YOLOv8(4) 模型训练
文章目录
规范文件
YOLO 系列模型(如 YOLOv8)训练前的数据集目录规范,核心作用是让模型能正确识别并关联 “图片 - 标签”,保证训练流程顺利启动,各部分解析如下:
- 核心目录结构(适配 YOLO 训练要求)
数据集需按以下层级组织:
数据集根目录
├─ images # 存放所有图片文件
│ ├─ train # 训练集图片(模型训练时用于学习特征)
│ └─ val # 验证集图片(训练中实时评估模型性能)
└─ labels # 存放所有标签文件(与图片一一对应)
├─ train # 训练集标签(对应images/train下的图片)
└─ val # 验证集标签(对应images/val下的图片)
- 关键要求说明
“一一对应” 的必要性:labels 目录下的标签文件名,必须与对应的 images 目录下的图片文件名完全一致(仅后缀不同,如fire_001.jpg对应fire_001.txt)。这是 YOLO 模型加载数据的核心规则 —— 模型会通过文件名自动关联图片与标签,若不对应则会出现 “找不到标签” 的错误,导致训练中断。
目录的功能定位:
train(训练集):占数据集的 70%-80%,是模型学习目标特征(如火灾的形状、颜色)的主要数据;
val(验证集):占数据集的 20%-30%,用于训练过程中实时评估模型的泛化能力(避免过拟合),不参与模型参数更新。
该结构是 YOLO 系列模型的标准数据集格式,按此规范整理后,只需在训练配置文件(如data.yaml)中指定数据集根目录,模型即可自动加载训练 / 验证数据。
这个组织层级不是完全固定的,支持自定义,但需结合 YOLO 模型的配置规则来调整:
- 默认:推荐使用该层级(无需额外配置)
YOLOv8(Ultralytics 框架)的默认数据加载逻辑是匹配
“images/train→labels/train、images/val→labels/val” 的层级,
按此结构整理数据集,只需在data.yaml中指定数据集根目录即可自动加载,无需额外配置路径,是最便捷的方式。
- 支持自定义:需通过data.yaml配置路径
若想调整层级(比如将图片 / 标签放在其他目录、或重命名 train/val),可通过修改训练配置文件(data.yaml)实现,例如:
若将训练集图片放在dataset/train_imgs、标签放在dataset/train_labels,只需在data.yaml中指定:
train: dataset/train_imgs # 自定义训练集图片路径
val: dataset/val_imgs # 自定义验证集图片路径
nc: 1 # 类别数
names: ['fire'] # 类别名称
此时标签文件的路径需与图片路径对应(或通过框架的–label-dir参数指定标签目录)。
- 固定约束:图片与标签的 “文件名必须一一对应”
无论层级如何自定义,标签文件名必须与对应图片的文件名完全一致(仅后缀不同,如fire_001.jpg对应fire_001.txt)—— 这是 YOLO 关联 “图片 - 标签” 的核心规则,无法修改
val(验证集)中的图片必须和训练集一样包含完整的标注信息(比如人的标注),否则模型无法完成验证环节。
- 为什么验证集必须有标注?
验证集的核心作用是客观评估模型的预测效果,而评估的前提是 “有标准答案可对比”
模型在验证集图片上会输出预测结果(比如预测 “这张图里有人,坐标是 xxx”);
系统需要用验证集的标注(“标准答案:这张图里有人,坐标是 yyy”)和预测结果对比,计算精度、召回率等指标,判断模型是否学到位、是否过拟合;
如果验证集图片没有标注,系统没有 “标准答案”,就无法完成对比评估,训练过程中会报错(比如 “找不到验证集标签”),或无法输出有效的验证指标。
主目录下创建datasets
对于yolov8而言,必须创建名为 datasets 的文件夹
将前面的文件夹拷入datasets文件夹
配置.yaml文件(数据集描述文件)
.yaml是 YOLO 系列模型(尤其是 YOLOv8)训练时必不可少的核心配置文件,下面我会从文件本身的属性、编写规范、使用注意事项等维度,帮你全面理解这个文件:
一、文件基础属性
文件类型:YAML 格式文件(后缀.yaml/.yml),是一种轻量级的配置文件格式,比 JSON 更易读写,专门用于传递结构化数据;
核心作用:作为模型与数据集之间的 “桥梁”,告诉 YOLO 模型:
数据集的存储位置(训练 / 验证 / 测试集路径);
数据集包含的类别数量、类别名称及对应的 ID;
可选:是否使用数据增强、类别颜色(可视化用)等附加配置。
二、完整的data.yaml编写模板(以火灾检测为例)
# 1. 数据集路径配置(核心)
path: ./fire_dataset # 数据集根目录(推荐用相对路径,避免绝对路径移植报错)
train: images/train # 训练集图片路径(相对于path)
val: images/val # 验证集图片路径(相对于path)
test: images/test # 测试集图片路径(可选,留空则不使用)
# 2. 类别配置(核心)
nc: 2 # number of classes,类别总数(比如火灾+烟雾=2类)
names: # 类别名称列表,顺序对应类别ID(0、1、2...)
0: fire # 类别ID 0 → 火焰
1: smoke # 类别ID 1 → 烟雾
三 、 延续之前文件组织形式、本次测试所使用的.yaml文件的编写
自定义的:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: fire-smoke.v1i.yolov8_new # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
names: ['fire', 'smoke']
代码说明(该文件是 YOLOv8 训练的核心配置文件,用于指定数据集信息)
该文件的作用是告诉 YOLOv8 模型 “数据集在哪里、包含哪些类别”,各部分功能如下:
-
数据集路径配置区
path: fire-smoke.v1i.yolov8_new:指定数据集的根目录为fire-smoke.v1i.yolov8_new(模型会从这个目录开始查找图片 / 标签);
train: images/train:指定训练集图片的路径(是相对于path的相对路径,实际完整路径为bvn/images/train);
val: images/val:指定验证集图片的路径(实际完整路径为bvn/images/val);
test: :指定测试集图片的路径(此处留空表示暂不使用测试集,属于可选配置)。 -
类别配置区
names:定义数据集的类别列表,键是 “类别 ID”,值是 “类别名称”;
0: fire:表示类别 ID 为 0 的类别名称是fire;
1: smoke:表示类别 ID 为 1 的类别名称是smoke。
核心作用
YOLOv8 在训练时,会通过该文件:
定位到训练 / 验证集的图片;
自动匹配对应路径下的标签文件(标签文件名需与图片名一致);
识别类别 ID 对应的名称,完成 “预测结果→类别名称” 的映射,同时保证训练时的类别标注与配置一致。
一般来说,从平台下载下来对应版本的数据集,会自带配置好的.yaml文件,可以拿来直接用,下面是为了说
明这个文件的用处。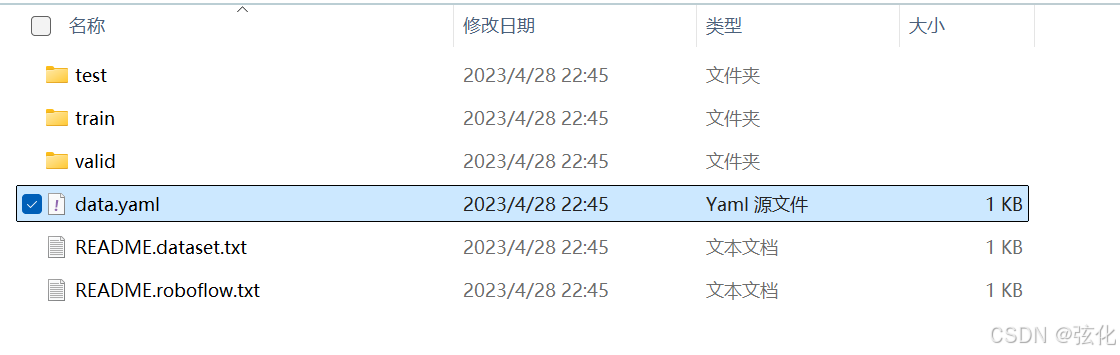
训练集自带的(建议使用):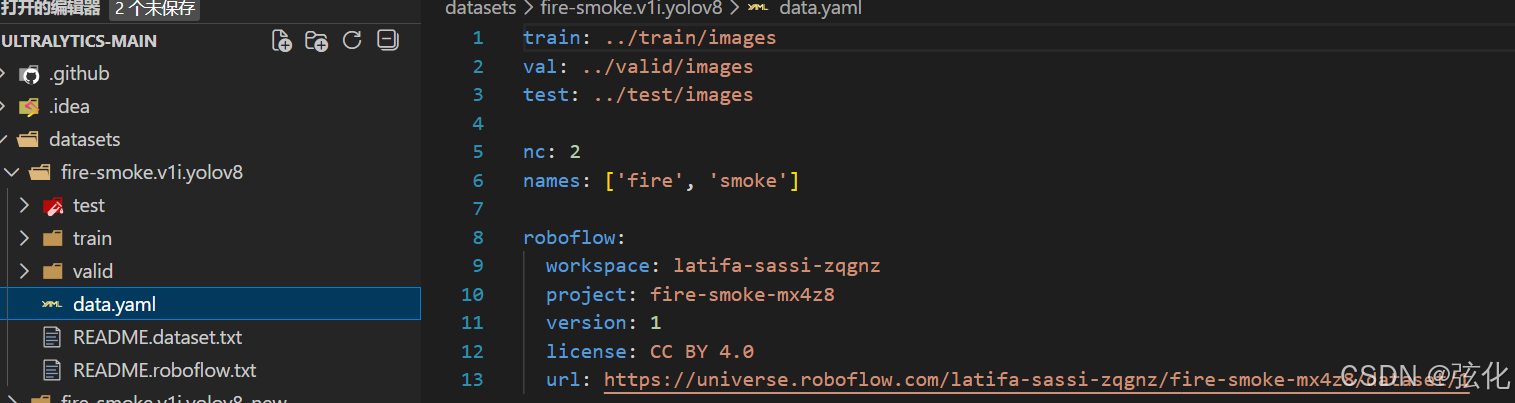
解压后的数据集文件夹
├─ train
│ └─ images # 训练集图片(对应train: ../train/images)
├─ valid
│ └─ images # 验证集图片(对应val: ../valid/images)
├─ test
│ └─ images # 测试集图片(对应test: ../test/images)
└─ data.yaml # 配置文件本身
path: E:\biyesheji\ultralytics-main\datasets\fire-smoke.v1i.yolov8 # dataset root dir
train: ./train/images # 训练集图片路径
val: ./valid/images # 验证集图片路径
test: ./test/images # 测试集图片路径
nc: 2
names: ['fire', 'smoke']
roboflow:
workspace: latifa-sassi-zqgnz
project: fire-smoke-mx4z8
version: 1
license: CC BY 4.0
url: https://universe.roboflow.com/latifa-sassi-zqgnz/fire-smoke-mx4z8/dataset/1
./train/images:表示 “当前data.yaml所在目录下的 train/images”,是 Roboflow 数据集的标准路径格式;
标签文件会自动存放在train/labels、valid/labels、test/labels目录,YOLO 会自动匹配,无需在 yaml 中指定。
- 类别配置(核心)
nc: 2:明确数据集有 2 个类别,与names列表长度一致(必须匹配,否则训练报错);
names: [‘fire’, ‘smoke’]:类别顺序对应标签文件中的 ID—— 标签里的0代表fire,1代表smoke,这是模型识别类别的核心映射规则。
开始训练
第一种方法: 指令运行:
yolo task=detect mode=train model=./yolov8n.pt data=E:\biyesheji\ultralytics-main\datasets\fire-smoke.v1i.yolov8\data.yaml epochs=30 workers=1 batch=16
yolo 是 Ultralytics YOLOv8 的命令行入口命令,所有 YOLOv8 的任务(训练、验证、预测)都通过该命令启动。
task=detect指定当前任务类型为目标检测(YOLOv8 还支持classify(分类)、segment(分割)等任务,需对应调整此参数)。
mode=train指定运行模式为训练模式(其他常用模式:val(验证)、predict(预测)、export(模型导出))。
model=./yolov8n.pt指定训练使用的预训练模型权重:
./yolov8n.pt表示加载当前目录下的yolov8n.pt文件;
yolov8n中的n是 “nano” 的缩写,代表 YOLOv8 中体积最小、速度最快的轻量级预训练模型,适合快速训练或显存较小的设备。
data=E:\biyesheji\ultralytics-main\datasets\fire-smoke.v1i.yolov8\data.yaml 指定数据集配置文件(即之前介绍的data.yaml),告诉模型数据集的路径、类别数量 / 名称等信息,是模型关联数据集的核心参数。
epochs=30指定训练的总轮数:表示整个训练数据集会被模型完整学习 30 次;轮数越多模型学习越充分,但也可能导致过拟合,30 是基础训练轮数。
workers=1指定数据加载的工作进程数:用于并行加载训练数据,加快数据读取速度;设置为 1 通常是为了适配 Windows 环境(Windows 对多进程支持较差,多进程易报错)。
batch=16指定批次大小:表示每次训练时,同时输入给模型的图片数量;批次越大训练效率越高,但对显卡显存要求越高(16 是显存中等设备的常用设置,需根据自身显卡调整)
运行中: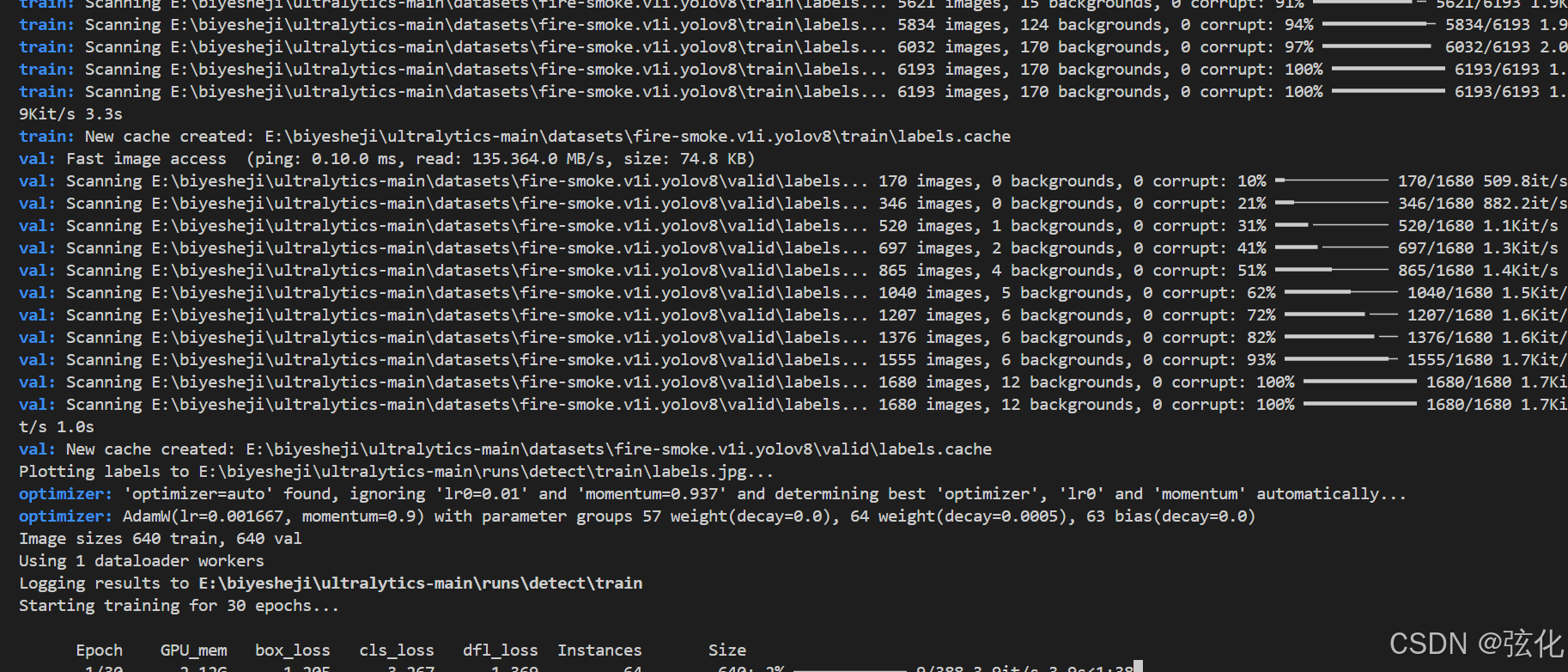
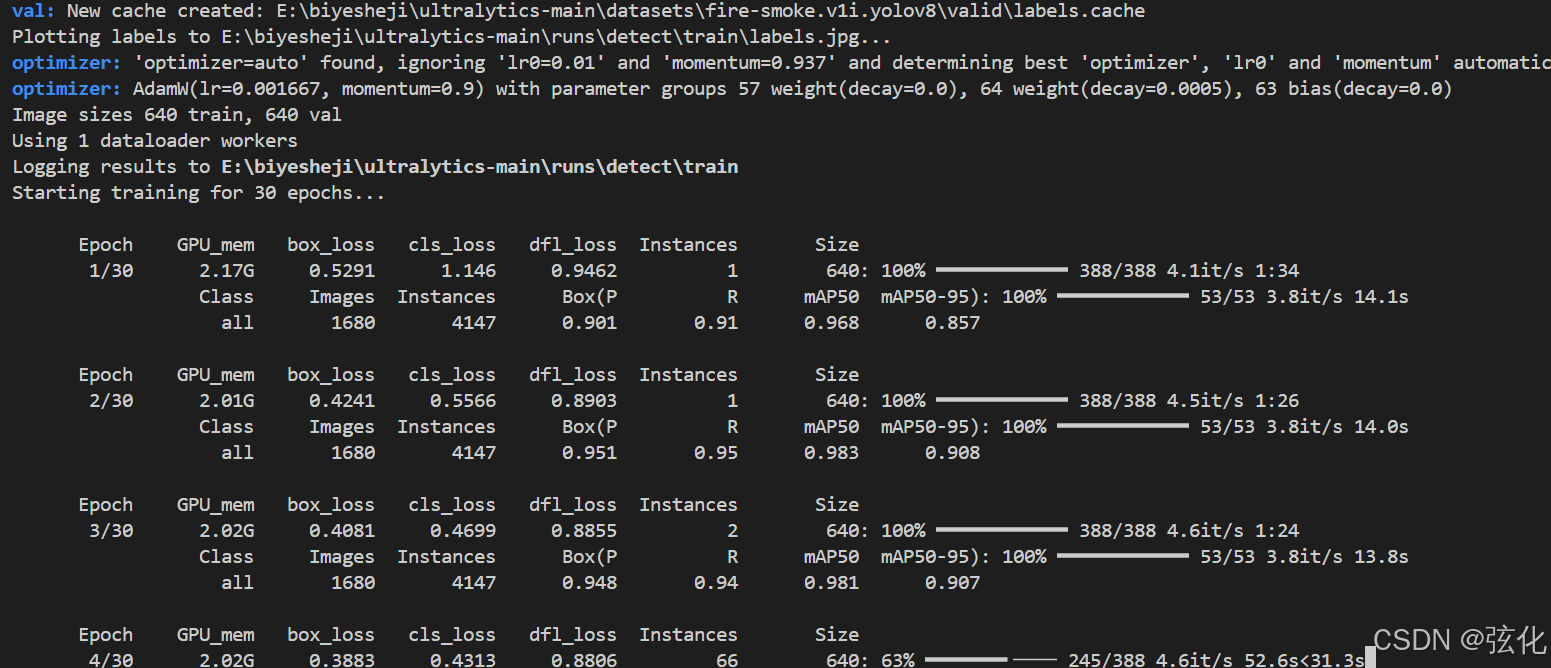
这是 YOLOv8 火灾烟雾检测模型的训练过程日志,可拆分为预处理 / 配置、训练基础信息、每轮训练指标、模型当前状态几个模块,各部分含义如下:
一、预处理与优化器配置
这是训练前的准备工作:
“New cache created: …labels.cache”:YOLO 自动生成标签缓存文件,后续训练时可快速加载标签、避免重复解析,以此提升训练效率。
“Plotting labels to …labels.jpg”:生成数据集标签分布可视化图(保存到训练日志目录),用于检查 “火灾”“烟雾” 等类别的样本分布是否均衡。
“optimizer: ‘optimizer=auto’ found…”:启用自动优化器模式,会忽略手动设置的学习率、动量,自动选择更优配置;后续 “optimizer: AdamW (lr=0.001667, momentum=0.9)…” 表示最终选定 AdamW 优化器(兼顾收敛速度与防过拟合),同时对不同参数组设置权重衰减,进一步降低过拟合风险。
二、训练基础参数
这些是训练的核心基础设置:
“Image sizes 640 train, 640 val”:训练集、验证集图片会统一缩放到 640×640 像素(YOLOv8 默认输入尺寸,平衡检测精度与速度)。
“Using 1 dataloader workers”:数据加载进程数设为 1,是适配 Windows 环境的设置,避免多进程加载时出现报错。
“Logging results to …runs/detect/train”:训练日志、模型权重、可视化结果会保存在该目录(YOLO 默认结果存储路径)。
“Starting training for 30 epochs…”:本次训练总轮数为 30 轮,当前已正式启动训练。
三、每轮训练指标
每轮日志包含训练损失、验证集评估两类指标:
训练损失指标(数值越小越好):
“GPU_mem 2.01G” 是当前训练占用的显卡显存;“box_loss 0.4241” 是边界框回归损失,值越小代表目标框定位越准确;“cls_loss 0.5566” 是类别分类损失,值越小代表 “火灾 / 烟雾” 的类别预测越准确;“df1_loss 0.8903” 是 YOLOv8 特有的分布焦点损失,用于优化样本不平衡问题,值越小效果越好。
验证集评估指标(越接近 1 越好):
“Box § 0.951” 是精确率,指预测为 “火灾 / 烟雾” 的结果中实际正确的比例;“R 0.95” 是召回率,指实际为 “火灾 / 烟雾” 的目标中被成功检测到的比例;“mAP50 0.983” 是 IoU=0.5 时的平均精度(核心检测准度指标);“mAP50-95 0.908” 是 IoU 从 0.5 到 0.95 的平均精度(更严格的检测准度标准)。
模型当前状态
从日志来看,训练到第 4 轮时,验证集的 mAP50 已接近 0.98,说明模型在验证集上的检测准度很高,收敛状态良好。后续训练需关注这些指标的变化,若出现指标明显下降,可能是模型发生了过拟合。
第二种: python 程序启动
注意:有的环境需要把worker设置为0才能用.py运行
,核心原因是Windows 系统的多进程机制与 Python 数据加载器的兼容性问题,具体拆解如下:
一、先理解workers参数的本质
workers是 YOLO 数据加载器(DataLoader)的子进程数:
workers > 0:启动多个子进程并行加载训练数据(比如 workers=1 就是 1 个额外子进程),目的是让 “数据加载” 和 “模型训练” 并行,提升整体训练速度;
workers = 0:禁用多进程,仅用主进程加载数据(单进程模式),加载速度稍慢,但兼容性最好。
二、Windows vs. 类 Unix 系统(Linux/macOS)的多进程差异(核心原因)
Python 的multiprocessing(多进程)模块在不同系统下的启动方式不同,这是导致报错的关键:
Linux/macOS:采用fork方式启动子进程 —— 直接复制主进程的内存空间(包括模型、数据集配置、文件句柄等),子进程能无缝继承所有资源,因此workers=1/2/4都能正常运行;
Windows:采用spawn方式启动子进程 —— 不会复制主进程,而是重新启动一个全新的 Python 解释器,并从头执行整个脚本。
这会导致子进程重复初始化数据集、模型等资源,甚至触发 “资源占用”“管道断裂(BrokenPipeError)”“标签文件找不到” 等报错;
更关键的是:YOLO 的DataLoader在 Windows 的spawn模式下,无法正确传递数据集的缓存、路径等关键信息,最终导致训练启动失败。
三、为什么命令行启动时 workers=1 可能能用,Python 脚本必须设 0?
命令行启动:脚本是 “一次性执行”,spawn启动的子进程仅加载数据相关逻辑,不会重复执行训练核心代码,因此偶尔能兼容 workers=1;
Python 脚本启动(尤其是 IDE 中运行):脚本的执行上下文更复杂(比如有全局变量、模型初始化代码),spawn启动的子进程会重新执行整个脚本的所有代码,导致资源冲突,只有设workers=0(禁用多进程)才能避免这种冲突。
四、补充说明:workers=0 的影响
唯一缺点:数据加载速度稍慢(主进程既要加载数据又要训练),但完全不影响训练结果(模型精度、收敛速度都不受影响);
若你的显卡显存 / CPU 性能较好,即使 workers=0,训练效率的下降也几乎可以忽略(尤其像你训练 30 轮、批次 16 的场景)。
# 导入YOLOv8核心库
from ultralytics import YOLO
import os
# 设置Python脚本的工作目录(可选,避免路径问题)
# 建议将脚本放在ultralytics-main目录下,或手动指定工作目录
os.chdir(r"E:\biyesheji\ultralytics-main")
# 1. 加载预训练模型(对应命令行的model=./yolov8n.pt)
model = YOLO("./yolov8n.pt") # 加载YOLOv8n预训练权重
# 2. 执行训练(参数与命令行一一对应)
results = model.train(
task="detect", # 任务类型:目标检测(对应task=detect)
mode="train", # 运行模式:训练(对应mode=train)
data=r"E:\biyesheji\ultralytics-main\datasets\fire-smoke.v1i.yolov8\data.yaml", # 数据集配置文件路径
epochs=30, # 训练轮数(对应epochs=30)
workers=0, # 数据加载进程数(对应workers=1) # 有的环境需要把worker设置为0才能用.py运行
batch=16, # 批次大小(对应batch=16)
device=0, # 可选:指定显卡(0为第一张显卡,cpu为使用CPU),不指定则自动检测
verbose=True # 可选:显示训练详细日志
)
# 训练完成后可打印验证结果(可选)
print("训练完成!最终验证集指标:")
print(f"mAP@0.5: {results.results_dict['metrics/mAP50(B)']:.4f}") # 打印mAP@0.5指标
print(f"精确率: {results.results_dict['metrics/precision(B)']:.4f}") # 打印精确率
print(f"召回率: {results.results_dict['metrics/recall(B)']:.4f}") # 打印召回率
注意:在运行之前记得切换python的解释器。(切为目标虚拟环境)
1 : 点击以打开选择窗口
2 :选择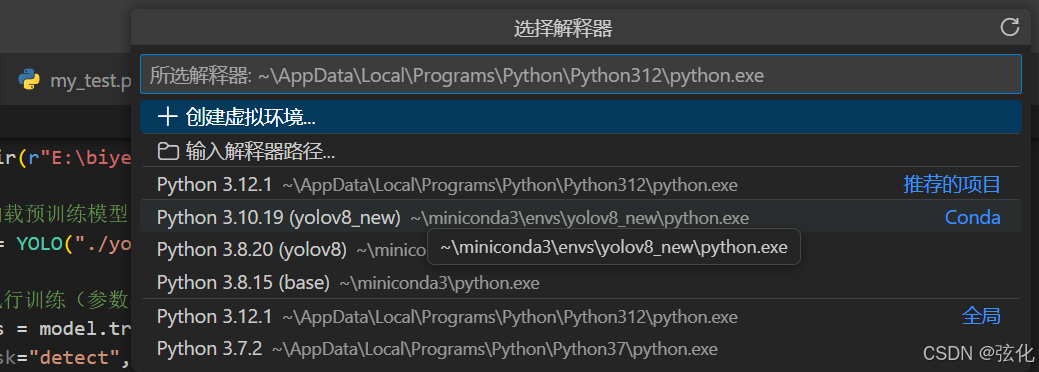
3 切换成功标志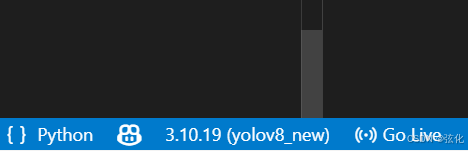
4 通过vscode启动
训练结果
- weights(文件夹)
内容:存放训练生成的模型权重文件,通常包含best.pt和last.pt两个核心权重:
best.pt:验证集指标(如 mAP)最优的模型权重;
last.pt:训练最后一轮的模型权重。
用途:后续用于目标检测预测、模型部署、微调训练等核心场景。 - args.yaml
内容:记录本次训练的所有参数配置(比如模型路径、数据集路径、epochs、batch、workers 等)。
用途:复现训练过程(后续用相同参数重新训练时可直接参考),或追溯训练时的配置细节。 - confusion_matrix.png
内容:混淆矩阵可视化图,展示模型对不同类别的 “预测结果 - 真实标签” 匹配情况(比如 “火灾” 被正确预测为火灾、或错误预测为烟雾的比例)。
用途:分析模型的分类错误类型,判断是否存在类别混淆的问题。 - F1_curve.png
内容:F1 值曲线(F1 是 “精确率” 与 “召回率” 的调和平均值),展示不同置信度阈值下模型的 F1 值变化。
用途:选择合适的置信度阈值(比如找到 F1 值最高的阈值),平衡模型的精确性与召回能力。 - labels_correlogram.jpg
内容:标签相关性图,展示数据集中不同类别(如 “火灾”“烟雾”)的共现关系(比如两类是否经常同时出现在同一张图中)。
用途:分析数据集的类别分布特征,判断是否存在类别关联的规律。 - labels.jpg
内容:数据集标签分布可视化图,展示每个类别的样本数量占比。
用途:检查数据集的类别均衡性(比如 “火灾” 和 “烟雾” 的样本数是否差距过大,避免模型偏向样本多的类别)。 - P_curve.png
内容:精确率曲线,展示不同置信度阈值下模型的精确率变化(精确率 = 预测正确的正样本数 / 所有预测为正样本的数量)。
用途:分析模型在 “高置信度预测” 时的精确性(比如阈值越高,精确率是否越稳定)。 - PR_curve.png
内容:精确率 - 召回率曲线,展示不同置信度阈值下 “精确率” 与 “召回率” 的权衡关系。
用途:评估模型的整体检测性能(曲线下面积越大,模型的精确率与召回率平衡效果越好)。 - R_curve.png
内容:召回率曲线,展示不同置信度阈值下模型的召回率变化(召回率 = 预测正确的正样本数 / 所有真实正样本的数量)。
用途:分析模型对 “真实目标” 的覆盖能力(比如阈值越低,是否能召回更多真实目标)。 - results.csv
内容:训练过程的数值化指标记录(比如每一轮的损失值、mAP、精确率、召回率等)。
用途:后续做自定义数据分析(比如绘制更精细的训练曲线),或统计训练过程的指标变化。 - results.png
内容:训练指标可视化图(包含损失曲线、mAP 曲线等),直观展示训练过程中 “损失下降”“指标上升” 的趋势。
用途:快速判断模型是否收敛(比如损失是否稳定下降、mAP 是否稳定上升),或是否出现过拟合(比如训练集指标高、验证集指标低)。 - train_batchX.jpg(如train_batch0.jpg)
内容:训练集批次图片的可视化结果,展示图片、真实标注框、模型训练时的预测框。
用途:观察模型在训练集上的拟合情况(比如模型是否能正确识别训练集中的目标)。 - val_batch0_labels.jpg & val_batch0_pred.jpg
内容:
val_batch0_labels.jpg:验证集批次图片的真实标注框可视化;
val_batch0_pred.jpg:验证集批次图片的模型预测框可视化。
用途:对比 “真实标签” 与 “模型预测” 的差异,直观评估模型在验证集上的检测效果(比如目标框是否准确、类别是否预测正确)。
使用所生成的模型
一、命令行指令(快速便捷,无需写代码)
- 检测单张图片
yolo task=detect mode=predict model=./runs/detect/train/weights/best.pt source="E:\biyesheji\test_images\fire_test.jpg" save=True
- 检测指定文件夹下的所有图片
yolo task=detect mode=predict model=./runs/detect/train/weights/best.pt source="E:\biyesheji\test_images" save=True
关键参数解释:
task=detect:指定目标检测任务(和训练时一致);
mode=predict:运行模式为 “预测 / 检测”;
model=./runs/detect/train/weights/best.pt:指定训练好的最优模型权重路径(需替换为你实际的best.pt路径);
source:待检测的文件 / 路径 —— 可以是单张图片路径、文件夹路径,甚至视频路径;
save=True:保存检测结果(会在runs/detect/predict目录生成带检测框的图片);
可选参数:
conf=0.5:置信度阈值(只显示置信度≥0.5 的检测结果,可调整);
device=0:指定显卡(0 为第一张显卡,cpu 为使用 CPU);
show=True:检测后直接弹窗显示图片(仅桌面环境可用)。
二、Python 脚本指令(灵活可控,可集成自定义逻辑)
from ultralytics import YOLO
import os
# 1. 加载训练好的best.pt模型
model = YOLO("./runs/detect/train/weights/best.pt") # 替换为你的best.pt实际路径
# 2. 执行检测(支持单张/文件夹/视频)
# 方式1:检测单张图片
results = model.predict(
source="E:\biyesheji\test_images\fire_test.jpg", # 单张图片路径
save=True, # 保存检测结果图片
conf=0.5, # 置信度阈值
device=0, # 指定显卡(0)或CPU("cpu")
show=False # 是否弹窗显示(False不显示,True显示)
)
# 方式2:检测指定文件夹下所有图片(注释方式1,取消注释方式2即可)
# results = model.predict(
# source="E:\biyesheji\test_images", # 图片文件夹路径
# save=True,
# conf=0.5,
# device=0
# )
# 3. 打印检测结果(可选,查看详细信息)
for result in results:
boxes = result.boxes # 获取检测框信息
print(f"检测到的目标数量:{len(boxes)}")
for box in boxes:
cls = box.cls # 类别ID
conf = box.conf # 置信度
xyxy = box.xyxy # 检测框坐标(左上x, 左上y, 右下x, 右下y)
print(f"类别:{model.names[int(cls)]},置信度:{conf:.2f},坐标:{xyxy}")
print(f"检测结果已保存到:{results[0].save_dir}") # 打印结果保存路径
脚本使用说明:
替换model = YOLO(“你的best.pt路径”)中的路径为实际的best.pt位置;
替换source为你要检测的图片 / 文件夹路径;
运行脚本:python predict_fire.py;
检测结果会自动保存到runs/detect/predict目录(每次运行会生成新的 predict 文件夹,如 predict2、predict3)。
三、使用注意事项
路径格式:Windows 系统下路径建议用r"E:\xxx\test.jpg"或"E:\xxx\test.jpg",避免转义字符报错;
模型路径:确保best.pt路径正确(训练后默认在runs/detect/train/weights/下);
结果查看:检测后的图片会在runs/detect/predict目录下,文件名和原文件一致,图片上会标注检测框、类别、置信度。
常见问题

为什么调整训练集目录后,要删除指定的settings.yaml文件?
因为第一次训练后,会生成一个配置文件,里面填写的目录的绝对路径是固定的。如果不删除后,重新生成,会找不到训练集。 或者可以手动gengga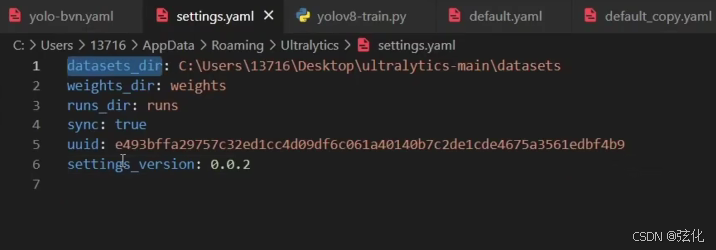
(如果是较新的源码版本,这里以及做了优化,可以不用管了)
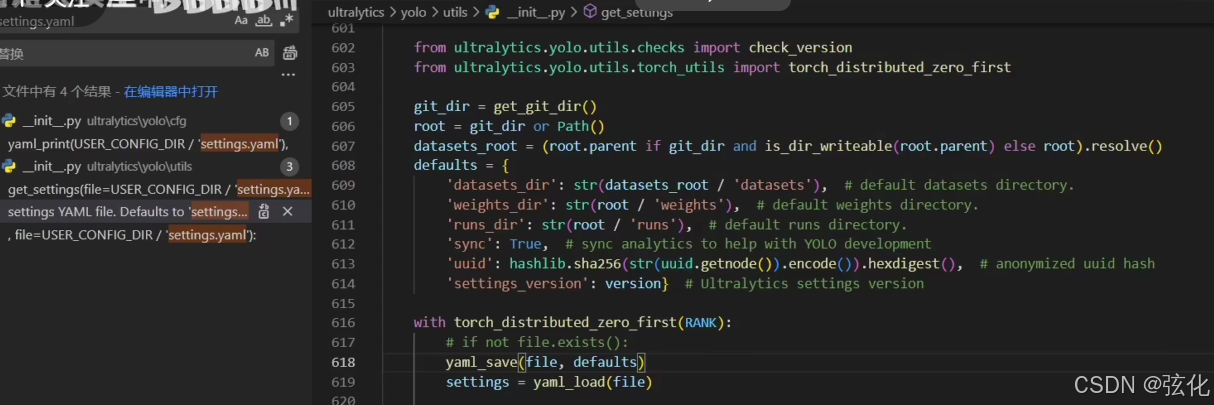
为了避免这种情况,也可以更改源码为(如果是较新的源码版本,这里以及做了优化,可以不用管了)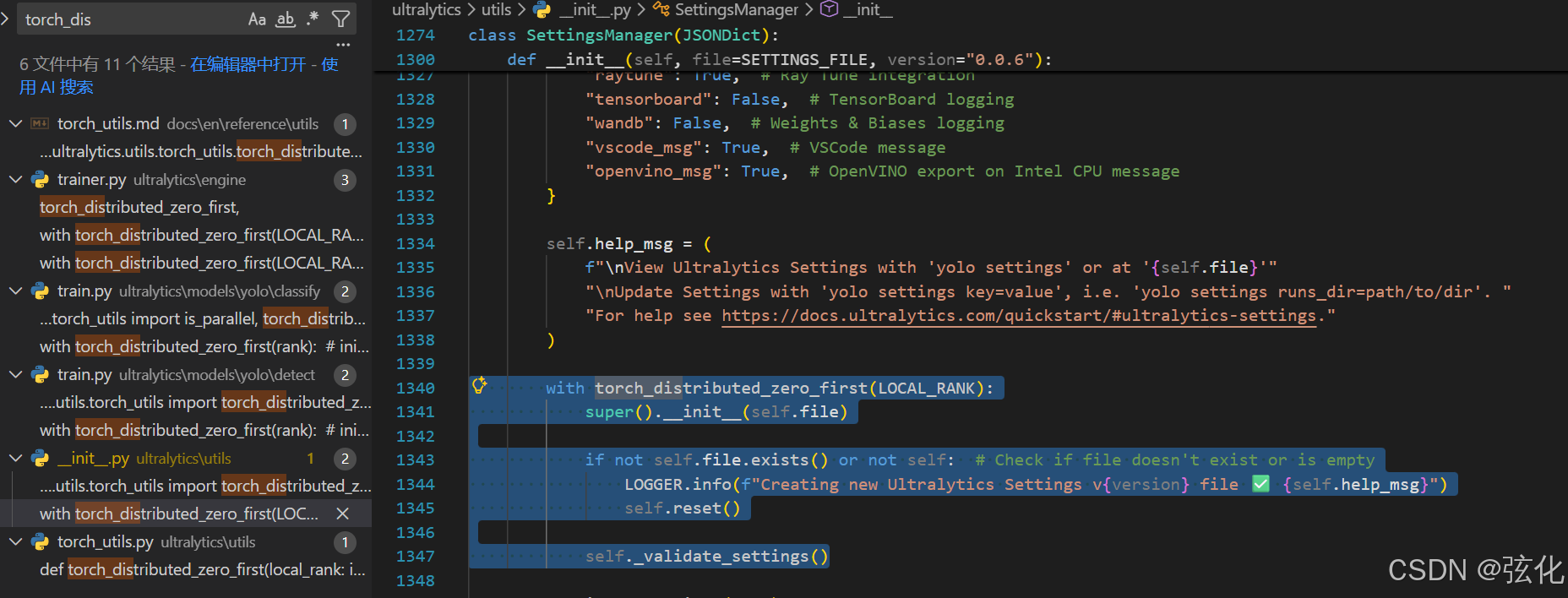
vscode中查找指定代码
Ctrl+Shift+F 也会使输入法变成繁体字,记得切回来
一、当前文件内查找(精准定位单行 / 片段)
基础查找:打开目标文件,按 Ctrl+F,编辑器顶部弹出搜索框,输入关键词,匹配内容会高亮,按 Enter 定位下一个,Shift+Enter 定位上一个;点击搜索框旁 “×” 清空,勾选 “大小写匹配”“全字匹配” 可精准筛选。
查找替换:按 Ctrl+H,输入查找与替换内容,支持逐个替换或全部替换。
正则匹配:勾选搜索框旁 .* 图标,输入正则表达式(如 \d{4} 匹配 4 位数字),实现复杂模式查找。
当前文件符号定位:按 Ctrl+Shift+O,输入函数、类、变量名,快速跳转到对应定义处,输入 @: 可按类型筛选(如 @method)。
二、全局 / 工作区查找(跨文件检索)
打开全局搜索:按 Ctrl+Shift+F 或点击左侧活动栏 “搜索” 图标,打开全局搜索面板。
输入搜索内容:在顶部搜索框输入代码片段 / 关键词,下方实时显示所有匹配结果(含文件名、行数)。
限定搜索范围:
包含 / 排除文件:在 “files to include” 输入 *.js *.vue 等限定类型,“files to exclude” 输入路径 / 类型排除无关文件。
正则 / 大小写 / 全字匹配:通过面板上的开关启用,适配复杂搜索场景。
跳转与替换:双击结果跳转到对应位置;按 Ctrl+Shift+H 可全局批量替换。
三、符号与引用查找(定位定义 / 引用)
全局符号搜索:按 Ctrl+T,输入符号名(函数、类等),快速跨文件定位所有匹配符号。
查找引用:选中变量 / 函数名,按 Shift+F12 或右键选择 “Find All References”,列出所有引用位置,方便追踪代码调用。
快速打开文件:按 Ctrl+P,输入文件名快速定位文件,输入 @ 可在文件内搜符号,输入 : 可跳转到指定行号(如 index.js:120)。
四、进阶技巧
命令面板调用:按 Ctrl+Shift+P,输入 “Search: Find in Files”“Search: Find” 等命令,触发对应查找功能。
面包屑导航:编辑器顶部面包屑,点击文件夹、文件名、符号名,快速在代码间切换定位。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)