用 RAG 重构需求管理:一个可落地的 AI 协作系统实践:技术分享系列(一)
01|从单点到协同:智能项目管理系统的架构演进与技术选型
这篇讲“为什么这么设计”,不讲所有细节实现。重点是:如何在项目管理系统里把业务稳定性和 AI 能力同时做好。
先说结论
这个系统最终走向的是一种“分工明确”的架构:
-
Java Spring Boot 负责核心业务(用户、项目、任务、风险、权限)
-
Python FastAPI 负责 RAG 检索(向量、模型、GPU)
-
前端 React 负责交互体验(看板、对话、确认动作)
-
LLM 作为可替换推理服务(本地或云端 OpenAI 兼容接口)
这套组合的核心价值是:业务层稳定、AI 层可迭代、运维层可拆分。
架构总览
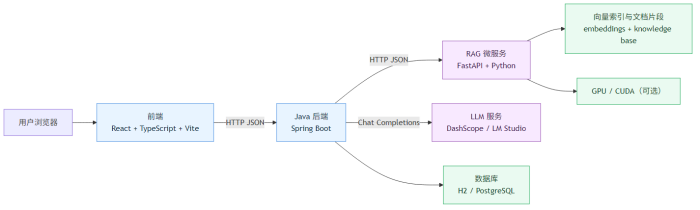
为什么不是“全都放一个后端里”
很多项目一开始会想:都在一个后端里做,最简单。但随着 AI 能力变重,这个策略会越来越吃力。
1) 技术生态差异明显
-
Java 在业务系统、鉴权、事务、数据一致性上很稳
-
Python 在向量检索、模型推理、AI 生态上更成熟
如果强行统一到一边,通常会牺牲另一边的开发效率。
2) 性能瓶颈不在同一个地方
-
业务 API:瓶颈常见在数据库访问和并发处理
-
RAG 检索:瓶颈常见在向量计算、模型加载、GPU 利用
拆服务后可以独立扩容和定位性能问题,不会互相拖慢。
3) 迭代节奏不同
-
业务规则变化需要谨慎发布(影响真实数据)
-
AI 策略变化频繁(prompt、阈值、检索策略常常要调整)
分离后可以减少“改 AI 误伤业务”的概率。
这次技术选型的“实战原则”
原则 A:核心业务优先确定性
任务状态流转、风险闭环、权限边界这些逻辑,优先放在 Java 业务层做强校验,不让“智能”破坏业务一致性。
原则 B:AI 能力通过接口接入
不把 AI 和业务写死耦合,使用清晰的 HTTP 边界:
-
ChatService编排流程 -
RagClient调检索服务 -
RawLlmClient调推理服务
这使得更换模型、替换检索策略时,改动集中且可控。
原则 C:允许“可退化”
当 RAG 服务不可用或相似度不达标时,系统可回退到常规对话,不让用户“完全不可用”。
服务边界与职责拆分
前端(React + TypeScript)
-
聊天 UI、多轮上下文管理
-
任务看板与成员确认交互
-
RAG 模式开关与增强模式选择
Java 后端(Spring Boot)
-
认证授权(JWT + Security)
-
项目/任务/风险/用户/会话等核心 API
-
AI 编排(检索、阈值判断、提示词拼接、动作检测)
Python RAG 服务(FastAPI)
-
向量检索与增强检索
-
模型与向量索引加载
-
返回可注入上下文和来源文档
LLM 服务(本地或云端)
-
执行最终文本生成
-
对接 OpenAI 兼容接口,降低切换成本
这套架构的代价与应对
代价 1:系统从 2 层变成 3 层
多了服务调用链,也多了故障点。
应对:增加健康检查、诊断接口、分层日志。
代价 2:配置复杂度上升
端口、超时、模型、阈值、跨域都要统一。
应对:环境变量优先,文档化默认值,提供排查清单。
代价 3:本地环境门槛更高
需要同时跑前端/后端/LLM/RAG。
应对:脚本化启动顺序,保留可独立调试入口。
可以直接复用的经验
-
业务系统 + AI 能力并行建设时,优先考虑“职责拆分”,不是“语言统一”
-
先定义降级路径,再加智能增强;不要让 AI 变成单点
-
把“诊断能力”当正式功能做(不是临时脚本)
下一篇预告
下一篇讲最容易引发线上事故的三类问题:CORS、枚举大小写、LLM 超时/格式兼容,并给出可以照抄的排查框架。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)