Claude Code 的安全边界:哪些事它不会帮你做?
那天我想批量抓取一个竞品的定价页面,做市场调研用。
需求很正常,做出海产品,了解竞争对手定价是基本功。我在 Claude Code 里描述了需求,它停了几秒,然后给我输出了一段话:大意是它可以帮我写通用的 HTTP 请求代码,但不会帮我写专门针对某个网站绕过反爬的逻辑。
我当时有点懵。不是生气,是没想到它会这么回答。
然后我意识到:我需要搞清楚它的边界在哪里,不然我会在错误的方向上浪费时间。
大多数人踩的坑不是"问了坏问题",是"不知道边界在哪"
用 Claude Code 做出海开发,有个特别常见的场景:你在做一个正经产品,但某个技术需求擦到了边界。
比如:需要解析竞品页面的数据结构。比如:想模拟用户行为测试自己的限流逻辑。比如:做安全加固,需要理解某类攻击的原理。
这些需求本身是合法的、正当的,但如果你 Prompt 写得不够清晰,很可能触发拒绝——不是因为你想做坏事,是因为它无法分辨上下文。
反过来也有问题:有人以为 AI 什么都能做,结果在一些根本不会被满足的需求上绕了很久,消耗了大量时间和精力。
我这篇文章想干的事情很简单:把边界画清楚,让你不用浪费时间在错误的方向上试探。
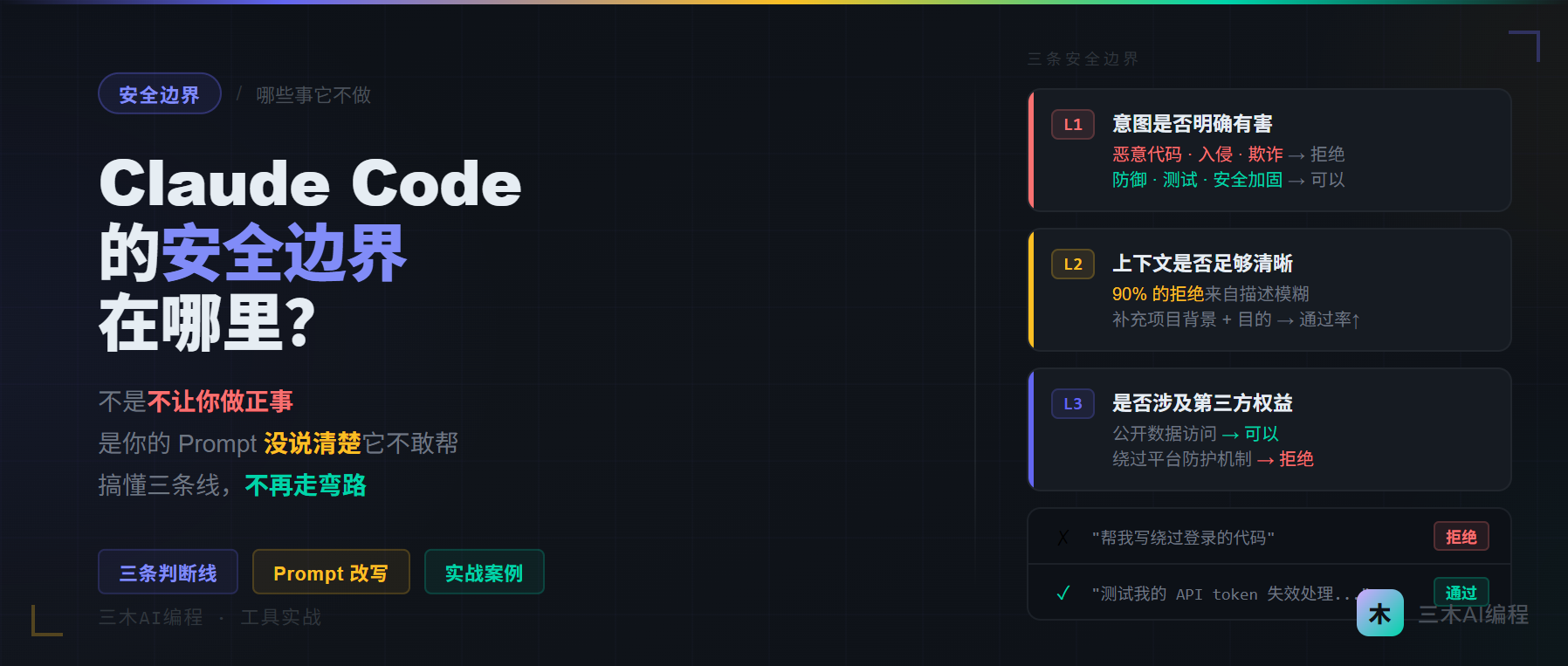
它的安全边界,本质上是三条线
理解清楚了这三条线,你就能预判它会不会帮你,以及怎么改 Prompt 让它帮你。
第一条线:意图是否明确有害
Claude Code 不会帮你做的事,核心判断标准是:这个请求是否有明确的伤害目标。
明确有害的,比如:
-
写恶意代码、病毒、勒索软件
-
帮某个具体的网站或系统实现入侵
-
绕过某个平台的身份验证机制
-
生成钓鱼邮件或欺诈性内容
这些它不会做,不管你怎么包装需求,不管你说自己是"安全研究员"还是"测试自己的系统"。
但注意:拒绝有害请求,和拒绝安全相关的合法开发是两件事。
你想了解 XSS 攻击原理、想给自己的应用写输入校验逻辑、想理解 SQL 注入的机制——这些它完全可以帮你,因为目的是防御,不是攻击。
第二条线:上下文是否足够清晰
这条线是最多人踩坑的地方,也是最容易通过调整 Prompt 解决的地方。
它拒绝你,很多时候不是因为你的需求有问题,是因为你的描述让它无法判断意图。
比如"帮我写一段绕过登录的代码"——意图完全不明,它不知道你是要测试自己的系统、还是要入侵别人的系统,所以默认拒绝。
但换成"帮我写一段单元测试,模拟绕过 JWT 验证的情况,用于测试我的 API 在 token 失效时的异常处理逻辑"——意图清晰,完全可以帮你。
说人话就是:你提供的上下文越具体,它越能准确判断,拒绝的概率越低。
这条规律在正当需求上百分之百有效。如果加了足够的上下文它还是拒绝,那通常说明需求本身确实有问题。
第三条线:是否涉及第三方权益
这条线最微妙,也是做出海开发最容易碰到的。
帮你爬取竞品数据、绕过某个 API 的频率限制、模拟大量虚假注册——这类需求涉及到第三方平台的权益,它会比较谨慎。
不是一律拒绝,是会视情况而定。
举个具体例子:
帮我写一个脚本,访问 competitor.com 的定价页面,解析 HTML 里的价格数据
这个它可能会帮,因为访问公开页面本身不违法。
帮我写一个脚本,模拟浏览器行为绕过 competitor.com 的反爬机制,批量抓取他们的用户评论数据
这个大概率拒绝,因为"绕过反爬"明确针对第三方的防护机制。
实际遇到边界时,怎么处理
情况一:需求本身合法,但 Prompt 触发了误判
这种最好处理,改 Prompt 就行。
改写原则:
-
说明你的项目背景(这是我自己的 SaaS 产品)
-
说明你的目的(用于测试 / 加固安全性 / 处理异常情况)
-
把"攻击性"词汇换成"防御性"词汇
原始 Prompt(容易被拒绝):
帮我写一个脚本,测试我的 API 有没有 rate limiting 漏洞
改写后(通过率高):
我正在给自己的 SaaS API 添加 rate limiting 功能,想写一个测试脚本验证限流逻辑是否正确。需要模拟同一个 IP 在 60 秒内发出超过 100 次请求,观察第 101 次是否返回 429 状态码。我用的是 Next.js API Routes,rate limiting 用的是 upstash/ratelimit。
两个 Prompt 的本质需求一样,但第二个里有三个关键信息:这是我自己的系统、目的是测试防御功能、技术栈具体。
情况二:需求合法但它还是拒绝,怎么办
这种情况我遇到过,处理方法是把需求拆解,拿走触发点,保留你真正需要的部分。
举个实际例子:
我需要写一个功能,检测同一个邮箱有没有注册过多个账号(防止滥用免费试用)。
直接问"帮我写检测账号滥用的逻辑"——它比较保守,给的方案过于简单。
我改成了两个步骤:
第一步,问它 Prisma 怎么查一个邮箱域名对应的所有账号:
用 Prisma 查询 User 表,找出邮箱域名相同的所有用户,按域名分组,返回每个域名下的用户数量和注册时间列表
第二步,问它怎么设计规则:
我想限制同一邮箱域名在 7 天内的免费注册数量,上限是 3 个。帮我设计这个校验逻辑,在用户注册时触发,用 NextAuth 的 signIn callback 实现
两个问题都顺利拿到了答案。
说人话就是:把一个敏感的大需求,拆成几个不敏感的小需求,逐步组合。
情况三:真的撞到了它不做的事
有些事它就是不做,改再多 Prompt 也没用。
这时候最好的选择是:接受它,换思路。
我自己遇到过一次明确的拒绝——想让它帮我写一段代码,模拟用户在没有同意条款的情况下完成支付流程,用来测试我的合规检查逻辑。
它解释说它不会帮我构造"绕过用户同意"的代码,因为这个模式可以被用于实际的欺骗性支付流程。
我当时有点崩溃,因为我的需求是测试,不是欺骗。
但我换了个思路:与其测试"绕过",不如测试"正确阻断"。我让它帮我写测试用例,验证在用户没有勾选同意的情况下,我的后端是否正确返回了 400 错误、是否记录了日志、是否阻止了 Stripe Checkout 的创建。
测试结果更好,覆盖面更完整。
有时候它的拒绝,是在逼你找到一个更好的解题路径。
踩坑环节
坑一:以为加了"教育目的"就能绕过限制
早期我以为在 Prompt 里加上"这只是学习用途"或者"仅供研究",就可以让它放松。
试了几次发现这个策略完全没用。它判断的是需求本身的风险,不是你贴的标签。
反而有时候这种强调会让它更警惕,因为正常的开发需求不需要特别声明自己是无害的。
解决方案: 不要用声明来证明自己,用具体的项目上下文来证明。你的技术栈、你的功能模块、你的测试场景——这些具体信息才是有效的信号。
坑二:以为被拒一次就没戏了,直接放弃
有一次我问它帮我处理一个涉及用户数据导出的功能,第一次被拒了,我以为这个方向走不通,换了个更复杂的方案折腾了两小时。
后来我重新描述了需求,加了业务场景(用户主动请求导出自己的数据,GDPR 的数据可携带权要求),它立刻帮我写了完整的导出逻辑。
第一次拒绝和第二次接受,需求完全一样,就是上下文不同。
解决方案: 被拒了不要直接放弃,先思考它拒绝的可能原因,补充缺失的上下文,重新问。给自己三次机会,三次都拒才算真正撞线了。
总结
它的边界不是枷锁,是一个强制你把需求想清楚的过滤器。
你的需求越具体、上下文越充分,这个过滤器越透明。模糊的需求,不仅 Claude Code 搞不定,人也搞不定。
最后一个问题: 你有没有遇到过"需求完全正当,但被 AI 拒绝"的情况?你当时是怎么重新描述需求的——是补充了上下文,还是换了一个方向表达?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)