优势被算成负数——这会误导模型惩罚本该鼓励的好行为。
图中对比了:是否启用标准差排序对这一问题的影响。结果显示:启用标准差排序后,这类“被误伤”的正样本比例在整个训练过程中显著下降,说明该设计有效缓解了优势估计偏差。
4.1. 主要结果(Main Results)
图像基准测试中表现强劲(Strong Performance on Image Benchmarks)
我们先来看 PyVision-Image 在几类图像理解任务上的整体表现。表 1(Tab. 1)汇总了它在三类任务上的得分:视觉搜索(visual search) 、多模态推理(multimodal reasoning) 和 智能体式推理(agentic reasoning) 。
为了理解这些对比的意义,我们把其他模型分成两类:
- 第一类 :使用预定义的静态工具集 (predefined static toolset),比如“裁剪(crop)”、“放大(zoom-in)”这类固定操作。代表模型有:
- Pixel-Reasoner(Su 等,2025a)
- Mini-o3(Lai 等,2025)
- DeepEyes(Zheng 等,2025c;Hong 等,2025)
- 第二类 :把Python 解释器本身当作基础工具(primitive tool) ,让模型通过写 Python 代码来调用任意函数(如图像处理、数学计算、逻辑判断等)。这类更灵活,代表模型有:
- Thyme(Zhang 等,2025b)
- CodeV(Hou 等,2025)
- CodeDance(Song 等,2025)
- CodeVision(Guo 等,2025b)
- DeepEyes-v2(Hong 等,2025)
PyVision-Image 属于第二类——它不靠人工设计的几个按钮式工具,而是自主生成 Python 代码来完成任务 ,这是它“智能体化(agentic)”的核心体现。
具体效果如何?来看数据:
- 在视觉搜索任务上(例如:“图中穿红衣服的人站在第几排?”),PyVision-Image 全面超越所有对手:
- 相比基线模型 Qwen2.5-VL-7B,它在 V* 上提升 ** +10.2%** ,
- 在 HRBench-4K 上提升 ** +6.5%** ,
- 在 HRBench-8K 上提升 ** +6.4%** 。
这说明:PyVision-Image 不只是“看清楚”,还能精准定位细节、理解空间关系、跨多图逐步聚焦目标 ——也就是所谓“细粒度视觉定位(fine-grained visual localization)”和“智能体式感知(agentic perception)”能力显著增强。
- 在多模态推理任务上(比如 DynaMath、MathVerse、WeMath,这些任务需要结合图像+数学公式+文字进行复杂推理),它也刷新了 SOTA(state-of-the-art,当前最优):
- 超越此前最强的 DeepEyes-v2,分别提升 ** +4.4%** (DynaMath)、** +3.1%** (MathVerse)、** +9.6%** (WeMath)。
换句话说:强化学习(RL)带来的“主动调用工具”能力,不仅帮它看得更准,还让它算得更对、想得更深 ——从纯感知跃迁到了“感知+推理”的联合优化。
- 在智能体式推理任务 (需多轮调用工具,比如“先找人脸→再识别人物→再查其职业→最后总结关系”),它比基线模型 Qwen2.5-VL-7B 提升 ** +3.8%** 。
这表明:模型不仅能“单步调用”,还能规划长链条动作(long-horizon reasoning) ,而动态工具调用机制(dynamic tool invocation)正是支撑这种规划的关键。
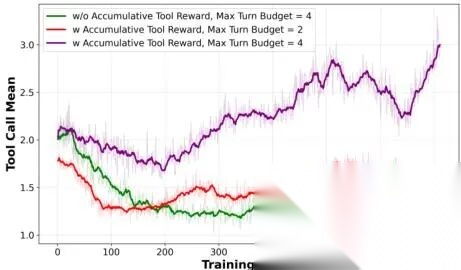 图 7. 强化学习训练过程中平均工具调用次数变化。我们做了消融实验(ablation),分别去掉“累积工具奖励(accumulative tool reward)”和限制“最大交互轮数(max turn budget)”。结果显示:若不设累积奖励,模型很快放弃调用工具,平均调用次数迅速掉到很低水平;而加入该奖励后,模型会持续、积极地使用工具,且最大轮数设得越高,工具调用增长越快、越多。
图 7. 强化学习训练过程中平均工具调用次数变化。我们做了消融实验(ablation),分别去掉“累积工具奖励(accumulative tool reward)”和限制“最大交互轮数(max turn budget)”。结果显示:若不设累积奖励,模型很快放弃调用工具,平均调用次数迅速掉到很低水平;而加入该奖励后,模型会持续、积极地使用工具,且最大轮数设得越高,工具调用增长越快、越多。
视频基准测试中的标记效率(Token Efficiency on Video Benchmarks)
视频比图像信息量大得多,但传统多模态大模型(MLLM)处理视频时有个通病:不管有没有用,一律均匀采帧 (比如每秒取 1 帧 → 1 FPS)。这导致大量冗余帧被塞进上下文,浪费视觉 token(visual token),拖慢速度、抬高成本。
PyVision-Video 换了一种思路:按需检索帧(on-demand frame retrieval) 。
它不预设采样率,而是让模型自己“边想边取”:
- 先用语言或逻辑推理判断“哪段视频可能含关键信息”;
- 再用 Python 代码(如
cv2.VideoCapture+ 条件过滤)从完整视频中动态提取最有信息量的关键帧(informative key frames) ; - 最后只把这几帧送入 MLLM 上下文。
这就像你查资料时不一页页翻整本百科全书,而是先看目录、再精准跳到第 37 页第 2 段——省时、省力、更准。
定量来看(图 4):在视频理解基准 VSI-Bench 上,
| 模型 | 平均视觉 token 数 / 样本 | 准确率 |
|---|---|---|
| PyVision-Video | ≈ 5,000 | 44.0% |
| Qwen2.5-VL-7B(1.0 FPS) | ≈ 45,000 | 38.0%(其最高分) |
| Video-R1 | ≈ 25,000 | 未达 44.0% |
| SpaceR | ≈ 25,000 | 45.6% |
PyVision-Video 仅用 1/9 的视觉 token (5K vs 45K),就达到接近甚至超过其他模型的性能。SpaceR 虽然精度略高(45.6%),但它仍依赖固定采样策略;而 PyVision-Video 是首次实现“少 token + 高精度 + 可解释性”三者兼顾 ——因为每帧都是模型自己选的,你知道它为什么选这一帧。
表 2(Tab. 2)进一步按任务类别拆解 VSI-Bench 结果(Yang 等,2024):PyVision-Video 在多个子类(如 spatial reasoning、temporal reasoning)上均优于 Video-R1 和 VITAL,并比 Qwen2.5-VL-7B 整体提升 ** +7.3%** 。
图 19 和图 20(Figs. 19 and 20)给出了直观示例:它们可视化展示了 PyVision-Video 如何在一段长视频中,自动定位并选取仅 3–5 帧 ,就足以完成复杂的“空间关系推理”(例如:“小球从左向右滚过桌子,中途被猫碰了一下,最终停在哪一侧?”)——其余几十上百帧全部跳过。
这再次印证:让模型做“决策者”,而非“执行器”,是提升效率与能力的关键跃迁。
4.2. 消融研究(Ablation Study)
为了搞清楚我们方法中每个组件到底起了多大作用,我们做了一整套“消融实验”——也就是每次只拿掉一个组件,其他都保持不变,看看模型表现会怎么变。具体测试了四个关键设计:最大轮次预算(Max Turn Budget) 、累积工具奖励(Accumulative Tool Reward) 、标准差排序(Standard Deviation Sorting) ,以及是否移除标准差归一化(Removing Standard Deviation Normalization) 。所有实验都以我们的完整训练算法作为基准(baseline),然后逐一“砍掉”一个部分进行对比。最终结果汇总在图5(Fig. 5)中。
最大轮次预算(Max Turn Budget)
想象一下,让一个视觉智能体(vision agent)解决一个问题时,它最多能“思考几步”?这个“最多几步”,就是“最大轮次预算”。在我们的基线设置里,这个值设为 4(即最多尝试 4 轮动作/推理)。我们还试了一个更保守的设置:只允许最多 2 轮。
有趣的是,刚开始训练时(比如训练到第 300 或 400 步),把预算从 2 提到 4 并不会立刻让模型变强——成绩几乎一样。但随着训练继续(比如到第 600 步),差距就出来了:用 4 轮预算训练的模型,明显比只用 2 轮的好很多。
换句话说 :更大的轮次预算本身不加速起步,但它抬高了模型能力的“天花板”,让模型在后期优化中能走得更远、想得更深。
累积工具奖励(Accumulative Tool Reward)
在基线训练中,我们给模型一种额外鼓励:每当它正确调用一个工具(比如 OCR、目标检测、颜色识别等),不仅在最后给总分,还在过程中按步累计加分——这个加分项叫“累积工具奖励”,公式(1)里用系数 0.1 控制它的强度。
为了看它有没有用,我们做了个对照实验:把系数直接设为 0(相当于完全关掉这个奖励)。结果发现:
- 工具调用次数明显变少了(见图7);
- 但在训练早期(前 500 步左右),关掉它的模型反而分数略高一点;
- 可是一过 500 步,它的曲线就开始往下掉,很快被基线甩开。
举个例子 :就像教学生解多步应用题,一开始只看答案对不对(终局奖励),他可能更快“蒙对”简单题;但加上“每写对一步就给小红花”(累积工具奖励),虽然开头慢点,却帮他养成了规范拆解问题的习惯,最终能稳稳拿下复杂题。这说明:累积工具奖励不是为了抢开局,而是为了练“长程推理力”。
标准差排序与归一化(Standard Deviation Sorting and Normalization)
这部分涉及 RL 训练中一个关键技术细节:如何更靠谱地算出“某个动作到底好不好”(即优势函数 advantage)。我们用了两个相关操作:
- 标准差排序(Standard Deviation Sorting) :把一批训练样本按它们的奖励波动程度(标准差)从小到大排个序,让模型先学稳定、可靠的样本,再逐步挑战波动大的。
→ 如果去掉它,图5显示:训练初期性能明显抖动、下降,说明它像“学习脚手架”,帮模型在噪声大的早期阶段站稳脚跟。 - 标准差归一化(Standard Deviation Normalization) :传统做法常在算优势值时,把一批 reward 的标准差当作分母来缩放,试图让信号更平稳。
→ 但我们发现:保留这个归一化,反而让训练曲线一直上下乱跳(见图5趋势),收敛变慢甚至不稳定。
原因直觉 :当 reward 本身稀疏或噪声大时,强行用标准差去“标准化”,等于放大了本就不准的波动,反而干扰了梯度方向。所以,我们选择去掉它 ,让优势估计更鲁棒。
4.3. 分析(Analysis)
强化学习训练动态(RL Training Dynamics)
我们用图3展示了 PyVision-Image 的强化学习(Reinforcement Learning, RL)训练过程的变化趋势。整个训练过程非常稳定,具体表现在以下几个方面:
- 熵损失(entropy loss) 和 梯度范数(gradient norm) 随训练轮次稳步下降 → 说明模型的输出越来越确定(不再“犹豫不决”),且参数更新越来越平稳(没有剧烈抖动);
- 平均工具调用次数(mean number of tool calls) 、准确率奖励(accuracy reward) 和 响应长度(response length) 持续上升 → 表明模型在每个对话回合(episode)中,越来越愿意、也越来越有能力进行多步推理和工具交互(比如先看图、再OCR识别文字、再搜索、再总结),而不是只答一句就结束。
举个例子:
- 初期模型可能只说:“这是一张猫的照片。”(1次响应,0次工具调用)
- 后期模型会说:“图中有一只橘猫坐在窗台上(视觉理解)。我检测到右下角有文字‘2024.05’(OCR工具调用)。经搜索,该日期可能对应某展览开幕时间(检索工具调用)。综上,这张图很可能来自‘城市动物摄影展’(推理总结)。”(1次长响应,3次工具调用,高准确率奖励)
此外,模型在验证集 上的表现(如任务完成率、答案正确率)在整个训练过程中单调提升 (一直变好,从不倒退),说明它不仅记住了训练数据,还能真正泛化到没见过的新任务——这是 RL 训练成功的强信号。
标准差排序(Standard Deviation Sorting)是怎么起作用的?
我们的消融实验(ablation study)发现:一旦去掉“标准差排序”这个模块,模型性能明显下降(见图5) 。这说明它不是可有可无的“装饰”,而是关键组件。我们从两个角度解释它为什么有效:
第一,它实现了“课程学习”(Curriculum Learning)
想象你教一个学生解数学题。你会先给简单题(全对)、再给难题(全错)、最后给“跳一跳够得着”的中等难度题(有的对、有的错)——这类题最能促进进步。
在 RL 中,“标准差”(standard deviation)就是衡量一组 rollout(一次完整交互尝试)中奖励值的波动程度 。
- 如果某组里所有 rollout 奖励都很高(全对)或都很低(全错),那标准差就小 → 这类样本提供的学习信号很弱(就像学生做10道全会的题,学不到新东西);
- 如果某组里奖励有高有低(有的对、有的错),标准差就大 → 说明这批样本难度适中,正好适合当前策略水平去“纠错+巩固”。
所以,“标准差排序”本质上是自动帮模型挑出当前阶段最有营养的训练样本 ,符合课程学习原则(Jiang et al., 2024)。
用公式表示:对每组 (含 个 rollout),计算其奖励 的标准差:
其中
对应 Python 实现如下(以一组 5 个奖励为例):
import numpy as np# 示例:某组5个rollout的奖励值(有的高、有的低)rewards = [0.8, 0.2, 0.9, 0.1, 0.7]# 计算均值和标准差mean_r = np.mean(rewards)std_r = np.std(rewards, ddof=0) # 总体标准差(非样本标准差)print(f"均值: {mean_r:.3f}, 标准差: {std_r:.3f}")# 输出: 均值: 0.540, 标准差: 0.336 ← 较高,说明这组值得优先学习
第二,它减少了“伪负优势样本”(positive samples with negative advantages)的干扰
在 RL 的 PPO 算法中,我们会对每个 rollout 计算一个叫 advantage(优势) 的量,用于判断“这次行为比平均表现好多少”。它的常见估计算法(如GAE)依赖于组内归一化 :同一组 rollout 的 advantage 是相互比较出来的。
问题来了:
- 一个 rollout 可能完全正确(比如准确回答了问题),但因为同组其他 rollout 更优秀(比如用了更少工具就答对了),它的 advantage 就变成负数;
- 这样一来,即使它是“好行为”,也会在策略更新时被惩罚(因为 advantage < 0),导致模型慢慢“忘记”这种合理行为——我们称这类样本为伪负优势的正样本 。
标准差排序通过优先选择“奖励方差大”的组,天然稀释了这种极端对比(即避免把“超优”和“普通正确”硬塞进同一组),从而大幅减少这类有害样本。图6显示:使用该方法后,这类样本在整个训练过程中的占比显著下降。
换句话说:它不只是“选好题”,还顺便“避开了坑题”——既提升正向学习效率,又防止优化方向被带偏。
5. 结论(Conclusion)
我们提出了 PyVision-RL:一个统一的、具备智能体(agentic)能力的多模态框架,专门用于图像(image)和视频(video)的理解任务。它的核心特点是——用 Python 作为动态工具调用的语言 。换句话说,它不像传统模型那样把所有功能“硬编码”进模型内部,而是让模型像程序员一样,在运行时实时调用 Python 函数(比如 cv2.resize()、PIL.Image.open()、torch.nn.functional.interpolate() 等)来完成具体视觉操作。这种“边想边做”的方式,极大提升了灵活性和可扩展性。
但问题是:让一个大语言模型(LLM)自主调用工具并完成复杂视觉任务,就像教新手司机一边看导航、一边换挡、一边避让行人——很容易出错或陷入死循环。为此,我们设计了一套专为工具调用强化学习(tool-use RL)量身定制的训练数据生成策略,叫作 过采样–过滤–排序框架(Oversampling–Filtering–Ranking framework) :
- 过采样(Oversampling) :对高质量的交互轨迹(例如“先裁剪→再识别文字→最后推理答案”这样成功走完多步的完整过程)人为复制多次,增加它们在训练数据中的权重;
- 过滤(Filtering) :自动剔除明显错误的轨迹,比如调用了一个根本不存在的函数(
import torch; torch.xxx()报错)、输入了非法参数(resize(-1, 256)宽度为负)、或者模型反复重复同一动作(连续 5 轮都输出print("hello")); - 排序(Ranking) :对剩余的有效轨迹,按完成任务的准确率、步骤简洁性、token 消耗量等指标打分排序,优先让模型学习更优、更高效的交互路径。
举个例子:
假设模型要回答“图中穿红衣服的人手里拿的是什么?”,可能的轨迹有:
① detect_objects() → filter_by_color("red") → crop_person() → ocr() → answer() (8 步,准确)
② ocr() → ocr() → ocr() (3 步全失败,被过滤)
③ detect_objects() → detect_objects() → detect_objects() (重复无进展,被过滤)
④ detect_objects() → filter_by_color("red") → crop_person() → classify_object() (7 步,准确,比①更短,排更高)
→ 最终训练时,④的权重 > ①,②③直接丢弃。
我们还发现一个关键规律:放宽单次交互的最大步数限制(max turn budget),模型性能上限会系统性提升 。
这很好理解:就像考试限时 1 分钟 vs 5 分钟,更多“思考+尝试+修正”的机会,自然能解决更复杂的推理问题。实验显示,把最大步数从 4 提到 8,PyVision-Image 在 MMMU 基准上的准确率提升了 6.2%。
实际效果如何?
- PyVision-Image 在多个主流图像理解基准(如 MMMU、DocVQA、ChartQA)上达到领先水平,显著超越此前所有基于智能体的多模态大语言模型(agentic MLLMs);
- PyVision-Video 则展现出强大的空间推理能力(例如判断物体运动方向、跟踪遮挡关系),同时大幅减少视觉 token 使用量——在 VSI-Bench 视频理解评测中,它用更少的计算资源(更低的 token 开销),实现了媲美甚至优于更强基线模型的准确率,做到了又快又准 。
总结来说,这两组结果共同说明:
动态工具调用(dynamic tooling) 让模型不再受限于预训练时学到的固定能力,而是按需加载真实世界工具;
持续多轮交互(sustained interaction) 让模型能像人类一样“分步拆解、逐步验证、动态调整”,真正实现深度多模态推理。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献230条内容
已为社区贡献230条内容

所有评论(0)