一文带大家理解:解决 RAG 质量管控难题的“瑞士军刀”——RAGAS
一、 RAGAS 框架的核心逻辑
RAGAS(全称是 Retrieval-Augmented Generation Assessment)的核心值在于它解决了 RAG 系统“黑盒”难测的问题。它不需要你准备海量的标注数据,而是通过 LLM 自动生成评估结果。它就像是 RAG 系统的“体检中心”。它通过大模型(LLM)作为评判者,自动评估 RAG 应用的性能。它的核心价值是——相比于人工一条条去核对检索结果,Ragas 可以自动化、规模化地运行测试,并给出量化的指标数据。
RAGAS 目前在开源社区和 RAG(检索增强生成)开发者中享有极高的声誉,被视为 RAG 评估领域的“标配”工具。虽然它在普通大众中的知名度不如一些应用软件,但在 AI 工程师和开发者眼中,它是解决 RAG 质量管控难题的“瑞士军刀”
1. 评估的四大核心要素
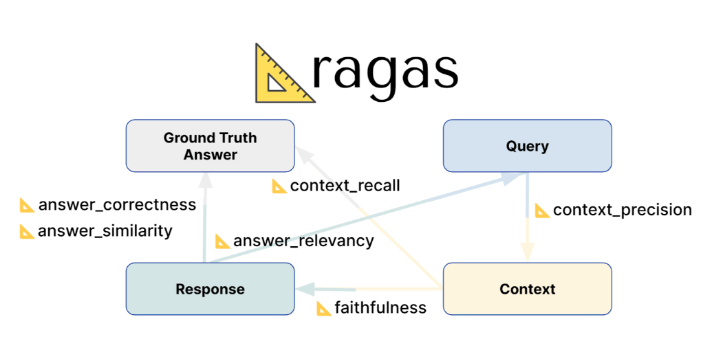
RAGAS 在进行评估时,主要依赖以下四个输入要素来计算指标:
- Question(问题): 用户的原始查询。
- Contexts(上下文): 从知识库中检索出来的文档片段。
- Answer(答案): RAG 系统根据上下文生成的最终回复。
- Ground Truth(真实答案): 人工标注的标准答案(这是唯一需要人工介入的环节,用于对比)。
2. 核心评估指标
RAGAS 构建了一套双维度的评估体系,分别对应 RAG 流程的两个阶段:
| 维度 | 指标名称 | 含义 | 作用 |
|---|---|---|---|
| 检索质量 | 上下文精度 | 检索到的上下文与问题的相关程度,过滤冗余信息。 | 评估检索器是否抓取了“有用”的信息,去除了噪音。 |
| 检索质量 | 上下文召回率 | 衡量是否检索到了回答问题所需的全部关键信息。 | 评估检索器是否“漏掉”了重要信息。 |
| 生成质量 | 忠实度 | 生成的答案是否忠实于检索到的上下文,是否存在“幻觉”。 | 评估生成器是否基于事实回答,没有胡编乱造。 |
| 生成质量 | 答案相关性 | 生成的答案对用户问题的响应程度。 | 评估最终答案是否切题、完整。 |
补充说明: 除了上述四大核心指标,RAGAS 还支持 答案准确性、上下文实体召回率 以及 噪声敏感度 等高级指标。
3. RAGAS 的优缺点
RAGAS 被广泛认为是目前最科学、最全面的开源 RAG 评估框架之一。
为什么它评价很高?(优势)
- 评估维度最全面:不同于早期只关注单一指标的工具,RAGAS 提出了多维度的评估体系(如忠实度、答案相关性、上下文精度、上下文召回率),能够全方位“体检”RAG 系统。
- 自动化程度高:它解决了“测试数据匮乏”的痛点。通过
TestsetGenerator模块,它可以基于你的文档库自动生成高质量的测试集(包含问题、标准答案和上下文),大大降低了人工标注的成本。 - 无参考评估(Reference-free):这是它的一大创新。除了计算准确率外,很多指标(如忠实度)不需要人工编写标准答案,而是利用 LLM 作为“裁判”进行推理判断,这使得大规模自动化评估成为可能。
- 生态集成好:它与主流框架(如 LangChain、LlamaIndex)无缝对接,且支持多种 LLM 作为后端评估模型(如 GPT-4、Claude、开源模型等),易于集成到现有的开发流程(CI/CD)中。
存在的槽点与挑战(劣势)
尽管好评如潮,但在实际使用中也存在一些挑战,你需要有所了解:
- 生成测试集的稳定性:有开发者反馈,RAGAS 的测试集生成功能有时“靠运气”,可能会出现连接错误,或者生成的 Prompt 是英文的(即使输入是中文),需要一定的调试技巧。
- 对评估模型依赖度极高:RAGAS 的核心逻辑是“用大模型评估小模型/系统”。如果作为“裁判”的 LLM(评估模型)能力不足,它就无法识别出细微的“幻觉”或语义偏差,导致评估结果失真(例如将错误的回答判为正确)。
- 成本问题:为了获得准确的评估结果,通常建议使用 GPT-4 或同级别的强模型作为评估器,这在大规模高频评估时会产生不菲的 API 费用。
二、 如何具体应用 RAGAS?
应用 RAGAS 通常分为三个阶段:环境准备、数据准备、评估执行。以下是具体的操作步骤:
第一步:环境安装与配置
RAGAS 是一个 Python 库,你可以通过 pip 直接安装。
# 安装核心库
pip install ragas
# 根据你使用的 LLM 和文档加载工具,可能还需要安装
pip install langchain openai datasets
配置说明: RAGAS 需要调用 LLM(如 OpenAI 的 GPT 系列、DeepSeek 等)来进行评判,因此你需要配置相应的 API Key。
第二步:准备评估数据集
你需要构建一个包含 question、answer、contexts 和 ground_truth 的数据集。
data_samples = {
'question': ['第一届超级碗是什么时候举行的?', '谁赢得了最多的超级碗冠军?'],
'answer': ['第一届超级碗于1967年1月15日举行', '新英格兰爱国者队赢得了创纪录的六次超级碗冠军'],
'contexts': [['第一届 AFL-NFL 世界冠军赛是一场美式橄榄球比赛...']],
'ground_truth': ['第一届超级碗于1967年1月15日举行', '新英格兰爱国者队赢得了创纪录的六次超级碗冠军']
}- 数据来源: 你可以手动构建,也可以使用 RAGAS 提供的
TestsetGenerator模块,基于你的文档库自动生成测试集,这能极大降低人工成本2。
第三步:执行评估
使用 RAGAS 的 evaluate 函数,传入你的数据集和想要评估的指标。
from ragas import evaluate
from ragas.metrics import context_precision, faithfulness, answer_relevancy, context_recall
# 将数据转换为 Dataset 格式
dataset = Dataset.from_dict(data_samples)
# 执行评估
result = evaluate(
dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall
]
)
print(result)三、 RAGAS 的典型应用场景
在实际开发和运维中,RAGAS 主要用于以下四个场景:
- MVP 原型验证(快速判断可行性)
在开发初期,利用 RAGAS 快速跑通流程,判断基础版本的核心指标(如上下文精度)是否达到及格线(例如 >60%),避免在无效方案上浪费过多资源。 - 检索策略对比(选型决策)
当你在纠结使用哪种检索算法(如 BM25 vs 向量检索 vs 混合检索)时,可以用 RAGAS 对同一数据集进行测试。场景示例: 发现向量检索在语义关联场景精度更高,而 BM25 在关键词密集场景召回率更好,从而决定采用混合检索策略。 - 生成模型与提示词优化
针对“幻觉”问题,重点监控 忠实度(Faithfulness) 指标。如果分数低,说明模型在编造信息。此时你可以调整提示词(Prompt),例如加入“仅基于提供上下文回答”的约束,再用 RAGAS 验证优化效果。 - 生产环境监控(CI/CD 集成)
将 RAGAS 集成到持续集成流程中。例如,每周自动运行一次评估,监控核心指标是否发生退化(如因知识库更新导致检索准确率下降),一旦低于阈值立即告警。
四、 RAGAS如何应用(TestsetGenerator是重点)
1. 需要提供什么?
只需要准备原始的知识文档库(Documents/Corpus)。
- 这可以是 PDF、TXT、Word 文件,或者是已经处理好的文本片段。
- 不需要对这些文档做任何标注,不需要写问题,也不需要写答案。
2. RAGAS 的 TestsetGenerator 做什么?
当我们把文档库喂给 TestsetGenerator 后,它会驱动 LLM 像一个“考官”一样工作,自动完成以下任务:
- 阅读文档:LLM 会先学习你的文档内容。
- 生成问题(Question):根据文档内容,自动生成有挑战性的问题。
- 生成真实答案(Ground Truth):LLM 会根据文档中的信息,写出它认为的“标准答案”。
- 关联上下文(Context):它会记录下生成该问题和答案所依据的原文片段。
3. 这种方式的优缺点
为了让大家更清楚是否采用这种方式,总结了它的特点:
| 特性 | 说明 |
|---|---|
| 优点 | 省时省力。这是构建大规模测试集最快的方法,特别适合冷启动阶段。 多样性:可以生成简单、推理、多跳(multi-context)等各种类型的问题 . |
| 缺点 | 可能存在偏差:生成的 ground_truth 是基于 LLM 对文档的理解,可能与人类的标准答案有细微差别。需要校验:建议生成后人工抽查一部分,确保生成的质量符合预期。 |
4. 建议的工作流(最佳实践)
虽然可以完全自动生成,但建议大家采用“机器生成 + 人工校验”的混合模式,效果最好:
第一步(自动生成):使用 TestsetGenerator 基于我们的文档库生成一批测试集(例如 50-100 条)。
第二步(人工审核):快速浏览生成的 question 和 ground_truth。
如果发现生成的答案有错误或问题太简单,可以调整 LLM 的提示词(Prompt)或参数重新生成。
第三步(微调):对于少量关键的核心数据,我们可以手动替换掉自动生成的 ground_truth,以确保核心场景的评估绝对准确。
使用 TestsetGenerator,我们的角色从“出题人”变成了“监考官”和“质检员”。只需要把书(文档)给它,它来负责出题和写标准答案,我们最后检查一下这套卷子出得合不合格即可。
总结建议
RAGAS 是目前 RAG 开发中不可或缺的工具,它目前是 RAG 评估领域的事实标准(De facto Standard)。建议大家在项目启动时就引入它,建立一个“评估-优化-再评估”的闭环。特别是对于召回率(Context Recall)和忠实度(Faithfulness)这两个指标,它们直接决定了 RAG 系统是否“有用”和“可靠”。如果大家需要客观数据来向团队或上级证明 RAG 系统的效果,或者需要建立一个自动化的质量监控流程,RAGAS 是目前最值得信赖的开源选择。建议结合人工审核一起使用,以弥补 LLM 作为裁判可能存在的主观偏差。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)