让大模型在知识图谱里“玩游戏”(保姆级教程),推理暴涨65%还能解数学题,收藏这一篇就够了!
大模型推理训练一直面临三难困境:数学和代码环境需要昂贵的专家标注,难以大规模扩展;游戏环境训练出的技能过于专业化,无法泛化到其他任务;训练过程缺乏可验证的反馈信号。理想的推理训练环境应该同时具备可扩展性、可泛化性和可验证性——但现实中很难找到这样的环境。
论文提出了解决方案:从知识图谱这类大规模结构化数据中自动构建推理环境,让模型在其中通过强化学习探索和推理。这个名为SIE(Structured In-context Environment,结构化上下文环境)的框架,将环境动态编码为结构化上下文并置于模型提示中作为软约束,模型在此上下文中的探索被建模为隐式动作,输出可直接用于推导RL微调的奖励信号。
从知识图谱自动生成推理环境
SIE框架基于知识图谱(Knowledge Graph, KG)自动构建推理环境,整个流程分为四个步骤:
第一步:种子子图检索。对每个知识图谱问答(KGQA)实例,包含问题Q、答案A、问题实体EQ和答案实体EA,采用双向检索策略:从问题实体和答案实体分别进行多跳搜索,最大跳数为nhop。
第二步:支持子图提取。使用Dijkstra算法提取所有从问题实体到答案实体的最短路径,这些路径构成支持子图Gsupport,包含推理所需的关键信息。
第三步:干扰子图过滤。对种子子图中不在支持子图内的部分进行两阶段语义过滤:先用ms-marco-MiniLM-L12-v2模型过滤出与问题语义相似度最高的关系,再保留包含这些关系且与问题相似度最高的三元组,构成干扰子图Gdistract。
第四步:构建部分SIE。论文构建了5个难度递增的部分环境:保留支持子图的比例分别为100%、75%、50%、25%和0%,与干扰子图混合后随机打乱。这种设计模拟了现实中信息不完整的场景。
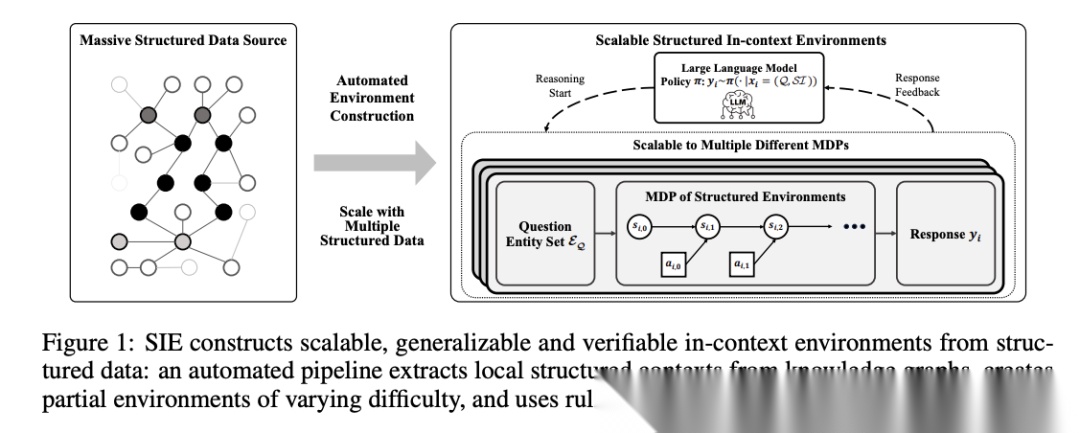
[Figure 1: SIE框架概览] 展示了从知识图谱构建结构化上下文环境的完整流程,以及模型如何在环境中进行推理和接收奖励反馈。
论文使用GRPO(Group Relative Policy Optimization)算法进行RL微调,奖励机制包括答案奖励(精确匹配ground-truth答案给1.0分,否则0.0分)和格式奖励(鼓励模型遵循推理和答案的输出范式)。
结构化环境带来的推理能力跃升
论文在Freebase知识图谱上构建训练数据,使用WebQSP和CWQ数据集,在Qwen2.5-7B-Instruct、Llama3.1-8B-Instruct、Qwen2.5-7B和Qwen3-8B四个模型上进行实验。
RL w/ SIE相比无上下文的RL训练(RL w/o Context)取得了显著提升:在WebQSP数据集上平均提升34.4%(Qwen2.5-7B-Instruct提升33.7%,Qwen3-8B提升41.6%);在CWQ数据集上平均提升50.2%(最高51.0%);在GrailQA数据集上平均提升62.6%(最高65.0%)。
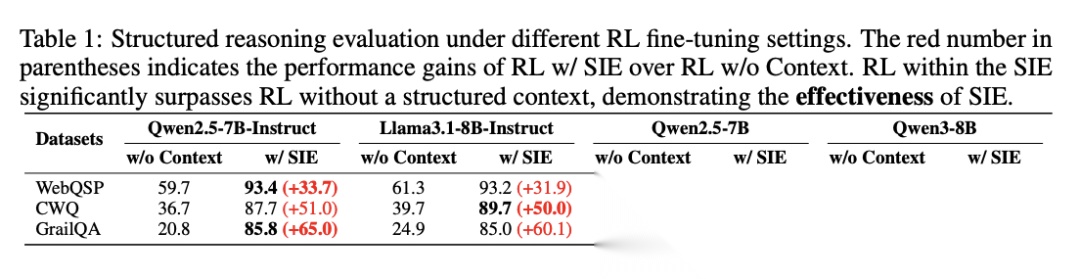
[Table 1: 不同方法在结构化推理任务上的表现] 对比了CoT、RL w/o Context、SFT w/ SRD和RL w/ SIE四种方法在WebQSP、CWQ和GrailQA三个数据集上的准确率,RL w/ SIE在所有模型和数据集上均取得最佳性能。
更令人惊讶的是训练效率。论文对比了RL w/ SIE与监督微调方法SFT w/ SRD(在蒸馏的结构化推理数据上训练):RL w/ SIE比SFT w/ SRD额外提升超过40%。在Qwen2.5-7B-Instruct上,WebQSP准确率为93.4% vs 40.5%(提升52.9%),CWQ准确率为87.7% vs 43.3%(提升44.4%)。SFT w/ SRD相比零样本思维链提示(CoT)平均提升11.4%,而RL w/ SIE平均提升53.7%。
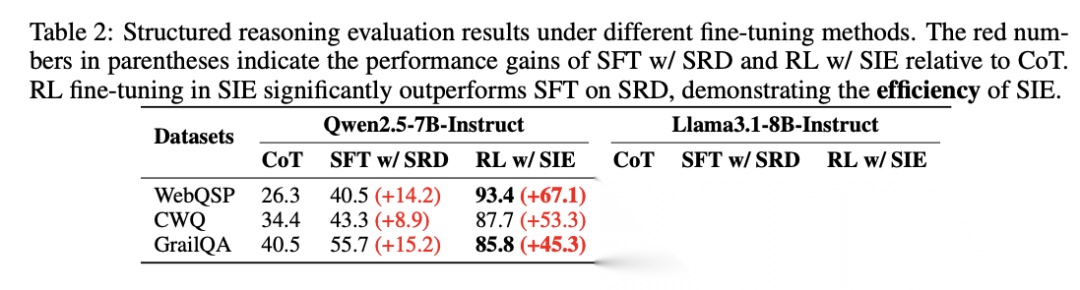
[Table 2: RL与SFT的效率对比] 展示了RL w/ SIE相比SFT w/ SRD在训练效率上的显著优势,证明强化学习在结构化环境中的探索能力远超监督学习。
推理能力成功迁移到数学和逻辑任务
论文在域外任务上测试了模型的泛化能力,包括数学推理(GSM8K、MATH500)和逻辑推理(KK-easy、KK-hard)。RL w/ SIE在所有域外任务上都实现了显著提升:GSM8K平均提升20.4%(Qwen2.5-7B提升59.2%),MATH500平均提升18.1%(Qwen2.5-7B提升29.0%),KK-easy平均提升12.3%,KK-hard平均提升11.1%。
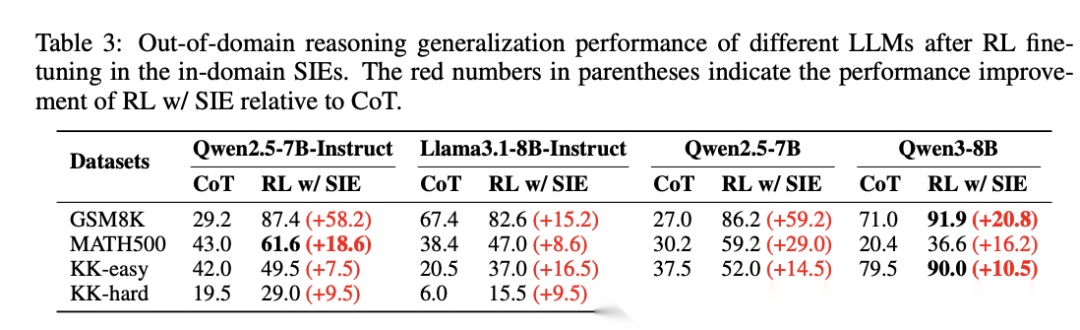
[Table 3: 域外泛化能力] 展示了在知识图谱环境中训练的模型如何将学到的组合推理能力有效迁移到数学和逻辑推理任务。
这说明模型在结构化环境中学到的不是死记硬背的模式,而是可迁移的组合推理能力。
信息不完整时依然稳健
论文系统研究了模型在信息不完整环境中的表现。即使在SIE-0%(完全不包含支持信息)的极端情况下,Qwen2.5-7B-Instruct在WebQSP上仍提升55.0%。从SIE-100%到SIE-0%,平均提升分别为64.2%、62.8%、61.6%、60.2%、52.5%,展现出惊人的鲁棒性。
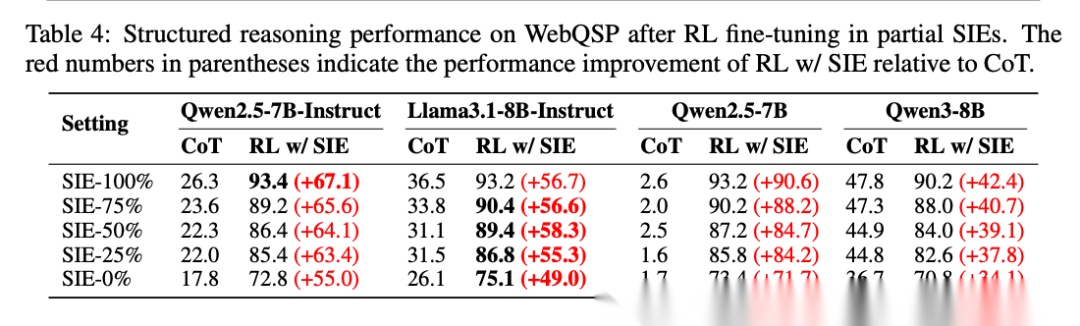
[Table 4: 部分SIE上的性能] 展示了模型在不同信息完整度的环境中的表现,证明即使缺失关键信息,模型仍能通过探索推断出正确答案。
更重要的是,这种鲁棒性也体现在泛化能力上。Qwen2.5-7B-Instruct在所有部分SIE上都保持正向泛化:从SIE-100%到SIE-0%,平均泛化提升分别为40.3%、40.1%、38.6%、38.6%、38.6%。
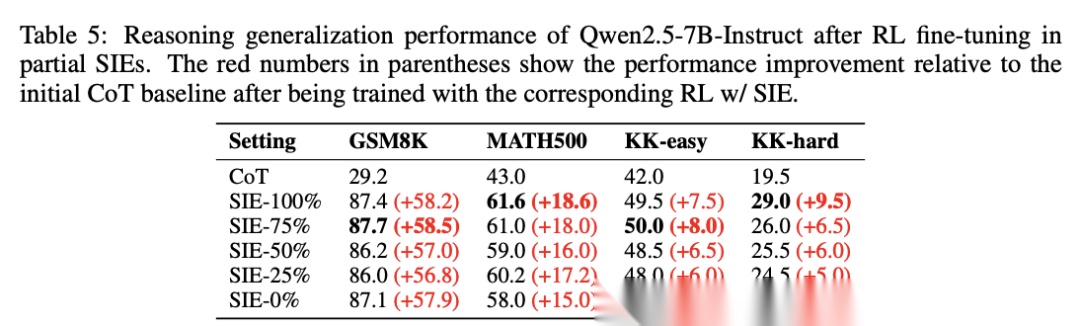
[Table 5: 部分SIE的泛化鲁棒性] 展示了在不同信息完整度环境中训练的模型在域外任务上的泛化表现,证明信息约束不会损害泛化能力。
算法通用性与冷启动影响
论文验证了SIE框架对主流RL算法的适用性。GRPO和REINFORCE++性能相当(WebQSP准确率93.4% vs 93.1%),PPO性能稍弱但仍有效(85.4%)。
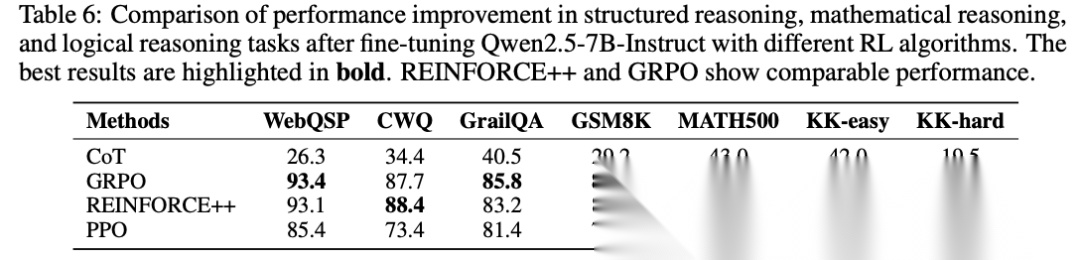
[Table 6: 不同RL算法的表现] 对比了GRPO、REINFORCE++和PPO三种算法在SIE框架下的性能,证明框架的算法无关性。
论文还研究了从SFT检查点开始RL训练的影响。结果显示,从SFT冷启动的RL训练(RL w/ SIE f/ SFT)在结构化推理上性能受限(WebQSP 88.5% vs 93.4%),但域外泛化更强(KK-hard 33.5% vs 29.0%)。这表明SFT约束了环境探索能力,限制了结构化推理的最大潜力。

[Table 7: SFT冷启动的影响] 对比了从随机初始化和SFT检查点开始RL训练的效果,揭示了监督学习与强化学习在探索-利用权衡上的差异。
X说
SIE框架解决了LLM推理训练的三难困境:通过从结构化数据自动构建环境实现可扩展性,通过组合推理能力的学习实现可泛化性,通过结构化验证实现可验证性。
关键发现可以总结为:结构化环境中的强化学习不仅大幅提升域内推理能力(提升30-65%),还能有效迁移到域外任务(提升10-60%);相比监督学习,强化学习在结构化环境中的探索能力带来额外40%以上的性能提升;即使在信息不完整的环境中,模型仍能通过探索推断缺失信息,实现稳健提升。
这为大模型推理能力的训练提供了新的范式:不需要昂贵的专家标注,不局限于特定领域,只需要大规模结构化数据和可验证的反馈信号。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)