科晶生物双擎AI驱动,解锁“蛋白/核酸”大分子定向设计新范式

在创新药发现、合成生物学及基因调控等前沿研究中,寻找能与特定靶标(蛋白质或复杂核酸分子)高特异性、高亲和力结合的多肽,是推进项目的核心环节。然而,传统的实验突变筛选往往耗时长、成本高,且犹如“大海捞针”,假阳性率令人头疼。
随着人工智能大模型在生命科学领域的飞速突破,数字化计算生物学为大分子互作难题带来了全新解题思路。合肥科晶生物技术有限公司,秉持“按需设计,生命分子”的理念,依托前沿的AI算法矩阵,正式推出「蛋白质高亲和多肽设计」与「核酸高亲和多肽设计」两大技术服务,致力于通过高精度的“干实验”预测,助您大幅缩减“湿实验”的试错成本!
核心服务一:蛋白质高亲和多肽设计 —— 突破天然序列,精准锚定靶心
针对复杂的蛋白质靶标,科晶生物摒弃了传统模板的限制,采用备受业界瞩目的从头设计(De novo design)策略,搭建了一套严谨的“数字漏斗式”虚拟筛选流程:
- 精准划定结合口袋:基于目标靶点(诱饵蛋白)的三维构象,科学分析并精准锁定活性位点(特定氨基酸区间),让多肽设计直击“靶心”。
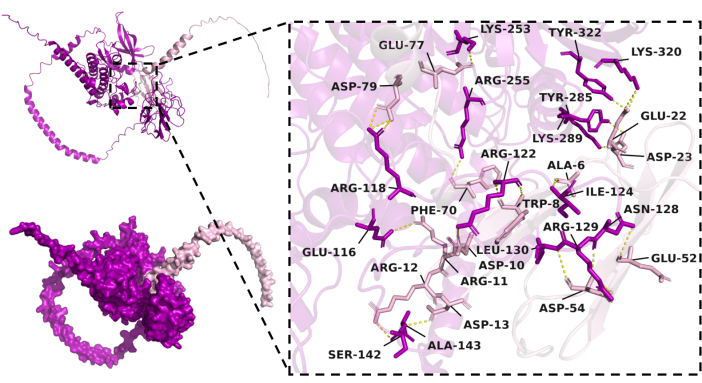
蛋白互作活性位点绘图
- RFdiffusion海量生成:利用深度学习扩散模型 RFdiffusion,针对活性位点一次性生成上千个高特异性结合物(Binder)。通过精细控制多肽长度(如 8-15bp),在保障结构多样性的同时,有效规避假阳性。
- HDOCK 动力学精筛:引入高效蛋白对接工具 HDOCK 进行能量评估。筛选出结合能(Docking Score)极低(参考值 < -200,置信度得分 > 0.7)的高潜分子,精准识别具备优秀互作潜力的稳定构象。
- AlphaFold3 终极确证:对Top级候选物进行 AlphaFold3 一对一精细复合物建模。重点关注 pTM(预测整体折叠正确性)与 ipTM(预测界面接触准确性)双重指标。当综合得分 pTM+ipTM > 0.75 时,代表对接效果优异,结果具有极高的生物学参考价值!
科研赋能“大礼包”:不仅交付序列与三维模型,我们还为候选多肽提供详尽的理化性质预测(包括消光系数、GRAVY疏水性指标、理论等电点pH及不稳定指数),全方位预判多肽的成药性与水溶性,扫清后续实验障碍。
核心服务二:核酸高亲和多肽设计 —— 全原子生成,解锁基因靶向新密码
在基因编辑、转录调控以及核酸药物递送领域,针对DNA/RNA等核酸序列的多肽配体设计难度极大。为此,科晶生物引入了专门应对复杂大分子的前沿生成架构:
- 核酸三维微环境解析:借助强大的三维预测模型,精准解析目标核酸(如特定基因的翻译起始位点区)的空间构象,明确最佳结合微环境。
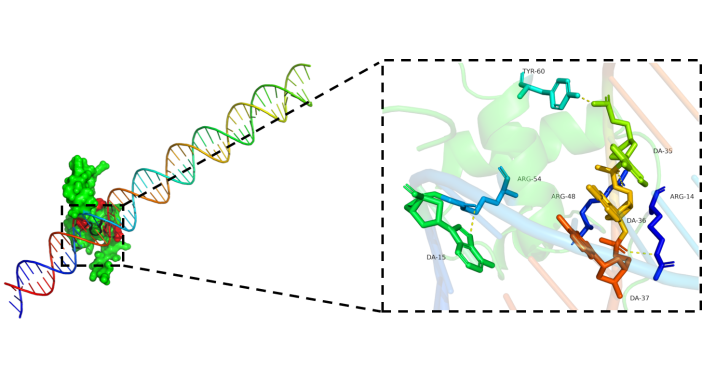
核酸-蛋白互作核心位点绘图
- Boltzgen 全原子定向设计:采用专为泛大分子互作打造的 Boltzgen 全原子扩散大模型,针对目标核酸序列从头设计数百个高亲和力多肽(如 30bp 长度)。它能够充分适应核酸表面的静电与空间特征,为核酸靶向提供丰富的高质量候选物。
- 双重严苛交叉验证:同样历经 HDOCK 的物理能量对接洗礼,并利用 AlphaFold3 针对“核酸-蛋白质”复合体进行精准的空间评估。通过提取核心多肽的 pLDDT(局部结构置信度)及复合体界面的 ipTM+pTM 打分体系,层层大浪淘沙,确保筛选出的多肽既能“紧密结合”,又能“结构稳定”。
为什么选择科晶生物?
在算力与算法狂飙的时代,严谨的数据逻辑才是科研成败的基石。
✅硬核算法矩阵:深度整合 RFdiffusion、Boltzgen、HDOCK 与 AlphaFold3,技术底座扎实,真正做到生成、筛选、验证的技术闭环。
✅多维客观评价:我们深知计算机打分仅是预测指标,拒绝“唯分数论”。综合考量对接结合能、结构置信度及界面匹配度,多维度交叉验证确保数据的客观性,最大限度降低体内动态环境误差。
✅专业交付体验:提供详尽规范的结题报告、完整的数据表格、原始 PDB 模型文件及权威参考文献。数据图表直观精美,可直接赋能您的学术论文撰写与项目申报。
让每一个靶点都有迹可循,让每一次结合都精准无误。科晶生物致力于成为您新药发现与科学研究中最可靠的数字化技术“外脑”。
如果您正面临靶标难成药、多肽筛选周期长、湿实验盲目试错成本高等痛点,欢迎随时与我们探讨数字化解决方案!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)