【RL】Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers
好的,以下是这篇论文的完整中文翻译。
通过对齐训练和推理路由器来稳定MoE强化学习
作者: Wenhan Ma†‡∗, Hailin Zhang‡, Liang Zhao‡, Yifan Song†‡, Yudong Wang†‡, Zhifang Sui†⋄, Fuli Luo⋄
† 北京大学计算机学院,多媒体信息处理国家重点实验室
‡ 小米LLM-Core团队
摘要
强化学习(RL)已成为增强大型语言模型能力的关键方法。然而,在混合专家(MoE)模型中,路由机制常常引入不稳定性,甚至导致灾难性的强化学习训练崩溃。我们分析了MoE模型的训练-推理一致性,并发现这两个阶段的路由行为存在显著差异。此外,即便在完全相同的条件下,路由框架在重复的前向传播中也可能产生不同的专家选择。为了解决这一根本性的不一致问题,我们提出了序列生成路由重放(Rollout Routing Replay, R3),该方法记录来自推理引擎的路由分布,并在训练过程中进行重放。R3显著降低了训练与推理之间的策略KL散度,并在不影响训练速度的情况下缓解了极端差异。在多种设置下的大量实验证实,R3成功地稳定了RL训练,防止了崩溃,并优于GSPO和TIS等方法。我们相信这项工作能为稳定MoE模型中的RL训练提供新的解决方案。
1. 引言
强化学习(RL)已成为大型语言模型(LLM)后训练阶段的基石 (Guo et al., 2025; OpenAI, 2024; Ouyang et al., 2022)。通过利用大规模RL,LLM获得了应对复杂问题所需的高级能力,包括通过更深刻和更长的推理来解决竞赛级数学问题 (Guo et al., 2025) 和实用的代码智能体任务 (Luo et al., 2025a)。
基于LLM的RL面临的一个关键挑战是平衡效率和稳定性,而后者对于可靠的性能至关重要。现代RL框架通常为推理和训练阶段采用不同的引擎(例如,用于序列生成(rollout)的SGLang (Zheng et al., 2024) 和用于训练的Megatron (Shoeybi et al., 2019))。这种架构上的分离可能导致不同的token概率,从而可能引发灾难性的RL崩溃 (He and Lab, 2025)。为了缓解这种差异,Yao et al. (2025) 在策略更新中引入了重要性采样机制,而He and Lab (2025) 则引入了专门的计算核心来减少LLM推理过程中的不确定性。然而,在实践中,现有方法并不能完全解决在混合专家(MoE)模型上进行RL训练时加剧的离策略(off-policy)问题。
在这项工作中,我们发现路由分布是导致MoE RL不稳定的关键因素。在MoE模型中,路由器为每个输入token动态选择并激活一部分专家。与密集模型相比,MoE模型中多样的路由决策导致训练和推理之间的策略差异更大。我们没有采用像丢弃差异过大的数据 (Zhao et al., 2025a) 这样的变通方法,而是建议从根本原因入手解决这种不稳定性:即路由分布本身。
具体来说,我们提出了序列生成路由重放(R3),这是一种简单而有效的方法,用于稳定MoE模型的RL训练。R3的工作原理是,在序列生成过程中捕获推理引擎的路由分布,并将其直接重放到训练引擎中。这个过程显著缩小了训练和推理之间的差距,表现为不同引擎产生的logits的KL散度大幅降低。结果是,两个阶段之间概率差异显著的token数量减少了大约一个数量级。
在真实的、有可验证奖励的RL(RLVR)任务中,使用MoE模型时,R3在训练稳定性和性能方面表现出显著的优势。与现有的旨在稳定RL训练的方法相比,我们的方法在效率和整体性能上都显示出显著的改进。此外,它既适用于同策略(on-policy)也适用于小批量式离策略(mini-batch style off-policy)的RL场景,这突显了我们方法的鲁棒性。
我们的主要贡献如下:
- 我们系统地识别并分析了MoE模型中训练和推理之间的路由分布差异,并强调了其在训练不稳定性中的作用。
- 我们提出了序列生成路由重放(R3),该方法在训练引擎内部重用推理时的路由分布,以对齐训练和推理的路由行为。
- 我们在多种RL设置(多/单小步训练,基础/SFT模型)中将R3应用于MoE强化学习,并表明R3在稳定性和整体性能方面优于GSPO和TIS。
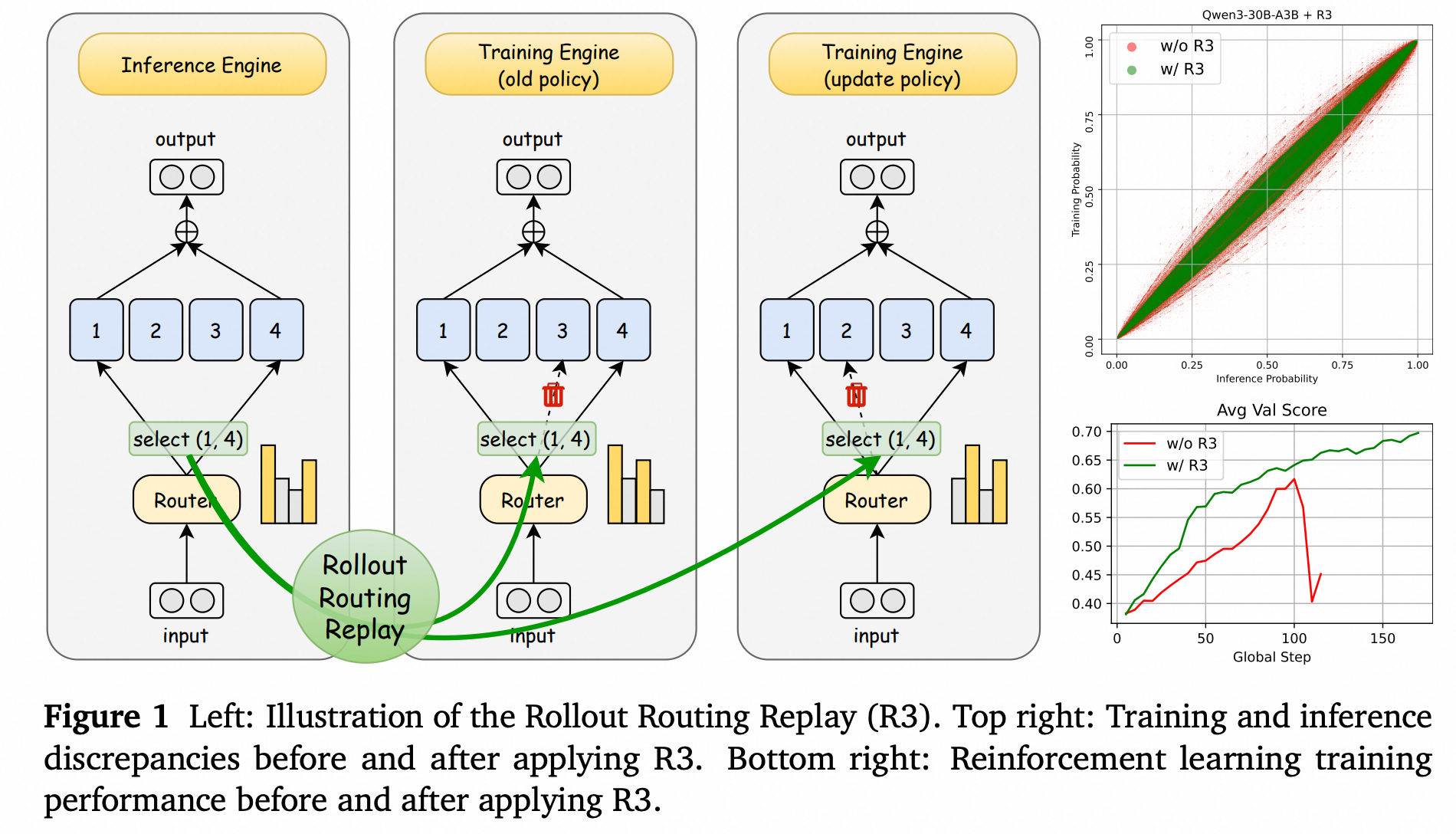
(图1)
- 左图: 序列生成路由重放(R3)的示意图。在推理引擎中生成序列时,记录下路由器的选择(例如,选择了专家1和4)。在训练引擎中计算旧策略和更新策略时,强制使用相同的专家选择。
- 右上图: 应用R3前后训练和推理概率的差异。应用R3后,散点更集中于y=x对角线。
- 右下图: 应用R3前后强化学习训练的性能。应用R3后,验证分数(Avg Val Score)更高且更稳定,而没有R3的训练则在中途崩溃。
2. 预备知识

符号表示
我们考虑一个由参数𝜃自回归语言模型,表示为一个策略𝜋𝜃,它根据查询𝑥 ∈ D生成一个响应𝑦。序列的似然函数由以下分解给出:𝜋𝜃(𝑦|𝑥) = ∏ |𝑦| 𝑡=1 𝜋𝜃(𝑦𝑡|𝑥, 𝑦<𝑡),其中|𝑦|是序列长度。𝜋infer和𝜋train分别表示在推理引擎和训练引擎中运行的策略。
近端策略优化(PPO)
(Schulman et al., 2017) 是强化学习中策略优化的基石算法。对于给定的查询𝑥,PPO通过最大化以下目标来更新策略𝜋𝜃:
JPPO(𝜃) = E𝑥∼D,𝑦∼𝜋infer(𝜃old)(·|𝑥) [ 1 |𝑦| |𝑦|∑︁ 𝑡=1 min ( 𝑤𝑡(𝜃)𝐴𝑡, clip(𝑤𝑡(𝜃), 1 − 𝜀, 1 + 𝜀)𝐴𝑡 ) ] (1)
token 𝑦𝑡在序列𝑦中的重要性采样比率𝑤𝑡(𝜃)定义为:
𝑤𝑡(𝜃) = 𝜋train(𝜃)(𝑦𝑡|𝑥, 𝑦<𝑡) / 𝜋train(𝜃old)(𝑦𝑡|𝑥, 𝑦<𝑡)
优势值𝐴𝑡通常由一个独立的价值模型估计,𝜀是重要性比率的裁剪范围。为简洁起见,我们省略了KL正则化项。
一个关键的不一致性源于通常的做法:使用不同的引擎进行序列生成和训练,即数据由推理策略(𝜋infer)采样,但损失函数却使用训练策略(𝜋train)计算,如公式1所示。这种策略不匹配导致了强化学习中的训练不稳定,而在MoE模型中,我们发现这个问题主要源于路由器的不一致性。我们提出的解决方案缓解了这一根本性问题,使其具有广泛的适用性,并且与近期的策略优化框架如GRPO (Shao et al., 2024)、GSPO (Zheng et al., 2025) 和 DAPO (Yu et al., 2025) 是正交且兼容的。
3. 训练-推理差异
RL框架中的训练-推理差异经常导致训练不稳定和模型崩溃。在本节中,我们证明这种策略不匹配在MoE模型中被显著放大,主要源于不一致的路由分布。此外,我们观察到,即使是多次运行相同的训练框架,也可能产生不同的token概率,进一步加剧了RL训练的不稳定性。
3.1 MoE模型中训练与推理的策略差异
我们使用一个MoE模型 Qwen3-30B-A3B (Yang et al., 2025) 进行实验,分析训练和推理引擎之间的策略差异。首先,我们使用SGLang推理引擎为2048个数学问题生成答案,并保存每个生成token的概率。这个过程产生了大约2000万个响应token。然后,将这些响应传递给Megatron训练框架,以获得训练引擎分配的相应概率。我们使用几个指标来量化这两种概率分布之间的差异。
KL散度估计
令𝑇为所有响应token的集合,我们使用Schulman (2020) 提出的𝑘3方法来估计训练和推理概率分布之间的KL散度:
DKL(𝜋train(𝜃) || 𝜋infer(𝜃)) ≈ 1/|𝑇| ∑︁ 𝑡∈𝑇 [ 𝜋train(𝜃)(𝑡)/𝜋infer(𝜃)(𝑡) − 1 − log(𝜋train(𝜃)(𝑡)/𝜋infer(𝜃)(𝑡)) ] (2)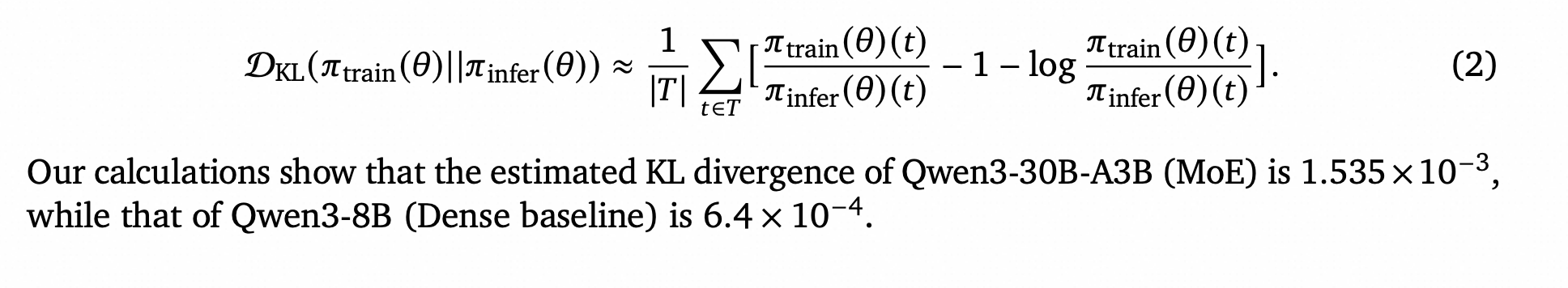
我们的计算显示,Qwen3-30B-A3B(MoE)的估计KL散度为1.535×10⁻³,而Qwen3-8B(密集模型基线)的KL散度为6.4×10⁻⁴。
可视化
为了可视化MoE模型的训练-推理差异,我们随机采样了1000万个响应token,并绘制了一个散点图,其中x轴是SGLang的概率,y轴是Megatron的概率。点围绕𝑦=𝑥线的集中程度表示一致性程度。如图2a和2c所示,与Qwen3-8B相比,Qwen3-30B-A3B的散点带要宽得多,揭示了更大的训练-推理差异。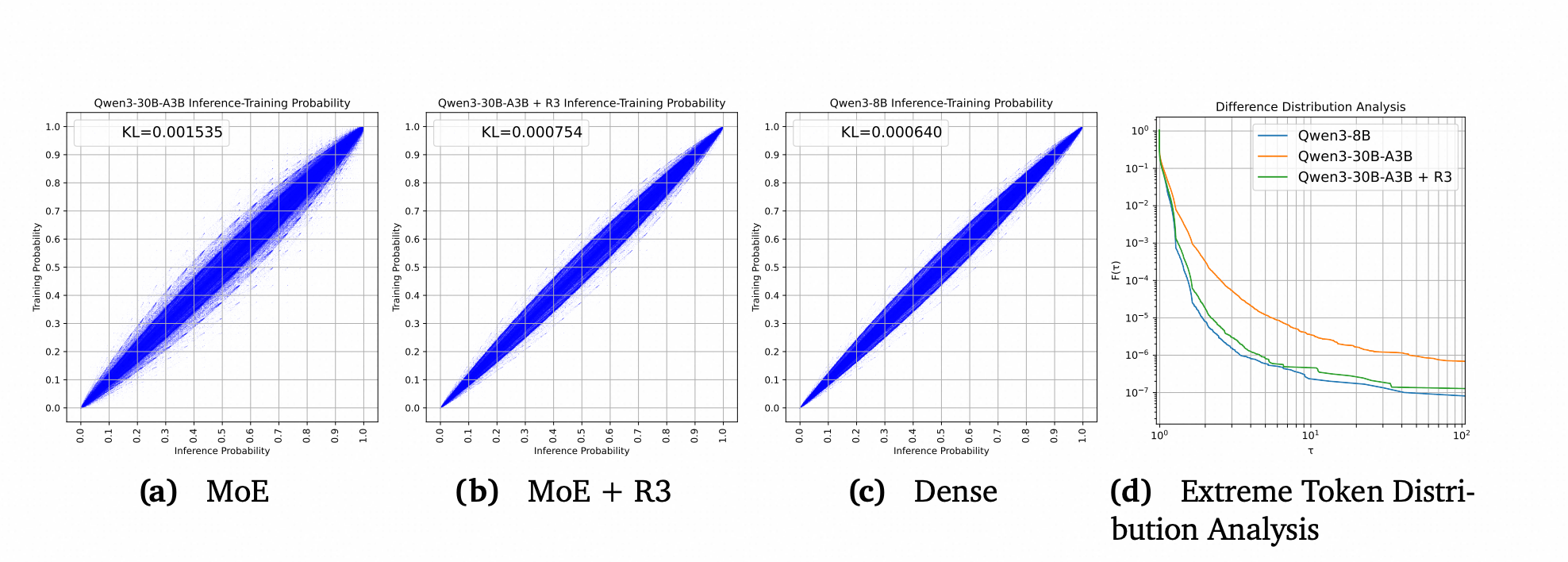
极端Token分布分析
为了量化模型在训练和推理期间行为的差异,我们引入了极端Token分布函数 𝐹(𝜏),定义为:
𝐹(𝜏) = 1/|𝑇| ∑︁ 𝑡∈𝑇 I [ max(𝜋train(𝜃)(𝑡)/𝜋infer(𝜃)(𝑡), 𝜋infer(𝜃)(𝑡)/𝜋train(𝜃)(𝑡)) > 𝜏 ] (3)
该函数衡量了极端token的比例——即训练分布𝜋train(𝜃)和推理分布𝜋infer(𝜃)之间的概率比率超过阈值𝜏的token。图2d绘制了该函数𝐹(𝜏)与阈值𝜏的关系。该图显示,当𝜏 > 2时,Qwen3-30B-A3B模型的极端token比例比Qwen3-8B模型高出一个数量级。这一显著差距表明MoE模型中存在高得多的训练-推理可变性。
3.2 MoE模型中训练与推理的路由差异
从功能连续性的角度来看,MoE和密集模型之间的关键区别在于路由引入的非连续性。在MoE模型中,路由器输入的微小扰动可能导致选择完全不同的专家,从而引起层输出的巨大变化。而密集模型没有明确的专家选择过程,不会出现这种现象。
(图2)
- (a) MoE模型的训练-推理差异图,散点分散,KL散度较大。
- (b) 应用R3后MoE模型的训练-推理差异图,散点更集中,KL散度显著减小。
- © 密集模型的训练-推理差异图,散点非常集中,KL散度最小。
- (d) 极端Token分布函数图。MoE模型的曲线(蓝色)远高于密集模型(绿色),表明其极端token比例高得多。应用R3后(橙色),MoE模型的曲线大幅下降,接近密集模型的水平。
基于此,我们进一步分析了MoE模型中训练和推理之间的路由分布差异。我们使用SGLang (Zheng et al., 2024) 和 Qwen3-30B-A3B (Yang et al., 2025) 为2048个数学问题生成响应。对于每个响应,我们从推理引擎收集所有token(包括输入token)的路由分布。然后,我们将这些序列输入到Megatron引擎进行前向传播,得到训练引擎观察到的路由分布。我们在不同层面对这两组路由信息进行比较:
路由器层面比较: 对于每个token和每个MoE层,我们计算MoE路由器做出的不同专家选择的数量,并计算这些差异的频率。图3a展示了结果。可以观察到,大约10%的路由器在训练时选择了与推理时不同的专家。
Token层面比较: 对于每个token,我们统计其在所有层中MoE路由器做出的不同专家选择的总数,并计算其频率。图3b展示了这些发现。结果表明,94%的token在至少一个层的前向传播中选择了不同的专家。
序列层面比较: 对于一个序列,我们计算每个token的路由分布差异,然后在token上取平均,得到每个序列的平均差异,并绘制直方图(图3c)。结果显示,平均每个token的差异约为6个路由器。
这些发现表明,在训练和推理期间,MoE模型表现出路由分布差异。在第4节中,我们将通过经验证明,与密集模型相比,路由差异是MoE模型额外的训练-推理差异的主要贡献者。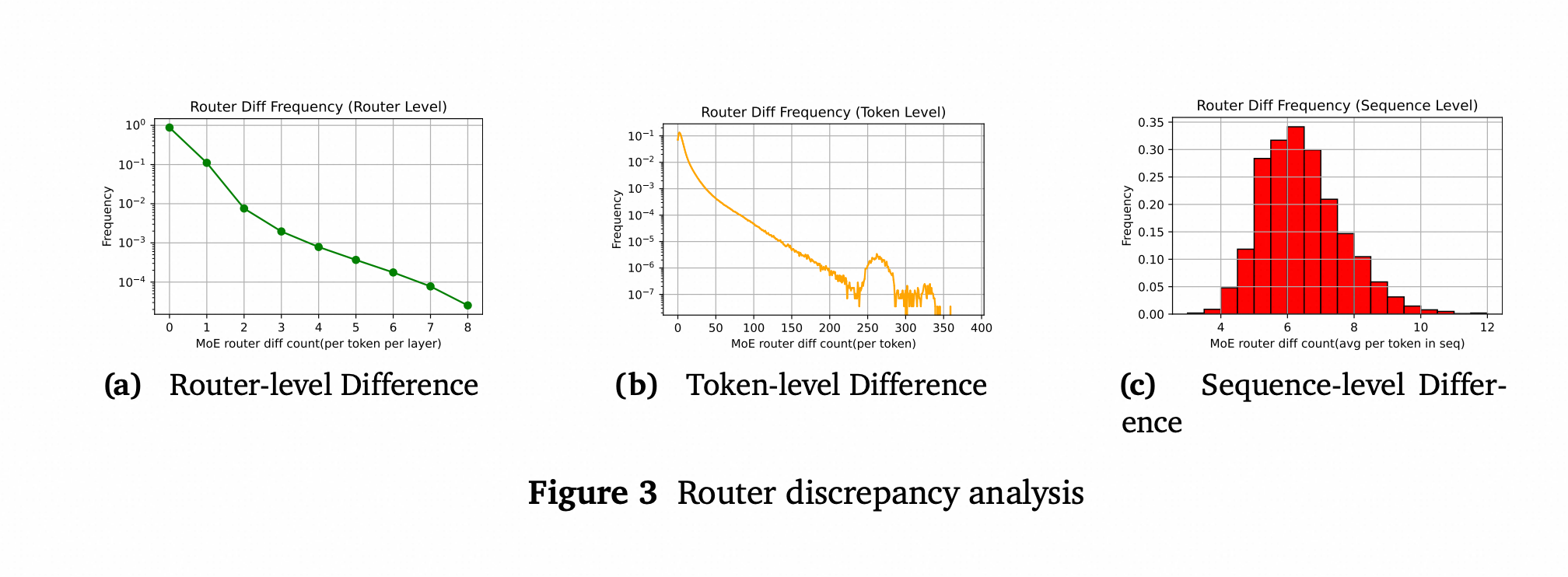
(图3) 路由差异分析图。
(a) 路由器层面:约10%的路由器选择不同。
(b) Token层面:94%的token至少在一个层选择不同。
© 序列层面:平均每个token约有6个路由器选择不同。
3.3 同一框架内对同一序列重复前向传播的差异
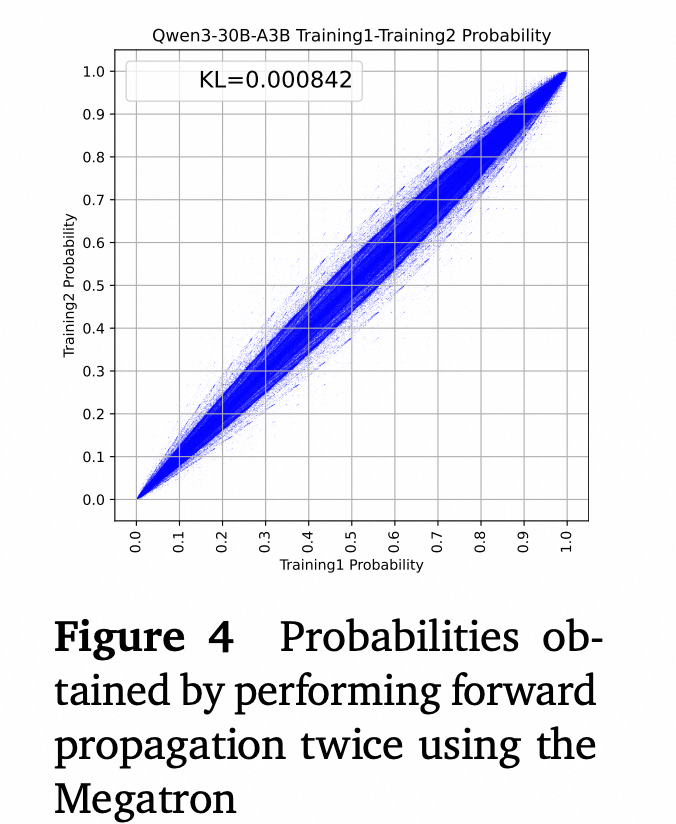
我们在Megatron框架下对同一组序列进行了两次前向传播,并获得了两个概率分布。按照第3.1节的程序,我们计算了这些分布之间的KL散度并绘制了结果(散点图见图4,KL散度=8.4×10⁻⁴)。
结果显示,对于Megatron引擎中的MoE模型,即使输入序列完全相同,两次前向传播的最终输出概率也可能不同。在强化学习的设置中,这种变化给旧策略𝜋train(𝜃old)的计算增加了噪声。这种噪声使得重要性采样比率不可靠,可能破坏甚至中断强化学习过程。
(图4) Megatron框架内两次前向传播的概率差异图,显示即使在同一框架内也存在不一致性。
4. 序列生成路由重放 (Rollout Routing Replay)
本节详细描述了序列生成路由重放(R3)的实现、其在多轮对话中的缓存支持,以及对其在训练-推理差异上效果的分析。
4.1 实现

我们首先描述训练框架中MoE层的常规前向传播。考虑序列𝑠的第𝑡个token和第𝑙个Transformer块中的MoE层。设训练时该层的输入为xtrain。路由器logits计算如下:
strain = xtrain * W𝑟 (4)
其中W𝑟表示路由器的线性权重矩阵。设专家数量为𝑀,要选择的专家数量为𝐾。训练期间,路由器根据logits选择top-𝐾个专家。这由一个二进制掩码表示:
Itrain = TopKMask(strain, 𝐾) (5)
其中Itrain ∈ {0, 1}𝑀 且 ∑𝑖 𝐼train,𝑖 = 𝐾。然后,通过对所选专家的logits应用softmax来生成门控权重:
𝑔train,𝑖 = (𝐼train,𝑖 * exp(𝑠train,𝑖)) / (∑𝑀 𝑗=1 𝐼train,𝑗 * exp(𝑠train,𝑗)) (6)
最后,MoE层的输出计算为专家输出的加权和:
ytrain = ∑𝑀 𝑖=1 𝑔train,𝑖 * E𝑖(xtrain) (7)
其中E𝑖(·)表示第𝑖个专家网络。
现在我们引入序列生成路由重放。假设在推理阶段,MoE层的输入是xinfer。路由器计算推理logits sinfer = xinfer * W𝑟,并从中获得路由掩码 Iinfer = TopKMask(sinfer, 𝐾)。R3的核心思想是在训练的前向传播中重用推理时的路由掩码Iinfer,但仍然对训练时的logits应用softmax以保留梯度流。具体来说,在这条重放路径上,“重放”门控权重𝑔replay计算如下:
𝑔replay,𝑖 = (𝐼infer,𝑖 * exp(𝑠train,𝑖)) / (∑𝑀 𝑗=1 𝐼infer,𝑗 * exp(𝑠train,𝑗)) (8)
然后,使用这些重放权重来组合训练时专家的输出,产生重放输出yreplay:
yreplay = ∑𝑀 𝑖=1 𝑔replay,𝑖 * E𝑖(xtrain) (9)
这种设计有两个主要目的:(a) 对齐训练和推理:使用Iinfer确保了训练时重放的专家与推理时选择的专家相匹配,消除了专家选择上的不匹配。(b) 保留梯度数据流:通过只重放掩码,梯度仍然可以反向传播到logits,而不会干扰计算图,这有助于有效优化路由器。
4.2 路由器掩码缓存与多轮对话支持
许多推理引擎使用KV Cache前缀缓存策略 (Kwon et al., 2023; Zheng et al., 2024) 来避免对已见上下文进行冗余的预填充(prefill)计算,这显著减少了多轮交互中的总计算量。我们观察到,缓存的路由器掩码具有相似的属性:对于相同的前缀token,MoE路由器应该产生相同的结果。因此,来自推理引擎的路由掩码Iinfer可以与前缀KV Cache一起缓存。具体来说,对于每个层和token前缀,相应的路由掩码与KV Cache一起存储。当相同的前缀出现并命中缓存时,掩码可以被重用,无需重新计算。这使得R3能够与前缀缓存机制无缝集成。
缓存路由掩码在智能体(agent)场景中尤其有益。许多智能体任务,如软件工程 (Jimenez et al., 2024) 和网页浏览 (Wei et al., 2025),都涉及自回归生成和工具调用之间的多轮交互。为提高效率,这些过程直接重用前几轮的KV Cache,因此不必重新生成已计算的数据。路由掩码缓存使R3在RL智能体任务中保持高效,无需重新预填充来生成路由掩码,这对于训练大规模、先进的MoE模型至关重要。
4.3 R3对训练-推理差异的实证分析
为了评估R3在减少训练-推理差异方面的有效性,我们使用Qwen3-30B-A3B模型重复了第3.1节中描述的过程。在此过程中,我们缓存在SGLang上推理时获得的路由分布,并在Megatron框架内重放它们。在获得推理引擎概率和训练引擎概率后,使用公式2,我们估计了训练和推理之间的KL散度。结果显示,应用R3后,训练和推理之间的KL散度从1.5×10⁻³降至7.5×10⁻⁴,接近于密集模型观察到的6.4×10⁻⁴。这直观地表明训练-推理差异有所减小。我们还在图2d中绘制了应用R3后训练-推理差异比率的累积分布图。该图表明,对于MoE模型,应用R3将具有较大训练-推理差异的token频率降低了一个数量级。
5. 实验
在本节中,我们评估了我们的R3方法在强化学习中的性能改进,并将其与其他基线方法进行比较。
5.1 设置
任务和数据集
我们选择数学推理作为训练的目标任务。对于训练数据集,我们从多个开源数据集(包括BigMath, ORZ等)中收集并筛选了约10万个可验证的数学问题。对于评估数据集,我们采用AIME24, AIME25, AMC23和MATH500(5级)作为我们的基准数据集。我们报告AIME24和AIME25的Avg@32,AMC23的Avg@16,以及MATH500(5级)的Avg@4。在训练过程中,一些模型可能会在后期出现性能下降甚至崩溃。为确保公平评估,我们在单次训练运行中每5个全局步测量一次模型性能,并报告观察到的最高性能及其对应的训练步数。
模型
我们选择了两个模型进行实验:(a) Qwen3-30B-A3B-Base (Yang et al., 2025) (b) Qwen3-30B-A3B-SFT,这是在我们的通用指令遵循数据集上从Qwen3-30B-A3B-Base微调而来的。
基线方法
我们考虑以下基线优化方法进行比较:(a) GRPO (Shao et al., 2024),额外应用了DAPO (Yu et al., 2025) 的Clip Higher技术,参数𝜖low=0.2,𝜖high=0.27;(b) TIS (Yao et al., 2025),使用上裁剪阈值𝐶=2;© GSPO (Zheng et al., 2025),采用序列级重要性采样,参数𝜖low=3×10⁻⁴,𝜖high=4×10⁻⁴。由于我们的R3方法与GSPO或TIS等优化器是正交的,我们还评估了这些技术的各种组合。
多小步 vs. 单小步
在类似PPO的算法中,一个全局步收集的一批样本通常被分成多个小步(mini steps)进行多次策略更新。然而,先前的研究表明,采用严格的同策略(on-policy)策略,即只用单个小步,可能会产生更好的性能。我们研究了这两种设置。对于多小步,我们将小步数设为8,意味着每个PPO小步训练2048/8=256个样本,进行8次优化器更新,学习率为1×10⁻⁶。在多小步场景中,对于R3方法,我们在重新计算旧策略和更新策略时都重放了路由。对于单小步场景,我们将小步数设为1,意味着所有2048个样本一次性更新。由于更新次数较少,我们将学习率提高到3×10⁻⁶。在这种场景下,我们不重新计算旧策略。
其他设置
我们使用VeRL框架实现R3,使用Megatron进行训练,SGLang进行推理。批大小设为256,n=8,每轮共2048个样本。最大提示长度为2048,最大生成长度为30720。我们采用Yu et al. (2025) 的动态采样策略,在生成过程中只保留部分正确的样本,直到累积到足够的批大小用于训练。没有引入用于专家平衡的辅助损失。
5.2 实验结果与分析
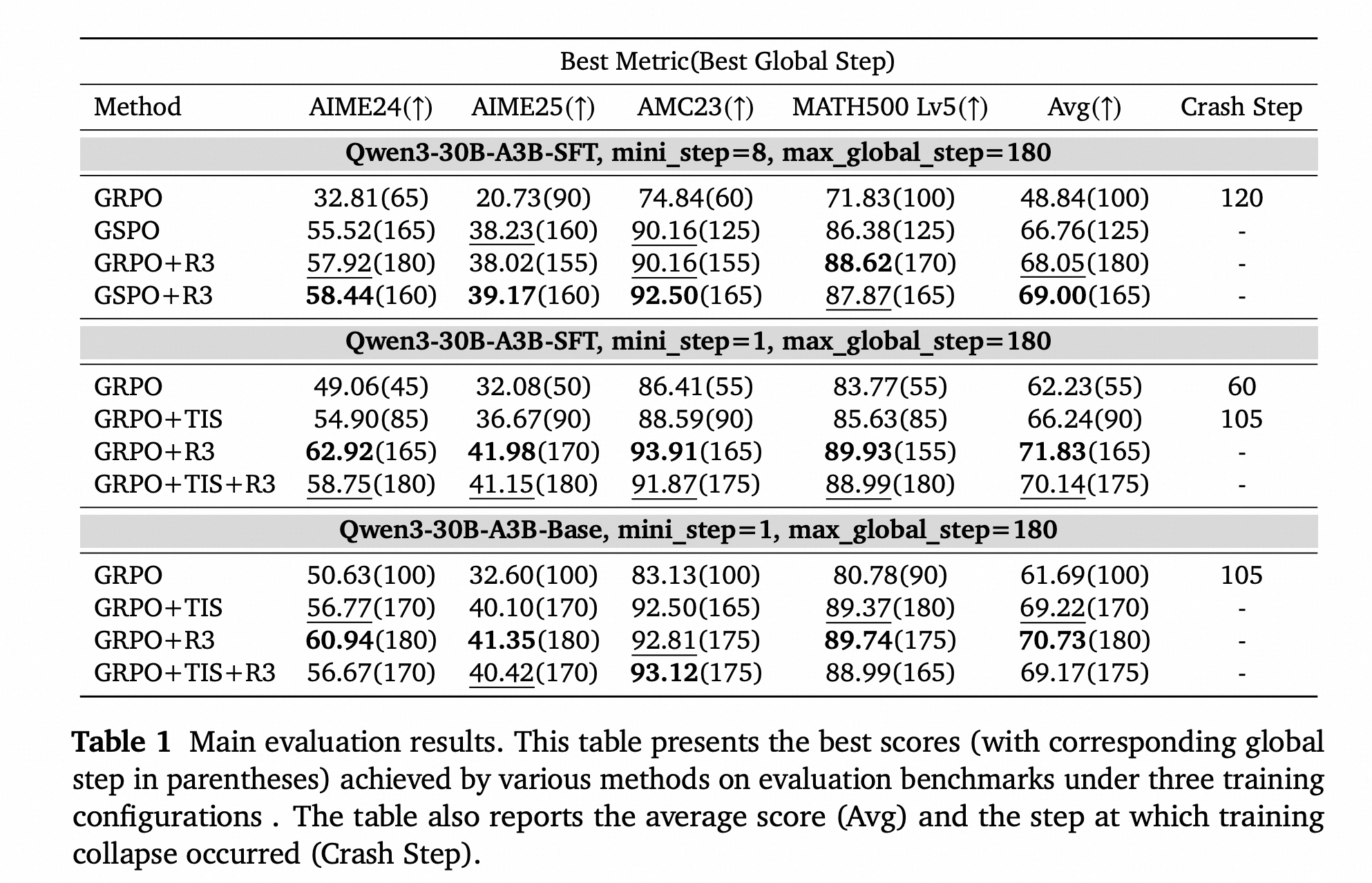
(表1) 主要评估结果。展示了各种方法在三种训练配置下在评估基准上取得的最佳分数(括号内为对应的全局步数)。还报告了平均分(Avg)和训练崩溃发生的步数(Crash Step)。
整体性能
R3在不同场景下均取得了更好的结果。在多小步设置中,GRPO+R3比GSPO高出1.29分。此外,将R3与GSPO结合进一步将性能提高了0.95分。在单小步设置中,R3在SFT模型上比TIS高出5.58分,在基础模型上高出1.51分。然而,将R3与TIS结合并没有带来明显增益,甚至可能降低性能;例如,在SFT模型的单小步设置中,TIS+R3比单独的R3低1.69分。由于R3已经显著降低了训练和推理之间的策略差异,TIS的额外校正带来的益处微乎其微 (Yao et al., 2025)。
训练稳定性
在单小步设置中,三个没有使用R3的强化学习过程在训练中崩溃了。为了调查这些崩溃的原因,我们绘制了每个训练步的估计训练-推理KL散度和极端token分布函数𝐹(𝜏=2)(见图5)。我们观察到,在每个训练过程中,KL散度和𝐹(𝜏=2)的值都随着训练过程增加。此外,崩溃的训练运行几乎总是伴随着异常高的KL和𝐹(𝜏=2)值。例如,在使用GRPO的SFT模型单小步设置中,在60个全局步后,𝐹(𝜏=2)的值超过了0.1。这表明对于10%的token,训练框架下的概率与推理框架下的概率相差超过2倍,显示出严重的训练-推理不一致。相比之下,在使用R3的训练过程中,大部分时间里𝐹(𝜏=2)的值都保持在10⁻⁴以下。通过对齐训练和推理分布,R3有效地稳定了MoE模型的强化学习。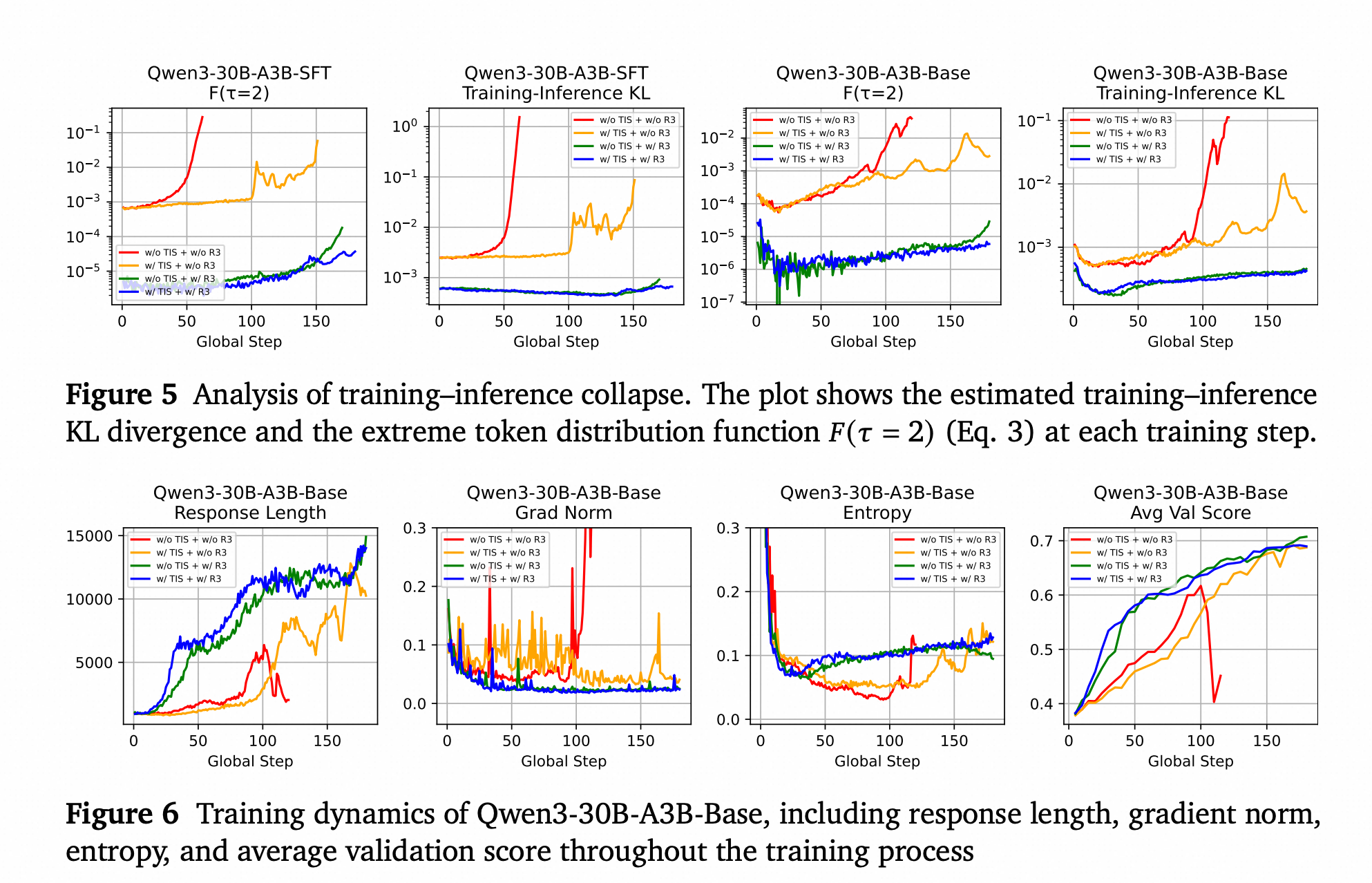
(图5) 训练-推理崩溃分析。图表显示了每个训练步的训练-推理KL散度和极端token分布函数𝐹(𝜏=2)。未使用R3的曲线(蓝色/橙色)会急剧上升并导致崩溃,而使用R3的曲线(绿色/红色)则保持在非常低的水平。
优化和生成行为
在训练过程中,R3还增强了优化稳定性、探索行为和生成动态。我们绘制了单小步+基础模型组在整个训练过程中的序列长度、梯度范数、生成熵和评估分数(见图6)。结果显示,R3具有更小的梯度范数、更平滑的序列增长模式和更稳定的熵。(a) 序列长度:使用R3时,生成的序列长度在训练初期迅速增长,表明R3能快速捕捉到正确的优化方向。相比之下,其他两个训练过程在第80步后才缓慢增长,并表现出更明显的波动。(b) 梯度范数:R3始终保持较低的梯度范数,表明优化过程更稳定。© 生成熵:使用R3时,熵在约25步后开始稳定增加,表明模型更早开始探索更好的策略。没有R3时,熵增加得晚得多且波动剧烈。
(图6) Qwen3-30B-A3B-Base的训练动态图,包括响应长度、梯度范数、熵和平均验证分数。使用R3的曲线(绿色/红色)通常表现出更稳定、更健康的训练趋势。
6. 相关工作
…(这部分是对相关领域研究的综述,主要强调了MoE架构、LLM强化学习不稳定性以及现有解决方案,并凸显了本文R3方法的独特性和直接性。)
7. 结论
在这项工作中,我们确定了训练-推理路由差异是MoE强化学习不稳定的主要来源。为解决此问题,我们提出了序列生成路由重放(R3),该方法在训练期间重用推理时的路由分布,以对齐专家选择,同时保留梯度流。在多种RL设置下的实验表明,R3显著降低了训练-推理的差异,稳定了训练,并持续优于现有方法。我们的结果证明了在MoE模型中对齐训练和推理的重要性,并表明R3为提高稳定性提供了一个实用的解决方案。
附录 (Appendix)
附录部分包含了更详细的实验结果图表。
- A. 详细评估结果: 按不同评估集(AIME24, AMC23等)分别展示了各方法在训练过程中的得分变化曲线。
- B. 详细训练指标: 展示了训练过程中的各种指标变化曲线,如响应长度、奖励、梯度范数、熵、极端token比例(F(τ=2))、训练-推理KL散度等。这些图表为正文中的分析提供了更详细的数据支持。
好的,我们来详细解释一下这篇名为《Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers》(通过对齐训练和推理路由器来稳定MoE强化学习)的论文。
这篇论文的核心在于解决一个具体且重要的问题:为什么在使用强化学习(RL)训练混合专家(MoE)大语言模型时,训练过程非常不稳定,甚至会崩溃? 论文给出的答案是训练和推理(Inference)阶段的路由器(Router)行为不一致,并提出了一种简单而有效的解决方案 R3 (Rollout Routing Replay)。
下面我们分点来详细解析:
1. 核心思想 (Core Idea)
简单来说,这篇论文做的事情是:
- 发现问题: 在MoE模型中,同一个输入token,在生成答案(推理阶段)和更新模型(训练阶段)时,可能会被分配给完全不同的“专家”(Experts)组合。这种不一致性导致了策略的巨大差异,使得强化学习的更新非常不稳定。
- 提出方案 (R3): 在模型生成答案(推理)时,把每个token选择的“专家”组合记录下来。然后在训练时,强制模型使用这套一模一样的“专家”组合进行计算和更新。
- 验证效果: 实验证明,这个名为R3的方法极大地降低了训练和推理之间的策略差异(KL散度),有效防止了训练崩溃,并提升了模型最终的性能。
2. 问题背景与论文发现 (Problem & Findings)
2.1. 训练-推理不一致性 (Training-Inference Discrepancy)
在现代大模型的强化学习(如PPO算法)中,通常分为两个阶段:
- Rollout/Inference(推理/采样): 用当前的策略(
π_infer)生成一批数据(例如,生成对数学问题的解答)。这个过程通常在专门的、高度优化的推理引擎(如vLLM, SGLang)上进行。 - Training(训练): 用上一步生成的数据来计算损失并更新模型参数(
π_train)。这个过程在训练框架(如Megatron, DeepSpeed)上进行。
由于推理引擎和训练框架在底层实现、硬件优化、甚至数值精度上都有差异,导致即使是同一个模型,对于同一个输入,π_infer 和 π_train 计算出的token概率也会有微小差别。这个问题对于所有模型都存在,但论文发现,在MoE模型中,这个问题被急剧放大了。
2.2. MoE模型如何放大问题?
- 密集模型 (Dense Model): 模型的计算路径是固定的。输入微小的变化只会导致输出微小的变化。训练和推理的微小差异影响可控。
- 混合专家模型 (MoE Model): MoE模型有一个路由器 (Router),它会根据输入token的特征,动态地从众多“专家”(本质上是前馈神经网络)中选择几个(例如Top-2)来激活。
- 路由器的不连续性: 这是问题的关键。路由器输入的微小扰动,就可能导致它选择的专家组合发生改变(例如,从选择专家1和4,变为选择专家2和5)。
- 不一致的根源: 由于训练和推理框架的差异,导致送入路由器的输入特征(
xtrainvsxinfer)有微小不同。这个微小的不同足以让路由器在两个阶段做出不同的选择。 - 灾难性后果: 选了不同的专家,就相当于走了两条完全不同的计算路径,最终输出的token概率可能天差地别。这使得PPO算法中用于计算策略更新幅度的重要性采样比率
w_t(θ)变得极其不稳定,从而导致训练崩溃。
2.3. 论文的量化分析 (Quantitative Analysis)
论文通过实验数据证明了上述猜想:
- 策略差异 (Policy Discrepancy, Figure 2a vs 2c): MoE模型(Qwen3-30B-A3B)的训练-推理概率散点图比密集模型(Qwen3-8B)要分散得多,KL散度也大得多(1.53e-3 vs 6.4e-4)。
- 极端Token分析 (Extreme Token Analysis, Figure 2d): MoE模型中,训练和推理概率相差超过一倍的“极端token”数量比密集模型高出一个数量级。
- 路由器差异 (Router Discrepancy, Figure 3): 直接对比了训练和推理时路由器的选择。发现:
- 约10%的路由器在两个阶段选择了不同专家。
- 高达94%的token在至少一个MoE层上选择了不同的专家。
- 平均每个token在所有MoE层中,有约6个路由器的选择是不同的。
这些数据强有力地证明了路由器不一致是导致MoE模型RL训练不稳定的核心原因。
3. 解决方案:Rollout Routing Replay (R3)
R3的实现非常巧妙且直观,具体步骤如下(参考论文Figure 1和第4节):
-
推理阶段 (Inference):
- 当模型生成一个token时,在每一层的MoE模块,路由器会计算出一个专家选择的掩码(Mask),记为
I_infer。这个Mask决定了哪些专家被激活。 - 核心操作: 将这个
I_infer掩码缓存下来,与生成的token序列一起保存。
- 当模型生成一个token时,在每一层的MoE模块,路由器会计算出一个专家选择的掩码(Mask),记为
-
训练阶段 (Training):
- 当用这个序列来训练模型时,数据流到同一层的MoE模块。
- 此时,训练框架下的路由器会根据当前输入计算出一组新的logits(
strain)。 - 核心操作: 不使用
strain来决定选择哪些专家。而是直接加载并重放 (Replay) 之前缓存的I_infer掩码,强制激活与推理时完全相同的专家。 - 保留梯度流: 尽管专家的选择是被强制的,但计算这些被选中专家的权重时,仍然使用
strain(即训练时的路由器输出)进行Softmax。公式如下:𝑔_replay,𝑖 = (𝐼_infer,𝑖 * exp(𝑠_train,𝑖)) / (Σ_𝑗 𝐼_infer,𝑗 * exp(𝑠_train,𝑗))
这样做的好处是,梯度仍然可以反向传播到strain,从而更新路由器的参数。也就是说,R3在强制对齐计算路径的同时,并没有阻止路由器的学习和优化。
R3的优势:
- 直击痛点: 从根源上消除了训练和推理的路由器选择差异。
- 效果显著: 实验表明,使用R3后,MoE模型的训练-推理KL散度从1.5e-3降至7.5e-4,几乎和密集模型(6.4e-4)一样低(见Figure 2b, 2d)。
- 实现简单,无额外开销: 只是记录和重用掩码,计算开销极小。论文还提到可以和KV Cache一起缓存,无缝集成到现有框架中。
4. 实验结果 (Experiments)
论文在数学推理任务上进行了详尽的实验,对比了多种方法(GRPO, GSPO, TIS)在有/无R3时的表现。
-
稳定性 (Stability, Table 1 “Crash Step”):
- 在没有R3的情况下,多个实验组的训练过程都在中途崩溃了(例如,GRPO在第60步崩溃)。
- 所有使用了R3的实验组都成功完成了训练,没有发生崩溃。
- Figure 5显示,没有R3的训练,KL散度和“极端token”比例会随训练飙升,最终导致崩溃。而有R3的训练则一直保持在很低的水平。
-
性能 (Performance, Table 1):
- R3不仅稳定了训练,还带来了显著的性能提升。例如,在SFT模型+单mini-step的设置下,
GRPO+R3的平均分(71.83)远高于GRPO(62.23)和GRPO+TIS(66.24)。 - 这证明了稳定的训练过程能让模型更有效地学习,达到更高的性能上限。
- R3不仅稳定了训练,还带来了显著的性能提升。例如,在SFT模型+单mini-step的设置下,
-
训练动态 (Training Dynamics, Figure 6):
- 使用了R3后,模型的梯度范数更小、生成序列长度增长更平滑、熵(探索程度)也更稳定地提升,这些都表明R3带来了更健康、更稳定的优化过程。
总结
这篇论文通过严谨的分析和实验,定位了MoE模型在强化学习训练中不稳定的核心原因——训练与推理阶段的路由器行为不一致。并据此提出了一个简单、高效且有效的解决方案 R3 (Rollout Routing Replay),即在训练时重放推理阶段的专家选择。R3不仅成功解决了训练崩溃的问题,还显著提升了模型的最终性能,为未来在MoE架构上进行大规模强化学习研究提供了一个重要的基础性技术。
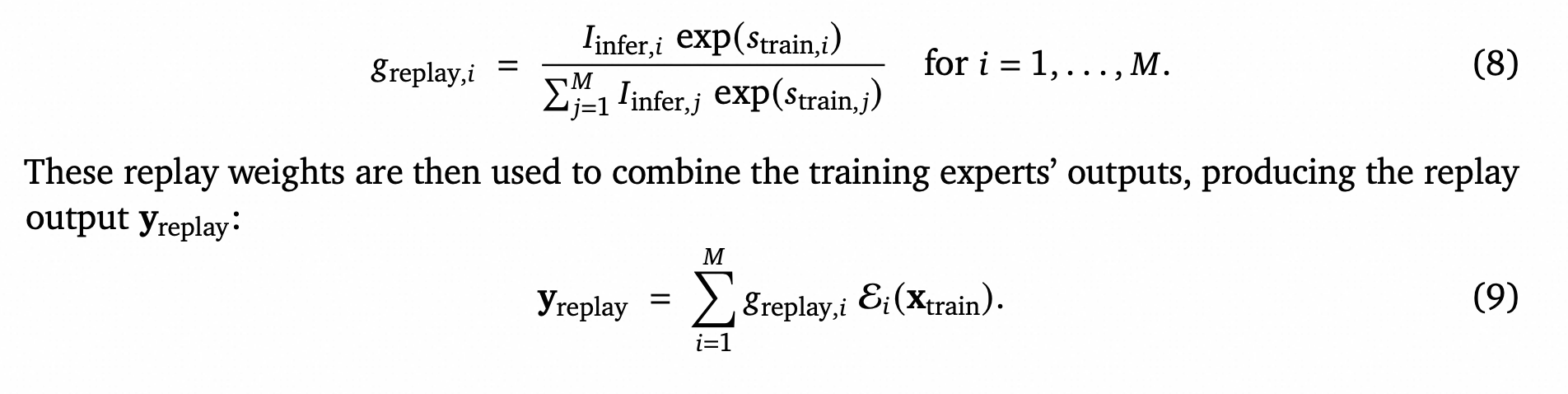
这公式什么意思?举例以实际的矩阵举例 路由重放。
好的,我们来详细解释这两个公式,并用一个具体的矩阵例子来说明“路由重放”(Route Replay)的过程。
公式解释
这两个公式是 R3 (Rollout Routing Replay) 方法的核心。它们描述了在训练阶段,如何利用推理阶段记录的信息来计算MoE(混合专家)层的输出。
公式 (8): 计算重放门控权重 (Replay Gating Weights)
g_replay,i = (I_infer,i * exp(s_train,i)) / (Σ_j I_infer,j * exp(s_train,j))
g_replay,i: 这是最终计算出的、用于专家i的“重放权重”。它决定了专家i的输出在最终结果中占多大的比重。s_train,i: 这是在训练阶段,路由器为专家i计算出的“得分”或“逻辑值 (logit)”。它反映了在当前训练前向传播中,路由器“倾向于”选择专家i的程度。I_infer,i: 这是最关键的部分。它是一个从推理阶段记录下来的“掩码 (mask)”。它是一个二进制值(0或1)。- 如果
I_infer,i = 1,表示在推理时,专家i被选中了。 - 如果
I_infer,i = 0,表示在推理时,专家i未被选中。
- 如果
exp(): 指数函数,用于将得分(logits)转换为正数。- 分子
I_infer,i * exp(s_train,i): 这一步是“掩码”操作。只有在推理时被选中的专家(I_infer,i = 1),其训练得分s_train,i才会被保留并计算指数;否则,结果直接为0。 - 分母
Σ_j ...: 这是归一化项。它将所有被推理掩码选中的专家的指数得分加起来,以确保最终所有权重g_replay,i的总和为1。
一句话总结公式(8): 它在训练时计算了一组权重,但这组权重只分配给那些在推理时被选中的专家。权重的具体大小由训练时的路由器得分决定,但“谁有资格获得权重”则由推理时的选择决定。
公式 (9): 计算重放输出 (Replay Output)
y_replay = Σ_i g_replay,i * E_i(x_train)
y_replay: 这是MoE层的最终输出向量。E_i(x_train): 这是专家网络i对训练输入x_train进行计算后得到的输出向量。g_replay,i: 从公式(8)计算出的权重。
一句话总结公式(9): 这是标准的MoE加权求和。它将每个专家的输出乘以对应的权重,然后相加。因为公式(8)保证了未被选中的专家的权重为0,所以这个求和实际上只混合了那些在推理时被选中的专家的输出。
举例说明:路由重放
假设我们有一个MoE层,总共有 M=4 个专家,每次选择 K=2 个(Top-2)。
步骤 1: 推理阶段 (Rollout Phase)
-
一个token输入到MoE层,路由器计算出4个专家的得分(logits)。我们称之为
s_infer。s_infer=[1.5, -0.5, 2.8, 1.2] -
路由器选择得分最高的2个专家。这里是
2.8(对应专家3) 和1.5(对应专家1)。 -
生成推理掩码
I_infer。这是一个二进制向量,被选中的位置为1,未被选中的为0。I_infer=[1, 0, 1, 0](专家1和专家3被选中) -
【核心】 这个
I_infer向量[1, 0, 1, 0]会被记录并保存下来。
步骤 2: 训练阶段 (Replay Phase)
-
现在,我们用之前生成的数据来训练模型。当同一个token的数据流经同一个MoE层时,由于训练框架和推理引擎的细微差别,路由器计算出的得分
s_train可能会与s_infer不同。s_train=[1.3, 0.1, 2.5, 1.9] -
【关键区别】
- 如果没有R3:路由器会根据
s_train重新选择Top-2专家,即2.5(专家3) 和1.9(专家4)。选择的掩码将是[0, 0, 1, 1]。这与推理时的选择[1, 0, 1, 0]不一致,从而导致训练不稳定。 - 有了R3:我们不理会
s_train的Top-2结果。我们强制使用之前保存的I_infer = [1, 0, 1, 0]。
- 如果没有R3:路由器会根据
-
应用公式(8)计算
g_replay权重:-
我们有
I_infer = [1, 0, 1, 0]和s_train = [1.3, 0.1, 2.5, 1.9]。 -
计算分母(归一化项):
Σ_j I_infer,j * exp(s_train,j)= (1 * exp(1.3)) + (0 * exp(0.1)) + (1 * exp(2.5)) + (0 * exp(1.9))= exp(1.3) + 0 + exp(2.5) + 0≈ 3.67 + 12.18 = 15.85 -
计算每个专家的权重
g_replay,i:g_replay,1 = (1 * exp(1.3)) / 15.85 = 3.67 / 15.85 ≈ 0.23g_replay,2 = (0 * exp(0.1)) / 15.85 = 0g_replay,3 = (1 * exp(2.5)) / 15.85 = 12.18 / 15.85 ≈ 0.77g_replay,4 = (0 * exp(1.9)) / 15.85 = 0
-
最终得到的重放权重向量是
g_replay=[0.23, 0, 0.77, 0]。
-
-
应用公式(9)计算最终输出
y_replay:- 假设4个专家分别输出了
E1, E2, E3, E4。 y_replay = 0.23 * E1 + 0 * E2 + 0.77 * E3 + 0 * E4y_replay = 0.23 * E1 + 0.77 * E3
- 假设4个专家分别输出了
结论
通过这个例子,我们可以清晰地看到:
- 对齐计算路径:尽管训练时路由器本身可能想选择专家3和4,但R3方法强制它使用了和推理时完全一样的专家组合(专家1和3)。
- 保留梯度流:权重的具体数值(0.23和0.77)是由
s_train计算得来的。这意味着梯度仍然可以从最终的损失反向传播到s_train,进而更新路由器的参数。路由器仍然在学习,只不过它的学习目标是更好地为“正确的”(即推理时选择的)专家分配权重。
Preserving the gradient data flow: By replaying only the
mask, the gradients can still flow back to the logits without interfering with the computation
graph, which helps to optimize the router effectively 回传到logits 是什么意思? 没有影响,可以用图表示一下嘛
好的,我们来详细解释“梯度可以回传到logits”的含义,并用图来表示这个过程。
“回传到logits”是什么意思?
在神经网络训练中,我们通过反向传播算法来更新模型的参数(权重和偏置)。这个过程是这样的:
- 模型进行一次前向传播,从输入计算到最终的输出,并根据输出和真实标签计算出一个损失值(Loss)。
- 然后进行反向传播,计算损失值对模型中每一个参数的梯度(gradient)。梯度表示了如果微调这个参数,损失值会如何变化。
- 最后,使用优化器(如Adam)根据梯度来更新参数,使得下一次计算的损失值更小。
“梯度可以回传到logits”这句话里的logits,特指MoE层中**路由器(Router)**计算出的、未经softmax的原始得分(在论文里是 s_train)。
所以,这句话的完整意思是:
即使我们强制使用了推理时的专家选择(mask),模型的损失值对路由器得分(s_train)的梯度依然能够被计算出来。这意味着我们仍然可以根据这个梯度来更新路由器的参数,让路由器学得更好。
换句话说,R3方法没有“切断”路由器参与学习的路径。
为什么说“没有影响计算图”?
“计算图”(Computation Graph)是深度学习框架(如PyTorch, TensorFlow)在内部表示模型计算流程的一种方式。它记录了所有操作和张量(tensor)之间的依赖关系,是反向传播能够进行的基础。
R3方法的巧妙之处在于,它引入的 I_infer (推理掩码) 是一个外部给定的、固定的常量(对于单次反向传播而言)。它参与了前向计算,但它本身不是模型参数,也不需要计算梯度。
在计算图中,从最终损失到 s_train 的路径是通畅的,因为 s_train 通过 exp() 函数和乘法/除法运算,最终影响了模型的输出 y_replay,进而影响了损失。因此,框架可以沿着这条路径计算梯度。I_infer 只是像一个“开关”一样,决定了 s_train 的哪些分量可以参与后续计算。
用图来表示
我们用一个简化的图来对比没有R3和有R3的情况。假设M=4, K=2。
1. 没有R3的正常MoE层(Standard MoE)
图解:
- 前向传播 (蓝色箭头):
- 输入
x_train经过路由器,得到得分s_train。 TopK操作根据s_train选择得分最高的2个专家,生成掩码I_train。注意:TopK操作是不可导的,通常框架会用一些技巧(如straight-through estimator)来让梯度“绕过”它。s_train和I_train一起通过 Softmax 得到门控权重g_train。g_train与专家输出E_i(x_train)加权求和得到y_train。y_train最终影响到Loss。
- 输入
- 反向传播 (红色虚线箭头):
- 梯度从
Loss回传到y_train,再到g_train和E_i。 - 梯度从
g_train回传到s_train,从而更新路由器的参数。
- 梯度从
2. 有R3的MoE层(MoE with R3)
图解:
- 前向传播 (蓝色箭头):
- 输入
x_train经过路由器,得到得分s_train。 - 【核心区别】 我们不再使用
TopK操作。而是直接从外部加载固定的推理掩码I_infer。I_infer在这个计算图中被视为一个常量(Constant)。 s_train和 固定的I_infer一起通过公式(8)的“掩码Softmax”得到门控权重g_replay。g_replay与专家输出E_i(x_train)加权求和得到y_replay。y_replay最终影响到Loss。
- 输入
- 反向传播 (红色虚线箭头):
- 梯度从
Loss回传到y_replay,再到g_replay和E_i。 - 梯度从
g_replay回传到s_train。这条路径是完全通畅的! 因为g_replay的计算明确地依赖于s_train(exp(s_train))。 - 因为
I_infer是一个常量,所以没有梯度会流向它。它不会被更新。
- 梯度从
总结对比
| 特性 | 标准MoE (没有R3) | MoE with R3 |
|---|---|---|
| 专家选择 | 由训练时的s_train通过TopK动态决定。 |
由推理时记录的I_infer强制决定。 |
| 梯度流 | 梯度需要处理不可导的TopK操作。 |
梯度直接通过可导的exp()和乘法回传到s_train,路径更干净。 |
| 计算图 | I_train是s_train的函数,依赖关系在图中。 |
I_infer是外部常量,不依赖s_train,计算图更简单。 |
| 效果 | 路径不一致:训练和推理的计算路径(专家选择)可能不同。 | 路径一致:强制训练和推理走相同的计算路径。 |
| 路由器优化 | 路由器被优化,以选择“最佳”专家。 | 路由器被优化,以为“已被指定”的专家分配“最佳”权重。 |
所以,“By replaying only the mask, the gradients can still flow back to the logits without interfering with the computation graph” 这句话非常精准:
- Replaying only the mask:只重放
I_infer这个选择结果。 - Gradients can still flow back to the logits:梯度仍然能到达
s_train,路由器可以被优化。 - Without interfering with the computation graph:通过将
I_infer作为常量引入,避免了TopK的不可导问题,简化了梯度路径,让反向传播更直接、稳定。
我们考虑以下基线优化方法进行比较:(a) GRPO (Shao et al., 2024),额外应用了DAPO (Yu et al., 2025) 的Clip Higher技术,参数𝜖low=0.2,𝜖high=0.27;(b) TIS (Yao et al., 2025),使用上裁剪阈值𝐶=2;© GSPO (Zheng et al., 2025),采用序列级重要性采样,参数𝜖low=3×10⁻⁴,𝜖high=4×10⁻⁴

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)