为什么训练侧大家爱 MoE,但部署侧很多公司最后还是更偏爱 Dense?
这几年大模型架构几乎都在卷
MoE,原因并不难理解:它能把模型总容量继续做大,同时把单 token 的激活计算控制在一个相对可接受的范围内,所以训练侧和榜单侧都很喜欢。但一到真实部署环节,很多团队最后又会重新偏向Dense。原因不是 Dense 更先进,而是部署真正要结算的,不只是 active parameters 这一本账,还包括权重驻留、跨卡通信、batch 敏感性、tail latency、量化成熟度、运维复杂度和最终利润表。
关键词: MoE、Dense、训练成本、推理部署、active parameters、总参数、通信开销、吞吐、延迟、工程复杂度、模型选型
这几年你如果持续关注开源大模型,会发现一个很明显的现象:
- 训练侧越来越爱
MoE - 发布侧越来越喜欢讲
total params和active params - 论文和榜单里,大参数
MoE模型越来越常见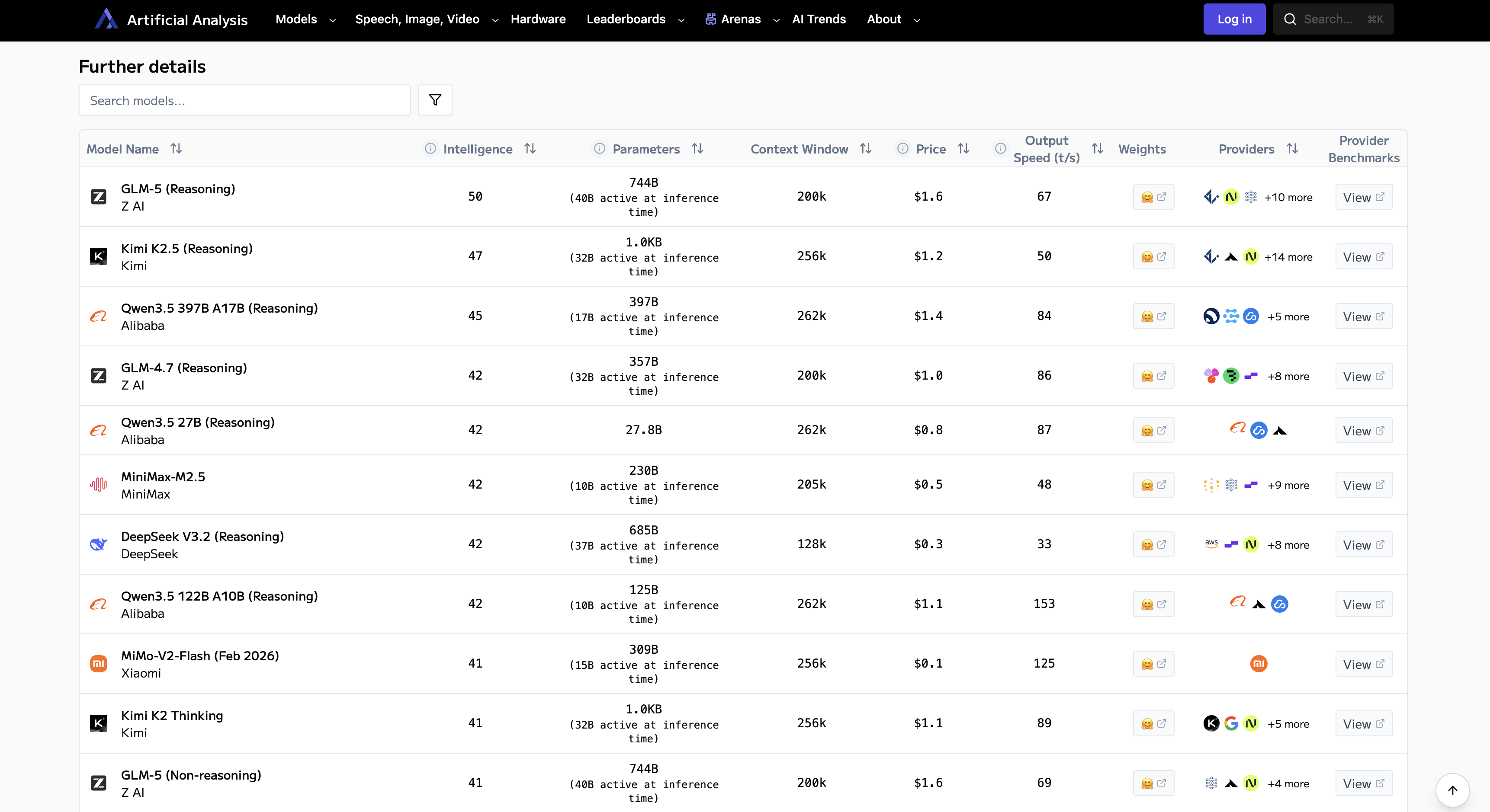 图片来源:https://artificialanalysis.ai/models/open-source
图片来源:https://artificialanalysis.ai/models/open-source
(Qwen2.5-27B dense模型在一众大规模参数MoE模型中脱颖而出~)
但到了真正要做服务上线、成本核算和资源规划的时候,你又会发现另一面:
- 很多公司虽然承认
MoE很强 - 但真正长期稳定跑在线业务时,最后还是更偏爱
Dense - 或者至少,会优先把
Dense当成更稳妥的基线方案
这就引出一个非常值得讲透的问题:
为什么训练侧大家爱 MoE,但部署侧很多公司最后还是更偏爱 Dense?
这不是一个“谁先进谁落后”的问题,而是一个典型的“优化目标不同,所以最优解不同”的问题。
如果只用一句话先概括全文,我会这样说:
MoE 更像训练世界里的扩容利器,Dense 更像部署世界里的稳定货币。
下面我们把这件事拆开讲。
先给一张表:为什么训练侧更爱 MoE,但部署侧常常更偏 Dense
如果你只想先抓住全文主线,可以先看这张表:
| 比较维度 | Dense | MoE | 谁通常更占优 |
|---|---|---|---|
| 模型容量扩张 | 参数一变大,每个 token 的计算通常也同步变大 | 总容量可以继续放大,但单 token 只激活部分 experts | 训练侧通常更偏 MoE |
| 单 token 激活计算 | 接近全量主干参数都参与 | 只激活部分 experts,active params 更小 | 训练侧通常更偏 MoE |
| 继续冲 benchmark 的潜力 | 能提升,但越往上堆成本越陡 | 更适合继续做大容量、拉高能力上限 | 训练侧通常更偏 MoE |
| 参数叙事和传播力 | 更直接,但“总量”和“激活量”通常是同量级 | 可以同时讲 total params 和 active params | 研究发布侧通常更偏 MoE |
| 权重驻留压力 | 结构规整,但参数多了显存照样涨 | 虽然 active 小,但大量 expert 权重仍要驻留或高效分布 | 部署侧通常更偏 Dense 的可控性 |
| 多卡通信复杂度 | 有通信,但路径更规整 | 常常额外引入 expert 路由和更重的 all-to-all 通信 | 部署侧通常更偏 Dense |
| 延迟稳定性 | 执行路径固定,更容易控 P95/P99 | 路由和负载倾斜会带来更大抖动 | 部署侧通常更偏 Dense |
| batch 依赖程度 | 对碎片化请求更友好 | 更依赖较好的 batch 和系统组织度来摊薄开销 | 部署侧通常更偏 Dense |
| 量化和工具链成熟度 | 通常更成熟,兼容性更好 | 取决于框架和实现,变体多、门槛更高 | 部署侧通常更偏 Dense |
| 运维和排障复杂度 | 更熟悉、更线性 | 要处理路由、热点 expert、负载均衡、跨卡流量 | 部署侧通常更偏 Dense |
| 组织能力要求 | 普通推理团队也更容易接住 | 更依赖强框架、强系统和强并行能力 | 大多数公司通常更偏 Dense |
| 最适合的角色 | 稳定交付、低摩擦上线、通用基线 | 继续冲能力上限、适合强基础设施团队榨取红利 | 两者各有最优场景 |
如果把这张表压缩成一句话,就是:
MoE 更擅长解决“怎么把模型继续做大”的问题,Dense 更擅长解决“怎么把模型稳定交付出去”的问题。
一、先说结论:训练侧和部署侧,压根不是在优化同一件事
很多人会误以为:
- 训练时表现更优的架构,部署时也应该更优
- 榜单更高的架构,线上性价比也应该更高
- active params 更小的模型,推理一定更便宜
但现实是,训练侧和部署侧往往根本不是在为同一个目标函数服务。
训练侧真正关心的通常是:
- 能不能把模型能力继续做上去
- 能不能在给定训练预算内,把总容量扩得更大
- 能不能在 benchmark 上建立更强的领先优势
- 能不能在 scaling 上继续找到更有利的斜率
而部署侧更关心的是:
- 能不能装下
- 能不能稳定跑
- 能不能把吞吐做高
- 能不能把延迟压低
- 能不能把跨卡通信和尾延迟控制住
- 能不能在现有硬件和团队能力下,把利润表做正
也就是说:
- 训练侧更关注“能力上限”
- 部署侧更关注“单位成本下的可用智能”
这是全文最重要的前提。
只要这个前提不先建立,后面所有关于 Dense 和 MoE 的讨论都很容易鸡同鸭讲。
二、为什么训练侧会越来越爱 MoE
先说训练侧为什么如此偏爱 MoE。
原因并不神秘,核心只有一句:
MoE 给了大家一条继续放大模型容量,但不让每个 token 的计算量同步爆炸的路。
这件事对训练侧太重要了。
1. Dense 扩到后面,边际成本会越来越难看
Dense 模型的好处是规整、统一、简单,但它有一个天然限制:
- 参数变大,容量上升
- 但每个 token 也要实打实经过这整套参数
换句话说,在 Dense 架构里:
total params和active params往往是同一个量级
这意味着一件事:
只要你继续把 Dense 做大,训练时每一步的计算开销也会一起显著变大。
于是 Dense 的扩容会越来越贵:
- 训练算力涨得快
- 显存压力涨得快
- 并行复杂度涨得快
- 训练周期和资源占用都越来越夸张
如果行业还想继续卷更强的模型能力,就必须想办法把“更大容量”和“更高单 token 计算”做一定程度的解耦。
MoE 恰恰就是在解决这件事。
2. MoE 能把“总容量”和“单次激活计算”部分解耦
MoE 最关键的结构直觉是:
- 我可以准备很多 experts
- 但每个 token 在每层只路由到其中少数几个 experts
于是会出现一个非常诱人的效果:
- 总参数可以很大
- 但每个 token 实际激活的参数量却相对有限
也就是大家常说的:
total params很大active params相对可控
这对训练侧意味着什么?
意味着同样的训练预算下,模型有机会获得更高的表达容量和更强的任务上限,而不需要为每个 token 都支付等比例放大的 dense 计算成本。
你可以把它理解成:
Dense:每次都动用整个大脑MoE:搭建一个更大的专家系统,但一次只调用其中一部分专家
这就是训练侧最心动的地方。
3. MoE 更容易继续把模型“做大”
当行业进入顶级模型竞争阶段后,大家卷的不再只是通用聊天,而是:
- reasoning
- code
- multilingual
- long context
- agent 和 tool use
这些能力都在逼模型拥有更高的容量上限。
而 MoE 给了一个非常现实的答案:
- 我未必需要让每个 token 都走完整个超大网络
- 但我可以让模型整体“拥有”更大的专家池和更大的参数空间
于是对于训练团队来说,MoE 就像一个可继续放大的容器:
- benchmark 更容易继续冲高
- 参数量叙事更有传播力
- scaling 路径也更容易延长
这也是为什么这几年很多前沿模型都在继续往 MoE 靠。
4. MoE 天然适合做“更强容量叙事”
这里还有一个很现实、但大家不一定明说的因素:
MoE 非常适合构建“更大模型”的认知优势。
因为它可以同时讲两个数字:
- 总参数有多大
- 推理时活跃参数有多小
这两个数字放在一起,对外非常有吸引力:
- 听上去像一个超大模型
- 又不像 dense 一样显得那么“算不过来”
对训练侧、研究侧、市场传播侧来说,这个叙事都很强。
5. 训练生态这两年终于成熟到“能大规模卷 MoE”
其实 MoE 不是新想法,真正让它在这几年爆发的,是工程生态终于跟上来了。
过去大家对 MoE 的顾虑很多:
- 路由机制难训
- load balancing 难做
- expert 并行复杂
- 集群通信代价很高
- 实际训练不够稳定
但近几年,随着大规模训练框架和并行策略越来越成熟,很多团队已经具备了把 MoE 工业化的能力。
于是训练侧就更敢选它了。
换句话说,不是 MoE 突然变得“理论上更对”,而是:
到了今天,行业终于具备了把 MoE 训练红利吃出来的基础设施。
三、为什么部署侧很多公司最后还是更偏爱 Dense
上面说完训练侧,我们再看部署侧。
这里最容易出现的误判是:
既然 MoE 的 active params 更小,那它部署不是天然更香吗?
不一定。
因为部署要结算的账,远不止 active params 这一项。
甚至可以说,很多团队从“喜欢 MoE”回到“更偏爱 Dense”,往往就是因为他们真正开始把部署账一本一本拆开了。
1. 第一笔账:权重驻留账,不是 active 小就等于好部署
MoE 最大的误解之一,就是把“单 token 激活计算较小”直接等同于“部署成本较低”。
但在真实部署里,第一件事通常不是“这 token 算多少”,而是:
这些权重到底要不要常驻显存?
多数 MoE 推理场景下,虽然每个 token 只会命中部分 experts,但:
- 整个专家池的权重通常仍然要驻留在 GPU 上
- 或至少要以一种高效可访问的方式分布在多卡系统上
所以部署时首先要面对的是:
- 模型能不能装下
- 装下之后卡间怎么切
- experts 怎么分布
- 有没有严重的显存碎片和不均衡
这意味着:
MoE 的 active 小,解决的是“算多少”的问题;但部署首先还要解决“放哪儿”和“怎么取”的问题。
而在很多公司里,真正先把人打回现实的,恰恰就是这笔权重驻留账。
Dense 的优点则很朴素:
- 结构规整
- 分片方式清晰
- 参数布局更稳定
- 工具链支持更成熟
所以虽然它每个 token 算得更多,但“把模型放进去并稳定跑起来”这件事,通常更直接。
2. 第二笔账:通信账,MoE 很多时候不是算力瓶颈,而是通信瓶颈
这其实是 MoE 部署最关键、也最容易被低估的问题。
在 Dense 模型里,多卡并行当然也有通信,但整体路径相对规整。
而 MoE 不一样。
它除了常规的并行通信外,还要面对:
- token 到 expert 的路由
- 不同卡上 expert 的分布
- expert 并行下的数据搬运
- all-to-all 这类更重的通信模式
于是现实中经常出现一种情况:
- 理论上 active params 不大
- 但实际吞吐并没有想象中那么高
- 甚至多卡一拉起来,卡间通信开始主导系统表现
这也是很多部署团队对 MoE 爱恨交加的根源。
因为他们会发现:
Dense 更吃算力,MoE 很多时候更吃系统。
如果你的硬件互联能力不够强,或者你的推理框架对 MoE 路由/并行优化不够成熟,那么理论上的架构优势,很容易被通信代价吃掉。
3. 第三笔账:延迟账,Dense 往往更稳定,MoE 更容易出现波动
部署不是只看平均吞吐,还要看:
- P50 延迟
- P95 延迟
- P99 延迟
- 首 token 延迟
- 不同 batch 下的稳定性
在这件事上,Dense 有一个经常被低估的优势:
它的执行路径更固定,所以行为更可预测。
而 MoE 因为引入了路由机制,不同 token、不同 batch、不同流量分布下,触发的 experts 和卡间流量都可能变化。
这会带来几个问题:
- 延迟抖动更大
- tail latency 更难压
- 高并发下更容易出现局部热点
- 负载不均衡时更容易影响稳定性
也就是说,从服务视角看:
Dense更像一台输出稳定的机器MoE更像一套潜力很强但更考验调度的系统
如果你的业务是对实时性、稳定性和 SLA 特别敏感的在线服务,这种差别就会变得非常重要。
4. 第四笔账:batch 账,MoE 往往更依赖“足够好的吞吐条件”
很多 MoE 架构的优势,在较理想的 batch 条件下更容易体现。
为什么?
因为当请求规模更大、并行度更高时:
- experts 更容易被更充分地利用
- 通信和计算更有机会被摊薄
- 系统整体利用率更容易做上去
但现实业务不总是“理想 batch”:
- 请求长度参差不齐
- 并发波动很大
- 在线场景经常有低 batch、碎片化请求
- 高峰和低谷差异明显
在这种情况下,MoE 的系统开销不一定能被很好摊平。
于是就会出现一个现实判断:
MoE 更像一个在高组织度条件下更强的架构,Dense 则更像一个在复杂现实流量里更稳的架构。
这也是为什么很多云上统一服务平台、通用 API 服务商,哪怕认可 MoE 的能力优势,最后仍然会非常重视 Dense 方案。
5. 第五笔账:工具链账,Dense 的量化、蒸馏、微调、兼容性通常更成熟
很多团队选模型,看的不只是“今天能不能跑”,还要看:
- 能不能量化
- 能不能继续蒸馏
- 能不能做 LoRA / SFT / DPO
- 能不能方便接进现有推理框架
- 能不能稳定升级版本
在这些方面,Dense 通常有更成熟的生态优势:
- 量化路径更成熟
- 算子支持更完整
- 各类框架兼容性更好
- 微调、蒸馏和二次开发经验更多
而 MoE 往往会多出很多额外问题:
- expert 路由怎么兼容
- 量化后路由精度是否受影响
- 不同 expert 的量化误差是否一致
- 框架是否对该
MoE变体原生支持
这些问题不一定不能解决,但都会变成工程门槛。
对于很多不是“基础模型原厂”的公司来说,这类工程门槛本身就是成本。
6. 第六笔账:组织能力账,Dense 更适合大多数公司,MoE 更适合少数强工程团队
这是一个经常被技术讨论忽略,但在商业世界里非常真实的因素。
MoE 想把优势真正发挥出来,往往要求团队具备:
- 更强的并行和通信优化能力
- 更成熟的推理框架改造能力
- 更好的监控、调度和排障体系
- 对尾延迟、热点 expert、负载倾斜的持续治理能力
换句话说,MoE 的很多红利不是“拿来即用”的,而是“拿来以后还要配套组织能力去兑现”的。
而 Dense 的好处是:
- 工程路径更短
- 团队认知成本更低
- 运维难度更可控
- 风险暴露方式更熟悉
所以很多公司并不是觉得 Dense 一定比 MoE 强,而是会做一个非常现实的选择:
Dense 可能不是理论最优,但它往往是组织可驾驭性更高的最优。
四、训练世界里的“更优”,为什么到了部署世界里经常会变味
如果把上面这些账合在一起,你会发现一个非常有意思的现象:
训练世界奖励的是“更强容量”,部署世界奖励的是“更低摩擦”。
训练侧爱 MoE,是因为它更容易把能力天花板抬高。
部署侧偏爱 Dense,是因为它更容易:
- 装下
- 跑稳
- 跑透
- 算明白
- 复制到更多机器和更多场景
这两种偏好并不矛盾,它们只是服务于不同阶段的目标。
如果一定要把这件事说得更通俗一点,我会这样总结:
- 训练侧在追求“更强的模型”
- 部署侧在追求“更好的生意”
而“更强的模型”和“更好的生意”并不永远是同一个答案。
五、为什么很多公司最终会回到 Dense:不是技术倒退,而是利润表选择
这个地方特别值得讲透。
很多人一看到公司最后选了 Dense,就容易下意识觉得:
- 是不是这家公司技术不够强
- 是不是没有跟上架构趋势
- 是不是在用“落后方案”
其实很多时候都不是。
很多公司回到 Dense,真正原因往往只有一句:
Dense 更容易把智能稳定地变成可交付的利润。
为什么这么说?
因为企业最终看的是整张服务利润表,而不是单一 benchmark:
- 模型效果够不够
- 服务成本高不高
- GPU 利用率稳不稳
- tail latency 会不会拉高 SLA 成本
- 团队能不能管住这套系统
- 同样预算下,能不能支撑更多真实用户
在这个语境里,Dense 的价值就会被重新看见。
它不是最会讲故事的架构,但它常常是最容易持续交付的架构。
也正因为如此,你会看到一个很现实的行业分层:
- 顶级基础模型团队更愿意卷
MoE - 通用云服务平台会谨慎选择
MoE - 很多应用公司、私有化团队、成本敏感团队,依然会优先考虑
Dense
这背后的逻辑,和“谁更先进”关系没那么大,和“谁更适合我的约束条件”关系更大。
六、那是不是可以说 Dense 一定比 MoE 更适合部署?
也不能这么简单下结论。
更准确地说,应该是:
Dense 更适合大多数普通部署条件,MoE 更适合那些拥有强硬件、强框架、强系统能力的团队去榨取更高上限。
什么时候 MoE 更值得选?
- 你有更强的 GPU 集群和互联条件
- 你有成熟的推理框架和 expert parallel 能力
- 你确实需要更高能力上限
- 你的流量规模足够大,能把系统复杂度摊薄
- 你的团队能长期维护这套复杂系统
什么时候 Dense 更值得选?
- 你更看重延迟稳定性
- 你更在意部署链路简单
- 你硬件条件一般
- 你需要更成熟的量化和二次开发生态
- 你希望模型选型更稳妥、更通用、更可复制
所以真正成熟的判断方式,不是问:
Dense和MoE谁先进
而是问:
- 在我的约束条件下,谁能把“模型能力”转成“稳定服务能力”?
七、一个最容易记住的判断框架
如果你以后看到一个新模型,想快速判断它更像“训练赢家”还是“部署赢家”,我建议直接问自己下面这几件事:
1. 它大在哪里?
- 是总参数大
- 还是活跃参数也很大
- 还是容量大但激活算力受控
2. 它贵在什么地方?
- 贵在纯算力
- 贵在显存
- 贵在通信
- 贵在系统复杂度
3. 它适合什么流量形态?
- 高并发大 batch
- 还是低延迟碎片化请求
4. 它要求什么组织能力?
- 普通推理平台就能接
- 还是需要专门的系统优化团队
如果这四个问题都想清楚了,你对 Dense 和 MoE 的判断基本就不会跑偏。
八、最后总结:为什么训练侧爱 MoE,部署侧偏 Dense
我们最后把全文收成几句话。
第一句:
训练侧爱 MoE,是因为它让“更大容量”和“可接受的单 token 计算”之间出现了一种新的平衡。
第二句:
部署侧偏 Dense,不是因为 Dense 更强,而是因为 Dense 更规整、更稳定、更容易把智能能力转成现实服务能力。
第三句:
MoE 优化的是能力扩张问题,Dense 优化的是交付摩擦问题。
第四句,也是我最想强调的一句:
训练看的是天花板,部署看的是地板;天花板更高的架构,不一定就是地板最稳的架构。
这也是为什么今天的行业会同时出现两种趋势:
- 顶级模型继续卷
MoE - 大量真实业务仍然重视
Dense
它们不是互相否定,而是在不同优化目标下各自合理。
如果你把这个逻辑想透了,再去看任何一个新模型的发布、榜单、参数量、active params、部署成本和产品定价,你会发现很多以前看似矛盾的现象,都会突然变得非常好理解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)